23 ديسمبر 2025·8 دقيقة
كيفية بناء تطبيق ويب للتجزئة وتحليل المجموعات
دليل عملي خطوة بخطوة لبناء تطبيق ويب لتجزئة العملاء وتحليل المجموعات: نموذج البيانات، خطوط الأنابيب، واجهة المستخدم، المقاييس، والنشر.
دليل عملي خطوة بخطوة لبناء تطبيق ويب لتجزئة العملاء وتحليل المجموعات: نموذج البيانات، خطوط الأنابيب، واجهة المستخدم، المقاييس، والنشر.
قبل تصميم الجداول أو اختيار الأدوات، كن محددًا بشأن الأسئلة التي يجب أن يجيب عليها التطبيق. مصطلح «التجزئة والمجموعات» يمكن أن يكون له معانٍ كثيرة؛ الحالات الواضحة تمنعك من بناء منتج غني بالميزات لكنه لا يساعد أي شخص على اتخاذ قرار.
ابدأ بكتابة القرارات الدقيقة التي يريد الناس اتخاذها والأرقام التي يثقون بها لاتخاذها. أسئلة شائعة تشمل:
لكل سؤال، سجِّل النافذة الزمنية (يومي/أسبوعي/شهري) والدقة (مستخدم، حساب، اشتراك). هذا يبقي بقية البناء متوائمًا.
حدِّد المستخدمين الأساسيين ومسارات عملهم:
سجّل أيضًا احتياجات عملية: كم مرة يفحصون اللوحات؟ ما معنى «نقرة واحدة» بالنسبة لهم؟ وما البيانات التي يعتبرونها مرجعية.
عرّف نسخة قابلة للتسويق (MVP) تُجيب عن أهم 2–3 أسئلة بموثوقية. نطاق الـ MVP النموذجي: الشرائح الأساسية، بعض وجهات النظر للمجموعات (الاحتفاظ، الإيرادات)، ولوحات قابلة للمشاركة.
ادّخر عناصر «جميلة أن تتوفر» لاحقًا، مثل التصديرات المجدولة، التنبيهات، الأتمتة، أو منطق الشرائح متعدد الخطوات المعقّد.
إذا كانت السرعة لإطلاق أول نسخة حرجة، فكّر في تمهيد MVP بمنصة توليد واجهات مثل Koder.ai. يمكنك وصف مُنشئ الشرائح، خريطة الحرارة للمجموعات، واحتياجات ETL في محادثة وتوليد واجهة React وعامِل خلفي Go + PostgreSQL — ثم التكرار باستخدام وضع التخطيط، لقطات، والرجوع للخلف بينما تُعدّل الأطراف التعريفات.
يجب أن يكون النجاح قابلًا للقياس. أمثلة:
تصبح هذه المقاييس نجمك الشمالي عندما تظهر مقايضات لاحقًا.
قبل تصميم الشاشات أو كتابة مهام ETL، قرر ماذا يعني «عميل» و«فعل» في نظامك. نتائج المجموعات والتجزئة لا تثق إلا بقدر وضوح التعاريف الأساسية.
اختر معرفًا أساسيًا واحدًا ووثّق كيف يُربط كل شيء به:
كن صريحًا بشأن ربط الهوية: متى تدمج الزائر المجهول بالملف المعروف؟ وماذا لو انضم المستخدم لعدة حسابات؟
ابدأ بالمصادر التي تُجيب على حالات الاستخدام، ثم أضف أخرى حسب الحاجة:
لكل مصدر، سجّل نظام السجل والتواتر (زمن حقيقي، كل ساعة، يوميًا). هذا يمنع نقاشات "لماذا لا تتطابق الأرقام؟" لاحقًا.
حدّد منطقة زمنية واحدة للتقارير (غالبًا منطقة العمل أو UTC) وعرّف ما المقصود بـ "يوم"، "أسبوع"، و"شهر" (أسابيع ISO vs أسابيع تبدأ الأحد). إذا تتعامل مع إيراد، اختر قواعد العملة: العملة المخزنة، عملة التقرير، وتوقيت سعر الصرف.
اكتب التعريفات بلغة بسيطة وأعد استخدامها في كل مكان:
اعتبر هذه المسرد متطلبًا للمنتج: يجب أن يكون مرئيًا في الواجهة ومُشارًا إليه في التقارير.
تنجو أو تهلك تطبيقات التجزئة بناءً على نموذج البيانات. إذا لم يتمكن المحللون من الإجابة عن الأسئلة الشائعة باستعلام بسيط، يصبح كل شريحة جديدة مهمة هندسية مخصصة.
استخدم بنية حدث متسقة لكل ما تتتبعه. قاعدة عملية أساسية:
event_name (مثل signup, trial_started, invoice_paid)timestamp (خزّن بالـ UTC)user_id (الفاعل)properties (JSON لتفاصيل مرنة مثل utm_source, device, feature_name)حافظ على event_name مسيطرًا عليه (قائمة محددة)، واجعل properties مرنة — لكن وثّق المفاتيح المتوقعة. هذا يمنحك اتساقًا في التقارير دون عرقلة تغييرات المنتج.
التجزئة في الأساس "تصفية المستخدمين/الحسابات حسب السمات". ضع تلك السمات في جداول مخصصة بدلًا من إبقائها فقط في خصائص الأحداث.
سمات شائعة:
هذا يمكّن غير الخبراء من بناء شرائح مثل "مستخدمو SMB في الاتحاد الأوروبي على Pro مكتسبون عبر شريك" دون التنقيب في الأحداث الخام.
العديد من السمات تتغير مع الوقت — خاصة الخطة. إذا خزّنت فقط الخطة الحالية على سجل المستخدم/الحساب، تتغير نتائج المجموعات التاريخية.
نمطان شائعان:
account_plan_history(account_id, plan, valid_from, valid_to).اختر أحدهما بوعي بناءً على سرعة الاستعلام مقابل التخزين والتعقيد.
نموذج أساسي بسيط وودود للاستعلام هو:
user_id, account_id, event_name, timestamp, properties)user_id, created_at, region, إلخ)account_id, plan, industry, إلخ)هذا البناء يترجم بسلاسة لتجزئة العملاء وتحليل المجموعات/الاحتفاظ، ويتوسع مع إضافة منتجات وفرق واحتياجات تقارير إضافية.
تحليل المجموعات موثوق بقدر قواعده. قبل بناء الواجهة أو تحسين الاستعلامات، اكتب التعريفات الدقيقة التي سيستخدمها التطبيق حتى تتطابق كل رسم بياني وتصدير مع توقعات أصحاب المصلحة.
ابدأ بتحديد أنواع المجموعات التي يحتاجها المنتج. خيارات شائعة:
كل نوع يجب أن يرتبط بحدث مرجعي واحد واضح (وأحيانًا خاصية)، لأن ذلك يحدد عضوية المجموعة. قرر ما إذا كانت العضوية ثابتة أو يمكن تغييرها عند تصحيح بيانات تاريخية.
بعدها، عرّف كيف تحسب فهرس المجموعة (الأعمدة مثل الأسبوع 0، الأسبوع 1…). اجعل هذه القواعد واضحة:
اختيارات صغيرة هنا قد تغيّر الأرقام بدرجة تكفي لخلق تساؤلات عن التوافق.
عرّف ماذا يمثل كل خانة في جدول المجموعة. مقاييس نمطية:
كما حدد المقسوم عليه لمعدلات (مثال: معدل الاحتفاظ = المستخدمون النشطون في الأسبوع N ÷ حجم المجموعة في الأسبوع 0).
المجموعات تصبح معقدة عند الحواف. قرر قواعد لـ:
وثّق هذه القرارات بلغة بسيطة؛ سيشكرك نفسك المستقبلي (ومستخدموك).
تحليلاتك للتجزئة والمجموعات موثوقة بقدر جودة البيانات الداخلة. خط أنابيب جيد يجعل البيانات متوقعة: نفس المعنى، نفس الشكل، والمستوى الصحيح من التفاصيل يوميًا.
تستخدم معظم المنتجات مزيجًا من المصادر حتى لا يتوقف الفريق على تكامل واحد:
قاعدة عملية: حدّد مجموعة صغيرة من "الأحداث الضرورية" التي تشغّل المجموعات الأساسية (مثلاً: signup، أول فعل ذي قيمة، purchase)، ثم وسّع.
أضف التحقق قريبًا من نقطة الاستيعاب حتى لا تنتشر البيانات السيئة.
ركز على:
عندما ترفض أو تصلح سجلات، سجّل القرار في سجل تدقيق حتى تشرح "لماذا تغيّرت الأرقام".
البيانات الخام غير متناسقة. حوّلها إلى جداول تحليلية نظيفة ومتسقة:
user_id بـ account_id/organization_id لتجزئة B2B.شغّل المهام بجدول (أو تدفّق) مع قواعد تشغيل واضحة:
عامل خط الأنابيب كمنتج: قِسه، راقبه، واجعله مستقراً ومملًا.
مكان تخزين بيانات التحليلات يحدّد ما إذا كانت لوحة المجموعات فورية أم بطيئة للغاية. الاختيار الصحيح يعتمد على حجم البيانات، أنماط الاستعلام، وسرعة الحاجة للنتائج.
بالنسبة للمنتجات المبكرة، PostgreSQL يكفي غالبًا: مألوف، رخيص التشغيل، ويدعم SQL جيدًا. يعمل أفضل عندما يكون حجم الأحداث معتدلًا وتتوخى الحذر في الفهرسة والتقسيم.
إذا توقعت تدفقات أحداث ضخمة (مئات الملايين إلى مليارات الصفوف) أو العديد من المستخدمين المتزامنين للوحة، فكّر في مخزن بيانات (BigQuery, Snowflake, Redshift) للمرونة على نطاق واسع، أو متجر OLAP (ClickHouse, Druid) للجمعيات السريعة جدًا.
قاعدة عملية: إذا كان استعلام "الاحتفاظ بالأسبوع، مفلتر حسب الشريحة" يأخذ ثوانٍ في Postgres حتى بعد الضبط، فأنت تقترب من منطقة الـ warehouse/OLAP.
احتفظ بالأحداث الخام، لكن أضف هياكل صديقة للاستعلام:
user_id/account_id بـ segment_id مع valid_from/valid_to عند تغير العضويةهذا الفصل يمكّنك من إعادة حساب المجموعات/الشرائح دون إعادة كتابة جدول الأحداث بأكمله.
معظم استعلامات المجموعات تُفلتر بالزمن، الكيان، ونوع الحدث. أعطِ أولوية لـ:
(event_name, event_time))اللوحات تكرر نفس التجميعات: الاحتفاظ حسب المجموعة، العدود بالأسبوع، التحويل حسب الشريحة. احسب هذه مسبقًا بجدول زمني (ساعي/يومي) إلى جداول ملخّصة حتى تقرأ الواجهة بضعة آلاف صفوف — لا مليارات.
احتفظ بالبيانات الخام للتفاصيل، لكن اجعل التجربة الافتراضية تعتمد على الملخصات السريعة. هذا ما يميّز بين "التجول بحرية" و"الانتظار أمام دائرة التحميل".
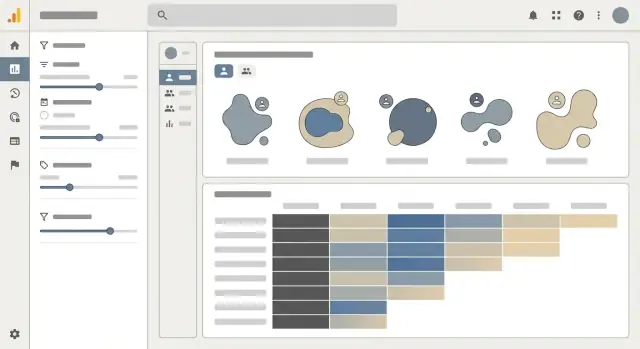
منشئ الشرائح هو المكان الذي ينجح فيه التجزئة أو يفشل. إذا بدا ككتابة SQL، فلن يستخدمه معظم الفرق. هدفك هو "منشئ أسئلة" يسمح لشخص ما بوصف من يعني، دون معرفة كيف تُخزن البيانات.
ابدأ بمجموعة صغيرة من أنواع القواعد التي ترتبط بأسئلة واقعية:
Country = United States, Plan is Pro, Acquisition channel = AdsTenure is 0–30 days, Revenue last 30 days > $100Used Feature X at least 3 times in the last 14 days, Completed onboarding, Invited a teammateاعرض كل قاعدة كجملة مع قوائم منسدلة وأسماء ودية للحقول (اخفِ أسماء الأعمدة الداخلية). حيث يمكن، اعرض أمثلة (مثلاً "المدة = أيام منذ أول تسجيل دخول").
غير الخبراء يفكرون بالمجموعات: "US and Pro and used Feature X"، مع استثناءات مثل "(US or Canada) and not churned." اجعلها بسيطة:
دع المستخدمين يحفظوا الشرائح باسم، وصف، ومالك/فريق اختياري. يجب إعادة استخدام الشرائح المحفوظة عبر اللوحات وعروض المجموعات، وأن تكون مُؤرَّخة حتى لا تغيّر التقارير القديمة بصمت.
أظهر دائمًا حجم الشريحة المقدر أو الدقيق مباشرة في المنشئ، متجددًا مع تغير القواعد. إذا كنت تستخدم العَيّنة للسرعة، كن صريحًا:
وأيضًا أظهر ما الذي يُحتسب: "المستخدمون يُعدُّون مرة واحدة" مقابل "الأحداث تُعدُّ"، ونافذة الزمن المستخدمة لقواعد السلوك.
اجعل المقارنات خيارًا أساسيًا: اختَر "الشريحة أ مقابل الشريحة ب" في نفس العرض (الاحتفاظ، التحويل، الإيراد). تجنّب إجبار المستخدمين على تكرار المخططات.
نمط بسيط: مُحدِّد "قارن مع..." يقبل شريحة محفوظة أخرى أو شريحة عارضة، مع تسميات واضحة وألوان متسقة عبر الواجهة.
تنجح لوحة المجموعات عندما تجيب عن سؤال واحد بسرعة: "هل نحتفظ (أم نفقد) الأشخاص، ولماذا؟" يجب أن تجعل الواجهة الأنماط واضحة، ثم تترك القارئ يغوص في التفاصيل دون فهم SQL أو نمذجة البيانات.
استخدم خريطة حرارة (heatmap) كأساس العرض، لكن عنونها كالتقرير — لا كلغز. كل صف يجب أن يعرض تعريف المجموعة وحجمها بوضوح (مثال: "أسبوع 7 أكتوبر — 3,214 مستخدمين"). كل خانة يجب أن تدعم التبديل بين نسبة الاحتفاظ والأعداد المطلقة، لأن النسب تخفي الحجم والأعداد تخفي النسبة.
حافظ على رؤوس الأعمدة متناسقة ("الأسبوع 0، الأسبوع 1، الأسبوع 2..." أو تواريخ فعلية)، وأظهر حجم المجموعة بجانب تسمية الصف ليحكم القارئ على درجة الثقة.
أضف تلميحات على كل تسمية مقياس (الاحتفاظ، التسرب، الإيرادات، المستخدمون النشطون) تذكر:
تلميح قصير أفضل من صفحة مساعدة طويلة؛ يمنع سوء التفسير وقت اتخاذ القرار.
ضع الفلاتر الأكثر شيوعًا فوق خريطة الحرارة واجعلها قابلة للعكس:
أظهر الفلاتر النشطة كشرائح (chips) وضمن زر "إعادة تعيين" بنقرة واحدة حتى لا يخشى الناس الاستكشاف.
وفّر تصدير CSV للعرض الحالي (بما في ذلك الفلاتر وما إذا كانت الجدول يعرض % أو أعداد). كما قدّم روابط قابلة للمشاركة تحفظ الإعداد.
عند المشاركة، طبّق الصلاحيات: الرابط لا يوسّع الوصول أكثر مما يملكه المشاهد بالفعل. إذا أضفت زر "نسخ الرابط"، أظهر تأكيدًا بسيطًا ورابطًا إلى /settings/access لإدارة من يمكنه الرؤية.
أدوات التجزئة وتحليل المجموعات غالبًا ما تتعامل مع بيانات العملاء، لذا الأمان والخصوصية لا يمكن أن يكونا فكرة لاحقة. عاملها كميزات منتج: تحمي المستخدمين، تقلل عبء الدعم، وتبقيك ملتزمًا أثناء النمو.
ابدأ بمصادقة مناسبة لجمهورك (SSO لـ B2B، بريد/كلمة مرور لـ SMB، أو كلاهما). ثم طبّق أدوارًا بسيطة ومتوقعة:
حافظ على اتساق الصلاحيات عبر الواجهة وواجهة البرمجة. إذا كان نقطة نهاية تصدر بيانات المجموعات، فصلاحية الواجهة وحدها غير كافية — طبّق فحوصًا خادمية أيضًا.
إذا كان التطبيق يدعم مساحات/عملاء متعددين، افترض "سيحاول شخص ما رؤية بيانات مساحة أخرى" وصمّم للعزل:
workspace_id.هذا يمنع تسريبات عبر المستأجرين، خاصة عندما ينشئ المحللون فلاتر مخصصة.
معظم تحليلات التجزئة والاحتفاظ تعمل بدون بيانات شخصية خام. قلّل مما تستوعبه:
أيضًا، شفّر البيانات أثناء التخزين والنقل، وخزن الأسرار (مفاتيح API، بيانات الاتصال) في مدير أسرار مناسب.
عرّف سياسات احتفاظ لكل مساحة: كم ستحتفظ بالأحداث الخام، الجداول المشتقة، والتصديرات. نفّذ مسارات حذف تُزيل البيانات فعلًا:
مسار واضح موثّق لاحتفاظ وحذف البيانات مهم بقدر المخططات نفسها.
اختبار تطبيق تحليلات ليس مجرد "هل الصفحة تحمل؟". أنت تُطلق قرارات. خطأ رياضي بسيط في احتساب الاحتفاظ أو خلل ترشيح خفي يمكن أن يضلل فريقًا كاملًا.
ابدأ باختبارات وحدة تتحقق من حسابات المجموعات ومنطق الشرائح باستخدام مجموعات بيانات صغيرة مع إجابة "صحيحة" واضحة (مثلاً 10 مستخدمين سجلوا في الأسبوع 1، 4 عادوا في الأسبوع 2 → احتفاظ 40%). اختبر:
تشغل هذه الاختبارات في CI حتى يتحقق كل تغيير في منطق الاستعلام أو التجميعات تلقائيًا.
معظم إخفاقات التحليلات سببها البيانات. أضف فحوصًا آلية تُشغّل على كل تحميل أو يوميًا على الأقل:
user_id, account_id)عند فشل فحص، أرسل تنبيهًا مع سياق كافٍ للعمل: أي حدث، أي نافذة زمنية، ومدى الانحراف عن الأساس.
شغّل اختبارات أداء تحاكي الاستخدام الحقيقي: نطاقات تواريخ كبيرة، فلاتر متعددة، خصائص عالية التفرُّد، وشرائح متداخلة. تتَبّع أزمنة الاستجابة عند النسب المئوية العليا (p95/p99) وفرض ميزانيات (مثلاً معاينة الشريحة تحت 2 ثانية، اللوحة تحت 5 ثوانٍ). إذا تراجعت الاختبارات، ستعرف قبل الإصدار التالي.
أخيرًا، قم باختبار قبول المستخدم مع زملاء المنتج والتسويق. اجمع مجموعة من "الأسئلة الحقيقية" التي يطرحونها اليوم وعرّف الإجابات المتوقعة. إذا لم يستطع التطبيق إعادة نتائج موثوقة (أو تفسير سبب الاختلاف)، فهو غير جاهز للشحن.
إطلاق تطبيق التجزئة وتحليل المجموعات أقل عن "إطلاق كبير" وأكثر عن إقامة حلقة أمنة: إطلاق، ملاحظة، تعلُّم، وتحسين.
اختر المسار الذي يتناسب مع مهارات فريقك واحتياجات التطبيق.
الاستضافة المدارَة (مثلاً منصة تنشر من Git) غالبًا أسرع للحصول على HTTPS موثوق، رجوع للخلف، ومقياس تلقائي مع جهد عملياتي قليل.
الحاويات مناسبة عندما تحتاج سلوك تشغيل متسق عبر البيئات أو تتوقع الانتقال بين مزوّدي السحابة.
الخوادم المعتمدة على الدوال (Serverless) جيدة للأحمال المتقطعة، لكن انتبه لوقت الاقلاع البارد والوظائف الطويلة لـ ETL.
إذا أردت مسارًا متكاملًا من النموذج الأولي إلى الإنتاج دون إعادة بناء لاحقة، فإن Koder.ai يدعم توليد التطبيق (React + Go + PostgreSQL)، نشره واستضافته، ربط نطاقات مخصصة، واستخدام لقطات/رجوع للخلف لتقليل المخاطر أثناء التكرار.
استخدم ثلاث بيئات: dev, staging, production.
في dev وstaging، تجنّب استخدام بيانات عملاء خام. حمّل مجموعات بيانات عيّنة آمنة تشبه الإنتاج (نفس الأعمدة، نفس أنواع الأحداث، نفس الحالات الحديّة). هذا يجعل الاختبار واقعيًا دون مشكلات الخصوصية.
اجعل staging بمثابة "عرض البروفة": بنية تحتية شبيهة بالإنتاج، لكن بيانات اعتماد معزولة، قواعد بيانات منفصلة، وأعلام ميزات لاختبار قواعد المجموعات الجديدة.
راقب ما ينكسر وما يبطيء:
أضف تنبيهات بسيطة (بريد/Slack) لعمليات ETL الفاشلة، ارتفاع معدلات الخطأ، أو ارتفاع مفاجئ في مهلات الاستعلام.
خطط إصدارات شهرية (أو كل أسبوعين) بناءً على ملاحظات مستخدمي غير الخبراء: فلاتر مربكة، تعريفات مفقودة، أو أسئلة مثل "لماذا هذا المستخدم في هذه المجموعة؟".
أعطِ أولوية للإضافات التي تفتح قرارات جديدة — أنواع مجموعات جديدة (مثلاً حسب قناة الاكتساب، مستوى الخطة)، افتراضات UX أفضل، وشرح أوضح — دون كسر التقارير الحالية. تساعد أعلام الميزات والحسابات ذات الإصدارات على التطور بأمان.
إذا شارك فريقك الدروس علنًا، فلاحظ أن بعض المنصات (بما في ذلك Koder.ai) تقدم برامج تكريمية قليلة مثل أرصدة لإنشاء محتوى عن بناءك أو إحالة مستخدمين آخرين — مفيدة عندما تقلّ التكاليف أثناء التجريب السريع.
ابدأ بـ 2–3 قرارات محددة يجب أن يدعمها التطبيق (مثل: الاحتفاظ في الأسبوع الأول حسب القناة، مخاطر التسرب حسب الخطة)، ثم عرّف:
بنِ بناء الـ MVP للإجابة على هذه الأمور بصورة موثوقة قبل إضافة تنبيهات أو أتمتة أو منطق معقد.
اكتب التعريفات بلغة بسيطة وأعد استخدامها في كل مكان (تلميحات الواجهة، الصادرات، الوثائق). على الأقل عرّف:
ثم طبّق قواعد موحدة للـ ، ، و حتى تتطابق المخططات وملفات CSV.
اختر مُعرفًا أساسيًا ووثّق كيف تترجم البقية إليه:
user_id للاحتفاظ/الاستخدام على مستوى الشخصaccount_id لتجميع B2B ومقاييس الاشتراكanonymous_id لسلوك ما قبل التسجيلعرّف متى يحدث ربط الهويات (مثلاً عند تسجيل الدخول)، وماذا يحدث في الحالات الحديّة (مستخدم في عدة حسابات، دمج، نسخ مكررة).
قاعدة عملية هي نموذج events + users + accounts:
event_name, timestamp (UTC), , , (JSON)إذا كانت سمات مثل الخطة تتغير بمرور الوقت، فإن تخزين القيمة «الحالية» فقط سيحوّل نتائج المجموعات التاريخية. نهجان شائعان:
plan_history(account_id, plan, valid_from, valid_to)اختر بناءً على ما تفضله بين سرعة الاستعلام أو بساطة التخزين/ETL.
اختر نوع المجموعة الذي يرتبط بحدث مرجعي واحد غير غامض (التسجيل، أول شراء، أول استخدام للميزة). ثم حدّد:
وكذلك قرر ما إذا كانت عضوية المجموعة ثابتة أم قابلة للتغيير عند تصحيح البيانات المتأخرة.
اتخذ قرارًا مسبقًا حول كيفية التعامل مع الحالات الحديّة:
ضع هذه القواعد في تلميحات الواجهة وبيانات التصدير حتى يفهم الأطراف النتائج باستمرار.
ابدأ بمسارات الاستيعاب الأقرب إلى مصدر الحقيقة:
أضف تحققًا مبكرًا (حقول مطلوبة، صحة الطوابع الزمنية، مفاتيح إزالة التكرار) واحتفظ بسجل تدقيق للرفض/التصليح حتى تشرح تغيّر الأرقام.
بالأحجام المتوسطة، يمكن أن يكفي PostgreSQL مع فهارس وتقسيم جيد. لمجاميع أحداث ضخمة أو كثرة مستخدمي لوحة التحكم المتزامنين، فكّر في مخزن بيانات (BigQuery/Snowflake/Redshift) أو متجر OLAP (ClickHouse/Druid) لأداء تجميع سريع.
لتسريع الواجهات، احسب مسبقًا نتائج شائعة مثل:
segment_membership (مع نوافذ الصلاحية إذا تغيرت العضوية)احتفظ بالبيانات الخام للتفاصيل، لكن اجعل تجربة الافتراضية تعتمد على الملخصات السريعة.
اعتمد سياسات وصول بسيطة ومتوقعة وطبّقها على الخادم:
للتطبيق متعدد المستأجرين، ضع في كل جدول وطبّق نطاق صفوف (RLS أو ما يعادله). قلّل من جمع البيانات الشخصية، اخفِها افتراضيًا، ونفّذ سياسات حذف تحذف الخام والمشتق (أو تميّز الملخصات كـ"قديمة" لإعادة الحساب).
user_idaccount_idpropertiesحافظ على event_name مسيطَرًا عليه (قائمة معروفة) وproperties مرنة لكن موثقة. هذا الترتيب يدعم حسابات المجموعات والتجزئة لغير الخبراء.
workspace_id