06 نوفمبر 2025·8 دقيقة
كيفية بناء تطبيق ويب لتتبّع الحوادث وإدارة تقارير ما بعد الحادث
مخطط عملي لتصميم وبناء وإطلاق تطبيق ويب لتتبع الحوادث وتقارير ما بعد الحادث — من سير العمل إلى نمذجة البيانات وتجربة المستخدم.
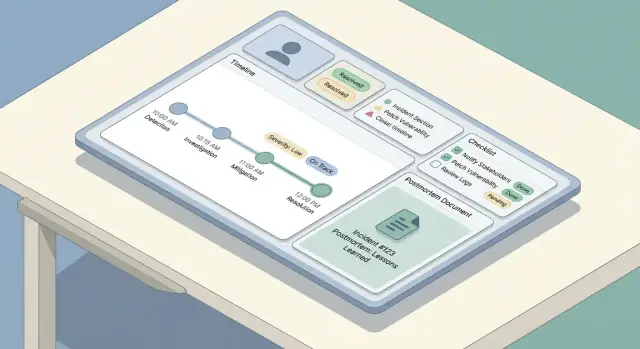
مخطط عملي لتصميم وبناء وإطلاق تطبيق ويب لتتبع الحوادث وتقارير ما بعد الحادث — من سير العمل إلى نمذجة البيانات وتجربة المستخدم.
قبل أن ترسم الشاشات أو تختار قاعدة بيانات، اتفقوا على ما يعنيه فريقكم بـ تطبيق تتبّع الحوادث — وما الذي يجب أن تحققه "إدارة تقارير ما بعد الحادث". كثير من الفرق تستخدم نفس المصطلحات بطرق مختلفة: لفريقٍ ما الحادث هو أي مشكلة أبلغ عنها العميل؛ ولآخر قد يعني فقط انقطاع من المستوى العالي مع تصعيد للمناوبة.
اكتب تعريفًا قصيرًا يجيب عن:
يدفع هذا التعريف سير عمل الاستجابة للحوادث ويمنع أن يصبح التطبيق صارمًا جدًا (لا أحد يستخدمه) أو مرنًا جدًا (البيانات غير متسقة).
قرّر ما هو تقرير ما بعد الحادث في منظمتكم: ملخص خفيف لكل حادث، أم تحليل جذري كامل للحوادث شديدة الشدة؟ أوضح ما إذا كان الهدف هو التعلم، الامتثال، تقليل تكرار الحوادث، أو كل ما سبق.
قاعدة مفيدة: إذا توقّعون أن ينتج عن تقرير ما بعد الحادث تغيّرًا، فعلى أداتكم دعم تتبع عناصر الإجراءات، لا الاكتفاء بتخزين الوثائق.
معظم الفرق تبني هذا النوع من التطبيقات لإصلاح مجموعة صغيرة من نقاط الألم المتكررة:
حافظ على هذه القائمة ضيقة. كل ميزة تضيفها يجب أن تُطابق واحدة على الأقل من هذه المشاكل.
اختر بضعة مقاييس يمكنك قياسها تلقائيًا من نموذج بيانات التطبيق:
تصبح هذه مقاييسكم التشغيلية و"تعريف الإنجاز" للإصدار الأول.
نفس التطبيق يخدم أدوارًا مختلفة في عمليات المناوبة:
إذا صمّمت للجميع دفعة واحدة، ستبني واجهة فوضوية. بدلًا من ذلك، اختر مستخدمًا أساسيًا للإصدار الأول—وتأكد أن الآخرين يمكن أن يحصلوا على ما يحتاجون إليه عبر عروض مخصَّصة، لوحات تحكم، وصلاحيات لاحقًا.
سير واضح للعمل يمنع وضعين شائعين من الفشل: حوادث تتوقف لأن لا أحد يعرف "ما التالي"، وحوادث تبدو "مكتملة" لكنها لا تنتج تعلمًا. ابدأ برسم دورة الحياة من البداية إلى النهاية ثم ربط الأدوار والصلاحيات بكل خطوة.
معظم الفرق تتبع قوسًا بسيطًا: كشف → فرز → تخفيف → حل → تعلّم. يجب أن يعكس تطبيقك هذا بمجموعة صغيرة من الخطوات المتوقعة، لا قائمة خيارات لا تنتهي.
عرّف ما يعنيه "مكتمل" لكل مرحلة. على سبيل المثال، قد يعني التخفيف إيقاف تأثير العميل، حتى لو ظل السبب الجذري مجهولًا.
اجعل الأدوار واضحة حتى يتصرف الناس دون انتظار الاجتماعات:
ينبغي أن تُظهر واجهة المستخدم "المالك الحالي" بوضوح، وينبغي للسير أن يدعم التفويض (إعادة التعيين، إضافة مستجيبين، تدوير القائد).
اختر حالات مطلوبة والانتقالات المسموح بها، مثل Investigating → Mitigated → Resolved. أضف ضوابط:
فصّل التحديثات الداخلية (سريعة، تكتيكية، قد تكون فوضوية) عن تحديثات أصحاب المصلحة (مُنسّقة، مؤرخة زمنياً، مُختارة). ابنِ تيارين للتحديثات بقوالب ورؤية وقواعد موافقة مختلفة—غالبًا ما يكون القائد هو الناشر الوحيد لتحديثات أصحاب المصلحة.
أداة حوادث جيدة تبدو "بسيطة" في الواجهة لأن نموذج البيانات تحتها متسق. قبل بناء الشاشات، قرّر ما الكائنات التي توجد، كيف ترتبط، وما الذي يجب أن يظل دقيقًا تاريخيًا.
ابدأ بمجموعة صغيرة من الكيانات الأساسية:
معظم العلاقات واحد إلى متعدد:
استخدم معرّفات ثابتة (UUIDs) للحوادث والأحداث. يحتاج البشر إلى مفتاح ودود مثل INC-2025-0042 يمكنك توليده من تسلسل.
نمذج هذه مبكرًا حتى تتمكن من التصفية والبحث والتقارير:
بيانات الحوادث حساسة وغالبًا ما تُراجع لاحقًا. عامل التعديلات كبيانات—لا كمحاولات للكتابة فوقها:
هذه البنية تجعل ميزات لاحقة—البحث، المقاييس، والصلاحيات—أسهل للتنفيذ دون إعادة عمل.
عندما ينهار شيء، مهمة التطبيق هي تقليل الكتابة وزيادة الوضوح. يغطي هذا القسم "مسار الكتابة": كيف ينشئ الناس حادثًا، كيف يحدثونه، وكيف تُعاد تركيب القصة لاحقًا.
حافظ على نموذج الاستقبال قصيرًا بما يكفي لإنهائه أثناء التحري. مجموعة الحقول الإلزامية الجيدة الافتراضية:
كل شيء آخر اختياري عند الإنشاء (التأثير، روابط تذاكر العملاء، سبب مشتبه به). استخدم إعدادات افتراضية ذكية: ضع وقت البدء على "الآن"، اختر فريق المناوبة للمستخدم مسبقًا، وقدم إجراءًا بنقرة واحدة "أنشئ وافتح غرفة الحادث".
يجب تحسين واجهة التحديث للتكرار والقصيرة. قدّم لوحة تحديث مدمجة مع:
اجعل التحديثات قابلة للإضافة: كل تحديث يصبح مدخلاً مختومًا زمنيًا، لا كتابة فوق النص السابق.
ابنِ خطًا زمنيًا يخلط بين:
هذا يخلق سردًا موثوقًا دون إجبار الناس على تذكّر تسجيل كل نقرة.
أثناء الانقطاع، تحدث الكثير من التحديثات من الهاتف. أعط الأولوية لشاشة سريعة وقليلة الاحتكاك: نقاط لمس كبيرة، صفحة تمرير واحدة، مسودات صديقة للعمل بدون اتصال، وإجراءات بنقرة واحدة مثل "نشر تحديث" و"نسخ رابط الحادث".
الشدة هي "زر السرعة" لاستجابة الحوادث: تخبر الناس بمدى العجلة، مدى انتشار الاتصالات، وما التنازلات المقبولة.
تجنّب تسميات غامضة مثل "عالية/متوسطة/منخفضة". اجعل كل مستوى شدة يربط بتوقعات تشغيلية واضحة—خاصة زمن الاستجابة وتواتر الاتصالات.
مثال:
اجعل هذه القواعد مرئية في واجهة المستخدم أينما تُختار الشدة، حتى لا يحتاج المستجيبون للبحث في الوثائق.
تقلل القوائم المرجعية العبء الإدراكي عند الضغط. اجعلها قصيرة، قابلة للتنفيذ، ومرتبطة بالأدوار.
نمط مفيد هو بضعة أقسام:
اجعل عناصر القائمة مُختومة زمنياً ومنسوبة، بحيث تصبح جزءًا من سجل الحادث.
نادراً ما يعيش الحادث في أداة واحدة. يجب أن يسمح تطبيقك للمستجيبين بإرفاق روابط إلى:
فضّل الروابط "المُصنّفة" (مثلاً، Runbook، Ticket) حتى يمكن تصفيتها لاحقًا.
إذا كانت مؤسستك تتبع أهداف موثوقية، أضف حقولًا خفيفة مثل هل تأثر SLO (نعم/لا)، تقدير استهلاك ميزانية الخطأ، وخطر خرق SLA للعميل. اجعلها اختيارية—لكن سهلة الملء أثناء الحادث أو مباشرة بعده.
تقرير ما بعد الحادث الجيد سهل البدء، يصعب نسيانه، ومتّسق عبر الفرق. أبسط طريقة للوصول لذلك هي تقديم قالب افتراضي (بحقول مطلوبة قليلة) وملؤه تلقائيًا من سجل الحادث حتى يقضي الناس وقتهم في التفكير بدلًا من إعادة الكتابة.
قالبكم الافتراضي يجب أن يوازن بين البنية والمرونة:
اجعل "السبب الجذري" اختياريًا في البداية إذا أردت نشرًا أسرع، لكن اشترطه قبل الموافقة النهائية.
لا يجب أن يكون التقرير مستندًا منفصلًا يطفو في العدم. عند إنشاء تقرير ما بعد الحادث، اربط تلقائيًا:
استخدم هذه العناصر لملء أجزاء من القالب. على سبيل المثال، يمكن أن يبدأ قسم "التأثير" بأوقات بدء/انتهاء الحادث والشدة الحالية، بينما يمكن لسجل "ما قمنا به" أن يجلب مدخلات من أحداث الخط الزمني.
أضف مسار عمل خفيف حتى لا تتوقف التقارير:
في كل خطوة، سجّل ملاحظات القرار: ما الذي تغيّر، ولماذا، ومن وافق. هذا يمنع "التعديلات الصامتة" ويجعل المراجعات المستقبلية أو التدقيق أسهل بكثير.
إذا رغبت في واجهة أبسط، عالج المراجعات كتعليقات مع نتائج صريحة (Approve / Request changes) واحفظ الموافقة النهائية كسجل غير قابل للتغيير.
للفرق التي تحتاج ذلك، اربط حالة "منشور" بتدفّق تحديثات الحالة الخاص بكم (انظر /blog/integrations-status-updates) دون نسخ المحتوى يدويًا.
تقارير ما بعد الحادث تقلل الحوادث المستقبلية فقط إذا نُفّذت أعمال المتابعة فعلاً. عامل عناصر الإجراءات ككيانات أساسية في التطبيق—لا كفقرة في أسفل المستند.
يجب أن يحتوي كل عنصر إجراء على حقول متسقة حتى يمكن تتبعه وقياسه:
أضف بيانات وصفية صغيرة ومفيدة: وسوم (مثلاً "مراقبة"، "توثيق"), مكوّن/خدمة، و"منشأ من" (معرّف الحادث ومعرّف تقرير ما بعد الحادث).
لا تحصر عناصر الإجراءات داخل صفحة تقرير واحد. قدّم:
هذا يحوّل المتابعات إلى طابور تشغيل بدلاً من ملاحظات متناثرة.
بعض المهام متكررة (تجارب اللعب الربعية، مراجعات أدلة التشغيل). ادعم قالبًا متكررًا يولد عناصر جديدة بجدول زمني، مع إبقاء كل تكرار قابلاً للتتبع بشكل مستقل.
إذا كان الفريق يستخدم متعقّب أعمال خارجيًا، اسمح لعنصر الإجراء بأن يتضمن رابط مرجعي خارجي ومعرّف خارجي، مع إبقاء تطبيقك مصدر الارتباط والتحقق للحوادث.
ابنِ تذكيرات خفيفة: أبلغ المالكين مع اقتراب تاريخ الاستحقاق، علّم القائد عند تأخر الأعمال، واطرح أنماط التأخر المزمنة في التقارير. اجعل القواعد قابلة للتكوين حتى تتوافق مع واقع عمليّات المناوبة وعبء العمل.
غالبًا ما تحتوي الحوادث وتقارير ما بعد الحادث على تفاصيل حساسة—معرّفات عملاء، عناوين داخلية، نتائج تحقيقات أمنية، أو مشاكل مع موردين. قواعد وصول واضحة تحافظ على فائدة الأداة للتعاون دون أن تتحول إلى مصدر تسريب بيانات.
ابدأ بمجموعة صغيرة ومفهومة من الأدوار:
إذا كان لديكم فرق متعددة، فكر في تقنين الأدوار بحسب الخدمة/الفريق (مثال: "محرّرو المدفوعات") بدلًا من منح وصول شامل عالمي.
صنّف المحتوى مبكرًا، قبل أن يعتاد الناس عادات:
نمط عملي هو وسم الأقسام كـ داخلي أو قابل للمشاركة وفرض ذلك عند التصدير وصفحات الحالة. قد تتطلب الحوادث الأمنية نوع حادث منفصل مع إعدادات افتراضية أكثر صرامة.
لكل تغيير على الحوادث والتقارير، سجّل: من غيّره، ماذا غيّر، ومتى. تضمّن تعديلات الشدة، الطوابع الزمنية، التأثير، والموافقات النهائية. اجعل سجلات التدقيق قابلة للبحث وغير قابلة للتحرير.
ادعم مصادقة قوية خارج الصندوق: البريد الإلكتروني + MFA أو رابط سحري، وأضف SSO (SAML/OIDC) إن توقع المستخدمون ذلك. استخدم جلسات قصيرة العمر، كوكيز آمنة، حماية CSRF، وإبطال الجلسات تلقائيًا عند تغيّر الأدوار. لمزيد من اعتبارات النشر، انظر /blog/testing-rollout-continuous-improvement.
عندما يكون الحادث نشطًا، يقوم الناس بالمسح — لا بالقراءة. يجب أن تُظهر تجربة المستخدم الحالة الحالية بوضوح خلال ثوانٍ، مع السماح للمستجيبين بالغوص في التفاصيل دون أن يتوهوا.
ابدأ بثلاث شاشات تغطي معظم تدفقات العمل:
قاعدة بسيطة: صفحة تفاصيل الحادث يجب أن تُجيب على "ما الذي يحدث الآن؟" في الأعلى، و"كيف وصلنا إلى هنا؟" أسفلها.
تتراكم الحوادث بسرعة، لذا اجعل الاكتشاف سريعًا ومتسامحًا:
قدّم طرق عرض محفوظة مثل الحوادث المفتوحة الخاصة بي أو Sev-1 هذا الأسبوع حتى لا يعيد مهندسو المناوبة بناء المرشحات في كل نوبة.
استخدم شارات متناسقة وآمنة من ناحية الألوان عبر التطبيق (وتجنّب درجات دقيقة تفشل تحت الضغط). احتفظ بنفس مفردات الحالة في كل الأماكن: القائمة، رأس التفاصيل، وأحداث الخط الزمني.
بنظرة سريعة، يجب أن يرى المستجيبون:
أعطِ أولوية لتيسير المسح:
صمِّم للحظة الأسوأ: إن كان شخص نائمًا على استدعاء ويتصفح عبر هاتفه، يجب أن توجهه الواجهة بسرعة إلى الإجراء الصحيح.
التكاملات هي ما يحوّل متعقّب الحوادث من "مكان لكتابة ملاحظات" إلى النظام الذي تُدار به الحوادث فعليًا. ابدأ بسرد الأنظمة التي يجب ربطها: المراقبة/الرصد (PagerDuty/Opsgenie, Datadog, CloudWatch)، الدردشة (Slack/Teams)، البريد الإلكتروني، نظام التذاكر (Jira/ServiceNow)، وصفحة الحالة.
ينتهي الأمر بمعظم الفرق بمزيج:
التنبيهات مزعجة، وتُعاد المحاولة، وغالبًا ما تصل خارج الترتيب. عرّف مفتاح "عدم التكرار" المستقر لكل حدث مزوّد (مثلاً: provider + alert_id + occurrence_id)، وخزّنه مع قيد فريد. لتمييز التكرار، قرّر قواعد مثل "نفس الخدمة + نفس البصمة خلال 15 دقيقة" يجب أن تُضاف إلى حادث قائم بدل إنشاء واحد جديد.
كن صريحًا بشأن ما يملكه تطبيقك وما يبقى في الأداة المصدر:
عندما يتعطل تكامل، تدهور بلطف: قوّم محاولات إعادة، أظهر تحذيرًا في الحادث ("نشر Slack متأخر"), واسمح للمشغلين بالمتابعة يدويًا دائمًا.
عامل تحديثات الحالة كمخرَج أساسي: يجب أن يكون إجراء "Update" المهيكل في واجهة المستخدم قادرًا على النشر إلى الدردشة، الإضافة إلى خط زمني الحادث، والمزامنة اختياريًا إلى صفحة الحالة—دون إجبار المستجيب على كتابة نفس الرسالة ثلاث مرات.
أداة الحوادث هي نظام "أثناء الانقطاع"، لذا فضّل البساطة والموثوقية على الحداثة. أفضل ستاك عادةً ما يكون الذي يستطيع فريقك بناؤه وتشغيله وإصلاحه بثقة في الثانية صباحًا.
ابدأ بما تُنتجه مهندسوكم بالفعل. إطار ويب شائع (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) عادةً خيار آمن أفضل من إطار جديد يفهمه شخص واحد فقط.
بالنسبة للتخزين، قاعدة بيانات علائقية (PostgreSQL/MySQL) تناسب سجلات الحوادث جيدًا: الحوادث، التحديثات، المشاركون، عناصر الإجراءات، والتقارير تستفيد من المعاملات والعلاقات الواضحة. أضف Redis فقط إذا كنت تحتاج حقًا للتخزين المؤقت، قوائم الانتظار، أو أقفال عابرة.
يمكن أن يكون الاستضافة بسيطة كمنصة مُدارة (مثل Render/Fly/Heroku) أو سحابتكم الحالية (AWS/GCP/Azure). فضّل قواعد بيانات مُدارة ونسخ احتياطي مُدارة إن أمكن.
الحوادث النشطة تبدو أفضل مع تحديثات وقت-حقيقي، لكنك لا تحتاج دائمًا WebSockets منذ البداية.
نمط عملي: صمّم API/أحداث بحيث يمكنك البدء بالاستطلاع ومن ثم الترقية إلى WebSockets لاحقًا دون إعادة كتابة الواجهة.
إذا فشل هذا التطبيق أثناء حادث، فسيصبح جزءًا من الحادث. أضف:
عامل هذا كنظام إنتاجي:
إذا أردت التحقق من سير العمل والشاشات قبل الاستثمار في بناء كامل، يمكن استخدام نهج تجريبي: استخدم أداة مثل Koder.ai لتوليد نموذج أولي عامل من مواصفات دردشة مفصّلة، ثم كرر مع المستجيبين خلال تمارين الطاولة. لأن Koder.ai يمكنه إنتاج واجهات React فعلية مع backend بـ Go + PostgreSQL (ويدعم تصدير الشيفرة المصدرية)، يمكنك اعتبار الإصدارات المبكرة "نماذج قابلة للتصرف" أو كنقطة انطلاق ليتقوّى عليها فريقكم—دون فقدان الدروس التي جمعتوها من المحاكاة.
إطلاق تطبيق تتبع الحوادث دون بروفة مخاطرة. أفضل الفرق تعامل الأداة كأي نظام تشغيلي آخر: اختبر المسارات الحرجة، نفّذ تدريبات واقعية، انشر تدريجيًا، وواصل الضبط حسب الاستخدام الحقيقي.
ركّز أولًا على التدفقات التي يعتمد عليها الناس تحت ضغط:
أضف اختبارات انحدار تتحقق مما لا ينبغي أن ينكسر: الطوابع الزمنية، المناطق الزمنية، وترتيب الأحداث. الحوادث هي سرد—إذا كان الخط الزمني خاطئًا، يفقد الناس الثقة.
أخطاء الصلاحيات هي مخاطر تشغيلية وأمنية. اكتب اختبارات تثبت:
اختبر أيضًا "الحالات القريبة": مثل فقدان المستخدم الوصول منتصف الحادث أو تغيّر عضوية الفريق.
قبل النشر الواسع، نفّذ محاكاة طاولة باستخدام تطبيقكم كمصدر الحقيقة. اختر سيناريوهات معروفة للمنظمة (انقطاع جزئي، تأخير بيانات، فشل طرف ثالث). راقب الاحتكاك: حقول مربكة، سياق مفقود، نقرات كثيرة، غموض في الملكية.
سجّل الملاحظات فورًا وحوّلها لتحسينات صغيرة وسريعة.
ابدأ بفريق تجريبي واحد وبعض القوالب الجاهزة (أنواع الحوادث، قوائم مرجعية، صيغ تقارير). قدّم تدريبًا قصيرًا ودليلًا صفحياً "كيف ندير الحوادث" مرتبطًا من التطبيق (مثلاً /docs/incident-process).
تابع مقاييس الاعتماد وحرِّك قائمة الاختناقات: وقت الإنشاء، نسبة الحوادث التي تحتوي تحديثات، معدل إتمام تقارير ما بعد الحادث، وزمن إغلاق عناصر الإجراءات. اعتبر هذه مقاييس منتج—لا مقاييس امتثال—وواصل التحسين في كل إصدار.
ابدأ بكتابة تعريف واضح يتفق عليه فريقكم:
يجب أن يرتبط هذا التعريف مباشرة بحالات سير العمل والحقول المطلوبة حتى تبقى البيانات متسقة دون أن تكون مرهقة.
عامل تقارير ما بعد الحادث كمسار عمل بدلاً من مستند وحسب:
إذا توقّعون حدوث تغيير، فأنت بحاجة إلى تتبع عناصر الإجراءات وتذكيرات—ليس مجرد تخزين المستندات.
تجنّب الأتمتة المتقدّمة حتى تعمل هذه التدفقات بسلاسة تحت الضغط.
استخدم عددًا قليلاً من المراحل المتوقعة والمتوافقة مع طريقة عمل الفرق:
عرّف ما الذي يعنيه "مكتمل" لكل مرحلة، ثم أضف حواجز أو متطلبات:
هذا يمنع توقف الحوادث ويحسّن جودة التحليل لاحقًا.
نمذِج بعض الأدوار الواضحة واربِطها بصلاحيات:
اجعل المالك/القائد الحالي واضحًا في واجهة المستخدم وسمح بالتفويض (إعادة التعيين، تدوير القائد).
حافظ على نموذج بيانات صغير لكن منظم:
استخدم معرفات ثابتة (UUIDs) زائد مفتاح ودود للإنسان مثل INC-2025-0042. اعتبر التعديلات تاريخًا عبر created_at/created_by وسجل تدقيق للتغييرات.
افصل بين تيّارين وطبق قواعد مختلفة:
نفّذ قوالب/رؤية مختلفة واحتفظ بكليهما في سجل الحادث حتى تتمكن من إعادة بناء القرارات لاحقًا دون تسريب معلومات حساسة.
عرّف مستويات الشدة مع توقعات واضحة (عجلة الاستجابة وتواتر الاتصالات). مثال:
اعرض القواعد في واجهة المستخدم عند اختيار الشدة حتى لا يحتاج المستجيبون للرجوع إلى وثائق خارجية أثناء الانقطاع.
عامل عناصر الإجراءات كسجلات منظمة، لا نص حر:
قدّم آراء عامة (متأخر، مستحق هذا الأسبوع، محجوز) وتذكيرات خفيفة وتصعيدات حتى لا تختفي المتابعات بعد الاجتماع.
استخدم مفاتيح عدم التكرار الخاصة بالمزوّد وقواعد إلغاء التكرار:
provider + alert_id + occurrence_idدائمًا وفّر ربطًا يدويًا كخيار احتياطي عندما تتعطل واجهات برمجة التطبيقات أو التكاملات.