05 مايو 2025·8 دقيقة
Datadog وتحول إلى منصة: القياسات، التكاملات، وتدفقات العمل
اكتشف كيف تتحول Datadog إلى منصة حين تصبح القياسات، التكاملات، وتدفقات العمل هي المنتج — وأفكار عملية يمكنك تطبيقها على مكدسك.
اكتشف كيف تتحول Datadog إلى منصة حين تصبح القياسات، التكاملات، وتدفقات العمل هي المنتج — وأفكار عملية يمكنك تطبيقها على مكدسك.
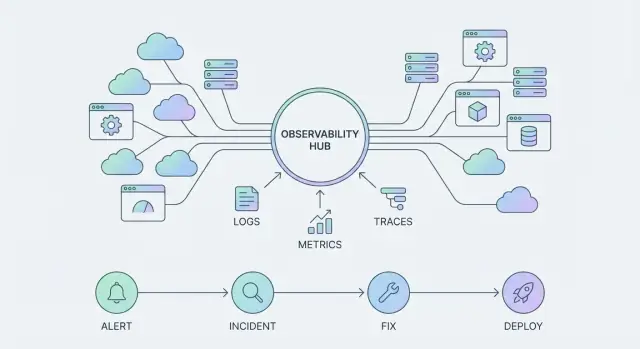
أداة الملاحظة تساعدك على الإجابة عن أسئلة محددة حول نظام — عادةً عبر عرض لوحات، سجلات، أو نتائج استعلام. هي شيء "تستخدمه" عند حدوث مشكلة.
أما منصة الملاحظة فأوسع: توحّد كيف تُجمَع القياسات، كيف تستكشفها الفرق، وكيف تُدار الحوادث من البداية للنهاية. تصبح شيئًا تُشغّله مؤسستك يومياً عبر خدمات وفرق متعددة.
معظم الفرق تبدأ بلوحات: مخططات CPU، رسوم معدل الأخطاء، وربما بعض عمليات بحث السجلات. هذا مفيد، لكن الهدف الحقيقي ليس لوحات أجمل — بل اكتشاف أسرع وحل أسرع.
يحدث انتقال المنصة عندما تتوقف عن السؤال "هل نستطيع رسم هذا؟" وتبدأ بالسؤال:
هذه أسئلة مركزة على النتائج، وتتطلب أكثر من التصور: تتطلب معايير بيانات مشتركة، تكاملات متسقة، وتدفقات عمل تربط القياسات بالإجراء.
مع تطور منصات مثل منصة الملاحظة من Datadog، لا يقتصر "سطح المنتج" على اللوحات فقط. إنه ثلاث ركائز مترابطة:
لوحة واحدة يمكن أن تساعد فريقاً واحداً. المنصة تصبح أقوى مع كل خدمة تُضاف، كل تكامل يُفعّل، وكل سير عمل يُوحد. مع الوقت، يتحول ذلك إلى أقل نقاط عمياء، أدوات مكررة أقل، وحوادث أقصر — لأن كل تحسّن يصبح قابلاً لإعادة الاستخدام بدلاً من أن يكون فريداً.
عندما تنتقل الملاحظة من "أداة نستعلمها" إلى "منصة نبني عليها"، تتوقف القياسات عن كونها مجرد عادم خام وتبدأ بالعمل كسطح المنتج. ما تختار إرساله — وكم تتسق في إرساله — يحدد ما يمكن لفرقك رؤيته وأتمتته والثقة به.
تتفق معظم الفرق على مجموعة صغيرة من الإشارات:
كل إشارة مفيدة بمفردها. معاً، تشكل واجهة واحدة لأنظمتك — ما تراه في اللوحات، التنبيهات، جداول الحوادث، والتحقيقات اللاحقة.
أحد أوضاع الفشل الشائعة هو جمع "كل شيء" لكن بتسمية غير متسقة. إذا استخدمت خدمة userId، وأخرى uid، وثالثة لا تسجل شيئاً، فلن تستطيع تقطيع البيانات أو ربط الإشارات أو بناء مراقبات قابلة لإعادة الاستخدام.
تحصل الفرق على قيمة أكبر عندما تتفق على بعض الاتفاقيات القليلة — أسماء الخدمات، وسوم البيئة، معرفات الطلب، ومجموعة سمات قياسية — بدل زيادة حجم الإدخال.
الحقول عالية التباين هي سمات لها قيم كثيرة ممكنة (مثل user_id، order_id، أو session_id). قوية لتصحيح الأخطاء التي "تحدث لعميل واحد فقط"، لكنها قد تزيد التكلفة وتبطئ الاستعلامات إذا استُخدمت في كل مكان.
نهج المنصة متعمد: احتفظ بالحقول عالية التباين حيث تقدم قيمة تحقيق واضحة، وتجنبها في الأماكن المخصصة للتجميعات العالمية.
العائد هو السرعة. عندما تشترك المقاييس والسجلات والتتبعات والأحداث والملفات الشخصية في نفس السياق (الخدمة، الإصدار، المنطقة، معرف الطلب)، يقضي المهندسون وقتاً أقل في ربط الأدلة ووقتاً أكثر في إصلاح المشكلة الفعلية. بدلاً من التنقل بين أدوات والتخمين، تتبع خيطاً واحداً من العرض إلى السبب الجذري.
معظم الفرق تبدأ الملاحظة بـ "إدخال البيانات". هذا ضروري، لكنه ليس استراتيجية. استراتيجية القياسات هي ما يحافظ على سرعة الانضمام وأيضاً يجعل بياناتك متسقة بما يكفي لتغذية لوحات مشتركة، تنبيهات موثوقة، وSLOs ذات معنى.
عادةً ما يحصل Datadog على القياسات عبر طرق عملية قليلة:
في البداية، تفوز السرعة: يثبت الفريق وكالة، يفعّل بعض التكاملات، ويشعر بالقيمة فوراً. الخطر أن يخترع كل فريق وسومَه وأسماء خدماته وصيغ سجلاته — مما يجعل العروض عبر الخدمات فوضوية والتنبيهات غير موثوقة.
قاعدة بسيطة: اسمح بالانطلاق السريع، لكن اشترط التوحيد خلال 30 يوماً. هذا يمنح الفرق زخمًا دون تثبيت الفوضى.
لست بحاجة إلى تصنيف ضخم. ابدأ بمجموعة صغيرة يجب أن تحملها كل إشارة (سجلات، مقاييس، تتبعات):
service: قصير، ثابت، بأحرف صغيرة (مثال: checkout-api)env: prod, staging, devteam: معرف الفريق المالِك (مثال: payments)version: نسخة النشر أو SHA من Gitإذا أردت وسمًا واحدًا إضافيًا يعود بسرعة، أضف tier (frontend, backend, data) لتبسيط الفلاتر.
قضايا التكلفة عادةً تنشأ من إعدادات افتراضية سخية للغاية:
الهدف ليس جمع أقل — بل جمع البيانات الصحيحة بشكل متسق، لتوسيع الاستخدام دون مفاجآت.
معظم الناس يرون أدوات الملاحظة كـ"شيء تُثبتُه". في الواقع، تنتشر داخل المؤسسة بنفس طريقة انتشار الموصلات الجيدة: تكامل واحد في كل مرة.
ليس مجرد أنبوب بيانات. غالبًا ما يتضمن ثلاثة أجزاء:
هذا الجزء الأخير هو ما يحوّل التكاملات إلى توزيع. إذا كانت الأداة تقرأ فقط، فهي وجهة لوحات. إذا كانت أيضًا تكتب، تصبح جزءًا من العمل اليومي.
تكاملات جيدة تقلل وقت الإعداد لأنها تأتي بإفتراضات معقولة: لوحات مُعَدّة مسبقاً، مراقبات موصى بها، قواعد تحليل، ووسوم شائعة. بدل أن يخترع كل فريق "لوحة CPU" أو "تنبيهات Postgres"، تحصل على نقطة بداية معيارية تطابق الممارسات الفضلى.
الفرق لا تزال تُخصص — لكنها تُخصص من قاعدة مشتركة. هذا التوحيد مهم عند توحيد الأدوات: التكاملات تخلق أنماطًا قابلة للتكرار يمكن للخدمات الجديدة نسخها، مما يحافظ على نمو قابل للإدارة.
عند تقييم الخيارات، اسأل: هل يمكنه استقبال الإشارات وأيضاً اتخاذ إجراء؟ أمثلة: فتح حوادث في نظام التذاكر، تحديث قنوات الحادث، أو إرفاق رابط تتبع بPR أو عرض النشر. الإعدادات ثنائية الاتجاه هي حيث تبدأ تدفقات العمل بالشعور "الأصلي".
ابدأ صغيرًا ومتوقعًا:
قاعدة إبهام: أعطِ الأولوية للتكاملات التي تحسّن الاستجابة للحوادث فوراً، لا تلك التي تضيف مزيدًا من اللوحات فقط.
العروض القياسية هي المكان الذي تصبح فيه المنصة قابلة للاستخدام يوميًا. عندما تتشارك الفرق نفس نموذج العقل — ما هي "الخدمة"، ما معنى "صحية"، وأين تنقر أولاً — يصبح التصحيح أسرع وتسليم المسؤوليات أنظف.
اختر مجموعة صغيرة من "الإشارات الذهبية" واربط كل منها بلوحة قابلة لإعادة الاستخدام. لمعظم الخدمات عادةً:
المفتاح هو الاتساق: تخطيط لوحة واحد يعمل عبر الخدمات يفوق عشر لوحات مخصّصة ذكية.
كتالوج خدمات (حتى لو كان خفيفًا) يحوّل "يجب أن ينظر أحدهم إلى هذا" إلى "هذا الفريق يملكه". عندما تُوسم الخدمات بالمالكين، البيئات، والاعتماديات، يمكن للمنصة الإجابة فورًا على أسئلة أساسية: ما المراقبات المنطبقة؟ أي اللوحات أفتح؟ من يتلقى التنبيه؟
هذه الوضوح يقلل من تراسل Slack أثناء الحوادث ويساعد المهندسين الجدد على الخدمة الذاتية.
عامل هذه العناصر كقطع معيارية وليست إضافات اختيارية:
لوحات المظهر فقط (رسوم جميلة دون قرارات)، التنبيهات المؤقتة (أنشئت بسرعة ولم تُضبط)، والاستعلامات غير الموثقة (شخص واحد فقط يفهم الفلتر السحري) تولد ضجيجًا في المنصة. إذا كان استعلام مهمًا، احفظه وسمّه واربطه بعرض خدمة يجده الآخرون.
تصبح الملاحظة "حقيقية" للأعمال عندما تقصر الوقت بين المشكلة والحل الواثق. يحدث ذلك عبر تدفقات العمل — مسارات قابلة للتكرار تأخذك من الإشارة إلى الإجراء، ومن الإجراء إلى التعلم.
سير عمل قابل للتوسع أكثر من مجرد تنبيه لشخص ما.
يجب أن يفتح التنبيه حلقة فرز مركزة: تأكيد التأثير، تحديد الخدمة المتأثرة، وسحب السياق الأكثر صلة (نشرات حديثة، صحة الاعتماديات، قفزات الأخطاء، إشارات التشبع). من هناك، يحول التواصل الحدث الفني إلى استجابة منسقة — من يملك الحادث، ماذا يرى المستخدمون، ومتى التحديث التالي.
التخفيف هو المكان الذي تريد فيه "تحركات آمنة" في متناول اليد: أعلام الميزات، تحويل الحركة، التراجع، حدود المعدل، أو حل معروف. أخيراً، يغلق التعلم الحلقة بمراجعة خفيفة تلتقط ما تغيّر، ما نجح، وما يجب أتمتته لاحقًا.
تضيف منصات مثل منصة Datadog قيمة عندما تدعم العمل المشترك: قنوات الحوادث، تحديثات الحالة، التسليم بين الفرق، وجداول زمنية متناسقة. يمكن لتكاملات ChatOps تحويل التنبيهات إلى محادثات منظمة — إنشاء حادث، تعيين الأدوار، ونشر الرسوم والاستعلامات الرئيسية مباشرة في الخيط حتى يرى الجميع نفس الأدلة.
Runbook مفيد يكون قصيرًا، حاسمًا، وآمناً. يجب أن يشمل: الهدف (استعادة الخدمة)، الملاك وجداول مناوبة الأون-كول، فحوصات خطوة بخطوة، روابط إلى اللوحات/المراقبات الصحيحة، و"إجراءات آمنة" تقلل المخاطر (مع خطوات التراجع). إذا لم يكن آمناً للتنفيذ عند 3 صباحًا، فهو غير جاهز.
يكون السبب الجذري أسرع عندما تُقرَن الحوادث تلقائياً بالنشرات، تغييرات الإعداد، وتقلبات أعلام الميزات. اجعل "ما الذي تغيّر؟" عرضاً ذا أولوية حتى تبدأ عملية الفرز بالأدلة لا بالتخمين.
SLO (هدف مستوى الخدمة) هو وعد بسيط حول تجربة المستخدم عبر نافذة زمنية — مثل "99.9% من الطلبات ناجحة خلال 30 يومًا" أو "زمن التحميل p95 أقل من 2 ثانية".
هذا يتفوق على لوحة "خضراء" لأن اللوحات غالبًا ما تعرض صحة النظام (CPU، الذاكرة) بدل تأثير المستخدم. يمكن للنظام أن يبدو سليماً بينما المستخدمون يتعرضون للفشل. تجبر SLOs الفريق على قياس ما يشعر به المستخدم فعلاً.
ميزانية الخطأ هي مقدار عدم الاعتمادية المسموح به وفق SLO. إذا وعدت 99.9% نجاحًا خلال 30 يومًا، فمسموح لك حوالي 43 دقيقة من الأخطاء في تلك النافذة.
هذا يخلق نظام تشغيل عملي للقرارات:
بدلاً من الجدال في اجتماع النشر، تناقش رقماً يراه الجميع.
تعمل تنبيهات SLO بشكل أفضل عندما تُنَبِّه على معدل الحرق (كم بسرعة تستهلك الميزانية)، لا على أعداد الأخطاء الخام. هذا يقلل الضوضاء:\n\n- قفزة قصيرة تتعافى بنفسها قد لا تُوقظ أحدًا.\n- مشكلة مستمرة قد تستنفد الميزانية قريباً فتُطلق تنبيهًا واضحًا وقابلًا للتنفيذ.
يستخدم العديد من الفرق نافذتين: حرق سريع (ندعو بسرعة) وحرق بطيء (تذكرة/إشعار).
ابدأ صغيرًا — اثنان إلى أربعة SLOs ستستخدمها فعلاً:
عندما تستقر هذه، يمكنك التوسع — وإلا فسوف تبني جدار لوحات آخر. للمزيد، راجع /blog/slo-monitoring-basics.
التنبيه هو المكان الذي تتعثر فيه برامج الملاحظة: البيانات موجودة، اللوحات تبدو رائعة، لكن تجربة الأون-كول تصبح صاخبة وغير موثوقة. إذا تعلم الناس تجاهل التنبيهات، تفقد المنصة قدرتها على حماية العمل.
الأسباب الشائعة متشابهة للغاية:\n\n- الكثير من التنبيهات من نوع "للعلم" التي لا تتطلب إجراء.\n- حدود مكررة عبر خدمات دون سياق (نفس قاعدة CPU لأحمال مختلفة).\n- أدوات أو فرق متعددة تنبه على نفس العرض — مثلاً مراقبة معدل الأخطاء في APM ومراقبة أخطاء معتمدة على السجلات تنبهان لنفس الحادث.\n- مقاييس صاخبة (نسب زمن استجابة متقلبة، تأثيرات autoscaling) تُولّد تغيّرات بدلاً من مشاكل حقيقية.
بمصطلحات Datadog، تظهر الإشارات المكررة غالبًا عندما تُنشأ مراقبات من أسطح مختلفة (مقاييس، سجلات، تتبعات) دون قرار حول أي منها هو المصدر المرجعي للنداء.
بدءًا من قواعد توجيه مفهومة للبشر:
افتراضي مفيد: نَبّه على الأعراض، لا على كل تغيير في المقياس. نادِ عندما يشعر المستخدم (معدل الأخطاء، عمليات الدفع الفاشلة، تأخر مستمر، حرق SLO)، لا على "مدخلات" مثل CPU أو عدد الحاويات إلا إذا كانت تتنبأ بالتأثير بشكل موثوق.
اجعل نظافة التنبيهات جزءًا من العمليات: تنقية ومِزْوَجة المراقبات شهريًا. أزل المراقبات التي لا تُطلق أبدًا، ضبط العتبات المزعجة، وادمج المكررات حتى يكون لكل حادث نداء أساسي واحد مع سياق داعم.
عند الاتقان، يصبح التنبيه تدفق عمل يثق به الناس — لا مولد ضوضاء في الخلفية.
أن تسمي الملاحظة "منصة" لا يعني فقط وجود سجلات ومقاييس وتتبعات وتكاملات في مكان واحد. يعني أيضاً الحوكمة: الاتساق والضوابط التي تحافظ على النظام قابلاً للاستخدام عندما يتكاثر عدد الفرق، الخدمات، اللوحات، والتنبيهات.
دون حوكمة، قد تنحرف Datadog (أو أي منصة) إلى ألبوم لاصق صاخب — مئات لوحات متشابهة قليلاً، ووسوم غير متناسقة، ملكية غير واضحة، وتنبيهات لا يثق بها أحد.
الحوكمة الجيدة توضح من يقرر ماذا، ومن مسؤول عندما تصبح المنصة فوضوية:
بعض الضوابط الخفيفة تفعل أكثر من مستندات سياسة طويلة:
service, env, team, tier) مع قواعد واضحة للوسوم الاختيارية. طبقها في CI عندما تستطيع.أسرع طريقة لرفع الجودة هي مشاركة ما ينجح:
إذا أردت أن يستمر ذلك، اجعل المسار المحكوم هو الطريق الأسهل — نقرات أقل، إعداد أسرع، وملكية أوضح.
عندما تتصرف الملاحظة كمنصة، تبدأ باتباع اقتصاد المنصات: كلما تبناها المزيد من الفرق، تُنتَج قياسات أكثر، وتصبح المنصة أكثر فائدة.
هذا يخلق دورانًا:
لكن الفخ أن نفس الحلقة تزيد التكلفة. المزيد من المضيفات، الحاويات، السجلات، التتبعات، والقياسات المخصّصة يمكن أن تتزايد أسرع من ميزانيتك إن لم تُدِرها عمداً.
ليس عليك "إيقاف كل شيء". ابدأ بتشكيل البيانات:
راقب مجموعة صغيرة من المقاييس تظهر ما إذا كانت المنصة تعود بقيمتها:
اجعلها مراجعة منتج لا تدقيق. اجمع مالكي المنصة، بعض فرق الخدمات، والتمويل. راجع:\n\n- أكبر محركات التكلفة حسب نوع البيانات (سجلات/مقاييس/تتبعات) وحسب الفريق\n- أكبر المكاسب: حوادث قُصِّرَت، انقطاعات تجنّبت، عمل مكرر أُزيل\n- 2–3 إجراءات متّفق عليها (مثلاً: تعديل قواعد العينة، إضافة طبقات احتفاظ، إصلاح تكامل مزعج)
الهدف هو الملكية المشتركة: تصبح التكلفة مدخلاً لقرارات أفضل في الت instrumention، لا سببًا لإيقاف الملاحظة.
إذا تحولت الملاحظة إلى منصة، يتوقف "مكدس الأدوات" عن كونه مجموعة حلول نقطية ويبدأ بالتصرف كبنية تحتية مشتركة. هذا التحول يجعل التشتت في الأدوات أكثر من إزعاج: يخلق ازدواجية في القياسات، تعريفات غير متسقة (ما الذي يُحسب خطأ؟)، وحِمل من الأون-كول أعلى لأن الإشارات لا تتطابق بين السجلات والمقاييس والتتبعات والحوادث.
التوحيد لا يعني بالضرورة "مورد واحد لكل شيء". يعني أن يكون لديك أنظمة سجل واحدة أو سجلات أقل للحقائق والرد، ملكية أوضح، ومجموعة أصغر من الأماكن التي ينظر الناس إليها أثناء الانقطاع.
تخفي الفوضى الأدواتية التكاليف في ثلاثة أماكن: الوقت المفقود في التنقّل بين واجهات، التكاملات الهشة التي تحتاج صيانة، والحوكمة المشتتة (تسمية، وسم، احتفاظ، وصول). يمكن لنهج منصتي أكثر توحيدًا أن يقلل تبديل السياق، يوحّد عروض الخدمة، ويجعل تدفقات الحوادث قابلة للتكرار.
عند تقييم مكدسك (بما في ذلك Datadog أو بدائل): اضغط على هذه الأسئلة:\n\n- التكاملات الأساسية المطلوبة: مزود السحابة، Kubernetes, CI/CD, إدارة الحوادث، التنبيه، ومتاجر البيانات الأساسية — بالإضافة لأي أنظمة أعمال لا يمكنك الشحن بدونها.\n- تدفقات العمل: هل يمكنك الانتقال من تنبيه → مالك → runbook → جدول زمني → تقرير ما بعد الحادث دون نسخ/لصق يدوي؟\n- الحوكمة: معايير الوسم، ضوابط الوصول، الاحتفاظ، وحواجز ضد توسع اللوحات/المراقبات.\n- نموذج التسعير: ما الذي يدفع التكلفة (مضيفات، حاويات، سجلات مُستَقبلة، تتبعات مفهرسة)؟ هل يمكنك توقع النمو دون مفاجآت؟
اختر خدمة أو اثنتين حقيقيتين بحركة فعلية. حدد مقياس نجاح واحد مثل "انخفاض وقت تحديد السبب الجذري من 30 دقيقة إلى 10" أو "تقليل التنبيهات المزعجة بنسبة 40%". أدرج القياس اللازم فقط، وراجع النتائج بعد أسبوعين.
اجمع الوثائق الداخلية مركزياً بحيث يتراكم التعلم — اربط runbook التجربة، قواعد الوسم، واللوحات من مكان واحد (مثلاً /blog/observability-basics كنقطة بدء داخلية).
لن "تنشر Datadog" مرة واحدة. تبدأ صغيرًا، تُحدد معايير مبكراً، ثم توسع ما ينجح.
الأيام 0–30: الانضمام (أثبت القيمة سريعًا)
اختر 1–2 خدمة حرجة ومسار واحد يواجه العميل. أدرج سجلات، مقاييس، وتتبعات متسقة، واربط التكاملات التي تعتمدون عليها (سحابة، Kubernetes، CI/CD، الأون-كول).
الأيام 31–60: التوحيد (اجعله قابلاً للتكرار)
حوّل ما تعلمته إلى افتراضات: تسمية الخدمة، الوسم، قوالب اللوحات، تسمية المراقبات، والملكية. أنشئ عروض "الإشارات الذهبية" (الزمن، الحركة، الأخطاء، التشبع) ومجموعة SLO بسيطة للمسارات الأكثر أهمية.
الأيام 61–90: التوسع (وسع بدون فوضى)
أدرج فرقًا إضافية باستخدام نفس القوالب. قدِّم الحوكمة (قواعد الوسم، بيانات تعريف مطلوبة، عملية مراجعة للمراقبات الجديدة) وابدأ بتتبع التكلفة مقابل الاستخدام حتى تظل المنصة صحية.
عندما تعامل الملاحظة كمنصة، عادةً ما ترغب في تطبيقات صغيرة "لصقية" حولها: واجهة كتالوج الخدمات، مركز runbook، صفحة جدول زمني للحوادث، أو بوابة داخلية تربط الملاك → اللوحات → SLOs → إجراءات.
هذا النوع من الأدوات الخفيفة يمكنك بناؤه بسرعة على Koder.ai — منصة توليد واجهات عبر الدردشة تنتج تطبيقات ويب (عادة React للواجهة، Go + PostgreSQL للخلفية)، مع تصدير الشفرة ودعم النشر. عمليًا، تستخدمها الفرق لنماذج تشغيلية تجعل الحوكمة وتدفقات العمل أسهل دون سحب فريق منتج كامل من خارطة الطريق.
نظّم جلستين مدة كل منهما 45 دقيقة: (1) "كيف نستعلم هنا" مع أنماط استعلام مشتركة (حسب الخدمة، env، المنطقة، الإصدار)، و(2) "دليل التصحيح" بخط سير بسيط: تأكيد التأثير → فحص مؤشرات النشر → تضييق الخدمة → فحص التتبعات → تأكيد صحة الاعتماديات → قرار تراجع/تخفيف.
أداة مراقبة/ملاحظة هي شيء تلجأ إليه عند وجود مشكلة (لوحات، بحث في السجلات، استعلام). أما منصة الملاحظة فهي شيء تُديره باستمرار: تُوحّد كيف تُجمع القياسات، كيف تصل الفرق إليها، من يملك ماذا، كيفية التنبيه، وسير العمل خلال الحوادث — كل ذلك بهدف تحسين النتائج (اكتشاف أسرع وحل أسرع).
لأن أكبر المكاسب تأتي من النتائج وليس من المظهر:
الرسوم البيانية مفيدة، لكنك تحتاج معايير مشتركة وتدفقات عمل لتقليل MTTD/MTTR باستمرار.
ابدأ بخط أساس مطلوب يجب أن تحمله كل إشارة:
serviceenv (prod, staging, dev)الحقول عالية التباين (مثل user_id, order_id, session_id) مفيدة عند تصحيح أخطاء تخص عميل واحد، لكنها قد تزيد التكاليف وتبطئ الاستعلامات إذا استُخدمت في كل مكان.
استخدمها عن قصد:
تتفق الفرق عادةً على هذه الأنواع الأساسية:
الطرق العملية الشائعة:
اختر المسار الذي يناسب حاجتك للتحكم، ثم ألزِم قواعد التسمية/الوسوم نفسها عبرها.
افعل كلا الأمرين:
هذا يمنع كل فريق من اختراع مخططه الخاص بينما يحافظ على زخم التبني.
لأن التكاملات ليست مجرد أنبوب بيانات — فهي تشمل:
أعطِ أولوية للتكاملات ثنائية الاتجاه التي تستقبل البيانات وتنفذ إجراءات أيضاً، حتى تصبح الملاحظة جزءاً من العمل اليومي وليس وجهة بيانات فقط.
ارتكز على الاتساق وإعادة الاستخدام:
تجنب لوحات المظهر فقط والتنبيهات المؤقتة. إذا كان استعلام ما مهمًا، احفظه، سمّه، واربطه بعرض الخدمة حتى يجده الآخرون بسهولة.
ننبه على معدل الحرق (burn rate) لميزانية الخطأ، لا على كل ارتفاع عابر في الأخطاء. نمط شائع:
ابدأ بمجموعة صغيرة من SLOs (2–4) لكل خدمة ووسع فقط عندما تُستخدم فعلاً. للمزيد، راجع /blog/slo-monitoring-basics.
teamversion (نسخة النشر أو SHA من Git)يمكنك إضافة tier (frontend, backend, data) كفلتر إضافي مفيد.
المهم أن تشترك كل هذه الإشارات في نفس السياق (service/env/version/request ID) لتسريع الارتباط.