12 سبتمبر 2025·7 دقيقة
حزمة بدء مراقبة الإنتاج لليوم الأول
حزمة بدء مراقبة الإنتاج لليوم الأول: الحد الأدنى من السجلات والمقاييس والتتبُّعات التي يجب إضافتها، بالإضافة إلى تدفق فرز بسيط لتقارير «إنه بطيء».
حزمة بدء مراقبة الإنتاج لليوم الأول: الحد الأدنى من السجلات والمقاييس والتتبُّعات التي يجب إضافتها، بالإضافة إلى تدفق فرز بسيط لتقارير «إنه بطيء».
أول شيء ينهار نادراً ما يكون التطبيق بأكمله. عادةً ما يكون خطوة واحدة ازدادت حركة المرور فجأة، استعلام واحد كان جيدًا في الاختبارات، أو تبعية واحدة بدأت تتوقف مؤقتًا. المستخدمون الحقيقيون يضيفون تنوعًا حقيقيًا: هواتف أبطأ، شبكات متقطعة، مدخلات غريبة، وزِحام حركة في أوقات غير مناسبة.
عندما يقول شخص ما «الأمر بطيء»، قد يقصد أشياء مختلفة جدًا. قد تستغرق الصفحة وقتًا طويلاً للتحميل، قد تتأخر التفاعلات، قد يتوقف أحد نداءات الـ API أو يتراجع، قد تتراكم المهام الخلفية، أو قد يبطئ خِدمة طرف ثالث كل شيء.
لهذا تحتاج إشارات قبل أن تحتاج لوحات تحكم. في اليوم الأول، لا تحتاج مخططات مثالية لكل نقطة نهاية. تحتاج سجلات ومقاييس وتتبع كافيين لتجيب عن سؤال واحد بسرعة: أين يذهب الوقت؟
هناك أيضًا خطر حقيقي في الإفراط في القياس مبكرًا. الكثير من الأحداث يصنع ضوضاء، يكلف مالًا، وقد يبطئ التطبيق. والأسوأ أن الفرق تتوقف عن الوثوق بالتليمتري لأنه يبدو فوضويًا وغير متسق.
هدف واقعي لليوم الأول بسيط: عندما تتلقى تقرير «إنه بطيء»، يجب أن تتمكن من العثور على الخطوة البطيئة في أقل من 15 دقيقة. يجب أن تستطيع تحديد ما إذا كان الاختناق في عرض العميل (client rendering)، معالج الـ API واعتمادياته، قاعدة البيانات أو الكاش، أو عامل خلفي أو خدمة خارجية.
مثال: تدفق الخروج الجديد يبدو بطيئًا. حتى دون جبل من الأدوات، تريد أن تكون قادرًا على قول: «95% من الوقت يذهب إلى استدعاءات مزوّد الدفع»، أو «استعلام السلة يفحص عددًا كبيرًا من الصفوف». إذا كنت تبني التطبيقات بسرعة باستخدام أدوات مثل Koder.ai، فإن هذا الأساس من اليوم الأول يصبح أكثر أهمية، لأن سرعة النشر مفيدة فقط إذا كنت تستطيع التصحيح بسرعة أيضًا.
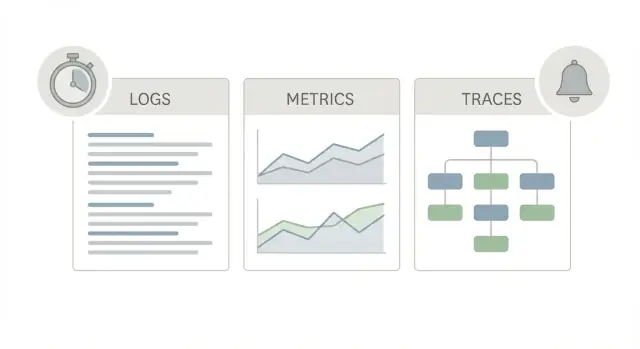
حزمة بدء مراقبة الإنتاج الجيدة تستخدم ثلاث «نظرات» مختلفة لنفس التطبيق، لأن كل واحدة تجيب عن سؤال مختلف.
السجلات هي القصة. تخبرك بما حدث لطلب واحد، مستخدم واحد، أو مهمة خلفية واحدة. سطر سجل يمكن أن يقول «فشل الدفع للطلب 123» أو «انقضاء مهلة DB بعد 2s»، بالإضافة إلى تفاصيل مثل request_id، user_id، ورسالة الخطأ. عندما يبلغ شخص ما عن مشكلة عابرة غريبة، غالبًا ما تكون السجلات هي أسرع طريقة لتأكيد حدوثها ومن تأثر.
المقاييس هي لوحة النتائج. هي أرقام يمكنك تتبعها والتنبيه بناءً عليها: معدل الطلبات، معدل الأخطاء، نسب التأخير، CPU، عمق الطابور. المقاييس تخبرك ما إذا كان شيء نادرًا أم واسع الانتشار، وما إذا كان يزداد سوءًا. إذا قفز التأخير للجميع عند 10:05، فالمقاييس ستظهر ذلك.
التتبُّعات هي الخريطة. التتبُّع يتبع طلبًا واحدًا أثناء انتقائه عبر نظامك (web -> API -> database -> third-party). تُظهر أين يُنفق الزمن، خطوة بخطوة. هذا مهم لأن «إنه بطيء» نادرًا ما يكون لغزًا كبيرًا واحدًا. عادة ما يكون قفزة واحدة بطيئة.
أثناء حادث، يبدو تدفق عملي مثل هذا:
قاعدة بسيطة: إذا لم تستطع الإشارة إلى اختناق واحد بعد بضع دقائق، فأنت لا تحتاج المزيد من التنبيهات. تحتاج تتبُّعات أفضل، ومعرّفات متسقة تربط التتبُّعات بالسجلات.
معظم الحوادث من نوع «لا نستطيع العثور عليه» لا تنجم عن نقص البيانات. تحصل لأن الشيء نفسه مُسجَّل بطريقة مختلفة عبر الخدمات. بعض الاتفاقيات المشتركة في اليوم الأول تجعل السجلات والمقاييس والتتبُّعات تتماشى عندما تحتاج إجابات سريعة.
ابدأ باختيار اسم خدمة واحد لكل وحدة قابلة للنشر والحفاظ على ثباته. إذا تحوّل "checkout-api" إلى "checkout" في نصف لوحاتك، تخسر التاريخ وتنكسر التنبيهات. افعل الشيء نفسه لتسميات البيئة. اختر مجموعة صغيرة مثل prod و staging، واستخدمها في كل مكان.
بعد ذلك، اجعل كل طلب سهل المتابعة. أنشئ request_id عند الحافة (API gateway، خادم الويب، أو المعالج الأول) وقم بتمريره عبر استدعاءات HTTP، طوابير الرسائل، والمهام الخلفية. إذا قال تذكرة الدعم «كان بطيئًا عند 10:42»، يتيح لك معرّف واحد جلب السجلات والتتبُّع الدقيق دون تخمين.
مجموعة اتفاقيات تعمل جيدًا في اليوم الأول:
request_id منشور عبر الخدمات والمهامroute (أو المعالج)، method, status_code, و tenant_id إذا كنت متعدد المستأجريناتفق على وحدات الزمن مبكرًا. اختر الملي ثانية لـ API latency والثواني للوظائف الأطول، والتزم بذلك. الوحدات المختلطة تخلق مخططات تبدو جيدة لكنها تروي قصة خاطئة.
مثال ملموس: إذا سجلت كل API الحقل duration_ms, route, status, و request_id، فإن تقريرًا مثل «الـ checkout بطيء للمستأجر 418» يصبح فلترًا سريعًا بدلًا من نقاش حول أين تبدأ.
إذا فعلت شيئًا واحدًا فقط في حزمة بدء مراقبة الإنتاج، اجعل السجلات سهلة البحث. يبدأ هذا بالسجلات المهيكلة (غالبًا JSON) ونفس الحقول عبر كل خدمة. سجلات النص العادي جيدة للتطوير المحلي، لكنها تتحول إلى ضوضاء بمجرد أن يكون لديك حركة حقيقية، إعادة المحاولة، وعدة مثيلات.
قاعدة جيدة: سجّل ما ستستخدمه فعليًا أثناء الحادث. معظم الفرق تحتاج للإجابة عن: ما هو الطلب؟ من الذي فعله؟ أين فشل؟ ماذا لمس؟ إذا لم يساعد سطر السجل في أحد هذه، فغالبًا لا يجب أن يوجد.
لليوم الأول، احتفظ بمجموعة صغيرة ومتسقة من الحقول حتى تتمكن من الفلترة وربط الأحداث عبر الخدمات:
request_id, trace_id إذا وُجد)user_id أو session_id, route, method)status_code, duration_ms)عند حدوث خطأ، سجّله مرة واحدة، مع السياق. أضف نوع الخطأ (أو رمز)، رسالة قصيرة، تتبُّع الاستثناء للخوادم، واعتماد أعلى تدخّل (مثل postgres، payment provider، cache). تجنّب تكرار نفس تتبُّع الاستثناء في كل إعادة محاولة. بدلًا من ذلك، أرفق request_id حتى تتمكن من متابعة السلسلة.
مثال: يبلغ مستخدم أنه لا يستطيع حفظ الإعدادات. بحث واحد عن request_id يظهر 500 على PATCH /settings، ثم انتهاء مهلة إلى Postgres مع duration_ms. لم تكن بحاجة إلى الحمولة الكاملة، فقط route، المستخدم/الجلسة، واسم الاعتماد.
الخصوصية جزء من التسجيل، ليست مهمة لاحقة. لا تسجل كلمات المرور، الرموز، رؤوس المصادقة، أجسام الطلبات الكاملة، أو بيانات شخصية حساسة. إذا كنت بحاجة إلى تحديد مستخدم، سجّل معرفًا ثابتًا (أو قيمة مشفّرة) بدلاً من البريد الإلكتروني أو أرقام الهواتف.
إذا كنت تبني تطبيقات على Koder.ai (React, Go, Flutter)، فالأجدر تضمين هذه الحقول في كل خدمة مُولّدة من البداية حتى لا تنتهي بـ "إصلاح التسجيل" أثناء أول حادث.
حزمة بدء مراقبة الإنتاج الجيدة تبدأ بمجموعة صغيرة من المقاييس التي تجيب عن سؤال واحد بسرعة: هل النظام صحي الآن، وإذا لا، أين يتألم؟
تظهر معظم مشاكل الإنتاج كواحدة من أربع "إشارات ذهبية": التأخير (الاستجابات بطيئة)، الحركة (تغير الحمل)، الأخطاء (فشل الأمور)، والتشبع (مصدر مشترك ممتلئ). إذا استطعت رؤية هذه الأربع إشارات لكل جزء رئيسي من تطبيقك، يمكنك فرز معظم الحوادث دون تخمين.
يجب أن تكون مقاييس التأخير على شكل نسب مئوية (percentiles)، ليس متوسطات. تتبع p50, p95, و p99 حتى ترى عندما يعاني قطاع صغير من المستخدمين. للحركة، ابدأ بعدد الطلبات بالثانية (أو الوظائف بالدقيقة للعاملين). للأخطاء، فرِّق 4xx مقابل 5xx: ارتفاع 4xx غالبًا يعني سلوك العميل أو تغيُّر في التحقق؛ ارتفاع 5xx يشير إلى مشكلتك أو اعتمادياتك. التشبع هو إشارة "نقترب من نفاد شيء" (CPU، الذاكرة، اتصالات DB، تراكم الطوابير).
مجموعة دنيا تغطي معظم التطبيقات:
مثال ملموس: إذا أبلغ المستخدمون "إنه بطيء" وقفز p95 للـ API بينما بقت الحركة ثابتة، فتحقق من التشبع بعد ذلك. إذا كان استخدام تجمع DB مثبتًا قرب الحد الأقصى وارتفعت الانتهاءات، فقد وجدت عنق زجاجة محتمل. إذا كانت قاعدة البيانات بخير لكن عمق الطابور يزداد بسرعة، قد تكون الأعمال الخلفية هي التي تستهلك الموارد المشتركة.
إذا كنت تبني تطبيقات على Koder.ai، اعتبر هذه القائمة جزءًا من تعريف "تمّ" لليوم الأول. من الأسهل إضافة هذه المقاييس بينما التطبيق صغير بدلًا من فعلها أثناء أول حادث حقيقي.
إذا قال مستخدم "إنه بطيء"، السجلات كثيرًا ما تخبرك ماذا حدث، والمقاييس تخبرك كم مرة يحدث. التتبُّعات تخبرك أين ذهب الوقت داخل طلب واحد. هذا الجدول الزمني الواحد يحول شكًا غامضًا إلى إصلاح واضح.
ابدأ على جانب الخادم. قيِّم الطلبات الواردة عند حافة تطبيقك (المعالج الأول الذي يستلم الطلب) حتى يتمكن كل طلب من إنتاج تتبُّع واحد. يمكن أن ينتظر تتبُّع جانب العميل.
تتبُّع اليوم الأول الجيد يحتوي على spans تُمثل الأجزاء التي عادةً ما تسبب البطء:
لجعل التتبُّعات قابلة للبحث والمقارنة، سجّل بعض السمات الرئيسية وحافظ على اتساقها عبر الخدمات.
لـ inbound request span، سجّل route (استخدم قالبًا مثل /orders/:id، ليس الـ URL الكامل)، طريقة HTTP، status_code، والـ latency. ل spans قواعد البيانات، سجّل نظام DB (PostgreSQL, MySQL)، نوع العملية (select, update)، واسم الجدول إذا كان من السهل إضافته. للنداءات الخارجية، سجّل اسم الاعتماد (payments, email, maps)، المضيف الهدف، والحالة.
العينات مهمة في اليوم الأول، وإلا ستزيد التكاليف والضوضاء بسرعة. استخدم قاعدة بسيطة: سجّل 100% من الأخطاء والطلبات البطيئة (إذا كان SDK يدعم ذلك)، وعيّن عينة صغيرة من الحركة العادية (مثل 1-10%). ابدأ أعلى عند انخفاض الحركة ثم خفّضها مع زيادة الاستخدام.
ما يبدو "جيدًا": تتبُّع واحد حيث يمكنك قراءة القصة من الأعلى إلى الأسفل. مثال: GET /checkout استغرقت 2.4s، DB قضت 120ms، الكاش 10ms، واستدعاء دفع خارجي استغرق 2.1s مع إعادة محاولة. الآن تعرف أن المشكلة في الاعتماد الخارجي، ليس في الكود الخاص بك. هذا هو جوهر حزمة بدء مراقبة الإنتاج.
عندما يقول شخص ما "إنه بطيء"، أسرع فوز هو تحويل ذلك الشعور الغامض إلى بضعة أسئلة ملموسة. يعمل هذا تدفق فرز حزمة بدء مراقبة الإنتاج حتى لو كان تطبيقك جديدًا تمامًا.
ابدأ بتضييق المشكلة، ثم اتبع الأدلة بالترتيب. لا تقفز مباشرة إلى قاعدة البيانات.
بعد أن تُمكّن الوضع، قم بتحسين صغير واحد: دوّن ما حدث وأضِف إشارة ناقصة واحدة. على سبيل المثال، إذا لم تتمكن من معرفة ما إذا كان البطء في منطقة واحدة فقط، أضِف وسمًا بالمنطقة إلى مقاييس التأخير. إذا رأيت span طويل لقاعدة البيانات بدون دليل على أي استعلام كان، أضِف تسميات الاستعلام بعناية، أو حقل "query name".
مثال سريع: إذا قفز p95 للـ checkout من 400 ms إلى 3 s وأظهرت التتبُّعات span بطئًا في استدعاء الدفع بقيمة 2.4 s، يمكنك إيقاف الجدال حول كود التطبيق والتركيز على المزود، ومحاولات الإعادة، والمهل الزمنية.
عندما يقول شخص ما "إنه بطيء"، يمكنك إضاعة ساعة فقط في فهم ما يقصده. حزمة بدء مراقبة الإنتاج مفيدة فقط إذا ساعدتك على تضييق المشكلة بسرعة.
ابدأ بثلاثة أسئلة توضيحية:
ثم انظر إلى بعض الأرقام التي عادةً ما تخبرك إلى أين تذهب بعد ذلك. لا تبحث عن لوحة تحكم مثالية. تريد فقط إشارات "أسوأ من الطبيعي".
إذا ارتفع p95 لكن الأخطاء ثابتة، افتح تتبُّعًا لواحد من الطلبات البطيئة في آخر 15 دقيقة. تتبُّع واحد غالبًا ما يوضح ما إذا كان الوقت يُنفق في قاعدة البيانات، استدعاء API خارجي، أو الانتظار على أقفال.
ثم قم ببحث سجلات واحد. إذا كان لديك تقرير مستخدم محدد، ابحث بواسطة request_id (أو trace_id إذا خزنته في السجلات) واقرأ الجدول الزمني. إذا لم يكن لديك، ابحث عن رسالة الخطأ الأكثر شيوعًا في نفس نافذة الزمن وانظر إن كانت تتماشى مع البطء.
أخيرًا، قرر ما إذا كنت ستخفف الآن أم تتابع التحقيق. إذا كان المستخدمون محظورين والتشبع عالي، قد يشتري التحجيم السريع أو التراجع أو تعطيل ميزة غير أساسية بعض الوقت. إذا كان التأثير صغيرًا والنظام مستقرًا، استمر بالتحقيق باستخدام التتبُّعات وسجلات الاستعلامات البطيئة.
بعد ساعات من إصدار، تبدأ تذاكر الدعم بالوصول: "الخروج يستغرق 20 إلى 30 ثانية." لا أحد يستطيع إعادة إنتاجها على أجهزتهم، فَيبدأ التخمين. هنا تظهر فائدة حزمة بدء مراقبة الإنتاج.
أولًا، اذهب إلى المقاييس وأكد العرض. مخطط p95 latency لطلبات HTTP يظهر قفزة واضحة، لكن فقط لـ POST /checkout. المسارات الأخرى طبيعية، ومعدل الأخطاء ثابت. هذا يضيّق المشكلة من "الموقع كله بطيء" إلى "مسار واحد أصبح أبطأ بعد الإصدار".
بعدها، افتح تتبُّعًا لطلب POST /checkout بطيء. مخطط التتبُّع يجعل الجاني واضحًا. نتيجتان شائعتان:
PaymentProvider.charge يأخذ 18 ثانية، ومعظم الوقت في الانتظار.DB: insert order بطيء، يظهر انتظارًا طويلاً قبل أن يرجع الاستعلام.الآن تحقق بالسجلات، مستخدمًا نفس request_id من التتبُّع (أو trace_id إذا خزّنته في السجلات). في سجلات ذلك الطلب، ترى تحذيرات متكررة مثل "payment timeout reached" أو "context deadline exceeded"، بالإضافة إلى محاولات إعادة أضيفت في الإصدار الجديد. إذا كان المسار قاعدة بيانات، قد تُظهر السجلات رسائل انتظار قفل أو استعلام بطيء مُسجلًا فوق عتبة.
مع توافق الإشارات الثلاث، يصبح الإصلاح بسيطًا:
المهم أنك لم تُجسِّ. المقاييس أشارت إلى المسار، التتبُّعات أشارت إلى الخطوة البطيئة، والسجلات أكدت وضع الفشل مع الطلب الدقيق بين يديك.
معظم وقت الحوادث يُضيع على ثغرات يمكن تجنبها: البيانات موجودة، لكنها صاخبة، محفوفة بالمخاطر، أو تفتقد التفصيل الوحيد الذي تحتاجه لربط الأعراض بالسبب. حزمة بدء مراقبة الإنتاج تفيد فقط إذا بقيت قابلة للاستخدام تحت الضغط.
فخ شائع هو تسجيل الكثير، خصوصًا أجسام الطلبات الخام. يبدو هذا مفيدًا حتى تدفع تكلفة تخزين هائلة، البحث يصبح بطيئًا، وتلتقط عن غير قصد كلمات مرور أو رموز أو بيانات شخصية. فضّل الحقول المهيكلة (route, status_code, latency, request_id) وسجّل فقط أجزاء صغيرة مصرح بها من الإدخال.
وقود الوقت الآخر هو مقاييس تبدو مفصّلة لكنها مستحيلة التجميع. الوسوم عالية التميّز مثل معرفات المستخدم الكاملة أو البريد الإلكتروني أو أرقام الطلبات يمكن أن تفجّر عدد سلاسل المقاييس وتجعل اللوحات لا تُعتمد. استخدم وسومًا خشنة بدلاً من ذلك (اسم المسار، طريقة HTTP، فئة الحالة، اسم الاعتماد)، واحتفظ بأي شيء محدد بالمستخدم في السجلات حيث ينتمي.
أخطاء تتكرر وتُعيق التشخيص السريع:
مثال عملي: إذا قفز p95 للـ checkout من 800ms إلى 4s، تريد إجابة سؤالين خلال دقائق: هل بدأ مباشرة بعد نشر، وهل الوقت يُنفق في تطبيقك أم في اعتماد خارجي (قاعدة بيانات، مزوّد دفع، كاش)؟ مع النسب المئوية، وسم الإصدار، وتتبُّعات تحمل اسم المسار واسم الاعتماد، يمكنك الوصول لذلك بسرعة. بدونها، تحترق نافذة الحادث في نقاشات افتراضية.
النجاح الحقيقي هو الاتساق. حزمة بدء مراقبة الإنتاج تساعد فقط إذا شُحِن كل خدمة جديدة بنفس الأساسيات، مسمّاة بنفس الطريقة، وسهلة العثور عند حدوث عطل.
حوّل اختياراتك من اليوم الأول إلى قالب قصير يعيد فريقك استخدامه. اجعله صغيرًا، لكن محددًا.
request_id لكل طلب وارد واحمله في السجلات والتتبُّعات.أنشئ عرضًا "منزليًا" واحدًا يمكن لأي شخص فتحه أثناء الحادث. يجب أن تعرض شاشة واحدة الطلبات لكل دقيقة، معدل الأخطاء، p95 latency، ومقياس التشبع الرئيسي، مع فلتر للبيئة والإصدار.
احتفظ بالتنبيهات بسيطة في البداية. تنبيهان يغطيان الكثير: ارتفاع معدل الأخطاء لمسار رئيسي، وقفزة p95 latency على نفس المسار. إذا أضفت المزيد، تأكد أن لكل واحد إجراء واضح.
أخيرًا، حدّد مراجعة شهرية متكررة. أزل التنبيهات المزعجة، ضيّق التسمية، وأضِف إشارة ناقصة واحدة كانت ستوفر وقتًا في الحادث الأخير.
لإدماج هذا في عملية البناء، أضِف "بوابة المرصودية" إلى قائمة التحقق قبل النشر: لا نشر بدون request_id، وسوم الإصدار، العرض المنزلي، والتنبيهان الأساسيان. إذا كنت تنشر باستخدام Koder.ai، يمكنك تعريف إشارات اليوم الأول هذه في وضع التخطيط قبل النشر، ثم التكرار بأمان باستخدام snapshots والتراجع عندما تحتاج إلى تعديل بسرعة.
Start with the first place users enter your system: the web server, API gateway, or your first handler.
request_id and pass it through every internal call.route, method, status, and duration_ms for every request.That alone usually gets you to a specific endpoint and a specific time window fast.
Aim for this default: you can identify the slow step in under 15 minutes.
You don’t need perfect dashboards on day one. You need enough signal to answer:
Use them together, because each answers a different question:
During an incident: confirm impact with metrics, find the bottleneck with traces, explain it with logs.
Pick a small set of conventions and apply them everywhere:
Default to structured logs (often JSON) with the same keys everywhere.
Minimum fields that pay off immediately:
Start with the four “golden signals” per major component:
Then add a tiny component checklist:
Instrument server-side first so every inbound request can create a trace.
A useful day-one trace includes spans for:
Make spans searchable with consistent attributes like (template form), , and a clear dependency name (for example , , ).
A simple, safe default is:
Start higher when traffic is low, then reduce as volume grows.
The goal is to keep traces useful without exploding cost or noise, and still have enough examples of the slow path to diagnose it.
Use a repeatable flow that follows evidence:
These mistakes burn time (and sometimes money):
service_name, environment (like prod/staging), and versionrequest_id generated at the edge and propagated across calls and jobsroute, method, status_code, and tenant_id (if multi-tenant)duration_ms)The goal is that one filter works across services instead of starting over each time.
timestamp, level, service_name, environment, versionrequest_id (and trace_id if available)route, method, status_code, duration_msuser_id or session_id (a stable ID, not an email)Log errors once with context (error type/code + message + dependency name). Avoid repeating the same stack trace on every retry.
routestatus_codepaymentspostgrescacheWrite down the one missing signal that would have made this faster, and add it next.
Keep it simple: stable IDs, percentiles, clear dependency names, and version tags everywhere.