09 نوفمبر 2025·7 دقيقة
كيف تتكامل أدوات البرمجة بالذكاء الاصطناعي فعلاً في سير العمل الإنتاجي
دليل عملي لاستخدام أدوات البرمجة بالذكاء الاصطناعي في الإنتاج: أين تساعد، وكيف تتكامل مع طلبات السحب والاختبارات وCI/CD والأمان ومعايير الفريق.
دليل عملي لاستخدام أدوات البرمجة بالذكاء الاصطناعي في الإنتاج: أين تساعد، وكيف تتكامل مع طلبات السحب والاختبارات وCI/CD والأمان ومعايير الفريق.
العروض التوضيحية مُحسّنة للسرعة والتأثير: مستودع نظيف، مهمة ضيقة، ومسار سليم. الهندسة اليومية عكس ذلك — حواف تراثية، متطلبات متطورة، سياق جزئي، وقاعدة شيفرة مليئة بقرارات اتُّخذت لأسباب وجيهة.
في العرض يمكن للذكاء الاصطناعي أن “يفوز” بإنتاج شيء يعمل مرة واحدة. في الإنتاج، المعيار أعلى: يجب أن تكون التغييرات مفهومة، قابلة للاختبار، آمنة، ومتوافقة مع الأنماط الموجودة. العمل الخفي ليس كتابة الشيفرة بقدر ما هو ملاءمة تلك الشيفرة لما حولها: معالجة الأخطاء، التسجيل، الترحيلات، حدود الأداء، والدعم التشغيلي.
عادة ما تقلق الفرق بشأن ثلاثة أشياء:
هذه المخاوف مشروعة، ولا تُحلّ بتحسين المطالبات فقط. تُحلّ بدمج المساعدة بالذكاء الاصطناعي داخل نفس الضوابط التي تثقون بها: مراجعة الشيفرة، الاختبارات، فحوصات CI، ومعايير هندسية واضحة.
يجب أن يكون "جاهزًا للإنتاج" صريحًا. على سبيل المثال: يتبع اتفاقياتكم، يتضمن اختبارات بالمستوى المناسب، يحدث الوثائق عند الحاجة، ويمر عبر CI دون تصحيح يدوي. إن لم تستطع وصفه، فلن تستطيع تقييم التغييرات المولّدة بالذكاء الاصطناعي باستمرار.
عامل الذكاء الاصطناعي كمبتدئ سريع في فريق: ممتاز في توليد الخيارات، إعادة التشكيل، والبرمجيات الروتينية—أقل موثوقية في اتخاذ قرارات المنتج أو فهم السياق التاريخي. توقع تسريعًا، لا قيادة أوتوماتيكية. الهدف هو تقليل الخطوات المملة مع الحفاظ على سيطرة عمليتكم الهندسية.
أسرع طريق للحصول على قيمة من أدوات البرمجة بالذكاء الاصطناعي هو البدء حيث العمل متكرر، المدخلات واضحة، والمخرجات سهلة التحقق. إن وجهتهم نحو قرارات منتج غامضة أو هندسة معقدة منذ اليوم الأول سيكلفكم وقتًا في تفكيك الاقتراحات أكثر من شحن الميزات.
فلتر بسيط: هل يستطيع المراجع إثبات أن التغيير صحيح بسرعة؟ إذا كان الجواب نعم، فهو مرشح جيد. إذا كانت الصحّة تعتمد على سياق نطاقي عميق، مقايضات تصميم طويلة الأمد، أو "ما يقصده المستخدمون"، فاعتبر الذكاء الاصطناعي شريكًا للعصف الذهني—وليس المؤلف.
تشمل المجالات الجيدة للبدء غالبًا:
اختر مجموعة صغيرة حتى يتعلم الفريق بشكل متسق. بالنسبة للعديد من الفرق، الثلاثي الأول الأفضل هو الاختبارات + إعادة التشكيل + الوثائق. كلٌ منها يولِّد نتائج ملموسة، والإخفاقات عادةً تظهر في المراجعة أو CI.
اجعل ما يمكن للذكاء الاصطناعي اقتراحه وما يجب أن يقرره البشر صريحًا (مقاطع الشيفرة، حالات الاختبار، مسودات الوثائق مقابل المتطلبات، وضعية الأمان، اتجاهات المعمارية، حدود الأداء). هذا يوضّح المساءلة.
أضف قائمة تحقق خفيفة إلى قالب PR أو اتفاق الفريق:
هذا يحافظ على الانتصارات المبكرة حقيقية—ويمنع "يبدو معقولًا" من أن يصبح "تم الدمج إلى main".
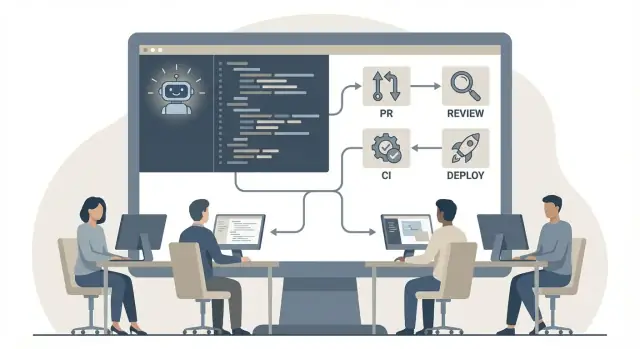
أدوات البرمجة بالذكاء الاصطناعي أكثر فائدة عندما تُعامل كزميل يمكنك سؤاله عن أمور سريعة—ثم تتحقق من النتائج. فعليًا، تخلط الفرق بين ثلاث "واجهات" حسب المهمة.
الإكمال المضمن الأفضل للعمل المستمر: كتابة القوالب، مطابقة الحقول، إضافة شروط صغيرة، أو إكمال نمط مألوف. يتفوق عندما تعلم ما تبنيه.
دردشة IDE أفضل للتفكير والتنقّل: "أين تُطبق هذه المصادقة؟" أو "ما شكل هذا DTO؟" جيدة أيضًا لتوليد المسودة الأولى لدالة ثم صقلها بحكمتك.
أدوات CLI تناسب العمليات الدُفعية: توليد ملاحظات الإصدار من الالتزامات، تلخيص الاختبارات الفاشلة، أو صياغة خطة ترحيل من diff. مفيدة أيضًا عندما تريد مخرجات محفوظة في ملفات أو مستخدمة داخل سكربتات.
بعض الفرق تستخدم منصات عالية المستوى للتحويل من دردشة إلى شريحة عمل كاملة (مثال: Koder.ai)، ثم تصدّر المصدر وتعيده إلى سير عمل المستودع العادي للمراجعة والاختبار وCI.
استخدم الذكاء الاصطناعي في الاستكشاف عندما لا تزال تؤطر المشكلة: توضيح المصطلحات النطاقية، سرد الخيارات، رسم نهج مبدئي، أو طلب مخاطر وحالات حافة.
استخدمه في تحرير الشيفرة الموجودة عندما يمكنك تقديم قيود واضحة: أي ملفات للمس، أي سلوك يجب ألا يتغير، وأي اختبارات لتحديثها. الهدف ليس "إعادة كتابة كبيرة"، بل تصحيح دقيق قابل للمراجعة.
السياق محدود، لذا يتعامل المطورون مع ذلك عبر:
عادة مجربة: اطلب diffًا أدنى أولًا. ثم كرر—تغيير سلوك واحد، ملف واحد، تحديث اختبار واحد—حتى تبقى مراجعة الشيفرة سريعة وتكون الانكسارات أسهل للاكتشاف.
تحسن نتائج الأدوات بشكل كبير عندما تعامل المطالبات كمدخلات هندسية، لا كرسائل دردشة. الهدف ليس "اكتب شيفرة لي"، بل "وسع هذه القاعدة دون كسر عاداتها".
قبل طلب تغييرات، ثبّت النموذج بما يبدو "طبيعيًا":
إضافة سطر في الطلب مثل "اتبع الأنماط الموجودة في src/payments/* وحافظ على الدوال تحت ~30 سطرًا إن أمكن" غالبًا ما تمنع تناقضات معمارية.
بدلًا من حل واحد، اطلب 2–3 مقاربات مع تداعياتها:
هذا يولد قرارات قابلة للمراجعة، وليس شيفرة فقط.
الملفات الكبيرة الملصوقة صعب التحقق منها. فضّل تغييرات متزايدة:
BillingService واختباراته."إذا لم تستطع الأداة إخراج diff نظيف، اطلب "الأقسام المتغيرة فقط" وقائمة بالملفات المتأثرة.
Given these files: BillingService.ts, billing.test.ts
Goal: add proration support.
Constraints: follow existing naming, keep public API stable.
Output: 2 options + a unified diff for the chosen option.
(ملاحظة: لا تُترجم كتل الشيفرة أعلاه.)
عندما تعطيك مطالبة نتائج جيدة بانتظام (مثال: "اكتب اختبارات بأسلوبنا" أو "ولد ترحيل مع تراجع"), خزّنها في مكتبة مقاطع فريق—مع أمثلة ونقاط تحذّر. هكذا تصبح المطالبات عملية مدوّنة، لا فولكلور.
الذكاء الاصطناعي يمكنه كتابة الشيفرة بسرعة، لكن جودة الإنتاج ما زالت تعتمد على PRs منضبطة. عامل المساعدة بالذكاء الاصطناعي كمساهم مبتدئ قوي: مفيد لزيادة الإنتاجية، لكنه ليس بديلًا للمساءلة.
PRs صغيرة ومقيدة هي أفضل طريقة لمنع "توسع الذكاء الاصطناعي". هدفك نية واحدة لكل PR. إن أنتجت الأداة الكثير من التعديلات، قسّمها إلى التزامات منطقية حتى يتسنى للمراجعين متابعة السرد.
تسميات وصفية مهمة أكثر مع التغييرات المساعدة بالذكاء الاصطناعي. أدرج:
حتى لو بدت الشيفرة نظيفة، احتفظ بقاعدة صارمة: كل تغيير من إنشاء الذكاء الاصطناعي يخضع لمراجعة بشرية. هذا ليس عدم ثقة—بل للتأكد من أن الفريق يفهم ما يندمج ويمكنه صيانته لاحقًا.
على المراجعين التركيز على ما يخطئ النموذج غالبًا:
أضف قائمة تحقق خفيفة إلى قالب PR:
الهدف بسيط: اجعل PRs قابلة للقراءة، اجعل البشر مسؤولين، ولا تجعل "يبدو صحيحًا" كافيًا بدون دليل.
الذكاء الاصطناعي ممتاز في توسيع تغطية الاختبارات، لكن الهدف ليس "اختبارات أكثر" بل اختبارات موثوقة تحمي السلوك الذي تهتم به فعلاً.
نمط عملي: اطلب من الأداة كتابة اختبارات من العقد العام: توقيع الدالة، مخطط استجابة الـ API، أو قواعد مرئية للمستخدم. يمكنه بسرعة تعداد حالات الحافة التي يتجاهلها البشر غالبًا—مدخلات فارغة، قيم الحد، نول، مسائل المناطق الزمنية، ومسارات الخطأ.
للحفاظ على جودة عالية، اجعل المطالبات محددة: "اكتب اختبارات لهذه السيناريوهات وشرح ماذا يثبت كل اختبار." هذا الشرح يسهل كشف الحالات غير الملائمة أو المكررة.
قد ينتج الذكاء الاصطناعي اختبارات تمر لأسباب خاطئة—تؤكد تفاصيل التنفيذ، تُمندح كل شيء، أو تكرر الشيفرة المختبرة. عامل الاختبارات المولّدة مثل الكود المولّد:
إن بدا الاختبار هشًا، أعد كتابته حول السلوك، لا البنية.
عندما تكون مجموعة المدخلات واسعة (محللات، مدققات، حسابات مالية)، اطلب من الذكاء الاصطناعي خصائص تحقق: ثوابت يجب أن تبقى دائمًا. أمثلة: "الترميز/فك الترميز يعيد الأصل"، "الفرز معادٍ للذات"، "لا يوجد مبالغ سالبة". كما يمكنه اقتراح مدخلات فزّ للتعامل مع Unicode الغريب، أحمال كبيرة، JSON معطوب.
لا تلصق سجلات عملاء حقيقية، أسرارًا، أو لقطات إنتاج في المطالبات. استخدم بيانات اصطناعية وممثلة (حجوم، صيغ، توزيعات) واحفظ Fixtures مشتركة داخل المستودع مع مصدر وملاحظات مراجعة واضحة.
عند التنفيذ الجيد، يساعدك الذكاء الاصطناعي على الشحن بثقة أفضل—ليس فقط بعلامات خضراء أسرع.
أدوات الذكاء الاصطناعي أكثر فائدة في CI/CD عندما تُحسّن حلقات التغذية الراجعة دون خفض معيار النشر. عامل مخرجات الذكاء الاصطناعي كشيفرة يجب أن تجتاز نفس الفحوص الآلية وإجراءات السلامة.
نمط عملي هو السماح للذكاء الاصطناعي بالمساعدة في توليد التغييرات، ثم الاعتماد على CI للتحقق منها. المراحل "الصديقة للذكاء الاصطناعي" هي الحتمية والسريعة:
إذا كان الفريق يستخدم مساعدًا لصياغة الشيفرة، اجعل من السهل تشغيل نفس الفحوص محليًا وفي CI كي لا تتقافز الأخطاء ذهابًا وإيابًا.
احتفظ بقواعد دمج واضحة وغير قابلة للتفاوض. الحد الأدنى الشائع:
هنا يمكن للذكاء الاصطناعي المساعدة أيضًا: إنشاء الاختبارات المفقودة أو إصلاح الفحوص الفاشلة—دون السماح بتجاوزها.
تعمل إعادة التشكيل المدعومة بالذكاء الاصطناعي أفضل عندما تكون مقيدة النطاق: وحدة واحدة، واجهة واحدة، تغيير سلوك واحد. التغييرات العريضة عبر مستودعات أكثر مخاطرًا لأنها تضخم الأخطاء الدقيقة. فضّل PRs متزايدة وأضف اختبارات انكسار مستهدفة قبل التعديلات "الميكانيكية".
افترض أن التغييرات المولّدة قد تفشل بطريقة جديدة. انشر خلف أعلام ميزات، اجعل الإصدارات صغيرة، واجعل العودة روتينًا. اشترط خطة طرح واضحة (ما الذي يتغير، كيف تُراقَب، وكيف تُرجَع) كي لا تعتمد السلامة على بطل عند حدوث خطأ.
إذا كان لديك منصة تنشر معاينات تلقائيًا، فضّل الميزات التي تقلل المخاطر التشغيلية—لقطات ونقاط تراجع. (مثال: Koder.ai يدعم لقطات والتراجع ضمن سير استضافته.)
أدوات الذكاء الاصطناعي أسرع عندما تكون بلا احتكاك—وخطرها الأكبر عندما تكون بلا احتكاك. عاملها مثل أي خدمة طرف ثالث: حدد ما يُسمح بمغادرته من بيانات، ما الشيفرة التي يمكن استيرادها، ومن يوافق.
ضع قائمة "لا تشارك أبدًا" واضمنها في القوالب والتدريب:
فضّل "وصفًا بدلًا من اللصق": لخص المشكلة، أرفق مقتطفات صغيرة، واحذف المعرفات. إن أمكن، مرر الاستخدام عبر خطة مؤسسية مع ضبط احتفاظ البيانات ورؤية إدارية.
إذا كانت إقامة البيانات مطلبًا، تأكد أن الأداة يمكن تشغيلها في المناطق المطلوبة. بعض المنصات (بما في ذلك Koder.ai، التي تعمل على AWS عالميًا) تسمح بنشر التطبيقات في دول محددة للمساعدة في قيود الخصوصية والانتقال عبر الحدود.
قد تعكس الشيفرة المولّدة أنماطًا مرخّصة عن غير قصد. اشترط على المهندسين:
إن كان لدى فريقكم سياسة قانونية/امتثال، اربطها في دليل الهندسة (مثال: /handbook/ai-use).
اجعل مخرجات الذكاء الاصطناعي تجتاز نفس البوابات كالشفرة البشرية:
عرّف من يمكنه استخدام أي أدوات، في أي مستودعات، وبأي إعدادات. أضف موافقات خفيفة للمناطق عالية المخاطر (المدفوعات، المصادقة، تصدير البيانات) ووثّق الاستثناءات. عند وقوع حادث، تريد أثر تدقيق واضح—دون لوم الأداة.
الذكاء الاصطناعي يسرّع التنفيذ، لكنه قد يخفف من صيغ اتفاقياتكم بهدوء: التسمية، الطبقات، معالجة الأخطاء، و"كيف نفعل الأشياء هنا". عامل الأداة كمساهم مبتدئ—مساعد لكنه موجه.
اجعل المعايير قابلة للفحص الآلي لكي تُدفع الشيفرة المولّدة نحو الشكل الصحيح. استخدم قوالب المشروع، linters، وقواعد التنسيق، ثمشغّلها تلقائيًا.
مزيج عملي:
عندما يقترح المساعد كودًا، يجب أن يكون من السهل للمطورين تشغيل نفس الفحوص قبل الدفع.
المساهمون الجدد غالبًا ما يتعثرون مع التجريدات الداخلية. دلّ الأداة على أمثلة حقيقية واطلب شرحها، ثم اربط الشرح بالملفات المصدرية.
القاعدة: يجب أن تستشهد التفسيرات بالشيفرة الموجودة، لا تخلق اتفاقيات جديدة. إن لم تجد مرجعًا، فهذه إشارة أن وثائقك أو أمثلتك ناقصة.
قرارات المعمارية يجب أن تعيش كـ ADRs، لا كسلوك ضمني في الشيفرة المولدة. إن كان PR يُدخل تبعية جديدة، حدًا، أو نموذج بيانات جديد، اشترط تحديث ADR أو إنشاء واحد جديد.
اشترط مبررًا في وصف PR: لماذا هذا النهج، لماذا هذه المقايضة، وما البدائل التي نُفّذت. إن كتب معظمها الذكاء الاصطناعي، لا يزال الإنسان يملك سبب الاختيار.
نشر أدوات الذكاء الاصطناعي يتعلق بالعادات المشتركة أكثر من الأداة نفسها. الهدف ليس أن يجعل الجميع "يستخدم الذكاء الاصطناعي"، بل أن يجعل الفريق أكثر أمانًا وسرعة عندما يختار استخدامه.
ابدأ بمجموعة تجريبية صغيرة (4–8 مطورين بمستويات مختلفة) ومنحهم مهمة واضحة: تحديد أين تساعد الأداة، أين تضر، وما الضوابط المطلوبة.
نظم تدريبًا تمهيديًا قصيرًا (60–90 دقيقة) يغطي: نقاط قوة الأداة، أنماط الإخفاق الشائعة، وكيف تتوقعون مراجعة المخرجات. ثم عقد ساعات مكتبية أسبوعية لمدة شهر لعرض حالات فعلية، مطالبات، وحالات حافة محرجة.
أنشئ مستندًا خفيفًا "ما يفعل وما لا يفعل" في دليل الهندسة (/docs/ai-coding). اجعله عمليًا وحديثًا:
عندما يعترض أحدهم على تغيير بمساعدة الذكاء الاصطناعي، عامل الاعتراض كأي اقتراح آخر: اطلب مبررًا. اسأل: "ما الخطر الذي يُدخله هذا؟" و"ما الدليل الذي سيحسم الأمر؟" (معايير، اختبارات، diff أصغر، أو مذكرة تصميم). إذا لزم، اعتمِد التغيير المحافظ للإصدار الحالي وجدول العمل للمتابعة.
يجب أن يقلل الذكاء الاصطناعي الأعمال الشاقة، لا يقلّل الفهم. ضع أهداف تعلم (مثال: "كل PR يشرح السبب"، "تدوير ملكية الوحدات المعقدة") وشجّع الاقتران: يقود شخص، ويقيّم آخر اقتراحات الذكاء الاصطناعي. مع الزمن، يحافظ هذا على الحكم الحاد—ويجعل الأداة مساعدًا لا عكازًا.
قياس أدوات البرمجة بالذكاء الاصطناعي أقل عن إثبات أنها "تعمل" وأكثر عن تعلم أين تساعد الفريق فعلًا على الشحن بسلامة أقل احتكاكٍ. الفخ السهل هو اختيار مقياس تجميلي (مثل "أسطر مولّدة" أو "عدد الطلبات") ثم مشاهدة سلوك يهدف لزيادة الرقم بدلًا من النتيجة.
ابدأ بمجموعة صغيرة من النتائج التي تهتم بها بالفعل:
استخدمها كمؤشرات اتجاهية، لا لتقييم الأداء الفردي. إن شعر الناس بأنهم قيد الحكم، سيلتفّون حول القياس.
المقاييس الكمية لا تشرح لماذا تغيّر شيء. أضف ملاحظات نوعية خفيفة:
عند تجربة أداة، سجّل فئات محددة: اختبارات مولّدة، إعادة تشكيلات مساعدة، وثائق محدثة، بالإضافة إلى سلبيات مثل "تشويش المراجعة"، "انحراف الأسلوب"، أو "استخدام واجهة API خاطئ". عبر بضعة سباقات، تتضح الأنماط.
إذا زاد الذكاء الاصطناعي تغطية الاختبارات لكنه زاد الاختبارات المتقلبة، شدّد الإرشادات: اشترط تأكيدات حتمية وإضافة قائمة مراجعة للمراجعة. إن سرّع إعادة تشكيل الروتين، تعمّق بتوفير قوالب وأمثلة. اعتبر الأدوات والقواعد قابلة للتغيير—هدفك تحسين قابل للقياس، لا تبرير ضجيج.
لأن العروض التقديمية مصممة لمسار نجاح واضح: مستودع نظيف، مهمة ضيقة، وبدون تعقيدات. العمل في الإنتاج يتطلب ملاءمة التغييرات مع معايير الفريق — اختبارات، معالجة الأخطاء، تسجيل السجلات، الأمان، التوافق، حدود الأداء، الترحيلات، والدعم التشغيلي.
تغيّر يعمل مرة واحدة في عرض تجريبي قد يكون غير مقبول في الإنتاج إذا كان يصعب مراجعته أو صيانته أو يحمل مخاطر عند النشر.
اجعل تعريفه صريحًا وقابلًا للفحص. تعريف الفريق المفيد غالبًا يتضمن:
إن لم تستطع وصفه، فلن تستطيع تقييم الأعمال المساعدة بالذكاء الاصطناعي باستمرار.
أعلى حالات الاستخدام ذات العائد المبكر هي الأعمال المتكررة ذات مدخلات واضحة وقابلية تحقق سهلة عبر المراجعة/CI، مثل:
تجنب البدء بقرارات منتج غامضة أو إعادة تصميم معماري—هذه تحتاج سياقًا عميقًا لا يملكه النموذج بشكل موثوق.
استخدم فلترًا بسيطًا: هل يستطيع المراجع إثبات صحة التغيير بسرعة؟
عامله كمشارك سريع مبتدئ: جيد في المسودات والخيارات، ليس في اتخاذ القرار النهائي.
غيّر السطح حسب المهمة بدلاً من إجبار أداة واحدة على فعل كل شيء.
ثبت النموذج في عادات المستودع قبل طلب تغييرات:
src/payments/*)المطالبات تعمل كمدخلات هندسية: قيود، حدود، وخطوات التحقق—لا تكن مجرد "اكتب كودًا".
اجعل PRs أصغر مما تفعل عادةً بدون الذكاء الاصطناعي:
الفروق الصغيرة تقلل إجهاد المراجعة وتجعل العيوب الخفية أسهل للاكتشاف.
نعم — اشترط مراجعة بشرية لكل التغييرات المساعدة بالذكاء الاصطناعي. الهدف هو القابلية للصيانة والمساءلة:
الأداة تسرع المسودات، ولكن البشر ما زالوا يملكون ما يُشَحَن.
ابدأ من العقدة العامة (واجهات الدوال، مخطط استجابة الـ API، قواعد مرئية للمستخدم) واطلب سيناريوهات واضحة وحالات حافة. ثم تحقق أن الاختبارات تعطي إشارة حقيقية:
الاختبارات المولدة مسودات—راجعها كما تراجع كود الإنتاج.
عامله كخدمة طرف ثالث وحدد ضوابط:
ai-assisted وقوائم تحقق خفيفة للتحققإن لم تستطع الأداة اجتياز معاييرك الحالية، فلا تُسمح للشيفرة الناتجة بالانتشار بغض النظر عن سرعة إنشائها.