23 أبريل 2025·8 دقيقة
كيف تدعم قواعد بيانات المتجهات البحث الدلالي لتطبيقات الذكاء الاصطناعي
تعلم كيف تخزن قواعد بيانات المتجهات التضمينات، تُجرِي بحث تشابه سريع، وتدعم البحث الدلالي، روبوتات RAG، التوصيات، وتطبيقات الذكاء الاصطناعي الأخرى.
ما معنى البحث الدلالي (بلغة بسيطة)
البحث الدلالي يركّز على ما تعنيه، وليس فقط الكلمات الدقيقة التي تكتبها.
إذا سبق وأن بحثت عن شيء وفكرت «الإجابة هنا بوضوح—لماذا لا يجدها؟»، فهذه تجربة حدود البحث بالكلمات. البحث التقليدي يطابق المصطلحات؛ وهذا يعمل عندما تتشابه صياغة الاستعلام مع صياغة المحتوى.
لماذا يفشل البحث بالكلمات في كثير من الأحيان
البحث بالكلمات يعاني من:
- المترادفات والصياغات: "cancel" مقابل "close" مقابل "terminate" للحساب.
- النية: "how do I stop being billed?" في الأصل تتعلق بإلغاء الاشتراك.
- السياق: "apple charger" (العلامة التجارية) مقابل "apple tree charger" (سخف، لكن الفكرة واضحة).
كما يمكنه المبالغة في تقدير الكلمات المتكررة، ليعيد نتائج تبدو ملائمة ظاهريًا بينما يتجاهل الصفحة التي تجيب فعلاً بصياغة مختلفة.
مثال بسيط
تخيل مركز مساعدة يحتوي على مقال بعنوان "Pause or cancel your subscription." يبحث المستخدم:
"stop my payments next month"
قد لا يصنّف نظام الكلمات ذاك المقال عاليًا إذا لم يتضمن "stop" أو "payments". البحث الدلالي مصمم لفهم أن "stop my payments" مرتبط بـ "cancel subscription"، ويضع ذلك المقال في القمة — لأن المعنى متطابق.
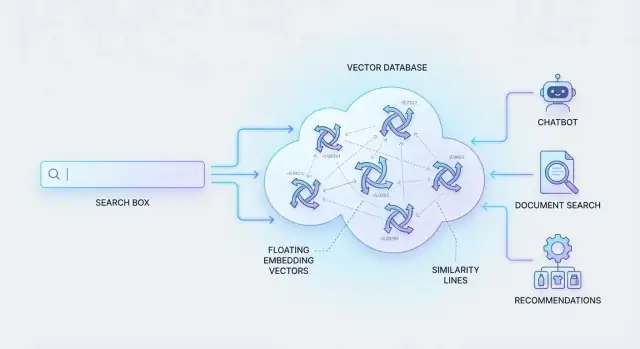
أين تقع قواعد بيانات المتجهات
لجعل هذا يعمل، تمثل الأنظمة المحتوى والاستعلامات كـ "بصمات معنى" (أرقام تلتقط التشابه). ثم يجب البحث عبر ملايين من هذه البصمات بسرعة.
هذا ما تُبنى لأجله قواعد بيانات المتجهات: تخزين هذه التمثيلات العددية واسترجاع أقرب التطابقات بكفاءة، حتى يبدو البحث الدلالي فوريًا على نطاق واسع.
التضمينات: تحويل المحتوى إلى متجهات ذات معنى
التضمين هو تمثيل رقمي للمعنى. بدلًا من وصف مستند بكلمات مفتاحية، تمثّله كقائمة أرقام ("متجه") تلتقط ما يتحدث عنه المحتوى. مقطعا محتوى متشابهين في المعنى سينتجان متجهات تقع قرب بعضها في ذلك الفضاء الرقمي.
كيف يبدو التضمين فعليًا
فكّر في التضمين كإحداثي على خريطة عالية الأبعاد. عادة لن تقرأ الأرقام مباشرة — فهي ليست مهيأة للبشر. قيمتها في سلوكها: إذا أنتجت "cancel my subscription" و"how do I stop my plan?" متجهات متقاربة، يستطيع النظام معاملتهما كمترابطين حتى لو تشابكت كلمات قليلة أو لم تتشابه.
النص، الصور، والصوت كلها يمكن أن تصبح متجهات
التضمينات ليست مقتصرة على النص.
- تضمينات النص تمثل الجمل، الفقرات، تذاكر الدعم، أوصاف المنتجات، والمزيد.
- تضمينات الصور تمثل التشابه البصري والمفاهيم (مثل "حذاء جري أحمر").
- تضمينات الصوت يمكن أن تمثل المتكلم، النغمة، أو معنى الكلام المنطوق عند إقرانها بنماذج تحويل الكلام.
هكذا يمكن لقاعدة متجهات واحدة أن تدعم "البحث بصورة"، "إيجاد أغاني مشابهة"، أو "توصية منتجات مشابهة".
التضمينات تُنتَج بواسطة نماذج — ليس بتعليم بشري
المتجهات لا تأتي من وسم يدوي. تُنتَج بواسطة نماذج تعلم آلي مدرّبة لضغط المعنى إلى أرقام. ترسل المحتوى إلى نموذج التضمين (مستضاف لديك أو عبر مزود)، ويعيد المتجه. يخزن تطبيقك ذلك المتجه جنبًا إلى المحتوى الأصلي والميتا داتا.
لماذا اختيار نموذج التضمين يؤثر في الجودة والتكلفة
النموذج الذي تختاره يؤثر بشدة على النتائج. النماذج الأكبر أو المتخصصة تحسن الصلة غالبًا لكنها أغلى وربما أبطأ. النماذج الأصغر أرخص وأسرع لكنها قد تفقد الدقة — خصوصًا للغة مجال محدد أو لغات متعددة أو استعلامات قصيرة. تختبر الكثير من الفرق عدة نماذج مبكرًا للعثور على التوازن قبل التوسع.
كيف تخزن قواعد بيانات المتجهات البيانات
قاعدة بيانات المتجهات مبنية على فكرة بسيطة: خزّن "المعنى" (متجه) مع المعلومات التي تحتاجها لتحديد، تصفية، وعرض النتائج.
نموذج البيانات الأساسي
معظم السجلات تبدو كالتالي:
- ID: معرف فريد تسيطر عليه (مثل
doc_18492أو UUID) - Vector (embedding): مصفوفة أرقام تمثل معنى المحتوى
- Metadata: حقول مفتاح–قيمة مثل title, URL, tags, author, language, created_at, أو tenant_id
مثال: قد يخزن مقال مركز المساعدة:
- ID:
kb_123 - Vector: 768 عددًا عائمًا (لنموذج تضمين شائع)
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
المتجه هو ما يُشغّل تشابه المعنى. المعرف والميتا داتا هما ما يجعل النتائج قابلة للاستخدام.
لماذا الميتا داتا أهم مما يتوقع الناس
الميتا داتا تؤدي مهمتين:
- التصفية قبل/بعد البحث المتجه: "أظهر فقط نتائج المنتج X"، "فقط الإنجليزية"، "فقط المستندات التي يمكن للمستخدم الوصول إليها"، أو "فقط العناصر الأحدث من 90 يومًا". هذا ضروري للملاءمة والتحكم بالوصول.
- العرض والإجراءات: عند عرض نتيجة، لا يريد المستخدم متجهًا — يريد عنوانًا، مقتطفًا، ورابطًا. الميتا داتا توفر التفاصيل اللازمة لواجهة المستخدم.
بدون ميتا داتا جيدة قد تسترجع المعنى الصحيح ولكن تعرض السياق الخاطئ.
أحجام المتجهات الشائعة وتبعات التخزين
حجم التضمين يعتمد على النموذج: 384، 768، 1024، و1536 أبعاد شائعة. مزيد الأبعاد يلتقط تفصيلًا أكبر لكنه يزيد أيضًا:
- التخزين (كل سجل يخزن أرقامًا أكثر)
- ضغط الذاكرة للبحث السريع
- زمن بناء الفهرس (خاصة مع فهرسة ANN)
كمبادرة تقريبية: مضاعفة الأبعاد غالبًا ما ترفع التكلفة والزمن إلا إذا عوضت بخيارات فهرسة أو ضغط.
أنماط التحديث: إدراج، تعديل، وحذف
المجموعات الحقيقية تتغير، لذا غالبًا تدعم قواعد بيانات المتجهات:
- Insert: إضافة محتوى جديد مع تضمينه وميتا داتاه
- Update: تغيير الميتا داتا أو استبدال المتجه إذا تغيّر المحتوى
- Delete: إزالة المحتوى القديم أو الملغى
- Re-embed: إعادة حساب المتجهات عند تغيير نموذج التضمين، طريقة التقسيم، أو تحرير النص بشكل كبير
التخطيط للتحديثات مبكرًا يمنع مشكلة "المعرفة القديمة" حيث يعيد البحث محتوى لم يعد مطابقًا لما يراه المستخدمون.
بحث التشابه: إيجاد "أقرب المعاني" بسرعة
بعد تحويل النصوص والصور والمنتجات إلى تضمينات، يصبح البحث مسألة هندسة: "أي المتجهات هي الأقرب إلى متجه هذا الاستعلام؟" يسمى هذا بحث أقرب جار. بدلًا من مطابقة الكلمات، يقارن النظام المعنى بقياس قرب المتجهات.
أقرب الجيران بلغة بسيطة
تخيل كل قطعة محتوى كنقطة في فضاء متعدد الأبعاد ضخم. عندما يبحث المستخدم، يتحول استعلامه إلى نقطة أخرى. يعيد بحث التشابه العناصر التي نقاطها الأقرب — "أقرب جيرانك". تلك الجيران من المرجح أن تشارك النية أو الموضوع أو السياق حتى لو لم تتشارك كلمات بالضبط.
مقاييس التشابه الشائعة
قواعد بيانات المتجهات عادةً تدعم طرقًا قياسية لقياس "القرب":
- Cosine similarity: يقارن الزاوية بين المتجهات (مفيد عندما تهتم بالاتجاه/المعنى أكثر من المقدار).
- Dot product: مرتبط بالـ cosine لكنه يتأثر أيضًا بطول المتجه؛ يُستخدم غالبًا مع المتجهات المُوَحَّدة.
- Euclidean distance: المسافة الخطية بين النقاط (مفيد في بعض النماذج والمجالات).
نماذج التضمين تُدرّب لقياس معين، لذا من المهم استخدام المقياس الذي يوصي به مزود النموذج.
البحث الدقيق مقابل التقريبي (ANN)
البحث الدقيق يفحص كل متجه ليجد أقرب الجيران الحقيقيين. هذا دقيق لكنه يصبح بطيئًا ومكلفًا على مقياس الملايين.
معظم الأنظمة تستخدم ANN (approximate nearest neighbor). ANN يستفيد من هياكل فهرسة ذكية ليقلّص البحث إلى مرشحين واعدين. عادة تحصل على نتائج "قريبة بما يكفي" من الأفضل الحقيقي — بسرعة أكبر.
مفاضلة الزمن مقابل الاستدعاء
ANN شائع لأنه يسمح بالضبط حسب حاجتك:
- زمن أقل (استجابات أسرع) بالبحث في مرشحين أقل
- استدعاء أعلى (العثور على المزيد من أفضل التطابقات الحقيقية) بالبحث في مرشحين أكثر
هذا الضبط هو سبب عمل بحث المتجه جيدًا في التطبيقات الحقيقية: يمكنك إبقاء الاستجابات سريعة بينما تعيد نتائج ذات صلة عالية.
سير عمل البحث الدلالي من البداية للنهاية
البحث الدلالي أسهل للفهم كخط أنابيب بسيط: تحوّل النص إلى معنى، تبحث عن معانٍ متشابهة، ثم تعرض أو تستخدم أفضل التطابقات.
1) تضمين الاستعلام
يكتب المستخدم سؤالًا (مثال: "How do I cancel my plan without losing data?"). يشغّل النظام هذا النص عبر نموذج التضمين، منتجًا متجهًا — مصفوفة أرقام تمثل معنى الاستعلام بدل كلماتها الحرفية.
2) بحث في قاعدة المتجهات
يُرسل متجه الاستعلام إلى قاعدة المتجهات، التي تجري بحث التشابه لإيجاد المتجهات "الأقرب" بين المحتوى المخزن.
تُرجع معظم الأنظمة top-K التطابقات: أفضل K مقاطع/مستندات متشابهة.
- لماذا K قابل للتعديل: قيمة K أصغر أسرع وغالبًا كافية (مثال: K=5).
- قيمة K أكبر تزيد الاستدعاء لكن قد تضم نتائج "قريبة" أكثر (مثال: K=50).
3) (اختياري) إعادة الترتيب لرفع الدقة
بحث التشابه محسن للسرعة، لذا قد تحتوي قائمة top-K الأولية على مطابقة قريبة لكنها غير مثالية. إعادة الترتيب (reranker) هو نموذج ثانٍ ينظر إلى الاستعلام وكل نتيجة مرشحة معًا ويعيد ترتيبها بحسب الصلة.
فكّر فيه هكذا: بحث المتجه يعطيك قائمة قصيرة قوية؛ إعادة الترتيب تختار أفضل ترتيب.
4) إرجاع النتائج (أو تغذية خطوات لاحقة)
أخيرًا، تُرجع أفضل التطابقات للمستخدم (كنتيجة بحث)، أو تمرّرها لمساعد ذكي (مثلاً نظام RAG) كـ "دليل".
إذا تبني هذا النوع من التدفق في تطبيق، منصات مثل Koder.ai يمكن أن تساعدك على النمذجة السريعة: تصف تجربة البحث الدلالي أو RAG بواجهة محادثة، ثم تكرر على الواجهة الأمامية React والواجهة الخلفية Go/PostgreSQL مع إبقاء خط الاسترجاع (تضمين → بحث متجه → إعادة ترتيب اختياري → إجابة) كجزء أساسي من المنتج.
مثال سريع "الكلمات مقابل الدلالي"
إذا قال مقال مركز المساعدة "terminate subscription" وبحث المستخدم "cancel my plan"، قد يفشل بحث الكلمات لأن "cancel" و"terminate" لا تتطابقان.
البحث الدلالي عادةً يسترجعه لأن التضمين يلتقط أن العبارتين تعبران عن نفس النية. أضف إعادة ترتيب، وتصبح النتائج العلوية عادةً ليست "مشابهة" فحسب، بل مباشرة قابلة للتنفيذ لسؤال المستخدم.
البحث الهجين ومرشحات الميتا داتا لنتائج أفضل
اختر الخطة المناسبة
انتقل من Free إلى Pro أو Business عندما يزداد استخدامك واحتياجات فريقك.
البحث المتجه النقي رائع في "المعنى"، لكن المستخدمين لا يبحثون دائمًا بالمقصد فقط. أحيانًا يحتاجون لمطابقة حرفية: اسم كامل، SKU، رقم فاتورة، أو رمز خطأ من سجل. يحل البحث الهجين هذا بمزج الإشارات الدلالية (المتجهات) مع الإشارات اللفظية (بحث كلمات تقليدي مثل BM25).
ماذا يفعل "البحث الهجين" بالفعل
يجرى الاستعلام الهجين غالبًا عبر مسارين متوازيين:
- بحث متجه: يجد محتوى مفهوميًا مشابهًا حتى لو اختلفت الصياغة
- بحث كلمات/BM25: يجد محتوى يتشارك نفس الرموز، ويكافئ المصطلحات النادرة والمطابقة الحرفية
ثم يدمج النظام تلك النتائج المرشحة في قائمة مرتبة واحدة.
متى يكون الهجين الخيار الأفضل بشكل افتراضي
البحث الهجين يتألق عندما يتضمن بياناتك سلاسل "يجب مطابقتها":
- أسماء منتجات مع معدّلات محددة (مثال: "Pro Max", "Gen 2")
- معرفات (أرقام الطلب، تذاكر، قطع)
- رموز أخطاء ("E0421", "ORA-00933") وأعلام الأوامر
- مصطلحات مجال نادرة حيث المترادفات قد تكون محفوفة بالمخاطر
البحث الدلالي وحده قد يعيد صفحات مرتبطة بشكل عام؛ وبحث الكلمات وحده قد يفشل في العثور على إجابات مُعاد صياغتها. الهجين يغطي الحالتين.
استخدام مرشحات الميتا داتا لتضييق مساحة البحث
مرشحات الميتا داتا تقصر الاسترجاع قبل الترتيب (أو بجواره)، محسّنة الملاءمة والسرعة. فلاتر شائعة تشمل:
- اللغة (إرجاع مستندات باللغة الإنجليزية فقط)
- نطاق التاريخ (السياسة الأحدث، ملاحظات الإصدار الأخيرة)
- الفئة أو المصدر (مستندات مقابل تذاكر؛ "billing" مقابل "security")
- علامات التحكم بالوصول (فقط ما يصرح للمستخدم برؤيته)
كيف يعمل الترتيب (مستوى عالٍ)
تستخدم معظم الأنظمة مزيجًا عمليًا: تشغّل كلا البحثين، تطبّع الدرجات لتصبح قابلة للمقارنة، ثم تطبّق أوزانًا (مثال: "اعتمد أكثر على الكلمات للمُعرفات"). بعض المنتجات أيضًا تعيد ترتيب القائمة المدموجة بنموذج خفيف أو قواعد، بينما تضمن الفلاتر أنك ترتب المجموعة الصحيحة أصلاً.
RAG: استخدام قواعد المتجهات لتأسيس إجابات LLM
الاسترجاع المعزز بالتوليد (RAG) هو نمط عملي للحصول على إجابات أكثر موثوقية من LLM: استرجع أولًا معلومات ملائمة، ثم ولّد استجابة مرتبطة بذلك السياق.
فكرة RAG في جملة واحدة
بدلًا من أن تطلب من النموذج "تذكّر" مستندات شركتك، خزن تلك المستندات (كمتجهات) في قاعدة متجهات، استرجع المقاطع ذات الصلة وقت السؤال، ومرّرها إلى LLM كمصدر داعم.
لماذا قاعدة المتجهات تقلل الهلوسة
نماذج اللغة جيدة جدًا في الكتابة، لكنها تميل لملء الفراغات بثقة عندما تفتقد الحقائق المطلوبة. تجعل قاعدة المتجهات من السهل جلب المقتطفات الأقرب من قاعدة معرفتك وإدراجها في الـ prompt.
هذا التأسيس يحوّل النموذج من "اختراع إجابة" إلى "تلخيص وشرح هذه المصادر". كما يسهل تدقيق الإجابات لأنه يمكنك تتبع المقاطع المسترجعة وعرض الاستشهادات إن رغبت.
أساسيات التقسيم (حتى يعمل الاسترجاع فعلاً)
جودة RAG غالبًا ما تعتمد أكثر على التقسيم من النموذج نفسه.
- حجم المقطع: استهدف مقاطع تحتوي على فكرة مكتملة (فقرات قصيرة أو قسم قصير). صغير جدًا يفقد المعنى؛ كبير جدًا يجلب ضوضاء.
- التداخل: أضف تداخلًا صغيرًا حتى لا تُفصل التفاصيل المهمة عند الحواف.
- الحفاظ على السياق: احتفظ بالعناوين والرؤوس والمعرفات (اسم المستند، القسم، التاريخ) في الميتا داتا حتى تكون النتائج مفهومة وقابلة للتصفية.
وصف خط أنابيب RAG بسيط
تخيل هذا التدفق:
سؤال المستخدم → تضمين السؤال → استرجاع top-k مقاطع من قاعدة المتجه (+ فلاتر ميتا داتا اختيارية) → بناء المطالبة بالمقاطع المسترجعة → LLM يولد الإجابة → إرجاع الإجابة (ومصادرها).
قاعدة المتجهات تقع في المنتصف كـ "ذاكرة سريعة" تزود كل طلب بالأدلة الأكثر صلة.
حالات استخدام شائعة تدعمها قواعد بيانات المتجهات
من الدردشة إلى التطبيق، متكاملًا
وصف تجربة المستخدم التي تريدها ودع Koder.ai يبني هيكل التطبيق لك.
قواعد بيانات المتجهات لا تجعل البحث فقط "أذكى" — بل تمكّن تجارب منتج حيث يصف المستخدم ما يريد باللغة الطبيعية ويحصل على نتائج ملائمة. فيما يلي بعض الاستخدامات العملية المتكررة.
دعم العملاء: إيجاد إجابات تتجاوز الكلمات المفتاحية
فرق الدعم غالبًا لديها قاعدة معرفة، تذاكر قديمة، سجلات محادثة، وملاحظات إصدار — لكن البحث بالكلمات يواجه صعوبة مع المترادفات، إعادة الصياغة، والوصف الضبابي للمشكلة.
بهذا، يستطيع الوكيل (أو الشات بوت) استرجاع تذاكر سابقة "تعني نفس الشيء" حتى لو اختلفت الصياغة. يسرّع ذلك الحل، يقلل التكرار، ويساعد الوكلاء الجدد على التعلم بسرعة. مزج بحث المتجه مع فلاتر الميتا داتا (خط إنتاج، لغة، نوع المشكلة، نطاق التاريخ) يحافظ على تركيز النتائج.
اكتشاف المنتجات: البحث في الكتالوج كما يتحدث الناس
المتسوقون نادرًا يعرفون أسماء المنتجات الدقيقة. يبحثون بنوايا مثل "حقيبة صغيرة تستوعب لابتوب وتبدو احترافية". تلتقط التضمينات تلك التفضيلات — الأسلوب، الوظيفة، القيود — فتبدو النتائج أقرب إلى مساعد مبيعات بشري.
هذا الأسلوب يعمل في الكتالوغات، قوائم السفر، العقارات، مجال التوظيف، والأسواق. يمكنك أيضًا مزج الصلة الدلالية بقيود مهيكلة مثل السعر، الحجم، التوفر، أو الموقع.
التوصيات: "عناصر مشابهة" واكتشاف المحتوى
ميزة كلاسيكية هي "إيجاد عناصر مثل هذا". إذا عرض المستخدم عنصرًا أو قرأ مقالًا أو شاهد فيديوً، يمكنك استرجاع محتوى آخر ذا معنى أو صفات مماثلة — حتى عندما لا تتطابق الفئات.
هذا مفيد ل:
- وحدات "المزيد من هذا"
- مقترحات مقالات متصلة واقتراحات في قاعدة المعرفة
- الكشف عن مكرر أو شبه مكرر (لمراقبة المحتوى أو التنظيف)
البحث الداخلي مع صلاحيات: السياسات، المستندات، ملاحظات الاجتماعات
داخل الشركات، تتناثر المعلومات عبر مستندات، ويكيات، ملفات PDF، وملاحظات الاجتماعات. يساعد البحث الدلالي الموظفين على طرح أسئلة طبيعية ("ما سياسة التعويض عن المؤتمرات؟") وإيجاد المصدر الصحيح.
الجزء غير القابل للتفاوض هو التحكم بالوصول. يجب أن تحترم النتائج الصلاحيات — غالبًا عبر التصفية على الفريق، مالك المستند، مستوى السرية، أو قائمة ACL — بحيث يسترجع المستخدم فقط ما يسمح له برؤيته.
إذا أردت التوسع، نفس طبقة الاسترجاع هي ما يشغل أنظمة الأسئلة والأجوبة المؤسسية المدعومة بالتأسيس (RAG).
خطوط أنابيب البيانات: الاستيعاب، التقسيم، والتحديثات
نظام البحث الدلالي جيد بقدر خط الأنابيب الذي يغذيه. إذا وصلت المستندات بشكل غير متناسق، أو قُسِّمت بصورة سيئة، أو لم تُعاد تضمينها بعد التعديلات، فإن النتائج تنحرف عن توقعات المستخدمين.
تدفق استيعاب بسيط (يعمل)
تتبع معظم الفرق تسلسلًا قابلاً للتكرار:
- جمع البيانات (مستندات، PDF، تذاكر، سجلات محادثة، صفحات ويكي، بيانات منتجات).
- تنظيفها (إزالة القوالب، إصلاح التشفير، تطبيع المسافات، استخراج النص الرئيسي).
- تقسيمها (Chunking) (تقسيم إلى مقاطع يُحتمل أن يسترجعها المستخدم).
- تضمينها (توليد المتجهات بنموذج التضمين المختار).
- Upsert (كتابة المتجهات + الميتا داتا في قاعدة المتجهات، والاستبدال عند الحاجة).
خطوة "التقسيم" هي المكان الذي يكسب فيه كثيرون أو يخسرون. التقسيم بحسب البنية الطبيعية (عناوين، فقرات، أزواج سؤال/جواب) مع تداخل صغير عادةً ينجح.
الحفاظ على التضمينات محدثة
المحتوى يتغير باستمرار — السياسات تُحدَّث، الأسعار تتغير، تُعيد المقالات صياغتها. اعتبر التضمينات بيانات مشتقة يجب تجديدها.
تكتيكات شائعة:
- احتفظ بمعرف المستند المصدر، معرف المقطع، هاش المحتوى. إذا تغيّر الهاش، أعد تضمين المقطع.
- استخدم حذفات ناعمة (وضع المقاطع القديمة غير نشطة) لتجنب نتائج الأشباح.
- أعد البناء انتقائيًا بدل إعادة التضمين الكامل.
الدفعات مقابل التدفق المستمر
- الدفعات (Batch) مناسبة للملءِ الكبير، المزامنات الليلية، والمحتوى المتوقع (توثيق، قواعد معرفة).
- التدفق (Streaming) يناسب المصادر سريعة التغير (تذاكر الدعم، محتوى المستخدم، الجرد). يقلّل التقدّم لكنه يتطلب مراقبة وتحمّل تكاليف أقوى.
لغات متعددة ونماذج متعددة
إذا خدمتك لغات متعددة، يمكنك استخدام نموذج تضمين متعدد اللغات (أبسط) أو نماذج حسب اللغة (أحيانًا جودة أعلى). إذا جربت نماذج، فعنّون تضميناتك (مثال: embedding_model=v3) لتتمكن من اختبار A/B والعودة دون كسر البحث.
قياس الجودة والأداء
قد يبدو البحث الدلالي "جيدًا" في عرض تقديمي لكنه يفشل في الإنتاج. الفارق هو القياس: تحتاج مؤشرات صلة واضحة ومتطلبات زمنية، تقاس على استعلامات شبيهة بسلوك المستخدم الحقيقي.
مؤشرات الصلة التي تعكس رضى المستخدم
ابدأ بمجموعة صغيرة من المقاييس والتزم بها:
- الدقة / الاستدعاء (Precision / Recall): الدقة تُظهر كم النتايج العائدة ذات صلة؛ الاستدعاء يُظهر كم العناصر ذات الصلة استعدت كلها. استخدمهما عندما تعرف تعريفًا واضحًا لـ "ذو صلة".
- MRR (Mean Reciprocal Rank): مناسب عندما يتوقع المستخدم إجابة واحدة "الأفضل". يكافئ وضع المستند الصحيح في الأعلى.
- nDCG: مفيد عندما يمكن أن تكون عدة نتائج ذات درجات علاقة مختلفة (عالي الصلة مقابل شبه ملائم).
- الزمن (p50/p95): تتبع المتوسط وذيل الزمن. p50 السريع مع p95 بطيء سيشعر المستخدم بالبطء أحيانًا.
بناء مجموعة اختبار موثوقة
أنشئ مجموعة تقييم من:
- استعلامات حقيقية من سجلات البحث أو تذاكر الدعم (بعد إخفاء الهوية).
- مستندات متوقعة (تسميات ذهبية) يتفق عليها خبراء المجال.
- حالات حافة: استعلامات قصيرة ("refund"), أسئلة طويلة، مصطلحات غامضة، أسماء منتجات نادرة، واستعلامات "بلا نتيجة" حيث السلوك الصحيح هو إظهار "لم يتم العثور على شيء".
احتفظ بمجموعة الاختبار بإصدار لتقارن عبر الإصدارات.
اختبارات A/B وخطوط تغذية راجعة
المقاييس خارج السجل لا تلتقط كل شيء. شغّل اختبارات A/B واجمع إشارات خفيفة الوزن:
- إبهام لأعلى/أسفل على النتائج
- معدل النقر والوقت المقضى
- أحداث "تعديل البحث"
استخدم هذه التغذية لتحديث الأحكام حول الملاءمة وكشف أنماط الفشل.
مراقبة الانجراف مع الزمن
الأداء قد يتغير عندما:
- تغيّر نموذج التضمين أو طريقة التقسيم
- يتغير مستودعك (منتجات جديدة، تغييرات سياسات، مصطلحات موسمية)
أعد تشغيل مجموعة الاختبار بعد أي تغيير، راقب اتجاهات المقاييس أسبوعيًا، وضع تنبيهات للانخفاضات الحادة في MRR/nDCG أو ارتفاعات في p95.
الأمان والخصوصية والتحكم بالوصول
شارك عبر نطاقك
ضع بحثك الدلالي أو روبوت الدردشة على نطاق مخصص لتمكين المعنيين من تجربته.
يغيّر بحث المتجهات كيفية استرجاع البيانات، لكنه لا يجب أن يغيّر من يحق له الاطلاع. إذا كان نظامك الدلالي أو RAG "يجد" المقطع الصحيح، فقد يُرجعه عن طريق الخطأ لشخص غير مصرح — ما لم تصمم الأذونات والخصوصية في خطوة الاسترجاع.
التحكم بالوصول: طبّقه وقت الاسترجاع
القاعدة الأأمن بسيطة: يجب أن يسترجع المستخدم فقط ما يحق له قراءته. لا تعتمد على التطبيق لإخفاء النتائج بعد إرجاعها من قاعدة المتجه — لأن المحتوى يكون قد غادر وحدته التخزينية بالفعل.
مقاربات عملية:
- ACL لكل مستند أو مقطع: خزّن حقول الإذن مع كل متجه ليتم تطبيقها على كل استعلام.
- عزل المستأجرين: لتطبيقات متعددة المستأجرين، فرّق البيانات حسب المستأجر (أقسام منطقية، مساحات اسم، أو فهارس منفصلة) لتجنب تسرب بين المستأجرين.
فلاتر الميتا داتا للأذونات
تدعم كثير من قواعد المتجهات فلاتر ميتا داتا (مثال: tenant_id, department, project_id, visibility) تعمل جنبًا إلى جنب مع بحث التشابه. إن استُخدمت بشكل صحيح، فهي طريقة نظيفة لتطبيق الأذونات وقت الاسترجاع.
تفصيل مهم: تأكّد أن الفلتر إلزامي وعلى مستوى الخادم، لا منطق اختياري على جانب العميل. كن حذرًا من "انفجار الأدوار" (عدد كبير من التركيبات). إذا كان نموذج الأذونات معقدًا، فكّر في حساب "مجموعات الوصول الفعلية" مسبقًا أو استخدام خدمة تفويض مخصصة لصكّ فلتر وقت الاستعلام.
البيانات الشخصية والمعلومات الحساسة: قرر ما لا يُضمّن أبدًا
يمكن للتضمينات أن تُشفِر معنى النص الأصلي. هذا لا يكشف تلقائيًا عن PII الخام، لكنه قد يزيد المخاطر (مثل تسهيل استرجاع حقائق حساسة).
إرشادات مفيدة:
- تجنّب تضمين الحقول الحساسة جدًا (أرقام الضمان الاجتماعي، تفاصيل الدفع، معرفات طبية) متى أمكن.
- احذف أو استبدل القيم قبل التضمين إذا كان النص يجب أن يكون قابلاً للبحث (استبدل القيم بأماكن نائبة).
- خزن الأصلي بعيدًا واسترجعه فقط بعد فحوصات الأذونات.
احتياجات التشغيل: نسخ احتياطية، الاحتفاظ، والتدقيق
عامل فهرسك كبيانات إنتاجية:
- نسخ واستعادة: الفهارس قد تكون مكلفة لإعادة بنائها؛ خطط للقطرات أو مسار إعادة البناء من البيانات المصدر.
- سياسات الاحتفاظ: احذف المتجهات عندما تنتهي صلاحية المستندات المصدر أو يطلب المستخدم الحذف.
- قابلية التدقيق: سجّل من استعلم عن ماذا (على الأقل سياق الاستعلام ومعرفات المستندات التي أُعيدت) لدعم التحقيقات والامتثال.
عندما تُطبّق هذه الممارسات جيدًا، يصبح البحث الدلالي سحريًا للمستخدمين — دون أن يتحول إلى مفاجأة أمنية لاحقًا.
المزالق، التكاليف، وقائمة اختيار عملية للاختيار
قد تبدو قواعد المتجهات "جاهزة للتوصيل"، لكن معظم خيبات الأمل تنتج عن الاختيارات المحيطة: كيف تقسم البيانات، أي نموذج تضمين تختار، وكيف تحافظ على كل شيء محدثًا.
أوضاع الفشل الشائعة (وكيف تكتشفها)
التقسيم السيئ هو سبب #1 للنتائج غير الملائمة. المقاطع الكبيرة جدًا تضيف ضوضاء؛ الصغيرة جدًا تفقد السياق. إذا كان المستخدمون غالبًا يقولون "وجد المستند الصحيح لكن المقطع خاطئ"، فاستراتيجية التقسيم بحاجة لتحسين.
نموذج التضمين الخاطئ يظهر كمطابقة دلالية متكررة لكنها منحرفة — النتائج جيدة الصياغة لكنها خارج الموضوع. يحدث ذلك عندما لا يكون النموذج مناسبًا لمجالك (قانوني، طبي، تذاكر دعم) أو نوع المحتوى (جداول، كود، نص متعدد اللغات).
البيانات القديمة تقتل الثقة بسرعة: المستخدم يبحث عن سياسة حديثة ويحصل على نسخة ربع سنوية قديمة. إذا تغيّر المصدر، فيجب أن تتغيّر التضمينات والميتا داتا (والحذف يجب أن يكون حقيقيًا).
التعامل مع البدايات الباردة والنتائج الفارغة
مبكرًا قد يكون لديك محتوى قليل جدًا أو استعلامات قليلة أو تغذية راجعة غير كافية لضبط الاسترجاع. خطط لـ:
- بدائل: بحث بالكلمات أو "إجابات مختارة" عند ضعف النتائج الدلالية.
- واجهة نتائج فارغة: أعرض فئات ذات صلة، اطرح سؤال توضيحي، أو وسّع الفلاتر.
- استعلامات إحماء: اختبر بمجموعة صغيرة من الأسئلة التمثيلية قبل الإطلاق.
محركات التكلفة التي يجب ميزانيتها
التكاليف عادة تأتي من أربعة مصادر:
- حوسبة التضمين (ملء أولي + تحديثات مستمرة)
- التخزين (متجهات، ميتا داتا، والفهارس)
- حجم الاستعلامات (قراءات، مخرجات الشبكة، والتزامن)
- إعادة الترتيب (اختياري لكنها قوية؛ قد تضيف تكلفة نموذج لكل استعلام)
عند مقارنة البائعين، اطلب تقديرًا شهريًا بسيطًا باستخدام عدد المستندات المتوقع، متوسط حجم المقطع، وقدرة الطلب القصوى. كثير من المفاجآت تحدث بعد الفهرسة وخلال ارتفاعات الحركة.
قائمة اختيار عملية لاختيار قاعدة بيانات متجهات
استخدم هذه القائمة القصيرة لاختيار ما يناسبك:
- جودة البحث: هل تدعم البائع البحث الهجين وفلترة الميتا داتا؟ هل يمكنك إضافة إعادة ترتيب؟
- الأداء: خيارات فهرسة ANN، زمن متوقع عند ذروة المرور، وسهولة التوسع.
- عمليات البيانات: إدراج/تحديث/حذف، إعادة فهرسة، إصدار، وملء دون توقف.
- الرصد: سجلات الاستعلام، مقاييس الاستدعاء/الزمن، وأدوات لتتبع "لماذا ظهرت هذه النتيجة".
- الأمان: تشفير، عزلة مستأجرين، الوصول القائم على الأدوار، وأنماط التصفية حسب الصلاحية.
- التكامل: SDKs، لغات مدعومة، وموصلات لمخازنك (S3، قواعد بيانات، مستندات).
- التكلفة الإجمالية: تسعير شفاف للتخزين، الكتابات، القراءات، وأي حوسبة مُدارة.
الاختيار الجيد لا يتعلق بمتابعة أحدث نوع فهرسة، بل بالموثوقية: هل يمكنك الحفاظ على البيانات حديثة، التحكم بالوصول، والمحافظة على الجودة مع نمو المحتوى وحركة المرور؟
الأسئلة الشائعة
ما هو البحث الدلالي، ببساطة؟
البحث بالكلمات يطابق الرموز الحرفية. البحث الدلالي يطابق المعنى عن طريق مقارنة التضمينات (المتجهات)، لذلك يمكنه إرجاع نتائج ملائمة حتى عندما يستخدم الاستعلام صياغة مختلفة (مثل: “stop payments” → “cancel subscription”).
ماذا تفعل قاعدة بيانات المتجهات فعليًا في نظام البحث الدلالي؟
قاعدة بيانات المتجهات تخزن التضمينات (مصفوفات أرقام) بالإضافة إلى معرفات وسياق (metadata)، ثم تجري عمليات بحث أقرب جار سريعة لإيجاد العناصر التي أقرب معنىً إلى الاستعلام. هي مُحسّنة لبحث التشابه على نطاق كبير (غالبًا ملايين المتجهات).
ما هو التضمين ولماذا هو مهم؟
التضمين هو «بصمة» رقمية يُنتجها النموذج للمحتوى. لا تفسّر الأرقام يدويًا؛ تُستخدم لقياس التشابه.
عمليًا:
- حول المستندات (أو المقاطع) إلى تضمينات
- حول استعلام المستخدم إلى تضمين
- استرجع أقرب التضمينات كنتاج
ما البيانات التي يجب أن أخزنها لكل عنصر في قاعدة بيانات المتجهات؟
تحتوي أغلب السجلات على:
- (أنت تتحكم فيه)
لماذا الميتا داتا مهمة للملاءمة والأمان؟
الميتا داتا تُمكّن قدرين حاسمين:
- التصفية: قصر النتائج على مجموعة صحيحة (اللغة، المنتج، نطاق التاريخ، الأذونات)
- العرض: إظهار عنوان ومقتطف ورابط بدلًا من إرجاع معرف داخلي فقط
بدون ميتا داتا قد تسترجع المعنى الصحيح ولكن تعرض سياقًا خاطئًا أو تكشف محتوى مقيد.
أي مقياس تشابه يجب أن أستخدم؟ (cosine, dot product, Euclidean)؟
الخياران الشائعان:
- التشابه الكوني (Cosine similarity): يقارن الزاوية بين المتجهات (مفيد عند الاهتمام بالاتجاه أكثر من الطول)
- الضرب الداخلي (Dot product): مرتبط بالـ cosine ويمكن أن يتأثر بطول المتجه
- المسافة الإقليدية (Euclidean distance): المسافة الخطية بين النقاط
استخدم المقياس الذي تدرب النموذج عليه؛ اختيار مقياس «خطأ» يمكن أن يضعف الترتيب بشكل ملحوظ.
ما الفرق بين البحث الدقيق و ANN (الأقرب التقريبي)؟
البحث الدقيق يقارن الاستعلام مع كل متجه، مما يصبح بطيئًا ومكلفًا عند الملايين. البحث الأقرب التقريبي (ANN) يستخدم هياكل فهرسة ذكية ليقلّص مجموعة المرشحين.
الاختيار قابل للضبط بين:
- استجابات أسرع (زمن استجابة أقل)
- تغطية أفضل للنتائج الحقيقية (استدعاء أعلى)
متى أستخدم البحث الهجين بدل البحث المتجه الصرف؟
البحث الهجين يجمع بين:
- بحث المتجهات للمعنى والصياغات المختلفة
- بحث بالكلمات / BM25 للمطابقات الحرفية (مثل معرفات الطلب، رموز الأخطاء)
غالبًا ما يكون الافتراضي الأفضل عندما يتضمن المستودع سلاسل يجب مطابقتها حرفيًا.
كيف تدعم قاعدة بيانات المتجهات أنماط RAG لتطبيقات LLM؟
RAG (الاسترجاع المعزز بالتوليد) يسترجع المقاطع الملائمة من مخزونك ويمدّ النموذج بها كـ context قبل توليد الإجابة.
تدفق نموذجي:
- تضمين سؤال المستخدم
- استرجاع أعلى K مقطعًا من قاعدة المتجهات (مع فلترة ميتا داتا)
- بناء المطالبة (prompt) بالمقاطع المسترجعة
- يقوم LLM بالتوليد مستندًا إلى تلك المصادر
ما هي أكثر العثرات شيوعًا عند بناء بحث دلالي باستخدام قواعد بيانات المتجهات؟
أخطر ثلاث مشكلات:
- تقسيم سيّئ للمقاطع (chunking): كبير جدًا يضيف ضوضاء؛ صغير جدًا يفقد السياق
- تضمينات قديمة: المحتوى يتغير دون إعادة توليد التضمينات فينتج نتائج غير محدثة
- عدم تطبيق تصفية أذونات عند الاسترجاع: قد تُرجع مقاطع مقيدة قبل أن يخفيها التطبيق
تخفيف المخاطر: قسم المحتوى بحسب البنية، نسخه وإصدار نماذج التضمين، وافرض فلترة ميتا داتا إلزاميًا على مستوى الخادم (مثل أو حقول ACL).