18 أغسطس 2025·8 دقيقة
LLVM لكريس لاتنر: المحرك الهادئ خلف سلاسل الأدوات الحديثة
تعرف كيف أصبح LLVM الذي بدأه كريس لاتنر منصة مترجم معيارية تقف خلف لغات وأدوات عديدة — تمكّن التحسينات، تشخيص أفضل، وبنايات تشغيل سريعة.
ما هو LLVM، بلغة بسيطة
من الأفضل التفكير في LLVM كـ «غرفة المحركات» التي تشترك فيها العديد من المترجمات وأدوات المطورين.
عندما تكتب شفرة بلغة مثل C أو Swift أو Rust، لا بد من وجود مكوّن يترجم تلك الشفرة إلى تعليمات يمكن لوحدة المعالجة أن تنفذها. المترجم التقليدي غالبًا ما يبني كل أجزاء تلك السلسلة بنفسه. LLVM يتبع نهجًا مختلفًا: يوفر قلبًا قابلاً لإعادة الاستخدام يعالج الأجزاء الصعبة والمكلفة — التحسين، التحليل، وتوليد شفرة الآلة لأنواع عديدة من المعالجات.
أساس مشترك للغات كثيرة
LLVM ليس مترجمًا واحدًا تستخدمه «مباشرة» في معظم الأحيان. إنه بنية تحتية للمترجم: لبنات بناء يمكن لفرق اللغات تجميعها لتكوين سلسلة أدوات. يمكن لفريق أن يركز على النحو والقواعد وميزات موجهة للمطور، ثم يسلم الأعمال الثقيلة إلى LLVM.
هذا الأساس المشترك سبب رئيسي في قدرة اللغات الحديثة على إصدار سلاسل أدوات سريعة وآمنة دون إعادة اختراع عقود من عمل المترجمات.
لماذا يهم حتى لو لم تكن متخصّصًا بالمترجمات
LLVM يظهر في تجربة المطور اليومية من خلال:
- السرعة: يمكنه تحويل الشفرة عالية المستوى إلى شفرة آلة فعّالة عبر منصات متعددة.
- أخطاء وتصحيح أفضل: النظام البيئي حول LLVM يتيح تشخيصات أغنى وأدوات أفضل.
- أكثر من "فقط الترجمة": التحليل الساكن، أدوات التحقق أثناء التشغيل، تغطية الشفرة، وغيرها من المساعدات للمطور غالبًا ما تبنى فوق نفس التمثيل والمكتبات الأساسية.
ما سيقدمه هذا المقال (وما لن يقدمه)
هذه جولة موجهة للأفكار التي بدأها كريس لاتنر: كيفية تنظيم LLVM، لماذا الطبقة الوسطى مهمة، وكيف تمكّن التحسينات والدعم متعدد المنصات. لن تكون كتابًا دراسيًا — سنبقي التركيز على الحدس والتأثير العملي بدل النظرية الصارمة.
الرؤية الأصلية لكريس لاتنر
كريس لاتنر عالم حاسوب ومهندس بدأ LLVM في أوائل الألفية بناءً على إحباط عملي: تقنيات المترجمات كانت قوية لكن صعبة إعادة الاستخدام. إذا أردت لغة جديدة أو تحسينات أفضل أو دعم ل معالج جديد، غالبًا ما كان عليك العبث بمترجم مُقفل متكامل حيث كل تغيير له آثار جانبية.
المشكلة التي أراد حلها
في ذلك الوقت، بُنيت العديد من المترجمات كآلات كبيرة واحدة: الجزء الذي يفهم اللغة، والجزء الذي يحسّن، والجزء الذي يولد شفرة الآلة كانت مترابطة بعمق. هذا جعلها فعّالة لهدفها الأصلي، لكن مكلفة للتكيّف.
هدف لاتنر لم يكن "مترجمًا للغة واحدة"، بل تأسيس أساس مشترك يمكن أن يُغذي لغات وأدوات متعددة — دون أن يعيد الجميع كتابة نفس الأجزاء المعقدة مرارًا وتكرارًا. كانت الفكرة أنه إذا أمكنك توحيد منتصف خط الترجمة، فستتمكن من الابتكار أسرع عند الحواف.
لماذا كانت فكرة "البنية المعيارية" جديدة آنذاك
التحول الرئيسي كان في اعتبار الترجمة كمجموعة من لبنات قابلة للفصل مع حدود واضحة. في عالم معياري:
- يمكن لفريق اللغة أن يركز على التحليل وبناء ميزات موجهة للمطور،
- يمكن لفريق التحسين أن يحسّن الأداء مرة واحدة ويشاركه على نطاق واسع،
- يمكن إضافة دعم العتاد دون إعادة تصميم كل شيء في الأعلى.
هذا الانفصال يبدو بديهيًا الآن، لكنه كان يناقض كيفية تطور العديد من المترجمات الإنتاجية.
مفتوح المصدر ومبني للاستخدام العام
أُصدر LLVM كمشروع مفتوح المصدر مبكرًا، وهذا كان مهمًا لأن البنية التحتية المشتركة تعمل فقط إذا استطاع مجموعات متعددة الوثوق بها، فحصها، وتوسيعها. مع مرور الوقت، أضافت الجامعات والشركات والمساهمون المستقلون أهدافًا جديدة، أصلحوا الحالات الحدودية، حسّنوا الأداء، وبنوا أدوات حوله.
جانب المجتمع لم يكن مجرد عمل خيري — بل جزء من التصميم: اجعل النواة مفيدة على نطاق واسع، فتُصبح مجدية للصيانة جماعيًا.
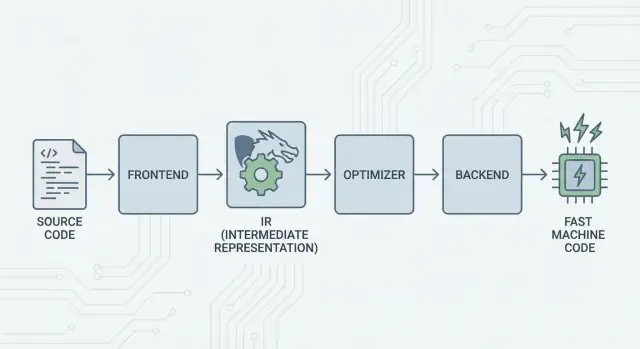
الفكرة الكبيرة: الواجهات الأمامية، نواة مشتركة، والمعالِجات الخلفية
فكرة LLVM الأساسية بسيطة: قسّم المترجم إلى ثلاثة أجزاء رئيسية حتى تستطيع لغات كثيرة مشاركة أصعب العمل.
1) الواجهات الأمامية: «ماذا قصد المبرمج؟»
الواجهة الأمامية تفهم لغة برمجة محددة. تقرأ الشفرة المصدرية، تتحقق من القواعد (النحو والأنواع)، وتحوّلها إلى تمثيل منظم.
النقطة الأساسية: الواجهات الأمامية لا تحتاج لمعرفة كل تفاصيل المعالج. مهمتها هي تحويل مفاهيم اللغة — الدوال، الحلقات، المتغيرات — إلى شيء أكثر عمومية.
2) النواة المشتركة: بدلاً من عمل N×M
تقليديًا، بناء مترجم يعني عمل نفس الشغل مرارًا وتكرارًا:
- مع N لغات وM أهداف معالج، ستحصل على N×M مجموعات للدعم.
LLVM يخفض ذلك إلى:
- N واجهات أمامية تترجم إلى شكل مشترك
- M معالِجات خلفية تترجم من ذلك الشكل المشترك إلى شفرة آلة
هذا "الشكل المشترك" هو مركز LLVM: خط أنابيب مشترك حيث تعيش التحسينات والتحليلات. أي تحسين في المنتصف يمكن أن يفيد العديد من اللغات دفعة واحدة بدل إعادة تنفيذه في كل مترجم.
3) المعالِجات الخلفية: «كيف نجعل هذا سريعًا على ذلك المعالج؟»
المعالج الخلفي يأخذ التمثيل المشترك وينتج مخرجات خاصة بالآلة: تعليمات لـ x86 أو ARM، وهكذا. هنا تكمن تفاصيل مثل المسجلات، اتفاقيات الاستدعاء، واختيار التعليمات.
صورة استيعابية لخط الأنابيب
فكر في الترجمة كمسار سفر:
- الشفرة المصدرية تبدأ في بلد معين (الواجهة الأمامية).
- تعبر إلى لغة وسطية موحَّدة (التمثيل الوسيط ونطاق التحسينات في LLVM).
- ثم تعتمد نظامًا محليًا للوصول إلى المدينة المقصودة (المعالج الخلفي).
النتيجة هي سلسلة أدوات معيارية: اللغات تركز على التعبير بوضوح، بينما النواة المشتركة لـ LLVM تركز على جعل تلك الأفكار تعمل بكفاءة عبر منصات متعددة.
LLVM IR: الطبقة الوسطى التي تمكّن إعادة الاستخدام
LLVM IR (التمثيل الوسيط) هو "اللغة المشتركة" التي تقع بين لغة البرمجة وشفرة الآلة التي ينفذها المعالج.
الواجهة الأمامية (مثل Clang لـ C/C++) تترجم الشفرة المصدرية إلى هذا الشكل المشترك. ثم تعمل أدوات تحسين LLVM ومولّدي الشفرة على الـ IR، وليس على اللغة الأصلية. أخيرًا، يقوم المعالج الخلفي بتحويل الـ IR إلى تعليمات مستهدفة.
لغة مشتركة بين الأدوات والمعالجات
فكر في LLVM IR كجسر مصمم بعناية:
- أعلى منه: يمكن توصيل العديد من لغات المصدر (C، C++، Rust، Swift، Julia، إلخ).
- أسفله: يمكن استهداف العديد من المعالجات.
- في المنتصف: يمكن إعادة استخدام نفس أدوات التحليل والتحسين.
لهذا يصف الناس LLVM غالبًا بأنه "بنية تحتية للمترجم" بدل أن يكون "مترجمًا". الـ IR هو العقدة المشتركة التي تجعل تلك البنية قابلة لإعادة الاستخدام.
لماذا الـ IR يمكّن إعادة الاستخدام (ويوفّر العمل على الجميع)
بمجرد أن تصبح الشفرة في LLVM IR، فإن معظم تمريرات التحسين لا تحتاج لمعرفة ما إذا كانت الشفرة بدأت كقوالب C++ أو ITERATORS في Rust أو جنريك Swift. هي تهتم بأفكار عامة مثل:
- "هذه القيمة ثابتة."
- "هذا الحساب متكرر؛ هل يمكننا إعادة استخدام النتيجة؟"
- "هذا التحميل من الذاكرة يمكن نقله أو إزالته بأمان."
لذلك لا تحتاج فرق اللغات لبناء وصيانة كومة محسنين كاملة بنفسها. يمكنهم التركيز على الواجهة الأمامية — التحليل، فحص الأنواع، قواعد اللغة — ثم التسليم إلى LLVM للأعمال الثقيلة.
كيف يبدو ذلك مفاهيميًا
LLVM IR منخفض المستوى بما فيه الكفاية ليناسب ترجمة نظيفة إلى شفرة الآلة، لكنه منظم بما يكفي للتحليل. مفهوميًا، يتكوّن من تعليمات بسيطة (جمع، مقارنة، تحميل/تخزين)، تدفق تحكم صريح (فروع)، وقيم ذات أنوع قوي — أشبه بلغة تجميع منظمة للمترجمات أكثر مما يكتبه الإنسان عادة.
كيف تعمل التحسينات (بدون الرياضيات)
عندما يسمع الناس "تحسينات المترجم"، غالبًا ما يتخيلون حيلًا غامضة. في LLVM، معظم التحسينات تُفهم أفضل على أنها إعادة كتابات آمنة وآلية للبرنامج — تحويلات تحافظ على وظيفة الشفرة لكن تهدف لجعلها أسرع (أو أصغر).
فكر بها كتحرير، لا اختراع
LLVM يأخذ شفرتك (في LLVM IR) ويطبّق تحسينات صغيرة متكررة، مثل تلميع مسودّة:
- إزالة العمل المكرر: إذا حُسبت قيمة مرتين ولم يتغير شيء بينهما، يمكن حسابها مرة واحدة وإعادة استخدامها.
- تبسيط المنطق الواضح: التعبيرات الثابتة يمكن طيّها مبكرًا (مثلاً تحويل
3 * 4إلى12) حتى يقل ما تقوم به وحدة المعالجة في وقت التشغيل. - تبسيط الحلقات: تمريرات الحلقات يمكنها تقليل الفحوص المتكررة، نقل العمل الثابت خارج الحلقة، أو التعرف على أنماط يمكن تنفيذها بكفاءة أكبر.
هذه التغييرات محافظة عمدًا. تقوم كل تمريرة بإعادة كتابة فقط عندما تستطيع إثبات أن ذلك لن يغير معنى البرنامج.
أمثلة مُقاربة
إذا كان برنامجك يقوم، مفهوميًا، بالتالي:
- يقرأ نفس قيمة التهيئة في كل تكرار من حلقة
- يؤدي نفس الحساب على نفس المدخلات في أماكن متعددة
- يفحص شرطًا يكون دائمًا صحيحًا/خطأً في سياق معين
…يحاول LLVM تحويل ذلك إلى "قم بالإعداد مرة واحدة"، "أعد استخدام النتائج"، و"حذف الفروع الميتة". إنها أقل سحرًا وأكثر صيانة.
المقايضة العملية: وقت التجميع مقابل وقت التشغيل
التحسين ليس مجانيًا: المزيد من التحليل والمزيد من التمريرات يعني عادةً تباطؤًا في التجميع، حتى لو كانت النتيجة النهائية أسرع. لذلك تقدم سلاسل الأدوات مستويات مثل "تحسين قليل" مقابل "تحسين مكثّف".
الملفات التعريفية تساعد هنا. مع التحسين الموجَّه بالملف الشخصي (PGO)، تشغّل البرنامج، تجمع بيانات الاستخدام الحقيقية، ثم تعيد التجميع بحيث يركز LLVM جهوده على المسارات التي تهم فعلاً — مما يجعل المقايضة أكثر قابلية للتنبؤ.
المعالِجات الخلفية: الوصول إلى العديد من المعالجات دون إعادة كتابة كل شيء
تعديلات آمنة
احفظ نقطة تحقق قبل تغييرات كبيرة لتتمكن من التراجع بثقة.
للمترجم وظيفتان مختلفتان للغاية. أولًا، يجب أن يفهم شفرتك المصدرية. ثانيًا، يجب أن يولد شفرة آلة يستطيع معالج معين تنفيذها. المعالِجات الخلفية في LLVM تركز على الوظيفة الثانية.
ما الذي يفعله المعالج الخلفي فعليًا
فكر في LLVM IR كـ "وصفة عالمية" لما يجب أن يفعله البرنامج. المعالج الخلفي يحوّل تلك الوصفة إلى التعليمات الدقيقة لعائلة معالجات معينة — x86-64 لأغلب الحواسيب المكتبية والخوادم، ARM64 للهواتف والحواسيب المحمولة الأحدث، أو أهداف متخصصة مثل WebAssembly.
عمليًا، المعالج الخلفي مسؤول عن:
- اختيار التعليمات: مطابقة عمليات الـ IR لتعليمات المعالج الحقيقية
- تخصيص المسجلات: اختيار القيم التي توضع في مسجلات سريعة مقابل الذاكرة
- الجدولة: ترتيب التعليمات بحيث ينفذها المعالج بأقصى كفاءة
- إخراج التجميع/الملف الصوتي: إصدار الشفرة التي يفهمها الرابط ونظام التشغيل
لماذا تسهّل البنية المشتركة دعم عتاد جديد
بدون نواة مشتركة، ستحتاج كل لغة لإعادة تنفيذ كل هذا لكل معالج تريد دعمه — عمل هائل وعبء صيانة دائم.
LLVM يقلب هذا: الواجهات الأمامية تنتج LLVM IR مرة واحدة، والمعالِجات الخلفية تتكفّل بالطريق الأخير لكل هدف. إضافة دعم لمعالج جديد عادةً ما تعني كتابة معالج خلفي واحد (أو توسيع أحدهم)، وليس إعادة كتابة كل مترجم في الوجود.
قابلية النقل للفرق التي تنشر عبر منصات متعددة
للمشروعات التي يجب أن تعمل على Windows/macOS/Linux، على x86 وARM، أو حتى داخل المتصفح، نموذج المعالِجات الخلفية في LLVM ميزة عملية. يمكنك الحفاظ على قاعدة شفرة واحدة وسلسلة بناء واحدة إلى حد كبير، ثم الاستهداف باختيار معالج خلفي مختلف (أو بناء عابر للمنصة).
هذه القابلية للنقل سبب في انتشار LLVM: الأمر ليس فقط عن السرعة — بل أيضًا عن تجنّب عمل مترجمات مكررة لكل منصة مما يبطئ الفرق.
Clang: حيث يشعر العديد من المطورين بـ LLVM لأول مرة
Clang هو الواجهة الأمامية للغات C وC++ وObjective-C التي تتصل بـ LLVM. إذا كان LLVM المحرك المشترك الذي يمكنه التحسين وتوليد شفرة الآلة، فـ Clang هو الجزء الذي يقرأ ملفات المصدر، يفهم قواعد اللغة، ويحوّل ما كتبته إلى شكل يستطيع LLVM العمل عليه.
لماذا لفتت Clang الانتباه
العديد من المطورين لم يكتشفوا LLVM من خلال قراءة أوراق بحثية للمترجمات — بل من خلال تجربة استبدال المترجم وشعورهم أن الملاحظات تحسّنت فجأة.
معروف عن تشخيصات Clang أنها أكثر قابلية للقراءة وأكثر تحديدًا. بدلًا من أخطاء غامضة، غالبًا ما يشير إلى التوكن المحدد الذي سبّب المشكلة، يعرض السطر المعني، ويشرح ما الذي كان متوقَّعًا. هذا مهم في العمل اليومي لأن حلقة "ترجمة، إصلاح، تكرار" تصبح أقل إحباطًا.
كما يقدّم Clang واجهات واضحة وموثقة (لا سيما عبر libclang ونظام أدوات Clang الأوسع). هذا سهّل على المحررات وبيئات التطوير المدمجة وباقي أدوات المطورين دمج فهم لغة عميق دون إعادة اختراع محلل C/C++.
كيف يظهر في سير العمل اليومي
بمجرد أن يتمكن أداة ما من تحليل شفرتك بدقة، تبدأ بالحصول على ميزات تشعر أنها أقل تحرير نصي وأكثر العمل مع برنامج منظم:
- تنقّل دقيق في الشفرة ("الانتقال إلى التعريف"، "العثور على المراجع") حتى في مشاريع C++ الكبيرة والمعقّدة
- دعم إعادة هيكلة يفهم الرموز والنطاقات، لا مجرد بحث/استبدال
- تلميحات داخلية وإصلاحات سريعة مستندة إلى البنية الحقيقية والنوع
لهذا غالبًا ما تكون Clang نقطة التماس الأولى مع LLVM: من خلالها تأتي تحسينات تجربة المطور العملية. حتى لو لم تفكر أبدًا في LLVM IR أو المعالجات الخلفية، فإنك تستفيد عندما يصبح إكمال الكود أذكى، وفحوصاتك الساكنة أدق، وأخطاء البناء أسهل للتعامل معها.
لماذا تبني العديد من اللغات الحديثة على LLVM
LLVM جذاب لفرق اللغات لسبب بسيط: يتيح لهم التركيز على اللغة بدل قضاء سنوات في إعادة اختراع مترجم مُحسن كامل.
وقت وصول أسرع إلى السوق
بناء لغة جديدة يتطلب بالفعل المحلل، فحص الأنواع، التشخيصات، أدوات الحزم، التوثيق، ودعم المجتمع. إذا كان عليك أيضًا إنشاء مُحسّن إنتاجي ومولّد شفرة ودعم منصات من الصفر، يتأخر الإطلاق — أحيانًا لسنوات.
LLVM يوفر نواة ترجمة جاهزة: تخصيص المسجلات، اختيار التعليمات، تمريرات تحسين ناضجة، وأهداف شائعة لمعالجات. يمكن للفرق توصيل واجهة أمامية تخفض لغتها إلى LLVM IR، ثم الاعتماد على خط الأنابيب القائم لإنتاج شفرات محلية لنظم macOS وLinux وWindows.
أداء عالٍ (بدون "بطولات")
محسّنات LLVM والمعالِجات الخلفية نتيجة هندسة طويلة الأمد واختبار متواصل في العالم الحقيقي. هذا يترجم إلى أداء أساسي قوي للغات التي تتبنّاه — غالبًا جيد بما فيه الكفاية مبكرًا، وقابل للتحسّن مع تحسّن LLVM.
لهذا بنت عدة لغات معروفة حول LLVM:
- Swift يستخدم LLVM لتوليد ثنائيات محلية مُحسّنة على منصات Apple.
- Rust يعتمد على LLVM لتوليد الشفرة ودعم معماريات عديدة.
- Julia يستخدم LLVM لتمكين شفرة عددية سريعة، بما في ذلك الترجمة أثناء التشغيل للحالات المتخصصة.
ليست كل لغة بحاجة إلى LLVM
اختيار LLVM هو مقايضة، ليس مطلبًا. بعض اللغات تُعطي أولوية للثنائيات صغيرة جدًا، أو تجميع فائق السرعة، أو تحكم صارم في سلسلة الأدوات. أخرى لديها مترجمات راسخة (مثل أنظمة مبنية على GCC) أو تفضّل مولدات أبسط.
LLVM شائع لأنه خيار افتراضي قوي — ليس لأنه المسار الوحيد الصحيح.
الترجمة أثناء التشغيل والوقت الفعلي: حلقات تغذية راجعة سريعة
حوّل المشاركة إلى أرصدة
احصل على أرصدة بمشاركة ما تبنيه أو بدعوة الآخرين لتجربة Koder.ai.
"الترجمة أثناء التشغيل" (JIT) أسهل طريقة لتصوره هي الترجمة أثناء التشغيل. بدلًا من ترجمة كل الشفرة مسبقًا إلى ملف نهائي، ينتظر محرك JIT حتى يُطلب جزء من الشفرة، ثم يترجمه على الفور — غالبًا باستخدام معلومات وقت التشغيل الفعلية (مثل الأنواع والحجوم) لاتخاذ قرارات أفضل.
لماذا قد تبدو JIT سريعة جدًا
لأنك لا تحتاج ترجمة كل شيء مقدمًا، يمكن لأنظمة JIT أن توفر تغذية راجعة سريعة للعمل التفاعلي. تكتب أو تولد جزءًا من الشفرة، تشغّله فورًا، والنظام يترجم فقط ما هو ضروري الآن. إذا تكرّر تشغيل نفس الشفرة، يمكن للـ JIT تخزين النتيجة المترجمة أو إعادة ترجمة المقاطع "الساخنة" بتكثيف.
أين يساعد التجميع في وقت التشغيل عمليًا
JIT يتألق حين تكون الأحمال ديناميكية أو تفاعلية:
- قشور التفاعل (REPLs) والمذكّرات: تقييم مقاطع على الفور مع الحصول على تنفيذ بسرعات قريبة من المحلية للحلقات الثقيلة.
- الإضافات والملحقات: التطبيقات يمكنها تحميل شفرة المستخدم في وقت التشغيل وتجميعها لتتماشى مع معالج المضيف.
- أحمال ديناميكية: عندما تتباين المدخلات كثيرًا، يمكن للملف الشخصي في وقت التشغيل توجيه أي المسارات تستحق التحسين.
- الحوسبة العلمية: يمكن تجميع نواة مولدة (لحجم مصفوفة محدد، شكل نموذج، أو خاصية عتاد) عند الطلب.
دور LLVM (بدون مبالغة)
LLVM لا يجعل كل برنامج أسرع تلقائيًا، وليس JIT مكتملًا من تلقاء نفسه. ما يوفره هو حزمة أدوات: IR محدد جيدًا، مجموعات كبيرة من تمريرات التحسين، وتوليد الشفرة للعديد من المعالجات. المشاريع يمكنها بناء محركات JIT فوق هذه اللبنات، مع اختيار التوازن الصحيح بين زمن بدء التشغيل، الأداء الأقصى، والتعقيد.
الأداء، القابلية للتنبؤ، والمقايضات العملية
سلاسل أدوات مبنية على LLVM يمكن أن تنتج شفرات سريعة جدًا — لكن "السريع" ليس خاصية واحدة ثابتة. يعتمد ذلك على إصدار المترجم، المعالج المستهدف، إعدادات التحسين، وحتى ما تطلبه من المترجم أن يفترضه عن البرنامج.
لماذا "نفس المصدر، نتائج مختلفة" يحدث
مترجمان يمكنهما قراءة نفس مصدر C/C++ (أو Rust، Swift، إلخ) ومع ذلك يولدان شفرة آلة مختلفة بشكل ملحوظ. جانب من ذلك مقصود: لكل مترجم مجموعة تمريرات تحسينه، وخوارزميات التقدير، وإعداداته الافتراضية. حتى داخل LLVM، قد يتخذ Clang 15 وClang 18 قرارات داخلية مختلفة بشأن الإدماج، أو تحويل الحلقات، أو جدولة التعليمات.
قد ينشأ أيضًا عن السلوك غير المحدد أو السلوك غير الموثّق في اللغة. إذا اعتمد برنامجك بطريق الخطأ على شيء لا تضمنه المواصفة (مثل فيضان الأعداد الصحيحة الموقعة في C)، فقد "يحسن"ه مترجم مختلف أو علم مختلف بطريقة تغير النتائج.
الحتمية، بنية التصحيح، وبناء الإصدار
يتوقع الناس غالبًا أن يكون التجميع حتميًا: نفس المدخلات تعطي نفس المخرجات. عمليًا، ستقترب لكن ليس دائمًا نفس الثنائيات عبر البيئات. مسارات البناء، الطوابع الزمنية، ترتيب الربط، بيانات التوجيه، وخيارات LTO كلها يمكن أن تؤثر على المنتج النهائي.
التمييز الأكبر والعملي هو النسخ Debug مقابل Release. عادةً ما تعطّل نسخ التصحيح العديد من التحسينات للحفاظ على إمكانية تتبع التنفيذ خطوة بخطوة ومسارات مكدس قابلة للقراءة. نسخ الإصدار تفعّل تحويلات مكثفة قد تعيد ترتيب الشفرة، وتقوم بإدماج الدوال، وتزيل المتغيرات — رائعة للأداء، لكن أصعب في التصحيح.
نصيحة عملية: قِس، ولا تفترض
عامل الأداء كمشكلة قياس:
- اجْرِ اختبارات على عتاد ممثل ومجموعات بيانات واقعية.
- سخّن الذاكرة المؤقتة وشغّل تكرارات متعددة.
- قارن البنايات باستخدام أعلام صريحة (مثل تغيير
-O2مقابل-O3، تفعيل/تعطيل LTO، أو اختيار هدف مع-march).
تغييرات أعلام بسيطة يمكن أن تغيّر الأداء إلى أي اتجاه. أفضل منهجية: ضع فرضية، قِسها، واحتفظ بمقاييس قريبة مما يستخدمه عملاؤك فعليًا.
أدوات تتجاوز الترجمة: التحليل، التصحيح، والسلامة
اعمل عبر المنصات
أنشئ تطبيق جوال بـFlutter بجانب أجزاء الويب والخادم.
غالبًا ما توصف LLVM بأنها حزمة أدوات مترجم، لكن العديد من المطورين يشعرون بتأثيرها من خلال أدوات تجلس حول عملية الترجمة: المحللات، المصححات، وفحوصات الأمان التي يمكن تفعيلها أثناء البناء والاختبار.
التحليل والتجهيز كـ "إضافات"
بسبب أن LLVM يعرّض تمثيلًا وسيطًا محددًا جيدًا وخط تمرير، فمن الطبيعي بناء خطوات إضافية تفحص أو تعيد كتابة الشفرة لغرض غير الأداء. قد تُدرج تمريرة عدادات للتجميع، أو تميّز عمليات الذاكرة المشبوهة، أو تجمع بيانات التغطية.
النقطة الأساسية أن هذه الميزات يمكن دمجها دون أن يعيد كل فريق لغة نفس السباكة.
المُنقّحات (Sanitizers): التقاط الأخطاء قرب المصدر
شعبية Clang وLLVM أدّت إلى انتشار عائلة "المنقّحات" التي تُدرج أدوات زمن تشغيل تكشف فئات شائعة من الأخطاء أثناء الاختبار — مثل وصول خارج النطاق، استخدام بعد الحرّ، سباقات البيانات، وأنماط السلوك غير المحدد. ليست دروعًا سحرية، وعادةً ما تبطئ البرامج، لذا تُستخدم أساسًا في CI والاختبارات قبل الإصدار. لكن عند تشغيلها، غالبًا ما تشير إلى موقع مصدر دقيق وشرح مقروء، وهو ما تحتاجه الفرق لتتبع الأخطاء المتقطعة.
تشخيصات أفضل = انضمام أسرع للأشخاص الجدد
جودة الأدوات تتعلق أيضًا بالتواصل. تحذيرات واضحة، رسائل خطأ قابلة للتنفيذ، ومعلومات تصحيح متناسقة تقلل عامل "الغموض" للمنضمين الجدد. عندما يشرح نظام الأدوات ما حدث وكيف تصلحه، يقضي المطورون وقتًا أقل في حفظ فروق المترجم والمزيد في فهم قاعدة الشفرة.
LLVM لا يضمن تشخيصات أو سلامة مثالية بمفرده، لكنه يوفر أساسًا مشتركًا يجعل بناء هذه الأدوات الموجهة للمطورين عمليًا وقابلاً للمشاركة عبر مشاريع كثيرة.
متى تستخدم LLVM (ومتى لا)
فكر في LLVM كـ "ابنِ مترجَمك وأدواتك". هذه المرونة سبب قوته، لكنها أيضًا سبب أنه ليس الحل المناسب لكل مشروع.
متى يكون LLVM مناسبًا جدًا
LLVM يبرع عندما تريد إعادة استخدام هندسة مترجم متقدمة بدل إعادة اختراعها.
إذا كنت تبني لغة برمجة جديدة، يمكن أن يمنحك LLVM خط أنابيب تحسين مثبتًا، توليدًا ناضجًا للشفرة للعديد من المعالجات، وطريقًا لدعم تصحيح جيد.
إذا كنت تنشر تطبيقات متعددة المنصات، فإن نظام المعالِجات الخلفية في LLVM يقلل العمل اللازم لاستهداف معماريات مختلفة. ستركز على لغتك أو منطق المنتج بدل كتابة مولدات شفرة منفصلة.
إذا كان هدفك أدوات المطور — لنترز، التحليل الساكن، تنقل الشفرة، إعادة الهيكلة — فإن LLVM والنظام المحيط به أساس قوي لأن المترجم بالفعل "يفهم" بنية الشفرة والأنواع.
متى قد يكون مبالغًا فيه
LLVM قد يكون ثقيلًا إذا كنت تعمل على أنظمة مدمجة صغيرة حيث حجم البناء، الذاكرة، وزمن التجميع مقيدون بشدة.
قد لا يكون مناسبًا أيضًا لخطوط أنابيب متخصصة جدًا حيث لا تريد تحسينات عامة، أو حيث لغتك أقرب إلى DSL ثابت مع تحويل مباشر إلى شفرة الآلة بسيطة.
قائمة فحص بسيطة
اطرح هذه الأسئلة الثلاثة:
- هل نحتاج لاستهداف منصات/معالجات متعددة الآن أو قريبًا؟
- هل نستفيد من التحسينات والمعلومات التصحيحية الموجودة بدل بناءها بأنفسنا؟
- هل نريد مسارًا بيئيًا (أدوات، تكامل، توظيف) أكثر من مترجم بسيط ومُخصّص؟
إن أجبت بـ"نعم" على معظمها، فعادةً ما يكون LLVM رهانًا عمليًا. إن رغبت بالحد الأدنى من المترجم الذي يحل مشكلة ضيقة جدًا، فقد يفوز نهج أخف.
ملاحظة عملية لفرق المنتج: فوائد LLVM دون أن تصبحوا خبراء مترجمات
معظم الفرق لا تريد "تبنّي LLVM" كمشروع. يريدون نتائج: بناءات عبر المنصات، ثنائيات سريعة، تشخيص جيد، وأدوات موثوقة.
لهذا السبب منصات مثل Koder.ai تبدو مثيرة في هذا السياق. إذا كان سير عملك يتجه أكثر نحو الأتمتة عالية المستوى (التخطيط، توليد البنى، التكرار في حلقة ضيقة)، فستستفيد من LLVM غير مباشرًا عبر سلسلة الأدوات تحت الغطاء — سواء كنت تبني تطبيق React، خلفية Go مع PostgreSQL، أو تطبيق موبايل Flutter. نهج Koder.ai القائم على الدردشة لـ "الترميز بالإيقاع" يركّز على إطلاق المنتج أسرع، بينما بنية المترجم الحديثة (LLVM/Clang وما حولها، حيث ينطبق) تواصل العمل غير البهيئ للّفت الأنظار: التحسين، التشخيص، والقابلية للنقل في الخلفية.