14 مايو 2025·8 دقيقة
لماذا نادرًا ما تنتمي أحمال OLTP و OLAP إلى قاعدة بيانات واحدة
تعرف لماذا خلط الأحمال المعاملاتية (OLTP) والتحليلية (OLAP) في قاعدة بيانات واحدة قد يبطئ التطبيقات، يزيد التكاليف، ويعقّد العمليات — وماذا تفعل بدلاً من ذلك.
تعرف لماذا خلط الأحمال المعاملاتية (OLTP) والتحليلية (OLAP) في قاعدة بيانات واحدة قد يبطئ التطبيقات، يزيد التكاليف، ويعقّد العمليات — وماذا تفعل بدلاً من ذلك.
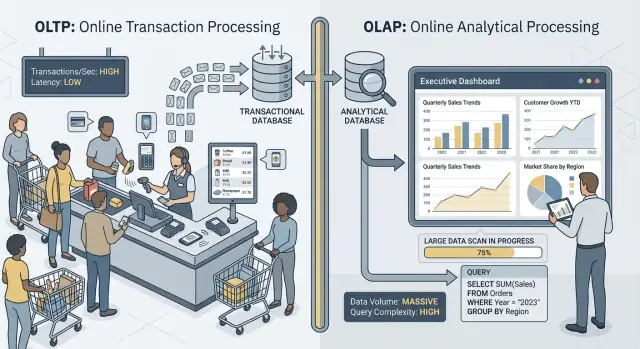
عندما يتحدث الناس عن “OLTP” و “OLAP” فهم يتكلمون عن طريقتين مختلفتين جدًا لاستخدام قاعدة البيانات.
OLTP (Online Transaction Processing) هو الحمل المسؤول عن الإجراءات اليومية التي يجب أن تكون سريعة وصحيحة في كل مرة. فكر: “احفظ هذا التغيير فورًا.”
المهام النموذجية في OLTP تشمل إنشاء طلب، تحديث المخزون، تسجيل دفعة، أو تغيير عنوان عميل. هذه العمليات عادة صغيرة (بضع صفوف)، متكررة، ويجب أن ترد في مللي ثوانٍ لأن شخصًا أو نظامًا آخر ينتظر.
OLAP (Online Analytical Processing) هو الحمل المستخدم لفهم ماذا حدث ولماذا. فكر: “امسح الكثير من البيانات وخلاصتها.”
المهام النموذجية في OLAP تشمل لوحات المعلومات، تقارير الاتجاهات، تحليل المجموعات، التنبؤات، وأسئلة "قطّع وفلتر" مثل: “كيف تغيرت الإيرادات بحسب المنطقة وفئة المنتج خلال الـ 18 شهرًا الماضية؟” هذه الاستعلامات غالبًا تقرأ صفوفًا كثيرة، تقوم بتجميعات ثقيلة، وقد تستغرق ثوانٍ (أو دقائق) دون أن تكون "خاطئة".
الفكرة الأساسية بسيطة: OLTP يُحسّن للكتابة السريعة والمتسقة والقراءات الصغيرة، بينما OLAP يُحسّن للقراءات الكبيرة والعمليات الحسابية المعقدة. نظرًا لاختلاف الأهداف، فإن إعدادات قاعدة البيانات، الفهارس، تخطيط التخزين، وطريقة التوسعة عادة ما تكون مختلفة أيضًا.
كما يجب ملاحظة الصياغة: نادراً، لا أبدًا. بعض الفرق الصغيرة يمكنها مشاركة قاعدة بيانات واحدة لفترة، خاصة مع حجم بيانات متواضع وانضباط استعلامي. الأقسام التالية تغطي ما الذي يتعطل أولًا، أنماط الفصل الشائعة، وكيف تنقل التقارير بعيدًا عن الإنتاج بأمان.
قد يستخدم كلا النظامين "SQL"، لكنهما مُحسّنان لوظائف مختلفة—وهذا يظهر في ما يعتبره كل منهما نجاحًا.
أنظمة OLTP (المعاملات) تشغل العمليات اليومية: تدفقات الدفع، تحديثات الحساب، الحجوزات، أدوات الدعم. الأولويات واضحة:
النجاح يُقاس غالبًا بمقاييس الكمون مثل p95/p99 زمن الطلب، معدل الأخطاء، وكيف يتصرف النظام تحت ذروة التزامن.
أنظمة OLAP (التحليلات) تجيب عن أسئلة مثل "ما الذي تغير هذا الربع؟" أو "أي شريحة انخفضت بعد التسعير الجديد؟" هذه الاستعلامات غالبًا:
النجاح هنا يشبه أكثر معدل استعلامات معالج، زمن الوصول للرؤى، والقدرة على تشغيل استعلامات معقدة دون ضبط يدوي لكل تقرير.
عندما تُجبر قاعدة بيانات على خدمة كلا الأحمال، تطلب منها أن تكون ممتازة في المعاملات الصغيرة عالية الحجم وفي المسوح الكبيرة الاستكشافية في نفس الوقت. النتيجة عادة تسوية: OLTP يحصل على كمون غير متوقع، OLAP يُقيّد لحماية الإنتاج، والفرق تتجادل حول من "مسموح" له الاستعلامات. الأهداف المختلفة تستحق بالعادة أنظمة منفصلة ومقاييس نجاح منفصلة.
عندما تعمل OLTP (معاملات التطبيق اليومي) و OLAP (التقارير والتحليلات) على نفس قاعدة البيانات، فإنهما يتنافسان على نفس الموارد المحدودة. النتيجة ليست "تقارير أبطأ" فقط. في كثير من الأحيان تكون: دفعات أبطأ، تسجيلات دخول متوقفة، وتقطعات تطبيق غير متوقعة.
استعلامات التحليل تكون طويلة وثقيلة: انضمامات عبر جداول كبيرة، تجميعات، فرز وتجميع. يمكن أن تحتكر أنوية CPU والذاكرة اللازمة لعمليات الانضمام والفرز.
في المقابل، استعلامات المعاملات عادة صغيرة لكنها حساسة للزمن. إذا امتلأت CPU أو ضغطت الذاكرة واضطرت إلى طرد بيانات، تبدأ تلك الاستعلامات الصغيرة بالانتظار خلف الكبيرة—حتى لو كل معاملة تحتاج بضع مللي ثوانٍ فقط من العمل الفعلي.
التحليلات غالبًا تُحدث مسوحًا كبيرة للجدول وتقرأ صفحات كثيرة بشكل تسلسلي. أحمال OLTP تفعل العكس: قراءات عشوائية صغيرة plus كتابات مستمرة للفهارس والسجلات.
جمعهما يجعل نظام التخزين يتعامل مع أنماط وصول متضادة. الكاشات التي كانت تساعد OLTP قد تُغسَل بمسوح التحليل، وزمن الكتابة قد يقفز عندما يكون القرص مشغولًا ببث بيانات للتقارير.
قليل من المحللين الذين يشغلون استعلامات واسعة قد يحتجزون الاتصالات لدقائق. إذا كان التطبيق يستخدم تجمعًا ثابت الحجم، تنتظر الطلبات اتصالًا حرًا. هذا التأثير الطابوري يمكن أن يجعل النظام يبدو معطّلًا: المتوسط قد يبدو مقبولًا، لكن الكمون في الذيل (p95/p99) يصبح مؤلمًا.
من الخارج يظهر ذلك كمهلات، تدفقات دفع بطيئة، نتائج بحث متأخرة، وسلوك غير مستقر—غالبًا "فقط أثناء التقارير" أو "فقط في نهاية الشهر". فريق التطبيق يرى أخطاء؛ فريق التحليلات يرى استعلامات بطيئة؛ المشكلة الحقيقية هي التنافس المشترك تحت السطح.
OLTP و OLAP لا يستخدما قاعدة البيانات "بنفس الطريقة"—هما يكافئان تصاميم فعلية معاكسة. عندما تحاول تلبية كليهما في مكان واحد، عادة تحصل على حل وسط مكلف وما زال دون أداء جيد.
حمل المعاملات يُهيمن عليه استعلامات قصيرة تمس شريحة صغيرة من البيانات: جلب طلب واحد، تحديث صف مخزون واحد، سرد آخر 20 حدثًا لمستخدم واحد.
هذا يدفع مخططات OLTP نحو تخزين صفّي (row-oriented) وفهارس تدعم عمليات البحث النقطية ونطاقات صغيرة (غالبًا على المفاتيح الأساسية، المفاتيح الأجنبية، وبعض الفهارس الثانوية ذات القيمة العالية). الهدف هو كمون متوقع ومنخفض—خصوصًا للكتابات.
حمل التحليلات غالبًا يحتاج قراءة صفوف كثيرة وعدد قليل من الأعمدة: "الإيرادات بالأسبوع والمنطقة"، "معدل التحويل بالحملة"، "أفضل المنتجات من حيث الهامش".
أنظمة OLAP تستفيد من التخزين العمودي (لقراءة الأعمدة الضرورية فقط)، التقسيم (لتقليص النطاقات بسرعة)، والتجميع المسبق (materialized views، rollups، جداول ملخّصة) حتى لا تعيد التقارير حساب نفس المجاميع مرارًا.
رد فعل شائع هو إضافة فهارس حتى تكون كل لوحة سريعة. لكن كل فهرس إضافي يزيد تكلفة الكتابة: الإدراجات، التحديثات، والحذوفات يجب أن تُحدّث هياكل أكثر. كما يزيد التخزين ويبطئ مهام الصيانة مثل vacuum، إعادة الفهرسة، والنسخ الاحتياطية.
تختار قواعد البيانات خطط التنفيذ بناءً على إحصاءات—تقديرات عدد الصفوف المطابقة لفلتر، مدى انتقائية الفهرس، وتوزيع البيانات. تتغير بيانات OLTP باستمرار. مع تغيّر التوزيعات، يمكن أن تنحرف الإحصاءات، وقد يختار المخطط خطة كانت ممتازة لبيانات الأمس لكنها بطيئة اليوم.
أضف استعلامات OLAP الثقيلة التي تمسح وتربط جداول كبيرة، وستحصل على مزيد من التغيّر: "الخطة الأفضل" تصبح أصعب في التنبؤ، والضبط لأحد الأحمال غالبًا ما يضر الآخر.
حتى لو قاعدة البيانات "تدعم التزامن"، فإن خلط التقارير الثقيلة مع المعاملات الحية يخلق تباطؤات دقيقة يصعب التنبؤ بها—وأصعب في شرحها لعميل ينظر إلى شاشة تحميل عند الدفع.
استعلامات نمط OLAP غالبًا تمسح الكثير من الصفوف، تربط جداول متعددة، وتستغرق ثوانيًا أو دقائق. خلال ذلك قد تحتجز أقفالًا (مثلًا على كائنات المخطط، أو عندما تحتاج إلى فرز/تجميع في هياكل مؤقتة) وغالبًا تزيد التنافس على الأقفال بشكل غير مباشر عن طريق إبقاء العديد من الصفوف "قيد اللعب".
حتى مع MVCC (التحكم بالتزامن متعدد الإصدارات)، يجب على قاعدة البيانات تتبع نسخ متعددة من نفس الصف حتى لا يحجب القراء والكتّاب بعضهم البعض. هذا يساعد، لكنه لا يلغي التنافس—خصوصًا عندما تمسس الاستعلامات جداول ساخنة تُحدّث باستمرار.
MVCC يعني أن نسخ الصفوف القديمة تبقى حتى يمكن لقاعدة البيانات إزالتها بأمان. تقرير طويل قد يبقي لقطة قديمة مفتوحة، مما يمنع التنظيف من استرجاع المساحة.
هذا يؤثر على:
النتيجة ضربة مزدوجة: التقارير تجعل قاعدة البيانات تعمل أكثر وتجعل النظام أبطأ مع الوقت.
أدوات التقارير غالبًا تطلب عزلًا أقوى (أو تعمل عن غير قصد في معاملة طويلة). العزل الأعلى قد يزيد الانتظار على الأقفال ويزيد كمية إصدار النسخ التي يجب أن يديرها المحرك. من جانب OLTP ترى هذا كارتفاعات غير متوقعة: معظم الطلبات تكتب بسرعة، ثم بعضاً فجأة يتأخر.
في نهاية الشهر، تجري المالية استعلام "الإيرادات بحسب المنتج" الذي يمسح الطلبات وبنود السطر للشهر بأكمله. بينما يجري، ما تزال كتابات الطلبات تُقبل، لكن الـ vacuum لا يستطيع استرجاع النسخ القديمة والمؤشرات ترتخي. يبدأ API الطلبات برؤية مهلات متقطعة—ليس لأنه "معطل"، بل لأن التنافس وصيانة التنظيف تدفع الكمون بهدوء عبر حدودك.
أنظمة OLTP تعيش وتموت من قابلية التنبؤ. الدفع أو تذكرة الدعم ليست "مقبولة إلى حد ما" لو كانت سريعة 95% من الوقت—المستخدمون يلاحظون اللحظات البطيئة. أما OLAP فغالبًا ما يكون متقطّعًا: بضعة استعلامات ثقيلة يمكن أن تكون هادئة لساعات ثم تستهلك CPU، الذاكرة، وI/O فجأة.
حركة التحليلات تميل للتجمع حول روتينيات:
بينما حركة OLTP عادة أكثر ثباتًا. عندما يتشارك الحملان نفس القاعدة، تتحول ذروة التحليلات إلى كمون غير متوقع للمعاملات—مهلات، صفحات أبطأ، وإعادة محاولات تزيد الحمولة.
يمكنك تقليل الضرر بإجراءات مثل تشغيل التقارير ليلاً، تحديد التزامن، فرض مهلات للعبارات، أو وضع حدود تكلفة للاستعلام. هذه حواجز قيمة، خاصة لـ "التقارير على الإنتاج".
لكنها لا تزيل التوتر الأساسي: استعلامات OLAP مصممة لاستخدام الكثير من الموارد للإجابة على أسئلة كبيرة، بينما OLTP يحتاج شرائح موارد صغيرة وسريعة طوال اليوم. اللحظة التي يتسلل فيها تحديث لوحة مفاجئ أو استعلام مخصص أو تقرير معاد تعبئته، تعود القاعدة المشتركة لتتعرض.
على بنية مشتركة، يمكن لمستخدم أو مهمة تحليلية "صاخبة" أن تحتجز الكاش، تشبع القرص، أو تضغط جدولة CPU—دون أن تفعل شيئًا خاطئًا. يصبح حمل OLTP ضحية عرضية، والأصعب أن الأعطال تبدو عشوائية: ارتفاعات في الكمون بدلًا من أخطاء واضحة وقابلة للتكرار.
خلط OLTP (المعاملات) و OLAP (التحليلات) لا يخلق صداع الأداء فقط—بل يجعل العمليات اليومية أصعب. تصبح قاعدة البيانات صندوق "الكل شيء"، وكل مهمة تشغيلية ترث مخاطر الأحمال معًا.
جداول التحليلات تميل للنمو بعرض وسرعة (تاريخ أطول، أعمدة أكثر، تجميعات). هذا الحجم الإضافي يغير قصة الاسترداد.
نسخة احتياطية كاملة تستغرق وقتًا أطول، تستهلك مساحة أكثر، وتزيد احتمال تفويت نافذة النسخ الاحتياطي. الاستعادة أسوأ: عندما تحتاج لاسترداد بسرعة، تستعيد ليس فقط بيانات المعاملات التي يحتاجها التطبيق، بل أيضًا مجموعات تحليلية كبيرة ليست ضرورية لتشغيل العمل. اختبارات التعافي من الكوارث تأخذ وقتًا أطول، فتحدث أقل—العكس تمامًا مما تريد.
نمو المعاملات عادة متوقع: مزيد من العملاء، المزيد من الطلبات، المزيد من الصفوف. نمو التحليلات غالبًا متقطع: لوحة جديدة، سياسة احتفاظ جديدة، أو فريق يقرر الاحتفاظ "لسنة إضافية" من الأحداث الخام.
عندما يعيش كلاهما معًا، يصعب الإجابة:
تؤدي هذه اللايقين إلى زيادة الحجز (دفع مقابل سعة فراغ لا تحتاجها) أو نقصه (انقطاعات مفاجئة).
في قاعدة بيانات مشتركة، قد تتحول استعلام بريء إلى حادث. ستنتهي بإضافة حواجز مثل مهلات الاستعلام، حصص الأحمال، نوافذ جدولة التقارير، أو قواعد إدارة الأحمال. هذه مفيدة، لكنها هشة: التطبيق والمحللون الآن يتنافسون على نفس الحدود، وتغيير سياسة لمجموعة واحدة قد يكسر الأخرى.
التطبيقات عادة تحتاج أذونات ضيقة ومحددة. المحللون يحتاجون غالبًا وصول قراءة واسع للتحقق والاستكشاف. وضع كلاهما في قاعدة واحدة يزيد الضغط لمنح صلاحيات أوسع "فقط لكي تعمل التقارير"، مما يوسع مجال الضرر من الأخطاء ويزيد عدد الأشخاص القادرين على رؤية بيانات تشغيل حساسة.
محاولة تشغيل OLTP و OLAP في نفس القاعدة تبدو أرخص—حتى تبدأ بالتوسعة. المشكلة ليست الأداء فقط. الطريقة الصحيحة لتوسعة كل حمل تدفعك نحو بنية تحتية مختلفة، وتجميعهما يفرض تسويات مكلفة.
أنظمة المعاملات مقيدة بالكتابات: تحديثات صغيرة كثيرة، كمون صارم، وذروات يجب استيعابها فورًا. توسعة OLTP عادة تعني توسيعًا رأسيًا (CPU أكبر، أقراص أسرع، ذاكرة أكثر) لأن الأحمال الكاتبة لا تتفرّع بسهولة.
عندما تصل للحدود الرأسية، تفكر في الشاردينغ أو أنماط توسعة كتابة أخرى. هذا يضيف عبء هندسي وغالبًا يتطلب تغييرات دقيقة في التطبيق.
أحمال التحليلات تتوسع بشكل مختلف: مسوح طويلة، تجميعات ثقيلة، ومعدل قراءة عالٍ. أنظمة OLAP عادة توسع بإضافة قدرة معالجة موزعة، والعديد من الإعدادات الحديثة تفصل التخزين عن المعالجة حتى تتمكن من زيادة قوة الاستعلام دون تكرار البيانات.
إذا شاركت OLAP قاعدة OLTP، لا يمكنك توسيع التحليلات باستقلالية. توسع القاعدة بأكملها—حتى لو كانت المعاملات جيدة.
للحفاظ على سرعة المعاملات أثناء تشغيل التقارير، يفرط الفرق في تجهيز قاعدة الإنتاج: رأس مال CPU إضافي، تخزين عالي الأداء، وحالات أكبر "احتياطًا". هذا يعني أنك تدفع أسعار OLTP لتشغيل سلوك OLAP.
الفصل يقلل الإفراط في التجهيز لأن كل نظام يُضبط لحمله: OLTP للكتابات قليلة الكمون، OLAP للقراءات الثقيلة. النتيجة غالبًا أرخص إجمالًا—حتى لو أصبحت لديك "نظامان"—لأنك تتوقف عن شراء سعة معاملات متميزة لتشغيل تقارير على الإنتاج.
معظم الفرق تفصل حمل المعاملات (OLTP) عن حمل التحليلات (OLAP) بإضافة نظام ثاني موجه للقراءة بدلاً من إجبار قاعدة واحدة على خدمتيْن.
خطوة شائعة أولى هي نسخة قراءة (follower) من قاعدة OLTP، حيث تُشغل أدوات BI الاستعلامات.
المزايا: تغييرات تطبيقية قليلة، SQL مألوف، إعداد سريع.
العيوب: ما زالت نفس المحرك والمخطط، لذا تقارير ثقيلة يمكن أن تشبع CPU/I/O على النسخة؛ بعض التقارير تتطلب ميزات غير متاحة على النسخ؛ وتأخر النسخ يعني أن الأرقام قد تتأخر دقائق أو أكثر. التأخر أيضًا يخلق محادثات مربكة "لماذا لا تتطابق مع الإنتاج؟" أثناء الحوادث.
أنسب: فرق صغيرة، حجم بيانات متواضع، "قرب-الزمن-الفعلي" مرن وليس حرجًا، واستعلامات التقارير تحت تحكم.
هنا يبقى OLTP مُحسّنًا للكتابات والقراءات النقطية، بينما تنتقل التحليلات إلى مخزن بيانات (أو قاعدة عمودية) مصممة للمسوح، الضغط، والتجميعات الكبيرة.
المزايا: أداء OLTP متوقع، لوحات أسرع، تزامن أفضل للمحللين، وضبط تكلفة/أداء أوضح.
العيوب: تحتاج تشغيل نظام آخر وتحتاج نموذج بيانات ملائم للتحليلات (غالبًا مخطط نجمي).
أنسب: بيانات متزايدة، العديد من الجهات المعنية، تقارير معقدة، أو متطلبات كمون OLTP صارمة.
بدلاً من ETL الدوري، تقوم ببث التغييرات باستخدام CDC من سجل OLTP إلى المستودع (غالبًا مع ELT).
المزايا: بيانات أحدث بأثر أقل على OLTP، معالجة تزايدية أسهل، وقابلية تدقيق أفضل.
العيوب: أجزاء أكثر متحركة وتتطلب تعاملًا دقيقًا مع تغييرات المخطط.
أنسب: أحجام أكبر، حاجة للحداثة العالية، وفرق جاهزة لأنابيب البيانات.
نقل البيانات من قاعدة المعاملات (OLTP) إلى نظام التحليلات (OLAP) أقل عن "نسخ جداول" وأكثر عن بناء أنبوب موثوق ومنخفض الأثر. الهدف بسيط: تحصل التحليلات على ما تحتاجه دون تعريض حركة الإنتاج.
ETL (Extract, Transform, Load) يعني تنظيف وإعادة تشكيل البيانات قبل أن تصل للمخزن. هذا مفيد عندما يكون حساب المستودع مكلفًا، أو تريد تحكمًا شديدًا فيما يُخزن.
ELT (Extract, Load, Transform) يحمل بيانات شبه خام أولًا، ثم يتحول داخل المستودع. غالبًا أسرع للإعداد وأسهل للتطور: يمكنك الاحتفاظ بتاريخ "مصدر الحقيقة" وتعديل التحويلات عندما تتغير المتطلبات.
قاعدة عملية: إذا تغير منطق العمل كثيرًا، ELT يقلل إعادة العمل؛ إذا كانت الحوكمة تتطلب بيانات مُنقّاة فقط، ETL قد يكون مناسبًا.
Change Data Capture (CDC) يبث الإدخالات/التحديثات/الحذوفات من OLTP (غالبًا من سجل القاعدة) إلى نظام التحليلات. بدلًا من مسح الجداول الكبيرة مرارًا، يسمح CDC بنقل ما تغير فقط.
ما الذي يتيح:
الحداثة قرار تجاري مع تكلفة تقنية.
حدد اتفاقية مستوى خدمة واضحة (مثلاً: "البيانات متأخرة حتى 15 دقيقة") حتى يعرف أصحاب المصلحة معنى "حديث".
الأنابيب عادة تنكسر بهدوء—حتى يلاحظ أحدهم أن الأرقام مختلفة. أضف فحوصًا خفيفة لـ:
هذه الضمانات تحافظ على موثوقية OLAP بينما تحمي OLTP.
الاحتفاظ بـ OLTP و OLAP معًا ليس خطأً تلقائيًا. يمكن أن يكون خيارًا مؤقتًا معقولًا عندما التطبيق صغير، احتياجات التقارير محدودة، ويمكنك فرض حدود صارمة حتى لا تفاجئ التحليلات عملائك بدفعات بطيئة أو مهلات.
التطبيقات الصغيرة ذات تحليلات خفيفة وحدود استعلام صارمة غالبًا تعمل جيدًا على قاعدة واحدة—خصوصًا في البداية. المفتاح أن تكون صريحًا بشأن معنى "خفيف": عدد قليل من اللوحات، أحجام صفوف متواضعة، وسقف واضح لزمن التشغيل والتزامن.
لبعض التقارير المتكررة الضيقة، العروض المادية أو الجداول المجمعة يمكن أن تقلل تكلفة التحليلات. بدلًا من مسح المعاملات الخام، تحسب مسبقًا مجاميع يومية أو ملخّصات لكل زبون. هذا يبقي معظم الاستعلامات قصيرة ومتوقعة.
إذا كان المستخدمون التجاريون يقبلون أرقام مؤخرة، نوافذ تشغيل خارج الذروة تساعد. جدولة المهام الثقيلة ليلاً أو خلال فترات منخفضة، وفكر بدور تقارير مخصص بصلاحيات وقيود موارد أشد.
إذا رأيت ارتفاعًا في زمن المعاملات، حوادث متكررة أثناء تشغيل التقارير، استنفاد تجمع الاتصالات، أو قصص "استعلام واحد أسقط الإنتاج"، فقد تجاوزت المنطقة الآمنة. حينها، فصل القواعد (أو على الأقل استخدام نسخ قراءة) يتوقف عن كونه تحسينًا ويصبح جزءًا من روتين التشغيل الأساسي.
نقل التحليلات بعيدًا عن قاعدة الإنتاج أقل عن "إعادة كتابة كبيرة" وأكثر عن جعل العمل مرئيًا، تحديد أهداف، والترحيل بخطوات مسيطرة.
ابدأ بالأدلة، لا الافتراضات. استخرج قائمة:
اشمل التحليلات المخفية: SQL المخصص من أدوات BI، الصادرات المجدولة، وتنزيلات CSV.
دوّن الأهداف التي ستُحسّن لها:
هذا يمنع النقاشات مثل "إنه بطيء" مقابل "إنه مقبول" ويساعد على اختيار الهندسة الصحيحة.
اختر أبسط خيار يحقق الأهداف:
اضبط مراقبة لتأخر النسخ/الأنبوب، أوقات تشغيل اللوحات، ونفقات المستودع. أضف ميزانيات استعلام (مهلات، حدود تزامن)، واحتفظ بدليل حادث: ماذا تفعل عند تراجع الحداثة، زيادة الأحمال، أو اختلاف المقاييس الأساسية.
إذا كنت مبكرًا في المنتج وتتحرك بسرعة، المخاطرة الأكبر هي بناء التحليلات داخل نفس مسار قاعدة البيانات الخاص بالمعاملات (مثلاً، استعلامات لوحة تتحول بهدوء إلى "حيوية للإنتاج"). إحدى الطرق لتجنب ذلك هي تصميم الفصل مقدمًا—حتى لو بدأت بنسخة قراءة متواضعة—وأدخله في قائمة فحص الهندسة لديك.
منصات مثل Koder.ai يمكن أن تساعد هنا لأنك تستطيع تصميم جانب OLTP (تطبيق React + خدمات Go + PostgreSQL) وتخطيط حدود التقارير/المستودع في وضع التخطيط قبل الإطلاق. مع نمو المنتج، يمكنك تصدير الشيفرة المصدرية، تطوير المخطط، وإضافة مكونات CDC/ELT دون أن تتحول "التقارير على الإنتاج" إلى عادة دائمة.
OLTP (Online Transaction Processing) يتعامل مع العمليات اليومية مثل إنشاء الطلبات، تحديث المخزون، وتسجيل المدفوعات. يعطي أولوية لـزمن استجابة منخفض، تزامن عالي، والصحة أو الاتساق.
OLAP (Online Analytical Processing) يجيب عن أسئلة العمل عبر عمليات مسح وتجميع واسعة (لوحات معلومات، اتجاهات، تحليلات مجموعات). يعطي أولوية لـمعدل نقل أعلى، استعلامات مرنة، والتلخيص السريع على حساب زمن الاستجابة بالمللي ثانية.
لأن الأحمال تتنافس على نفس الموارد:
النتيجة غالبًا هي تقلبات غير متوقعة في p95/p99 لعمليات المستخدم الأساسية.
عادةً لا. إضافة فهارس لتسريع لوحات المعلومات غالبًا ما يعود بنتيجة عكسية لأن:
لأجل التحليلات، عادةً ما تعطي نتائج أفضل من خلال التقسيم (partitioning)، التخزين العمودي (columnar)، أو التجميع المسبق في نظام مخصص لـ OLAP.
MVCC يساعد القراء والكتّاب على عدم حجب بعضهم البعض، لكنه لا يجعل خلط الأحمال "مجانيًا". القضايا العملية تشمل:
حتى دون حجب واضح، يمكن للتحليلات الثقيلة تدهور الأداء مع الوقت.
غالبًا ما تلاحظ علامات مثل:
إذا بدا النظام "بطيئًا عشوائيًا" أثناء تحديث اللوحات، فهذا علامة نموذجية على خلط الأحمال.
غالبًا ما يكون نسخة قراءة (read replica) خطوة أولى:
هي جسر جيد عندما حجم البيانات معتدل و"عدة دقائق تأخير" مقبولة.
مستودع بيانات أفضل عندما تحتاج إلى:
يتطلب عادةً نموذجًا ملائمًا للتحليلات (غالبًا مخطط نجمي) وأنبوبًا لتحميل البيانات.
CDC (Change Data Capture) يبث الإدخالات/التحديثات/الحذوفات من قاعدة OLTP (غالبًا من سجل المعاملات) إلى التحليلات.
يفيد لأنه:
المقابل هو أجزاء نظام أكثر وحاجة للتعامل بعناية مع تغييرات المخطط وترتيب الأحداث.
اختر بناءً على تكرار تغيّر منطق العمل وما تريد تخزينه:
نهج عملي: ابدأ بـ ELT للسرعة، ثم أضف حوكمة (اختبارات، نماذج مُنقحة) عندما تستقر المقاييس الحرجة.
نعم — مؤقتًا — إذا أبقيت التحليلات خفيفة جدًا وأضفت ضوابط:
يتوقف القبول عندما تبدأ التقارير بإحداث ارتفاعات متكررة في زمن المعاملات أو استنفاد تجمع الاتصالات أو حوادث إنتاجية.