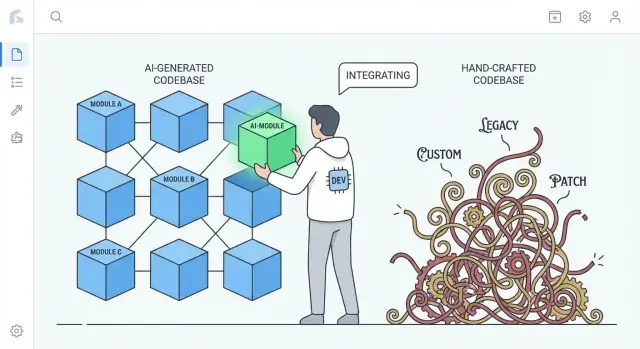
ماذا يعني "أسهل للاستبدال" في مشاريع حقيقية
"أسهل للاستبدال" نادرًا ما يعني حذف تطبيق كامل وإعادة بنائه من الصفر. في الفرق الحقيقية، يحدث الاستبدال على مقاييس مختلفة، وما يعنيه "إعادة الكتابة" يعتمد على ما ستستبدله.
استبدال مقابل إعادة كتابة: ما الموجود فعلاً على الطاولة
قد يكون الاستبدال:\n
- وحدة (قواعد الفوترة، توليد PDF، قوالب البريد)
- خدمة (API التوصية، عامل خلفي)
- واجهة أمامية (صفحة، منطقة ميزة، أو واجهة المستخدم كاملة)
- إعادة كتابة تطبيق كامل (نادرة، مكلفة، وأحيانًا ضرورية)
عندما يقول الناس إن قاعدة الشيفرة "أسهل لإعادة الكتابة"، فهم عادةً يقصدون أنه يمكنك إعادة بدء جزء واحد دون تفكيك كل شيء، وإبقاء العمل التجاري يعمل، والترحيل تدريجيًا.
المقارنة الحقيقية: كود مولَّد بالذكاء الاصطناعي مقابل كود مُصمَّم يدويًا بشدة
هذه الحجة ليست "كود الذكاء الاصطناعي أفضل" بحد ذاتها. إنها حول ميول شائعة.
- الكود المصمّم يدويًا بشدة قد يتراكم به أنماط فريدة، تجريدات ذكية، و"أطر عمل داخل التطبيق" لمرة واحدة. قد تكون هذه ممتازة، لكنها قد تخلق أيضًا نظامًا خاصًا يفهمه عدد قليل فقط.\n- الكود المولَّد بالذكاء الاصطناعي غالبًا ما يميل إلى الافتراضات المألوفة: مكتبات سائدة، طبقات تقليدية، وأنماط تشبه ما تجده في مشاريع مرجعية كثيرة.
هذا الاختلاف مهم أثناء إعادة الكتابة: الشيفرة التي تتبع قواعد متعارف عليها يمكن غالبًا استبدالها بتنفيذ تقليدي آخر مع تفاوض أقل ومفاجآت أقل.
ضبط التوقعات: كود الذكاء الاصطناعي قد يكون فوضويًا
يمكن أن يكون الكود المولَّد بالذكاء الاصطناعي غير متسق، متكررًا، أو ناقص الاختبارات. "أسهل للاستبدال" ليس ادّعاءً بأنه أنظف—بل ادّعاء بأنه غالبًا أقل تفرّدًا. إذا بُنيت فرعية من مكونات شائعة، فإن استبدالها يمكن أن يكون أشبه بتبديل قطعة معيارية بدلاً من هندسة آلة مخصصة.
لمحة: لماذا تُخفض المعيارية تكاليف التحويل
الفكرة الأساسية بسيطة: التوحيد يقلل تكاليف التحويل. عندما تُركّب الشيفرة من أنماط قابلة للتعرُّف وحواف واضحة، يمكنك إعادة توليد أو إعادة هيكلة أو إعادة كتابة أجزاء بخوف أقل من كسر تبعيات مخفية. الأقسام التالية تبين كيف يظهر ذلك في البنية، الملكية، الاختبارات، وزخم الهندسة اليومي.
الأنماط القياسية تقلل تكلفة البدء من جديد
ميزة عملية للكود المولَّد بالذكاء الاصطناعي هي أنه غالبًا ما يفترض أنماطًا شائعة ومألوفة: تخطيطات مجلدات معروفة، تسمية متوقعة، توافق مع قواعد الأطر السائدة، ونهج "كتاب دراسي" للتوجيه، التحقق، التعامل مع الأخطاء، والوصول إلى البيانات. حتى عندما لا تكون الشيفرة مثالية، فهي عادةً قابلة للقراءة بنفس طريقة العديد من الدروس ومشروعات البداية.
الألفة أفضل من الأصالة عندما تحتاج لإعادة الكتابة
إعادة الكتابة مكلفة إلى حد كبير لأن الناس يجب أن يفهموا أولًا ما يوجد. الشيفرة التي تتبع اتفاقيات معروفة تقلل زمن "فك الشيفرة". يمكن للمهندسين الجدد ربط ما يرونه بنماذج ذهنية يعرفونها بالفعل: أين توجد الإعدادات، كيف تتدفق الطلبات، كيف تُوصَّل التبعيات، وأين توضع الاختبارات.
هذا يجعل من الأسرع:\n
- تحديد الحواف للاستبدال (الوحدات، الخدمات، النقاط النهائية)\n- تكرار السلوك في تنفيذ جديد\n- مقارنة القديم والجديد جنبًا إلى جنب دون ترجمة بين أنماط مختلفة
بالمقابل، قواعد الشيفرة المصممة يدويًا كثيرًا ما تعكس أسلوبًا شخصيًا بعمق: تجريدات فريدة، ميكروفريموركات داخلية، أو نمط محدد للمجال لا يفهم إلا من له سياق تاريخي. تلك الاختيارات قد تكون أنيقة—لكنها تزيد تكلفة البدء من جديد لأن إعادة الكتابة يجب أن تعيد تعلم نظرة المؤلف للعالم.
يمكنك فرض الاتفاقيات بأي طريقة كانت
هذا ليس سحرًا حصرًا للذكاء الاصطناعي. يمكن للفرق (ويجب أن) تفرض البنية والنمط باستخدام القوالب، linters، formatters، وأدوات الإنشاء. الفارق هو أن الذكاء الاصطناعي يميل لأن ينتج "عامًّا افتراضيًا"، بينما الشيفرة المكتوبة يدويًا قد تنجرف نحو حلول مخصّصة ما لم تُحافظ الاتفاقيات بنشاط.
قِلَّة الغراء المصنَّع تعني غالبًا تبعيات مخفية أقل
كثير من ألم إعادة الكتابة لا تسببه "المنطق التجاري الرئيسي". سببه هو الغراء المصمّم—المساعدات المخصصة، الأطر الصغيرة المحلية، الحيل باستخدام الميتابرمجة، والاتفاقيات لمرة واحدة التي تربط كل شيء بصمت.
ما الذي يُعد "غراءً مخصّصًا"؟
الغراء المخصّص هو الشيء الذي ليس جزءًا من منتجك، ومع ذلك لا يمكن لمنتجك أن يعمل بدونه. أمثلة: حاوية حقن تبعيات مخصّصة، طبقة توجيه مصنوعة يدويًا، فئة أساسية سحرية تسجّل النماذج تلقائيًا، أو مساعدات تغير الحالة العالمية "للتسهيل". يبدأ غالبًا كموفّر وقت وينتهي كمعرفة مطلوبة لكل تغيير.
لماذا يزيد الغراء الفريد الاقتران (ومخاطر إعادة الكتابة)
المشكلة ليست بوجود الغراء—بل بتحوله إلى اقتران غير مرئي. عندما يكون الغراء فريدًا لفريقك، غالبًا ما:\n
- يخلق تبعيات ضمنية (تعمل الأشياء فقط لأن المساعدات تُنفَّذ بترتيب معين)\n- ينشر افتراضات عبر الملفات (تصبح تسميات الأسماء سلوكًا)\n- يجعل إعادة الهيكلة "البسيطة" محفوفة بالمخاطر (غيّر الغراء، ينكسر كل شيء)
أثناء إعادة الكتابة، يصعب تكرار هذا الغراء بشكلٍ صحيح لأن القواعد نادرًا ما تُدون. تكتشفها عند كسر الإنتاج.
لماذا يتجنب كود الذكاء الاصطناعي التفنن المفرط عادةً
تخرج مخرجات الذكاء الاصطناعي غالبًا نحو المكتبات القياسية، الأنماط الشائعة، والتوصيل الصريح. قد لا يخترع إطارًا صغيرًا عندما تكفي وحدة أو كائن خدمة واضح. هذا التواضع يمكن أن يكون ميزة: قواعد سحرية أقل تعني تبعيات مخفية أقل، مما يسهل انتزاع فرعية واستبدالها.
المقايضة: الإسهاب مقابل التفنن
العيب أن الشيفرة "البسيطة" قد تكون أكثر إسهابًا—المزيد من المعلمات الممررة، المزيد من الأنابيب الواضحة، وقلة الاختصارات. لكن الإسهاب غالبًا أرخص من الغموض. عندما تقرر إعادة الكتابة، تريد شيفرة سهلة الفهم، سهلة الحذف، وصعبة التفسير الخاطئ.
بنية متوقعة تدعم إعادة الكتابات التدريجية
"البنية المتوقعة" أقل عن الجمال وأكثر عن الاتساق: نفس المجلدات، قواعد التسمية، وتدفقات الطلب تتكرر في كل مكان. تميل مشاريع الذكاء الاصطناعي المولَّدة إلى الافتراضات المألوفة—controllers/, services/, repositories/, models/—مع نقاط نهاية CRUD متكررة وأنماط تحقق مماثلة.
هذا الاتساق مهم لأنّه يحوّل إعادة الكتابة من منحدر إلى سلم.
كيف يبدو الاتساق
ترى أنماطًا مُكررة عبر الميزات:
- حدود مجلد واضحة (API → service → data access)
- تسمية متسقة (
UserService, UserRepository, UserController)
- تدفق CRUD مشابه (list → get → create → update → delete)
- شكل قياسي للأخطاء، التسجيل، وكائنات الطلب/الاستجابة
عندما تُبنى كل ميزة بنفس الطريقة، يمكنك استبدال قطعة دون الحاجة إلى "إعادة تعلّم" النظام في كل مرة.
استبدال جزء واحد في كل مرة
تعمل إعادة الكتابة التدريجية بشكل أفضل عندما يمكنك عزل حد وإعادة بنائه خلفه. البنى المتوقعة تخلق تلك الفواصل بطبيعتها: كل طبقة لها وظيفة ضيقة، ومعظم الاستدعاءات تمر عبر مجموعة صغيرة من الواجهات.
نهج عملي هو أسلوب "الخنّاق": إبقِ واجهة الـ API العامة مستقرة، واستبدل الداخلية تدريجيًا.
مثال: استبدال طبقة الوصول للبيانات دون لمس الـ API
افترض أن التطبيق يملكcontrollers تستدعي خدمة، والخدمة تستدعي مخزنًا:\n
OrdersController → OrdersService → OrdersRepository
تريد الانتقال من استعلامات SQL مباشرة إلى ORM، أو من قاعدة بيانات إلى أخرى. في قاعدة شيفرة متوقعة، يمكن احتواء التغيير:\n
- أنشئ
OrdersRepositoryV2 (تنفيذ جديد)
- احتفظ بتواقيع الدوال نفسها (
getOrder(id), listOrders(filters))
- غيّر التوصيل في مكان واحد (حقن التبعيات أو مصنع)
- شغّل الاختبارات وانشر ميزّةًا تلو الأخرى
يبقى كود الكنترولر والخدمة في الغالب دون تغيير.
المقابل: الهياكل المصممة يدويًا
الأنظمة المصممة يدويًا بشكلٍ عالي قد تكون ممتازة—لكنها غالبًا تُشفّر أفكارًا فريدة: تجريدات مخصصة، ميتابرمجة ذكية، أو سلوك عابر مخفي في الفئات الأساسية. هذا قد يجعل كل تغيير يتطلب سياقًا تاريخيًا عميقًا. مع البنية المتوقعة، عادةً ما يكون سؤال "أين أغيّر هذا؟" واضحًا، مما يجعل إعادة الكتابة الصغيرة ممكنة بشكل أسبوعي.
ضعف "التعلّق بالمؤلف" يجعل الحذف مقبولًا أكثر
حاجز صامت في كثير من إعادة الكتابات ليس تقنيًا—بل اجتماعيًا. الفرق غالبًا تحمل مخاطر الملكية، حيث شخص واحد فقط يفهم حقًا كيف يعمل النظام. عندما كتب ذاك الشخص أجزاء كبيرة من الشيفرة يدويًا، تبدأ الشيفرة بالشعور كأثر شخصي: "تصميمي"، "حلّي الذكي"، "حلّ التغلب الذي أنقذ الإصدار". هذا التعلّق يجعل الحذف مكلفًا عاطفيًا، حتى عندما يكون منطقيًا اقتصاديًا.
يقلل الكود المولَّد بالذكاء الاصطناعي هذا التأثير. لأن المسودة الأولية قد تُنتج بواسطة أداة (وتتبع أنماطًا مألوفة)، تبدو الشيفرة أقل كـتوقيع وأكثر كتطبيق قابل للاستبدال. الناس عادةً ما يشعرون براحة أكبر في القول "لنستبدل هذه الوحدة" عندما لا تبدو كإلغاء لحرفة شخص ما—أو تحدٍّ لمكانته في الفريق.
لماذا يغيّر هذا سلوك إعادة الكتابة
عندما ينخفض التعلّق بالمؤلف، تميل الفرق إلى:\n
- التساؤل عن الشيفرة الحالية بحرية ("هل لا تزال هذه أفضل طريقة؟")\n- حذف أجزاء كبيرة دون التفاوض على الكبرياء أو السياسة\n- اختيار إعادة التوليد أو الاستبدال مبكرًا بدلًا من شهور من الرقع الحذرة\n- نشر المعرفة أسرع، لأن لا أحد يعامل التفاصيل الداخلية كـ"منطقة مملوكة"
ملاحظة عملية
قرارات إعادة الكتابة يجب أن تُدار بناءً على التكلفة والنتائج: جداول التسليم، المخاطر، القابلية للصيانة، وتأثير المستخدم. "سهل الحذف" خاصية مفيدة—وليس استراتيجية بذاتها.
المطالبات ومسارات التوليد يمكن أن تعمل كتوثيق
ابدأ تجربة لوحدة قابلة للاستبدال
ابنِ ميزة قابلة للاستبدال في Koder.ai وشاهد مدى سرعتك في استبدالها بأمان.
فائدة مغمورة للكود المولَّد بالذكاء الاصطناعي هي أن مدخلات التوليد يمكن أن تعمل كمواصفة حية. مطالبة، قالب، وتكوين المولِّد يمكن أن يصفوا الهدف بلغة بسيطة: ماذا يجب أن تفعل الميزة، أي قيود تهم (أمان، أداء، نمط)، وما مقياس "الانتهاء".
المطالبات كمواصفات حية
عندما تستخدم الفرق مطالبات قابلة للتكرار (أو مكتبات مطالبات) وقوالب ثابتة، فإنها تخلق أثرًا تدقيقيًا لقرارات كانت ستبقى ضمنية. مطالبة جيدة قد تحدد أشياء عادةً ما يجب أن يخمنها الصيانة المستقبلية:
- تدفق المستخدم والحالات الطرفية
- قواعد التسمية وبنية المجلدات
- كيف تُدار الأخطاء وتُسجل
- ما الذي يجب اختباره (وما يمكن تمثيله بمحاكاة)
هذا يختلف بشكلٍ ملحوظ عن قواعد الشيفرة المصممة يدويًا التي تنتشر قراراتها عبر رسائل الالتزام، المعرفة القبلية، واتفاقيات صغيرة غير مكتوبة.
مسارات التوليد تساعدك على إعادة إنتاج السلوك
إذا احتفظت بمسارات التوليد (المطالبة + إصدار النموذج + المدخلات + خطوات ما بعد المعالجة)، فإن إعادة الكتابة لا تبدأ من صفحة بيضاء. يمكنك إعادة استخدام نفس قائمة التحقق لإعادة إنتاج نفس السلوك تحت بنية أنظف، ثم مقارنة المخرجات.
عمليًا، هذا قد يحول إعادة الكتابة إلى: "أعد توليد الميزة X تحت اتفاقيات جديدة، ثم تحقق من التكافؤ"، بدلًا من "استخرج ما كان من المفترض أن تفعله الميزة X من الشيفرة."
تحذير مهم: عامِل المطالبات كشيفرة
هذا ينجح فقط إذا أُديرت المطالبات والتهيئات بنفس انضباط الشيفرة:
- version them in the repo (وليس في ملاحظات شخصية)
- require review for changes
- record which prompt/config generated which modules
بدون ذلك، تصبح المطالبات اعتمادًا غير موثق. ومعها، يمكن أن تكون التوثيق الذي غالبًا ما يتمنى نظام مبني يدويًا أن يملكه.
اختبارات قوية تحوّل إعادة الكتابة إلى هندسة روتينية
"أسهل للاستبدال" ليس فعلًا عن من كتب الشيفرة، بل عن ما إذا كان يمكنك تغييره بثقة. تصبح إعادة الكتابة هندسة روتينية عندما تخبرك الاختبارات بسرعة وموثوقية أن السلوك بقي نفسه.
يمكن أن يساعد الكود المولَّد بالذكاء الاصطناعي هنا—عندما تطلب ذلك. كثير من الفرق تطلب توليد اختبارات قالبية مع الميزات (اختبارات وحدة أساسية، اختبارات تكامل للحالة السعيدة، محاكيات بسيطة). قد لا تكون تلك الاختبارات مثالية، لكنها تخلق شبكة أمان أولية غالبًا ما تكون مفقودة في الأنظمة المصممة يدويًا حيث تُؤجل الاختبارات "إلى وقت لاحق".
أعطِ الأولوية لاختبارات العقد عند الحواف
إذا أردت قابلية الاستبدال، ركّز طاقة الاختبار على الحواف حيث تلتقي الأجزاء:
- واجهات خارجية: الطلبات، الاستجابات، رموز الخطأ، إعادة المحاولة، الترقيم
- المحوِّلات: مزوّدو الدفع، خدمات البريد، تخزين الملفات، الطوابير
- نماذج البيانات: الهجرات، التسلسل، قواعد التحقق
اختبارات العقد تُحکّم ماذا يجب أن يبقى صحيحًا حتى لو استبدلت الباطن. هذا يعني أنه يمكنك إعادة كتابة وحدة خلف API أو استبدال محوِّل دون إعادة التفاوض على السلوك التجاري.
استخدم التغطية كالبوصلة لا كإنجاز
أرقام التغطية يمكن أن تُرشِد إلى أماكن الخطر، لكن المطاردة للوصول إلى 100% غالبًا ما تنتج اختبارات هشة تعيق إعادة الهيكلة. بدلًا من ذلك:
- أضف اختبارات حيث تكون الفشل مكلفًا (المال، فقدان البيانات، ثقة المستخدم)
- فضِّل اختبارات قليلة ذات إشارة عالية على الكثير من الاختبارات السطحية
- عند إعادة الكتابة، قارن القديم والجديد عبر نفس اختبارات العقد
مع اختبارات قوية، تتوقف إعادة الكتابة عن كونها مشاريع بطولية وتصبح سلسلة خطوات آمنة وقابلة للرجوع.
عيوب كود الذكاء الاصطناعي الشائعة عادةً ما تكون سهلة الاكتشاف والعزل
حافظ على بساطة المعمارية
أنشئ بنية تقليدية يمكنك إعادة كتابتها شريحةً بشريحة دون إعادة تعلم الأكواد الوسيطة المخصصة.
كود الذكاء الاصطناعي يميل إلى الفشل بطرق يمكن التنبؤ بها. غالبًا ترى منطقًا مكررًا (نفس المساعد معاد تنفيذه ثلاث مرات)، فروعًا "قريبة" تتعامل مع الحالات الطرفية بشكل مختلف، أو وظائف تتضخم بإلحاق تصحيحات نموذجية. لا شيء من ذلك مثالي—لكن له ميزة: المشاكل عادةً ما تكون مرئية.
العيوب الواضحة أفضل من الأخطاء الذكية الخفية
الأنظمة المصممة يدويًا قد تخفي التعقيد خلف تجريدات ذكية، تحسينات دقيقة، أو سلوك مترابط "تمامًا". تلك الأخطاء مؤلمة لأنّها تبدو صحيحة وتنجح في المراجعات السطحية.
كود الذكاء الاصطناعي أكثر عرضة لأن يكون غير متسق بوضوح: معلمة مُتجاهلة في مسار واحد، فحص تحقق موجود في ملف واحد وليس في آخر، أو أسلوب مختلف للتعامل مع الأخطاء كل بضع دوال. هذه التناقضات تظهر أثناء المراجعة والتحليل الساكن، وأسهل عزلها لأنها نادرًا ما تعتمد على بديهيات مقصودة.
مرشحو إعادة الكتابة يظهرون عبر التكرار
التكرار هو الإشارة. عندما ترى نفس تسلسل الخطوات يظهر مرارًا—parse input → normalize → validate → map → return—عبر نقاط النهاية أو الخدمات، لقد وجدت فاصلًا طبيعيًا للاستبدال. يحلو للذكاء الاصطناعي أن "يحل" طلبًا جديدًا بإعادة طباعة حل سابق مع تعديلات، مما ينتج عناقيد شبه مكررة.
نهج عملي: علِم أي مقطع متكرر كمرشح للاستخراج أو الاستبدال، خصوصًا عندما:
- يظهر في 3+ أماكن مع اختلافات بسيطة
- الاختلافات تتعلق بحالات طرفية أو رسائل خطأ
- الشيفرة لا تملك مالكًا واضحًا وتُرقع باستمرار
قاعدة عامة: اجمع التكرارات في وحدة واحدة مُختبرة
إذا استطعت تسمية السلوك المتكرر في جملة، فيجب أن يكون على الأرجح وحدة واحدة.
استبدل القطع المتكررة بمكوّن واحد مُختبر جيدًا (مساعد، خدمة مشتركة، أو دالة مكتبية)، اكتب اختبارات تُثبت حالات الحافة المتوقعة، ثم احذف النسخ. حولت العديد من النسخ الهشة إلى مكان واحد لتحسينه—ومكان واحد لإعادة كتابته لاحقًا إذا لزم.
القابلية للقراءة والاتساق يمكن أن تفوق التحسين اليدوي المتقن
كود الذكاء الاصطناعي عادةً ما يبرع عندما تطلب منه تحسين الوضوح بدلًا من التفنن. مع مطالبات وقواعد linting مناسبة، سيختار عادةً تدفق تحكم مألوفًا، تسمية تقليدية، ووحدات "مملة" بدلًا من التجديد. هذا يمكن أن يكون نصرًا طويل الأجل أكبر من بضع نسب مئوية في السرعة الناتجة عن حيل محسنة يدويًا.
لماذا الشيفرة المقروءة أسهل لإعادة الكتابة
تنجح إعادة الكتابة عندما يستطيع أشخاص جدد بسرعة بناء نموذج ذهني صحيح للنظام. الشيفرة المقروءة والمتسقة تقلل زمن الإجابة على أسئلة مثل "أين تدخل هذه الطلب؟" و"ما شكل البيانات هنا؟" إذا اتبعت كل خدمة أنماطًا مماثلة (الهيكل، التعامل مع الأخطاء، التسجيل، التهيئة)، يمكن لفريق جديد استبدال شريحة واحدة في كل مرة دون إعادة تعلم الاتفاقيات المحلية.
الاتساق يقلل أيضًا الخوف. عندما تكون الشيفرة متوقعة، يمكن للمهندسين حذف وإعادة بناء أجزاء بثقة لأن مساحة السطح أسهل للفهم ويبدو "نطاق التأثير" أصغر.
المقايضة مع حيل الأداء المصنوعة يدويًا
الكود المحسّن للغاية يدويًا قد يكون صعبًا على إعادة الكتابة لأن تقنيات الأداء تتسرب في كل مكان: طبقات تخزين مؤقت مخصصة، تحسينات دقيقة، نماذج تزامن محلية، أو اعتماد وثيق لهياكل بيانات محددة. هذه الاختيارات قد تكون صحيحة، لكنها تخلق غالبًا قيودًا غير واضحة حتى يحدث خلل.
تحذير: الأداء لا يزال مهمًا—قِسْه
الوضوح ليس إذنًا للتباطؤ. الفكرة أن تكسب الأداء بالدليل. قبل إعادة الكتابة، سجّل مقاييس الأساس (خوارزميات الكمون، CPU، الذاكرة، التكلفة). بعد استبدال مكوّن، قِس مرة أخرى. إذا تدهور الأداء، حسّن المسار الساخن المحدد—دون تحويل قاعدة الشيفرة الكاملة إلى لغز.
إعادة التوليد مقابل إعادة الهيكلة مقابل إعادة الكتابة: اختيار إعادة التعيين الصحيحة
عندما يبدأ نظام مساعد بالذكاء الاصطناعي بالشعور "بأنه غير صحيح"، لا تحتاج تلقائيًا إلى إعادة كتابة كاملة. إعادة التعيين الأفضل تعتمد على مقدار النظام الذي هو خاطئ مقابل مجرد فوضوي.
ثلاث خيارات لإعادة التعيين
إعادة التوليد تعني إعادة إنشاء جزء من الشيفرة من مواصفة أو مطالبة—غالبًا بالبدء من قالب أو نمط معروف—ثم إعادة توصيل نقاط التكامل (الراوت، العقود، الاختبارات). ليست "حذف كل شيء"، بل "إعادة بناء هذه الشريحة من وصف أوضح."\n
إعادة الهيكلة تحافظ على السلوك نفسه ولكن تغيّر البنية الداخلية: إعادة تسمية، تقسيم الوحدات، تبسيط الشروط، إزالة التكرار، وتحسين الاختبارات.\n
إعادة الكتابة تستبدل مكوّنًا أو نظامًا بتنفيذ جديد، عادةً لأن التصميم الحالي لا يمكن إصلاحه دون تغيير السلوك أو الحدود أو تدفقات البيانات.
متى تكون إعادة التوليد مناسبة جدًا
تتفوق إعادة التوليد عندما تكون الشيفرة في الغالب قالبية وتعيش القيمة في واجهاتها بدلًا من داخلها:
- شاشات CRUD ولوحات الإدارة
- محولات API وطبقات التكامل الرقيقة
- التمهيد: التوجيه، المسلسلات، DTOs، التحقق البسيط، التعامل الشائع مع الخطأ
إذا كان الوصف واضحًا والحدود نظيفة، غالبًا ما تكون إعادة التوليد أسرع من تفكيك التعديلات المتراكمة.
متى تكون إعادة التوليد محفوفة بالمخاطر (أو تفشل)
كن حذرًا عندما تشفر الشيفرة معرفة مجال مكتسبة أو قيود دقة:
- قواعد أعمال ثقيلة بالمجال وبها حالات طرفية كثيرة
- تزامن معقّد (طوابير، أقفال، محاولات، إجرائية القابلية للتكرار)
- منطق امتثال (سجلات تدقيقية، الاحتفاظ، قواعد الخصوصية)
في هذه المجالات، "قريب بما يكفي" قد يكون خاطئًا بتكلفة باهظة—إذًا إعادة التوليد قد تساعد، لكن فقط إذا استطعت إثبات التكافؤ باختبارات قوية ومراجعات.
أبواب المراجعة والنشر الجزئي
عامل الشيفرة المُولَّدة كاعتماد جديد: اشترط مراجعة بشرية، شغّل مجموعة الاختبارات بالكامل، وأضِف اختبارات مستهدفة للأخطاء التي رأيتها سابقًا. انشر في شرائح صغيرة—نقطة نهاية واحدة، شاشة واحدة، محوِّل واحد—خلف علم ميزّة أو إطلاق تدريجي إذا أمكن.
قاعدة افتراضية مفيدة: أعد توليد الغلاف، أعد هيكلة الحواف، وأعد كتابة فقط الأجزاء التي تواصل فيها الافتراضات الانكسار.
المخاطر وضوابط الأمان لكود "قابل للاستبدال حسب التصميم"
تحقق من التغييرات في الإنتاج
انشر واستضف تطبيقك لتختبر السلوك الحقيقي قبل الالتزام بإعادة الكتابة.
"سهل الاستبدال" يظل ميزة فقط إذا تعاملت الفرق مع الاستبدال كنشاط مهندسي مُهندس لا كزر إعادة ضبط عابر. يمكن أن تُبدَّل وحدات مولَّدة بسرعة—لكنها أيضًا قد تفشل بسرعة إذا وثقت بها أكثر مما تحققت منها.
مخاطر رئيسية للمراقبة
الكود المولَّد غالبًا ما يبدو كاملاً حتى لو لم يكن كذلك. هذا قد يخلق ثقة زائفة، خصوصًا عندما تنجح عروض الحالة السعيدة.
خطر ثانٍ هو حالات الحافة المفقودة: مدخلات غير عادية، مهلات، خصائص التزامن، وتعامل مع الأخطاء لم تُغطَّ في المطالبة أو البيانات النموذجية.
أخيرًا، هناك غموض التراخيص/الملكية الفكرية. حتى لو كان الخطر منخفضًا في عدة إعدادات، يجب أن تملك الفرق سياسة لما هي المصادر والأدوات المقبولة، وكيف تُتبع الأصول.
ضوابط تحافظ على أمان إعادة الكتابة
ضع الاستبدال خلف نفس البوابات كأي تغيير آخر:\n
- مراجعة الشيفرة بعدسة "كود مولَّد": الوضوح، أوضاع الفشل، تحقق المدخلات، والتسجيل.\n- فحوصات أمان (SAST، مسح التبعيات، كشف الأسرار) وقاعدة تمنع تجاوزها.\n- سياسات تبعيات: فضّل مكتبات معروفة قليلة، ثبّت الإصدارات، وتجنّب إدخال إطار جديد لأن المطالبة اقترحته.\n- آثار تدقيق: احتفظ بالمطالبات، إصدارات النماذج، وملاحظات التوليد في المستودع حتى تكون التغييرات قابلة للشَّرح لاحقًا.
وثّق الحدود قبل استبدال الوحدات
قبل استبدال مكوّن، اكتب حدّه وثوابته: ما المدخلات التي يقبلها، ما الذي يضمنه، ما الذي يجب ألا يفعله أبدًا (مثلاً: "لا تحذف بيانات العملاء"), ومتطلبات الأداء/الكمون. هذا "العقد" هو ما تختبره—بغض النظر عمن (أو ما) يكتب الشيفرة.
قائمة فحص خفيفة
- حدّد عقد الوحدة (المدخلات/المخرجات، الثوابت).
- أضف/أكد اختبارات لحالات الحافة.
- شغّل فحوصات الأمان ومسح التبعيات.
- راجع للقراءة والتعامل مع الفشل.
- سجّل بيانات المطالبة/أدوات التوليد.
- انشر خلف علم وراقب.
نتائج عملية وخطة خطوة تالية بسيطة
الكود المولَّد بالذكاء الاصطناعي غالبًا ما يكون أسهل لإعادة الكتابة لأنه يميل إلى اتباع أنماط مألوفة، يتجنَّب التخصيص الشخصي العميق، وأسهل في إعادة التوليد عند تغيُّر المتطلبات. تلك القابلية تتوقع خفض تكلفة الحذف والاستبدال اجتماعيًا وتقنيًا.
الهدف ليس "رمي الشيفرة"، بل جعل استبدال الشيفرة خيارًا طبيعيًا قليل الاحتكاك—مدعومًا بالعقود والاختبارات.
خطوات عملية يمكنك تنفيذها هذا الأسبوع
ابدأ بتوحيد الاتفاقيات حتى يتوافق أي كود مُعاد توليده أو مُعاد كتابته مع نفس القالب:
- ثبّت الاتفاقيات: التنسيق، بنية المجلدات، التسمية، التعامل مع الأخطاء، وشكل الـ API. اكتبها بإيجاز في CONTRIBUTING.md.
- أضف اختبارات العقد عند الحواف: ركّز على المدخلات/المخرجات للوحدات والخدمات (نقاط نهاية HTTP، رسائل الطوابير، طبقات الوصول للبيانات). يجب أن تمر هذه الاختبارات حتى لو تغيّرت التنفيذات.
- تتبع المطالبات والمواصفات: خزّن المطالبات، ملاحظات المتطلبات، ومسارات التوليد بجانب الشيفرة حتى تتمكن إعادة الكتابة من إعادة إنتاج النية، وليس النص فقط.
إذا كنت تستخدم سير عمل يعتمد على التفاعل، ابحث عن أدوات تُسهّل تلك الممارسات: حفظ مواصفات "وضع التخطيط" بجانب المستودع، التقاط مسارات التوليد، ودعم التراجع الآمن. على سبيل المثال، Koder.ai مصمّم حول التوليد المحادثي مع لقطات وتراجع، وهذا يتماشى جيدًا مع نهج "قابل للاستبدال حسب التصميم"—أعد توليد شريحة، حافظ على العقد ثابتة، وتراجع بسرعة إذا فشلت اختبارات التكافؤ.
نفِّذ مشروعًا تجريبيًا صغيرًا لـ"وحدة قابلة للاستبدال"
اختر وحدة واحدة مهمة لكنها معزولة بأمان—توليد تقارير، إرسال إشعارات، أو منطقة CRUD واحدة. حدّد واجهتها العامة، أضف اختبارات العقد، ثم اسمح لنفسك بإعادة التوليد/إعادة الهيكلة/إعادة الكتابة للبَاطن حتى تصبح مملة. قِس زمن الدورة، معدل العيوب، وجهد المراجعة؛ استخدم النتائج لوضع قواعد للفريق.
لتشغيل هذا عمليًا، احتفظ بقائمة فحص في كتاب التشغيل الداخلي (أو شاركها عبر /blog) واجعل مجموعة "العقود + الاتفاقيات + المسارات" مطلبًا للعمل الجديد. إذا كنت تُقيّم دعمًا أدواتيًا، وثّق ما تحتاجه من حل قبل أن تنظر إلى /pricing.