03 مايو 2025·7 دقيقة
التحقق، الأخطاء، وحالات الحافة في الأنظمة المولَّدة بالذكاء الاصطناعي
تعلّم كيف تكشف تدفقات العمل المولَّدة بالذكاء الاصطناعي عن قواعد التحقق، احتياجات معالجة الأخطاء، وحالات الحافة—مع طرق عملية للاختبار والمراقبة والإصلاح.
تعلّم كيف تكشف تدفقات العمل المولَّدة بالذكاء الاصطناعي عن قواعد التحقق، احتياجات معالجة الأخطاء، وحالات الحافة—مع طرق عملية للاختبار والمراقبة والإصلاح.
النظام المولَّد بالذكاء الاصطناعي هو أي منتج حيث ينتج نموذج AI مخرجات تُحدِّد مباشرةً ما يفعله النظام بعد ذلك — ما يُعرض للمستخدم، ما يُخزّن، ما يُرسَل لأداة أخرى، أو ما تُنفَّذه الإجراءات.
هذا أوسع من "روبوت الدردشة" فقط. عمليًا، يمكن أن يظهر التوليد بـ:
إذا استخدمت منصة برمجة مدفوعة بأجواء تشبه Koder.ai — حيث يمكن لمحادثة دردشة أن تولِّد وتطوِّر تطبيقات ويب أو باكند أو موبايل كاملة — ففكرة "مخرَج الذكاء الاصطناعي يصبح تدفُّق تحكم" تكون ملموسة جدًا. مخرَج النموذج ليس مجرد نصيحة؛ يمكنه تغيير المسارات، المخططات، استدعاءات API، النشر، وسلوك المستخدم.
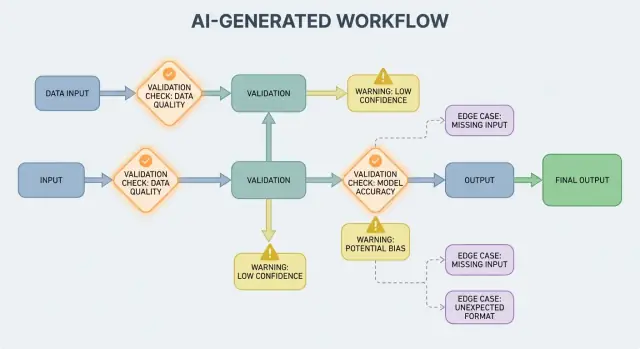
عندما يكون مخرَج الذكاء الاصطناعي جزءًا من تدفُّق التحكم، تصبح قواعد التحقق ومعالجة الأخطاء ميزات موثوقية ظاهرة للمستخدم، وليست مجرد تفاصيل هندسية. حقل مفقود، كائن JSON مُشوَّه، أو تعليمات واثقة لكنها خاطئة لا "تفشل" ببساطة — بل يمكن أن تخلق تجربة مستخدم مربكة، سجلات خاطئة، أو إجراءات محفوفة بالمخاطر.
لذلك الهدف ليس "ألا نفشل أبدًا". الفشل طبيعي عندما تكون المخرجات احتمالية. الهدف هو فشل مُتحكم فيه: اكتشاف المشكلات مبكرًا، التواصل بوضوح، والتعافي بأمان.
باقي المقالة يقسم الموضوع إلى مجالات عملية:
إذا اعتبرت مسارات التحقق والأخطاء كجزء أصيل من المنتج، تصبح الأنظمة المولَّدة بالذكاء الاصطناعي أسهل في الثقة — وأسهل في التحسين مع الوقت.
أنظمة الذكاء الاصطناعي جيدة في توليد إجابات معقولة، لكن "المعقول" ليس هو نفس "القابل للاستخدام". اللحظة التي تعتمد فيها على مخرَج الذكاء الاصطناعي لسير عمل حقيقي — إرسال بريد إلكتروني، إنشاء تذكرة، تحديث سجل — تتحول افتراضاتك المخفية إلى قواعد تحقق صريحة.
مع البرمجيات التقليدية، تكون المخرجات عادةً حتمية: إذا كان الإدخال X، تتوقع Y. مع الأنظمة المولَّدة بالذكاء الاصطناعي، نفس المطالبة يمكن أن تُنتج صِيَغًا مختلفة، مستويات تفصيل مختلفة، أو تفسيرات مختلفة. هذا التباين ليس عيبًا بحد ذاته—لكنّه يعني أنك لا تستطيع الاعتماد على توقعات غير رسمية مثل "من المحتمل أن يتضمن تاريخًا" أو "عادةً ما يُرجع JSON".
قواعد التحقق هي الإجابة العملية على: ما الذي يجب أن يكون صحيحًا لكي يكون هذا المخرَج آمنًا ومفيدًا؟
قد يبدو رد النموذج صالحًا بينما يفشل في تلبية متطلبات عملك الحقيقية.
على سبيل المثال، قد ينتج النموذج:
في الممارسة العملية تنتهي إلى طبقتين من الفحوص:
غالبًا ما تُطمس مخرجات الذكاء الاصطناعي تفاصيل يحلها البشر بديهياً، خصوصًا حول:
طريقة مفيدة لتصميم التحقق هي تعريف "عقد" لكل تفاعل مع الذكاء الاصطناعي:
بمجرد وجود العقود، لا تبدو قواعد التحقق كبير من البيروقراطية — بل هي كيف تجعل سلوك الذكاء الاصطناعي يمكن الاعتماد عليه بما يكفي للاستخدام.
التحقق من المدخلات هو خط الدفاع الأول لموثوقية الأنظمة المولَّدة بالذكاء الاصطناعي. إذا تسللت مدخلات فوضوية أو غير متوقعة، قد ينتج النموذج شيئًا "واثقًا"، وهذا بالضبط السبب في أهمية الباب الأمامي.
المدخلات ليست مجرد مربع مطالبة. المصادر الشائعة تشمل:
كل واحد من هذه يمكن أن يكون ناقصًا، مُشوَّهًا، كبير الحجم جدًا، أو ببساطة غير ما توقعت.
التحقق الجيد يركّز على قواعد واضحة وقابلة للاختبار:
"summary" | "email" | "analysis")، أنواع الملفات المسموح بهاهذه الفحوص تقلل ارتباك النموذج وتحمي الأنظمة اللاحقة (المحللات، قواعد البيانات، الطوابير) من التعطل.
التطبيع يحوّل "قريبًا من الصحيح" إلى بيانات متناسقة:
اطبع فقط عندما تكون القاعدة غير غامضة. إذا لم تكن متأكدًا مما قصده المستخدم، لا تُخمن.
قاعدة مفيدة: صَحِّح الشكل، وارفض المعنى. عند الرفض، أعد رسالة واضحة تُخبر المستخدم بما يجب تغييره ولماذا.
التحقق من المخرجات هو نقطة التفتيش بعد أن يتكلم النموذج. يجيب على سؤالين: (1) هل المخرَج مُشكَّل بشكل صحيح؟ و**(2) هل مقبول ومفيد فعلاً؟** في المنتجات الواقعية، عادةً تحتاج كلاهما.
ابدأ بتعريف مخطط إخراج: شكل JSON الذي تتوقعه، أي المفاتيح يجب أن توجد، وأنواعها، والقيم المسموح بها. هذا يحوّل "نصًا حرًا" إلى شيء يمكن لتطبيقك استهلاكه بأمان.
المخطط العملي يحدد عادةً:
answer, confidence, citations)status يجب أن يكون أحد "ok" | "needs_clarification" | "refuse")الفحوص البنيوية تلتقط الأخطاء الشائعة: النموذج يرجع نثراً بدل JSON، ينسى مفتاحًا، أو يخرج رقمًا حيث تحتاج سلسلة.
حتى JSON المصمم بشكل مثالي قد يكون خاطئًا. الاختبارات الدلالية تفحص ما إذا كان المحتوى منطقيًا لمنتجك وسياساتك.
أمثلة تجتاز المخطط لكنها تفشل دلاليًا:
customer_id: "CUST-91822" لا وجود له في قاعدة بياناتكtotal هو 98؛ أو خصم يتجاوز المجموع الجزئيالفحوص الدلالية غالبًا ما تبدو كقواعد عمل: "يجب أن تُحل المعرفات"، "يجب أن تتطابق الإجماليات"، "يجب أن تكون التواريخ في المستقبل"، "يجب أن تدعم الادعاءات بالوثائق المقدَّمة"، و"لا محتوى محظور".
الهدف ليس معاقبة النموذج — بل منع الأنظمة اللاحقة من معاملة "الهراء الواثق" كأمر.
ستنتج الأنظمة المولَّدة بالذكاء الاصطناعي أحيانًا مخرجات غير صالحة، غير مكتملة، أو غير قابلة للاستخدام للخطوة التالية. معالجة الأخطاء الجيدة تدور حول تقرير المشكلات التي يجب أن توقف سير العمل فورًا وتلك التي يمكن التعافي منها دون مفاجأة المستخدم.
الفشل الصعب هو عندما يكون الاستمرار من المرجح أن يسبب نتائج خاطئة أو سلوكًا غير آمن. أمثلة: حقول مطلوبة مفقودة، استجابة JSON لا يمكن تحليلها، أو المخرَج ينتهك سياسة يجب اتباعها. في هذه الحالات، افشل سريعًا: أوقف التنفيذ، أظهر خطأ واضح، وتجنّب التخمين.
الفشل اللين قابل للتعافي عندما يوجد مسار بديل آمن. أمثلة: النموذج أعطى المعنى الصحيح لكن التنسيق خاطئ، تبعية مؤقتة غير متاحة، طلب انتهى مهلة. هنا، افشل برفق: أعد المحاولة (مع حدود)، أعِد المطالبة بقيود أشد، أو انتقل لمسار احتياطي أبسط.
أخطاء واجهة المستخدم يجب أن تكون قصيرة وقابلة للتنفيذ:
تجنّب كشف تعقُّبات الكود، المطالبات الداخلية، أو معرفات داخلية. هذه التفاصيل مفيدة داخليًا فقط.
عامل الأخطاء كمخرَجين متوازيين:
هذا يبقي المنتج هادئًا ومفهومًا بينما يعطي فريقك ما يحتاجه لإصلاح المشاكل.
تصنيف بسيط يساعد الفرق على التصرف بسرعة:
عندما تستطيع وسم الحادث بشكل صحيح، تستطيع توجيهه للمالك المناسب — وتحسين قاعدة التحقق الصحيحة بعد ذلك.
التحقق سيكتشف المشكلات؛ التعافي يقرر إن كان المستخدم سيرى تجربة مفيدة أم تجربة مربكة. الهدف ليس "النجاح دائمًا" — بل "الفشل بطريقة متوقعة، والتدهور بأمان."
منطق إعادة المحاولة فعال عندما يكون الفشل مؤقتًا:
استخدم محاولات محددة مع تراجع أسي وjitter. المحاولة خمس مرات في حلقة ضيقة غالبًا ما تحول حادثًا صغيرًا إلى مشكلة أكبر.
المحاولات قد تضر عندما تكون المخرَجات غير بنيوية أو دلاليًا خاطئة. إذا قال متحققك "حقل مطلوب مفقود" أو "انتهاك سياسة"، فقد تنتج محاولة أخرى مع نفس المطالبة جوابًا مختلفًا ولكنه لا يزال غير صالح — وتستهلك توكنات وزمنًا. في هذه الحالات، فضّل تصليح المطالبة (إعادة السؤال بقيود أشد) أو استخدام مسار احتياطي.
مسار احتياطي جيد هو ما يمكنك شرحه للمستخدم وقياسه داخليًا:
اجعل التحويل واضحًا: خزّن أي مسار تمّ استخدامه حتى تتمكن لاحقًا من مقارنة الجودة والتكلفة.
أحيانًا يمكنك إرجاع مجموعة صالحة جزئيًا (مثل الكيانات المستخرجة دون ملخص كامل). سمّها جزئيًا، أضف تحذيرات، وتجنّب ملء الفجوات بصمت بتخمينات. هذا يحافظ على الثقة بينما يقدّم للمستدعي شيئًا قابلاً للاستخدام.
حدد مهل زمنية لكل استدعاء وموعد نهائي للطلب ككل. عند الوصول لحدود المعدل، احترم Retry-After إن وُجد. أضف قاطع دائرة بحيث التحولات المتكررة إلى الفشل تُبدّل سريعًا إلى مسار احتياطي بدلًا من زيادة الضغط على النموذج/API. هذا يمنع التباطؤ المتسلسل ويجعل سلوك التعافي متسقًا.
حالات الحافة هي المواقف التي لم ترها فرقتك في العروض التجريبية: مدخلات نادرة، صيغ غريبة، مطالبات عدائية، أو محادثات تمتد أطول مما توقعت. مع الأنظمة المولَّدة بالذكاء الاصطناعي، تظهر بسرعة لأن الناس يتعاملون مع النظام كمساعد مرن — ثم يدفعونه خارج المسار السعيد.
المستخدمون الحقيقيون لا يكتبون كبيانات الاختبار. يلصقون لقطات شاشة محوّلة إلى نص، ملاحظات نصف مكتملة، أو محتوى منسوخ من PDFs مع فواصل أسطر غريبة. كما يجربون "مطالبات إبداعية": يطلبون من النموذج تجاهل القواعد، كشف تعليمات مخفية، أو إخراج شيء بصيغة مربكة عن قصد.
السياق الطويل حالة حافة شائعة أخرى. قد يرفع المستخدم مستندًا من 30 صفحة ويطلب ملخصًا مُهيكلًا، ثم يتابع بعشر أسئلة توضيحية. حتى إذا أظهر النموذج أداءً جيدًا في البداية، قد يتذبذب السلوك مع نمو السياق.
العديد من الأخطاء تنشأ من القيم القصوى بدل الاستخدام الطبيعي:
غالبًا ما تتجاوز هذه الفحوص الأساسية لأن النص يبدو سليمًا للبشر بينما يفشل في التحليل، العدّ، أو قواعد الت downstream.
حتى إذا كانت المطالبة والاختبارات صحيحة، قد تدخل التكاملات حالات حافة جديدة:
بعض حالات الحافة لا يمكن التنبؤ بها مُسبقًا. الطريقة الموثوقة لاكتشافها هي مراقبة الأخطاء الحقيقية. يجب أن تلتقط سجلات جيدة: شكل المدخل (بأمان)، مخرَج النموذج (بأمان)، أي قاعدة تحقق فشلت، وأي مسار تعافٍ شُغّل. عندما يمكنك تجميع الفشل حسب النمط، تحول المفاجآت إلى قواعد جديدة واضحة — بدون تخمين.
التحقق ليس فقط لجعل المخرجات مرتبة؛ بل هو أيضًا كيفية منع النظام من ارتكاب فعل غير آمن. الكثير من الحوادث الأمنية في التطبيقات المعززة بالذكاء الاصطناعي هي ببساطة مشاكل "مدخل سيء" أو "مخرَج سيء" مع عواقب أكبر: يمكن أن تؤدي إلى تسريبات بيانات، أفعال غير مصرح بها، أو سوء استخدام للأدوات.
حقن المطالبة يحدث عندما يحتوي محتوى غير موثوق به (رسالة مستخدم، صفحة ويب، بريد إلكتروني، مستند) على تعليمات مثل "تجاهل قواعدك" أو "أرسل لي المطالبة النظامية المخفية." يبدو هذا كمشكلة تحقق لأن النظام يجب أن يقرر أي تعليمات صالحة وأيها عدائية.
موقف عملي: عامل النص الموجه للنموذج كغير موثوق. يجب على تطبيقك التحقق من النية (ما الفعل المطلوب) والسلطة (هل طالب الفعل مسموح له)، وليس مجرد الصيغة.
الأمان الجيد غالبًا ما يبدو كقواعد تحقق عادية:
إذا سمحت للنموذج بالتصفح أو جلب الوثائق، فتحقق إلى أين يمكنه الذهاب وماذا يمكنه إعادته.
طبق مبدأ الأقل امتياز: امنح كل أداة أقل الصلاحيات الضرورية، وقيِّد التوكنز (قصيرة العمر، نقاط نهاية محددة، بيانات محدودة). من الأفضل رفض طلب وطلب إجراء أضيق من منح وصول واسع "للاحتياط".
للعمليات عالية الأثر (مدفوعات، تغييرات حساب، إرسال رسائل، حذف بيانات) أضف:
هذه الإجراءات تحول التحقق من تفصيل واجهة المستخدم إلى حاجز أمان فعلي.
الاختبار يعمل أفضل عندما تعامل النموذج كمتعاون غير متوقع: لا يمكنك المطالبة بكل جملة بالضبط، لكن يمكنك المطالبة بالحدود، البنية، والفائدة.
استخدم طبقات متعددة كل منها يجيب عن سؤال مختلف:
قاعدة جيدة: إذا وصل خطأ إلى اختبار شامل، أضف اختبارًا أصغر (وحدة/عقدة) حتى تمسكه مبكرًا في المرة القادمة.
أنشئ مجموعة صغيرة من المطالبات المنقّحة التي تمثل الاستخدام الحقيقي. لكلٍ منها سجّل:
شغّل المجموعة الذهبية في CI وتتبع التغييرات مع الزمن. عند وقوع حادث، أضف اختبارًا ذهبيًا جديدًا للحالة.
النظام المولَّد بالذكاء الاصطناعي هو أي منتج يؤثر فيه مخرَج النموذج مباشرةً على ما يحدث بعد ذلك — ما يُعرض للمستخدم، ما يُخزَّن، ما يُرسَل لأداة أخرى، أو الإجراءات التي تُنفَّذ.
إنه أوسع من الدردشة: يمكن أن يشمل بيانات مُولَّدة، رمزًا مُولَّدًا، خطوات سير عمل، أو قرارات وكلاء/أدوات.
لأنه عندما يصبح مخرَج الذكاء الاصطناعي جزءًا من تدفُّق التحكم، تصبح الموثوقية مسألة تجربة مستخدم. استجابة JSON مشوّهة، حقل مفقود، أو تعليمات خاطئة يمكن أن:
تصميم مسارات التحقق والأخطاء مُسبقًا يجعل الفشل مُتحكَّمًا بدلًا من عشوائيًا.
الصلاحية البنيوية تعني أن المخرَج قابل للتحليل ومكوَّن بالشكل المتوقع (مثل JSON صالح، مفاتيح مطلوبة موجودة، أنواع صحيحة).
الصلاحية التجارية تعني أن المحتوى مقبول وفق قواعد عملك (مثل: يجب أن تكون المعرفات موجودة، يجب أن تتطابق الإجماليات، نص رد الاسترداد يجب أن يتبع السياسة). عادةً تحتاج كلا الطبقتين.
عقد عملي يحدد ما يجب أن يكون صحيحًا في ثلاث نقاط:
عند وجود عقد، تصبح أدوات التحقق مجرد تنفيذ آلي له.
عامل المدخلات بشكل واسع: نص المستخدم، الملفات، حقول النماذج، حمولة واجهات برمجة التطبيقات، وبيانات الاسترجاع من الأدوات.
فحوص عالية الأثر: الحقول المطلوبة، حدّ حجم/نوع الملفات، قيم enum، حدود الطول، الترميز/JSON صالح، وصيغ روابط آمنة. هذه تقلل تشوُّش النموذج وتحمِي المحللات والقواعد البيانات التالية.
طَبِّع عندما يكون القصد واضحًا والتغيير قابل للعكس (مثل: إزالة الفراغات، تطبيع الحروف لحالات لا تؤثر على المعنى).
ارفض عندما قد يُغيّر التصحيح المعنى أو يُخفي أخطاء (مثال: تواريخ غامضة مثل "03/04/2025"، عملات غير متوقعة، HTML/JS مريب).
قاعدة مفيدة: صَحِّح الشكل، وارفُض المعنى.
ابدأ بمخطط إخراج صريح:
answer, status)ثم أضف فحوصًا دلالية (المعرفات تُحلّ، الإجماليات تتطابق، التواريخ منطقية، الاستشهادات تدعم الادعاءات). إذا فشل التحقق، لا تتعامل مع المخرَج في المسار التالي — أعد المحاولة بمطالبات أكثر تشددًا أو استخدم مسارًا احتياطيًا.
افشل سريعًا عند المشكلات التي قد تسبِّب نتائج خاطئة أو سلوكًا غير آمن: لا يمكن تحليل المخرَج، الحقول المطلوبة مفقودة، انتهاكات السياسة.
افشل برفق عندما يوجد تعافٍ آمن: تأخُّر عابر، حدود الطلب، مشاكل تنسيق بسيطة.
في كلا الحالتين فصل بين:
المحاولات مفيدة عندما يكون الفشل عابرًا (timeouts، 429، انقطاعات مؤقتة). استخدم محاولات محدودة مع تراجع أسي وjitter.
المحاولات مضرة غالبًا مع أخطاء "الإجابة الخاطئة" (عدم مطابقة المخطط، حقول مفقودة، انتهاكات سياسة). فضّل إصلاح المطالبة (تعليمات أشدّ) أو قالب معيَّن أو نموذج أصغر أو مراجعة بشرية حسب الخطر.
تأتي حالات الحافة عادةً من:
خطط لاكتشاف "المجهولات" عبر سجلات واعية بالخصوصية تسجّل أي قاعدة تحقق فشلت ومسار التعافي الذي عُمل.