17 يونيو 2025·8 دقيقة
ما الذي يستبدله الذكاء الاصطناعي في عمل المطورين (وما لا يستبدله)
تحليل عملي لمسؤوليات المطور التي يمكن للذكاء الاصطناعي استبدالها، حيث يعزّز البشر عملهم، وأي المهام تبقى تحت مسؤولية الفريق بالكامل.
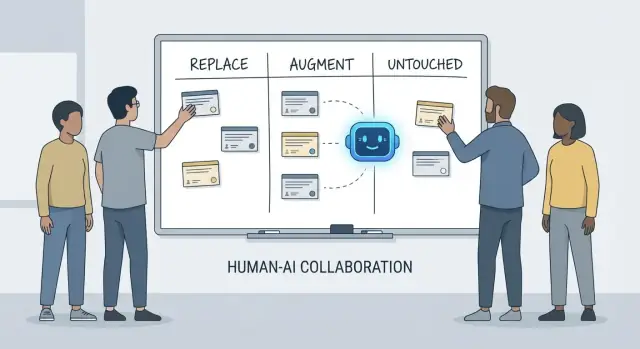
استبدال، تعزيز، دون مساس: إطار بسيط
تتحول المحادثات حول ما "سيفعله الذكاء الاصطناعي للمطورين" بسرعة إلى لُبس لأننا غالباً ما نخلط بين أدوات ومسؤوليات. فالأداة يمكنها توليد كود، تلخيص تذكرة، أو اقتراح اختبارات. والمسؤولية هي ما يزال الفريق مسؤولاً عنه عندما يكون الاقتراح خاطئاً.
يستخدم هذا المقال إطاراً بسيطاً—استبدال، تعزيز، دون مساس—لوصف العمل اليومي في فرق حقيقية مع مواعيد نهائية، كود قديم، حوادث إنتاج، وذين يتوقعون نتائج موثوقة.
ماذا يعني "استبدال" (وماذا لا يعني)
استبدال يعني أن الذكاء الاصطناعي يمكنه إكمال المهمة من البداية للنهاية معظم الوقت مع ضوابط واضحة، ودور الإنسان يتحول إلى الإشراف وفحوصات عيّنة.
الأمثلة عادة ما تكون أعمالاً محددة النطاق: توليد القالب، ترجمة الكود بين لغات، صياغة حالات اختبار متكررة، أو إنتاج توثيق أولي.
استبدال لا يعني غياب المساءلة البشرية. إذا أدى الناتج إلى كسر في الإنتاج، تسريب بيانات، أو انتهاك للمعايير، فالمسؤولية تبقى على الفريق.
ماذا يعني "تعزيز"
تعزيز يعني أن الذكاء الاصطناعي يجعل المطوّر أسرع أو أكثر دقة، لكنه لا يُنهي العمل بصورة موثوقة دون حكم بشري.
هذا هو الحال الشائع في الهندسة المهنية: ستحصل على مسودات مفيدة، نهج بديلة، تفسيرات سريعة، أو قائمة مختصرة للأخطاء المحتملة—لكن المطور يظل مُقرّراً لما هو صحيح وآمن ومناسب للمنتج.
ماذا يبقى "دون مساس"
دون مساس يعني أن المسؤولية الأساسية تبقى بقيادة بشرية لأنها تتطلب سياقاً ومقايضات ومساءلة لا تُضغط بسهولة إلى مطالبة.
فكر في: التفاوض على المتطلبات، اختيار قيود النظام على مستوى عالٍ، التعامل مع الحوادث، وضع معايير الجودة، واتخاذ قرارات لا توجد لها إجابة "صحيحة" وحيدة.
لماذا المسؤوليات هي وحدة التحليل
الأدوات تتغير بسرعة. المسؤوليات تتغير ببطء.
لذا بدلاً من السؤال "هل يمكن للذكاء الاصطناعي كتابة هذا الكود؟" اسأل "من يملك النتيجة؟" هذا التأطير يحافظ على التوقعات مبنية على الدقة والموثوقية والمساءلة—أمور أكثر أهمية من العروض البصرية المثيرة.
ماذا نعني بمسؤوليات المطور
عندما يسأل الناس ما الذي "يستبدله" الذكاء الاصطناعي في التطوير، فإنهم غالباً ما يقصدون مهام: كتابة دالة، توليد اختبارات، صياغة وثائق. الفرق، مع ذلك، لا يسلّم مهاماً—إنما يسلم نتائج. هنا تكمن أهمية مسؤوليات المطور.
حزمة المسؤوليات الاعتيادية
وظيفة المطور عادة تمتد إلى ما هو أكثر من وقت كتابة الكود:
- التسليم: تحويل فكرة غامضة إلى برنامج يعمل ويُشحن في الوقت.
- الجودة: الصلاحية، قابلية الصيانة، ومنع الانكسارات.
- الأمان والخصوصية: إعدادات افتراضية آمنة، معالجة البيانات، والوعي بالتهديدات.
- التشغيل: الحفاظ على تشغيل الخدمات، فهم أوضاع الفشل، والاستجابة للحوادث.
- التواصل: المواءمة مع المنتج، التصميم، الدعم، ومطوّرين آخرين.
تقع هذه المسؤوليات عبر دورة الحياة بأكملها—من "ماذا يجب أن نبني؟" إلى "هل هو آمن؟" إلى "ماذا يحدث عند الساعة 3 صباحاً إذا تعطل؟"
لماذا الأمر أكثر من قائمة تحقق
كل مسؤولية هي في الواقع العديد من القرارات الصغيرة: أي حالات الحافة مهمة، أي المقاييس تشير إلى الصحة، متى نقصّ النطاق، هل الإصلاح آمن للشحن، كيف تشرح مقايضة لأصحاب المصلحة. يمكن للذكاء الاصطناعي أن يساعد في تنفيذ أجزاء من هذا العمل (مسودات كود، اقتراح اختبارات، تلخيص سجلات)، لكن المسؤولية تتعلق بـامتلاك النتيجة.
أين تفشل عمليات التسليم بين الفرق
الانهيارات تحدث غالباً عند حدود التسليم:
- "سيتولى ضمان الجودة الأمر" (لكِنّ لا أحد عرّف ما معنى الجودة).
- "ستراجع الأمان" (لكن التصميم قد أغلق خيارات محفوفة بالمخاطر).
- "العمليات ستتعامل معها" (لكن الخدمة لم تُبنى لتكون قابلة للتشغيل).
عندما تكون الملكية غير واضحة، يسقط العمل في الفجوات.
حقوق القرار: من يقرر مقابل من ينفّذ
طريقة مفيدة للحديث عن المسؤوليات هي حقوق القرار:
- من يقرر المتطلبات والمقايضات والمخاطر المقبولة؟
- من ينفّذ التطبيق والتحقق؟
يمكن للذكاء الاصطناعي تسريع التنفيذ. حقوق القرار—والمساءلة عن النتائج—ما تزال بحاجة لاسم بشري مرفق بها.
الأعمال التي يمكن للذكاء الاصطناعي استبدالها غالباً (مع ضوابط)
مساعدات ترميز الذكاء الاصطناعي مفيدة حقاً عندما يكون العمل متوقعاً، منخفض المخاطر، وسهل التحقق. اعتبرها زميل مبتدئ سريع: ممتازة في إنتاج المسودات الأولى، لكنها لا تزال تحتاج إلى تعليمات واضحة وفحص دقيق.
عملياً، بعض الفرق تستخدم منصات "vibe-coding" (مثل Koder.ai) لتسريع هذه القطع القابلة للاستبدال: توليد البنى الأساسية، ربط تدفقات CRUD، وإنتاج مسودات أولية من واجهات المستخدم والباكند من المحادثة. المفتاح هو نفسه: ضوابط، مراجعة، وملكية واضحة.
القوالب منخفضة المخاطر
وقت كبير من المطورين يذهب في إعداد المشاريع وربط الأجزاء. غالباً ما يمكن للذكاء الاصطناعي توليد:
- ملفات وبُنى المجلدات الابتدائية (Controllers، Routes، DTOs)
- "كود الربط" المتكرر بين الطبقات
- نقاط نهاية CRUD بسيطة تتبع نمطاً معروفاً
الضابط هنا هو الاتساق: تأكد أنها تطابق اتفاقياتك الحالية ولا تخترع أنماطاً أو تبعيات جديدة.
إعادة الهيكلة والترحيلات الميكانيكية
عندما يكون التغيير ميكانيكياً إلى حد كبير—إعادة تسمية رمز عبر القاعدة، إعادة تنسيق، أو تحديث استخدام API بسيط—يمكن للذكاء الاصطناعي تسريع الأعمال الروتينية.
مع ذلك، اعتبرها تعديل جماعي: شغّل مجموعة الاختبارات الكاملة، افحص الفروقات بحثاً عن تغييرات سلوكية غير مقصودة، وتجنب السماح له "بتحسين" الأشياء خارج نطاق إعادة التهيئة المطلوبة.
مسودات التوثيق (مراجعة مطلوبة)
يمكن للذكاء الاصطناعي صياغة README، تعليقات داخلية، وسجلات التغيير استناداً إلى الكود وملاحظات الالتزامات. هذا يسرّع الوضوح، لكنه يمكن أن يُنتج معلومات خاطئة بصيغة واثقة.
الممارسة الجيدة: استخدم الذكاء الاصطناعي للهيكل والصياغة، ثم تحقق من كل ادعاء—خصوصاً خطوات الإعداد، افتراضات التكوين، وحالات الحافة.
توليد اختبارات أساسية كنقطة بداية
لوظائف نقية ومحددة جيداً، يمكن أن تزود اختبارات الوحدة المولّدة بالذكاء الاصطناعي تغطية أولية وتذكير بحالات الحافة. الضابط هو الامتلاك: أنت من يختار ما المهم، تضيف التأكيدات التي تعكس المتطلبات الحقيقية، وتتأكد أن الاختبارات تفشل للأسباب الصحيحة.
تلخيص الخيوط والسجلات
عند وجود محادثات طويلة في Slack، تذاكر، أو سجلات حوادث، يمكن للذكاء الاصطناعي تحويلها إلى ملاحظات موجزة وعناصر عمل. ثبتها بإعطاء السياق الكامل ثم تحقق من الحقائق الأساسية، الطوابع الزمنية، والقرارات قبل المشاركة.
الأعمال التي يعزّزها الذكاء الاصطناعي عادةً: أسرع، وليس مكتملًا
مساعدات الترميز في أفضل حالات استخدامه عندما تعرف مسبقاً ما تريد وتحتاج مساعدة للتحرك أسرع. يمكنها تقليل الوقت في "العمل الكتابي" وإبراز السياق المفيد، لكنها لا تلغي الحاجة للملكية والتحقق والحكم.
تسريع التنفيذ (مسودة أولية قوية)
مع مواصفة واضحة—المدخلات، المخرجات، حالات الحافة، والقيود—يمكن للذكاء الاصطناعي صياغة تنفيذ أولي منطقي: قوالب، تحويل بيانات، معالجات API، ترحيلات، أو إعادة هيكلة مباشرة. الفائدة هي الزخم: تحصل على شيء قابل للتشغيل بسرعة.
التحذير أن الكود الأولي غالباً ما يغفل متطلبات دقيقة (سيمانتكس الأخطاء، قيود الأداء، التوافق الترجيعي). اعتبره مسودة من متدرب: مفيد لكن غير موثوق.
اقتراح خيارات—مع مقايضات يجب عليك التحقق منها
عند اختيار نهج بين الخيارات (مثلاً: التخزين المؤقت مقابل التجميع، القفل المتفائل مقابل المتشدد)، يمكن للذكاء الاصطناعي اقتراح بدائل وسرد المقايضات. هذا مفيد للعصف الذهني، لكن المقايضات يجب أن تُفحَص أمام واقع نظامك: شكل حركة المرور، حاجات تناسق البيانات، قيود التشغيل، واتفاقيات الفريق.
فهم الكود والتنقّل في القاعدة
الذكاء الاصطناعي قوي أيضاً في شرح كود غير مألوف، الإشارة إلى أنماط، وترجمة "ما الذي يفعله هذا؟" إلى لغة بسيطة. مرفوقاً بأدوات البحث، يمكنه المساعدة في الإجابة على "أين يُستخدم X؟" وتوليد قائمة التأثير لمواقع الاستدعاء، التكوينات، والاختبارات التي تستدعي المراجعة.
بيئة عمل المطور: حلقات تغذية راجعة أفضل
توقع تحسينات عملية في جودة الحياة: رسائل خطأ أوضح، أمثلة صغيرة، ومقتطفات جاهزة للنسخ واللصق. هذه تقلل الاحتكاك، لكنها لا تستبدل المراجعة الحذرة، التشغيل المحلي، والاختبارات المستهدفة—خصوصاً للتغييرات التي تؤثر على المستخدمين أو أنظمة الإنتاج.
فهم المنتج والمتطلبات: يبقى بقيادة بشرية
يمكن للذكاء الاصطناعي مساعدتك في كتابة وصقل المتطلبات، لكنه لا يمكنه أن يقرر ما الذي يجب بناؤه أو لماذا هذا مهم. فهم المنتج متجذر في السياق: أهداف الأعمال، ألم المستخدم، قيود المنظمة، حالات الحافة، وتكلفة الخطأ. هذه المدخلات تعيش في المحادثات والتاريخ والمساءلة—أشياء يمكن للنموذج تلخيصها، لكنها لا تملكها.
تحويل الأهداف الضبابية إلى متطلبات قابلة للبناء
الطلبات المبكرة غالباً ما تبدو مثل "اجعل عملية الانضمام أسهل" أو "قِلّل تذاكر الدعم". وظيفة المطور هي ترجمة ذلك إلى متطلبات مقبولة ومعايير قبول.
هذه الترجمة عمل بشري لأنه يعتمد على أسئلة استقصائية وحكم:
- أي شريحة مستخدم ننميها، وأي سلوك يجب أن يتغير؟
- ما الذي يُعتَبَر "منجزاً"، وكيف سنقيسه؟
- أي قيود غير قابلة للتفاوض (خصوصية، أداء، مواعيد تسليم)؟
يمكن للذكاء الاصطناعي اقتراح مقاييس أو مسودات معايير قبول، لكنه لن يعرف أي القيود حقيقية ما لم يقدّمها شخص—ولن يعترض عندما يكون الطلب متناقضاً بذاته.
المقايضات وإدارة التوقعات
عمل المتطلبات هو المكان الذي تظهر فيه المقايضات غير المريحة: الوقت مقابل الجودة، السرعة مقابل القابلية للصيانة، ميزات جديدة مقابل الاستقرار. يحتاج الفريق لشخص يوضح المخاطر، يقترح خيارات، ويوائم أصحاب المصلحة على العواقب.
المواصفات الجيدة ليست نصاً فقط؛ إنها سجل قرار. يجب أن تكون قابلة للاختبار والتنفيذ، بتعريفات حادة (المدخلات، المخرجات، حالات الحافة، وأوضاع الفشل). يمكن للذكاء الاصطناعي مساعدة في هيكلة المستند، لكن مسؤولية الصحة—والقول "هذا غامض ونحتاج قراراً"—تبقى بشرية.
قرارات تصميم النظام والمعماريات
أطلق نموذجًا أوليًا متكاملًا
حوّل المواصفات إلى واجهة React وواجهة خلفية بـ Go وPostgreSQL في دردشة إرشادية واحدة.
تصميم النظام هو المكان الذي يتحول فيه "ماذا نبني؟" إلى "بماذا نبني وماذا سيحدث عند الأخطاء؟" يمكن للذكاء الاصطناعي مساعدتك في استكشاف الخيارات، لكنه لا يملك تبعاتها.
اختيار معمارية تتناسب مع الواقع
الاختيار بين مونوثول، مونوثولٍ مقسّم، مايكروسيرفيسز، سيرفرلس، أو منصات مُدارة ليس اختباراً بإجابة صحيحة واحدة. إنه مسألة توافق: الحجم المتوقع، حدود الميزانية، وقت الوصول إلى السوق، ومهارات الفريق.
يمكن للمساعد تلخيص الأنماط واقتراح بنى مرجعية، لكنه لن يعرف أن فريقك يتناوب المناوبة أسبوعياً، أن عملية التوظيف بطيئة، أو أن عقد مزود قاعدة البيانات يتجدد في الربع القادم. تلك التفاصيل غالباً ما تقرر نجاح المعمارية.
إبراز المقايضات بوضوح
المعماريات الجيدة في الغالب مقايضات: البساطة مقابل المرونة، الأداء مقابل التكلفة، السرعة اليوم مقابل القابلية للصيانة لاحقاً. يمكن للذكاء الاصطناعي إنتاج قوائم إيجابيات/سلبيات بسرعة، وهو مفيد—خصوصاً لتوثيق القرار.
لكن لا يستطيع تحديد الأولويات عندما تؤذي المقايضات. مثلاً، "نقبل استجابة أبطأ قليلاً للحفاظ على بساطة النظام وقابلية تشغيله" هو قرار أعمال، لا مسألة تقنية بحتة.
الحدود، ملكية البيانات، وأنماط الفشل
تحديد حدود الخدمات، من يملك أي بيانات، وماذا يحدث أثناء الانقطاعات الجزئية يتطلب سياقاً إنتاجياً عميقاً. يمكن للذكاء الاصطناعي العصف بأوضاع الفشل ("ماذا لو تعطل مزود الدفع؟"), لكنه لا يقرر سلوك التوقع، رسائل العملاء، أو خطة التراجع—وهذه قرارات بشرية.
واجهات برمجة تطبيقات تبقى قابلة للاستخدام
تصميم API هو تصميم عقد. يمكن للذكاء الاصطناعي توليد أمثلة واكتشاف تناقضات، لكن عليك أن تقرر النسخ، التوافق الترجيعي، وما ستدعمه على المدى الطويل.
متى لا نبني (أو متى نحذف)
ربما أعظم قرار معماري هو قول "لا"—أو حذف ميزة. لا يمكن للذكاء الاصطناعي قياس تكلفة الفرصة أو المخاطرة السياسية. الفرق هي التي تقرر ويجب أن تفعل.
التصحيح وتحليل السبب الجذري عملياً
التصحيح هو المكان الذي يظهر فيه الذكاء الاصطناعي بشكل لافت—وحيث يمكنه إضاعة الوقت بهدوء. يمكن للمساعد مسح السجلات، الإشارة إلى مسارات كود مريبة، أو اقتراح إصلاح "يبدو مناسباً". لكن تحليل السبب الجذري ليس مجرد توليد تفسيرات؛ إنه إثبات واحد.
الذكاء الاصطناعي يقترح؛ أنت تؤكد السبب الجذري
عامل ناتج الذكاء الاصطناعي كفرضيات، لا استنتاجات. كثير من الأخطاء لها أسباب محتملة متعددة، والنموذج معرض لاختيار قصة مرتبة تتماشى مع مقتطف الكود الذي ألصقته، لا واقع النظام الجاري.
سير عمل عملي:
- اطلب من الذكاء الاصطناعي أسباباً محتملة وما الدليل الذي يميّزها.
- أعِد إنتاج المشكلة واجمع ذلك الدليل.
- فقط بعد ذلك اقبل إصلاحاً (وتحقق أنه يزيل الشرط الفاشل فعلاً).
إعادة الإنتاج وجمع الأدلة ما زالا يقودهما البشر
إعادة الإنتاج الموثوقة هي قوة خارقة للتصحيح لأنها تحول اللغز إلى اختبار. يمكن للذكاء الاصطناعي مساعدتك في كتابة إعادة إنتاج دنيا، صياغة سكربتات تشخيص، أو اقتراح تسجيلات إضافية، لكنك من يقرر أي إشارات مهمة: معرفات الطلب، التوقيت، اختلافات البيئة، أعلام الميزة، شكل البيانات، أو التزامن.
عندما يبلغ المستخدمون عن أعراض ("التطبيق تجمد"), ما زال عليك ترجمتها إلى سلوك نظامي: أي نقطة نهاية توقفت، أي مهلات نفذت، أي إشارات ميزانية خطأ تغيّرت. هذا يتطلب سياقاً: كيف يُستخدم المنتج وما معناها "الطبيعي".
تجنّب التفسيرات المقبولة ظاهرياً لكنها خاطئة
إذا كان الاقتراح لا يمكن التحقق منه، افترض أنه خاطئ حتى يثبت العكس. فضّل التفسيرات التي تُنبئ باختبار قابل للفحص (مثال: "سيحدث هذا فقط على حمولات كبيرة" أو "فقط بعد تسخين الكاش").
إصلاح سريع، تراجع، أم إعادة تصميم؟
حتى بعد العثور على السبب، يبقى القرار صعباً. يمكن للذكاء الاصطناعي سرد المقايضات، لكن البشر يختارون الردّ:
- إصلاح سريع لوقف النزيف.
- التراجع لاستعادة حالة معروفة جيدة.
- إعادة التصميم إذا كشف الفشل عدم تطابق أعمق.
تحليل السبب الجذري هو في النهاية مساءلة: امتلاك الشرح، الإصلاح، والثقة أنه لن يعود.
مراجعة الكود: الحكم والمعايير لا تتأتمت
امتلك الكود الذي تطلقه
حافظ على التحكم عبر تصدير قاعدة الكود وتطبيق معايير فريقك أثناء المراجعة.
مراجعة الكود ليست مجرد قائمة تحقق لمشاكل النمط. إنها اللحظة التي يقرر فيها الفريق ما هو مستعدون لصيانته ودعمه ومساءلته. يمكن للذكاء الاصطناعي أن يساعدك على الرؤية أكثر، لكنه لا يستطيع أن يقرر ما الذي يهم، ما يناسب نية المنتج، أو ما تقبله فريقك من مقايضات.
ما يجيد الذكاء الاصطناعي في المراجعات
يمكن لمساعدات الترميز أن تكون كعين ثانية لا تكل. يمكنها سريعاً:
- الإشارة إلى أخطاء محتملة، أنماط مريبة، فحوص مفقودة للـnull، أو تعاملات سلسلة غير آمنة.
- اقتراح تسمية أوضح، إعادة هيكلة، أو تبسيط تدفق التحكم.
- الإشارة إلى تنسيقات متضاربة أو تكرار واضح.
- توليد أسئلة مراجعة ("ماذا يحدث إن أعاد هذا API قائمة فارغة؟").
استخدمها لتقليل الوقت بين فتح PR وملاحظة المخاطر.
ما يزال يحتاج حكم بشري
مراجعة الصلاحية ليست فقط ما إذا كان الكود يُترجم. البشر يربطون التغيير بسلوك المستخدم الحقيقي، قيود الإنتاج، والصيانة على المدى الطويل. لا زال المراجع بحاجة إلى تقرير:
- ماذا نشحن: يمكن للذكاء الاصطناعي تعداد المشاكل، لكنه لا يختار أيها مانع للإصدار.
- قابلية القراءة والصيانة: الكود "صحيح تقنياً" قد يظل مربكاً أو هشاً.
- حالات الحافة والفجوات البيئية: كثير من الإخفاقات "يعمل على جهازي"—تكوين، شكل البيانات، تزامن، أو توقيت النشر. لا يمكن للذكاء الاصطناعي استنتاج واقع التشغيل بثقة.
- المعايير والنية: الفريق فقط يعرف اتفاقياته، تحمل المخاطر، وأهداف المنتج. تغيير قد يكون نظيفاً تقنياً ومع ذلك خطأً سلوكياً.
سير عمل عملي: الذكاء الاصطناعي كمراجع مشارك
عامل الذكاء الاصطناعي كمراجع ثانٍ، لا كموافق نهائي. اطلب منه تمريرة مستهدفة (فحوص أمان، حالات الحافة، التوافق الترجيعي)، ثم اتخذ قراراً بشرياً حول النطاق والأولوية وما إذا كان التغيير يتماشى مع معايير الفريق ونية المنتج.
استراتيجية الاختبار وملكية الجودة
يمكن لمساعدات الذكاء الاصطناعي توليد اختبارات بسرعة، لكنها لا تملك الجودة. مجموعة الاختبارات هي رهانات حول ما يمكن أن ينكسر، ما يجب ألا ينكسر، وما أنت على استعداد لشحنه دون إثبات كل حالة حافة. هذه الرهانات قرارات منتج وهندسة—لا تزال تُتخذ بواسطة الناس.
الذكاء الاصطناعي يصيغ اختبارات؛ البشر يحددون الأهداف
المساعدون جيدون في إنتاج هيكلية اختبار الوحدة، محاكاة الاعتماديات، وتغطية "المسار السعيد" من التنفيذ. ما لا يستطيعون القيام به بثقة هو تحديد أية تغطية مهمة.
يحدد البشر:
- أي الوحدات تحتاج تغطية عميقة لأنها حرجة أو تتغير كثيراً.
- ماذا يعني "منجز" لعملية إعادة هيكلة مخاطرة مقابل إصلاح صغير.
- متى نستثمر في اختبارات انحدار مقابل مراقبة وخطط تراجع.
اختيار الخلطة المناسبة من أنواع الاختبارات
تحتاج معظم الفرق لاستراتيجية مكدسة، لا "مزيد من الاختبارات" فحسب. يمكن للذكاء الاصطناعي المساعدة في كتابة الكثير منها، لكن الاختيار والحدود قادتها البشر:
- اختبارات الوحدة لقواعد الأعمال وحالات الحافة المعقدة.
- اختبارات التكامل لتفاعلات قاعدة البيانات/الرسائل/الخدمات.
- اختبارات نهاية لنهاية لرحلات المستخدم الحرِجة (قليلة، مستقرة، عالية القيمة).
- اختبارات العقد للحفاظ على توافق الواجهات بين الفرق/الخدمات.
- اختبارات الأداء لحماية الكمون والتكلفة تحت الحمولة.
تجنّب الاختبارات المتقلبة والثقة الكاذبة
الاختبارات المولدة آلياً كثيراً ما تُقلّد التنفيذ الداخلي، فتنشئ تأكيدات هشة أو إعدادات مفرطة في المحاكاة تمر حتى عندما يفشل السلوك الحقيقي. يمنع المطورون ذلك بـ:
- اختبار السلوك المرصود، لا تفاصيل التنفيذ الداخلية.
- الحفاظ على بيانات حتمية والتحكم بالزمن والعشوائية والاتصالات الشبكية.
- مراجعة حالات الفشل لتقرير: خطأ حقيقي، خطأ في الاختبار، أم مشكلة بيئية.
مواءمة الاستراتيجية مع المخاطر وتواتر النشر
استراتيجية جيدة تطابق طريقة الشحن. عمليات نشر أسرع تحتاج تحققاً آلياً أقوى ومسارات تراجع أوضح؛ عمليات أكثر بطئاً يمكنها تحمل تحقق مسبق أثقل. مالك الجودة هو الفريق، لا الأداة.
قياس النتائج المهمة
الجودة ليست نسبة تغطية. تابع ما إذا كانت الاختبارات تحسّن النتائج: حوادث إنتاج أقل، استرداد أسرع، وتغييرات أكثر أماناً (تراجعات أصغر، نشرات واثقة أسرع). يسرّع الذكاء الاصطناعي العمل، لكن المساءلة تبقى على المطورين.
الأمن والخصوصية والامتثال
عمل الأمن أقل في توليد الكود وأكثر في اتخاذ مقايضات ضمن قيود حقيقية. يمكن للذكاء الاصطناعي إظهار قوائم مرجعية وأخطاء شائعة، لكن قرار المخاطرة يبقى فريقي.
نمذجة التهديدات تحتاج سياقاً
نمذجة التهديدات ليست تمريناً عاماً—ما يهم يعتمد على أولويات العمل، المستخدمين، وأوضاع الفشل. يمكن للمساعد اقتراح تهديدات نموذجية (حقن، تحطيم المصادقة، إعدادات غير آمنة)، لكنه لن يعرف أي منها مكلف فعلاً لمنتجك: اختراق حساب، تسريب بيانات، أم تعطيل الخدمة، أو أي الأصول قانونياً حساسة.
مخاطر التطبيق الخاصة لا تشبه أنماطاً جامدة
الذكاء الاصطناعي جيد في التعرف على الأنماط المعروفة، لكن كثيراً من الحوادث تنشأ من تفاصيل خاصة بالتطبيق: حالة صلاحيات، نهاية إدارية "مؤقتة"، أو مسار عمل يتجاوز الموافقات. تلك المخاطر تتطلب قراءة نية النظام، لا مجرد الكود.
الأسرار والصلاحيات والاحتفاظ بيانات خيارٌ واعٍ
الأدوات قد تذكّرك بعدم تحرير المفاتيح، لكنها لا تملك السياسة الكاملة:
- أين تخزن الأسرار (خزّن، CI، وقت التشغيل) وكيف يتم تدويرها.
- أدوار الأقل امتياز والمراجعات الدورية للوصول.
- احتفاظ البيانات: ماذا نخزن، وكم مدة الاحتفاظ، ومن يمكنه التصدير.
تبعيات الطرف الثالث ومخاطر سلسلة التوريد
قد ينبهك الذكاء الاصطناعي إلى مكتبات قديمة، لكن الفرق ما تزال بحاجة لممارسات: تثبيت الإصدارات، التحقق من المصدر، مراجعة التبعيات العابرة، واتخاذ قرار قبول المخاطر أو الاستثمار في العلاج.
الامتثال والتدقيق يتطلبان دليلاً
الامتثال ليس "أضف تشفير". إنه ضوابط، وثائق، ومساءلة: سجلات الوصول، مسارات الموافقة، إجراءات الحوادث، ودليل أنك اتبعتها. يمكن للذكاء الاصطناعي صياغة قوالب، لكن البشر يجب أن يتحققوا من الأدلة ويوقعوا—لأن هذا ما يعتمد عليه المدققون والعملاء.
التشغيل والموثوقية واستجابة الحوادث
انتقل من المسودة إلى النشر
انشر واستضف تطبيقك عندما تكون جاهزًا، مع إمكانية التراجع عند الحاجة.
يمكن للذكاء الاصطناعي تسريع أعمال التشغيل، لكنه لا يتولّى الملكية. الموثوقية سلسلة قرارات تحت عدم اليقين، وتكلفة القرار الخاطئ عادة أعلى من تكلفة قرار بطيء.
أين يساعد الذكاء الاصطناعي يومياً
الذكاء الاصطناعي مفيد في صياغة وصيانة الوثائق التشغيلية—runbooks، قوائم التحقق، و"إذا حدث X فجَرّب Y"—كما يمكنه تلخيص السجلات، تجميع التنبيهات المتشابهة، واقتراح فروض أولية.
هذا يسرّع التجاوب مع:
- لوحات المراقبة ووصف التنبيهات.
- ملاحظات السعة وخوارزميات التوسع.
- قوالب تقارير ميزانية الأخطاء.
هذه مسرّعات عظيمة، لكنها ليست العمل الحقيقي.
الأجزاء التي تبقى مملوكة من قبل البشر
نادراً ما تتبع الحوادث السيناريو المكتوب. مهندسو المناوبة يتعاملون مع إشارات غامضة، أعطال جزئية، ومقايضات فوضوية بينما الساعة تدق. يمكن للذكاء الاصطناعي اقتراح أسباب مرجّحة، لكنه لا يقرر بثقة إذا كان يجب إبلاغ فريق آخر، تعطيل ميزة، أو قبول تأثير قصير الأمد على العملاء للحفاظ على سلامة البيانات.
سلامة النشر أيضاً مسؤولية بشرية. الأدوات يمكن أن توصي بالتراجع، أعلام الميزة، أو إصدارات مرحلية، لكن الفرق ما تزال تختار المسار الأكثر أماناً مع مراعاة المجال التأثيري وسياق العمل.
ما بعد الحوادث: التعلم هو الهدف
يمكن للذكاء الاصطناعي صياغة جداول زمنية وسحب أحداث رئيسية من الدردشة والتذاكر والمراقبة. يبقى الجزء الحاسم للبشر: تحديد ما معنى "جيد"، ترتيب الإصلاحات، وتنفيذ تغييرات تمنع التكرار (ليس مجرد علاج نفس العَرَض).
إذا عاملت الذكاء الاصطناعي كمساعد في وثائق التشغيل واكتشاف الأنماط—لا كقائد حادث—ستحصل على سرعة دون التخلي عن المساءلة.
التواصل الفريق، الإرشاد، والملكية
يمكن للذكاء الاصطناعي شرح المفاهيم بوضوح وعند الطلب: "ما هو CQRS؟"، "لماذا يحدث هذا الانسداد؟"، "لخّص هذا PR." هذا يساعد الفرق على التحرك أسرع. لكن التواصل في العمل ليس مجرد نقل معلومات—إنه بناء ثقة، إقامة عادات مشتركة، وتقديم التزامات يمكن الاعتماد عليها.
الإعداد: أكثر من وثائق
المطورون الجدد لا يحتاجون إجابات فحسب؛ يحتاجون سياقاً وعلاقات. يمكن للذكاء الاصطناعي تلخيص الوحدات، اقتراح مسارات قراءة، وترجمة المصطلحات. البشر ما يزالون من يعلم ما المهم هنا: أي المقايضات يفضل الفريق، ما معنى "جيد" في القاعدة الحالية، ومن تتحدث إليه إذا شعرت بأن شيئاً ما خطأ.
المواءمة عبر الأدوار
معظم احتكاكات المشاريع تظهر بين الأدوار: المنتج، التصميم، ضمان الجودة، الأمان، الدعم. يمكن للذكاء الاصطناعي صياغة ملاحظات اجتماعات، اقتراح معايير قبول، أو إعادة صياغة ملاحظات بنبرة محايدة. الناس ما يزالون من يتفاوضون على الأولويات، يحلون الغموض، ويلاحظون عندما يكون صاحب مصلحة "موافقاً" دون أن يكون بالفعل كذلك.
تعريف الإنجاز وحدود الملكية
تفشل الفرق عندما تكون المسؤولية غامضة. يمكن للذكاء الاصطناعي توليد قوائم تحقق، لكنه لا يفرض المساءلة. يجب على البشر تحديد ما يعنيه "مُنْجَز" (اختبارات؟ وثائق؟ خطة نشر؟ مراقبة؟)، ومن يملك ماذا بعد الدمج—خصوصاً عندما يخفي الكود المولَّد آلياً تعقيدات.
قائمة تحقق: استخدام مسؤول للذكاء الاصطناعي في سير عمل الفريق
- الإفصاح عن استخدام الذكاء الاصطناعي عندما يؤثر على القرارات، التقديرات، أو الكود المؤلف.
- التحقق من الحقائق: روابط، واجهات برمجة التطبيقات، ادعاءات الأمان، و"أفضل الممارسات" قبل المشاركة.
- اجعل المطالبات خالية من الأسرار (مفاتيح، بيانات العملاء، تفاصيل الحوادث).
- عامل نواتج الذكاء الاصطناعي كمسوّدة؛ عيّن مالكاً بشرياً لكل قرار.
- دوّن قواعد الفريق: متى يُسمح بالذكاء الاصطناعي، ومتى لا، وراجِع التوقّعات.
- فضّل تغييرات صغيرة قابلة للمراجعة—تجنّب إعادة هيكلة كبيرة تلقائياً.
الأسئلة الشائعة
ماذا يعني إطار العمل استبدال / تعزيز / دون مساس فعلاً؟
يفصل هذا الإطار بين المهام (أشياء يمكن للأداة أن تساعد في تنفيذها) والمسؤوليات (النتائج التي يكون فريقك مسؤولاً عنها).
- استبدال: يمكن للذكاء الاصطناعي إكمال المهمة من البداية للنهاية معظم الوقت مع ضوابط؛ البشر يشرفون.
- تعزيز: يسرّع الذكاء الاصطناعي عملك، لكنك ما زلت تقرر ما هو الصحيح والآمن.
- دون مساس: تبقى المسؤولية بشرية لأن الأمر يعتمد على السياق والمقايضات والمساءلة.
لماذا نركز على المسؤوليات بدل المهام؟
لأن الفرق لا تسلّم "مهام" فقط، بل تسلّم نتائج.
حتى لو كتب مساعد نصّياً كوداً أو اختبر أو صاغ وثائق، يظل فريقك مسؤولاً عن:
- الصحة ومنع الانكسارات
- الأمان والخصوصية
- القابلية للتشغيل وتأثير الحوادث التشغيلية
- تلبية المتطلبات الحقيقية (وليس فقط ما في المطالبة)
أي أنواع من عمل المطورين يمكن للذكاء الاصطناعي استبدالها بأمان؟
يعني "استبدال" العمل المحكوم والقابل للتحقق ومنخفض المخاطر حيث يكون من السهل اكتشاف الأخطاء.
مرشحات جيدة تشمل:
- كود القالب والربط المتبع ضمن نمط محدد
- إعادة تهيئة ميكانيكية (إعادة تسمية، ترحيل API بسيطة)
- مسودات أولية للوثائق أو سجلات التغييرات (مع مراجعة)
- اختبارات بداية لوظائف نقية ومحددة جيداً
ما الضوابط التي تجعل استبدال العمل عملياً وموثوقاً في فرق حقيقية؟
استخدم ضوابط تجعل الأخطاء واضحة ورخيصة الاكتشاف:
- قيد الطلب: نطاق دقيق، الملفات، الاتفاقيات، التبعيات
- طلب تشغيل الاختبارات (بالإضافة إلى lint/فحوصات الأنواع)
- راجع الفروقات كما لو أنها تحرير جماعي—انتبه لـ"تحسينات إضافية" غير مرغوبة
- تحقق من أي ادعاءات فعلية في الوثائق (خطوات الإعداد، الافتراضات، الحواف)
- اجعل التغييرات صغيرة وقابلة للتراجع
لماذا يكون الذكاء الاصطناعي عادة تعزيزاً بدل استبدال للعمل الهندسي المهني؟
لأن عمل المهنيين عادةً يحتوي على قيود مخفية لن يتعرّف عليها النموذج بالموثوقية الكافية:
- توقعات التوافق الترجيعي
- ميزانيات الأداء والكمون
- حقائق تشغيلية (نشر، مناوبات، أعلام الميزة)
- نية المنتج ودلالات الحواف
عامِل مخرجات الذكاء الاصطناعي كمَسَوَّدة تُعدِّلها ليناسب نظامك، لا كحل نهائي موثوق.
كيف أستخدم الذكاء الاصطناعي للتصحيح دون أن يضللني؟
استخدمه لتوليد فرضيات وخطة أدلة، لا نتائج نهائية.
حَلقة عملية:
- اطلب من الذكاء الاصطناعي أسباباً محتملة وما الدليل الذي يميز بينها
- اعمل على إعادة إنتاج المشكلة وجمع الدليل (سجلات، تتبعات، إعدادات، شكليات البيانات)
- لا تقبل إصلاحاً إلا إذا غيّر سلوك الفشل الملاحظ ومنع تكراره
إذا لم تستطع التحقق من اقتراحٍ ما، افترض أنه خاطئ حتى يثبت العكس.
ما دور الذكاء الاصطناعي في مراجعة الكود؟
يمكن للذكاء الاصطناعي أن يساعدك على ملاحظة المشكلات أسرع، لكن البشر يقرّرون ما المقبول للشحن.
مطالب مراجعة مفيدة للذكاء الاصطناعي:
- "عدّد حالات الحافة ومواطن الفشل المحتملة."
- "تحقق من مخاطر الأمان/الخصوصية والإعدادات غير الآمنة."
- "نَبّه لمخاوف التوافق الترجيعي."
ثم قم بجولة بشرية للحكم على النية، القابلية للصيانة، ومخاطر النشر (ما هو معيق للشحن وما يمكن متابعته لاحقاً).
هل يمكن للذكاء الاصطناعي أن يتولّى الاختبار وملكية الجودة؟
يمكن للذكاء الاصطناعي لمسودّات الاختبارات بسرعة، لكنه لا يملك قرار أي تغطية مهمة فعلاً.
حافظ على مسؤولية البشر عن:
- تحديد المزيج الصحيح من أنواع الاختبارات (وحدات، تكامل، نهاية لنهاية، عقدية، أداء)
- منع الاختبارات المتقلبة (تحكم بالزمن والعشوائية والشبكات)
- اختبار السلوك بدلاً من تفاصيل التنفيذ
- مواءمة الجهود مع المخاطر وتواتر النشر
استخدم الذكاء الاصطناعي للبناء السريع والعصف الذهني لحالات الحافة، لا كمالك للجودة.
لماذا تُصنّف المتطلبات وتصميم النظام ضمن المسؤوليات التي تبقى دون مساس؟
لأن هذه القرارات تعتمد على سياق العمل والمساءلة الطويلة الأمد.
الذكاء الاصطناعي يمكن أن:
- يقترح بنى معمارية ومقايضات
- يعصف بخيارات حالات الفشل ويكتشف تضارب واجهات برمجة التطبيقات
- يصاغ مستندات القرار
لكن البشر يحددون:
كيف أستخدم الذكاء الاصطناعي بأمان مع قيود الأمان والخصوصية والامتثال؟
لا تلصق أسراراً أو بيانات حساسة بالتعليمات.
قواعد عملية:
- احذف المفاتيح، الرموز، بيانات الاعتماد، والنقاط الطرفية المملوكة
- تجنّب مُعرِّفات العملاء وسجلات الحوادث غير المجهّلة إذا كانت حساسة
- اجعل المطالبات تركز على أقل مثال قابل لإعادة الإنتاج ومُجرّد السجلات
- اتفق فريقياً على الكشف عن استخدام الذكاء الاصطناعي عندما يؤثر على القرارات، التقديرات، أو الكود المؤلف