21 سبتمبر 2025·8 دقيقة
Meilisearch للبحث الفوري على الخادم في تطبيقاتك
تعلّم كيفية إضافة Meilisearch إلى خادمك للبحث السريع المتحمل للأخطاء: الإعداد، الفهرسة، قواعد الترتيب، الفلاتر، الأمان، وخوارزميات التوسع الأساسية.
تعلّم كيفية إضافة Meilisearch إلى خادمك للبحث السريع المتحمل للأخطاء: الإعداد، الفهرسة، قواعد الترتيب، الفلاتر، الأمان، وخوارزميات التوسع الأساسية.
البحث على جانب الخادم يعني أن الاستعلام يُعالَج على الخادم الخاص بك (أو خدمة بحث مخصّصة)، وليس داخل المتصفح. يرسل تطبيقك طلب بحث، يقوم الخادم بتنفيذه مقابل فهرس، ويعيد النتائج مرتبة.
هذا مهم عندما تكون مجموعة بياناتك كبيرة للغاية بحيث لا يمكن إرسالها إلى العميل، عندما تحتاج إلى تناسق في الصلة عبر المنصات، أو عندما يكون التحكم في الوصول أمرًا لا تفاوض فيه (مثل أدوات داخلية حيث يجب أن يرى المستخدمون ما يُسمح لهم فقط). كما أنه الخيار الافتراضي عندما تريد تحليلات، تسجيل، وأداء متوقع.
الناس لا يفكرون في محركات البحث — إنهم يقيمون التجربة. تدفق بحث “فوري” جيد عادةً يعني:
إذا افتُقِد أحد هذه العناصر، يعوض المستخدمون بمحاولات استعلام مختلفة، التمرير أكثر، أو التخلي عن البحث تمامًا.
هذه المقالة هي سير عمل عملي لبناء تلك التجربة باستخدام Meilisearch. سنغطي كيفية إعداده بأمان، كيفية هيكلة ومزامنة بياناتك المفهرسة، كيفية ضبط الصلة وقواعد الترتيب، كيفية إضافة الفلاتر/الفرز/الصفات، وكيفية التفكير في الأمان والتوسيع حتى يبقى البحث سريعًا مع نمو التطبيق.
Meilisearch مناسب جدًا لـ:
الهدف طوال الوقت: نتائج تبدو فورية، دقيقة، وموثوقة — دون تحويل البحث إلى مشروع هندسي ضخم.
Meilisearch هو محرك بحث تشغّله بجانب تطبيقك. ترسله إليه مستندات (مثل منتجات، مقالات، مستخدمين، أو تذاكر دعم)، وهو يبني فهرسًا مُحسّنًا للبحث السريع. ثم يستعلم تطبيقك الخلفي (أو الواجهة الأمامية) Meilisearch عبر واجهة HTTP بسيطة ويحصل على نتائج مرتبة في أجزاء من الثانية.
يركز Meilisearch على الميزات التي يتوقعها الناس من البحث الحديث:
صُمِّم ليبدو سريع الاستجابة ومتسامحًا، حتى عندما يكون الاستعلام قصيرًا، أو قليلاً خاطئًا، أو غامضًا.
Meilisearch ليس بديلاً لقاعدة البيانات الأساسية لديك. تظل قاعدة البيانات مصدر الحقيقة للكتابات، المعاملات، والقيود. يخزن Meilisearch نسخة من الحقول التي تختار جعلها قابلة للبحث أو الفلترة أو العرض.
نموذج ذهني جيد هو: قاعدة البيانات للتخزين والتحديث، Meilisearch لإيجادها بسرعة.
يمكن أن يكون Meilisearch سريعًا للغاية، لكن النتائج تعتمد على بعض العوامل العملية:
لمجموعات البيانات الصغيرة إلى المتوسطة، يمكنك غالبًا تشغيله على آلة واحدة. مع نمو الفهرس، سترغب في اتخاذ قرارات أكثر دقة بشأن ما تفهرسه وكيف تحافظ على تحديثه — مواضيع سنغطيها لاحقًا.
قبل أن تثبت أي شيء، قرر ما الذي ستبحث عنه فعليًا. سيبدو Meilisearch “فوريًا” فقط إذا كانت فهارسك ووثائقك تتطابق مع طريقة تصفح الناس لتطبيقك.
ابدأ بسرد الكيانات القابلة للبحث — عادةً المنتجات، المقالات، المستخدمون، مستندات المساعدة، المواقع، إلخ. في العديد من التطبيقات، أبسط نهج هو فهرس واحد لكل نوع كيان (مثلاً products, articles). هذا يحافظ على قواعد الترتيب والفلاتر متوقعة.
إذا كانت تجربة المستخدم تبحث عبر عدة أنواع في مربع واحد ("ابحث عن كل شيء"), يمكنك الاحتفاظ بفهارس منفصلة ودمج النتائج في الخادم، أو إنشاء فهرس "عالمي" مخصص لاحقًا. لا تجبر كل شيء في فهرس واحد إلا إذا كانت الحقول والفلاتر متوافقة حقًا.
كل وثيقة تحتاج إلى معرف ثابت (مفتاح أساسي). اختر شيئًا:\n\n- لا يتغير أبدًا (أو يتغير نادراً جداً)\n- فريد داخل الفهرس\n- موجود بالفعل في قاعدة بياناتك (مثل id, sku, slug)
بالنسبة لشكل الوثيقة، فضّل الحقول المسطحة عندما تستطيع. الهياكل المسطحة أسهل للفلترة والفرز. الحقول المتداخلة جيدة عندما تمثل مجموعة ضيقة وغير متغيرة (مثل كائن author)، لكن تجنّب التداخل العميق الذي يعكس كامل مخطط العلاقات لديك—وثائق البحث يجب أن تكون مُحسّنة للقراءة، لا مصممة كقاعدة بيانات.
طريقة عملية لتصميم الوثائق هي وسم كل حقل بدور واحد:\n\n- قابلة للبحث: النص الذي يكتبه الناس (title, name, description)\n- قابلة للفلترة: السمات المستخدمة كقيود (category, price range, status, tags)\n- معروضة: ما تعيده للواجهة (title, thumbnail URL, short snippet)
هذا يمنع خطأ شائع: فهرسة حقل "لمجرد الاحتمال" ثم تتساءل لاحقًا لماذا النتائج صاخبة أو الفلاتر بطيئة.
"اللغة" قد تعني أمورًا مختلفة في بياناتك:\n\n- لغة الوثيقة (كل مقال له lang: "en")\n- لغة المستخدم (لغة واجهة المستخدم)\n- الحقول ذات اللغات المختلطة (أسماء المنتجات بعدة لغات)
قرّر مبكرًا ما إذا كنت ستستخدم فهارس منفصلة لكل لغة (بسيطة وقابلة للتوقّع) أو فهرس واحد مع حقول اللغة (فهارس أقل، ومنطق أكثر). الإجابة الصحيحة تعتمد على ما إذا كان المستخدمون يبحثون بلغة واحدة في كل مرة وكيف تخزن الترجمات.
تشغيل Meilisearch بسيط، لكن "آمن افتراضيًا" يتطلب بعض الخيارات المدروسة: أين تنشره، كيف تحفظ البيانات، وكيف تتعامل مع المفتاح الرئيسي.
التخزين: يكتب Meilisearch فهرسه إلى القرص. ضع دليل البيانات على تخزين دائم وموثوق (ليس تخزين حاوية زائل). خطط للسعة مع النمو: يمكن أن تتسع الفهارس بسرعة مع نصوص كبيرة وعدد كبير من السمات.
الذاكرة: خصّص ذاكرة كافية للحفاظ على استجابة البحث تحت الحمل. إذا لاحظت تبديل الذاكرة الافتراضية (swapping)، سيتأثر الأداء.
النسخ الاحتياطي: قم بالنسخ الاحتياطي لدليل بيانات Meilisearch (أو استخدم لقطات على مستوى التخزين). جرّب الاستعادة مرة واحدة على الأقل؛ النسخة الاحتياطية التي لا يمكنك استعادتها مجرد ملف.
المراقبة: راقب CPU، RAM، استخدام القرص وI/O القرص. كذلك راقب صحة العملية وسجل الأخطاء. على الأقل، أرسل تنبيهًا إذا توقفت الخدمة أو نفد القرص.
شغّل Meilisearch دائمًا بمفتاح ماستر في أي شيء يتجاوز التطوير المحلي. خزّنه في مدير أسرار أو مخزن متغيرات بيئة مشفر (لا في Git، ولا في ملف .env نصي مُرتكب في المستودع).
مثال (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
فكّر أيضًا في قواعد الشبكة: اربط الواجهة بواجهة خاصة أو قيد الوصول الوارد بحيث يصل Meilisearch فقط من خوادمك الخلفية.
curl -s http://localhost:7700/version
فهرسة Meilisearch غير متزامنة: ترسل الوثائق، يضعها Meilisearch في قائمة مهام، وفقط بعد نجاح تلك المهمة تصبح الوثائق قابلة للبحث. عامل الفهرسة كنظام مهام، لا كطلب واحد.
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
taskUid. استعلم حتى تصبح succeeded (أو failed).curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
إذا لم تتطابق الأعداد، لا تخمن — افحص تفاصيل خطأ المهمة أولًا.
الدفعات تتعلق بالحفاظ على المهام قابلة للتنبؤ وقابلة للاسترداد.
addDocuments يعمل كـ upsert: الوثائق ذات المفتاح الأساسي نفسه تُحدَّث، والجديدة تُدرَج. استخدم هذا للتحديثات العادية.
قم بـ إعادة فهرسة كاملة عندما:\n\n- غيّرت شكل الوثائق بشكل كبير،\n- تحتاج إلى إعادة حساب حقول مشتقة،\n- انحرفت مزامنتك وتريد إعادة ضبط نظيفة.
للإزالات، استدعِ صراحة deleteDocument(s)؛ وإلا فقد تبقى السجلات القديمة.
ينبغي أن تكون الفهرسة قابلة لإعادة المحاولة. المفتاح هو معرفات الوثائق الثابتة.
taskUid المرجعي جنبًا إلى جنب مع معرف الدفعة/المهمة، وأعد المحاولة بناءً على حالة المهمة.قبل بيانات الإنتاج، فهرس مجموعة صغيرة (200–500 عنصر) تطابق حقولك الحقيقية. مثال: مجموعة products بـ id, name, description, category, brand, price, inStock, createdAt. هذا يكفي للتحقق من تدفق المهام، العدّ، وسلوك التحديث/الحذف — دون انتظار استيراد ضخم.
"الصلة" في البحث ببساطة: ما الذي يظهر أولًا ولماذا. يتيح لك Meilisearch ضبط ذلك دون أن تضطر لبناء نظام تسجيل نقاط خاص بك.
إعدادان يشكلان ما يمكن لـ Meilisearch فعله بمحتواك:\n\n- searchableAttributes: الحقول التي يبحث فيها Meilisearch عندما يكتب المستخدم استعلامًا (مثال: title, summary, tags). ترتيبها مهم: الحقول الأسبق تُعدّ أكثر أهمية.
displayedAttributes: الحقول المعادة في الاستجابة. هذا مهم للخصوصية وحجم الحمولة — إذا لم يُعرض حقل، فلن يُعاد.خط أساس عملي هو جعل بعض الحقول عالية الإشارة قابلة للبحث (title, نص رئيسي) والاحتفاظ بحقول العرض لما تحتاجه الواجهة.
يعتمد Meilisearch في ترتيب الوثائق المطابقة على قواعد الترتيب — سلسلة من "حاسمات الربط". مفهوميًا، يفضّل:\n\n1) النتائج التي تطابق الاستعلام جيدًا (بما في ذلك تحمل الأخطاء)، ثم\n2) النتائج حيث التطابق أقوى (كلمات أقرب، تطابق في حقول أكثر أهمية)، ثم\n3) النتائج التي تتوافق مع منطق عملك (فرز مخصص مثل الحداثة أو الشيوع).
لا تحتاج إلى حفظ التفاصيل الداخلية لتضبطه بفعالية؛ تختار أساسًا أي الحقول مهمة ومتى تطبق الفرز المخصص.
الهدف: "مطابقة العنوان يجب أن تفوز." ضع title أولاً:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
الهدف: "المحتوى الأحدث يظهر أولاً." أضف قاعدة فرز واجعل الاستعلام يطلبها (أو اضبط ترتيبًا مخصصًا):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
ثم اطلب:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
الهدف: "ترقية العناصر الشائعة." اجعل popularity قابلاً للفرز وفرز حسبه عند الملاءمة.
اختر 5–10 استعلامات حقيقية يكتبها المستخدمون. احفظ النتائج العليا قبل التغييرات، ثم قارن بعد.
مثال:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerإذا كانت قائمة "بعد" تطابق نية المستخدم بشكل أفضل، احتفظ بالإعدادات. إذا أثرت سلبًا على حالات الحافة، عدّل شيئًا واحدًا في كل مرة (ترتيب السمات، ثم قواعد الفرز) حتى تعرف ما الذي أحدث التحسين.
مربع البحث الجيد ليس مجرد "اكتب كلمات، احصل على تطابقات." يريد الناس أيضًا تضييق النتائج ("العناصر المتوفرة فقط") وترتيبها ("الأرخص أولًا"). في Meilisearch، تفعل ذلك بـ الفلاتر، الفرز، والصفات.
الفلتر هو قاعدة تطبّقها على مجموعة النتائج. الصفة هي ما تعرضه في الواجهة لمساعدة المستخدمين على بناء تلك القواعد (غالبًا كخانات اختيار أو أعداد).
أمثلة غير تقنية:
قد يبحث المستخدم عن "running" ثم يفلتر إلى category = Shoes وstatus = in_stock. يمكن للصفات إظهار العدّ مثل "Shoes (128)" و"Jackets (42)" حتى يفهم المستخدم المتاح.
يحتاج Meilisearch منك أن تسمح صراحة بالحقل المستخدم للفلترة والفرز.
category, status, brand, price, created_at (إذا فلترة حسب الوقت), tenant_id (لعزل العملاء).price, rating, created_at, popularity.احتفظ بالقائمة ضيقة. جعل كل شيء قابلاً للفلترة/الفرز يمكن أن يزيد حجم الفهرس ويبطئ التحديثات.
حتى لو كان لديك 50,000 تطابق، يرى المستخدمون فقط الصفحة الأولى. استخدم صفحات صغيرة (غالبًا 20–50 نتيجة)، اضبط limit معقولًا، وتصفح باستخدام offset (أو ميزات الترقيم الأحدث إذا فضّلت). كذلك حدّ عمق الصفحة الأقصى في تطبيقك لمنع طلبات مكلفة مثل "صفحة 400".
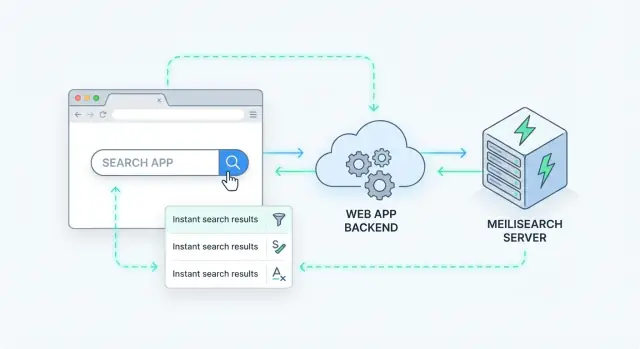
طريقة نظيفة لإضافة البحث على جانب الخادم هي معاملة Meilisearch كخدمة بيانات متخصصة خلف واجهة برمجة التطبيقات الخاصة بك. يتلقى تطبيقك طلب بحث، يستدعي Meilisearch، ثم يعيد استجابة منقّحة للعميل.
ينتهي معظم الفرق بتدفق كهذا:
GET /api/search?q=wireless+headphones&limit=20).هذا النمط يجعل Meilisearch قابلاً للاستبدال ويمنع كود الواجهة الأمامية من الاعتماد على تفاصيل الفهرس الداخلية.
إذا كنت تبني تطبيقًا جديدًا (أو تعيد بناء أداة داخلية) وتريد تنفيذ هذا النمط بسرعة، منصة ترميز سريعة مثل Koder.ai يمكن أن تساعد في توليد التدفق الكامل — واجهة React، خلفية Go، وPostgreSQL — ثم تدمج Meilisearch خلف نقطة واحدة /api/search بحيث تبقى الواجهة بسيطة وتظل الأذونات على جانب الخادم.
يدعم Meilisearch الاستعلام من العميل، لكن الاستعلام من الخلفية عادةً أكثر أمانًا لأن:\n\n- الأسرار تبقى خاصة: لا تخاطر بكشف مفاتيح API الخاصة.
يمكن أن يعمل الاستعلام من الواجهة لبيانات عامة بمفاتيح مقيدة، لكن إذا كانت لديك قواعد رؤية خاصة بالمستخدم، وجه البحث عبر الخادم.
حركة البحث غالبًا ما تتكرر ("iphone case", "return policy"). أضف التخزين المؤقت على طبقة API:
عامل البحث كنقطة نهاية مفتوحة للعامة:\n\n- طبق حدود معدل لكل IP أو لكل مستخدم.
limit وطول الاستعلام.غالبًا ما يُوضَع Meilisearch "خلف" تطبيقك لأنه يمكن أن يعيد بيانات حساسة تجاريًا بسرعة. عاملها كقاعدة بيانات: قفلها، وكشف فقط ما يجب لكل مُنادي.
Meilisearch لديه مفتاح ماستر يمكنه كل شيء: إنشاء/حذف الفهارس، تحديث الإعدادات، وقراءة/كتابة الوثائق. احتفظ به على الخادم فقط.
للتطبيقات، أنشئ مفاتيح API بمحدودية الإجراءات والفهارس. نمط شائع:
الحد الأدنى من الامتياز يعني أن المفتاح المسروق لا يستطيع حذف البيانات أو قراءة فهارس غير ذات صلة.
إذا كنت تخدم عملاء متعددين (مستأجرين)، لديك خياران رئيسيان:
1) فهرس واحد لكل مستأجر.
سهل الفهم ويقلل خطر الوصول المتقاطع. العيوب: المزيد من الفهارس للإدارة، ويجب تطبيق التحديثات على كل فهرس بشكل متسق.
2) فهرس مشترك + فلتر tenantId.
خزن حقل tenantId على كل وثيقة واطلب فلترًا مثل tenantId = "t_123" لجميع عمليات البحث. يمكن أن يتوسع هذا جيدًا، لكن فقط إذا ضمنت تطبيق الفلتر في كل طلب دائمًا (مثلاً عن طريق مفتاح مقيَّد حتى لا يتمكن المنادي من إزالته).
حتى لو كان البحث صحيحًا، قد تكشف النتائج حقولًا لم تقصد إظهارها (بريد إلكتروني، ملاحظات داخلية، أسعار التكلفة). قوّم ما يمكن إرجاعه:\n\n- حدِّد displayed/retrievable attributes إلى قائمة مسموح بها آمنة.
قم باختبار "أسوأ حالة" سريعًا: ابحث عن مصطلح شائع وتأكد من أن الحقول الخاصة لا تظهر.
إذا لم تكن متأكدًا ما إذا كان المفتاح ينبغي أن يكون على جانب العميل، افترض "لا" وحافظ على البحث على جانب الخادم.
Meilisearch سريع عندما تضع في اعتبارك عبئين: الفهرسة (الكتابة) واستعلامات البحث (القراءة). معظم بطء "الغموض" هو ببساطة أحدهما ينافس الآخر على CPU، RAM، أو القرص.
حِمل الفهرسة يمكن أن يقفز عند استيراد دفعات كبيرة، تشغيل تحديثات متكررة، أو إضافة العديد من الحقول القابلة للبحث. الفهرسة عملية خلفية، لكنها لا تزال تستهلك CPU ونطاق قرص. إذا نما طابور المهام، قد تبدأ عمليات البحث بالشعور بالبطء حتى لو أن حجم الاستعلامات لم يتغير.
حِمل الاستعلام ينمو مع حركة المرور، لكن أيضًا مع الميزات: المزيد من الفلاتر، المزيد من الصفات، مجموعات نتائج أكبر، والمزيد من تحمل الأخطاء الإملائية يمكن أن يزيد العمل لكل طلب.
I/O القرص هو المسبب الصامت. الأقراص البطيئة (أو الجيران الصاخبون على وحدات التخزين المشتركة) يمكن أن يحول "فوري" إلى "فيما بعد". التخزين NVMe/SSD هو القاعدة الشائعة للإنتاج.
ابدأ بحجم بسيط: امنح Meilisearch ذاكرة كافية للحفاظ على الفهارس ساخنة وCPU كافي للتعامل مع QPS الذروة. ثم فصل الاهتمامات:
راقب مجموعة صغيرة من الإشارات:\n\n- زمن البحث (p50/p95) ومعدل المعاملات\n- طول طابور المهام / وقت معالجة المهمة (طابور متصاعد يعني أن الفهرسة لا تواكب)
يجب أن تكون النسخ الاحتياطية روتينية، لا بطولية. استخدم ميزة snapshot في Meilisearch مجدولًا، خزّن اللقطات خارج الصندوق، واختبر الاستعادة دوريًا. للترقيات، اقرأ ملاحظات الإصدار، جرّب الترقية في بيئة غير الإنتاج، وخطط لوقت إعادة الفهرسة إذا أثر تغيير الإصدار على سلوك الفهرسة.
إذا كنت تستخدم لقطات بيئة وعودة مثل نظام المنصة لديك (مثلاً عبر workflow لقطات/استعادة في Koder.ai)، موافق نشر البحث مع نفس الانضباط: لقطة قبل التغييرات، تحقق من فحوصات الصحة، واحتفظ بممر سريع للعودة للحالة المعروفة الجيدة.
حتى مع تكامل نظيف، تميل مشاكل البحث إلى الوقوع في عدد قليل من الفئات المتكررة. الخبر الجيد: Meilisearch يمنحك رؤية كافية (المهام، السجلات، الإعدادات الحتمية) لتصحيح الأخطاء بسرعة — إذا اقتربت منه منهجيًا.
filterableAttributes، أو الوثائق تخزنها بشكل غير متوقع (سلسلة مقابل مصفوفة مقابل كائن متداخل).sortableAttributes/rankingRules يدفع العناصر "الخاطئة" للأعلى.ابدأ بالتحقق مما إذا كان Meilisearch قد طبّق آخر تغيير لك بنجاح.
filter، ثم sort، ثم facets.إذا لم تستطع تفسير نتيجة، قلّص تكوينك مؤقتًا: أزل المرادفات، قلّل تعديلات قواعد الترتيب، واختبر بمجموعة صغيرة من الوثائق. تصبح قضايا الصلة المعقّدة أسهل بكثير عند 50 وثيقة بدلًا من 5 ملايين.
your_index_v2 بالتوازي، طبّق الإعدادات، وأعد تشغيل نموذج من استعلامات الإنتاج.filterableAttributes وsortableAttributes تتوافق مع متطلبات الواجهة.Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
البحث على جانب الخادم يعني أن الاستعلام يُنفَّذ على الخادم الخاص بك (أو خدمة بحث مخصّصة)، وليس داخل المتصفح. هذا هو الخيار الصحيح عندما:
يلاحظ المستخدمون أربعة أشياء فوراً:
إذا غاب أحدها، يعيد الناس كتابة الاستعلامات، يتصفحون كثيراً، أو يتخلون عن البحث.
عاملها كـ فهرس بحث، وليست مصدر الحقيقة. قاعدة البيانات الخاصة بك تتعامل مع الكتابات، المعاملات والقيود؛ Meilisearch يخزن نسخة من الحقول التي تختار جعلها قابلة للبحث، أو الفلترة، أو العرض.
نموذج ذهني مفيد:
الافتراض الشائع هو فهرس واحد لكل نوع كيان (مثلاً products, articles). هذا يحافظ على:
إذا كنت بحاجة إلى “بحث شامل”، يمكنك الاستعلام عبر عدة فهارس ودمج النتائج في الخادم، أو إضافة فهرس عام مخصّص لاحقاً.
اختر مفتاحاً أساسياً يكون:
id, sku, slug)المعرفات الثابتة تجعل الفهرسة قابلة لإعادة التشغيل بأمان: عند إعادة المحاولة لن تُنشأ سجلات مكررة لأن التحديثات تصبح upserts آمنة.
صنِّف كل حقل حسب دوره حتى لا تفهرس كثيراً:
وضع هذه الأدوار بوضوح يقلل النتائج الضوضائية ويمنع فهارس كبيرة وبطيئة.
الـفهرسة غير متزامنة: تحميل الوثائق يُنشيء مهمة، وتصبح الوثائق قابلة للبحث فقط بعد نجاح تلك المهمة.
تدفق موثوق به:
succeeded أو failedإذا بدت النتائج قديمة، افحص حالة المهمة قبل أي استنتاجات أخرى.
استخدم العديد من الدفعات الصغيرة بدلاً من رفع ضخم واحد. نقاط بداية عملية:
الدفعات الصغيرة أسهل لإعادة المحاولة، وأسهل لتحديد السجلات الخاطئة، وأقل عرضة لانتهاء المهلة.
رافعتان ذات تأثير مرتفع:
searchableAttributes: الحقول التي يُبحث فيها وبأي أولويةpublishedAt, price, أو popularityنهج عملي: خذ 5–10 استعلامات حقيقية من المستخدمين، سجّل النتائج العليا “قبل”، غيّر إعداداً واحداً، ثم قارن “بعد”.
معظم مشاكل الفلترة/الفرز تأتي من إعداد مفقود:
filterableAttributes لتتمكن من فلترتهsortableAttributes لتتمكن من الفرز بهأيضاً تحقق من شكل الحقل وأنواع البيانات في الوثائق (سلسلة مقابل مصفوفة مقابل كائن متداخل). إذا فشل فلتر ما، افتح آخر إعدادات/حالة مهمة وتأكد أن الوثائق المفهرسة تحتوي على القيم المتوقعة.