07 أغسطس 2025·8 دقيقة
من GPT-1 إلى GPT-4: تاريخ نماذج GPT من OpenAI
استعرض تاريخ نماذج GPT من OpenAI — من GPT-1 إلى GPT-4o — وتعرّف كيف طورت كل جيل فهم اللغة، سهولة الاستخدام، وجوانب السلامة.
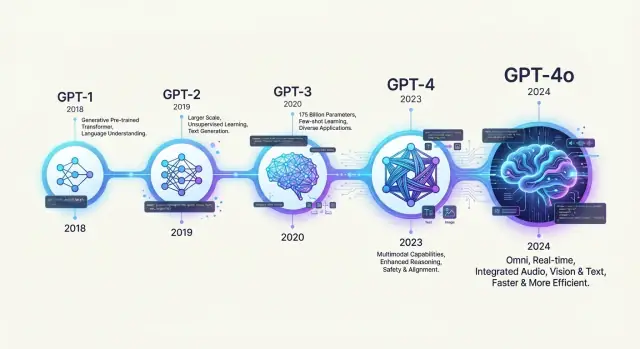
استعرض تاريخ نماذج GPT من OpenAI — من GPT-1 إلى GPT-4o — وتعرّف كيف طورت كل جيل فهم اللغة، سهولة الاستخدام، وجوانب السلامة.
نماذج GPT هي عائلة من نماذج اللغة الكبيرة المصممة للتنبؤ بالكلمة التالية في تسلسل نصي. تقرأ كميات ضخمة من النصوص، تتعلّم أنماط استخدام اللغة، ثم تستخدم هذه الأنماط لتوليد نص جديد، الإجابة عن الأسئلة، كتابة الشفرات، تلخيص المستندات، والمزيد.
الاختصار يشرح الفكرة الأساسية:
فهم كيف تطورت هذه النماذج يساعد على فهم ما يمكنها فعله وما لا يمكنها، ولماذا تبدو كل جيل وكأنه قفزة في القدرات. كل نسخة تعكس اختيارات تقنية ومقايضات بشأن حجم النموذج، بيانات التدريب، الأهداف، والعمل على السلامة.
المقالة تتبع عرضًا تسلسليًا رفيع المستوى: من النماذج اللغوية المبكرة وGPT-1، مرورًا بـ GPT-2 وGPT-3، إلى توليف التعليمات وChatGPT، وختامًا بـ GPT-3.5 وGPT-4 وعائلة GPT-4o. على الطريق سننظر في الاتجاهات التقنية الرئيسية، كيف تغيّرت أنماط الاستخدام، وماذا توحي هذه التحولات بشأن مستقبل نماذج اللغة الكبيرة.
قبل GPT، كانت النماذج اللغوية جزءًا جوهريًا من أبحاث معالجة اللغة الطبيعية. الأنظمة المبكرة كانت نماذج n‑gram التي تتنبأ بالكلمة التالية من نافذة ثابتة من الكلمات السابقة باستخدام حسابات بسيطة. كانت تدعم تصحيح الإملاء والإكمال التلقائي الأساسي لكنها كانت تواجه صعوبات مع السياق بعيد المدى ونادرية البيانات.
الخطوة التالية كانت نماذج لغوية عصبية. الشبكات الأمامية ولاحقًا الشبكات العودية (RNNs)، وخاصة LSTMs وGRUs، تعلّمت تمثيلات كلمات موزعة وكان بإمكانها نظريًا التعامل مع تسلسلات أطول. في نفس الفترة، نماذج مثل word2vec وGloVe جعلت تمثيلات الكلمات شائعة، مبينة أن التعلم غير المراقب من النص الخام قادر على التقاط بنية دلالية غنية.
مع ذلك، كانت الشبكات العودية بطيئة في التدريب، وصعبة التوازي، وما تزال تواجه مشاكل مع السياق الطويل. الاختراق جاء مع ورقة 2017 "Attention Is All You Need" التي قدّمت بنية الترانسفورمر. استبدل الترانسفورمر التكرار بالانتباه الذاتي، مما سمح للنماذج بربط أي موضعين في التسلسل مباشرة وجعل التدريب عالي التوازي.
هذا فتح الباب لتوسيع النماذج اللغوية إلى ما هو أبعد مما تستطيع الشبكات العودية التعامل معه. بدأ الباحثون يرون أن ترانسفورمر كبير واحد مُدرَّب على التنبؤ بالرمز التالي على مجموعات نصية ضخمة يمكنه أن يتعلم قواعد النحو والدلالة وحتى بعض مهارات الاستدلال دون إشراف مهمات محددة.
الفكرة الأساسية لدى OpenAI كانت تأطير هذا كـ تدريب مسبق توليدي: أولًا تدريب ترانسفورمر من نوع decoder على مجموعة إنترنت واسعة النطاق لنمذجة النص، ثم تكييف نفس النموذج لمهام لاحقة بحد أدنى من التدريب الإضافي. هذا النهج وعد بنموذج عام واحد بدل العديد من النماذج الضيقة.
ذلك التحول المفاهيمي — من أنظمة صغيرة خاصة بكل مهمة إلى ترانسفورمر كبير مُدرَّب مسبقًا توليديًا — مهد الطريق لأول نموذج GPT وكل سلسلة GPT التالية.
GPT-1 كان الخطوة الأولى في سلسلة GPT. صدر في 2018، وضم 117 مليون معلمة وبُني على بنية الترانسفورمر. رغم صغر حجمه مقارنةً بالإصدارات التالية، بلور الوصفة الأساسية التي تتبعها كل نماذج GPT لاحقًا.
تدرّب GPT-1 على فكرة بسيطة لكنها قوية:
في التدريب المسبق تعلَّم GPT-1 التنبؤ بالرمز التالي على نص مأخوذ بشكل أساسي من BooksCorpus ومصادر شبيهة بويكيبيديا. هذا الهدف—التنبؤ بالكلمة التالية—لم يتطلب وسمًا بشريًا، مما سمح للنموذج بامتصاص معرفة واسعة عن اللغة والأساليب والحقائق.
بعد التدريب المسبق، تم ضبط النموذج دقيقًا بتعلم مُراقَب على معايير NLP الكلاسيكية: تحليل المشاعر، الإجابة عن الأسئلة، استنتاج النصوص، وغيرها. أُضيف رأس تصنيف صغير في القمة وتدرَّب النموذج بأكمله (أو معظمُه) نهايةً إلى نهاية على كل مجموعة معنونة.
النقطة المنهجية الجوهرية كانت أن نفس النموذج المدرب مسبقًا يمكن تكييفه بخفة لمهام عديدة بدل تدريب نموذج مستقل لكل مهمة من الصفر.
رغم حجمه النسبي الصغير، قدم GPT-1 عدة رؤى مؤثرة:
أظهر GPT-1 أيضًا آثارًا مبكرة للتعميم صفري وقليل الأمثلة، رغم أن التقييم في الغالب ما زال يعتمد على الضبط الدقيق لمهام منفصلة.
لم يكن الهدف من GPT-1 التوزيع للمستخدمين العامين أو إطلاق API. عدة عوامل أبقته في مجال البحث:
مع ذلك، وضع GPT-1 القالب: تدريب مسبق توليدي على مجموعات نصية كبيرة ثم ضبط دقيق لمهام محددة. كل نموذج GPT لاحق يمكن رؤيته كنسل مُوسّع ومحسّن لهذا الترانسفورمر المولِّد الأول.
GPT-2، صدر في 2019، كان أول نموذج GPT يجذب انتباهًا عالميًا حقيقيًا. وسّع بنية GPT-1 من 117 مليون إلى 1.5 مليار معلمة، مبرزًا إلى أي مدى يمكن أن يصل التوسيع البسيط لنموذج الترانسفورمر.
هيكليًا كان GPT-2 مشابهًا جدًا لـ GPT-1: ترانسفورمر decoder مدرَّب للتنبؤ بالرمز التالي على مجموعة نصوص ويب كبيرة. الاختلاف الأساسي كان في الحجم:
هذا القفز في الحجم حسّن الطلاقة والتماسك عبر مقاطع أطول وقدرة أفضل على اتباع المطالبات دون تدريب خاص بالمهمة.
جعل GPT-2 العديد من الباحثين يعيدون التفكير فيما يمكن أن يحققَه "مجرد" التنبؤ بالرمز التالي.
بدون أي ضبط دقيق، كان GPT-2 قادرًا على أداء مهام صفرية مثل:
وبوجود أمثلة قليلة داخل المطالبة (few-shot)، تحسن الأداء غالبًا. هذا ألمح إلى أن نماذج اللغة الكبيرة قد تمثل داخليًا مجموعة واسعة من المهام، مستخدمةً الأمثلة في السياق كوسيلة برمجية ضمنية.
جودة التوليد المبهرة أثارت مناقشات عامة حول نماذج اللغة الكبيرة. في البداية حجبت OpenAI النسخة الكاملة 1.5B، مستشهدة بمخاوف من:
بدلًا من ذلك، اتبعت OpenAI إصدارًا مرحليًا:
كان هذا النهج المبكر مثالًا لسياسة نشر ذكاء اصطناعي ترتكز على تقييم المخاطر والمراقبة.
حتى نقاط التحقق الأصغر لـ GPT-2 أدت إلى موجة من المشاريع مفتوحة المصدر. طوَّر المطورون نماذج مخصّصة للكتابة الإبداعية، إكمال الشفرات، وروبوتات محادثة تجريبية. بحثة التحيز والأخطاء والأنماط الفاشلة تُجرِى بشكل واسع.
غيّرت هذه التجارب كيف يرى الكثيرون نماذج اللغة الكبيرة: من آثار بحثية متخصصة إلى محركات نص عامّة. أثر GPT-2 وضع توقعات—ورفَع المخاوف—التي شكَّلت استقبال GPT-3 وChatGPT ونماذج GPT-4 لاحقًا.
وصل GPT-3 في 2020 برقم لافت: 175 مليار معلمة، أكثر من 100× حجم GPT-2. الرقم عبّر عن قدرة حفظ هائلة لكنه، والأهم، كشف سلوكيات لم تكن مرئية على هذا النطاق من قبل.
الاكتشاف الحاسم مع GPT-3 كان التعلم في السياق. بدلًا من ضبط النموذج لمهام جديدة، يمكنك لصق أمثلة قليلة في المطالبة:
النموذج لا يحدّث أوزانه؛ بل يستخدم المطالبة كنوع من مجموعة تدريب مؤقتة. قاد ذلك إلى مصطلحات مثل zero-shot وone-shot وfew-shot prompting، وأشعل موجة "هندسة المطالبات": صياغة التعليمات والأمثلة والتنسيق للحصول على سلوك أفضل دون المساس بالنموذج نفسه.
بعكس GPT-2 الذي توافرت أوزانه للتحميل، توفّر GPT-3 أساسًا عبر API تجاري. أطلقت OpenAI بيتا خاصة لـ OpenAI API في 2020، مموهة GPT-3 كمحرِّك نص عام يمكن للمطورين النداء عليه عبر HTTP.
غيّر هذا نمط استخدام النماذج اللغوية من آثار بحثية إلى منصة واسعة. بدلًا من تدريب نماذجهم الخاصة، صار بإمكان الشركات الناشئة والمؤسسات بناء نماذج أولية بأيقونة مفتاح API، والدفع حسب عدد الرموز.
المتبنّون الأوائل استكشفوا أنماطًا سرعان ما أصبحت قياسية:
أثبت GPT-3 أن نموذجًا عامًا واحدًا—متاح عبر API—يمكن أن يزوّد نطاقًا واسعًا من التطبيقات، ممهِّدًا الطريق لـ ChatGPT ونُسخ GPT-3.5 وGPT-4 لاحقًا.
الـ GPT-3 الأساسي تدرّب فقط للتنبؤ بالرمز التالي على نص إنترنت كبير. هذا الهدف يجعله جيدًا في مواصلة الأنماط، لكنه ليس بالضرورة جيدًا في تنفيذ ما يطلبه المستخدمون. كثيرًا ما كان على المستخدمين صياغة مطالبات بعناية، وكان النموذج:
أطلق الباحثون على هذه الفجوة بين ما يريده المستخدمون وما يفعله النموذج اسم مشكلة المحاذاة: سلوك النموذج لم يكن متوافقًا بشكل موثوق مع نوايا البشر أو قيمهم أو توقعات السلامة.
كان مشروع InstructGPT (2021–2022) نقطة تحول. بدلًا من التدريب على النص الخام فقط، أضافوا مرحلتين أساسيتين على رأس GPT-3:
أنتج هذا نماذج:
في دراسات المستخدم، فضّل الناس نماذج أصغر من InstructGPT على نماذج GPT-3 الأكبر غير المضبوطة، مما أوضح أن المحاذاة وجودة الواجهة يمكن أن تفوق حجم النموذج الخام.
امتدّ ChatGPT (أواخر 2022) نهج InstructGPT إلى الحوار متعدد الأدوار. كان في الأساس نموذجًا من فئة GPT-3.5، مضبَّطًا بـ SFT وRLHF على بيانات محادثة بدلًا من مجرد تعليمات مفردة.
بدلًا من API أو بيئة للمطورين، أطلقت OpenAI واجهة محادثة بسيطة:
خفض هذا الحاجز أمام المستخدمين غير التقنيين. لا حاجة لهندسة مطالبات معقّدة، ولا للكود؛ اكتب واحصل على إجابات.
كانت النتيجة اختراقًا شعبياً: تقنية بُنيت على سنوات من أبحاث الترانسفورمر والمحاذاة صارت متاحة لأي شخص يمتلك متصفحًا. توليف التعليمات وRLHF جعل النظام يبدو متعاونًا وآمنًا بما يكفي للإصدار الواسع، بينما حولت واجهة الدردشة نموذجًا بحثيًا إلى منتج يومي.
مثل GPT-3.5 اللحظة التي توقفت فيها نماذج اللغة الكبيرة عن كونها محض فضول بحثي وبدأت تشعر كأدوات يومية. جلس هذا الجيل بين GPT-3 وGPT-4 من حيث القدرة، لكن أهميته الحقيقية كانت في سهولة الوصول والعملية.
فنيًا، حسّن GPT-3.5 بنية GPT-3 الأساسية ببيانات تدريب أفضل، تحسينات في الأمثل، وتوليف تعليمات واسع. نماذج في هذه السلسلة — بما في ذلك text-davinci-003 ولاحقًا gpt-3.5-turbo — تدربت لتتبع التعليمات بشكل أكثر موثوقية، وترد بأمان أكثر، وتحافظ على محادثة متعددة الأدوار متماسكة.
هذا جعل GPT-3.5 خطوة طبيعية نحو GPT-4: استدلال أقوى في المهام اليومية، تعامل أفضل مع المطالبات الطويلة، وسلوك حواري أكثر استقرارًا، كل ذلك بدون القفزة الكاملة في التعقيد وتكاليف GPT-4.
الإصدار العام الأول من ChatGPT أواخر 2022 كان مدعومًا بنموذج من فئة GPT-3.5 مضبوطًا بـ RLHF. هذا حسّن بشكل كبير كيف كان النموذج:
بالنسبة لكثيرين، كانت هذه أول تجربة مباشرة مع نموذج لغة كبير، وحددت معايير لما يجب أن تبدو عليه "دردشة الذكاء الاصطناعي".
gpt-3.5-turbo ولماذا أصبح الافتراضيعند إطلاق gpt-3.5-turbo عبر API، قدّم مزيجًا جذابًا من السعر والسرعة والقدرة. كان أرخص وأسرع من نماذج GPT-3 السابقة، ومع ذلك قدم متابعة تعليمات وجودة حوار أفضل.
هذا التوازن جعل gpt-3.5-turbo الخيار الافتراضي للعديد من التطبيقات:
لذلك، لعب GPT-3.5 دورًا انتقاليًا محوريًا: قوي بما يكفي لفتح منتجات حقيقية على نطاق واسع، واقتصادي بما يكفي للنشر الواسع، ومحاذَ بمدينة كافية ليبدو مفيدًا في سير العمل اليومي.
صدر GPT-4 في 2023، ومثّل تحولًا من "نموذج نص كبير" إلى مساعد عام أقوى بقدرات استدلالية ومؤهلات متعددة الوسائط.
بالمقارنة مع GPT-3 وGPT-3.5، ركّز GPT-4 أقل على مجرد عدد المعلمات وركز أكثر على:
شملت العائلة الرائدة gpt-4 ولاحقًا gpt-4-turbo، التي تهدف لتقديم جودة مماثلة أو أفضل بتكلفة وزمن استجابة أقل.
من الميزات البارزة في GPT-4 قدرته متعدد الوسائط: إلى جانب النص يمكنه قبول الصور. يمكن للمستخدمين:
جعل ذلك GPT-4 أقل نموذجًا نصيًا فحسب وأكثر محرك استدلال عام يتواصل عبر اللغة.
تدرَّب GPT-4 ونُقّح مع تركيز أقوى على السلامة والمحاذاة:
أصبحت نماذج مثل gpt-4 وgpt-4-turbo خيارًا افتراضيًا للاستخدامات الإنتاجية الجادة: أتمتة الدعم، مساعدي الترميز، أدوات التعليم، وبحث المعرفة. وضع GPT-4 الأساس لإصدارات لاحقة مثل GPT-4o التي دفعت الكفاءة والتفاعل في الوقت الحقيقي إلى الأمام مع المحافظة على معظم مكاسب الاستدلال والسلامة.
ترمز GPT-4o ("omni") إلى تحول من "الأقوى بأي ثمن" إلى "سريع، ميسور، ومتوافر دائمًا". صُمِّم لتقديم جودة شبيهة بـ GPT-4 مع تكلفة أقل وسرعة تجعل التجارب الحية ممكنة.
يوحّد GPT-4o النص والرؤية والصوت في نموذج واحد. بدلًا من ربط مكونات منفصلة، يتعامل بطبيعته مع:
هذا التكامل يقلل الكمون والتعقيد. يمكن لـ GPT-4o الاستجابة في الوقت القريب من الحقيقي، بث الإجابات أثناء التفكير، والتبديل بسلاسة بين الوسائط خلال محادثة واحدة.
هدف تصميم رئيسي لـ GPT-4o هو الكفاءة: أداء أفضل مقابل الدولار وزمن استجابة أقل. هذا يمكّن:
النتيجة هي إتاحة قدرات كانت حكراً على واجهات API ذات التكلفة العالية لطلاب وهواة وشركات ناشئة وفرق صغيرة تجريبية.
يدفع GPT-4o mini الوصول أكثر عبر مقايضة بعض القدرة القصوى مقابل السرعة والتكلفة المنخفضة. مناسب لـ:
نظرًا لأن 4o mini اقتصادية، يمكن للمطورين تضمينها في المزيد من الأماكن—داخل التطبيقات، بوابات العملاء، الأدوات الداخلية—دون القلق كثيرًا بشأن فواتير الاستخدام.
معًا، توسع GPT-4o وGPT-4o mini ميزات GPT المتقدمة إلى حالات الاستخدام متعددة الوسائط والحوارية في الوقت الحقيقي، مع توسيع من يستطيع عمليًا البناء والاستفادة من هذه النماذج.
تمر عبر كل جيل من نماذج GPT عدة تيارات تقنية: التوسيع، الملاحظات، السلامة، والتخصص. معًا تفسر لماذا يشعر كل إصدار بأنه مختلف نوعيًا وليس أكبر فحسب.
اكتشاف رئيسي وراء تقدم GPT هو قوانين التوسيع: عندما تزيد معلمات النموذج، وحجم البيانات، والحوسبة بشكل متوازن، يتحسّن الأداء بسلاسة عبر مهام عديدة.
أظهرت النماذج المبكرة أن:
أدى ذلك إلى نهج منهجي:
النماذج الخام قوية لكن غير مبالية لتوقعات المستخدم. يعيد RLHF تشكيلها إلى مساعدين مفيدين:
على المدى صار هذا يتطوّر إلى توليف التعليمات + RLHF: ضبط مبدئي على أزواج تعليمات–استجابة ثم تطبيق RLHF لصقل السلوك. هذا المزيج هو أساس تفاعلات نمط ChatGPT.
مع نمو القدرات زادت الحاجة إلى تقييمات سلامة منهجية وتنفيذ سياسات.
نُهج تقنية تضمن:
تتكرر هذه الآليات: اكتشاف ظروف فشل جديدة يؤدي إلى تغذية عكسية إلى بيانات التدريب ونماذج المكافأة والمرشحات.
أصدرت الإصدارات الأولى نموذجًا رائدًا وعدة متغيرات أصغر. مع الوقت تحول الاتجاه إلى عائلات نماذج مُحسّنة لقيود وحالات استخدام مختلفة:
تحت السطح، يعكس هذا تكديسًا ناضجًا: بُنى أساسية مشتركة وأنابيب تدريب، ثم ضبط مخصّص وطبقات سلامة لإنتاج محفظة بدل كتلة واحدة. هذه الاستراتيجية المتعددة النماذج هي الآن اتجاه تقني ومنتجي محدد في تطور GPT.
حوّلت نماذج GPT الذكاء المبني على اللغة من أداة بحث متخصصة إلى بنية تحتية يبني عليها كثير من الناس والمنظمات.
للمطورين، تتصرف نماذج GPT كمحرِّك "لغة" مرن. بدلًا من كتابة قواعد صلبة، يرسلون مطالبات لغة طبيعية ويتلقون نصًا أو شيفرة أو مخرجات مُنظّمة.
غيّر هذا كيفية تصميم البرمجيات:
وبالتالي، تعتمد العديد من المنتجات الآن على GPT كمكوّن جوهري بدل ميزة إضافية.
تستخدم الشركات GPT داخليًا وواجهات متجهة للعملاء.
داخليًا، تعمل الفرق على أتمتة تصنيف الدعم، صياغة الرسائل والتقارير، مساعدة البرمجة وضمان الجودة، وتحليل الوثائق والسجلات. خارجيًا، GPT يشغّل روبوتات المحادثة، المساعدين في مجموعات الإنتاجية، مساعدين الترميز، أدوات المحتوى والتسويق، ومساعدين متخصصين في المالية والقانون والرعاية الصحية.
توفر الواجهات المستضافة والـ API إمكانات متقدّمة دون إدارة بنية تحتية أو تدريب نماذج من الصفر، مما يخفض الحاجز أمام المنظمات الصغيرة والمتوسطة.
يستخدم الباحثون GPT للعصف الذهني، توليد الشيفرة للتجارب، صياغة الأوراق، واستكشاف الأفكار باللغة الطبيعية. يميل المدرّسون والطلاب إلى الاعتماد على GPT للشرح، أسئلة الممارسة، التدريس الخاص، ودعم اللغات.
الكتاب والمصمّمون والمبدعون يستخدمون GPT للتخطيط، الإبداع، بناء العوالم وصقل المسودات. النموذج ليس بديلاً بقدر ما هو متعاون يسرّع الاستكشاف.
ينجم عن انتشار GPT مخاوف مهمة: قد تُؤدي الأتمتة إلى تغيّر أو إزاحة بعض الوظائف مع زيادة الطلب على مهارات جديدة. ونظرًا لأن GPT يتدرّب على بيانات بشرية، فقد يعكس ويضخم تحيّزات اجتماعية إن لم يُقَيَّد بعناية. كما يمكن إساءة استخدامه لإنتاج محتوى مُضلِّل أو مزيف على نطاق واسع.
دفعت هذه المخاطر العمل على تقنيات المحاذاة، سياسات الاستخدام، المراقبة، وأدوات الاِكتشاف والنسب. الموازنة بين التطبيقات القوية والسلامة والعدالة والثقة تبقى تحديًا مفتوحًا مع استمرار تطور نماذج GPT.
مع ازدياد قدرة نماذج GPT، تتحول الأسئلة الأساسية من "هل نستطيع بناؤها؟" إلى "كيف نبنيها وننشرها ونحكمها؟".
الكفاءة والوصول. GPT-4o و4o mini تلمح إلى مستقبل حيث النماذج عالية الجودة تعمل بتكلفة منخفضة، على خوادم أصغر، وربما على أجهزة شخصية. أسئلة رئيسية:
التخصيص دون الإفراط في التكيّف. يريد المستخدمون نماذج تتذكر الأسلوب والتفضيلات دون تسريب البيانات أو الانحياز المفرط. الأسئلة:
الموثوقية والاستدلال. حتى أفضل النماذج لا تزال تهلوس، تفشل بصمت، أو تتصرّف غير متوقعة تحت تغيّر التوزيع. البحث يستكشف:
السلامة والمحاذاة على نطاق واسع. مع اكتساب النماذج قدرات وكيل عبر الأدوات والأتمتة، يبقى محاذاتها مع القيم البشرية—ومحافظة عليها أثناء التحديثات—تحديًا مفتوحًا. يشمل هذا التعدد الثقافي: من تُشفر قيمه ومعاييره، وكيف تُدار الخلافات؟
التنظيم والمعايير. تصوغ الحكومات والمجموعات الصناعية قواعد للشفافية، استخدام البيانات، العلامات المائية، والإبلاغ عن الحوادث. الأسئلة المفتوحة:
من المرجح أن تصبح أنظمة GPT المستقبلية أكثر كفاءة، أكثر تخصيصًا، ومندمجة بإحكام في الأدوات والمنظمات. إلى جانب القدرات الجديدة، نتوقع ممارسات سلامة رسمية أكثر، تقييمًا مستقلاً، وضوابط مستخدم أوضح. التاريخ من GPT-1 إلى GPT-4 يوضِّح تقدمًا ثابتًا، لكنه يذكر أيضًا أن التقدّم التقني يجب أن يسيرُ جنبًا إلى جنب مع الحوكمة والمدخلات الاجتماعية وقياس الأثر في العالم الحقيقي.
GPT (Generative Pre-trained Transformer) هي شبكات عصبية كبيرة تُدرَّب للتنبؤ بالكلمة التالية في تسلسل نصي. عبر التدريب على نطاق واسع على مجموعات نصية ضخمة، تتعلم القواعد النحوية والأسلوب والمعلومات وأنماط التفكير. بعد التدريب يمكنها:
معرفة التاريخ توضح:
كما يساعدك على وضع توقعات واقعية: نماذج GPT متعلِّمات لأنماط النص ولا تُعد مصادر معصومة للحقائق.
تجعل توليف التعليمات وRLHF السلوك أقرب إلى ما يريده الناس:
معًا، يؤدي ذلك إلى:
هذه التغييرات دفعت GPT-4 من مولِّد نص إلى مساعد عام للأغراض المتعددة.
GPT-4o وGPT-4o mini مُحسَّنان للسرعة والتكلفة والاستخدام في الوقت الحقيقي أكثر مما يُركّز على أقصى قدرة:
المطورون عادةً ما يستخدمون نماذج GPT لـ:
نظرًا لتوفرها عبر واجهات برمجة تطبيقات، يمكن الفرق دمج هذه القدرات دون تدريب أو استضافة نماذج ضخمة بأنفسهم.
لاستخدامات حرجة، يجب التحقق من المخرجات، وقيودها عبر أدوات استرجاع ومتحققات، وإشراف بشري.
اتجاهات ستشكل أنظمة GPT المستقبلية:
التوجّه نحو أنظمة أكثر قدرة وأيضًا أكثر تحكّمًا ومسؤولية.
إرشادات عملية مقترحة:
تهدف هذه النماذج إلى جعل ميزات GPT المتقدمة متاحة اقتصاديًا لشريحة أوسع من المستخدمين والمطورين.
الاستخدام الآمن والفعّال يقتضي مزج نقاط قوة GPT مع ضوابط تصميمية وبشرية.