05 أكتوبر 2025·8 دقيقة
بناء تطبيق ويب في الزمن الحقيقي لمراقبة ومنع انتهاكات SLA
تعلم مخططًا عمليًا لبناء تطبيق ويب يتابع مؤقتات SLA، يكتشف الانتهاكات فورًا، ينبه الفرق، ويعرض الامتثال في الزمن الحقيقي.
تعلم مخططًا عمليًا لبناء تطبيق ويب يتابع مؤقتات SLA، يكتشف الانتهاكات فورًا، ينبه الفرق، ويعرض الامتثال في الزمن الحقيقي.
قبل أن تصمم الشاشات أو تكتب منطق الكشف، حدّد بدقة ما الذي يحاول تطبيقك منعه. «مراقبة الـSLA» يمكن أن تعني أي شيء من تقرير يومي إلى توقع انتهاك ثانيةً بثانية—وهما منتجان مختلفان تمامًا مع حاجات معمارية مختلفة.
ابدأ بالاتفاق على نافذة الاستجابة التي يمكن لفريقك تنفيذها عمليًا.
إذا كانت منظمتك للدعم تعمل بدورات 5–10 دقائق (قوائم الترياج، أدوار الاستدعاء)، فقد يعني "الزمن الحقيقي" تحديثات لوحة كل دقيقة مع تنبيهات خلال دقيقتين. إذا كنت تتعامل مع حوادث عالية الشدة حيث تهم كل دقيقة، فقد تحتاج إلى حل كشف وتنبيه خلال 10–30 ثانية.
اكتب هذا كهدف قابل للقياس، مثل: «اكتشاف الانتهاكات المحتملة خلال 60 ثانية وإخطار المتاح على النداء خلال دقيقتين». هذا يصبح حاجزًا لاتخاذ التنازلات لاحقًا في المعمارية والتكلفة.
أدرج الوعود المحددة التي تتابعها، وعرّف كل واحدة بلغة بسيطة:
سجل أيضًا كيف ترتبط هذه بـSLO و SLA في مؤسستك. إن اختلف SLO الداخلي عن SLA المعلن للعميل، قد يحتاج التطبيق لتتبع كلاهما: واحد للتحسين التشغيلي، وآخر للمخاطر التعاقدية.
سمّ المجموعات التي ستستخدم أو تعتمد على النظام: الدعم، الهندسة، نجاح العملاء، القادة/المديرون، واستجابة الحوادث/المتاح على النداء.
لكل مجموعة، التقط ما تحتاجه لاتخاذ قرار فوري: «هل هذه التذكرة معرضة للخطر؟»، «من المالك؟»، «هل نحتاج للتصعيد؟» هذا سيشكّل لوحة التحكم، توجيه التنبيهات، وصلاحيات الوصول.
هدفك ليس الرؤية فقط—بل الفعل في الوقت المناسب. قرر ما الذي يجب أن يحدث عندما يرتفع الخطر أو يحدث انتهاك:
بيان نتيجة جيد: «تقليل انتهاكات SLA بتمكين الكشف عنها واستجابة الحوادث ضمن نافذة الاستجابة المتفق عليها.»
قبل بناء منطق الكشف، اكتب تمامًا ما يبدو "جيدًا" و"سيئًا" لخدمتك. معظم مشاكل مراقبة الـSLA ليست تقنية—إنها مشكلات تعريف.
SLA (اتفاقية مستوى الخدمة) وعد للعملاء، عادة مع عواقب (اعتمادات، غرامات). SLO (هدف مستوى الخدمة) هو هدف داخلي تسعى لتحقيقه للبقاء فوق الـSLA بأمان. KPI (مؤشر الأداء الرئيسي) هو أي مقياس تتبعه (مفيد، لكن ليس دائماً مرتبطًا بوعد).
مثال: SLA = «الرد خلال ساعة». SLO = «الرد خلال 30 دقيقة». KPI = «متوسط وقت الاستجابة الأولي».
أدرج كل نوع انتهاك تحتاج لاكتشافه والحدث الذي يبدأ المؤقت.
فئات شائعة للانتهاك:
كن صريحًا بشأن ما يُحتسب كـ"استجابة" (رد عام مقابل ملاحظة داخلية) و"حل" (resolved مقابل closed)، وما إذا كانت إعادة الفتح تعيد ضبط المؤقت.
العديد من الـSLA تُحسب فقط خلال ساعات العمل. عرّف التقويم: أيام العمل، العطل، أوقات البدء/الانتهاء، والمنطقة الزمنية المستخدمة للحساب (عميل، العقد، أم الفريق). كما قرّر ما يحدث عندما يعبر العمل الحدود (مثال: تذكرة تصل عند 16:55 مع SLA استجابة 30 دقيقة).
وثّق متى يتوقف عدّ الـSLA، مثل:
اكتب هذه كقواعد يمكن لتطبيقك تطبيقها بشكل ثابت، واحتفظ بأمثلة للحالات المعقدة للاختبار لاحقًا.
مراقب الـSLA الخاص بك يعتمد على جودة البيانات. ابدأ بتحديد "أنظمة السجل" لكل ساعة SLA. بالنسبة للعديد من الفرق، أداة التذاكر هي مصدر الحقيقة لطوابع دورة الحياة، بينما تشرح أدوات المراقبة لماذا حدث شيء.
معظم إعدادات الزمن الحقيقي تسحب من مجموعة صغيرة من الأنظمة الأساسية:
إذا اختلف نظامان، قرّر مسبقًا أيهما يفوز لكل حقل (مثال: "حالة التذكرة من ServiceNow، درجة العميل من CRM").
على الأقل، تتبع الأحداث التي تبدأ أو توقف أو تغير مؤقت الـSLA:
فكّر أيضًا في أحداث تشغيلية: تغييرات تقويم العمل، تحديثات المنطقة الزمنية للعميل، وتغييرات جدول العطل.
فضّل الويبهوكس للتحديثات شبه الفورية. استخدم الاستطلاع عندما لا تتوفر الويبهوكس أو تكون غير موثوقة. احتفظ بتصديرات API/الاستيراد الخلفي للمصالحة (مثلًا، عمليات ليلية لملء الفجوات). ينتهي الأمر بالعديد من الفرق إلى هجينة: ويبهوكس للسرعة، واستطلاع دوري للأمان.
الأنظمة الحقيقية فوضوية. توقع:
عامل هذه كمتطلبات منتج، لا كـ"حالات حافة"—كشف الانتهاكات يعتمد على ضبطها.
تطبيق مراقبة SLA جيد أسهل في البناء والصيانة عندما تكون المعمارية واضحة ومتعمدة. على مستوى عالٍ، تبني خط أنابيب يحول الإشارات التشغيلية الخام إلى "حالة SLA"، ثم يستخدم تلك الحالة لتنبيه الأشخاص وتشغيل لوحة التحكم.
فكّر في خمسة كتل:
هذه الفصلية تحافظ على مسؤوليات نظيفة: الاستيعاب لا ينبغي أن يحتوي منطق الـSLA، واللوحات لا ينبغي أن تقوم بحسابات ثقيلة.
قرّر مبكرًا مدى "الزمن الحقيقي" الذي تحتاجه فعلاً.
نهج عملي: ابدأ بإعادة حساب متكررة لقاعدة أو اثنين، ثم انقل قواعد التأثير العالي إلى التدفق الحدثي.
تجنّب تعقيد المناطق المتعددة والبيئات المتعددة في البداية. عادةً تكون منطقة واحدة، بيئة إنتاج واحدة، وإعداد مختبر أدنى كافية حتى تتحقق من جودة البيانات وفائدة التنبيهات. اجعل «التوسع لاحقًا» قيد تصميم، لا مطلب بناء.
إذا أردت تسريع الإصدار الأول من لوحة التحكم وسير العمل، منصة مثل Koder.ai يمكنها مساعدتك على إنشاء واجهة React وواجهة خلفية Go + PostgreSQL بسرعة من مواصفات محادثة، ثم تكرار الشاشات والمرشحات أثناء التحقق مما يحتاجه المستجيبون فعليًا.
دوّن هذه قبل التنفيذ:
الاستيعاب هو المكان الذي يصبح فيه نظام مراقبة الـSLA إما موثوقًا—أو مزعجًا ومربكًا. الهدف بسيط: قبول أحداث من أدوات متعددة، تحويلها إلى تنسيق "حقيقي" موحد، وتخزين سياق كافٍ لشرح كل قرار لاحقًا.
ابدأ بتوحيد ما يبدو عليه "الحدث ذو الصلة بالـSLA"، حتى لو اختلفت الأنظمة العليا. مخطط أساسي عملي يتضمن:
ticket_id (أو معرف الحالة/عنصر العمل)timestamp (متى حدث التغيير، ليس متى استلمته)status (opened, assigned, waiting_on_customer, resolved, إلخ)priority (P1–P4 أو ما يعادلها)customer (معرّف الحساب/المستأجر)sla_plan (قواعد الـSLA المطبقة)قم بترقيم إصدارات المخطط (مثلاً schema_version) حتى تتمكن من تطوير الحقول دون كسر المنتجين الأقدم.
تسمي الأنظمة ذاتها بأسماء مختلفة: “Solved” مقابل “Resolved”، “Urgent” مقابل “P1”، فروق في المناطق الزمنية، أو أولويات مفقودة. ابنِ طبقة تطبيع صغيرة التي:
is_customer_wait أو is_pause) التي تبسّط منطق الانتهاك لاحقًاالتكاملات تعيد المحاولة. يجب أن يكون الاستيعاب لديك مُعرفًا بحيث لا تخلق الأحداث المكررة نسخًا إضافية. أساليب شائعة:
event_id من المنتج ورفض المكرراتticket_id + timestamp + status) وعمل upsertعندما يسأل أحدهم "لماذا أرسلنا تنبيه؟" تحتاج إلى ورقة أثر. خزّن كل حدث خام مقبول وكل حدث مطبّع، بالإضافة إلى من/ما الذي غيّره. هذا السجل التدقيقي ضروري للمحادثات مع العملاء والمراجعات الداخلية.
بعض الأحداث ستفشل في التحليل أو التحقق. لا ترمها بهدوء. وجّهها إلى قائمة انتظار/جدول رسائل ميتة مع سبب الخطأ، الحمولة الأصلية، وعدد محاولات إعادة المحاولة، حتى تتمكن من إصلاح الخرائط وإعادة التشغيل بأمان.
يحتاج تطبيق الـSLA إلى "ذاكرتين" مختلفتين: ما هو صحيح الآن (لإطلاق التنبيهات) وما حدث عبر الزمن (للشرح والإثبات).
الحالة الحالية هي أحدث حالة معروفة لكل عنصر عمل بالإضافة إلى مؤقتات الـSLA النشطة (وقت البدء، وقت الإيقاف المؤقت، وقت الاستحقاق، الدقائق المتبقية، المالك الحالي).
اختر مخزنًا مُحسّنًا للقراءات/الكتابات السريعة حسب المعرف وفلاتر بسيطة. الخيارات الشائعة: قواعد بيانات علائقية (Postgres/MySQL) أو مخزن قيمة-مفتاح (Redis/DynamoDB). بالنسبة للعديد من الفرق، Postgres كافٍ ويبسّط التقارير.
حافظ على نموذج الحالة صغيرًا وسهل الاستعلام. ستقرؤه باستمرار لواجهات مثل "المعرّض للخطر قريبًا".
يجب أن يلتقط التاريخ كل تغيير كسجل غير قابل للتغيير: إنشاء، تعيين، تغيير أولوية، تحديث حالة، رد العميل، بدء/انتهاء الإيقاف المؤقت، إلخ.
جدول أحداث إلحاقي يجعل التدقيق وإعادة التشغيل ممكنين. إذا اكتشفت لاحقًا خطأ في منطق الانتهاك، يمكنك إعادة معالجة الأحداث لإعادة بناء الحالة ومقارنة النتائج.
نمط عملي: جدول حالة + جدول أحداث في نفس قاعدة البيانات بالبداية؛ انتقل لمخزن تحليلات منفصل لاحقًا إذا نما الحجم.
حدِّد الاحتفاظ بحسب الغرض:
استخدم التقسيم (partition) بحسب الشهر/الربع لجعل الأرشفة والحذف متوقعة.
خطر الأداء يُكسب هنا: صمّم التخزين حول أسئلة اللوحة الخمس الأولى:
due_at وstatus (وربما queue/team).breached_at (أو علم حسابي للانتهاك) والتاريخ.(customer_id, due_at).هذا هو مكان الفوز بالأداء: بنية التخزين حول أهم 3–5 عروض، لا حول كل تقرير ممكن.
كشف الانتهاكات في الزمن الحقيقي يتعلق بشيء واحد في الغالب: تحويل سير عمل بشري فوضوي (تعيين، انتظار العميل، إعادة الفتح، نقل) إلى مؤقتات SLA واضحة وموثوقة.
ابدأ بتعريف الأحداث التي تتحكم في ساعة الـSLA لكل نوع تذكرة أو طلب. أنماط شائعة:
من هذه الأحداث، احسب وقت الاستحقاق. في SLAs الصارمة قد يكون "created_at + ساعتين". بالنسبة لـSLA على ساعات العمل، هو "ساعتان عمل"، ما يتطلب تقويمًا.
انشئ وحدة تقويم صغيرة تجيب سؤالين باستمرار:
احتفظ بالعطل، ساعات العمل، والمناطق الزمنية في مكان واحد لكي يستخدم كل منطق الـSLA نفس الحساب.
بعد الحصول على وقت الاستحقاق، حساب الوقت المتبقي بسيط: due_time - now (بالدقائق التجارية إن وُجدت). ثم عرّف عتبات خطر الانتهاك مثل "مستحق خلال 15 دقيقة" أو "أقل من 10% من الـSLA المتبقي". هذا يغذي شارات الأهمية وتوجيه التنبيهات.
يمكنك:
هجينة عملية: تحديثات مدفوعة بالأحداث للدقة، بالإضافة إلى نبضة على مستوى الدقيقة لالتقاط عبور العتبات الزمنية عندما لا تصل أحداث جديدة.
التنبيهات هي النقطة التي يصبح فيها مراقبة الـSLA عملية. الهدف ليس "المزيد من الإشعارات"—بل إيصال الشخص المناسب ليتخذ الإجراء الصحيح قبل فوات المهلة.
استخدم مجموعة صغيرة من أنواع التنبيهات مع نوايا واضحة:
طابق كل نوع بقناة تسليم مختلفة (chat للتحذيرات، paging للانتهاكات المؤكدة، إلخ).
يجب أن يكون التوجيه مدفوعًا بالبيانات، لا مشفوعًا بالترميز الثابت. استخدم جدول قواعد بسيط مثل: الخدمة → الفريق المالك، ثم طبّق معدلات تعديل:
هذا يتجنب "البث للجميع" ويجعل الملكية مرئية.
حالة الـSLA يمكن أن تتقلب سريعًا أثناء الاستجابة للحوادث. ألغِ التكرار بمفتاح ثابت مثل (ticket_id, sla_rule_id, alert_type) وطبّق:
فكّر أيضًا في تجميع تحذيرات متعددة في ملخّص دوري واحد.
كل إشعار يجب أن يجيب: “ما، متى، من، ما التالي”:
إن لم يستطع أحد التصرف خلال 30 ثانية من قراءة التنبيه، فالتنبيه يحتاج إلى سياق أفضل.
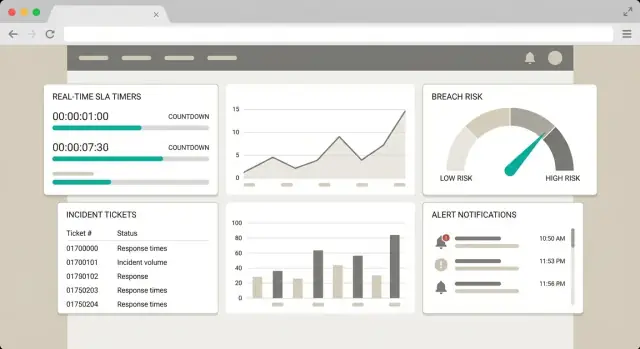
لوحة SLA الجيدة أقل عن الرسوم البيانية وأكثر عن مساعدة شخص لاتخاذ قرار خلال دقيقة. صمّم الواجهة حول ثلاث أسئلة: ما المعرض للخطر؟ لماذا؟ ما الإجراء؟
ابدأ بأربع عروض بسيطة، كلٌ لها هدف واضح:
اجعل العرض الافتراضي مركزًا على المعرّض للخطر قريبًا، لأن هناك تحدث الوقاية.
امنح المستخدمين مجموعة صغيرة من الفلاتر التي تتوافق مع الملكية وقرارات الترياج الواقعية:
اجعل الفلاتر مثبتة لكل مستخدم حتى لا يعيدوا ضبطها في كل زيارة.
كل صف في "المعرّض للخطر قريبًا" يجب أن يتضمن شرحًا قصيرًا وبسيطًا بالإنجليزية البسيطة، على سبيل المثال:
أضف درج "تفاصيل" يظهر جدولًا زمنيًا لتغيّرات حالة الـSLA (بدأ، أُوقِف، أعيد، انتهك)، حتى يثق المستخدم بالحساب دون القيام بعمليات حسابية.
صمّم سير العمل الافتراضي كالتالي: مراجعة → فتح → تصرّف → تأكيد.
يجب أن تحتوي كل بطاقة على أزرار إجراء تقود إلى مصدر الحقيقة:
إذا دعمت إجراءات سريعة (تعيين، تغيير أولوية، إضافة ملاحظة)، أظهرها حيث يمكنك تطبيقها بثبات ودوّن التغيير للتدقيق.
تطبيق مراقبة SLA في الزمن الحقيقي سرعان ما يصبح نظام سجل للأداء والحوادث وتأثير العملاء. عاملها كبرنامج إنتاجي من اليوم الأول: حد من الصلاحيات، احمِ بيانات العملاء، ووثّق كيفية تخزينها وحذفها.
ابدأ بنموذج صلاحيات صغير وواضح ووسّع عند الحاجة. إعداد شائع:
حافظ على التوافق بين الصلاحيات وسير العمل. مثلاً، قد يحدث مشغّل الحالة، لكن فقط المسؤول يغيّر مؤقتات الـSLA أو قواعد التصعيد.
مراقبة الـSLA غالبًا تتضمن معرّفات العملاء، درجات العقود، ومحتوى التذاكر. قلّل التعرض:
التكاملات نقطة ضعف متكررة:
حدد السياسات قبل أن تجمع شهورًا من التاريخ:
دوّن هذه القواعد وعكسها في الواجهة حتى يعرف الفريق ما يحتفظ به النظام—ولكم من الوقت.
اختبار تطبيق مراقبة الـSLA أقل عن "هل تحمل الواجهة" وأكثر عن "هل تُحسب المؤقتات، الإيقاف، والعتبات تمامًا كما يتوقع العقد—كل مرة". خطأ صغير (المنطقة الزمنية، ساعات العمل، الأحداث المفقودة) يمكنه خلق تنبيهات ضوضائية أو، والأسوأ، انتهاكات مفقودة.
حوّل قواعد الـSLA إلى سيناريوهات ملموسة يمكنك محاكاتها من الطرف إلى الطرف. اشمل التدفقات العادية وحالات الحافة المزعجة:
برهن أن منطق الكشف مستقر تحت فوضى التشغيل الحقيقية، ليس فقط بيانات العرض النظيفة.
أنشئ مجموعات أحداث قابلة لإعادة التشغيل: مكتبة صغيرة من "الجداول الزمنية للحوادث" التي يمكنك إعادة تمريرها عبر الاستيعاب والحساب كلما غيرت المنطق. هذا يساعد على التحقق من الحسابات عبر الزمن ويمنع التراجعات.
احتفظ بالمجموعات مهيكلة (في Git) وضمن المخرجات المتوقعة: الوقت المتبقي المحسوب، لحظة الانتهاك، نوافذ التوقف، ومحفزات التنبيه المتوقعة.
عامل مراقب الـSLA كنظام إنتاجي وأضف إشارات صحته الخاصة:
إن كانت لوحة العرض تُظهر "أخضر" بينما الأحداث متوقفة، ستفقد الثقة بسرعة.
اكتب كتاب تشغيل قصير وواضح لأنماط الفشل الشائعة: المستهلكات المتعثرة، تغييرات المخطط، انقطاعات الجهات العلوية، والعمليات الخلفية. ضمّن خطوات لإعادة تشغيل الأحداث وإعادة حساب المؤقتات بأمان (أي فترة، أي عملاء، وكيف تتجنب إرسال تنبيهات مزدوجة). اربطه من مستودع المستندات الداخلي أو صفحة بسيطة مثل /runbooks/sla-monitoring.
إطلاق تطبيق مراقبة SLA أسهل عندما تعامل الأمر كمنتج، لا كمشروع لمرة واحدة. ابدأ بإصدار قابل للحياة يظهر الحلقة من الطرف إلى الطرف: استيعاب → تقييم → تنبيه → تأكيد أنه ساعد شخصًا على التصرف.
اختر مصدر بيانات واحدًا، نوع SLA واحدًا، وتنبيهات أساسية. على سبيل المثال، راقب "وقت الاستجابة الأولية" باستخدام تغذية من نظام تذاكر واحد، وأرسل تنبيهًا عندما يقترب المؤقت من الانتهاء (وليس فقط بعد الانتهاك). هذا يبقي النطاق ضيقًا بينما تتحقق من الأجزاء الصعبة: الطوابع الزمنية، نوافذ العمل، والملكية.
بمجرد استقرار الـMVP، وسّع بخطوات صغيرة: أضف نوع SLA ثاني (مثلاً الحل)، ثم مصدر بيانات ثاني، ثم سير عمل أغنى.
أعد إعداد dev, staging, production مبكرًا. يجب أن يعكس الـstaging إعدادات الإنتاج (التكاملات، الجداول، مسارات التصعيد) دون إخطار المستجيبين الحقيقيين.
استخدم أعلام الميزة لطرح تدريجي:
إذا بنيت بسرعة مع منصة مثل Koder.ai، تكون اللقطات والرجوع مفيدة هنا: يمكنك نشر واجهة وقواعد إلى مجموعة تجريبية، ثم التراجع سريعًا إن كانت التنبيهات مزعجة.
اكتب وثائق إعداد قصيرة وعملية: “ربط مصدر البيانات”، “إنشاء SLA”، “اختبار تنبيه”، “ماذا تفعل عند الإخطار”. احتفظ بها قرب المنتج، مثلاً صفحة داخلية على /docs/sla-monitoring.
بعد الاعتماد الأولي، رتّب التحسينات التي تزيد الثقة وتقلل الضوضاء:
كرر بناءً على الحوادث الحقيقية: يجب أن تعلمك كل تنبيه ماذا تؤتمت، توضح، أو تزيل.
هدف مراقبة الـSLA هو بيان قابل للقياس يحدد:
اكتبه كهدف يمكن اختباره: “اكتشاف الانتهاكات المحتملة خلال X ثوانٍ وإخطار الحالي على النداء خلال Y دقائق.”
عرّف "الزمن الحقيقي" بناءً على قدرة فريقك على الاستجابة، لا على الممكن تقنياً.
المهم أن تلتزم بهدف زمني نهائي شامل (من الحدث → الحساب → التنبيه/لوحة العرض)، ثم صمم حوله.
ابدأ بمراقبة الوعود الموجهة للعملاء التي يمكن أن تُخترق فعلاً (وقد تترتب عليها تعويضات)، عادةً:
كثير من الفرق تراقب أيضاً SLO داخليٍّ أشد من SLA. إذا كان لديك كلاهما، خزن وعرِضهما حتى يتصرف المشغلون مبكراً بينما يتم الإبلاغ عن الامتثال التعاقدي بدقة.
أخطاء تعريف الـSLA هي سبب معظم الإشكالات. وضح:
ثم شفر هذه القواعد بشكل حتمي واحتفظ بمكتبة من جداول زمنية نموذجية لاختبارها.
حدد مجموعة تقويم واحدة متسقة:
نفّذ وحدة تقويم قابلة لإعادة الاستخدام تجيب على:
اختَر «نظام السجل» لكل حقل ودوِّن من يفوز عندما تتعارض الأنظمة.
مصادر نموذجية:
للسلوك شبه الحقيقي، فضّل ؛ أضف للمصالحة والأحداث الضائعة.
على الأقل، سجِّل الأحداث التي تبدأ أو توقف أو تغير ساعة الـSLA:
وانتبه للأحداث التي غالباً ما تُنسى كـتحديثات تقويم العمل، تغييرات المنطقة الزمنية، وتبديلات العطل — هذه تغيّر مواعيد الاستحقاق دون نشاط على التذكرة.
استخدم خط أنابيب بسيط من خمسة أجزاء:
أبقِ منطق الـSLA خارج طبقة الاستيعاب والحسابات الثقيلة خارج اللوحات. ابدأ بنموذج نشر بسيط (منطقة واحدة، بيئات حد أدنى) حتى تثق في جودة البيانات وفائدة التنبيهات.
اعتمد كلا النمطين بحسب الضرورة:
خلاصة عملية: تحديثات مدفوعة بالأحداث للدقة مع نقرة زمنية على مستوى الدقيقة لالتقاط عبور العتبات حتى عند غياب أحداث جديدة.
عامل التنبيه كـسير عمل لا كفيضان إشعارات:
(work_item_id, sla_rule_id, alert_type) وأرسل فقط عند الانتقالات مع نافذة تبريد.كل تنبيه يجب أن يتضمن: المالك/النداء، وقت الاستحقاق والوقت المتبقي، الإجراء التالي، وروابط مثل /tickets/{id} و/sla/tickets/{id}.