27 أغسطس 2025·6 دقيقة
مجموعات العمال في Go للمهام الخلفية: المحاولات، الإلغاء، والإيقاف النظيف
تساعد مجموعات العمال في Go الفرق الصغيرة على تشغيل المهام الخلفية مع إعادة المحاولة، الإلغاء، والإيقاف النظيف باستخدام أنماط بسيطة قبل إضافة بنية تحتية ثقيلة.
لماذا تتعقد المهام الخلفية بسرعة
في خدمة Go صغيرة، يبدأ العمل الخلفي عادة بهدف بسيط: إعادة الاستجابة HTTP بسرعة، ثم تنفيذ الأشياء البطيئة لاحقًا. قد يكون ذلك إرسال رسائل بريد إلكتروني، تغيير حجم صور، المزامنة مع API خارجي، إعادة بناء فهارس البحث، أو تشغيل تقارير ليلية.
المشكلة أن هذه المهام هي عمل حقيقي في الإنتاج، لكنها تفتقر لخطوط الحماية التي تحصل عليها طبيعيًا عند التعامل مع الطلبات. تشغيل goroutine من معالج HTTP يبدو مقبولًا إلى أن يحدث نشر أثناء تنفيذ المهمة، أو يبطئ API خارجي، أو تُعاد المحاولة على نفس الطلب فتفعل المهمة مرتين.
نقاط الألم الأولى متوقعة:
- مهام متوقفة: اتصال واحد يتجمد، ويتوقف تقدم العمال.
- عمل مكرر: محاولات على طبقة HTTP تعيد تشغيل نفس المهمة.
- لا خطة إيقاف: تنتهي العملية وتضيع الأعمال أو تبقى نصف منجزة.
- فشل صامت: تُسجّل الأخطاء مرة واحدة (أو لا تُسجّل) وتختفي.
- عواصف إعادة المحاولة: المهام الفاشلة تعيد المحاولة فورًا وتغمر التبعيات.
هنا يأتي دور نمط صغير وصريح مثل مجموعة عمال في Go. يجعل التزامن اختيارًا (N عمال)، ويحوّل "افعل هذا لاحقًا" إلى نوع مهمة واضح، ويمنحك مكانًا واحدًا للتعامل مع إعادة المحاولة، والمهلات، والإلغاء.
مثال: يحتاج تطبيق SaaS لإرسال فواتير. لا تريد 500 إرسال متزامن بعد استيراد دفعي، ولا تريد إعادة إرسال نفس الفاتورة لأن الطلب أُعيدت عليه المحاولة. تتيح مجموعة العمال تحديد معدل الإرسال ومعاملة "إرسال الفاتورة #123" كوحدة عمل متتبعة.
مجموعة العمال ليست الأداة المناسبة عندما تحتاج ضمانات متينة عبر العمليات. إذا كان لزامًا أن تبقى المهام بعد تعطل العمليات، أو تحتاج جدولًا زمنيًا للمستقبل، أو أن تعالجها خدمات متعددة، فستحتاج على الأرجح إلى صف حقيقي مع تخزين دائم لحالة المهمة.
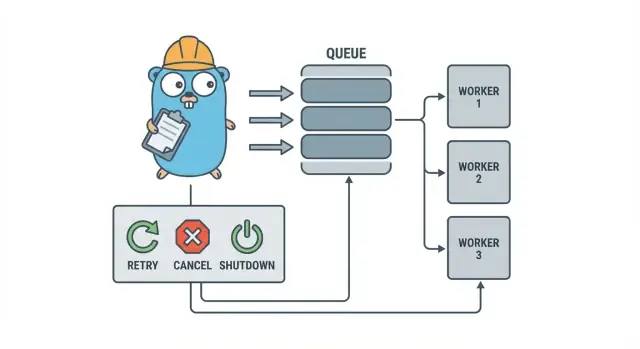
نموذج مجموعة العمال بلغة بسيطة
مجموعة العمال في Go مملة عمدًا: ضع العمل في طابور، اجعل مجموعة ثابتة من العمال تسحب منه، وتأكد أن كل شيء يمكن إيقافه نظيفًا.
المصطلحات الأساسية:
- مهمة (Job): وحدة عمل واحدة، مثل "غيّر حجم هذه الصورة" أو "أرسل هذه الفاتورة عبر البريد الإلكتروني".
- طابور (Queue): حيث تنتظر المهام.
- عامل (Worker): goroutine تأخذ مهمة وتشغّلها بشكل متكرر.
- موزع (Dispatcher): الجزء الذي يستقبل المهام ويغذّي الطابور.
في العديد من التصاميم داخل العملية، تُستخدم القناة (channel) كطابور. يمكن لقناة ذات مخزن مؤقت أن تحتفظ بعدد محدود من المهام قبل أن يحجب المنتجون. ذلك الحجب هو الضغط العكسي (backpressure)، وغالبًا ما يمنع خدمتك من قبول عمل غير محدود ونفاد الذاكرة عند ارتفاع الحركة.
حجم المخزن يغيّر شعور النظام. مخزن صغير يجعل الضغط مرئيًا بسرعة (النداء ينتظر أبكر). مخزن أكبر يُسهل التصدي للاندفاعات القصيرة لكنه قد يخفي التحميل المتزايد إلى أن يتفاقم. لا يوجد رقم مثالي، فقط رقم يناسب مقدار الانتظار الذي تتحمّله.
يمكنك أيضًا اختيار ما إذا كان حجم التجمع ثابتًا أم قابلًا للتغيير. التجمعات الثابتة أسهل للفهم وتحافظ على استخدام الموارد متوقعًا. يمكن أن تساعد زيادة العمال تلقائيًا في الحمل غير المتوازن، لكنها تضيف قرارات ستحتاج للصيانة (متى نوسع، بكم، ومتى نرجع).
أخيرًا، "التأكيد (ack)" في تجمع داخل العملية عادة يعني فقط أن العامل أكمل المهمة ولم يرجع خطأً. لا يوجد وسيط خارجي لتأكيد التسليم، لذا يحدد كودك معنى "تم" وما يحدث عند فشل أو إلغاء المهمة.
أهداف التصميم: إعادة المحاولة، الإلغاء، والإيقاف النظيف
ميكانيكيًا مجموعة العمال بسيطة: شغّل عددًا ثابتًا من العمال، غذّهم بالمهام، وعالجها. القيمة هي السيطرة: تزامن متوقع، تعامل واضح مع الفشل، ومسار إيقاف لا يترك عملًا نصف منجز.
ثلاثة أهداف تحافظ على سلامة الفرق الصغيرة:
- تحديد التزامن حتى لا يؤدي اندفاع واحد إلى انهيار قاعدة البيانات أو API خارجي.
- تجنب فقدان العمل (أو على الأقل معرفة ما الذي سقط ولماذا).
- البقاء قابلاً للتتبع: يجب أن تكون كل مهمة قابلة للتتبع عبر السجلات وبعض العدادات.
معظم الإخفاقات مملة، لكنك تريد التعامل معها بشكل مختلف:
- أخطاء عابرة (تقطعات الشبكة، حدود المعدل) التي يجب إعادة المحاولة عليها.
- أخطاء دائمة (مدخلات خاطئة، سجل مفقود) التي لا يجب إعادة المحاولة عليها.
- مهلات (تعليق تبعية) يجب قطعها حتى لا تسد العمال.
الإلغاء ليس هو نفسه "خطأ". إنه قرار: المستخدم ألغى، أو النشر استبدل عمليتك، أو خدمتك تُغلق. في Go عالِم الإلغاء كإشارة من الدرجة الأولى باستخدام context cancellation، وتأكد أن كل مهمة تتحقق منه قبل بدء عمل مكلف وفي نقاط آمنة أثناء التنفيذ.
الإيقاف النظيف هو المكان الذي تنهار فيه العديد من التجمعات. قرر مبكرًا ماذا يعني "آمن" لمهامك: هل تكمل العمل الجاري، أم تتوقف بسرعة ويعاد تشغيله لاحقًا؟ تدفق عملي مفيد هو:
- توقف عن قبول مهام جديدة.
- أخبر العمال بالتوقف بعد مهمتهم الحالية (أو التوقف فورًا).
- انتظر حتى موعد نهائي، ثم اخرج بالقوة.
إذا عرفّت هذه القواعد مبكرًا، تبقى إعادة المحاولة والإلغاء والإيقاف صغيرة ومتوقعة بدلًا من أن تتحول إلى إطار عمل كبير وفوضوي.
خطوة بخطوة: بناء مجموعة عامل أساسية
مجموعة العمال ليست إلا مجموعة goroutines تسحب المهام من قناة وتنفذ العمل. الجزء المهم هو جعل الأساسيات متوقعة: كيف تبدو المهمة، كيف يتوقف العاملون، وكيف تعرف متى انتهى كل العمل.
ابدأ بنوع Job بسيط. أعطه معرفًا (للـ logs)، حمولة (ماذا يُعالج)، عداد محاولات (مفيد لاحقًا لإعادة المحاولة)، طوابع زمنية، ومكان لتخزين بيانات سياق لكل مهمة.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
ستتخذ بعض الاختيارات العملية على الفور:
- اختر حجم الطابور بناءً على مقدار الانتظار الذي تستطيع تحمله.
- قرر ماذا يعني الضغط العكسي للنداءين: الانتظار، إرجاع خطأ، أم الحذف.
- اجعل
Stop()وWait()منفصلين حتى تتمكن من إيقاف القبول أولًا، ثم الانتظار لانتهاء العمل الجاري.
إضافة إعادة المحاولة دون تحويلها إلى إطار عمل ضخم
إعادة المحاولة مفيدة، لكنها أيضًا المكان الذي تتعقد فيه مجموعات العمال. اجعل الهدف ضيقًا: أعد المحاولة فقط عندما تكون المحاولة الأخرى لديها فرصة حقيقية للنجاح، وتوقف بسرعة عندما لا تكون هناك فرصة.
ابدأ بتحديد ما هو قابل لإعادة المحاولة. المشاكل المؤقتة (تقطعات الشبكة، المهلات، استجابات "حاول لاحقًا") عادةً تستحق إعادة المحاولة. المشاكل الدائمة (مدخلات خاطئة، سجل مفقود، إذن مرفوض) لا تستحق.
سياسة إعادة محاولة صغيرة عادةً كافية:
- وسم الأخطاء كقابلة لإعادة المحاولة أو غير قابلة (مثلاً لفّها بمساعد
Retryable(err)). - ضبط حد أقصى لعدد المحاولات (غالبًا 3 إلى 5). بعد ذلك عادةً تضيع الوقت.
- استخدم تناقصًا أسيًا مع تقلب (exponential backoff with jitter) حتى لا تُعاد المحاولات متزامنة.
- حدد سقفًا للتأخير (مثلاً لا تنام أكثر من 30 ثانية).
- سجّل محاولات إعادة المحاولة مع رقم المحاولة، التأخير التالي، ومعرف المهمة.
التراجع لا يحتاج لأن يكون معقّدًا. شكل شائع هو: delay = min(base * 2^(attempt-1), max)، ثم أضف تقلبًا (عشوائية ±20%). التقلب مهم لأن خلاف ذلك يفشل كثير من العمال معًا ويعاودون المحاولة معًا.
أين يعيش التأخير؟ للأنظمة الصغيرة، النوم داخل العامل مقبول، لكنه يشغل فتحة عامل. إذا كانت إعادة المحاولات نادرة، هذا مقبول. إذا كانت متكررة أو التأخيرات طويلة، فكر في إعادة إدخال المهمة في الطابور مع طابع "تشغيل بعد" حتى يظل العمال منشغلين بأعمال أخرى.
عند الفشل النهائي، كن صريحًا. خزّن المهمة الفاشلة (والخطأ الأخير) للمراجعة، سجّل ما يكفي من السياق لإعادة تشغيلها، أو دفعها إلى قائمة ميتة تفحصها بانتظام. تجنّب الإسقاط الصامت. تجمع يخفي الفشل أسوأ من عدم وجود إعادة محاولة.
الإلغاء والمهلات التي تؤدي فعليًا إلى إيقاف العمل
خطط سياسة إعادة المحاولة
ارسم قواعد إعادة المحاولة والتراجع أولاً، ثم اجعل Koder.ai يدمجها في مشغّل المهام.
لا يشعر تجمع العمال بالأمان إلا عندما يمكنك إيقافه. القاعدة البسيطة: مرّر context.Context عبر كل طبقة يمكن أن تحجب. هذا يعني الإرسال والتنفيذ والتنظيف.
إعداد عملي يستخدم حدّي زمن:
- مهلة لكل مهمة حتى لا تستحوذ مهمة على عامل إلى الأبد.
- مهلة إيقاف حتى تتمكن العملية من الخروج حتى لو لم تتعاون بعض المهام.
استخدم السياق من الطرف إلى الطرف
أعطِ كل مهمة سياقها المشتق من سياق العامل. بعد ذلك يجب أن يستخدم كل استدعاء بطيء (قاعدة بيانات، HTTP، قوائم، I/O ملف) ذلك السياق حتى يمكنه العودة مبكرًا.
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
إذا كان Run يستدعي قاعدة بياناتك أو مزوّد API، صِل السياق إلى تلك الاستدعاءات (مثل QueryContext، NewRequestWithContext، أو طرق العملاء التي تقبل السياق). إذا تجاهلت السياق في موضع واحد، يصبح الإلغاء "محاولة جادة" وغالبًا ما يفشل عندما تحتاجه.
العمل الجزئي وخطوات "آمنة لإعادة المحاولة"
قد يحدث الإلغاء في منتصف المهمة، لذا افترض أن العمل الجزئي طبيعي. اهدف إلى أن تكون الخطوات قابلة للتكرار (idempotent) حتى لا تولّد تكرارات. الأساليب الشائعة تشمل استخدام مفاتيح فريدة للإدخالات (أو upserts)، كتابة علامات تقدم (started/done)، تخزين النتائج قبل المتابعة، والتحقق من ctx.Err() بين الخطوات.
عامل الإيقاف كموعد نهائي: توقف عن قبول مهام جديدة، ألغِ سياقات العمال، وانتظر فقط حتى مهلة الإيقاف لخروج المهام الجارية.
الإيقاف النظيف: ماذا تفعل عند ضرورة خروج العملية
لإيقاف نظيف هدف واحد: توقف عن أخذ عمل جديد، أخبر العمل الجاري بالتوقف، واخرج دون ترك النظام في حالة غريبة.
ابدأ بالإشارات. في معظم عمليات النشر سترى SIGINT محليًا وSIGTERM من مدير العمليات أو وقت تشغيل الحاوية. استخدم سياق إيقاف يُلغى عند وصول إشارة، ومرره إلى التجمع ومعالجي المهام.
بعد ذلك، توقف عن قبول مهام جديدة. لا تدع المستدعين ينتظرون إلى الأبد محاولة الإرسال إلى قناة لم يعد أحد يقرأها. احتفظ بإرسال المهام وراء دالة واحدة تفحص علامة الإغلاق أو تختار على سياق الإيقاف قبل الإرسال.
ثم قرر ماذا يحدث للمهام الموجودة في الطابور:
- التفريغ (Drain): أكمل ما هو في الطابور بالفعل، لكن ارفض الإرسالات الجديدة.
- الإسقاط (Drop): تجاهل أي شيء لم يبدأ بعد.
التفريغ أكثر أمانًا لأمور مثل المدفوعات والبريد الإلكتروني. الإسقاط مناسب للمهام "إن كانت مفيدة" مثل إعادة حساب ذاكرة التخزين المؤقت.
تسلسل إيقاف عملي:
- التقاط SIGINT/SIGTERM وإلغاء سياق مشترك.
- إيقاف الإرسال (إغلاق مسار الإرسال، وليس بالضرورة قناة العمل).
- دع العمال يكملون أو ينهون بناءً على السياق.
- انتظر العمال باستخدام WaitGroup.
- طبق موعدًا نهائيًا ثم اخرج.
الموعد النهائي مهم. على سبيل المثال، امنح المهام الجارية 10 ثوانٍ للتوقف. بعد ذلك، سجّل ما يزال يعمل واخرج. هذا يجعل عمليات النشر متوقعة ويتجنب عمليات معلقة.
السجلات والقياسات البسيطة لمجموعات العمال
نمذجة خط أنابيب مهمة الفاتورة
ولّد مسار تحويل الطلب إلى فاتورة وحلقة العامل الخلفي من مواصفة واحدة.
عندما تفشل مجموعة العمال، نادرًا ما تفشل بصوت عالٍ. تتباطأ المهام، تتكدس إعادة المحاولات، ويبلغ أحدهم أن "لا شيء يحدث". السجلات وبعض العدادات الأساسية تحول ذلك إلى قصة واضحة.
أعطِ كل مهمة معرفًا ثابتًا (أو أنشئه عند الإرسال) وضمنه في كل سطر سجل. حافظ على اتساق السجلات: سطر عند بدء المهمة، سطر عند انتهائها، وسطر عند فشلها. إذا أعدت المحاولة، سجّل رقم المحاولة والتأخير التالي.
شكل سجل بسيط:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
يمكن أن تبقى المقاييس قليلة وتؤدي فائدة كبيرة. تتبع طول الطابور، المهام الجارية، إجمالي النجاحات والإخفاقات، وكمون المهمة (على الأقل المتوسط والحد الأقصى). إذا ظل طول الطابور يتزايد والمهام الجارية ملتصقة عند عدد العمال، فأنت مشبع. إذا بدا أن المرسلين يحجبون عند الإرسال إلى قناة jobs، فالضغط العكسي يصل إلى المستدعي. هذا ليس سيئًا دائمًا، لكنه يجب أن يكون مقصودًا.
عندما "تتوقف المهام" افحص ما إذا كانت العملية لا تزال تستقبل مهام، ما إذا كان طول الطابور يتزايد، ما إذا كان العمال على قيد الحياة، وأي المهام ظلت تعمل لأطول مدة. الأوقات الطويلة عادةً تشير إلى مهلات مفقودة، تبعيات بطيئة، أو حلقة إعادة محاولة لا تنتهي.
مثال واقعي: قائمة انتظار خلفية صغيرة لـ SaaS
تخيل SaaS صغير يتغير فيه الطلب إلى PAID. بعد الدفع تحتاج لإرسال ملف PDF للفاتورة، إرسال بريد إلى العميل، وإخطار الفريق الداخلي. لا تريد أن يعيق ذلك طلب الويب. هذا مناسب لمجموعة عامل لأن العمل حقيقي لكن النظام ما زال صغيرًا.
يمكن أن تكون حمولة المهمة بسيطة: تكفي لجلب الباقي من قاعدة البيانات. معالج الـ API يكتب صفًا مثل jobs(status='queued', type='send_invoice', payload, attempts=0) في نفس المعاملة مع تحديث الطلب، ثم حلقة الخلفية تستعلم عن المهام المعلّقة وتدفعها إلى قناة العمال.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
عندما يلتقطه عامل، المسار السعيد بسيط: حمّل الطلب، أنشئ الفاتورة، نادِ مزود البريد، ثم علم أن المهمة انتهت.
إعادة المحاولة هي حيث يصبح الأمر حقيقيًا. إذا كان مزود البريد لديك يعاني انقطاعًا مؤقتًا، لا تريد 1,000 مهمة تفشل إلى الأبد أو تضرب المزود كل ثانية. نهج عملي هو:
- عامل أخطاء الشبكة واستجابات 5xx كقابلة لإعادة المحاولة.
- استخدم تناقصًا أسيًا بسقف محدود (مثلاً 5s, 15s, 45s, 2m).
- حدد حدًا لمحاولات (مثلاً 10) ثم علم أن المهمة فشلت.
- سجّل الخطأ الأخير حتى يتمكن الدعم من رؤية ما حدث.
خلال الانقطاع، تنتقل المهام من queued إلى in_progress، ثم تعود إلى queued مع وقت تشغيل مستقبلي. عندما يتعافى المزود، يقوم العمال بتفريغ التراكم طبيعيًا.
تخيل الآن نشرًا. ترسل SIGTERM. يجب أن تتوقف العملية عن أخذ عمل جديد لكنها تكمل ما هو جاري. أوقف الاستعلام، أوقف تغذية قناة العمال، وانتظر العمال بمهلة. تُعلَم المهام المكتملة كمنتهية. المهام التي تظل قيد التشغيل عندما يحين موعد المهلة يجب أن تعاد إلى queued (أو تُترك في in_progress مع مراقب) حتى يلتقطها الإصدار الجديد.
أخطاء شائعة وفخاخ
معظم الأخطاء في المعالجة الخلفية ليست في منطق المهمة. إنها من أخطاء التنسيق التي تظهر تحت الحمل أو أثناء الإيقاف.
فخ كلاسيكي هو إغلاق قناة من أكثر من مكان واحد. النتيجة panic يصعب إعادة إنتاجها. اختر مالكًا واحدًا لكل قناة (عادة المنتج)، واجعله الوحيد الذي يستدعي close(jobs).
إعادة المحاولة مجال آخر حيث النوايا الحسنة تسبب انقطاعات. إذا أعدت المحاولة على كل شيء، ستعيد المحاولة حتى على الأخطاء الدائمة. هذا يهدر الوقت، يزيد الحمل، ويمكن أن يحول مشكلة صغيرة إلى حادث. صنّف الأخطاء وحدّ من المحاولات بسياسة واضحة.
التكرارات ستحدث حتى مع تصميم حذر. قد يتعطل عامل خلال مهمة، قد تنطلق مهلة بعد انتهاء العمل، أو قد تعيد إدخال المهمة أثناء النشر. إذا لم تكن المهمة قابلة للتكرار، تصبح التكرارات ضررًا حقيقيًا: فاتورتان، بريدان ترحيبيان، ردّان.
الأخطاء التي تظهر كثيرًا:
- إغلاق نفس القناة من أكثر من goroutine.
- إعادة محاولة الأخطاء الدائمة بدلًا من إظهارها.
- لا وجود لمفتاح عدم التكرار، فتسبب التكرارات آثارًا جانبية مزدوجة.
- طوابير غير محدودة في الذاكرة تكبر حتى يحدث ارتفاع في الذاكرة.
- تجاهل
context.Context، فتستمر المهام بعد بدء الإيقاف.
الطوابير غير المحدودة مخادعة بشكل خاص. قد يتجمع اندفاع عمل داخل الذاكرة بهدوء. فضِّل قناة ذات مخزن محدود وقرّر ماذا يحدث عند امتلائها: انتظر، احذف، أم أرجع خطأ.
قائمة تحقق سريعة قبل الإطلاق
نشر العامل الخلفي الخاص بك
انشر تطبيق Go الخاص بك مع دعم الاستضافة عندما تكون جاهزًا للتشغيل.
قبل أن تضع مجموعة العمال في الإنتاج، يجب أن تكون قادرًا على وصف دورة حياة المهمة بصوت عالٍ. إذا سأل أحدهم "أين هذه المهمة الآن؟"، لا ينبغي أن يكون الجواب تخمينًا.
قائمة فحص عملية قبل الإقلاع:
- يمكنك تسمية كل حالة وانتقال: queued, picked up, running, finished, failed (وماذا يحركها بين الحالات).
- التزامن هو مقبض واحد (مثل
workerCount)، وتغييره لا يتطلب إعادة كتابة الشيفرة. - إعادة المحاولة محدودة: عدد المحاولات الأقصى واضح، التراجع ينمو، والفشل الدائم يذهب لمكان مقصود.
- سلوك الإيقاف مثبت: توقف عن القبول، دع المهام الجارية تنتهي، ولا يزال هناك مهلة صارمة.
- السجلات تجيب الأساسيات: معرف المهمة، رقم المحاولة، المدة، وسبب الخطأ.
قم بتمرين واقعي واحد قبل الإصدار: ضع في الطابور 100 مهمة "إرسال إيصال بريد إلكتروني"، اجعل 20 منها تفشل قسريًا، ثم أعد تشغيل الخدمة أثناء التشغيل. ينبغي أن ترى إعادة المحاولات تعمل كما هو متوقع، لا آثار جانبية مكررة، والإلغاء فعليًا يوقف العمل عندما ينتهي المهلة.
إذا كان أي بند غامضًا، شدده الآن. تعديلات صغيرة هنا توفر أيامًا لاحقًا.
الخطوات التالية: متى تضيف بنية تحتية أثقل (ومتى لا)
تجمع داخل العملية غالبًا يكفي بينما المنتج صغير. إذا كانت مهامك "إنها جيدة أن تكون موجودة" (إرسال بريد، تحديث ذاكرة التخزين المؤقت، توليد تقارير) ويمكن إعادة تشغيلها، فمجموعة العمال تبقي النظام سهل الفهم.
علامات أنك تجاوزت تجمع داخل العملية
راقب هذه النقاط:
- تشغيل مثيلات تطبيق متعددة وتحتاج أن يلتقطها واحد منها فقط.
- تحتاج إلى متانة (المهام يجب أن تبقى بعد الأعطال والنشر).
- تحتاج سجل تدقيقي: من وضع المهمة ومتى وماذا كانت النتيجة بالضبط.
- تحتاج ضوابط ضغط عكسي عبر الخدمات، وليس فقط داخل عملية واحدة.
- تحتاج جدولة صارمة أو تأخيرات طويلة (ساعات أو أيام) مع استيقاظ موثوق.
إذا لم يكن أي من ذلك صحيحًا، فقد تضيف الأدوات الأثقل مزيدًا من التعقيد أكثر من القيمة.
الترحيل تدريجيًا دون إعادة كتابة كاملة
الضمان الأفضل هو واجهة مهمة مستقرة: نوع حمولة صغير، معرف، ومعالج يُرجع نتيجة واضحة. بعد ذلك يمكنك تبديل خلفية الطابور لاحقًا (من قناة داخل الذاكرة إلى جدول قاعدة بيانات، ثم إلى صف مخصّص) دون تغيير منطق العمل.
خطوة وسط عملية هي خدمة Go صغيرة تقرأ المهام من PostgreSQL، تطالب بها بقفل، وتحدّث الحالة. تحصل على المتانة وإمكانية التدقيق الأساسية مع الاحتفاظ بنفس منطق العامل.
إذا أردت نموذجًا سريعًا، يمكن لـ Koder.ai (koder.ai) توليد مشروع بداية Go + PostgreSQL من محادثة، متضمنًا جدول مهام حلقة عامل خلفية، ولقطات واسترجاع يمكنها المساعدة أثناء ضبط إعادة المحاولة وسلوك الإيقاف.