10 يوليو 2025·7 دقيقة
نماذج بسيطة لطابور مهام الخلفية للبريد الإلكتروني والويبهوكس
تعلم نماذج بسيطة لطابور مهام خلفية لإرسال البريد، تشغيل التقارير، وتسليم الويبهوكس مع إعادة محاولات، تباطؤ، والتعامل مع الـ dead-letter، دون أدوات ثقيلة.
تعلم نماذج بسيطة لطابور مهام خلفية لإرسال البريد، تشغيل التقارير، وتسليم الويبهوكس مع إعادة محاولات، تباطؤ، والتعامل مع الـ dead-letter، دون أدوات ثقيلة.
أي عمل قد يستغرق أكثر من ثانية أو اثنتين لا ينبغي أن يعمل داخل طلب المستخدم. إرسال الرسائل الإلكترونية، إنشاء التقارير، وتسليم الويبهوكس كلها تعتمد على الشبكات، خدمات طرف ثالث، أو استعلامات بطيئة. أحيانًا تتوقف، تفشل، أو تستغرق وقتًا أطول مما تتوقع.
إذا قمت بتلك الأعمال بينما ينتظر المستخدم، يلاحظ الناس ذلك فورًا. الصفحات تتجمد، أزرار "حفظ" تستمر في الدوران، وتنفد الطلبات مهلة. قد تحدث محاولات إعادة في المكان الخطأ أيضًا. يقوم المستخدم بالتحديث، أو موازن التحميل يعيد المحاولة، أو الواجهة الأمامية تعيد الإرسال، وتُنتهي بك المطاف برسائل مكررة، نداءات ويبهوك مكررة، أو تشغيل تقريرين يتنافسان مع بعضهما.
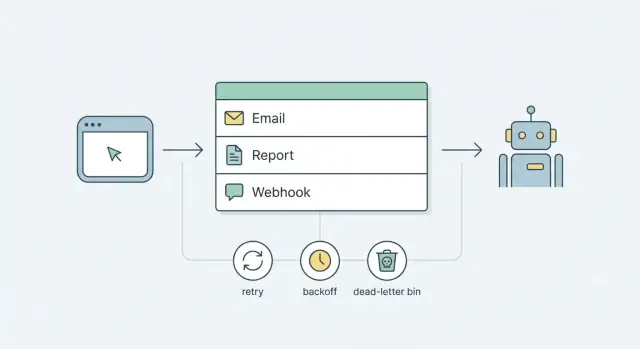
تحل المهام الخلفية هذه المشكلة بجعل الطلبات صغيرة ومتوقعة: استقبل الإجراء، سجّل مهمة لتُنفذ لاحقًا، وأجب بسرعة. تُنفذ المهمة خارج مسار الطلب، وفق قواعد تتحكم بها.
الجزء الصعب هو الموثوقية. بمجرد أن ينتقل العمل خارج مسار الطلب، عليك الإجابة عن أسئلة مثل:
تستجيب العديد من الفرق بإضافة "بنية تحتية ثقيلة": وسيط رسائل، أساطيل عاملين منفصلة، لوحات تحكم، تنبيهات، ودليل تشغيل. تلك الأدوات مفيدة عندما تحتاجها فعلاً، لكنها تضيف أيضًا أجزاء متحركة جديدة وأنماط فشل جديدة.
هدف البداية الأفضل أبسط: مهام موثوقة باستخدام أجزاء لديك بالفعل. لمعظم المنتجات، يعني ذلك طابور مدعوم بقاعدة بيانات بالإضافة إلى عملية عامل صغيرة. أضف استراتيجية واضحة لإعادة المحاولة والتباطؤ، ونمط طابور رسائل ميتة للمهام التي تستمر في الفشل. تحصل على سلوك متوقع دون الالتزام بمنصة معقدة من اليوم الأول.
حتى لو كنت تبني بسرعة باستخدام أداة دردشة مثل Koder.ai، يبقى هذا الفصل مهمًا. يجب أن يحصل المستخدم على استجابة سريعة الآن، وينهي نظامك العمل البطيء والمعرض للفشل بأمان في الخلفية.
الطابور هو خط انتظار للعمل. بدلاً من تنفيذ المهام البطيئة أو غير الموثوقة أثناء طلب المستخدم (إرسال بريد، إنشاء تقرير، نداء ويبهوك)، تضع سجلًا صغيرًا في الطابور وترد سريعًا. لاحقًا، عملية منفصلة تلتقط ذلك السجل وتنفّذ العمل.
بعض الكلمات التي سترى كثيرًا:
التدفق الأبسط يبدو هكذا:
Enqueue: تطبيقك يحفظ سجل مهمة (النوع، الحمولة، وقت التشغيل).
Claim: العامل يجد المهمة المتاحة التالية و"يقفلها" بحيث لا يعمل عليها سوى عامل واحد.
Run: العامل يؤدي المهمة (إرسال، توليد، تسليم).
Finish: علم أنها انتهت، أو سجّل فشلًا وحدد وقت التشغيل التالي.
إذا كان حجم المهام معتدلًا ولديك قاعدة بيانات بالفعل، فطابور مدعوم بقاعدة بيانات غالبًا ما يكفي. سهل الفهم، سهل التصحيح، ويلبي احتياجات شائعة مثل معالجة رسائل البريد وموثوقية تسليم الويبهوكس.
منصات البث تبدأ أن تكون ذات معنى عندما تحتاج إلى قدرة تمرير عالية جدًا، الكثير من المستهلكين المستقلين، أو القدرة على إعادة تشغيل سجلات أحداث ضخمة عبر أنظمة كثيرة. إذا كنت تشغّل عشرات الخدمات بملايين الأحداث في الساعة، أدوات مثل Kafka قد تساعد. حتى ذلك الحين، جدول قاعدة بيانات زائد حلقة عامل يغطي الكثير من حالات الطابور الواقعية.
يبقى طابور قاعدة البيانات مرتبًا فقط إذا أجاب كل سجل مهمة عن ثلاثة أسئلة بسرعة: ما الذي يجب فعله، متى نحاول التالي، وماذا حدث في المرة الأخيرة. إذا فعلت ذلك بشكل صحيح تصبح العمليات مملة (وهذا هو الهدف).
خزن أصغر مدخل مطلوب لأداء العمل، لا المخرج المُولَّد بالكامل. الحمولات الجيدة هي معرفات وبعض المعاملات مثل { "user_id": 42, "template": "welcome" }.
تجنب تخزين كتل كبيرة (HTML كامل للبريد، بيانات تقرير كبيرة، أجسام ويبهوك ضخمة). ذلك يجعل قاعدة البيانات تنمو أسرع ويصعب التصحيح. إذا احتاجت المهمة مستندًا كبيرًا، خزّن مرجعًا بدلاً من ذلك: report_id، export_id، أو مفتاح ملف. يستطيع العامل جلب البيانات الكاملة عند التشغيل.
على الأقل، أجرِ مساحة لـ:
job_type المعالج (send_email, generate_report, deliver_webhook). يحمل payload مدخلات صغيرة مثل المعرفات والخيارات.queued, running, succeeded, failed, dead).attempt_count و max_attempts حتى تتوقف عن إعادة المحاولة عندما لا يفيد.created_at و next_run_at (متى تصبح مؤهلة). أضف started_at و finished_at إذا أردت رؤية أفضل للمهام البطيئة.idempotency_key لمنع التأثيرات المزدوجة، و last_error لترى سبب الفشل بدون الغوص في الكثير من السجلات.قابلية التكرار تبدو فخمة، لكن الفكرة بسيطة: إذا نفّذت نفس المهمة مرتين، يجب أن تكتشف المرة الثانية ذلك ولا تفعل شيئًا خطيرًا. على سبيل المثال، يمكن لمهمة تسليم ويبهوك استخدام مفتاح idempotency مثل webhook:order:123:event:paid حتى لا تسلم نفس الحدث مرتين إذا تداخلت إعادة المحاولة مع نفاد مهلة.
التقط أيضًا بعض الأرقام الأساسية مبكرًا. لا تحتاج لوحة تحكم ضخمة لتبدأ، فقط استعلامات تخبرك: كم عدد المهام في الطابور، كم تفشل، وعمر أقدم مهمة في الطابور.
إذا كان لديك قاعدة بيانات بالفعل، يمكنك بدء طابور خلفي بدون إضافة بنية جديدة. المهام هي صفوف، والعامل عملية تستمر في اختيار الصفوف المستحقة وتنفيذ العمل.
اجعل الجدول صغيرًا ومملًا. تريد حقولًا كافية للتشغيل، إعادة المحاولة، وتصحيح المشاكل لاحقًا.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
إذا بنيت على Postgres (شائع مع backends بلغة Go)، jsonb طريقة عملية لتخزين بيانات المهمة مثل { "user_id":123,"template":"welcome" }.
عندما يجب أن يؤدي إجراء مستخدم مهمة (إرسال بريد، إطلاق webhook)، اكتب صف المهمة في نفس معاملة قاعدة البيانات مع التغيير الرئيسي عندما يكون ذلك ممكنًا. هذا يمنع "المستخدم تم إنشاؤه لكن المهمة مفقودة" إذا حدث تعطل بعد الكتابة الرئيسية مباشرة.
مثال: عند تسجيل مستخدم، أدخل صف المستخدم ومهمة send_welcome_email في معاملة واحدة.
يكرر العامل نفس الدورة: اعثر على مهمة مستحقة، ادّعها حتى لا يأخذها أحد، عالجها، ثم علمها منتهية أو جدولة إعادة المحاولة.
عمليًا، يعني ذلك:
status='queued' و next_run_at <= now().SELECT ... FOR UPDATE SKIP LOCKED نهج شائع).status='running', locked_at=now(), locked_by='worker-1'.done/succeeded)، أو سجّل last_error وحدد المحاولة التالية.يمكن أن تعمل عدة عوامل في نفس الوقت. خطوة الادعاء تمنع الالتقاط المزدوج.
عند الإغلاق، توقف عن أخذ مهام جديدة، أتم المهمة الحالية، ثم اخرج. إذا ماتت عملية أثناء المهمة، استخدم قاعدة بسيطة: اعتبر المهام العالقة في running بعد مهلة كقابلة لإعادة الإدراج بواسطة مهمة دورية "reaper".
إذا كنت تبني في Koder.ai، فإن نمط طابور قاعدة البيانات هذا افتراضي قوي للرسائل، التقارير، والويبهوكس قبل إضافة خدمات طابور متخصصة.
إعادة المحاولات هي كيف يبقى الطابور هادئًا عندما يكون العالم الحقيقي فوضويًا. بدون قواعد واضحة، تتحول إعادة المحاولات إلى حلقة مزعجة ترسل رسائل إلى المستخدمين، تضرب واجهات برمجة التطبيقات، وتخفي الخطأ الحقيقي.
ابدأ بتقرير ما يجب إعادة المحاولة وما يجب فشلها سريعًا.
أعد المحاولة للمشاكل المؤقتة: مهل الشبكة، أخطاء 502/503، حدود المعدل، أو انقطاع اتصال قاعدة البيانات.
افشل سريعًا عندما لا تنجح المهمة: عنوان بريد مفقود، استجابة 400 من webhook لأن الحمولة غير صالحة، أو طلب تقرير لحساب محذوف.
التباطؤ هو الوقف بين المحاولات. التباطؤ الخطي (5s, 10s, 15s) بسيط، لكنه قد يخلق موجات من الحركة. التباطؤ الأُسّي (5s, 10s, 20s, 40s) يوزع الحمل بشكل أفضل وغالبًا ما يكون أكثر أمانًا للويبهوكس ومزودي الطرف الثالث. أضف jitter (تأخير عشوائي صغير) حتى لا تعيد آلاف المهام المحاولة في نفس الثانية بعد انقطاع.
قواعد تتصرف جيدًا في الإنتاج:
حد المحاولات يتعلق بحدّ الضرر. بالنسبة للعديد من الفرق، 5 إلى 8 محاولات تكفي. بعد ذلك، أوقف إعادة المحاولة وضع المهمة للمراجعة (تدفق dead-letter) بدلًا من التكرار إلى الأبد.
المهلات تمنع "المهام الزومبي". قد تكون مهلات البريد 10 إلى 20 ثانية لكل محاولة. عادةً يحتاج الويبهوكس لمجال أقصر، مثل 5 إلى 10 ثوانٍ، لأن المتلقي قد يكون معطلاً وتريد المتابعة. قد تسمح تقارير التوليد بدقائق، لكنها يجب أن تملك حدًا صارمًا.
إذا بنيت هذا في Koder.ai، اعتبر should_retry, next_run_at, ومفتاح idempotency كحقول أساسية. تلك التفاصيل الصغيرة تبقي النظام هادئًا عند حدوث مشكلة.
حالة الطابور الميت هي المكان الذي تذهب إليه المهام عندما لا تكون إعادة المحاولة آمنة أو مفيدة. تحول الفشل الصامت إلى شيء يمكنك رؤيته، والبحث فيه، والتصرف بشأنه.
احفظ ما يكفي لفهم ما حدث ولإعادة تشغيل المهمة دون تخمين، لكن كن حذرًا بشأن الأسرار.
احتفظ بـ:
إذا كانت الحمولة تحتوي على رموز أو بيانات شخصية، احذفها أو شفّرها قبل التخزين.
عندما تصل مهمة إلى dead-letter، اتخذ قرارًا سريعًا: أعد المحاولة، أصلح، أم تجاهل.
إعادة المحاولة للمشكلات الخارجية والانقطاعات. الإصلاح للبيانات الخاطئة (بريد مفقود، عنوان webhook خاطئ) أو خطأ في الكود. التجاهل يجب أن يكون نادرًا، لكنه ممكن عندما لم تعد المهمة ذات صلة (مثلاً حذف العميل). إذا تجاهلت، سجّل سببًا حتى لا يبدو أن المهمة اختفت.
إعادة إدراج يدوية هي الأكثر أمانًا عندما تُنشئ مهمة جديدة وتبقي القديمة غير قابلة للتغيير. علم مهمة الـ dead-letter بمن أعاد إدراجها، متى، ولماذا، ثم أدخل نسخة جديدة بمعرف جديد.
للتنبيه، راقب إشارات عادةً ما تعني ألمًا حقيقيًا: ارتفاع سريع في عدد الـ dead-letter، تكرار نفس الخطأ عبر مهام كثيرة، ومهام قديمة في الطابور لا يتم الادعاء عليها.
إذا كنت تستخدم Koder.ai، لقطات الحالة والرجوع يمكن أن تساعد عندما يؤثر إصدار سيء على الفشل فجأة، لأنك تستطيع التراجع بسرعة أثناء التحقيق.
أخيرًا، أضف صمامات أمان لانقطاعات البائعين. قلل معدل الإرسال لكل مزود، واستخدم قاطع دائرة: إذا كان مستلم webhook يفشل بشدة، أوقف المحاولات الجديدة لفترة قصيرة حتى لا تغمر خوادمهم (وخوادمك).
يعمل الطابور أفضل عندما يكون لكل نوع مهمة قواعد واضحة: ما الذي يُعد نجاحًا، ما يجب إعادة محاولته، وما الذي يجب ألا يحدث مرتين مطلقًا.
البريد الإلكتروني. معظم فشل البريد مؤقت: مهلات المزود، حدود المعدل، أو انقطاعات قصيرة. عاملها كقابلة لإعادة المحاولة مع تباطؤ. الخطر الأكبر هو الإرسال المكرر، لذا اجعل وظائف البريد قابلة للتكرار. خزّن مفتاح تفادي ثابت مثل user_id + template + event_id وامتنع عن الإرسال إذا كان المفتاح معلمًا بالفعل كمرسل.
يستحق أيضًا تخزين اسم القالب وإصدارَه (أو هاش للمحتوى المولَّد). إذا احتجت لإعادة تشغيل المهام، يمكنك اختيار إعادة إرسال نفس المحتوى بالضبط أو إعادة التوليد من القالب الأحدث. إذا أعاد المزود معرف رسالة، احفظه لتتبع الدعم.
التقارير. تفشل التقارير بطرق مختلفة. قد تعمل لدقائق، تضرب حدود التصفح (pagination)، أو تستنفد الذاكرة إذا فعلت كل شيء دفعة واحدة. قسم العمل إلى قطع أصغر. نمط شائع: مهمة "طلب تقرير" واحدة تنشئ العديد من مهام "صفحة" أو "شق"، كل منها يعالج شريحة من البيانات.
خزن النتائج للتحميل لاحقًا بدلاً من إبقاء المستخدم منتظرًا. يمكن أن يكون ذلك جدولًا في قاعدة البيانات مفهرسًا بـ report_run_id، أو مرجع ملف بالإضافة إلى بيانات وصفية (status, row count, created_at). أضف حقول تقدم حتى تعرض الواجهة "قيد المعالجة" مقابل "جاهز" دون تخمين.
الويبهوكس. الويبهوكس تتعلق بموثوقية التسليم، لا بالسرعة. وقع كل طلب (مثلاً HMAC بمفتاح مشترك) وأدرج طابعًا زمنيًا لمنع إعادة التشغيل.
قواعد بسيطة:
الترتيب والأولوية. معظم المهام لا تحتاج ترتيبًا صارمًا. عندما يكون الترتيب مهمًا، فعادة ما يكون لكل مفتاح (لكل مستخدم، لكل فاتورة، لكل نقطة نهاية webhook). أضف group_key وشغّل مهمة واحدة فقط جارية لكل مفتاح.
للالوية، افصل العمل العاجل عن البطيء. لا ينبغي أن يؤخر تراكم تقارير كبيرة رسائل إعادة تعيين كلمة المرور.
مثال: بعد عملية شراء، أدرج في الطابور (1) بريد تأكيد الطلب، (2) webhook للشريك، و(3) مهمة تحديث تقرير. البريد يعيد المحاولة بسرعة، الويبهوك يعيد المحاولة أبطأ مع تباطؤ، والتقرير يعمل لاحقًا بأولوية منخفضة.
يسجل مستخدم في تطبيقك. يجب أن تحدث ثلاثة أشياء، لكن لا يجب أن تبطئ صفحة التسجيل: إرسال بريد ترحيبي، إخطار CRM عبر webhook، وإدراج المستخدم في تقرير نشاط ليلي.
بعد إنشاء سجل المستخدم مباشرة، اكتب ثلاثة صفوف مهمة في طابور قاعدة البيانات. كل صف لديه نوع، حمولة (مثل user_id), حالة، عدد محاولات، وnext_run_at.
دورة الحياة النموذجية تبدو هكذا:
queued: أنشئت وتنتظر عاملًاrunning: عامل قد ادعاهاsucceeded: انتهت، لا عمل إضافيfailed: فشلت، مجدولة لاحقًا أو انتهت المحاولاتdead: فشلت مرات كثيرة وتحتاج نظر إنسانيمهمة البريد الترحيبي تتضمن مفتاح idempotency مثل welcome_email:user:123. قبل الإرسال، يفحص العامل جدول مفاتيح القابلية للتكرار المكتملة (أو يطبق قيدًا فريدًا). إذا نفذت المهمة مرتين بسبب تعطل، ترى الجولة الثانية المفتاح وتتخطى الإرسال. لا رسائل ترحيب مزدوجة.
الآن نقطة نهاية CRM للويبهوك معطلة. تفشل مهمة الويبهوك بنفاد مهلة. يحدد عامل إعادة محاولة باستخدام تباطؤ (مثلاً: دقيقة، 5 دقائق، 30 دقيقة، ساعتان) مع قليل من jitter حتى لا تعيد الكثير من المهام المحاولة في نفس الثانية.
بعد بلوغ الحد الأقصى للمحاولات، تصبح المهمة dead. لا يزال المستخدم مسجلًا، تلقى البريد الترحيبي، ومهمة التقرير الليلي تعمل كالمعتاد. فقط إخطار CRM عالق، وهو مرئي.
في الصباح التالي، يمكن للدعم (أو من هو متاح) التعامل معه دون الغوص في السجلات لوقت طويل:
webhook.crm).dead إلى queued, أعد ضبط المحاولات) أو عطِّل الوجهة مؤقتًا.إذا بنيت التطبيقات على منصة مثل Koder.ai، ينطبق نفس النمط: حافظ على سير المستخدم سريعًا، ادفع الآثار الجانبية إلى مهام، واجعل الفشل سهل التفقد وإعادة التشغيل.
أسرع طريقة لكسر طابور هي اعتباره خيارًا. تبدأ الفرق غالبًا بـ "أرسل البريد داخل الطلب هذه المرة فقط" لأنه يبدو أبسط. ثم ينتشر: إعادة تعيين كلمة المرور، الإيصالات، webhooks، تصدير التقارير. قريبًا يصبح التطبيق بطيئًا، ترتفع مهلات الطلبات، وأي مشكلة طرف ثالث تصبح انقطاعًا لديك.
فخ شائع آخر هو تجاهل القابلية للتكرار. إذا كانت المهمة قد تعمل مرتين، يجب ألا تخلق نتيجتين. بدون قابلية التكرار، تتحول إعادة المحاولات إلى رسائل مكررة، أحداث webhooks مكررة، أو أسوأ.
مشكلة ثالثة هي الرؤية. إذا كنت تتعلم عن الفشل من تذاكر الدعم فقط، الطابور يؤذي المستخدمين بالفعل. حتى نظرة داخلية بسيطة تظهر عدادات المهام حسب الحالة بالإضافة إلى last_error قابلة للبحث توفر وقتًا ثمينًا.
بعض المشاكل تظهر مبكرًا، حتى في الطوابير البسيطة:
التباطؤ يمنع الانقطاعات المصنوعة ذاتيًا. حتى جدول بسيط مثل 1 دقيقة، 5 دقائق، 30 دقيقة، 2 ساعة يجعل الفشل أكثر أمانًا. أيضًا اضبط حد محاولات حتى تتوقف المهمة المعطلة وتصبح مرئية.
إذا بنيت على منصة مثل Koder.ai، من الأفضل شحن هذه الأساسيات مع الميزة نفسها، لا بعد أسابيع كمشروع تنظيف.
قبل إضافة أدوات أكثر، تأكد من أن الأساسيات متينة. طابور مدعوم بقاعدة بيانات يعمل جيدًا عندما تكون كل مهمة سهلة الادعاء، سهلة إعادة المحاولة، وسهلة الفحص.
قائمة تحقق موثوقية سريعة:
بعد ذلك، حدد أول ثلاثة أنواع مهمة واكتب قواعدها. مثلاً: بريد إعادة تعيين كلمة المرور (محاولات سريعة، حد قصير)، تقرير ليلي (محاولات قليلة، مهلات أطول)، تسليم ويبهوك (محاولات أكثر، تباطؤ أطول، إيقاف على 4xx الدائمة).
إذا لم تكن متأكدًا متى يكفي طابور قاعدة البيانات، راقب إشارات مثل احتكاك على مستوى الصفوف من العديد من العاملين، احتياج لترتيب صارم عبر أنواع مهام كثيرة، انتشار كبير (حدث واحد يولّد آلاف المهام)، أو استهلاك عبر خدمات حيث فرق مختلفة تملك عوامل مختلفة.
إذا أردت نموذجًا سريعًا، يمكنك تخطيط التدفق في Koder.ai (koder.ai) باستخدام وضع التخطيط، توليد جدول المهام وحلقة العامل، والتكرار مع لقطات واسترجاع قبل النشر.
إذا كانت مهمة قد تستغرق أكثر من ثانية أو ثانيتين، أو تعتمد على مكالمة شبكة (مزود بريد، نقطة نهاية ويب هوك، استعلام بطيء)، فحمّلها كوظيفة خلفية.
اجعل طلب المستخدم يركز على التحقق من المدخلات، كتابة التغيير الرئيسي في البيانات، إدخال مهمة في الطابور، وإرجاع استجابة سريعة.
ابدأ بطابور مبني على قاعدة بيانات عندما:
أضف وسيط رسائل أو منصة تدفق لاحقًا عندما تحتاج إلى معدل مرور عالٍ جدًا، مستهلكين مستقلين كثيرين، أو إمكانية إعادة تشغيل أحداث عبر خدمات متعددة.
تتبع الأساسيات التي تجيب: ماذا تفعل، متى تجرب مرة أخرى، وما الذي حدث في المحاولة الأخيرة.
حد أدنى عملي:
خزن المدخلات، لا المخارج الكبيرة.
أمثلة جيدة في الـ payload:
user_id, template, report_id)تجنب:
الخطوة الأساسية هي "المطالبة" الذرية حتى لا يأخذ عاملان نفس المهمة.
نهج شائع في Postgres:
FOR UPDATE SKIP LOCKED)running واضبط locked_at/locked_byبهذه الطريقة يمكن للعاملين التوسع دون معالجة مكررة لنفس السطر.
افترض أن المهام قد تعمل مرتين أحيانًا (انهيارات، نفاد المهلة، إعادة المحاولة). اجعل التأثير الجانبي آمنًا.
أنماط بسيطة:
idempotency_key مثل welcome_email:user:123هذا مهم خاصة للبريد والويب هوكس لتجنب الازدواجية.
استخدم سياسة افتراضية واضحة وبسيطة:
افشل بسرعة للأخطاء الدائمة (مثل عنوان بريد مفقود، حمولة غير صالحة، أو أغلب 4xx من مستلم webhook).
الـ dead-letter معناها "توقف عن إعادة المحاولة واجعلها مرئية". استخدمها عندما:
max_attemptsخزّن سياقًا كافيًا للعمل:
تعامل مع المهام العالقة في حالة running بقاعدتين:
running الأقدم من حد معين إلى قائمة الانتظار أو تعيّنها كفاشلةهذا يسمح للنظام بالتعافي من انهيار العاملين بدون تنظيف يدوي كبير.
افصل العمل البطيء عن العاجل:
إذا كان الترتيب مهمًا، عادة ما يكون ذلك "لكل مفتاح" (لكل مستخدم، لكل فاتورة). أضف group_key وتأكد من تشغيل مهمة واحدة فقط لكل مفتاح للحفاظ على الترتيب المحلي دون إجبار الترتيب العالمي.
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at، بالإضافة إلى created_atlocked_at, locked_bylast_erroridempotency_key (أو آلية تفادي التكرار الأخرى)إذا كانت الوظيفة تحتاج بيانات كبيرة، خزّن مرجعًا (مثل report_run_id أو مفتاح ملف) واستردّ المحتوى عند تشغيل العامل.
last_error ورمز الحالة الأخير (لـ webhooks)عند إعادة التشغيل، من الأفضل إنشاء مهمة جديدة وترك الميتة ثابتة.