07 أغسطس 2025·8 دقيقة
نوام شازير ومعماريّة الترانسفورمر وراء نماذج اللغة الكبيرة
اكتشف كيف ساهم نوام شازير في تشكيل بنية الترانسفورمر: الانتباه الذاتي، الانتباه متعدد الرؤوس، ولماذا أصبح هذا التصميم العمود الفقري لنماذج اللغة الكبيرة الحديثة.
اكتشف كيف ساهم نوام شازير في تشكيل بنية الترانسفورمر: الانتباه الذاتي، الانتباه متعدد الرؤوس، ولماذا أصبح هذا التصميم العمود الفقري لنماذج اللغة الكبيرة الحديثة.
الترانسفورمر هو وسيلة لمساعدة الحواسيب على فهم التسلسلات — أشياء يكون فيها الترتيب والسياق مهمين، مثل الجمل، الكود، أو سلسلة استعلامات بحث. بدلاً من قراءة توكن واحد في كل مرة وحمل ذاكرة هشة للأمام، ينظر الترانسفورمر عبر كامل التسلسل ويقرر ما يجب الانتباه إليه عند تفسير كل جزء.
هذا التحوّل البسيط اتضح أنه ذو تأثير كبير. إنه سبب رئيسي في أن نماذج اللغة الكبيرة الحديثة يمكنها الحفاظ على السياق، اتباع التعليمات، كتابة فقرات متماسكة، وتوليد كود يشير إلى دوال ومتغيرات سابقة.
إذا استخدمت شات بوت، ميزة "لخّص هذا"، بحث دلالي، أو مساعد برمجي، فقد تفاعلت مع أنظمة مبنية على الترانسفورمر. نفس المخطط الأساسي يدعم:
سنفكك الأجزاء الرئيسية — الانتباه الذاتي، الانتباه متعدد الرؤوس، الترميزات الموضعية، والكتلة الأساسية للترانسفورمر — ونوضّح لماذا ينجح هذا التصميم في التوسع مع تكبير النماذج.
سنلمس أيضاً المتغيّرات الحديثة التي تحافظ على الفكرة الأساسية لكنها تُعدّل لأجل السرعة، التكلفة، أو نوافذ سياق أطول.
هذه جولة عالية المستوى بتفسيرات بلغة بسيطة وقليل من الرياضيات. الهدف بنية الفهم: ما الذي تفعله القطع، لماذا تعمل معاً، وكيف يترجم ذلك إلى قدرات منتج حقيقية.
نوام شازير هو باحث ومهندس في الذكاء الاصطناعي معروف كأحد المؤلفين المشاركين لورقة 2017 Attention Is All You Need. قدمت تلك الورقة بنية الترانسفورمر، التي أصبحت لاحقًا أساساً للعديد من نماذج اللغة الكبيرة الحديثة. عمل شازير جزء من جهد جماعي: الترانسفورمر صممه فريق من الباحثين في جوجل، ومن المهم نسب الفضل بهذه الطريقة.
قبل الترانسفورمر، اعتمدت العديد من أنظمة معالجة اللغة على نماذج متسلسلة كانت تعالج النص خطوة بخطوة. أظهر اقتراح الترانسفورمر أنه يمكنك نمذجة التسلسلات بفعالية دون تكرار عن طريق استخدام الانتباه كآلية رئيسية للجمع بين المعلومات عبر الجملة.
أهميّة هذا التحوّل أنه سهّل توازي التدريب (يمكن معالجة العديد من التوكنات دفعة واحدة)، وفتح الباب لتكبير النماذج والبيانات بطريقة أصبحت عملية بسرعة للمنتجات الحقيقية.
مساهمة شازير — إلى جانب المؤلفين الآخرين — لم تبقَ محصورة في المقاييس الأكاديمية. أصبح الترانسفورمر وحدة قابلة لإعادة الاستخدام يمكن للفرق تكييفها: تبديل المكوّنات، تغيير الحجمال، ضبطها لمهام معينة، ومن ثم تدريبه على نطاق واسع.
هكذا تنتقل العديد من الاختراعات: ورقة تقدم وصفة عامة ونظيفة؛ المهندسون يحسّنونها؛ الشركات تطبّقها؛ وفي النهاية تصبح خياراً افتراضياً لبناء ميزات لغوية.
من الدقيق القول إن شازير كان مساهماً رئيسياً وأحد مؤلفي الورقة. ومن غير الدقيق أن تُقدَمه كمخترع وحيد. الأثر ناتج عن التصميم الجماعي — وعن التحسينات الكثيرة التي أضافها المجتمع بعد المخطط الأصلي.
قبل الترانسفورمر، كانت معظم مشاكل التسلسل (الترجمة، الكلام، توليد النص) تهيمن عليها الشبكات العصبية المتكررة (RNNs) ولاحقاً LSTMs. الفكرة الأساسية بسيطة: قراءة النص توكن واحد في كل مرة، الاحتفاظ بـ "ذاكرة" جارية (حالة مخفية)، واستخدام تلك الحالة للتنبؤ بما سيأتي بعد.
تعالج الـ RNN الجملة كسلسلة. كل خطوة تحدّث الحالة المخفية بناءً على الكلمة الحالية والحالة السابقة. حسّن الـ LSTM ذلك بإضافة بوابات تقرر ما يُحتفظ به، وما يُنسى، وما يُصدر — مما يجعل الاحتفاظ بالإشارات المفيدة أطول أمداً أسهل.
في الممارسة، الذاكرة المتسلسلة لها عنق زجاجة: الكثير من المعلومات يجب ضغطها عبر حالة واحدة مع ازدياد طول الجملة. حتى مع LSTMs، يمكن أن تتلاشى الإشارات من كلمات سابقة أو تُستبدل.
هذا جعل بعض العلاقات صعبة التعلم بشكل موثوق — مثل ربط ضمير بالاسم الصحيح بعد كلمات عديدة، أو تتبّع موضوع عبر فواصل متعددة.
الـ RNNs والـ LSTMs بطيئة أيضاً في التدريب لأنها لا تستطيع التوازي الكامل عبر الزمن. يمكنك تجميع أمثلة مختلفة في دفعة، لكن داخل جملة واحدة، الخطوة 50 تعتمد على 49، التي تعتمد على 48، وهكذا.
هذا الحساب خطوة بخطوة يصبح قيداً جاداً عندما تريد نماذج أكبر، بيانات أكثر، وتجارب أسرع.
كان الباحثون بحاجة إلى تصميم يمكنه ربط الكلمات ببعضها دون السير بدقة من اليسار إلى اليمين أثناء التدريب — طريقة لنمذجة العلاقات بعيدة المدى مباشرةً والاستفادة أفضل من العتاد الحديث. هذا الضغط مهّد الطريق لنهج الانتباه الذي قدّمته ورقة Attention Is All You Need.
الانتباه هو طريقة النموذج للسؤال: "أي الكلمات الأخرى يجب أن أنظر إليها الآن لأفهم هذه الكلمة؟" بدلاً من قراءة الجملة بصرامة من اليسار إلى اليمين والاعتماد على ذاكرة قصيرة الأمد، يسمح الانتباه للنموذج بالتطلع إلى أهم أجزاء الجملة عند الحاجة.
نموذج ذهني مفيد هو محرك بحث صغير يعمل داخل الجملة.
فيشكل النموذج استعلامًا للموقع الحالي، يُقارن بالمفاتيح لكل المواقع، ثم يسترجع مزيجًا من القيم.
تنتج تلك المقارنات درجات صلة: إشارات تقريبية "ما مدى ارتباط هذا؟". يحولها النموذج بعد ذلك إلى أوزان انتباه، وهي نسب تجمع إلى 1.
إذا كانت كلمة واحدة ذات صلة كبيرة، تحصل على جزء أكبر من تركيز النموذج. إذا كانت عدة كلمات مهمة، ينتشر الانتباه بينها.
خذ: "ماريا أخبرت جينا أنها ستتصل لاحقاً."
لفهم "هي"، يجب على النموذج النظر إلى مرشحين مثل "ماريا" و"جينا". يمنح الانتباه وزناً أعلى للاسم الذي يناسب السياق.
أو فكّر: "المفاتيح في الخزانة مفقودة." يساعد الانتباه على ربط "هي/هو" أو التصريف الصحيح بالفعل مع "المفاتيح" (الفاعل الحقيقي)، وليس "الخزانة"، حتى لو كانت أقرب. هذه هي الفائدة الأساسية: الانتباه يربط المعنى عبر المسافة، عند الطلب.
الانتباه الذاتي هو فكرة أن كل توكن في التسلسل يمكنه النظر إلى توكنات أخرى في نفس التسلسل ليقرر ما الذي يهم الآن. بدلاً من معالجة الكلمات من اليسار إلى اليمين كما كانت تفعل النماذج المتكررة القديمة، يتيح الترانسفورمر لكل توكن جمع دلائل من أي مكان في المدخل.
تخيّل الجملة: "صببت الماء في الكوب لأن هو/هي كان فارغاً." يجب أن يتصل توكن "هو/هي" بـ "الكوب"، لا بـ "الماء". مع الانتباه الذاتي، يمنح توكن "هو/هي" أهمية أكبر للتوكنات التي تحل معه معناه ("الكوب"، "فارغ") وأهمية أقل لغير ذات الصلة.
بعد الانتباه الذاتي، لم يعد كل توكن مجرد نفسه. يصبح نسخة واعية للسياق — مزيج موزون من معلومات التوكنات الأخرى. يمكنك التفكير فيه كأن كل توكن يصنع ملخّصًا مُخصّصًا للجملة، مضبوطًا لما يحتاجه ذلك التوكن.
عملياً، يعني ذلك أن تمثيل "الكوب" قد يحمل إشارات من "صببت"، "الماء"، و"فارغ"، بينما يستخرج "فارغ" ما يصفه.
لأن كل توكن يمكنه حساب انتباهه على كامل التسلسل في نفس الوقت، لا يحتاج التدريب للانتظار لمعالجة التوكنات السابقة خطوة بخطوة. هذا التوازي في المعالجة سبب رئيسي في كفاءة تدريب الترانسفورمرز على مجموعات بيانات كبيرة وقدرتها على التوسع إلى نماذج هائلة.
يجعل الانتباه الذاتي من السهل الربط بين أجزاء بعيدة من النص. يمكن لتوكن أن يركز مباشرة على كلمة ذات صلة بعيدة — دون تمرير المعلومات عبر سلسلة طويلة من الخطوات الوسيطة.
ذلك يساعد في مهام مثل التعريف المرجعي ("هي"، "ذلك"، "هم"), تتبّع المواضيع عبر فقرات، ومعالجة تعليمات تعتمد على تفاصيل سابقة.
آلية انتباه واحدة قوية، لكنها قد تشبه فهم محادثة عبر زاوية كاميرا واحدة فقط. فالجملة قد تحتوي على عدة علاقات في آن واحد: من فعل ماذا، ما الذي تشير إليه الضمائر، أي الكلمات تضبط النبرة، وما هو الموضوع العام.
عند قراءة "الجائزة لم تدخل في الحقيبة لأنها كانت صغيرة جداً"، قد تحتاج لتتبّع عدة دلائل: نحوياً، دلالياً، وسياق العالم الواقعي. قد يركز رأس واحد على الاسم الأقرب؛ ورأس آخر على العبارة الفعلية ليقرر ما تشير إليه "كانت".
الانتباه متعدد الرؤوس يجري عدة حسابات انتباه بالتوازي. يُشجَّع كل "رأس" على النظر إلى الجملة من عدسة مختلفة — توصف غالبًا كفراغات فرعية.
عملياً، يمكن أن تتخصص الرؤوس في أنماط مثل:
بعد أن ينتج كل رأس ملاحظاته، لا يختار النموذج واحداً فقط. بل يضمّ مخرجات الرؤوس (يرصّها جانباً بجانب) ثم يسقطها مرة أخرى إلى "مساحة العمل" الرئيسية للنموذج عبر طبقة خطية متعلّمة.
فكر في الأمر كمزج عدة ملاحظات جزئية في ملخّص واحد واضح يمكن للطبقة التالية استخدامه. النتيجة تمثيل قادر على التقاط العديد من العلاقات مرة واحدة — أحد أسباب نجاح الترانسفورمرز عند التوسع.
الانتباه الذاتي رائع في رصد العلاقات — لكنه لوحده لا يعرف من جاء أولاً. إذا قلبت كلمات الجملة، يمكن لطبقة انتباه بسيطة أن تعامل النسخة المبدلة كمكافئة لأنها تقارن التوكنات دون أي إحساس مدمج بالمكان.
الترميز الموضعية تحلّ هذا بإدخال معلومات "أين أنا في التسلسل؟" إلى تمثيلات التوكن. بعد إلحاق الموضع، يمكن للانتباه أن يتعلّم أنماطاً مثل "الكلمة التالية مباشرة بعد نفي مهمة جداً" أو "الفاعل يظهر عادة قبل الفعل" بدون أن يستنتج الترتيب من النِفَاض.
الفكرة الأساسية بسيطة: يتم دمج تضمين كل توكن مع إشارة موقعية قبل دخوله كتلة الترانسفورمر. يمكن التفكير بإشارة الموقع كميزات إضافية تضع وسم "هذا هو التوكن رقم 1"، "رقم 2"، وهكذا.
هناك بعض الأساليب الشائعة:
خيارات الترميز الموضعي يمكن أن تؤثر ملحوظاً على نمذجة السياق الطويل — مثل تلخيص تقرير طويل، تتبّع الكيانات عبر فقرات كثيرة، أو استرجاع تفاصيل ذُكرت قبل آلاف التوكنات.
مع المدخلات الطويلة، لا يتعلم النموذج اللغة فقط؛ يتعلم أين ينظر. أساليب النسبية والدوّارية تميل إلى تسهيل مقارنة التوكنات البعيدة والحفاظ على الأنماط مع زيادة السياق، بينما بعض الأساليب المطلقة قد تتدهور أسرع عند تجاوز نافذة التدريب.
عملياً، الترميز الموضعي قرار تصميم هادئ لكنه قد يحدّد ما إذا كان LLM يبدو دقيقاً ومتسقاً عند 2000 توكن — وما إذا كان يظل متماسكاً عند 100000 توكن.
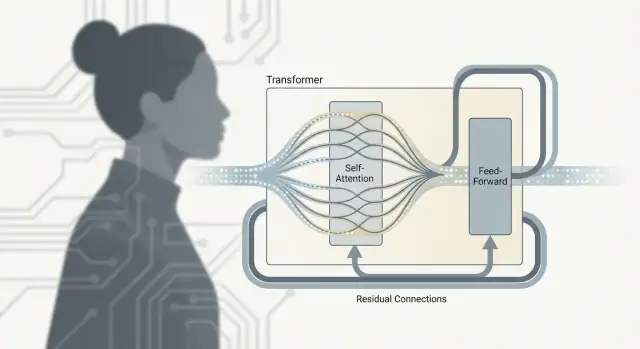
الترانسفورمر ليس مجرد "انتباه". العمل الحقيقي يحدث داخل وحدة متكررة — غالباً ما تُسمى كتلة الترانسفورمر — التي تخلط المعلومات بين التوكنات ثم تُنقّحها. رصّ العديد من هذه الكتل يعطي العمق الذي يجعل نماذج اللغة الكبيرة قادرة للغاية.
الانتباه هو خطوة التواصل: كل توكن يجمع سياقاً من توكنات أخرى.
شبكة التغذية الأمامية (FFN)، وتُسمى أيضاً MLP، هي خطوة التفكير: تأخذ تمثيل كل توكن بعد التحديث وتُطبّق نفس الشبكة الصغيرة عليه بشكل مستقل.
بعبارة بسيطة، تُحوّل FFN وتُعيد تشكيل ما يعرفه كل توكن الآن، وتساعد النموذج على بناء ميزات أغنى (مثل أنماط النحو، الحقائق، أو دلائل الأسلوب) بعد أن جمع السياق ذي الصلة.
التناوب مهم لأن الجزأين يقومان بمهام مختلفة:
تكرار هذا النمط يسمح للنموذج ببناء معنى أعلى تدريجياً: تواصل، حساب، تواصل مرة أخرى، حساب مرة أخرى.
كل طبقة فرعية (انتباه أو FFN) تُحاط بوصلة باقي: يُضاف الإدخال إلى الإخراج. هذا يساعد النماذج العميقة على التدريب لأن التدرجات يمكنها المرور عبر "ممر التخطي" حتى لو كانت طبقة معينة لا تزال تتعلم. كما يسمح للطبقة بإجراء تعديلات صغيرة بدلاً من إعادة تعلم كل شيء من الصفر.
تطبيع الطبقات هو مُثبِّت يحافظ على تفعيلات الشبكة من أن تنجرف كبيرة جداً أو صغيرة جداً أثناء مرورها عبر طبقات عديدة. فكّر فيه كمحافظة على مستوى الصوت حتى لا تُغرق أو تُجفف الطبقات اللاحقة الإشارة — ما يجعل التدريب أكثر سلاسة وموثوقية، خاصة عند مقياس نماذج اللغة الكبيرة.
الترانسفورمر الأصلي في ورقة Attention Is All You Need بُني للترجمة الآلية، حيث تحول تسلسل (مثل الفرنسية) إلى تسلسل آخر (مثل الإنجليزية). هذه المهمة تنقسم طبيعياً إلى دورين: قراءة المدخل جيداً، وكتابة المخرَج بسلاسة.
في ترانسفورمر مشفّر–مفكّك، يعالج المشفّر كامل جملة المدخل دفعة واحدة وينتج مجموعة غنية من التمثيلات. ثم يقوم المفكّك بتوليد المخرَج توكينًا تلو الآخر.
الأهم أن المفكّك لا يعتمد فقط على التوكنات الماضية الخاصة به؛ بل يستخدم أيضاً انتباهًا عرضياً للعودة إلى إخراج المشفّر، مما يساعده على البقاء متجذِّراً في النص المصدر.
هذا الإعداد لا يزال ممتازاً عندما تحتاج إلى تكيُّف محكم مع مدخل — الترجمة، التلخيص، أو الإجابة على سؤال بنص معين.
معظم نماذج اللغة الكبيرة الحديثة هي مفكّك فقط. تُدرَّب على مهمة بسيطة وفعّالة: توقع التوكن التالي.
لتعمل هذه الفكرة، تستخدم الانتباه الذاتي المُقنّع (المسمى غالبًا الانتباه السببي). كل موضع يمكنه الانتباه فقط إلى التوكنات الأسبق، لا المستقبلية، لذا يبقى التوليد متسقاً: يكتب النموذج من اليسار إلى اليمين، ويطيل التسلسل باستمرار.
هذا منتشر لأنه بسيط للتدريب على مجموعات نصية ضخمة، ويتماشى مباشرة مع حالة استخدام التوليد، ويقاس بكفاءة مع البيانات والحساب.
النماذج المشفّرة فقط (على غرار BERT) لا تولِّد نصاً؛ بل تقرأ المدخل كاملاً ثنائياً. هي رائعة للتصنيف، البحث، والتضمينات — أي مهمة حيث فهم قطعة نص أهم من إنتاج استمرار طويل.
اتضح أن الترانسفورمرز مناسبة للغاية للتوسع: إذا منحتها نصاً أكثر، حساباً أكثر، ونماذج أكبر، فهي تستمر في التحسن بطريقة متوقعة.
سبب كبير هو البساطة الهيكلية. الترانسفورمر مبني من كتل متكررة (انتباه ذاتي + شبكة تغذوية أمامية صغيرة + تطبيع)، وتتصرف تلك الكتل بشكل مماثل سواءً كنت تدرب على مليون كلمة أو تريليون.
نماذج التسلسل السابقة (مثل RNNs) كانت تضطر لمعالجة التوكنات واحداً تلو الآخر، ما يحد من العمل الممكن في آن واحد. الترانسفورمرز، بالمقابل، تستطيع معالجة كل التوكنات في التسلسل بالتوازي أثناء التدريب.
هذا يجعلها مناسبة جداً لوحدات معالجة الرسوميات/TPUs والإعدادات الموزعة الكبيرة — بالضبط ما تحتاجه عند تدريب LLMs الحديثة.
نافذة السياق هي جزء النص الذي يمكن للنموذج "رؤيته" في وقت واحد — المطالبة الخاصة بك زائد أي تاريخ محادثة أو نص وثيقة حديث. نافذة أكبر تسمح للنموذج بربط أفكار عبر جمل أو صفحات أكثر، تتبع القيود، والإجابة على أسئلة تعتمد على تفاصيل سابقة.
لكن السياق ليس مجاناً.
الانتباه الذاتي يقارن التوكنات مع بعضها. كلما طالت السلسلة، نما عدد المقارنات بسرعة (تقريباً مع مربع طول التسلسل).
لهذا السبب قد تكون النوافذ السياقية الطويلة مكلفة من حيث الذاكرة والحساب، ولماذا تركز الجهود الحديثة على جعل الانتباه أكثر كفاءة.
عندما تُدرَّب الترانسفورمرز على نطاق واسع، فهي لا تتحسن لمهمة ضيقة واحدة فقط. غالباً ما تبدأ بإظهار قدرات عامة ومرنة — التلخيص، الترجمة، الكتابة، الكودينغ، والتفكير — لأن نفس آلية التعلم العامة تُطبّق عبر بيانات ضخمة ومتنوعه.
تصميم الترانسفورمر الأصلي ما زال نقطة الإشارة، لكن معظم نماذج الإنتاج هي "ترانسفورمر زائد": تعديلات عملية صغيرة تحافظ على الكتلة الأساسية (الانتباه + MLP) بينما تحسّن السرعة، الاستقرار، أو طول السياق.
العديد من الترقيات هي أقل عن تغيير ماهية النموذج وأكثر عن جعله يُتمرّن ويعمل بشكل أفضل:
هذه التغييرات عادة لا تغير "طبيعة" الترانسفورمر — بل تصقله.
تمديد السياق من بضعة آلاف توكن إلى عشرات أو مئات الآلاف يعتمد غالباً على الانتباه المتفرق (الانتباه فقط إلى توكنات مختارة) أو متغيرات انتباه فعّالة (تقريب أو إعادة هيكلة الانتباه لتقليل الحساب).
المقايضة عادة بين الدقة، الذاكرة، وتعقيد الهندسة.
نماذج MoE تضيف عدة شبكات فرعية "خبيرة" وتوجّه كل توكن عبر جزء منها فقط. مفهوماً: تحصل على عقل أكبر، لكنك لا تُفعّل كلّه في كل مرة.
هذا يمكن أن يخفض الحساب لكل توكن بالنسبة لعدد معلمات معين، لكنه يزيد تعقيد النظام (التوجيه، موازنة الخبراء، التقديم).
عندما يروّج نموذج لنسخة ترانسفورمر جديدة، اسأل عن:
معظم التحسينات حقيقية — لكنها نادراً ما تكون مجانية.
أفكار الترانسفورمر مثل الانتباه الذاتي والتوسع مثيرة — لكن فرق المنتج تشعر بها أساساً كصِفَق: كم من النص يمكنك إرساله، كم بسرعة تحصل على إجابة، وكم يكلفك كل طلب.
طول السياق: سياق أطول يسمح بإدراج مستندات، تاريخ دردشة، وتعليمات أكثر. لكنه يزيد إنفاق التوكنات ويمكن أن يبطئ الاستجابات. إذا كانت ميزتك تعتمد على "اقرأ هذه 30 صفحة وأجب"، فاعطِ أولوية لطول السياق.
الكمون: تجارب الدردشة المواجهة للمستخدم وأدوات المساعد الحي تعتمد على زمن الاستجابة. الإخراج المتدفق يساعد، لكن اختيار النموذج، المنطقة، وتجميع الطلبات أيضاً مهمة.
التكلفة: التسعير غالباً بالتوكن (المدخل + المخرج). نموذج أفضل بنسبة 10% قد يكلف 2–5× أكثر. استخدم مقارنات على أساس التسعير لتقرر أي مستوى جودة يستحق الدفع.
الجودة: عرّفها بالنسبة لحالتك: الدقة الموضوعية، اتّباع التعليمات، النبرة، استخدام الأدوات، أو الكود. قيّم باستخدام أمثلة حقيقية من مجالك، لا مقاييس عامة فقط.
إذا كنت تحتاج أساساً إلى بحث، إزالة تكرار، تجميع، توصيات، أو "إيجاد المشابه"، فعادة ما تكون التضمينات (نماذج من نوع المشفّر) أرخص، أسرع، وأكثر استقراراً من استدعاء نموذج دردشة للتوليد. استخدم التوليد فقط في الخطوة النهائية (تلخيصات، شروحات، مسودات) بعد الاسترجاع.
لشرح أعمق، وفّر لفريقك رابطاً لشرح تقني مثل /blog/embeddings-vs-generation.
عند تحويل قدرات الترانسفورمر إلى منتج، الجزء الصعب عادةً أقل ارتباطاً بالهندسة المعمارية وأكثر ارتباطاً بسير العمل حولها: تجريب المطالبات، التأريض، التقييم، والنشر الآمن.
مسار عملي هو استخدام منصة تطوير سريعة لتجريب ونشر ميزات معززة بـ LLMs: يمكنك وصف تطبيق الويب، نقاط النهاية الخلفية، ونموذج البيانات في المحادثة، التجريب في وضع التخطيط، ثم تصدير كود المصدر أو النشر مع استضافة ومجالات مخصّصة وعودة عبر لقطات. هذا مفيد خصوصاً عند تجربة الاسترجاع، التضمينات، أو حلقات استدعاء الأدوات وتحتاج دورات تكرار ضيقة دون إعادة بناء بنية أساسية من الصفر.
الترانسفورمر هو بنية شبكات عصبية لمعطيات التسلسل تستخدم الانتباه الذاتي لربط كل توكن بكل توكن آخر في نفس المدخل.
بدلاً من تمرير المعلومات خطوة بخطوة (كما في RNNs/LSTMs)، يبني السياق عن طريق تحديد ما الذي يجب الانتباه إليه عبر كامل التسلسل، مما يحسن الفهم بعيد المدى ويجعل التدريب أكثر قابلية للتوازي.
تتعامل RNNs وLSTMs مع النص توكين بعد توكين، ما يجعل التدريب أصعب على التوازي ويخلق عنق زجاجة في الاعتماد طويل المدى.
الترانسفورمرز تستخدم الانتباه لربط التوكنات البعيدة مباشرة، ويمكنها حساب تداخلات كثيرة بين التوكنات بالتوازي أثناء التدريب—مما يجعلها أسرع في التدرج عند توفر بيانات وحساب أكبر.
الانتباه هو آلية للإجابة على: "ما التوكنات الأخرى ذات الأهمية لفهم هذا التوكن الآن؟"
يمكنك تشبيهه بمحرك بحث مصغر داخل الجملة:
الناتج هو مزيج موزون من التوكنات ذات الصلة، فيعطي لكل موضع تمثيلاً واعياً للسياق.
الانتباه الذاتي يعني أن توكنات التسلسل تُنبه إلى توكنات أخرى في نفس التسلسل.
هو الأداة الأساسية التي تسمح للنموذج بحل مرجعيات مثل من تشير إليه الضمائر (مثل "هو/هي/ذلك")، وعلاقات الفاعل–الفعل عبر فواصل، واعتماديات تظهر بعيداً في النص—دون تمرير كل شيء عبر ذاكرة متسلسلة واحدة.
الانتباه متعدد الرؤوس يُجري عدة عمليات انتباه متوازية، ويمكن لكل رأس أن يتخصص في أنماط مختلفة.
عملياً، غالباً ما يركز كل رأس على علاقات مختلفة (البنية النحوية المحلية، الروابط بعيدة المدى، حل مرجع الضمائر، إشارات الموضوع)، ثم يجمع النموذج هذه النظرات المتعددة في تمثيل موحد يسمح بالتقاط عدة هياكل في آن واحد.
الانتباه الذاتي وحده لا يعرف ترتيب الكلمات—بدون إشارة موضعية، قد تبدو الجملة المبدلة بنفس المعنى.
الترميزات الموضعية تضيف إشارة "أين أنا في التسلسل؟" إلى تمثيلات التوكنات حتى يتعلم النموذج أنماطاً مرتبطة بالترتيب، مثل "ما يأتي بعد كلمة النفي مهم" أو أن الفاعل غالباً يسبق الفعل.
خيارات شائعة تشمل السيروساينودية الثابتة، مواقع مطلوبة قابلة للتعلّم، أو أساليب نسبية/روتاريَّة.
كتلة الترانسفورمر تَجمع عادة بين:
الترانسفورمر الأصلي في ورقة Attention Is All You Need كان بنية مشفّر–مفكّك (encoder–decoder):
اليوم معظم نماذج اللغة الكبيرة هي تُدرَّب على توقع التوكن التالي باستخدام ، ما يتوافق مع التوليد من اليسار إلى اليمين ويُسهّل التوسع على مجموعات نصية ضخمة.
نوام شازير كان أحد مؤلفي ورقة 2017 "Attention Is All You Need" التي قدمت الترانسفورمر.
من الصحيح اعتباره مساهماً رئيسياً، لكن من غير الدقيق عرضه كمخترع وحيد—الترانسفورمر صُمِّم بواسطة فريق في جوجل، وتأثيره نابع أيضاً من التحسينات اللاحقة التي أضافتها المجتمع والصناعة.
مع النوافذ السياقية الطويلة، يصبح الانتباه الاعتيادي مكلفاً لأن عدد المقارنات يزداد تقريباً بمربع طول التسلسل، ما يؤثر على الذاكرة والقدرة الحاسوبية.
طرق عملية للتعامل مع ذلك:
تكديس العديد من هذه الكتل ينتج عمقاً يمكّن النموذج من تعلم ميزات أغنى وسلوك أقوى عند الحجم الكبير.