04 مايو 2025·8 دقيقة
نظرية قواعد البيانات لجيفري أولمان وراء الاستعلامات السريعة والقابلة للتوسع
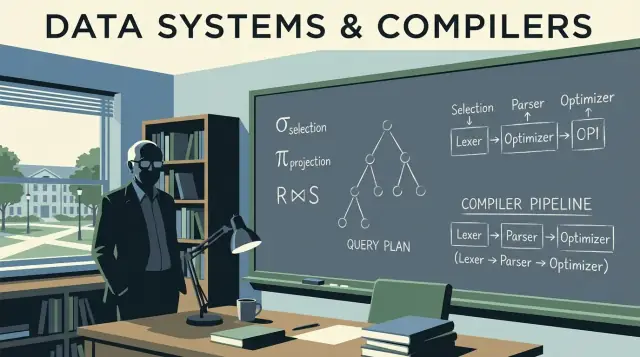
كيف تُشغّل أفكار جيفري أولمان الأساسية قواعد البيانات الحديثة: الجبر العلائقي، قواعد التحسين، الانضمامات، وتخطيط شبيه بالمترجم الذي يساعد الأنظمة على التوسع.