02 سبتمبر 2025·2 دقيقة
Protobuf مقابل JSON للواجهات: السرعة، الحجم، والتوافق
قارن Protobuf و JSON لواجهات API: حجم الحمولة، السرعة، سهولة التصحيح، الأدوات، تطور المخطط، ومتى يصلح كل تنسيق للمنتجات الحقيقية.
قارن Protobuf و JSON لواجهات API: حجم الحمولة، السرعة، سهولة التصحيح، الأدوات، تطور المخطط، ومتى يصلح كل تنسيق للمنتجات الحقيقية.
عندما ترسل أو تستقبل واجهة برمجة تطبيقات بيانات، تحتاج إلى تنسيق بيانات—طريقة موحدة لتمثيل المعلومات في أجسام الطلب والاستجابة. ثم تُصبح هذه البيانات متسلسلة (تُحوَّل إلى بايتات) للنقل عبر الشبكة، وتُفكَّك بعد ذلك إلى كائنات قابلة للاستخدام على العميل والخادم.
اثنان من الخيارات الشائعة هما JSON و Protocol Buffers (Protobuf). يمكنهما تمثيل نفس بيانات العمل (مستخدمون، طلبات، طوابع زمنية، قوائم عناصر)، لكن كلًّا منهما يقدّم توازنات مختلفة بين الأداء، حجم الحمولة، وسير عمل المطور.
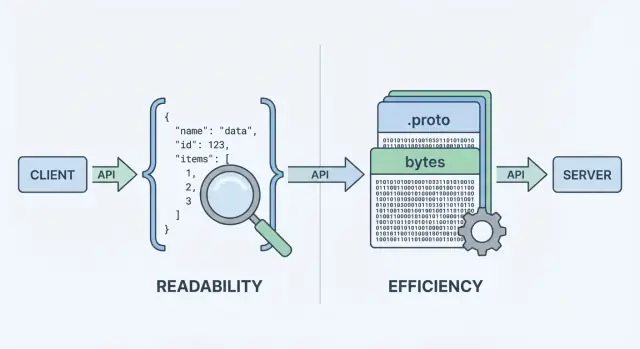
JSON (JavaScript Object Notation) هو تنسيق نصي مبني من هياكل بسيطة كالكائنات والمصفوفات. شائع في واجهات REST لأنه سهل القراءة، سهل التسجيل، وسهل الفحص بأدوات مثل curl وDevTools في المتصفح.
سبب كبير لانتشار JSON: معظم اللغات توفر دعمًا ممتازًا، ويمكنك فحص الاستجابة بصريًا وفهمها فورًا.
Protobuf هو تنسيق تسلسل ثنائي أنشأته Google. بدلًا من إرسال نص، يرسل تمثيلًا ثنائيًا مضغوطًا يُعرَّف عبر مخطط (ملف .proto). يصف المخطط الحقول وأنواعها والأرقام الوسمية لكل حقل.
نظرًا لكونه ثنائيًا ومعتمدًا على مخطط، ينتج Protobuf عادةً حمولة أصغر ويمكن أن يكون أسرع في التحليل—وهذا مهم عند وجود حجم عالي من الطلبات، شبكات محمولة، أو خدمات حساسة للكمون (شائع في إعدادات gRPC، لكنه ليس مقتصرًا على gRPC).
من المهم فصل ما ترسله عن كيفية ترميزه. يمكن نمذجة "مستخدم" بمعرف واسم وبريد إلكتروني في كل من JSON وProtobuf. الفرق هو التكلفة التي تدفعها في:
لا توجد إجابة واحدة تناسب الجميع. للعديد من واجهات Public API، يظل JSON الافتراضي لأنه في متناول الجميع ومرن. لبيئات الاتصال بين الخدمات الداخلية الحساسة للأداء أو العقود الصارمة، قد يكون Protobuf خيارًا أفضل. هدف هذا الدليل مساعدتك على الاختيار بناءً على القيود—لا على الأيديولوجيا.
عندما تُعيد واجهة بيانات، لا يمكنها إرسال "كائنات" مباشرة عبر الشبكة؛ يجب تحويلها إلى تدفق بايتات أولًا. هذا التحويل هو التسلسل—فكِّر فيه كـتغليف البيانات للشحن. في الطرف الآخر، يقوم العميل بالعكس (فك التسلسل)، يفك البايتات إلى هياكل بيانات قابلة للاستخدام.
تدفق الطلب/الاستجابة النموذجي يبدو هكذا:
خطوة "الترميز" هي المكان الذي يهم فيه اختيار التنسيق. ترميز JSON ينتج نصًا قابلًا للقراءة مثل {\"id\":123,\"name\":\"Ava\"}. ترميز Protobuf ينتج بايتات ثنائية مدمجة لا معنى لها للبشر بدون أدوات.
لأن كل استجابة يجب أن تُغَلف وتُفك، يؤثر التنسيق على:
نمط API لديك غالبًا ما يوجّه القرار:
curl، وبسيط للتسجيل والفحص.يمكنك استخدام JSON مع gRPC (عبر transcoding) أو استخدام Protobuf فوق HTTP عادي، لكن راحة استخدام المكدس لديك—الأطر، البوابات، مكتبات العميل، وعادات التصحيح—ستقرر غالبًا ما هو الأسهل إدارة يومية.
عندما يقارن الناس protobuf vs json، عادة ما يبدأون بمقياسين: مدى اتساع الحمولة ومدة الترميز/فك الترميز. العنوان بسيط: JSON نصي ويميل لأن يكون مُجلِّياً؛ Protobuf ثنائي ويميل لأن يكون مضغوط.
JSON يكرر أسماء الحقول ويستخدم تمثيلات نصية للأرقام والبوول والهيكل، لذا غالبًا ما يرسل بايتات أكثر عبر السلك. Protobuf يستبدل أسماء الحقول بوسوم رقمية ويضغط القيم بكفاءة، ما يؤدي عادةً إلى حمولات أصغر—خاصة للكائنات الكبيرة، الحقول المكررة، والبيانات المتداخلة.
مع ذلك، الضغط قد يقلل الفارق. مع gzip أو brotli، مفاتيح JSON المتكررة تضغط جيدًا، لذلك قد يتقلص الفارق بين JSON وProtobuf في بيئات حقيقية. Protobuf يمكن ضغطه أيضًا، لكن المكسب النسبي غالبًا ما يكون أصغر.
JSON هو تنسيق نصي يسهل قراءته وتسجيله واختباره بالأدوات الشائعة. Protobuf هو تنسيق ثنائي مضغوط يُعرَّف عبر ملف .proto، وغالبًا ما يعطي أحجام حمولة أصغر وفك تشفير أسرع.
اختر بناءً على القيود: الوصول وسهولة التصحيح (JSON) مقابل الكفاءة والعقود الصارمة (Protobuf).
الواجهات تبادل بايتات، وليست كائنات في الذاكرة. التسلسل (Serialization) يقوم بترميز كائنات الخادم إلى حمولة (نص JSON أو ثنائي Protobuf) للنقل؛ فك التسلسل (Deserialization) يعيد تلك البايتات إلى كائنات قابلة للاستخدام على الطرف الآخر.
اختيارك للتنسيق يؤثر على عرض الحزمة (bandwidth)، الكمون، ووقت CPU المستهلك في (فك)التسلسل.
غالبًا نعم، خصوصًا مع كائنات كبيرة أو متداخلة وحقول مكررة؛ لأن Protobuf يستعمل وسوم رقمية وترميزات ثنائية فعالة.
ومع ذلك، عند تفعيل gzip أو brotli، فإن مفاتيح JSON المتكررة تضغط جيدًا، وبالتالي قد يقل الفارق في الحجم في بيئات الإنتاج. قِس الحجم الخام والمضغوط على حد سواء.
قد يكون كذلك. يحتاج محلل JSON إلى تجزئة النص، التعامل مع الهروب/اليونيكود، وتحويل السلاسل إلى أرقام. فك Protobuf يكون أكثر مباشرة (قراءة الوسم → القيمة ذات النوع)، ما يقلل غالبًا وقت CPU وتوليد القمامة (allocations).
لكن إذا كانت الحمولات صغيرة، فقد تكون العوامل الأخرى (TLS، RTT، عمل التطبيق) هي المسيطرة على الكمون.
لأن Protobuf ثنائي، فإنه أقل قابلية للقراءة افتراضيًا. JSON قابل للقراءة بسهولة ويمكن تفحصه في DevTools، السجلات، curl وPostman. حزم Protobuf تظهر كسلاسل base64 أو ثنائية عند تسجيلها.
تحسين عملي شائع: سجِّل "عرض تصحيح مُفكك ومُحجَّب" (مثلا تمثيل JSON) بجانب الحمولة الثنائية عندما يكون ذلك آمنًا.
JSON مرن وغالبًا «بلا مخطط» ما لم تطبّق JSON Schema/OpenAPI. هذه المرونة قد تؤدي إلى حقول غير متسقة، قيم متنكرة كسلاسل («stringly-typed») ودلالات null غامضة.
Protobuf يفرض أنواعًا عبر عقدة .proto، يُولِّد كودًا مُطبَّقًا بنوع صارم، ويسهّل تطور العقود بين فرق ولغات متعددة.
في Protobuf، الهوية الحقيقية على السلك هي أرقام الحقول (الوسوم). تغييرات آمنة عادة:
reserved).تغييرات محفوفة بالمخاطر:
نعم. استخدم تفاوض المحتوى (content negotiation):
Accept: application/json أو Accept: application/x-protobufContent-Type المطابقVary: Accept حتى لا تخلط الكاشات بين الصيغإذا كانت الأدوات تعرقل ذلك، فواجهة منفصلة (مثل ) يمكن أن تكون حلًا مؤقتًا.
يعتمد على بيئتك:
ضع في الاعتبار تكلفة صيانة توليد الكود وإصدار المخططات المشتركة عند اختيار Protobuf.
لا تجعل الاختيار بديلاً عن تدابير الأمان والموثوقية. تنسيق البيانات ليس طبقة أمان.
إرشادات عملية للاثنين:
أبقِ المكتبات والمحللات مُحدَّثة لتقليل المخاطر الأمنية الناتجة عن ثغرات المكتبات.
في JSON، تعتمد التوافقية على الاتفاقيات: اجعل التغييرات إضافية قدر الإمكان، وتجنّب تغيير الأنواع، وعامِل الحقول المجهولة على أنها قابلة للتجاهل.
/v2/...