08 أكتوبر 2025·8 دقيقة
قواعد بيانات SQL الموزعة: متى تستخدم Spanner و CockroachDB و YugabyteDB
تعلم ما هي قواعد بيانات SQL الموزعة، كيف تختلف Spanner وCockroachDB وYugabyteDB، وما هي حالات الاستخدام الحقيقية التي تبرر SQL قوي الاتساق ومتعدد المناطق.
تعلم ما هي قواعد بيانات SQL الموزعة، كيف تختلف Spanner وCockroachDB وYugabyteDB، وما هي حالات الاستخدام الحقيقية التي تبرر SQL قوي الاتساق ومتعدد المناطق.
"Distributed SQL" هي قاعدة بيانات تبدو وتتعامل مثل قاعدة بيانات علائقية تقليدية — جداول، صفوف، روابط، معاملات وSQL — لكنها مصممة لتعمل كعنقود عبر عدة آلات (وغالبًا عبر مناطق) بينما تظل تتصرف كـ قاعدة بيانات منطقية واحدة.
هذا المزيج مهم لأنه يحاول تقديم ثلاثة أشياء في آن واحد:
قاعدة بيانات علائقية كلاسيكية (مثل PostgreSQL أو MySQL) تكون عادةً الأسهل تشغيلًا عندما تعيش كل الأشياء على عقدة رئيسية واحدة. يمكنك توسيع القراءات بنسخ متماثلة، لكن توسيع الكُتّاب والبقاء خلال انقطاعات إقليمية يتطلب عادةً بنية إضافية (تجزئة، فشل يدوي، ومنطق تطبيقي دقيق).
اتخذت العديد من أنظمة NoSQL النهج المعاكس: التوسع والتوفر أولًا، وفي بعض الأحيان عن طريق تبسيط الضمانات الاتساقية أو تقديم نماذج استعلام أبسط.
تهدف Distributed SQL إلى طريق وسط: الحفاظ على النموذج العلائقي والمعاملات ACID، لكن توزيع البيانات تلقائيًا للتعامل مع النمو والنكسات.
بُنيت قواعد بيانات Distributed SQL للمشكلات مثل:
لهذا السبب تُقيَّم منتجات مثل Google Spanner وCockroachDB وYugabyteDB غالبًا للنشر متعدد المناطق والخدمات المتاحة دائمًا.
Distributed SQL ليس "أفضل" تلقائيًا. أنت تقبل وجود أجزاء متحركة أكثر وحقائق أداء مختلفة (رحلات الشبكة، الإجماع، كمون عابر للمناطق) مقابل المرونة والتوسع.
إذا كان عبئك يناسب قاعدة بيانات مُدارة بشكل جيد في منطقة واحدة مع إعداد نسخ بسيط، فإن RDBMS التقليدية أبسط وأرخص. تستحق Distributed SQL ثمنها عندما يكون البديل شِيارًا مخصصًا، فشلًا معقَّدًا، أو متطلبات عمل تتطلب اتساقًا وتوافرًا متعدد المناطق.
تهدف Distributed SQL لأن تبدو كقاعدة بيانات SQL مألوفة بينما تخزن البيانات عبر آلات متعددة (وغالبًا عبر مناطق). الجزء الصعب هو تنسيق عدة حواسيب لتتصرف كنظام واحد موثوق.
يُنسَخ كل جزء من البيانات عادةً إلى عدة عقد (النسخ). إذا فشلت عقدة، يمكن لنسخة أخرى أن تخدم القراءات وتقبل الكتابات.
لمنع انحراف النسخ، تستخدم أنظمة Distributed SQL بروتوكولات إجماع — في أغلب الأحيان Raft (CockroachDB، YugabyteDB) أو Paxos (Spanner). على مستوى عالٍ، يعني الإجماع:
تلك "المصادقة بالأغلبية" هي ما يمنحك الاتساق القوي: بمجرد التزام المعاملة، لن يرى العملاء الآخرون نسخة أقدم من البيانات.
لا يمكن لآلة واحدة أن تخزن كل شيء، لذا تُقسَّم الجداول إلى قطع أصغر تُسمى shards/partitions (يسميها Spanner splits؛ CockroachDB يسميها ranges؛ YugabyteDB يسميها tablets).
كل تجزئة تُنسَخ (باستخدام الإجماع) وتوضع على عقد محددة. لا يكون الوضع عشوائيًا: يمكنك التأثير فيه بسياسات (على سبيل المثال، إبقاء سجلات عملاء الاتحاد الأوروبي في مناطق الاتحاد الأوروبي، أو إبقاء التجزئات الساخنة على عقد أسرع). يقلل الوضع الجيد من الرحلات الشبكية ويجعل الأداء أكثر قابلية للتنبؤ.
مع قاعدة بيانات أحادية العقد، يمكن أن تُلتزم المعاملة غالبًا بعمل محلي على القرص. في Distributed SQL، قد تمسّ المعاملة عدة تجزئات — وربما على عقد مختلفة.
عادةً ما يتطلب الالتزام الآمن تنسيقًا إضافيًا:
تدخل هذه الخطوات جولات شبكة إضافية، ولهذا تضيف المعاملات الموزعة عادةً كمونًا—خصوصًا عندما تمتد البيانات عبر مناطق.
عند الانتشار عبر مناطق، تحاول الأنظمة إبقاء العمليات "قريبة" من المستخدمين:
هذا هو جوهر موازنة متعدد المناطق: يمكنك تحسين الاستجابة المحلية، لكن الاتساق القوي عبر مسافات طويلة سيظل يدفع تكلفة شبكة.
قبل أن تتجه نحو Distributed SQL، تحقق من احتياجاتك الأساسية. إذا كان لديك منطقة رئيسية واحدة، حمل متوقع، وبصمة تشغيل صغيرة، فإن قاعدة بيانات علائقية تقليدية (أو Postgres/MySQL مُدارة) عادةً أبسط طريقة لإصدار الميزات بسرعة. يمكنك غالبًا تمديد إعداد منطقة واحدة بعيدًا بقرائن قراءة، التخزين المؤقت، والعمل على المخططات/الفهارس.
يستحق Distributed SQL النظر الجدي عندما يصبح واحد (أو أكثر) مما يلي صحيحًا:
الأنظمة الموزعة تضيف تعقيدًا وتكلفة. كن حذرًا إذا:
إذا كنت تجيب "نعم" على اثنين أو أكثر، فمحتمل أن تستحق Distributed SQL التقييم:
يبدو Distributed SQL كأنه "تحصل على كل شيء"، لكن الأنظمة الحقيقية تُجبرك على اختيارات—خاصة عندما لا تستطيع المناطق أن تتواصل بثبات.
فكر في انقسام الشبكة كـ "الرابط بين المناطق متقلب أو معطَّل". في تلك اللحظة، يمكن لقاعدة البيانات أن تُعطي الأولوية لواحد من التالي:
عادةً تُبنى أنظمة Distributed SQL لتفضيل الاتساق للمعاملات. هذا ما تريده الفرق غالبًا—إلى أن يعني الانقسام أن بعض العمليات يجب أن تنتظر أو تفشل.
الاتساق القوي يعني أنه بمجرد التزام معاملة، أي قراءة لاحقة تُعيد تلك القيمة المُلتزمَة—لا "عملت في منطقة ولم تعمل في أخرى". هذا حاسم لـ:
إذا كان وعد منتجك "عندما نؤكّد، فهو حقيقي"، فالاتساق القوي ميزة وليست رفاهية.
سلوكان عمليان مهمان:
الاتساق القوي عبر المناطق عادةً يتطلب إجماع (توافق عدة نسخ قبل الالتزام). إذا امتدت النسخ عبر قارات، يصبح حدّ السرعة هو سرعة الضوء: كل كتابة عابرة للمناطق يمكن أن تضيف عشرات إلى مئات المللي ثانية.
المقايضة بسيطة: أمان جغرافي وصحّة أكبر غالبًا يعني زمن كتابة أعلى ما لم تخطط بعناية لمكان وجود البيانات وحيث تُسمح بالالتزامات.
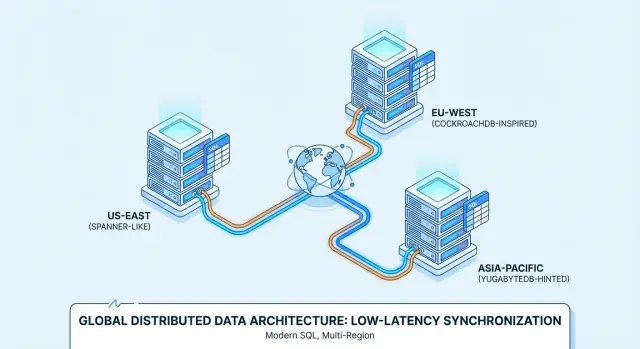
Google Spanner هي قاعدة بيانات Distributed SQL تُقدَّم غالبًا كخدمة مُدارة على Google Cloud. صُممت للنشر متعدد المناطق حيث تريد قاعدة بيانات منطقية واحدة مع بيانات مكرَّرة عبر عقد ومناطق. يدعم Spanner خيارين من لهجات SQL—GoogleSQL (لهجته الأصلية) ولهجة متوافقة مع PostgreSQL—لذلك تختلف قابلية النقل اعتمادًا على اختيارك والميزات التي يعتمد عليها تطبيقك.
CockroachDB هي قاعدة بيانات Distributed SQL تسعى لأن تشعر الفرق بأنها مألوفة لمستخدمي PostgreSQL. تستخدم بروتوكول شبكة متوافق مع PostgreSQL وتدعم جزءًا كبيرًا من SQL بأسلوب PostgreSQL، لكنها ليست بديلًا مطابقًا بايتًا لبايت لـ Postgres (بعض الامتدادات وسلوكيات الحواف تختلف). يمكنك تشغيلها كخدمة مُدارة (CockroachDB Cloud) أو استضافتها بنفسك.
YugabyteDB هي قاعدة بيانات موزعة بواجهة SQL متوافقة مع PostgreSQL (YSQL) وإضافة واجهة متوافقة مع Cassandra (YCQL). مثل CockroachDB، يتم تقييمها غالبًا من الفرق التي تريد تجربة تطوير شبيهة بـ Postgres أثناء التوسع عبر العقد والمناطق. تتوفر كخدمة مُدارة (YugabyteDB Managed) أو ذاتية الاستضافة.
الخدمات المُدارة تقلل عادةً العمل التشغيلي (ترقيات، نسخ احتياطية، تكامل المراقبة)، بينما تمنحك الاستضافة الذاتية سيطرة أكبر على الشبكات، أنواع الحالات، ومواقع تشغيل البيانات الفيزيائية. Spanner غالبًا ما يُستخدم مُدارًا على GCP؛ CockroachDB وYugabyteDB يُشاهدان في نماذج مُدارة وذاتية الاستضافة، بما في ذلك تعدد السحابات وعلى البنية المحلية.
كلهم "يتحدثون" SQL، لكن التوافق اليومي يعتمد على اختيار اللهجة (Spanner)، تغطية ميزات Postgres (CockroachDB/YugabyteDB)، وما إذا كان تطبيقك يعتمد امتدادات Postgres محددة أو وظائف أو سلوكيات معاملات. التخطيط المبكر يدفع ثماره: اختبر استعلاماتك، هجراتك، وسلوك ORM بدلاً من افتراض التوافق الفوري.
مطابقة كلاسيكية لـ Distributed SQL هي منتج SaaS B2B مع عملاء عبر أمريكا الشمالية، أوروبا، وAPAC—فكر في أدوات دعم، منصات موارد بشرية، لوحات تحليلات، أو أسواق.
المتطلب التجاري واضح: يريد المستخدمون استجابة "تطبيق محلي"، بينما تريد الشركة قاعدة بيانات منطقية واحدة متاحة دائمًا.
تنتهي العديد من فرق SaaS بمزيج من المتطلبات:
يمكن لـ Distributed SQL نمذجة هذا بوضوح مع المحلية لكل عميل: ضع بيانات كل عميل الأساسية في منطقة محددة (أو مجموعة مناطق) مع الحفاظ على المخطط ونموذج الاستعلام عبر النظام بأكمله. هذا يجنب انتشار "قاعدة بيانات لكل منطقة" مع تكدس البنية.
للحفاظ على سرعة التطبيق، تهدف عادةً إلى:
هذا مهم لأن الرحلات العبر-المنطقية تهيمن على زمن استجابة المستخدم. حتى مع الاتساق القوي، يضمن تصميم المحلية الجيد أن معظم الطلبات لا تدفع تكلفة الشبكة العابرة للقارات.
تفيد المكاسب التقنية فقط إذا ظل التشغيل قابلاً للإدارة. بالنسبة لـ SaaS عالمي، خطط لـ:
عند التنفيذ الجيد، يمنحك Distributed SQL تجربة منتج واحدة تشعر محلية—دون تقسيم فريق الهندسة إلى "الستاك الأوروبي" و"الستاك APAC".
تكون الأنظمة المالية حيث يمكن أن يتحول "الاتساق في نهاية المطاف" إلى خسارة فعلية للأموال. إذا وضع عميل طلبًا، تم تفويض دفعة، وتحديث رصيد، فهذه الخطوات يجب أن تتفق على حقيقة واحدة—الآن.
الاتساق القوي مهم لأنه يمنع منطقتين (أو خدمتين مختلفتين) من اتخاذ كل منهما قرارًا "معقولًا" يؤدي إلى دفتر غير صحيح.
في سير عمل نموذجي — إنشاء طلب → حجز أموال → التقاط دفعة → تحديث الرصيد/الدفتر — تريد ضمانات مثل:
تتناسب Distributed SQL هنا لأنها تمنحك معاملات ACID وقيودًا عبر العقد (وغالبًا عبر المناطق)، لذا تبقى ثوابت دفتر الحسابات حتى أثناء حالات الفشل.
معظم تكاملات الدفع قابلة لإعادة المحاولة بكثرة: انتهاء المهلات، إعادة إرسال الويب هوك، وإعادة معالجة الوظائف الخلفية أمور طبيعية. يجب أن تساعد قاعدة البيانات في جعل المحاولات آمنة.
نهج عملي هو دمج مفاتيح عدم التكرار على مستوى التطبيق مع فريدة مفروضة من قاعدة البيانات:
idempotency_key لكل عميل/محاولة دفع.(account_id, idempotency_key).بهذه الطريقة، تصبح المحاولة الثانية عملية لا تضر بدلًا من خصم مزدوج.
يمكن أن تولد أحداث بيع أو جولات دفع طفرات كتابة مفاجئة. مع Distributed SQL، يمكنك التوسع بإضافة عقد لزيادة قدرة الكتابة مع الحفاظ على نفس نموذج الاتساق.
المفتاح هو التخطيط للمفاتيح الساخنة (مثل حساب تاجر واحد يستقبل كل الحركة) واستخدام أنماط مخطط تُوزّع الحمولة.
عادة تتطلب التدفقات المالية سجلات تدقيق غير قابلة للتغيير، قابلية التتبع (من/ماذا/متى)، وسياسات احتفاظ متوقعة. افترض أنك ستحتاج إلى: إدخالات دفترية قابلة للإلحاق فقط، سجلات مؤقتة بالتوقيت، وصول محكوم، وسياسات أرشفة/احتفاظ لا تضر قابلية التدقيق.
المخزون والحجوزات يبدو بسيطًا حتى تخدم مناطق متعددة نفس المورد النادر: آخر مقعد لحفلة، منتج "إصدار محدود"، أو غرفة فندق في ليلة معينة.
الجزء الصعب ليس قراءة التوافر—بل منع شخصين من المطالبة بنفس العنصر تقريبًا في آنٍ واحد.
في إعداد متعدد المناطق بدون اتساق قوي، قد تعتقد كل منطقة لفترة وجيزة أن لديها مخزونًا بناءً على بيانات قديمة قليلاً. إذا انتهى الأمر بمستخدمين في مناطق مختلفة يقومان بالدفع خلال تلك النافذة، قد تُقبل كلتا المعاملتين محليًا وتتصادم لاحقًا أثناء المصالحة.
هذا هو سبب الإفراط في البيع عبر المناطق: ليس لأن النظام "خاطئ"، بل لأنه سمح لحقائق متباينة مؤقتة.
غالبًا ما تُختار قواعد بيانات Distributed SQL هنا لأنها تستطيع فرض نتيجة موحدة للمكتوب—فـ "آخر مقعد" يُخصَّص مرة واحدة فعلًا، حتى لو جاءت الطلبات من قارات مختلفة.
حجز + تأكيد: ضع حجزًا مؤقتًا (سجل حجز) داخل معاملة، ثم أكد الدفع في خطوة ثانية.
انتهاء الصلاحية: يجب أن تنتهي الحجوزات تلقائيًا (مثلاً بعد 10 دقائق) لمنع احتجاز المخزون إذا تخلى المستخدم عن العملية.
صندوق المعاملات (Transactional outbox): عند تأكيد حجز، اكتب صفًا "حدث للإرسال" في نفس المعاملة، ثم أرسله بشكل غير متزامن للبريد الإلكتروني أو التو صيل أو نظام الرسائل—بدون خطر فجوة "تم الحجز لكن لم يُرسَل التأكيد".
الخلاصة: إذا كان عملك لا يتحمل التخصيص المزدوج عبر المناطق، فالمتطلّبات المعاملية القوية تصبح ميزة منتج، لا ميزة تقنية ترفيهية.
التوافر العالي مناسب جيدًا لـ Distributed SQL عندما يكون التوقف مكلفًا، لا تُقبل الانقطاعات غير المتوقعة، وتريد أن تكون الصيانة مملة.
الهدف ليس "أبدًا تفشل"—بل تلبية SLOs واضحة (مثلاً 99.9% أو 99.99%) حتى عند موت عقد، انطفاء مناطق، أو عند تطبيق ترقيات.
ابدأ بترجمة "متاح دائمًا" إلى توقعات قابلة للقياس: أقصى وقت توقف شهري، هدف زمن الاسترداد (RTO)، وهدف نقطة الاسترداد (RPO).
يمكن لأنظمة Distributed SQL الاستمرار في تقديم قراءات/كتابات أثناء العديد من الفشلات الشائعة، لكن ذلك فقط إذا كانت طوبولوجيا النشر تتوافق مع SLO الخاص بك وتطبيقك يتعامل مع الأخطاء العابرة (محاولات، idempotency) بشكل نظيف.
الصيانة المخططة مهمة أيضًا. التحديثات الدورانية واستبدال الحالات أسهل عندما تستطيع قاعدة البيانات نقل القيادة/النسخ بعيدًا عن العقد المتأثرة دون إيقاف العنقود كله.
النشر عبر مناطق توافر (multi-zone) يحميك من انقطاع AZ/منطقة توافر واحدة والعديد من الأعطال المادية، عادة بكمون وتكلفة أقل. تكون كافية غالبًا إذا كان امتثالك وقاعدة المستخدمين معظمها داخل منطقة واحدة.
النشر متعدد المناطق (multi-region) يحميك من انقطاع منطقة كاملة ويدعم فشل إقليمي. المقابل هو كمون كتابة أعلى للمعاملات المتسقة بقوة التي تمتد عبر المناطق، بالإضافة إلى تخطيط سعة أكثر تعقيدًا.
لا تفترض أن الفشل غير مرئي أو فوري. حدِّد ماذا يعني "فشل" لخدمتك: ارتفاعات أخطاء قصيرة؟ فترات قراءة-فقط؟ بضع ثوانٍ من الكمون المرتفع؟
قم بـ "أيام لعبة" لإثبات ذلك:
حتى مع النسخ المتزامن، احتفظ بنسخ احتياطية وتدرّب على الاستعادة. النسخ الاحتياطي يحمي من أخطاء المشغّل (هجرات خاطئة، حذف عرضي)، أخطاء التطبيق، أو تلف يمكن أن ينسخ.
تحقق من استعادة النقطة الزمنية (إن وجدت)، سرعة الاستعادة، والقدرة على الاسترداد إلى بيئة نظيفة دون لمس الإنتاج.
تظهر متطلبات إقامة البيانات عندما تقول اللوائح أو العقود أو السياسات الداخلية إن سجلات معينة يجب أن تُخزن (وأحيانًا تُعالَج) داخل دولة أو منطقة محددة.
قد ينطبق هذا على البيانات الشخصية، معلومات الرعاية الصحية، بيانات الدفع، أحمال حكومية، أو مجموعات بيانات يملكها العميل حيث يحدد العقد مكان بياناتهم.
غالبًا ما يُؤخذ Distributed SQL في الاعتبار هنا لأنه يمكن أن يحافظ على قاعدة بيانات منطقية واحدة مع وضع البيانات في مناطق مختلفة فعليًا—بدون إجبارك على تشغيل بنية تطبيق منفصلة لكل جغرافيا.
إذا تطلب المنظم أو العميل أن "تبقى البيانات في المنطقة"، فليس كافيًا أن يكون لديك نسخ منخفضة الكمون بالقربية. قد تحتاج إلى ضمان:
هذا يدفع الفرق نحو تصاميم حيث يكون الموقع محوريًا، لا فكرة لاحقة.
نمط شائع في SaaS هو وضع بيانات كل مستأجر في منطقة محددة. على سبيل المثال: سجلات عملاء الاتحاد الأوروبي مثبّتة في مناطق الاتحاد الأوروبي، سجلات US في US.
عمومًا تجمع بين:
الهدف هو جعل انتهاك الإقامة عرضيًا صعبًا عبر الوصول التشغيلي، استعادة النسخ الاحتياطية، أو إعادة تكرار عبر المناطق.
التزامات الإقامة والامتثال تختلف حسب البلد، الصناعة، والعقد. وتتغير أيضًا مع الوقت.
عامل طوبولوجيا قاعدة البيانات كجزء من برنامج الامتثال، وخضع افتراضاتك لمراجعة مستشار قانوني مؤهل (وحيث يلزم، مراجعي الحسابات).
يمكن أن تعقّد الطوبولوجيا الصديقة للإقامة "المنظور العالمي" للأعمال. إذا بُقيت بيانات العملاء عمدًا في مناطق منفصلة، فقد تحتاج التحليلات والتقارير إلى:
في الممارسة، تفصل العديد من الفرق بين أحمال التشغيل (قوية الاتساق، واعية بالإقامة) عن التحليلات (مخازن بيانات إقليمية أو مجموعات مُحكومة)، للحفاظ على الامتثال دون إبطاء تقارير المنتج اليومي.
يمكن أن تنقذك Distributed SQL من أعطال مؤلمة وقيود إقليمية، لكنها نادرًا ما توفر المال تلقائيًا. يساعد التخطيط المسبق على تجنب دفع ثمن "تأمين" لا تحتاجه فعلاً.
تتقسم الميزانية غالبًا إلى أربعة بنود:
تضيف أنظمة Distributed SQL تنسيقًا—خصوصًا للكتابات المتسقة بقوة التي يجب أن يؤكدها نصاب. طريقة عملية لتقدير التأثير:
هذا لا يعني "لا تفعل ذلك"، لكن يعني أن تصمم الرحلات لتقليل الكتابات المتسلسلة (تجميع، محاولات idempotent، معاملات أقل تشابكًا).
إذا كان مستخدموك في منطقة واحدة غالبًا، فإن Postgres في منطقة واحدة مع نسخ قراءة جيدة، نسخ احتياطية قوية، وخطة فشل مجرّبة يمكن أن يكون أرخص وأبسط—وسريعًا.
تستحق Distributed SQL التكلفة عندما تحتاج حقًا إلى كتابات متعددة المناطق، RPO/RTO صارمة، أو وضع بيانات ملتزم.
عامل الإنفاق كتجارة:
إذا كان الخسارة المتجنبة (تعطل + هجرة العملاء + مخاطر الامتثال) أكبر من القسط المستمر، فتصميم متعدد المناطق مبرر. إن لم يكن، ابدأ ببساطة—وضع مسار للتطور لاحقًا.
اعتماد Distributed SQL أقل عن "نقل ورفع" لقاعدة بيانات وأكثر عن إثبات أن عبء عملك يتصرف جيدًا عندما تنتشر البيانات والإجماع عبر العقد (وربما المناطق). خطة خفيفة النطاق تساعدك على تجنب المفاجآت.
اختر حمل عمل واحد يمثل ألمًا حقيقيًا: مثلاً checkout/حجز، إنشاء حساب، أو تدوين دفتر.
حدد مقاييس النجاح مقدمًا:
إذا أردت تسريع مرحلة PoC، يساعد بناء سطح تطبيق "واقعي" صغير (API + واجهة) بدلًا من مقاييس تركيبية فقط. على سبيل المثال، تستخدم الفرق أحيانًا Koder.ai لتهيئة تطبيق React + Go + PostgreSQL بدائي عبر دردشة، ثم تبديل طبقة قاعدة البيانات إلى CockroachDB/YugabyteDB (أو الاتصال بـ Spanner) لاختبار أنماط المعاملات والمحاولات وسلوك الفشل من الطرف إلى الطرف. الفكرة ليست الستاك الابتدائي—بل تقصير الحلقة من "فكرة" إلى "حمل يمكن قياسه".
المراقبة وكتيبات التشغيل تهم بقدر SQL:
ابدأ برِحلة PoC، ثم خُصّص وقتًا لمراجعة الجاهزية للإنتاج وتحويل تدريجي (كتابة مزدوجة أو قراءات ظل عندما أمكن).
إذا احتجت مساعدة في تقدير التكلفة أو الطبقات، راجع /pricing. للمزيد من الأدلة العملية وأنماط الترحيل، تصفح /blog.
إذا وثقت نتائج PoC، الموازيات المعمارية، أو دروس الترحيل، فكّر في مشاركتها مع فريقك (وعامًّا إن أمكن): منصات مثل Koder.ai تقدم حتى طرقًا لكسب أرصدة مقابل إنشاء محتوى تعليمي أو إحالة بنّائين آخرين، مما يمكن أن يعوّض تكاليف التجربة أثناء التقييم.
قاعدة بيانات Distributed SQL توفر واجهة علاقية وSQL (جداول، روابط، قيود، معاملات) لكنها تعمل كعنقود عبر عدة آلات—وغالبًا عبر مناطق—مع التصرف كـ قاعدة بيانات منطقية واحدة.
عمليًا، تحاول أن تجمع بين:
نظام RDBMS أحادي-العقد أو بنموذج primary/replica أبسط وأرخص وأسرع عادةً لـ OLTP في منطقة واحدة.
تصبح Distributed SQL جذابة عندما يكون البديل:
تعتمد معظم الأنظمة على فكرتين أساسيتين:
هذا ما يمكّن الاتساق القوي حتى عند فشل عقد—لكنّه يضيف رسوم تنسيق عبر الشبكة.
يقسمون الجداول إلى قطع أصغر (تسمى غالبًا partitions/shards، أو بأسماء خاصة بالمصنّع مثل ranges/tablets/splits). كل جزء:
تؤثر عادةً على وضع النسخ بسياسات بحيث تبقى البيانات الساخنة والكتاب الرئيسيون قريبين، مما يقلل الرحلات عبر الشبكة.
المعامَلات الموزعة غالبًا ما تمسّ عدة أجزاء، وربما على عقد/مناطق مختلفة. الالتزام الآمن قد يتطلب:
تلك الرحلات الشبكية الإضافية هي السبب الرئيسي لارتفاع زمن الاستجابة للكتابة—خصوصًا عندما يشمل الإجماع مناطق متعددة.
ضع Distributed SQL في الاعتبار عندما تجيب بنعم على اثنين أو أكثر:
إذا كانت أحمالك تعمل في منطقة واحدة مع نسخ/كاش، فغالبًا ما تكون RDBMS التقليدية الافتراضية الأفضل.
الاتساق القوي يعني أنه بمجرد التزام معاملة، القراءات اللاحقة لا تُظهر بيانات أقدم.
بالمصطلحات المنتجية، يساعد على منع:
المقابل: أثناء انقطاع الشبكة، قد يحجب النظام أو يفشل بعض العمليات بدل قبول حقائق متباينة.
اعتمد على قيود قاعدة البيانات + المعاملات:
idempotency_key (أو ما شابه) لكل طلب/محاولة(account_id, idempotency_key)بهذه الطريقة، تصبح المحاولات الإضافية عديمة التأثير بدلًا من مضاعفات—وهذا حاسم للمدفوعات والتزويد وإعادة معالجة الوظائف الخلفية.
فصل عملي:
قبل الاختيار، اختبر ORM/الهجرات والامتدادات التي تعتمد عليها—لا تفترض الاستبدال الفوري.
ابدأ بـ PoC مركز حول سير عمل مهم واحد (checkout، حجز، تسجيل دفاتر).
تحقق من:
للمساعدة في تقدير التكلفة/الطبقات، راجع /pricing. للملاحظات التنفيذية، تصفح /blog.