05 أكتوبر 2025·8 دقيقة
RabbitMQ لتطبيقاتكم: أنماط، الإعداد، والتشغيل
تعلم كيفية استخدام RabbitMQ في تطبيقاتك: المفاهيم الأساسية، الأنماط الشائعة، نصائح الاعتمادية، التوسيع، الأمان، والمراقبة للإنتاج.
تعلم كيفية استخدام RabbitMQ في تطبيقاتك: المفاهيم الأساسية، الأنماط الشائعة، نصائح الاعتمادية، التوسيع، الأمان، والمراقبة للإنتاج.
RabbitMQ هو وسيط رسائل: يجلس بين أجزاء نظامك وينقل «العمل» (الرسائل) بشكل موثوق من المُنتجين إلى المستهلكين. عادةً ما تلجأ فرق التطبيقات إليه عندما تبدأ الدعوات المتزامنة المباشرة (HTTP بين الخدمات، قواعد بيانات مشتركة، مهام مجدولة) بإنشاء تبعيات هشة، أحمال غير متساوية، وسلاسل فشل يصعب تتبُّعها.
ذروة الحركة والأحمال غير المتساوية. إذا حصل تطبيقك على زيادة مفاجئة (مثلاً زيادة بعامل 10 في التسجيلات أو الطلبات)، فمعالجة كل شيء فورًا قد تُثقل الخدمات الخلفية. مع RabbitMQ، يضع المُنتِج المهام في صف بسرعة والمستهلكون يعالجونها بوتيرة مُتحكَّم بها.
الترابط الوثيق بين الخدمات. عندما يجب على الخدمة A استدعاء الخدمة B والانتظار، تنتشر الأعطال والكمون. الرسائل تفك هذا الترابط: تنشر A رسالة وتتابع؛ B تعالج عندما تكون متاحة.
تعامل أفضل مع الفشل. ليس كل فشل يجب أن يظهر كمشكلة للمستخدم. يساعدك RabbitMQ على إعادة المحاولة في الخلفية، عزل "الرسائل السامة"، وتجنُّب فقدان العمل أثناء الانقطاعات المؤقتة.
عادةً ما تحصل الفرق على أحمال أكثر سلاسة (تهدئة الذروات)، خدمات مفصولة (تبعات زمن التشغيل أقل)، وإعادة محاولات مُتحكَّمة (قليل من المعالجات اليدوية). ومهم أيضاً أن يصبح من السهل استنتاج أين تعيق الرسائل—عند المُنتِج، في الصف، أم عند المستهلك.
يركز هذا الدليل على RabbitMQ العملي لفرق التطبيقات: المفاهيم الأساسية، الأنماط الشائعة (نشر/اشتراك، صفوف العمل، إعادة المحاولة وصفوف الرسائل الفاسدة)، ومخاوف التشغيل (الأمان، التوسيع، المراقبة، واستكشاف الأخطاء).
لا يهدف إلى أن يكون شرحًا كاملًا لمواصفات AMQP أو غوصًا عميقًا في كل إضافة (plugin) لـ RabbitMQ. الهدف هو مساعدتك على تصميم تدفقات رسائل تظل قابلة للصيانة في أنظمة حقيقية.
RabbitMQ هو وسيط رسائل يوجّه الرسائل بين أجزاء نظامك، بحيث يستطيع المنتجون تسليم العمل والمستهلكون معالجته عندما يكونون جاهزين.
مع استدعاء HTTP مباشر، ترسل الخدمة A طلبًا إلى الخدمة B وتَنتظر عادةً ردًا. إذا كانت الخدمة B بطيئة أو متوقفة، تفشل الخدمة A أو تتوقّف، ويجب أن تتعامل مع المهلات (timeouts)، وإعادة المحاولة، والضغط العكسي في كل مستدعي.
مع RabbitMQ (غالبًا عبر AMQP)، تنشر الخدمة A رسالة إلى الوسيط. RabbitMQ يخزن ويوجّه الرسالة إلى الصف(وف) المناسبة، وتستهلكها الخدمة B بشكل غير متزامن. التحول الرئيسي هو أنك تتواصل عبر طبقة وسطى قابلة للتحمّل تُخزّن الذروات وتهدئ الأحمال غير المتساوية.
الرسائل مناسبة عندما:
الرسائل غير مناسبة عندما:
متزامن (HTTP):
خدمة الخروج (checkout) تستدعي خدمة الفوترة عبر HTTP: "إنشئ فاتورة." ينتظر المستخدم بينما تعمل الفوترة. إذا كانت الفوترة بطيئة، يزداد زمن الخروج؛ إذا كانت متوقفة، يفشل الخروج.
غير متزامن (RabbitMQ):
ينشر الخروج invoice.requested مع معرف الطلب. يحصل المستخدم على تأكيد فوري بأن الطلب تم استلامه. تستهلك الفوترة الرسالة، تنشئ الفاتورة، ثم تنشر invoice.created ليستخدمها البريد/الإشعارات. كل خطوة يمكن أن تعيد المحاولة بشكل مستقل، والانقطاعات المؤقتة لا تعطل المسار بأكمله تلقائيًا.
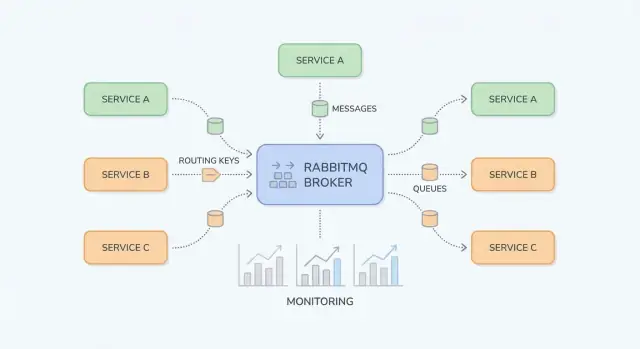
من الأسهل فهم RabbitMQ إذا فصلت "مكان نشر الرسائل" عن "مكان تخزينها". ينشر المنتجون إلى التبادلات؛ التبادلات توجّه إلى الصفوف؛ يقرأ المستهلكون من الصفوف.
التبادل لا يخزن الرسائل. يقيم القواعد ويحوّل الرسائل إلى صفوف.
billing أو email).region=eu و tier=premium)، لكن احتفظ به للحالات الخاصة لأنه أصعب في الاستدلال.الصف هو المكان الذي تجلس فيه الرسائل حتى يعالجها مستهلك. يمكن أن يكون للصف مستهلك واحد أو عدة مستهلكين (مستهلكون متنافسون)، وتُسلَّم الرسائل عادةً إلى مستهلك واحد في كل مرة.
الbinding يربط تبادلًا بصفّ ويحدد قاعدة التوجيه. فكّر فيه كـ: "عندما تهبط رسالة في التبادل X بمفتاح التوجيه Y، سلّمها إلى الصف Q." يمكنك ربط عدة صفوف بنفس التبادل (pub/sub) أو ربط صف واحد بعدة أنماط.
بالنسبة للتبادلات المباشرة، التوجيه حرفي. بالنسبة لتبادلات topic، تبدو مفاتيح التوجيه ككلمات مفصولة بنقاط، مثل:
orders.createdorders.eu.refundedيمكن أن تتضمن الربط wildcards:
* يطابق كلمة واحدة بالضبط (مثال: orders.* يطابق orders.created)# يطابق صفر أو أكثر من الكلمات (مثال: orders.# يطابق orders.created وorders.eu.refunded)هذا يعطيك طريقة نظيفة لإضافة مستهلكين جدد دون تغيير المنتج—أنشئ صفًا جديدًا واربطه بالنمط الذي تحتاجه.
بعد أن يسلم RabbitMQ رسالة، يبلغ المستهلك بما حدث:
كن حذرًا مع requeue: الرسالة التي تفشل دائمًا قد تدور إلى ما لا نهاية وتمنع الصف. كثير من الفرق تزاوج بين nacks واستراتيجية إعادة محاولات مع DLQ حتى تُعالَج الفشل بشكل متوقع.
يتألق RabbitMQ عندما تحتاج إلى نقل العمل أو الإشعارات بين أجزاء نظامك دون أن تجعل كل شيء ينتظر خطوة بطيئة واحدة. فيما يلي أنماط عملية تظهر في المنتجات اليومية.
عندما يجب على عدة مستهلكين أن يتفاعلوا مع نفس الحدث—دون أن يعرف الناشر من هم—فإن النشر/الاشتراك حل أنيق.
مثال: عندما يحدث تحديث لملف المستخدم، قد تُعلِم فهرسة البحث، التحليلات، ومزامنة CRM بالتوازي. مع fanout تبث إلى كل الصفوف المرتبطة؛ مع topic توجّه بشكل انتقائي (user.updated, user.deleted). هذا يتجنب ربط الخدمات ويتيح للفرق إضافة مشتركين لاحقًا دون تغيير المنتج.
إذا كانت مهمة ما تستغرق وقتًا، ادفعها إلى صف ودع العُمال يعالجونها بشكل غير متزامن:
هذا يحافظ على سرعة طلبات الويب ويسمح لك بموازنة عدد العمال بشكل مستقل. كما أنه طريقة طبيعية للتحكم في التزامن: يصبح الصف "قائمة مهام" وعدد العمال هو "مقبض الإنتاجية".
العديد من سير العمل يعبر حدود الخدمات: طلب → فوترة → شحن هو المثال الكلاسيكي. بدلًا من أن تستدعي خدمة واحدة التالية وتعلق، يمكن لكل خدمة أن تنشر حدثًا عند إنهاء خطوتها. تستهلك الخدمات اللاحقة الأحداث وتتابع سير العمل.
هذا يحسّن المرونة (انقطاع مؤقت في الشحن لا يكسر عملية الخروج) ويجعل الملكية أوضح: كل خدمة تتفاعل مع الأحداث التي تهمها.
RabbitMQ هو أيضًا مخزن مؤقت بين تطبيقك واعتمادات قد تكون بطيئة أو متقلبة (واجهات طرف ثالث، أنظمة قديمة، قواعد بيانات معالجة دفعية). تضع الطلبات بسرعة في الصف، ثم تعالجها مع إعادة محاولات متحكم بها. إذا كانت التبعية متوقفة، يتراكم العمل بأمان ويُصرف لاحقًا—بدلًا من إحداث مهلات عبر التطبيق كله.
إذا كنت تخطط لإدخال الصفوف تدريجيًا، فخطوة أولى جيدة تكون "صندوق بريد غير متزامن" صغير أو صف مهام خلفي واحد (انظر /blog/next-steps-rollout-plan).
يبقى إعداد RabbitMQ سهل العمل عندما تكون المسارات متوقعة، الأسماء متسقة، والحمولات تتطور دون كسر المستهلكين الأقدمين. قبل إضافة صف آخر، تأكد أن "قصة" الرسالة واضحة: من أين تنشأ، كيف تُوجَّه، وكيف يمكن لزميل تتبُّعها من البداية للنهاية.
اختيار التبادل الصحيح يقلل الربط الأحادي والمنشورات المفاجئة:
billing.invoice.created).billing.*.created, *.invoice.*). هذا الخيار الأكثر شيوعًا لتوجيه أحداث قابل للصيانة.قاعدة جيدة: إن كنت "تبتكر" منطق توجيه معقد في الكود، فربما ينتمي ذلك إلى نمط topic exchange بدلًا من ذلك.
عامل جسم الرسائل كواجهات عامة. استخدم إصدارًا واضحًا (schema_version: 2) وهدف للتوافق الرجعي:
هذا يبقي المستهلكين الأقدَم يعملون بينما يعتمد الجدد المخطط الجديد بمرور الوقت.
اجعل استكشاف الأخطاء رخيصًا بتوحيد الميتاداتا:
correlation_id: يربط الأوامر/الأحداث التي تنتمي لنفس العمل التجاري.trace_id (أو W3C traceparent): يربط الرسائل بتتبُّع موزع عبر HTTP والتدفقات غير المتزامنة.عند قيام كل ناشر بضبط هذه القيم بشكل متسق، يمكنك تتبع معاملة واحدة عبر خدمات متعددة بلا عناء.
استخدم أسماء متوقعة وقابلة للبحث. نمط شائع:
<domain>.<type> (مثل billing.events)<domain>.<entity>.<verb> (مثل billing.invoice.created)<service>.<purpose> (مثل reporting.invoice_created.worker)الثبات أفضل من الذكاء: شكرك المستقبلي (وفريق المناوبة) سيقدّر ذلك.
الرسائل الموثوقة تتعلق بالتخطيط للفشل: ينهار المستهلكون، تتعطل واجهات برمجة التطبيقات الخلفية، وبعض الأحداث تالفة ببساطة. يوفر RabbitMQ الأدوات، لكن كود التطبيق يجب أن يتعاون.
إعداد شائع هو التسليم مرة واحدة على الأقل: الرسالة قد تُسلَّم أكثر من مرة، لكنها لا يجب أن تُفقد بصمت. يحدث هذا عادةً عندما يستلم المستهلك رسالة، يبدأ العمل، ثم يفشل قبل ack—RabbitMQ سيعيد إدخال الرسالة ويعيد تسليمها.
الخلاصة العملية: التكرارات طبيعية، لذا يجب أن يكون معالجك آمنًا للتشغيل عدة مرات.
اللامتأثر بالتكرار يعني "معالجة نفس الرسالة مرتين يعطي نفس تأثير معالجة مرة واحدة." طرق مفيدة تشمل:
message_id ثابت (أو مفتاح أعمال مثل order_id + event_type + version) واحفظه في جدول/كاش للمعالجات مع TTL.PENDING) أو قيود تفرد قاعدة البيانات لمنع الإنشاء المزدوج.من الأفضل أن تُعامل إعادة المحاولات كتدفق منفصل، لا حلقة ضيقة داخل المستهلك.
النمط الشائع:
هذا يخلق تدرجًا زمنيًا دون ترك الرسائل "عالقة" كغير مؤكدة.
بعض الرسائل لن تنجح أبدًا (مخطط سيئ، بيانات مرجعية مفقودة، خطأ برمجي). اكتشفها عبر:
وجّه هذه الرسائل إلى DLQ للحجر. عامل DLQ كصندوق عملياتي: فحص الحمولة، إصلاح السبب الأساسي، ثم إعادة تشغيل يدوية لرسائل مختارة (من الأفضل عبر أداة/سكريبت مسيطر عليه) بدل إعادة كل شيء إلى الصف الرئيسي.
أداء RabbitMQ عادةً ما يحده عدد عوامل عملية: كيفية إدارة الاتصالات، مدى سرعة المستهلكين في معالجة العمل بأمان، وهل تُستخدم الصفوف كـ "مخزن". الهدف هو إنتاجية مستقرة دون تراكم متزايد.
خطأ شائع هو فتح اتصال TCP جديد لكل ناشر أو مستهلك. الاتصالات أثقل مما تظن (handshakes، heartbeats، TLS)، لذا اجعلها طويلة العمر وأعد استخدامها.
استخدم القنوات (channels) لتشغيل عدة أعمال عبر عدد أصغر من الاتصالات. كقاعدة عامة: قليل من الاتصالات، الكثير من القنوات. ومع ذلك، لا تنشئ آلاف القنوات بلا ضوابط—لكل قناة تكلفة، ومكتبة العميل قد يكون لها حدود. أفضل ممارسة: تجمع قنوات صغيرة لكل خدمة وأعد استخدام القنوات للنشر.
إذا سحب المستهلكون عددًا كبيرًا من الرسائل دفعة واحدة، سترى زيادات في الذاكرة، أوقات معالجة طويلة، وتأخر متباين. اضبط prefetch بحيث يحتفظ كل مستهلك بعدد محدود من الرسائل غير المؤكدة.
إرشادات عملية:
الرسائل الكبيرة تقلل الإنتاجية وتزيد ضغط الذاكرة (على الناشرين، الوسيط، والمستهلكين). إذا كانت حمولةك كبيرة (مستندات، صور، JSON ضخم)، ففكر بتخزينها خارجيًا (تخزين كائنات أو قاعدة بيانات) وإرسال معرف + بيانات وصفية عبر RabbitMQ.
قاعدة إرشادية جيدة: احتفظ بالرسائل في نطاق الـ KB، لا MB.
نمو الصف هو عرض، ليس استراتيجية. أضف ضغطًا عكسيًا حتى يتباطأ الناشرون عندما لا يستطيع المستهلكون المواكبة:
عند الشك، غيّر مقبض واحد في كل مرة وقِس: معدل النشر، معدل ack، طول الصف، والكمون من البداية للنهاية.
الأمان في RabbitMQ يتعلق بتقوية "الحواف": كيف يتصل العملاء، من يستطيع فعل ماذا، وكيف تحمي بيانات الاعتماد. استخدم هذه القائمة كأساس وعدّلها بحسب متطلبات الامتثال لديك.
أذونات RabbitMQ قوية عند استخدامها باستمرار:
للتحصين التشغيلي (المنافذ، الجدران النارية، والتدقيق)، احتفظ بدفتر تشغيل داخلي قصير واربطه من /docs/security حتى تتبع الفرق معيارًا واحدًا.
عندما يتعطل RabbitMQ، تظهر الأعراض أولًا في تطبيقك: نقاط نهاية بطيئة، مهلات، تحديثات مفقودة، أو مهام "لا تنتهي أبدًا". الملاحظية الجيدة تتيح لك التأكد ما إذا كان الوسيط هو السبب، تحديد الاختناق (الناشر، الوسيط، أو المستهلك)، والتحرك قبل أن يلاحظ المستخدمون.
ابدأ بمجموعة صغيرة من الإشارات التي تخبرك ما إذا كانت الرسائل تتدفق:
انبِه على الاتجاهات، لا القيم المطلقة فقط:
سجلات الوسيط تساعدك على التمييز بين "خروج RabbitMQ" و"إساءة استخدام العملاء". ابحث عن فشل المصادقة، اتصالات محجوزة (resource alarms)، وأخطاء القناة المتكررة. على جانب التطبيق، تأكد أن كل محاولة معالجة تسجل correlation ID، اسم الصف، والنتيجة (acked, rejected, retried).
إذا كنت تستخدم تتبع موزعًا، انقل رؤوس التتبع عبر خصائص الرسالة لتربط "طلب API → رسالة منشورة → عمل المستهلك".
ابنِ لوحة لكل مسار حاسم: معدل النشر، معدل ack، العمق، unacked، إعادة الطباعة، وعدد المستهلكين. أضف روابط مباشرة في اللوحة إلى دفتر التشغيل الداخلي، مثلاً /docs/monitoring، وقائمة فحص "ما الذي تفحصه أولًا" لمن يستجيبون في النوبة.
عندما "يتوقف شيء عن الحركة" في RabbitMQ، قاوم رغبة إعادة التشغيل أولًا. معظم المشكلات تظهر بوضوح عندما تراجع (1) الربط والتوجيه، (2) صحة المستهلك، و(3) إنذارات الموارد.
إذا أفاد الناشرون "نُشِر بنجاح" لكن الصفوف تبقى فارغة (أو يمتلئ صف خاطئ)، افحص التوجيه قبل الكود.
ابدأ بواجهة الإدارة (Management UI):
topic).إذا كان الصف يحتوي على رسائل لكن لا يستهلكها أحد، تأكد من:
التكرارات عادةً ما تنشأ من إعادة المحاولات (توقف المستهلك بعد المعالجة وقبل ack)، انقطاعات الشبكة، أو إعادة الإدخال اليدوية. خفف ذلك بجعل المعالجات لامتأثرة بالتكرار (مثلاً إلغاء التكرار عن طريق معرف الرسالة في قاعدة البيانات).
التسليم خارج الترتيب متوقع عندما يوجد مستهلكون متعددون أو عمليات إعادة إدخال. إن كان الترتيب مهمًا، استخدم مستهلكًا واحدًا لذلك الصف، أو قسم المفاتيح إلى صفوف متعددة.
الإنذارات تعني أن RabbitMQ يحمي نفسه.
قبل إعادة التشغيل، أصل السبب الجذري وتجنب حلقات "الرسائل السامة". أعد الإدخال بدفعات صغيرة، أضف حد إعادة محاولات، وعَلِّم الفشل ببيانات وصفية (عدد المحاولات، آخر خطأ). فكّر في إرسال الرسائل المعاد تشغيلها إلى صف مختلف أولًا حتى تتمكن من الإيقاف سريعًا لو تكرر الخطأ.
اختيار أداة الرسائل أقل عن "الأفضل" وأكثر عن مطابقة نمط حركة المرور، تحمّل الفشل، وراحة التشغيل.
يتألق RabbitMQ عندما تحتاج توصيلًا موثوقًا للرسائل وتوجيهًا مرنًا بين مكونات التطبيق. خيار قوي لسير العمل غير المتزامن الكلاسيكي—أوامر، مهام خلفية، إخطاريات، ونماذج طلب/استجابة—خاصة عندما تريد:
إذا كانت أهدافك نقل العمل أكثر من الاحتفاظ بتاريخ طويل للأحداث، فغالبًا ما يكون RabbitMQ اختيارًا مريحًا.
Kafka وغيرها مصممة لالبث عالي الإنتاجية وسجلات الأحداث طويلة الأمد. اختر نظامًا شبيهًا بـ Kafka عندما تحتاج:
المقايضة: أنظمة على غرار Kafka قد تحتاج عبء تشغيل تشغيلي أعلى وقد تدفعك لتصميم موجه للإنتاجية (تجميع، استراتيجية تجزئة). RabbitMQ يميل لأن يكون أسهل للمرور للإنتاجية المتوسطة والمنخفضة مع كمون منخفض ووزن توجيه غني.
إذا كان لديك تطبيق واحد يُنتج وظائف وحوض عمال واحد يستهلكها—وكنت راضيًا عن دلالات أبسط—قد يكفي صف مبني على Redis (أو خدمة مهام مُدارة). الفرق عادةً ما تتخطاه عندما تحتاج ضمانات أقوى للتسليم، dead-lettering، أنماط توجيه متعددة، أو فصل أوضح بين المنتجين والمستهلكين.
صمّم عقود الرسائل كما لو أنك قد تنتقل لاحقًا:
إذا احتجت لاحقًا إلى تدفقات قابلة لإعادة المعالجة، يمكنك غالبًا جسر أحداث RabbitMQ إلى نظام سجل-مستند مع الاحتفاظ بـ RabbitMQ لسير العمل التشغيلي. لخطة نشر عملية، انظر /blog/rabbitmq-rollout-plan-and-checklist.
يعمل نشر RabbitMQ بشكل أفضل عندما تتعامل معه كمنتج: ابدأ صغيرًا، عرّف ملكية، وبرهن الاعتمادية قبل التوسع.
اختر سير عمل واحد يستفيد من المعالجة غير المتزامنة (مثلاً: إرسال البريد، إنشاء التقارير، المزامنة مع API طرف ثالث).
إذا احتجت قالبًا للتسمية، طبقات إعادة المحاولة، وسياسات أساسية، خزنها مركزيًا في /docs.
أثناء تنفيذ هذه الأنماط، فكّر بتوحيد الهيكلية عبر الفرق. على سبيل المثال، فرق تستخدم Koder.ai غالبًا تولّد هيكل خدمة ناشر/مستهلك صغير من موجه دردشة (يشمل التسمية، توصيل retry/DLQ، وأغطية trace/correlation)، ثم تصدر الشفرة للمراجعة وتتكرّر في "وضع التخطيط" قبل النشر.
ينجح RabbitMQ عندما "يملك شخص ما الصف". قرر هذا قبل الإنتاج:
إذا كنت تؤسس دعمًا رسميًا أو استضافة مُدارة، مواءم التوقعات مبكرًا (انظر /pricing) وحدد طريق اتصال للحوادث/التشغيل عند /contact.
شغّل تجارب صغيرة محددة بالزمن لبناء الثقة:
بمجرد أن تستقر خدمة واحدة لعدة أسابيع، كرّر نفس الأنماط—لا تعيد اختراعها لكل فريق.
استخدم RabbitMQ عندما تريد فكّ ترابط الخدمات، امتصاص ذروة حركة المرور، أو نقل العمل البطيء خارج مسار الطلب.
أمثلة مناسبة: مهام الخلفية (إرسال رسائل بريد إلكتروني، إنشاء ملفات PDF)، إشعارات أحداث لعدة مستهلكين، وتدفقات عمل يجب أن تستمر أثناء انقطاعات مؤقتة في الخدمات الخلفية.
تجنّبه عندما تحتاج إلى إجابة فورية حقًا (عمليات القراءة البسيطة/التحقق) أو عندما لا يمكنك الالتزام بإدارة الإصدارات، وإعادة المحاولة، والمراقبة — فهذه الأمور إلزامية في الإنتاج.
انشر إلى تبادل وقم بتوجيه الرسائل إلى صفوف:
orders.* أو orders.#.معظم الفرق تختار topic exchanges افتراضيًا لتوجيه أحداث قابل للصيانة.
الصفّ يخزن الرسائل حتى يعالجها مستهلك؛ الربط (binding) هو القاعدة التي توصل التبادل بالصف.
لفحص أخطاء التوجيه:
هذه الفحوص الثلاثة تفسر معظم حالات "نُشر لكن لم يُستهلك".
استخدم صف عمل عندما تريد أن يعالج كل عامل مهمة واحدة من بين عدة عمال.
نصائح عملية:
التسليم "مرة واحدة على الأقل" يعني أن الرسالة قد تُسلم أكثر من مرة (مثلاً إذا تعطل المستهلك بعد إجراء العمل وقبل إرسال ack).
اجعل المستهلكين آمنين عبر:
message_id ثابت (أو مفتاح أعمال) وتسجيل المعالجات المنفذة مع TTL.PENDING) أو قيود تفرد قاعدة البيانات.افترض وجود تكرارات وصمّم وفقًا لذلك.
تجنّب حلقات إعادة الإدخال الضيقة. نمط شائع: "صفوف إعادة المحاولة" ثم DLQ:
أعد التشغيل من DLQ فقط بعد إصلاح السبب الجذري، وبدفعات صغيرة.
ابدأ بأسماء متوقعة وتعامل مع الرسائل كواجهات برمجة APIs:
schema_version في الحمولة.وحد الميتاداتا:
ركز على إشارات قليلة تُظهر ما إذا كان العمل يتدفق:
نَبِّه على الاتجاهات (مثل "تراكم يتزايد لمدة 10 دقائق") واستخدم سجلات تتضمن اسم الصف، correlation_id، ونتيجة المعالجة.
الحد الأدنى للأمان:
احفظ دفتر تشغيل داخلي موجز واربطه من /docs/security.
ابحث أولًا أين توقف التدفق:
إعادة التشغيل نادرًا ما تكون الخيار الأول.
correlation_id لربط الأحداث/الأوامر بعمل واحد.trace_id (أو رؤوس W3C traceparent) لربط العمل غير المتزامن بتتبُّع موزع.هذا يسهل التعلم والاستجابة للحوادث.