15 يونيو 2025·8 دقيقة
السماح للذكاء الاصطناعي بتصميم مخططات الباكند وواجهات الـAPI ونماذج البيانات
اكتشف كيف تُسرّع المخططات وواجهات الـAPI المولَّدة آليًا التسليم، أين تفشل، وسير عمل عملي لمراجعة الاختبارات والحكم على تصميم الباكند.
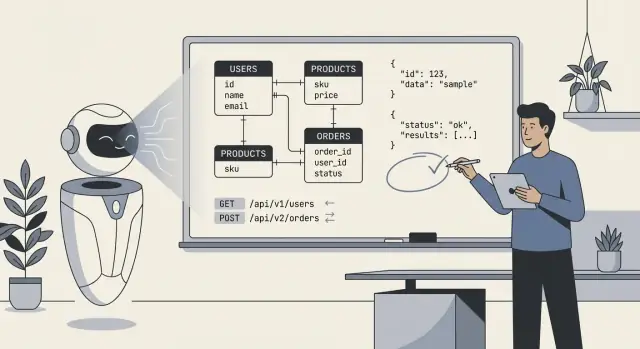
ماذا يعني فعليًا "الذكاء الاصطناعي صمم باكندك"
عندما يقول الناس "الذكاء الاصطناعي صمّم الباكند لدينا"، فإنهم عادةً يقصدون أن النموذج أنتج مسودة أولية للمخطط التقني الأساسي: جداول قاعدة البيانات (أو المجموعات)، كيف ترتبط هذه الأجزاء ببعضها، وواجهات الـ API التي تقرأ وتكتب البيانات. في الممارسة العملية، الأمر أقل "الذكاء الاصطناعي بنى كل شيء" وأكثر «الذكاء الاصطناعي اقترح بنية يمكننا تنفيذها وتحسينها».
ما الذي يتضمنه باكند مصمّم بواسطة الذكاء الاصطناعي عادةً
في الحد الأدنى، يمكن للذكاء الاصطناعي توليد:
- مخططات وكيانات: جداول/مجموعات مثل
users,orders,subscriptions، بالإضافة إلى الحقول والأنواع الأساسية. - العلاقات: روابط واحد-إلى-كثير وكثير-إلى-كثير (مثال: الطلب يحتوي على عناصر سطرية متعددة؛ المنتج ينتمي لعدة فئات).
- القيود والتحققات: الحقول المطلوبة، المفاتيح الفريدة، نطاقات بسيطة، حالات شبيهة بالقيم المحدودة، وقواعد التكامل المرجعي الأساسية.
- مساحة واجهة الـ API: نقاط نهاية CRUD، أشكال الطلب/الاستجابة، أنماط الترقيم (pagination)، صيغ الأخطاء، وأحيانًا اقتراحات للإصدار.
ما الذي لا يستطيع تحديده دون سياق عملك
يمكن للذكاء الاصطناعي استنتاج أنماط "نمطية"، لكنه لا يستطيع باعتماد كامل اختيار النموذج الصحيح عندما تكون المتطلبات غامضة أو خاصة بالمجال. لن يعرف سياساتك الحقيقية مثل:
- ماذا يعني "مستخدم" (أدوار؟ منظمات؟ حسابات ضيف؟).
- أي الحقول إلزامية قانونيًا، حساسة، أو خاضعة لقواعد الاحتفاظ.
- أي الإجراءات يجب أن تكون قابلة للتدقيق، قابلة للعكس، أو تتطلب موافقة.
- المعنى الحقيقي للحالات (مثل:
cancelledمقابلrefundedمقابلvoided).
التوقع الصحيح: مساعد، لا سلطة نهائية
عامل مخرجات الذكاء الاصطناعي كنقطة انطلاق سريعة ومنظمة—مفيدة لاستكشاف الخيارات وكشف النواقص—لكن ليست كالمواصفة التي تُرسل كما هي. دورك هو تزويد النموذج بقواعد واضحة وحالات حافة، ثم مراجعة ما أنتجه بنفس الطريقة التي تراجع بها مسودة مهندس مبتدئ: مفيدة، أحيانًا مُبشِّرة، وأحيانًا خاطئة بطرق دقيقة.
المدخلات التي تحدد جودة مخرجات الذكاء الاصطناعي
يمكن للذكاء الاصطناعي صياغة مخطط أو API بسرعة، لكنه لا يستطيع اختراع الحقائق المفقودة التي تجعل الباكند "مناسبًا" لمنتجك. أفضل النتائج تظهر عند معاملته كمصمم مبتدئ سريع: أنت تزود القيود الواضحة، وهو يقترح الخيارات.
المدخلات التي يحتاجها الذكاء الاصطناعي فعليًا
قبل أن تطلب جداول أو نقاط نهاية أو نماذج، دوّن الأساسيات:
- الكيانات الأساسية والتعريفات: ما الكائنات الموجودة (مثل User, Subscription, Order) وماذا يعني كل واحد في عملك.
- تدفقات العمل الرئيسية: الرحلات الأساسية (التسجيل، السداد، الاسترداد، الموافقات) والحالات التي تمر بها.
- الأدوار والأذونات: من يمكنه فعل ماذا (admin, staff, customer, auditor) وما الذي يجب تقييده.
- احتياجات التقارير والتحليلات: الأسئلة التي يجب أن تجيبها لاحقًا (إيراد شهري، احتفاظ cohorts، مقاييس SLA)، بما في ذلك أبعاد التجميع.
- التكاملات والمعرفات الخارجية: مزودو الدفع، CRMs، أنظمة الهوية—وما المعرفات التي يجب حفظها.
- توقعات السعة والأداء: ترتيب الحجم التقريبي (مئات مقابل ملايين سجلات) وتوقعات الكمون.
- الامتثال والاحتفاظ: GDPR/CCPA، سجلات التدقيق، قواعد حذف البيانات، محلّية البيانات، فترات الاحتفاظ.
- الحقائق التشغيلية: عمليات الرجوع، الاستيراد، التجاوز اليدوي، وحالات "فريق الدعم يحتاج تعديل X".
لماذا النقص في المتطلبات يولد نماذج هشة
عندما تكون المتطلبات غامضة، يميل الذكاء الاصطناعي إلى "التخمين" بالافتراضات الافتراضية: حقول اختيارية في كل مكان، أعمدة حالة عامة، ملكية غير واضحة، وتسميات غير متسقة. يؤدي ذلك غالبًا إلى مخططات تبدو معقولة لكنها تنهار في الاستخدام الحقيقي—خصوصًا حول الأذونات، التقارير، وحالات الحافة (الاسترداد، الإلغاء، الشحن الجزئي، الموافقات متعددة الخطوات). ستدفع ثمن ذلك لاحقًا بترحيلات، حلول التوافق، وواجهات API مربكة.
قالب متطلبات قابل للنسخ
استخدم هذا كنقطة بداية والصقه في مطالبتك:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
أين يساعد الذكاء الاصطناعي أكثر: السرعة، الاتساق، والشمولية
الذكاء الاصطناعي في أفضل حالاته عندما تعامل معه كآلة مسودات سريعة: يمكنه رسم نموذج بيانات مبدئي ومنطقي ومجموعة مطابقة من النقاط النهائية خلال دقائق. تغيّر هذه السرعة طريقة عملك—ليس لأن المخرجات "صحيحة" سحريًا، بل لأنك تستطيع التكرار على شيء ملموس فورًا.
السرعة: من صفحة فارغة إلى هيكل عملي
أكبر فائدة هي إزالة البداية الفارغة. أعطِ الذكاء الاصطناعي وصفًا قصيرًا للكيانات، تدفقات المستخدمين الأساسية، والقيود، وستقترح الجداول/المجموعات، العلاقات، وسطح API أساسي. هذا ذو قيمة خاصة عندما تحتاج إثبات مفهوم سريعًا أو تستكشف متطلبات غير مستقرة بعد.
السرعة مفيدة خاصة في:
- النماذج الأولية حيث تحتاج التحقق من تدفقات بيانات حقيقية
- الأدوات الداخلية حيث "الكفاية" أهم من المثالية النمذجية
- المراحل المبكرة من منتج تتوقع إعادة كتابة أجزاء منه لاحقًا
الاتساق: اتخاذ القرارات النمطية بنفس الطريقة دائمًا
البشر يتعبون ويبتعدون عن المعايير. الذكاء الاصطناعي لا يفعل ذلك—لذا فهو ممتاز لتكرار الاتفاقيات عبر الباكند بأكمله:
- أنماط تسمية متسقة (مثل
createdAt,updatedAt,customerId) - أشكال نقاط نهاية متوقعة (
/resources,/resources/:id) - ترقيم وتصفيه موحّد
يجعل هذا الاتساق مثالياً للتوثيق، الاختبار، وتسليم العمل لمطوّر آخر.
الشمولية: "هل نسينا نقطة نهاية؟"
الذكاء الاصطناعي جيد أيضًا في الاكتمال. إذا طلبت مجموعة CRUD كاملة بالإضافة إلى عمليات شائعة (بحث، قوائم، تحديثات مجمعة)، فعادةً سيولد سطحًا أوليًا أكثر شمولية من مسودة بشرية مستعجلة.
فائدة شائعة سريعة هي توحيد الأخطاء: مظروف خطأ موحّد (code, message, details) عبر النقاط النهائية. حتى لو قمت لاحقًا بتحسينه، فإن وجود شكل واحد في البداية يمنع خليطًا فوضويًا من الردود.
العقيدة الرئيسية: دع الذكاء الاصطناعي ينتج الـ80% الأول بسرعة، ثم اقضِ وقتك على الـ20% التي تتطلب حكمًا—قواعد العمل، حالات الحافة، و"لماذا" وراء النموذج.
أوضاع الفشل النموذجية في المخططات المولَّدة آليًا
غالبًا تبدو المخططات المولَّدة آليًا "نظيفة": جداول مرتبة، تسميات معقولة، وعلاقات تتماشى مع المسار السعيد. تظهر المشاكل عادة عندما تصطدم بيانات حقيقية، مستخدمون حقيقيون، وتدفقات عمل حقيقية بالنظام.
التطبيع: إما زائد أو ناقص
يمكن للذكاء الاصطناعي التذبذب بين طرفي النقيض:
- تطبيع زائد: تقسيم كل شيء إلى جداول كثيرة (مثلاً جداول منفصلة لكل خاصية)، مما يجعل الاستعلامات الشائعة مكلفة ويزيد تعقيد الانضمامات.
- تطبيع ناقص: حشو حقول مكررة في جدول واحد (مثلاً أعمدة عنوان متعددة، أعلام حالة مفككة) مما يصعب التحقق والتحديث.
اختبار سريع: إذا كانت صفحاتك الشائعة تحتاج إلى أكثر من 6 انضمامات، فقد تكون في وضع تطبيع زائد؛ إذا كانت التحديثات تتطلب تغيير نفس القيمة في العديد من الصفوف، فقد تكون في تطبيع ناقص.
نسيان حالات الحافة المهمة للإنتاج
غالبًا ما يحذف الذكاء الاصطناعي متطلبات "مملة" لكنها حاسمة لتصميم الباكند:
- تعدد المستأجرين: نسيان
tenant_idعلى الجداول أو عدم فرض نطاق المستأجر في قيود التفرد. - الحذف الناعم: إضافة
deleted_atدون تحديث قواعد التفرد أو أنماط الاستعلام لاستبعاد السجلات المحذوفة. - التدقيق: فقدان
created_by/updated_by، سجل التغييرات، أو سجلات أحداث لا تتغير. - المناطق الزمنية: الخلط بين "date" و"timestamp" دون قاعدة واضحة (تخزين UTC مقابل العرض المحلي).
افتراضات خاطئة عن التفرد ودورة الحياة
قد يخمن الذكاء الاصطناعي:
- أن الحقل فريد عالميًا بينما هو فريد لكل مستأجر فقط (مثل "invoice_number"),
- أن الحقل مطلوب بينما هو اختياري أثناء الانضمام،
- أن حالة واحدة كافية بينما تحتاج إلى حالات دورة حياة (draft → active → suspended → archived).
تظهر هذه الأخطاء عادة في ترحيلات محرجة وحلول تطبيقية جانبية.
نقاط عمياء في الأداء
معظم المخططات المولَّدة لا تعكس كيف ستستعلم:
- عدم وجود فهارس مركبة للاستعلامات الشائعة (tenant_id + created_at),
- لا خطة لمسارات "ساخنة" (أحدث العناصر، عداد غير المقروءة),
- اعتماد كبير على حقول JSON دون استراتيجية فهرسة.
إذا لم يستطع النموذج وصف أهم 5 استعلامات لتطبيقك، لا يمكنه تصميم المخطط لهما بثقة.
تصميم API: ما الذي ينجزه الذكاء الاصطناعي وما الذي يخطئ فيه
الذكاء الاصطناعي غالبًا ما يكون جيدًا في إنتاج API "يبدو قياسيًا". سيحاكي أنماطًا مألوفة من أطر العمل وواجهات عامة، مما يوفّر وقتًا حقيقيًا. الخطر أنه قد يُحسِّن لما يبدو معقولًا بدلًا مما هو صحيح لمنتجك، نموذج بياناتك، وتغيراتك المستقبلية.
ما الذي ينجزه عادةً
أساسيات نمذجة الموارد. مع نطاق واضح، يميل الذكاء الاصطناعي لاختيار أسماء وطرق URL معقولة (مثل /customers, /orders/{id}, /orders/{id}/items). كما أنه جيد في تكرار اتفاقية التسمية عبر النقاط النهائية.
هيكلية نقاط النهاية الشائعة. غالبًا ما يشمل الأساسيات: قوائم مقابل تفاصيل، عمليات create/update/delete، وأشكال طلب/استجابة متوقعة.
اتفاقيات أساسية. إذا طلبت صراحةً، يمكنه توحيد الترقيم، التصفية، والفرز. مثال: ?limit=50&cursor=... (ترقيم مؤشري) أو ?page=2&pageSize=25، بالإضافة إلى ?sort=-createdAt وفلاتر مثل ?status=active.
أين يخطئ غالبًا
تسريب التجريدات. فشل كلاسيكي هو كشف جداول داخلية مباشرةً كـ"موارد"، خاصة عندما يحتوي المخطط على جداول وصل، حقول منقولة، أو أعمدة تدقيق. ينتهي بك الأمر بنقاط نهاية مثل /user_role_assignments التي تعكس تفاصيل التنفيذ بدلًا من مفهوم واجهة المستخدم (مثلاً "الأدوار لمستخدم"). هذا يجعل الـ API أصعب استخدامًا وتغييرًا لاحقًا.
تباين في التعامل مع الأخطاء. قد يخلط الذكاء الاصطناعي الأساليب: أحيانًا إرجاع 200 مع جسم خطأ، وأحيانًا استخدام 4xx/5xx. تريد عقدًا واضحًا:
- استخدم رموز HTTP المناسبة (
400,401,403,404,409,422) - مظروف خطأ موحّد (مثلاً
{ "error": { "code": "...", "message": "...", "details": [...] } })
الإصدار بعد الفعالية. كثير من التصاميم المولَّدة تتجاهل استراتيجية الإصدار حتى تصبح المشكلة مؤلمة. قرر منذ اليوم الأول ما إذا كنت ستستخدم إصدار المسار (/v1/...) أو الإصدار عبر الرأس، وحدد ما الذي يعتبر تغييرًا كاسرًا. حتى إذا لم تقم أبدًا بترقية الإصدار، فإن وجود القواعد يمنع تغييرات غير مقصودة.
قاعدة إبهام جيدة
استخدم الذكاء الاصطناعي للسرعة والاتساق، لكن تعامل مع تصميم الـ API كواجهة منتج. إذا كانت نقطة النهاية تعكس قاعدة بياناتك بدلًا من النموذج الذهني للمستخدم، فهذه إشارة إلى أن الذكاء الاصطناعي فضل سهولة التوليد على قابلية الاستخدام طويلة الأمد.
مسار عملي لاستخدام الذكاء الاصطناعي دون فقدان السيطرة
خطّط النموذج أولًا
استخدم وضع التخطيط لتحديد الكيانات والقواعد والحالات الحدّية قبل توليد الكود.
عامل الذكاء الاصطناعي كمصمم مبتدئ سريع: رائع في إنتاج المسودات، لكنه غير مسؤول عن النظام النهائي. الهدف هو استخدام سرعته مع الحفاظ على معماريتك مقصودة، قابلة للمراجعة، وموجهة بالاختبارات.
إذا كنت تستخدم أداة بناء مثل Koder.ai، فتصبح هذه الفواصل في المسؤولية أكثر أهمية: المنصة يمكنها بسرعة صياغة وتنفيذ باكند (مثلاً خدمات Go مع PostgreSQL)، لكنك تحتاج لتحديد الثوابت، حدود التفويض، وقواعد الترحيل التي ستعيش بها.
حلقة قابلة للتكرار: مطالبة → مسودة → مراجعة → اختبارات → تعديل
ابدأ بمطالبة محكمة تصف النطاق، القيود، و"معنى النجاح". اطلب أولًا نموذجًا مفاهيميًا (كيانات، علاقات، وثوابت)، لا جداول مباشرة.
ثم كرر في حلقة ثابتة:
- المطالبة: صِف المتطلبات، عدم-الأهداف، افتراضات التسمية والسعة.
- المسودة: اطلب من الذكاء الاصطناعي نموذجًا مفاهيميًا + مخططًا أوليًا + عقود API.
- المراجعة: فحص صحة النطاق، حالات الحافة، واتساق قرارات المنتج.
- الاختبارات: كتابة أو توليد اختبارات تشفر القرارات (قواعد التحقق، التفويض، idempotency، سلامة الترحيل).
- التعديل: أعِد تغذية النموذج بما فشل (نتائج المراجعة + إخفاقات الاختبار) واطلب نسخة مصححة.
تعمل هذه الحلقة لأنها تحوّل "اقتراحات AI" إلى آثار يمكن إثباتها أو رفضها.
فصل النموذج المفاهيمي عن المخطط الفيزيائي وعقود الـ API
حافظ على ثلاث طبقات متميزة:
- النموذج المفاهيمي: ما يهم العمل (مثلاً "يمكن إيقاف الاشتراك مؤقتًا"، "يجب أن تشير الفاتورة إلى فترة فوترة")
- المخطط الفيزيائي: كيف تُخزّن (جداول/مجموعات، فهارس، قيود، تقسيم)
- عقود الـ API: كيف يتعامل العملاء معه (الموارد، الحمولة، الأخطاء، استراتيجية الإصدار)
اطلب من الذكاء الاصطناعي إخراج هذه الأجزاء كأقسام منفصلة. عندما يتغير شيء (مثلاً حالة جديدة أو قاعدة)، حدِّث الطبقة المفاهيمية أولًا، ثم صِل التغييرات إلى المخطط والـ API. هذا يقلل الارتباط العرضي ويجعل عمليات إعادة الهيكلة أقل إيلامًا.
اجعل القرارات قابلة للتتبع بملاحظات تصميم خفيفة
يجب أن تترك كل دورة أثرًا. استخدم ملخصات قصيرة على نمط ADR (صفحة أو أقل) تسجل:
- القرار: ما الذي اخترته (مثلاً "الحذف الناعم عبر
deleted_at"). - التبرير: لماذا (متطلبات تدقيق، تدفق الاستعادة).
- البدائل التي تم النظر فيها: ولماذا رُفضت.
- العواقب: تأثير الترحيل، تعقيد الاستعلام، سلوك الـ API.
عندما تلصق ملاحظات المراجعة مرة أخرى في الذكاء الاصطناعي، ضمّن ملاحظات القرار ذات الصلة حرفيًا. هذا يمنع النموذج من "نسيان" الاختيارات السابقة ويساعد فريقك على فهم الباكند بعد أشهر.
المطالبات التي تُنتج مخططات وواجهات أفضل
يُوجَّه الذكاء الاصطناعي بسهولة عندما تعامل المطالبة كتمرين كتابة مواصفة: عرّف النطاق، اذكر القيود، وأصرّ على مخرجات ملموسة (DDL، جداول نقاط النهاية، أمثلة). الهدف ليس "أن تكون مبدعًا"—إنما "أن تكون دقيقًا".
مطالبات للكيانات والعلاقات (مع قيود)
اطلب نموذج بيانات وقواعد تحافظ على اتساقه.
- "صمّم مخططًا علائقيا للاشتراكات entities: User, Plan, Subscription, Invoice. ضمّن الضَّرْبات (cardinalities)، قيود التفرد، واستراتيجية الحذف الناعم. قواعد: اشتراك واحد نشط لكل مستخدم؛ الفواتير يجب أن تشير لسعر الخطة الثابت وقت الشراء؛ خزّن العملة كرمز ISO؛ الطوابع الزمنية بالـ UTC."
إذا كانت لديك اتفاقيات بالفعل، اذكرها: نمط التسمية، نوع المعرف (UUID مقابل bigint)، سياسة القابلية للقبول (nullable)، وتوقعات الفهرسة.
مطالبات للنقاط النهائية والعقود (مع أمثلة)
اطلب جدولًا للـ API مع عقود صريحة، لا فقط قائمة مسارات.
- "اقترح نقاط REST لإدارة الاشتراكات. لكل نقطة: الطريقة، المسار، المصادقة، معلمات الاستعلام، JSON الطلب، JSON الاستجابة، رموز الأخطاء، وإرشادات عدم التكرار. أضف أمثلة لنجاح وحالتي فشل."
أضف سلوك العمل: نمط الترقيم، حقول الفرز، وكيفية عمل التصفية.
مطالبات للترحيلات والتوافق الرجعي
اجعل النموذج يفكر بالإصدارات.
- "نضيف
billing_addressللعميل. قدّم خطة ترحيل آمنة: SQL للترحيل للأمام، خطوات تعبئة البيانات، إطلاق عبر ميزة-علمية (feature-flag)، واستراتيجية التراجع. يجب أن يبقى الـ API متوافقًا لمدة 30 يومًا؛ العملاء القدامى قد لا يرسلون الحقل."
مطالبات-مضادة يجب تجنّبها
المطالبات الغامضة تُنتج أنظمة غامضة.
- "صمّم قاعدة بيانات لتطبيق تجارة إلكترونية" (عام جدًا)
- "اجعلها قابلة للتوسع وآمنة" (تفتقد قياسات قابلة للقياس)
- "أنشئ أفضل مخطط" (بدون قواعد نطاق)
- "اصنع APIs لكل شيء" (بدون حدود أو أولويات)
عندما تريد مخرجات أفضل، ضيق المطالبة: حدد القواعد، حالات الحافة، وصيغة المخرجات المطلوبة.
قائمة مراجعة بشرية قبل الإطلاق
توسّع خارج النظام الخلفي
ولّد تطبيقات الويب والسيرفر والموبايل من الدردشة عندما يكون نظامك الخلفي جاهزًا.
يمكن للذكاء الاصطناعي صياغة باكند مناسب، لكن إطلاقه بأمان يحتاج دائمًا مرور بشري. اعتبر هذه القائمة "بوابة إصدار": إذا لم تستطع الإجابة على عنصر بثقة، أوقف وأصلح قبل أن يصبح بيانات إنتاج.
قائمة مراجعة المخطط (الجداول، المجموعات، والأعمدة)
- المفاتيح الأساسية: لكل جدول مفتاح أساسي واضح. إذا استخدمت UUIDs، أكد استراتيجية الإنشاء (قاعدة البيانات مقابل التطبيق) والفهرسة.
- المفاتيح الأجنبية والقيود: أضف قيود FK حيث العلاقات حقيقية. تحقق من قواعد ON DELETE/ON UPDATE المقصودة (restrict vs cascade vs set null).
- التفرد: طبق التفرد في قاعدة البيانات (ليس فقط في الكود): عناوين البريد، المعرفات الخارجية، القيود المركبة (مثل
(tenant_id, slug)). - قابلية القيم الفارغة: راجع كل حقل قابل للـ nullable. إذا كان "غير معروف" يختلف عن "فارغ"، نمذج ذلك صراحة.
- الفهارس: أضف فهارس للتصفية/الفرز/الانضمام المتكرر. أزل الفهارس العرضية على حقول منخفضة التفرّد التي لن تفيد.
- اتساق التسمية: اختر اتفاقيات (مفرد مقابل جمع، لاحقة
_id, الطوابع الزمنية) وطبّقها بشكل موحّد.
قرارات سلامة البيانات (التي تكلف لاحقًا لتغييرها)
اكد قواعد النظام كتابةً:
- التكامل المرجعي: أي علاقات يجب ألا تنكسر أبدًا؟ أي منها يمكن أن تكون بنية مجهولة؟
- قواعد الحذف التتبعي: إذا حُذف الأصل، هل يجب حذف الأبناء، تركهم يتيمين، أم منع الحذف؟
- استراتيجية الحذف الناعم: إذا استخدمت الحذف الناعم، تأكد أن الاستعلامات لن "تعيد" السجلات المحذوفة. قرر إن كانت قيود التفرد يجب أن تتجاهل الصفوف المحذوفة.
قائمة مراجعة الـ API (السلوك والسلامة)
- المصادقة والتفويض: حدد من يمكنه استدعاء كل نقطة وما الذي يمكنهم الوصول إليه (خاصةً في بيانات متعدد المستأجرين).
- التحقق: تحقق من الأنواع، النطاقات، الصيغ، وقواعد بين الحقول. لا تعتمد على أخطاء قاعدة البيانات كتحقق أساسي.
- قيود المعدل ومكافحة الإساءة: أضف افتراضات معقولة، لكل مستخدم/رمز/IP حيث يلزم.
- قابلية التكرار: لعمليات الإنشاء/المدفوعات، ادعم مفاتيح idempotency أو معرفات طلب حتمية.
- أخطاء موحّدة: نمّط شكل الخطأ ورموز HTTP. تأكد أن رسائل الخطأ لا تكشف أسرار النظام.
قبل الدمج، قم بمراجعة سريعة "المسار السعيد + أسوأ المسار": طلب طبيعي، طلب غير صالح، طلب غير مخوّل، سيناريو عالي الحمل. إن فاجأك سلوك الـ API، فسيفاجئ المستخدمين أيضًا.
استراتيجية الاختبار لباكند مولَّد بالذكاء الاصطناعي
يمكن للذكاء الاصطناعي توليد مخطط وواجهة API معقولة بسرعة، لكنه لا يثبت أن الباكند يتصرف بشكل صحيح تحت حمل وسيناريوهات وبيانات حقيقية. عامل مخرجات AI كمسودة وارتكز عليها بالاختبارات التي تثبّت السلوك.
اختبارات العقد للـ API
ابدأ باختبارات عقد تتحقق من الطلبات، الاستجابات، ودلالات الأخطاء—ليس فقط "المسارات السعيدة". ابنِ مجموعة صغيرة تعمل ضد نسخة حقيقية (أو حاوية) من الخدمة.
ركّز على:
- رموز الحالة وأجسام الأخطاء (مثلاً 400 مقابل 404 مقابل 409)
- حالات التحقق من الصحة (سلاسل فارغة، حمولة كبيرة، حقول غير متوقعة)
- ثبات الترقيم والفرز (ترتيب ثابت، صحة المؤشر)
- قابلية التكرار لعمليات الإنشاء/التحديث
إذا نشرت مواصفة OpenAPI، ولّد اختبارات منها—لكن أضف حالات مكتوبة يدويًا للأجزاء المعقدة التي لا تستطيع المواصفة التعبير عنها (قواعد التفويض، قيود العمل).
اختبارات الترحيل وخطط التراجع
غالبًا ما تفوّت المخططات المولَّدة تفاصيل تشغيلية: الافتراضات الآمنة، تعبئات البيانات، وقابلية الرجوع. أضف اختبارات ترحيل:
- تطبيق الترحيلات من قاعدة فارغة ومن لقطة قديمة "متسخة"
- التحقق من أن القيود (الفريدة، المفاتيح الأجنبية) تعمل كما هو متوقع بعد التعبئة
- تجربة التراجع (أو على الأقل خطة تصحيح للأمام) لكل ترحيل
احتفظ بخطة تراجع نصية للإنتاج: ماذا تفعل إذا كان الترحيل بطيئًا، أقفل جداول، أو كسر التوافق.
اختبارات التحميل/الأداء مرتبطة بنمط الاستعلام الحقيقي
لا تقسّ سرعتك على نقاط نهاية عامة. سجّل نماذج الاستعلام التمثيلية (قوائم العرض الأعلى، البحث، الانضمامات، التجميع) واختبرها بالحمل.
قِس:
- زمن الاستجابة p95/p99 لكل نقطة نهاية
- عدد استعلامات DB والاستعلامات البطيئة
- استخدام الفهارس (والفهارس المفقودة)
هنا تفشل تصاميم AI عادةً: جداول "منطقية" تنتج انضمامات مكلفة تحت الحمل.
أساسيات اختبار الأمان
أضف فحوصات آلية لـ:
- قواعد التفويض (المستخدم A لا يمكنه الوصول لموارد B)
- حقن (SQL/NoSQL، عبور المسارات، حقن JSON)
- معالجة البيانات الحساسة (لا أسرار في السجلات، حجب الحقول، التشفير حيث يلزم)
حتى اختبارات الأمان الأساسية تمنع أخطر فئة من أخطاء الذكاء الاصطناعي: نقاط نهاية تعمل لكنها تكشف أكثر من اللازم.
الترحيلات، إعادة الهيكلة، وقابلية الصيانة الطويلة الأمد
يمكن للذكاء الاصطناعي صياغة "نسخة 0" جيدة من المخطط، لكن باكندك سيعيش حتى الإصدار 50. الفرق بين باكند يصمد للتغيير وآخر ينهار هو كيفية تطوّره: الترحيلات، إعادة الهيكلة الخاضعة، وتوثيق النوايا.
تطوير المخططات المولَّدة آليًا بأمان
عامل كل تغيير مخطط كترحيل، حتى لو اقترح الذكاء الاصطناعي "فقط alter table". استخدم خطوات صريحة وقابلة للعكس: أضف أعمدة جديدة أولًا، عبِّئها، ثم شدِّد القيود. فضّل التغييرات الإضافية (حقول جديدة، جداول جديدة) على التدميرية (إعادة تسمية/حذف) حتى تثبت عدم اعتماد أي شيء على الشكل القديم.
عند طلب تحديثات من الذكاء الاصطناعي، أرفق المخطط الحالي وقواعد الترحيل التي تتبعها (مثلاً: "لا حذف أعمدة؛ استخدم توسيع/تقليص"). هذا يقلل احتمال اقتراح تغيير صحيح نظريًا لكنه خطير في الإنتاج.
التعامل مع تغييرات كاسرة بلا فوضى
التغييرات الكاسرة نادرًا ما تكون لحظة واحدة؛ إنها انتقال.
- الإهمال: احتفظ بالحقول/النقاط القديمة عملًة مع تسجيل الاستخدام.
- الكتابة المزدوجة: اكتب في العمود/الجدول القديم والجديد خلال نافذة الانتقال.
- التعبئات: شغل وظيفة واحدة أو متدرجة لملء البنية الجديدة.
الذكاء الاصطناعي مفيد في اقتراح خطة خطوة بخطوة (بما في ذلك مقتطفات SQL وترتيب الإطلاق)، لكن عليك التحقق من التأثير الزمني: الأقفال، المعاملات الطويلة، وإمكانية استئناف التعبئة.
إعادة هيكلة نماذج البيانات دون إعادة كتابة كل شيء
تهدف إعادة الهيكلة لعزل التغيير. إذا احتجت للتطبيع، تقسيم جدول، أو إدخال سجل أحداث، احتفظ بطبقات توافق: views، كود ترجمة، أو جداول "ظل". اطلب من الذكاء الاصطناعي اقتراح إعادة هيكلة تحافظ على عقود الـ API الحالية، وبيّن ما الذي يجب تغييره في الاستعلامات، الفهارس، والقيود.
وثّق الافتراضات حتى تظل المطالبات المستقبلية متسقة
معظم الانحراف طويل الأمد يحدث لأن المطالبة التالية تنسى النية الأصلية. احتفظ بعقد "نموذج بيانات" قصيرة: قواعد التسمية، استراتيجية المعرفات، دلالات الطوابع الزمنية، سياسة الحذف الناعم، والثوابت ("مجموع الطلب مشتق، لا يُخزن"). اربطها في الوثائق الداخلية (مثلاً /docs/data-model) وأعد استخدامها في مطالبات الذكاء الاصطناعي المستقبلية حتى تصمم الأجزاء ضمن نفس الحدود.
اعتبارات الأمان والخصوصية
ثبت السلوك بالاختبارات
حوّل الثوابت إلى فحوص قابلة للتكرار حتى تظل مسودة الذكاء الاصطناعي موثوقًا.
يمكن للذكاء الاصطناعي صياغة الجداول ونقاط النهاية بسرعة، لكنه لا "يملك" المخاطر. اعتبر الأمان والخصوصية متطلبات أساسية تضيفها إلى المطالبة، ثم تحقق منها في المراجعة—خاصة حول البيانات الحساسة.
ابدأ بتصنيف البيانات
قبل قبول أي مخطط، صنّف الحقول بحسب الحساسية (عامة، داخلية، سرية، خاضعة). يرتب هذا التصنيف ما يجب تشفيره، قناعتها، أو تقليل حفظه.
مثال: كلمات المرور لا تُخزن أبدًا كنص صريح (فقط هاشات ملحوبة)، الرّموز قصيرة العمر ومشفرة في الراحة، وPII مثل البريد/الهاتف قد يحتاج حجبًا في واجهات الإدارة وصادرات.
إذا كان الحقل غير ضروري لقيمة المنتج، لا تخزنه—الذكاء الاصطناعي غالبًا ما يضيف سمات "جميلة الوجود" تزيد من التعرض.
التحكم في الوصول: RBAC مقابل ABAC
تصادف APIات مولَّدة غالبًا فحوصات دور بسيطة. الـ RBAC سهل، لكنه ينهار مع قواعد الملكية ("المستخدم يرى فواتيره فقط") أو قواعد السياق ("الدعم يرى البيانات فقط أثناء تذكرة فعّالة"). الـ ABAC يتعامل مع هذه الحالات لكن يتطلب سياسات صريحة.
كن واضحًا بشأن النمط الذي تستخدمه، وتأكد أن كل نقطة نهاية تطبقه باستمرار—خصوصًا قوائم/بحث، التي تُعد نقاط تسريب شائعة.
منع السجلات العرضية للحقول الحساسة
قد يسجّل الكود المولَّد كامل جسم الطلب أو رؤوسه أو صفوف DB أثناء الأخطاء. هذا يمكن أن يُسرّب كلمات مرور، رموز مصادقة، وPII إلى السجلات وأدوات APM.
ضع افتراضات افتراضية مثل: سجلات مُهيكلة، قوائم سماح للحقول المسموح تسجليها، حجب الأسرار (Authorization, cookies, reset tokens)، وتجنّب تسجيل الحمولة الخام عند فشل التحقق.
الخصوصية، الاحتفاظ، والحذف
صمّم للحذف منذ اليوم الأول: حذف يبدأه المستخدم، إغلاق الحساب، وسير عمل "الحق في النسيان". عرّف نوافذ الاحتفاظ لكل فئة بيانات (مثلاً: أحداث التدقيق مقابل أحداث التسويق)، وتأكد أنك تستطيع إثبات ما حُذف ومتى.
إذا احتفظت بسجلات تدقيق، خزّن معرفات دنيا، احمها بوصول أشد، ووثّق كيف تصدر أو تحذف البيانات عند الطلب.
متى تستخدم الذكاء الاصطناعي (ومتى لا)
الذكاء الاصطناعي في أفضل حالاته عندما تعامل معه كمصمم معماري مبتدئ سريع: رائع في إنتاج مسودات أولى، أضعف في إجراء المقايضات الحرجة للمجال. السؤال الصحيح ليس "هل يستطيع الذكاء الاصطناعي تصميم باكند؟" بل "أي الأجزاء يمكن للذكاء الاصطناعي صياغتها بأمان، وأي الأجزاء تتطلب ملكية خبراء؟"
مناسبة جيدة: المسودات، النماذج الأولية، والأنماط المفهومة
يوفر الذكاء الاصطناعي وقتًا حقيقيًا عندما تبني:
- نماذج أولية صغيرة، أدوات داخلية، وMVPs حيث الهدف التعلم السريع
- نظم تعتمد CRUD بكثافة مع كيانات مألوفة (users, orders, subscriptions)
- "لحظات الصفحة البيضاء": إنشاء مخطط أولي، مساحة API، واتفاقيات التسمية للتكرار
هنا الذكاء الاصطناعي قيّم للسرعة، الاتساق، والشمولية—خصوصًا إذا كنت تعرف كيف تريد أن يتصرف المنتج وتستطيع اكتشاف الأخطاء.
غير ملائم: الأنظمة المنظمة، عالية المخاطر، أو المعقدة مجاليًا
كن متحفظًا (أو اعتبر تصميم AI مصدر إلهام فقط) عند العمل في مجالات:
- المالية: دفاتر الأستاذ، التسوية، سجلات التدقيق والقواعد التي يجب أن تكون دقيقة
- الرعاية الصحية: بيانات المرضى، نماذج الموافقة، متطلبات التشغيل البيني
- المجالات الحرجة للسلامة: حيث يمكن لافتراض "معقول" أن يُكلّف الكثير
في هذه المجالات، تفوق الخبرة المجالية سرعة الذكاء الاصطناعي. المتطلبات الدقيقة—قانونية، سريرية، محاسبية، تشغيلية—غالبًا ما تكون غائبة في المطالبة، والذكاء الاصطناعي سيملأ الفجوات بثقة.
دليل اتخاذ القرار: استخدم الذكاء الاصطناعي للمسودات، واشترط توقيع بشري
قاعدة عملية: دع الذكاء الاصطناعي يقترح خيارات، لكن اشترط مراجعة نهائية للثوابت، حدود التفويض، واستراتيجية الترحيل. إذا لم تستطع تسمية من المسؤول البشري عن المخطط وعقود الـ API، فلا تُطلق باكندًا صممه الذكاء الاصطناعي.
خطوات تالية
إذا كنت تقيم تدفقات العمل والضوابط، راجع الأدلة ذات الصلة في /blog. إذا أردت مساعدة لتطبيق هذه الممارسات على عملية فريقك، اطلع على /pricing.
إذا فضّلت سير عمل شامل حيث يمكنك التكرار عبر الدردشة، توليد تطبيق عملي، والحفاظ على السيطرة عبر تصدير الشيفرة ونقاط استرجاع صديقة للترحيل، فـ Koder.ai مصممة لهذا الأسلوب من بناء ومراجعة.
الأسئلة الشائعة
ماذا يعني عمليًا "الذكاء الاصطناعي صمم الباكند لدينا"؟
عادةً ما يعني أن النموذج قد أنشأ مسودة أولية من:
- الكيانات/الجداول (أو المجموعات) والحقول
- العلاقات والقيود الأساسية
- مجموعة أولية من نقاط نهاية CRUD
تظل هناك حاجة لفريق بشري للتحقق من قواعد العمل، حدود الأمان، أداء الاستعلامات، وسلامة عمليات الترحيل قبل الإطلاق.
ما المعلومات التي يجب أن أعطيها للذكاء الاصطناعي قبل أن أطلب مخططًا أو API؟
قدّم مدخلات لا يستطيع الذكاء الاصطناعي تخمينها بأمان:
- تعريفات الكيانات (ما معنى كل كائن فعليًا)
- تدفقات العمل الأساسية وتحولات الحالات
- الأدوار/الأذونات وحدود الـ tenant
- أسئلة التقارير التي ستحتاج إجابات لها لاحقًا
- تكاملات ونُهج حفظ المعرفات الخارجية
- أهداف السعة/الزمن-التأخّر
- قواعد الامتثال، الاحتفاظ، والحذف
كلما كانت القيود أوضح، قلّت فرصة أن يملأ الذكاء الاصطناعي الفراغات بإفتراضات هشة.
لماذا يجب أن أفصل النموذج المفاهيمي عن المخطط الفيزيائي وعقود الـ API؟
ابدأ بنموذج مفهومي (مفاهيم العمل + القيود)، ثم استخرج:
- المخطط الفيزيائي (الجداول، القيود، الفهارس)
- عقود الـ API (الموارد، الحمولة، الأخطاء)
فصل هذه الطبقات يجعل من الأسهل تغيير التخزين دون كسر الـ API — أو تعديل الـ API دون الإضرار بقواعد العمل.
ما هي أكثر أوضاع الفشل شيوعًا في المخططات التي يولدها الذكاء الاصطناعي؟
تشمل المشاكل الشائعة:
- تطبيع زائد أو ناقص (انضمامات كثيرة مقابل تكرار بيانات)
- نسيان نطاق تعدد المستأجرين (
tenant_idوقيود فريدة مركبة) - أخطاء الحذف الناعم (القيود والاستعلامات لا تأخذ
deleted_atفي الاعتبار) - نقص حقول التدقيق/السجلات عندما تحتاج لتتبّع الأحداث
كيف أتأكد أن مخططًا مولَّدًا بواسطة الذكاء الاصطناعي لن يكون بطيئًا في الإنتاج؟
اطلب من الذكاء الاصطناعي التصميم حول أهم استعلاماتك ثم تحقّق:
- أي عوامل/فرزات شائعة (مثلاً
tenant_id + created_at) - أي نقاط نهاية "ساخنة" (أحدث العناصر، عدّ العناصر غير المقروءة)
- أين تحتاج فهارس مركبة
- أين ستكون الانضمامات مكلفة
إذا لم تستطع تسمية أهم 5 استعلامات/نقاط نهاية، فاعتبر أي خطة فهرسة غير مكتملة.
ما الأخطاء الشائعة التي يقترفها الذكاء الاصطناعي عند توليد REST APIs؟
الذكاء الاصطناعي غالبًا ما ينتج إسكلتة API قياسية، لكن لاحظ:
- نقاط نهاية تعكس الجداول (تسرّب التجريد) مثل موارد جسرية (
user_role_assignments) التي تكشف تفاصيل تنفيذية بدلاً من مفاهيم واجهة المستخدم - تناقضات في التعامل مع الأخطاء (إرجاع
200مع جسم خطأ أحيانًا) - غياب استراتيجية إصدار وإرشادات تغيير كاسِر
عامل الـ API كواجهة منتج: صمم نقاط النهاية حول مفاهيم المستخدم، لا تفاصيل قاعدة البيانات.
ما سير العمل الآمن للتكرار مع الذكاء الاصطناعي دون فقدان السيطرة؟
استخدم حلقة متكررة قابلة للتكرار:
- المطالبة (Prompt): حدد القيود، عدم الأهداف، الاتفاقيات، وافتراضات السعة
- المسودة: اطلب من الذكاء الاصطناعي نموذجًا مفهوميًا + مخططًا أوليًا + عقود API
- المراجعة: تحقّق من صحة النطاق، الحواف، والأمان
كيف أوحّد التعامل مع الأخطاء في API مولَّد بواسطة الذكاء الاصطناعي؟
استخدم شكل أخطاء موحّد مع رموز HTTP مناسبة، على سبيل المثال:
- رموز الحالة:
400,401,403,404,409, ,
ما الذي يجب اختباره أولًا على باكند صممه الذكاء الاصطناعي؟
أولويات الاختبارات التي تثبّت السلوك:
- اختبارات عقود الـ API (رموز الحالة، حالات التحقق من الصحة، ثبات التصفُّح)
- اختبارات التفويض (المستخدم أ لا يمكنه الوصول إلى موارد المستخدم ب)
- اختبارات قابلية التكرار لعمليات الإنشاء/المدفوعات
- اختبارات الترحيل (التطبيق على قاعدة فارغة + لقطة قديمة؛ تحقق من القيود بعد تعبئة البيانات)
- اختبارات أمان أساسية (حقن، إزالة بيانات حساسة من السجلات)
الاختبارات هي وسيلتك لامتلاك التصميم بدلًا من وراثة افتراضات الذكاء الاصطناعي.
متى يكون الاعتماد على الذكاء الاصطناعي فكرة سيئة لتصميم الباكند؟
الذكاء الاصطناعي مفيد للمسودات عندما تكون الأنماط مفهومة جيدًا (نظم CRUD، أدوات داخلية، MVPs). كن حذرًا أو تجنّب الاعتماد عليه كحل نهائي في مجالات:
- المالية: دفاتر الحسابات، التسويات، قواعد التراجع
- الرعاية الصحية: بيانات المرضى، نماذج الموافقة، امتثال تبادل البيانات
- المجالات الحساسة للسلامة: حيث يمكن أن يكلف افتراض "معقول" كثيرًا
قاعدة عملية: دع الذكاء الاصطناعي يقترح خيارات، لكن اشترط توقيع بشري على ثوابت النموذج، حدود الأذونات، واستراتيجية الترحيل.