18 ديسمبر 2025·6 دقيقة
تصميم مخطط Postgres في وضع التخطيط: نهج خطوة بخطوة
وضع التخطيط لتصميم سكيمة Postgres يساعدك على تحديد الكيانات والقيود والفهارس والترحيلات قبل توليد الشيفرة، مما يقلل الحاجة لإعادة الكتابة لاحقًا.
وضع التخطيط لتصميم سكيمة Postgres يساعدك على تحديد الكيانات والقيود والفهارس والترحيلات قبل توليد الشيفرة، مما يقلل الحاجة لإعادة الكتابة لاحقًا.
إذا أنشأت نقاط نهاية ونماذج قبل أن يتضح شكل قاعدة البيانات، فعادةً ستعيد كتابة نفس الميزات مرتين. التطبيق يعمل للعرض التجريبي، ثم تأتي البيانات الحقيقية وحالات الحافة الحقيقية وتبدأ الأشياء بالشعور بالهشاشة.
معظم عمليات إعادة الكتابة تنشأ من ثلاثة مشاكل متوقعة:
كل واحدة منها تفرض تغييرات تتسرب عبر الشيفرة، الاختبارات، وتطبيقات العميل.
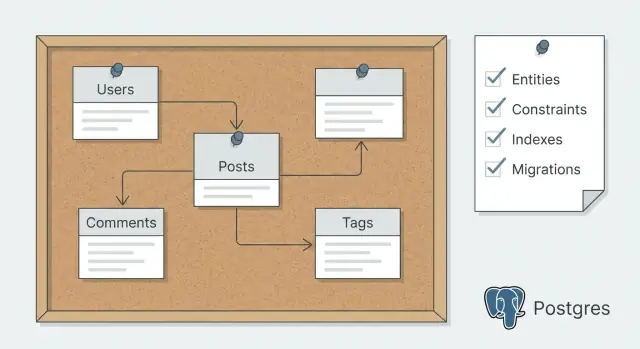
التخطيط لسكيمة Postgres يعني أن تقرر عقدة البيانات أولًا، ثم تولّد الشيفرة المطابقة لها. عمليًا، هذا يشبه كتابة الكيانات، العلاقات، والقليل من الاستعلامات المهمة، ثم اختيار القيود، الفهارس، ونهج الترحيل قبل أن يقوم أي أداة بإنشاء الجداول وعمليات CRUD.
هذا مهم أكثر عند استخدام منصة توليد سريعة مثل Koder.ai، حيث يمكنك توليد الكثير من الشيفرة بسرعة. التوليد السريع ممتاز، لكنه أكثر موثوقية عندما تكون السكيمة مستقرة. النماذج ونقاط النهاية المولّدة ستحتاج لتعديلات أقل لاحقًا.
إليك ما يخطئ عادةً عندما تتخطى التخطيط:
خطة سكيمة جيدة بسيطة: وصف بلغة واضحة للكيانات، مسودة للجداول والأعمدة، القيود والفهارس الأساسية، واستراتيجية ترحيل تتيح لك تغيير الأمور بأمان مع نمو المنتج.
يعمل تخطيط السكيمة بشكل أفضل عندما تبدأ بما يجب أن يتذكره التطبيق وما يجب أن يتمكن الناس من فعله بتلك البيانات. اكتب الهدف في 2 إلى 3 جمل بسيطة. إذا لم تستطع شرحه ببساطة، فربما ستنشئ جداول زائدة عن الحاجة.
بعدها، ركّز على الإجراءات التي تنشئ أو تغيّر البيانات. هذه الإجراءات هي المصدر الحقيقي للصفوف، وتكشف ما يجب التحقق منه. فكر بالأفعال، لا بالأسماء.
على سبيل المثال، قد يحتاج تطبيق حجوزات إلى إنشاء حجز، إعادة جدولته، إلغاؤه، استرداد المبلغ، وإرسال رسالة إلى العميل. تلك الأفعال تقترح بسرعة ما يجب تخزينه (فترات زمنية، تغييرات الحالة، مبالغ مالية) قبل أن تسمي الجدول.
التقط أيضًا مسارات القراءة، لأن عمليات القراءة توجه البنية والفهرسة لاحقًا. أدرج الشاشات أو التقارير التي سيستخدمها الناس وكيف يقسمون البيانات: “حجوزاتي” مرتبة بالتاريخ ومصفاة بالحالة، بحث إدارة حسب اسم العميل أو مرجع الحجز، الإيرادات اليومية بحسب الموقع، وعرض تدقيق من قام بتغيير ماذا ومتى.
أخيرًا، دوّن الاحتياجات غير الوظيفية التي تغيّر خيارات السكيمة، مثل سجل التدقيق، الحذف الناعم، فصل متعددة المستأجرين، أو قواعد الخصوصية (مثال: تقييد من يمكنه رؤية تفاصيل الاتصال).
إذا كنت تخطط لتوليد الشيفرة بعد ذلك، تصبح هذه الملاحظات مطالب قوية. توضح ما هو مطلوب، ما يمكن تغييره، وما يجب أن يكون قابلاً للبحث. إذا كنت تستخدم Koder.ai، فإن كتابة ذلك قبل التوليد يجعل وضع التخطيط أكثر فعالية لأن المنصة تعمل من متطلبات حقيقية بدلًا من تخمينات.
قبل أن تلمس الجداول، اكتب وصفًا بسيطًا لما يخزنه تطبيقك. ابدأ بسرد الأسماء التي تتكرر: user, project, message, invoice, subscription, file, comment. كل اسم منها مرشح لكيان.
ثم أضف جملة واحدة لكل كيان تجيب: ما هو ولماذا يوجد؟ مثال: “المشروع Project هو مساحة عمل ينشئها المستخدم لتجميع العمل ودعوة الآخرين.” هذا يمنع جداول غامضة مثل data، items، أو misc.
الملكية قرار كبير يؤثر على معظم الاستعلامات التي تكتبها. لكل كيان، قرّر:
الآن قرّر كيف ستُحدد السجلات. UUIDs ممتازة عندما يمكن إنشاء السجلات من أماكن متعددة (ويب، موبايل، وظائف خلفية) أو عندما لا تريد معرفات قابلة للتنبؤ. Bigint أصغر وأسرع قليلًا. إذا احتجت معرفًا يسهل على البشر قراءته، احتفظ به منفصلًا (مثال: project_code قصير وفريد داخل الحساب) بدلًا من إجباره كمفتاح أساسي.
أخيرًا، اكتب العلاقات بالكلمات قبل أن ترسم أي شيء: المستخدم لديه مشاريع عديدة، المشروع يحتوي على رسائل عديدة، والمستخدمون يمكن أن ينتموا لعدة مشاريع. علم كل رابط كإجباري أو اختياري، مثل “الرسالة يجب أن تنتمي لمشروع” مقابل “الفاتورة قد تنتمي لمشروع.” هذه الجمل تصبح مصدر الحقيقة للتوليد لاحقًا.
بمجرد أن تقرأ الكيانات بوضوح بلغة بسيطة، حوّل كل واحدة إلى جدول بأعمدة تطابق الحقائق الحقيقية التي تحتاج تخزينها.
ابدأ بالأسماء والأنواع التي يمكنك الالتزام بها. اختر أنماطًا متسقة: أسماء أعمدة snake_case، نفس النوع لنفس الفكرة، ومفاتيح أساسية متوقعة. للطوابع الزمنية، فضّل timestamptz حتى لا تفاجئك مناطق الزمن لاحقًا. للنقود، استخدم numeric(12,2) (أو خزن السنتات كعدد صحيح) بدلًا من الفواصل العشرية floats.
لحقل الحالة status، استخدم إما enum في Postgres أو عمود text مع CHECK constraint حتى تُسيطر على القيم المسموح بها.
قرّر ما هو مطلوب مقابل اختياري بترجمة القواعد إلى NOT NULL. إذا كان يجب أن توجد قيمة لكي يكون الصف منطقيًا، اجعله مطلوبًا. إذا كان فعلاً مجهولًا أو غير مطبق، اسمح بالقيم الفارغة null.
مجموعة أعمدة افتراضية عملية للتخطيط:
id (uuid أو bigint، اختر نهجًا واحدًا وابقَ ثابتًا)created_at و updated_atdeleted_at فقط إذا كنت بحاجة فعلاً للحذف الناعم والاستعادةcreated_by عندما تحتاج أثر تدقيقي واضح لمن فعل ماذاعلاقات many-to-many يجب أن تصبح عادةً جداول ربط. مثال: إذا كان بإمكان عدة مستخدمين التعاون على تطبيق، أنشئ app_members مع app_id و user_id، ثم فرض التفرّد على الزوج حتى لا تحدث التكرارات.
فكر في السجل التاريخي مبكرًا. إذا كنت تعرف أنك ستحتاج إلى إصدار نسخ، خطط لجدول غير قابل للتغيير مثل app_snapshots، حيث كل صف هو نسخة محفوظة مرتبطة بـ apps بواسطة app_id وموسومة بـ created_at.
القيود هي دروع السكيمة. قرّر أي قواعد يجب أن تكون صحيحة بغض النظر عن أي خدمة أو سكربت أو أداة إدارية تصل للقاعدة.
ابدأ بالهوية والعلاقات. كل جدول يحتاج مفتاحًا أساسيًا، وأي حقل “ينتمي إلى” يجب أن يكون مفتاحًا أجنبيًا حقيقيًا، لا مجرد عدد صحيح تأمل أن يتطابق.
ثم أضف التفرّد حيث تسبب التكرارات أضرارًا حقيقية، مثل حسابين بنفس البريد الإلكتروني أو عنصرين بنفس (order_id, product_id).
قيود ذات قيمة عالية للتخطيط مبكرًا:
amount >= 0, status IN ('draft','paid','canceled'), أو rating BETWEEN 1 AND 5.سلوك التتابع (cascade) هو المكان الذي يوفر فيه التخطيط جهدًا لاحقًا. اسأل نفسك ماذا يتوقع الناس فعلاً. إذا حُذف عميل، فهل يجب أن تختفي طلباته؟ عادةً لا؛ هذا يميل إلى تفضيل restrict ويحافظ على السجل. لبيانات تعتمد كليًا على الأصل مثل بنود الطلب، يمكن أن يكون CASCADE منطقيًا لأن البنود لا معنى لها بدون الوالد.
عندما تولّد النماذج ونقاط النهاية لاحقًا، تصبح هذه القيود متطلبات واضحة: ما الأخطاء التي يجب التعامل معها، ما الحقول المطلوبة، وما حالات الحافة المستحيلة بفعل التصميم.
يجب أن تجيب الفهارس على سؤال واحد: ما الذي يجب أن يكون سريعًا للمستخدمين الحقيقيين؟
ابدأ بالشاشات ونداءات الـ API التي تتوقع شحنها أولًا. صفحة قائمة تُصفى بحسب الحالة وتُرتب بالأحدث لها احتياجات مختلفة عن صفحة تفاصيل تحمل سجلات مرتبطة.
اكتب 5 إلى 10 أنماط استعلام باللغة البسيطة قبل اختيار أي فهرس. مثال: “عرض فواتيري لآخر 30 يومًا، تصفية مدفوع/غير مدفوع، ترتيب بحسب created_at”، أو “فتح مشروع وسرد مهامه بحسب due_date.” هذا يبقي اختيارات الفهارس مرتكزة على الاستخدام الحقيقي.
مجموعة أولية جيدة من الفهارس غالبًا تشمل أعمدة المفاتيح الأجنبية المستخدمة في الانضمام، أعمدة التصفية الشائعة (مثل status, user_id, created_at)، وواحد أو اثنين من الفهارس المركبة لاستعلامات متعددة عوامل ثابتة، مثل (account_id, created_at) عندما تقوم دائمًا بتصفية account_id ثم ترتيب بالزمن.
ترتيب الأعمدة في الفهرس المركب مهم. ضع العمود الذي تُصفى به في معظم الأحيان (والذي هو الأكثر انتقائية) أولًا. إذا كنت تُصفى دائمًا بـ tenant_id، فإن وضعه في بداية كثير من الفهارس غالبًا ما يكون منطقيًا.
تجنّب فهرسة كل شيء “للاحتمال”. كل فهرس يزيد العمل على INSERT و UPDATE، وقد يضر أكثر من بعض الاستعلامات النادرة الأبطأ.
خطط البحث النصي بشكل منفصل. إذا كنت تحتاج فقط مطابقة بسيطة “يحتوي”، قد يكفي ILIKE في البداية. إذا كان البحث جوهريًا، خطط للبحث النصي الكامل (tsvector) مبكرًا حتى لا تضطر لإعادة التصميم لاحقًا.
السكيمة ليست "مكتملة" عندما تنشئ الجداول الأولى. تتغير في كل مرة تضيف ميزة، تصلح خطأ، أو تتعلّم أكثر عن بياناتك. إذا قررت استراتيجية الترحيل مقدمًا، فإنك تتجنب إعادة كتابات مؤلمة بعد توليد الشيفرة.
احتفظ بقاعدة بسيطة: غيّر القاعدة على خطوات صغيرة، ميزة واحدة في كل مرة. يجب أن يكون كل ترحيل سهل المراجعة وآمنًا للتنفيذ في كل بيئة.
معظم الكسر يأتي من إعادة تسمية أو إزالة أعمدة، أو تغيير الأنواع. بدل أن تفعل كل شيء في خطوة واحدة، خطط لمسار آمن:
هذا يأخذ خطوات أكثر، لكنه أسرع عمليًا لأنه يقلل الانقطاعات والتصحيحات الطارئة.
بيانات seed جزء من الترحيلات أيضًا. قرّر أي جداول مرجعية “دائما موجودة” (roles, statuses, countries, plan types) واجعلها متوقعة. ضع إدخالات وتحديثات هذه الجداول في ترحيلات مخصصة حتى يحصل كل مطور وكل نشر على نفس النتائج.
حدد التوقعات مبكرًا:
التراجعات ليست دائمًا "down migration" مثالي. أحيانًا أفضل تراجع هو استعادة من نسخة احتياطية. إذا كنت تستخدم Koder.ai، من المفيد أيضًا تحديد متى تعتمد على اللقطات rollback للتعافي السريع، خصوصًا قبل تغييرات خطرة.
تخيل تطبيق SaaS صغير حيث ينضم الناس إلى فرق، ينشئون مشاريع، ويتتبعون مهام.
ابدأ بسرد الكيانات والحقول التي تحتاجها في اليوم الأول فقط:
العلاقات مباشرة: الفريق يحتوي على مشاريع عديدة، المشروع يحتوي على مهام عديدة، والمستخدمون ينضمون للفرق عبر team_members. المهام تنتمي إلى مشروع وقد تُعيّن لمستخدم.
أضف الآن بعض القيود التي تمنع أخطاء شائعة:
يجب أن تطابق الفهارس الشاشات الحقيقية. على سبيل المثال، إذا كانت قائمة المهام تُصفى بحسب المشروع والحالة وتُرتب بالأحدث، خطط لفهرس مثل tasks (project_id, state, created_at DESC). إذا كانت “مهامي” عرضًا أساسيًا، ففهرس مثل tasks (assignee_user_id, state, due_date) يمكن أن يساعد.
للتريحية، اجعل أول مجموعة من الترحيلات آمنة ومحافظة: إنشاء الجداول، المفاتيح الأساسية، المفاتيح الأجنبية، والقيود الفريدة الأساسية. تغيير جيد للمتابعة هو شيء تضيفه بعد إثبات الاستخدام، مثل إدخال الحذف الناعم (deleted_at) على المهام وتعديل فهارس “المهام النشطة” لتتجاهل الصفوف المحذوفة.
معظم عمليات إعادة الكتابة تحدث لأن السكيمة الأولى تفتقد قواعد وتفاصيل الاستخدام الحقيقية. جولة تخطيط جيدة ليست عن مخططات مثالية، بل عن اكتشاف الفخاخ مبكرًا.
خطأ شائع هو الاحتفاظ بالقواعد المهمة فقط في كود التطبيق. إذا كان يجب أن تكون قيمة فريدة، أو موجودة، أو ضمن نطاق، فيجب أن تفرضها قاعدة البيانات أيضًا. وإلا قد تتجاوز المهمة الخلفية، نقطة نهاية جديدة، أو استيراد يدوي منطقك.
اختيار الفهارس أيضًا يُعتبر غالبًا مشكلة لاحقة. إضافتها بعد الإطلاق غالبًا ما تتحول إلى عملية تخمين، وقد تُفهرس الشيء الخاطئ بينما الاستعلام البطيء الحقيقي هو انضمام أو فلترة على حقل الحالة.
جداول many-to-many مصدر آخر لأخطاء صامتة. إن لم يمنع جدول الربط التكرارات، قد تخزن نفس العلاقة مرتين وتضيّع ساعات في تتبع “لماذا هذا المستخدم لديه دوران؟”.
من السهل أيضًا إنشاء الجداول أولًا ثم تكتشف أنك تحتاج سجلات تدقيق، حذفًا ناعمًا، أو سجل أحداث. هذه الإضافات تتشعب إلى نقاط النهاية والتقارير.
أخيرًا، أعمدة JSON مغرية للبيانات المرنة، لكنها تزيل الضوابط وتجعل الفهارس أصعب. JSON مناسب للحملات المتغيرة حقًا، لا للحقول الأساسية في العمل.
قبل توليد الشيفرة، نفّذ قائمة التحقق السريعة:
توقّف هنا وتأكد أن الخطة كافية لتوليد الشيفرة دون مطاردة المفاجآت. الهدف ليس الكمال، بل التقاط الفجوات التي تسبب إعادة كتابة لاحقًا: علاقات مفقودة، قواعد غير واضحة، وفهارس لا تتطابق مع استخدام التطبيق.
استخدم هذا كفحص سريع قبل الإقلاع:
amount >= 0 أو الحالات المسموح بها).اختبار صحة سريع: تخيل أن زميلًا ينضم غدًا. هل يمكنه بناء النقاط النهاية الأولى دون أن يسأل "هل يمكن أن يكون هذا NULL؟" أو "ماذا يحدث عند الحذف؟" كل ساعة؟
بمجرد أن تُقرأ الخطة بوضوح وتبدو التدفقات الرئيسية منطقية على الورق، حوّلها إلى شيء قابل للتنفيذ: سكيمة حقيقية وترحيلات.
ابدأ بترحيل أولي ينشئ الجداول والأنواع (إن استخدمت enums) والقيود الضرورية. اجعل المحاولة الأولى صغيرة لكنها صحيحة. حمّل بعض بيانات seed وشغّل الاستعلامات التي سيحتاجها التطبيق فعليًا. إذا بدا أي تدفق محرجًا، صحّح السكيمة بينما تاريخ الترحيلات لا يزال قصيرًا.
ولّد النماذج ونقاط النهاية فقط بعد أن تتمكن من اختبار بعض الإجراءات من الطرف إلى الطرف مع السكيمة في المكان (إنشاء، تحديث، قائمة، حذف، بالإضافة إلى إجراء عمل تجاري حقيقي). توليد الشيفرة يكون الأسرع عندما تكون الجداول، المفاتيح، والتسميات مستقرة بما يكفي لئلا تُعيد تسمية كل شيء في اليوم التالي.
حلقة عملية تحافظ على قلة إعادة الكتابة:
قرّر مبكرًا ما الذي تتحقق منه في قاعدة البيانات مقابل طبقة الـ API. ضع القواعد الدائمة في القاعدة (المفاتيح الأجنبية، قيود التفرّد، قيود CHECK). أبقِ القواعد المرنة في الـ API (أعلام المزايا، حدود مؤقتة، منطق عابر للجدول يتغير كثيرًا).
إذا كنت تستخدم Koder.ai، فنهج معقول هو الاتفاق على الكيانات والترحيلات في وضع التخطيط أولًا، ثم توليد الواجهة الخلفية بـ Go وPostgreSQL. عندما ينعكس تغيير ما بشكل خاطئ، تساعد اللقطات والـ rollback على العودة بسرعة إلى إصدار صالح أثناء تعديل خطة السكيمة.
خطّط السكيمة أولاً. إنها تحدد عقدة بيانات مستقرة (الجداول، المفاتيح، القيود) بحيث لا تحتاج النماذج ونقاط النهاية المولّدة إلى إعادة تسمية أو إعادة كتابة مستمرة لاحقًا.
عمليًا: اكتب كياناتك، العلاقات، واستعلاماتك الأكثر أهمية، ثم قف عند القيود والفهارس والترحيلات قبل توليد الشيفرة.
اكتب 2–3 جمل تصف ما يجب أن يتذكره التطبيق وما يجب أن يفعله المستخدمون.
ثم أدرج:
هذا يمنحك وضوحًا كافيًا لتصميم الجداول دون الإفراط في البناء.
ابدأ بسرد الأسماء التي تتكرر (user, project, invoice, task). لكل اسم أضف جملة واحدة: ما هو ولماذا يوجد.
إن لم تستطع وصفه بوضوح، فربما ستنتهي بجداول غامضة مثل items أو misc وتندم لاحقًا.
اعتمد على استراتيجية معرف واحدة ومتسقة عبر السكيمة.
إن احتجت معرفًا سهل القراءة، أضف عمودًا منفصلًا وفريدًا (مثل project_code) بدلًا من جعله المفتاح الأساسي.
قرّر كل علاقة على حدة بناءً على توقعات المستخدمين وما يجب الحفاظ عليه.
افتراضات شائعة:
RESTRICT/NO ACTION عندما يؤدي حذف الأصل إلى محو سجلات مهمة (مثال: customers → orders).CASCADE عندما لا معنى للأبناء بدون الأصل (مثال: order → line items).اتخذ هذا القرار مبكرًا لأن له تأثيرًا مباشرًا على سلوك الـ API وحالات الحافة.
ضع القواعد الدائمة في قاعدة البيانات حتى تُجبر كل كاتب (API، سكربتات، واردات، أدوات إدارية) على الالتزام.
أولوية البداية:
ابدأ من أنماط الاستعلام الحقيقية، لا من التخمين.
اكتب 5–10 استعلامات بالإنجليزية البسيطة (تصف التصفية + الترتيب)، ثم اختر الفهارس بناءً عليها:
status، user_id، created_atاستخدم جدول ربط يحتوي على مفتاحين أجنبيين وقيود فريدة مركبة.
نمط مثال:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) لمنع التكرارهذا يمنع أخطاء صامتة مثل “لماذا يظهر هذا المستخدم مرتين؟” ويبقي الاستعلامات نظيفة.
الافتراضات الجيدة:
timestamptz للطوابع الزمنية (تفاصيل مناطق زمنية أقل مفاجأة)numeric(12,2) أو تخزين السنتات كعدد صحيح للنقود (تجنّب الـ floats)CHECK constraintsحافظ على تناسق الأنواع عبر الجداول حتى تبقى الانضمامات والتحقق متوقعة.
استخدم ترحيلات صغيرة وقابلة للمراجعة وتجنّب تغييرات مدمرة في خطوة واحدة.
مسار آمن:
وقرّر مسبقًا كيفية معالجة بيانات seed/reference حتى تتطابق كل البيئات.
PRIMARY KEY على كل جدولFOREIGN KEY على كل عمود “ينتمي إلى”UNIQUE حيث تسبب التكرارات أذى حقيقيًا (البريد الإلكتروني، (team_id, user_id) في جداول الربط)CHECK لقواعد بسيطة (مبالغ غير سالبة، حالات مسموح بها)NOT NULL للحقول الضرورية لوجود السطر(account_id, created_at))تجنّب فهرسة كل شيء؛ كل فهرس يبطئ INSERT وUPDATE.