09 أغسطس 2025·3 دقيقة
كيف تتسرب تجريدات الأُطر عندما يتوسّع النظام
تعرف لماذا تفشل طبقات التجريد على مستوى الأطر عند التوسّع، أنماط التسريب الشائعة، الأعراض التي يجب مراقبتها، وحلول عملية للتصميم والتشغيل.
تعرف لماذا تفشل طبقات التجريد على مستوى الأطر عند التوسّع، أنماط التسريب الشائعة، الأعراض التي يجب مراقبتها، وحلول عملية للتصميم والتشغيل.
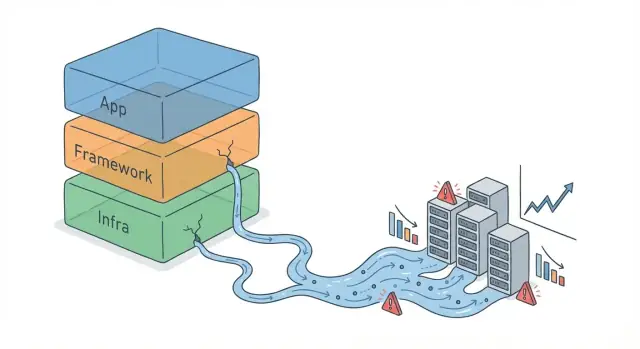
التجريد هو طبقة تبسيط: واجهة إطار عمل، ORM، عميل قائمة انتظار رسائل، أو حتى مساعد كاش مكوّن بسطر واحد. يسمح لك بالتفكير بمفاهيم أعلى مستوى («احفظ هذا الكائن»، «أرسل هذا الحدث») دون معالجة التفاصيل الدنيا باستمرار.
يحدث تسريب التجريد عندما تبدأ تلك التفاصيل المخفية بالتأثير على النتائج الحقيقية على أي حال — فتضطر لفهم وإدارة ما حاول التجريد إخفاءه. الكود لا يزال «يعمل»، لكن النموذج المبسّط لم يعد يتنبأ بالسلوك الحقيقي.
النمو المبكّر متسامح. مع حركة وبيانات قليلة، تخفي الموارد الفارغة الكفاءات الضعيفة: CPU فائض، كاش دافئ، واستعلامات سريعة. نادرًا ما تظهر قفزات زمن الاستجابة، وإعادة المحاولات لا تتكدّس، وسطر لوق بسيط قليل الأهمية.
مع ازدياد الحجم، نفس الاختصارات تتضخّم:
عادة ما تظهر تجريدات متسربة في ثلاث مناطق:
سوف نركّز لاحقًا على الإشارات العملية التي تدل على تسريب التجريد، كيف تشخّص السبب الجذري (ليس الأعراض فقط)، وخيارات التخفيف — من ضبط الإعدادات إلى الهبوط المتعمّد إلى مستوى أدنى عندما لا يعود التجريد مناسبًا لحجمك.
الكثير من البرمجيات تتبع نفس القوس: إثبات مفهوم، إطلاق المنتج، ثم نمو يفوق البنية الأصلية. في البداية، تبدو الأطر سحرية لأن افتراضاتها الافتراضية تتيح الحركة السريعة — التوجيه، الوصول للقاعدة، اللوقينغ، المحاولات، والمهام الخلفية «مجانًا».
عند التوسّع، ترغب في نفس الفوائد — لكن الافتراضات وواجهات الراحة تبدأ بالتصرف كافتراضات ثابتة.
افتراضات الإعدادات الافتراضية في الأطر عادة تفترض:
تظل هذه الافتراضات صحيحة مبكرًا، لذا يبدو التجريد نظيفًا. لكن التوسّع يغيّر معنى «الطبيعي». استعلام صالح على 10,000 صف يصبح بطيئًا على 100 مليون. معالج متزامن بدا بسيطًا يبدأ بالنضوب عند ذروات الحركة. سياسة إعادة محاولة كانت تنجح مع حالات فشل نادرة قد تضخّم الانقطاعات عندما تعيد آلاف العملاء المحاولة دفعةً واحدة.
التوسّع ليس مجرد "مستخدمين أكثر". إنه حجم بيانات أعلى، حركة متفجّرة، والمزيد من الأعمال المتزامنة في نفس الوقت. هذه الأشياء تضغط على أجزاء يخفيها التجريد: مجموعات الاتصالات، جدولة الخيوط، عمق الطوابير، ضغط الذاكرة، حدود I/O، وحدود المعدّل من الاعتمادات.
غالبًا ما تختار الأطر إعدادات آمنة وعامة (أحجام مجموعات، مهلات، سلوك التجميع). تحت الحمل، قد تتحوّل تلك الإعدادات إلى احتكاك، زمن ذيل طويل، وفشل متسلسل — مشكلات لم تكن مرئية عندما كان كل شيء يناسب الهوامش بسهولة.
نادرًا ما تعكس بيئات الاستيجينغ ظروف الإنتاج: مجموعات بيانات أصغر، خدمات أقل، اختلاف سلوك الكاش، ونشاط مستخدمين «أقل فوضى». في الإنتاج لديك أيضًا تقلب شبكي حقيقي، جيران صاخبون، نشرات متدرجة، وفشل جزئي. لهذا السبب قد تتسرّب تجريدات بدت محكمة في الاختبارات عندما تطبق ظروف العالم الحقيقي ضغطًا.
عندما يتسرّب تجريد إطار عمل، نادرًا ما تظهر الأعراض كرسالة خطأ واضحة. بدلًا من ذلك ترى أنماطًا: سلوك كان مناسبًا عند حركة منخفضة يصبح لا يُتنبأ به أو مكلفًا عند حجم أعلى.
غالبًا ما يعلن التجريد المتسرب عن نفسه عبر زمن استجابة مرئي للمستخدم:
هذه علامات كلاسيكية أن التجريد يخفي عنق زجاجة لا يمكنك تخفيفه دون الهبوط إلى مستوى أدنى (مثلاً: فحص الاستعلامات الفعلية، استخدام الاتصالات، أو سلوك الـ I/O).
بعض التسريبات تظهر أولًا في الفواتير بدلاً من لوحات العدادات:
إذا لم يستعد التكبير للبنية الأداء نسبيًا، غالبًا ما لا يكون السبب سعة خام — بل نفقات خفيّة لم تكن تدرك أنك تدفع ثمنها.
تصبح التسريبات مشاكل اعتمادية عندما تتداخل مع المحاولات وسلاسل الاعتمادات:
استخدم هذا للفحص قبل أن تشتري سعة إضافية:
إذا تركزت الأعراض في اعتماد واحد ولم تستجب بشكل متوقع لـ «مزيد من الخوادم»، فهي إشارة قوية أن عليك البحث تحت التجريد.
ORMs رائعة لإزالة البيروقراطية، لكنها تجعل من السهل نسيان أن كل كائن يتحول في النهاية إلى استعلام SQL. عند الحجم الصغير، يبدو هذا المقايضة غير مرئية. عند حجم أعلى، تكون قاعدة البيانات غالبًا المكان الأول الذي يبدأ فيه «التجريد النظيف» بفرض فوائد مقابل تكلفة.
يحدث N+1 عندما تحمل قائمة سجلات أصلية (استعلام واحد) ثم، داخل حلقة، تحمل سجلات مرتبطة لكل أصل (N استعلامات إضافية). في الاختبار المحلي يبدو الأمر مقبولًا — ربما N = 20. في الإنتاج، يصبح N = 2,000، ويحوّل التطبيق هدوءًا طلبًا واحدًا إلى آلاف الرحلات.
الجزء المربك أن لا شيء «ينكسر» فورًا؛ الزمن يترقّق تدريجيًا، مجموعات الاتصالات تمتلئ، وتتكاثر المحاولات الحمل.
التجريدات تشجع غالبًا على جلب كائنات كاملة افتراضيًا، حتى عندما تحتاج حقلين فقط. هذا يزيد I/O والذاكرة ونقل الشبكة.
في الوقت نفسه، قد يولّد ORM استعلامات تتخطى الفهارس التي ظننت أنها مستخدمة (أو التي لم تُنشأ أصلاً). فهرس واحد مفقود قد يحول بحثًا انتقائيًا إلى مسح جدول.
الانضمامات أيضًا تكلفة خفية: ما يبدو كـ "ضمن العلاقة" قد يتحوّل إلى استعلام متعدد الانضمامات بنتائج وسيطة كبيرة.
تحت الحمل، الاتصالات إلى DB مورد نادر. إذا كان كل طلب يتفرع إلى استعلامات متعددة، تضرب المجموعة حدها بسرعة ويبدأ التطبيق بالانتظار.
المعاملات الطويلة (أحيانًا عن طريق الخطأ) يمكن أن تسبب أيضًا احتجاجًا — الأقفال تستمر لفترة أطول، ويتقلّص التزامن.
EXPLAIN، وعامل الفهارس كجزء من تصميم التطبيق — ليس عملًا لاحقًا للـ DBA.تجريد متسرب هو طبقة تحاول إخفاء التعقيد (مثل ORM، مساعدي إعادة المحاولة، أغلفة التخزين المؤقت، الوسائط الوسطية)، لكن تحت الضغط والترافيك الكبير تبدأ التفاصيل المخفية بتغيير النتائج الفعلية.
عمليًا، هو عندما يتوقف «النموذج الذهني البسيط» عن توقع السلوك الحقيقي، وتضطر لفهم أمور مثل خطط الاستعلام، مجموعات الاتصالات، أعماق الطوابير، الـ GC، حدود الوقت وإعادة المحاولات.
الأنظمة المبكِّرة تملك سعة فائضة: جداول صغيرة، تزامن منخفض، كاش دافئ، وتفاعل قليل بين الأخطاء.
مع نمو الحجم، تتحوّل النفقات الصغيرة إلى عنق زجاجة ثابت، وتصبح حواف النطاق النادرة (انتهاء المهلة، فشل جزئي) أمورًا عادية. عندها تظهر التكاليف والقيود الخفيّة للتجريد في سلوك الإنتاج.
ابحث عن أنماط لا تتحسّن متناسبًا عند زيادة الموارد:
التزويد الناقص عادة يتحسّن تقريبًا خطّيًا عند إضافة سعة.
التسريب يظهر عندما:
استخدم قائمة التحقق في المقال: إذا ضربت الموارد ضعفًا ولم يُصلح ذلك النتيجة بشكل متناسب، فاشك في وجود تسريب.
تخفي ORMs أن كل عملية على كائن تتحول في النهاية إلى استعلام SQL. التسريبات الشائعة تشمل:
بدايةً، جرّب التحسينات البسيطة: التحميل المتعجل (eager loading) بحذر، اختيار الأعمدة المطلوبة فقط، التصفّح (pagination)، التجميع الدُفعي، وراجع SQL المولَّد باستخدام EXPLAIN.
مجاميع الاتصالات تحدد السعة القصوى لحماية DB، لكن تشتت الاستعلامات الخفيَّة يمكن أن يستنزف هذه المجموعات بسرعة.
عندما تمتلئ المجموعة، تنتظر الطلبات داخل التطبيق، يزيد زمن الاستجابة وتطول مدة الاحتفاظ بالموارد. المعاملات الطويلة تزيد الطين بلة عبر حبس الأقفال وتقليل التزامن الفعال.
إصلاحات عملية:
نموذج الخيط-لكل-طلب يفشل عندما تستنزف عمليات I/O البطيئة الخيوط؛ كل شيء ينتظر ويزداد الـ latency حتى تنفد الخيوط.
نموذج الـ async/event-loop يفشل بطريقة مختلفة: مكالمة متزامنة واحدة (مكتبة متزامنة، تحليل JSON ثقيل، لوقينغ بطيء) قد توقف الحلقة وتأثر على الجميع. كما يجعل الـ async من السهل فتح تزامن مفرط يختنق فيه مُعتمد خارجي بسرعة.
في كلا النموذجين، يتسرّب تجريد التعامل مع التزامن إلى حاجة صريحة لحدود تزامن، حدود زمن ولفّ الضغط.
الـ backpressure هو آلية لإخبار المستدعي «تمهل؛ لا أستطيع قبول المزيد بأمان».
بدونه، الاعتمادات البطيئة تزيد عدد الطلبات الجارية، استخدام الذاكرة، وأعماق الطوابير—وهذا يجعل الاعتماد أبطأ، مكوِّناً حلقة تغذية راجعة خطيرة.
أدوات شائعة:
إعادة المحاولات التلقائية يمكن أن تحوّل تباطؤًا إلى انقطاع:
طرق التخفيف:
التجهيزات المرصودة تقوم بعمل حقيقي عند الترافيك العالي:
user_id, email, order_id) يمكنها تفجير عدد السلاسل الزمنية وزيادة الذاكرة وتكلفة التخزينضوابط عملية: