تحديد الالتزام باتفاقية مستوى الخدمة وما الذي تبنيه
الالتزام باتفاقية مستوى الخدمة يعني الوفاء بالوعود القابلة للقياس في اتفاقية مستوى الخدمة (SLA) — عقد بين المزود والعميل. مهمة تطبيقك هي الإجابة عن سؤال بسيط مع أدلة: هل لبّينا ما وعدنا به، لهذا العميل، خلال هذه الفترة؟
من المفيد فصل ثلاثة مصطلحات مرتبطة:
- SLI (مؤشر مستوى الخدمة): القياس الخام (مثال: "نسبة الفحوصات الناجحة"، "زمن الرد الأول"، أو "زمن استعادة الخدمة").
- SLO (هدف مستوى الخدمة): هدف داخلي لمؤشر SLI (غالبًا أكثر تشددًا من SLA). مثال: "هدف توفر 99.95%".
- SLA: الالتزام المتفق عليه خارجيًا، وغالبًا مرتبط بخصومات أو عقوبات. مثال: "توفر شهري 99.9%".
المقاييس الشائعة التي ستتتبعها
تبدأ معظم تطبيقات تتبع SLA بمجموعة صغيرة من المقاييس التي ترتبط ببيانات تشغيلية حقيقية:
- التوافر / إمكانية الوصول: نسبة الوقت الذي تكون فيه الخدمة "عاملة" خلال فترة التقرير.
- زمن الاستجابة (الدعم): من إنشاء تذكرة العميل إلى أول رد بشري.
- زمن الحل: من فتح الحادث/التذكرة حتى الإغلاق أو الاستعادة.
- نوافذ التوافر: قواعد مثل "احتساب ساعات العمل فقط"، "استثناء الصيانة المجدولة"، أو "القياس من 08:00–18:00 في توقيت العميل".
من يستخدم التطبيق — ولماذا
مستخدمون مختلفون يريدون نفس الحقيقة، لكن معروضًا بطرق مختلفة:
- العمليات / SRE: كشف الانتهاكات مبكرًا والتحقق من جداول الحوادث.
- فرق الدعم: تتبع التزامات الاستجابة والحل لكل عميل.
- المدراء: رؤية الاتجاهات والمخاطر ومعرفة إن كانت الفرق تلبي الأهداف باستمرار.
- العملاء: الاطلاع على تقارير شفافة (وأحيانًا صفحة حالة) توضح ما حدث.
ما الذي تبنيه (وما الذي لا تبنيه)
هذا المنتج يتعلق بـالتتبع، الإثبات، والتقارير: جمع الإشارات، تطبيق القواعد المتفق عليها، وإنتاج نتائج صالحة للتدقيق. لا يضمن الأداء؛ بل يقيسه — بدقة وباتساق وبشكل يمكنك الدفاع عنه لاحقًا.
المتطلبات: المقاييس، القواعد، ومن يحتاج ماذا
قبل تصميم الجداول أو كتابة الكود، كن دقيقًا جدًا بشأن معنى "الامتثال" بالنسبة لعملك. معظم مشاكل تتبع SLA ليست تقنية — بل مشاكل متعلقة بالمتطلبات.
اجمع المدخلات (ولا تعتمد على الذاكرة)
ابدأ بجمع مصادر الحقيقة:
- عقود العملاء وMSA (بما في ذلك الملاحق وإضافات التذاكر)
- طبقات الخدمة (مثال: Basic مقابل Premium)، وأي العملاء ينتمون لكل طبقة
- ساعات العمل والمناطق الزمنية لكل عميل (أو لكل خدمة)
- الاستثناءات والقواعد الخاصة: نوافذ الصيانة المخطط لها، القوة القاهرة، تأخيرات ناتجة عن العميل، تبعيات طرف ثالث، فترات سماح
اكتب هذه القواعد بشكل صريح. إن لم يمكن صياغة قاعدة بوضوح، فلا يمكن حسابها بشكل موثوق.
قرر ما يجب تتبعه
أدرج "الأشياء" الواقعية التي قد تؤثر في رقم SLA:
- الحوادث/الانقطاعات (بداية، نهاية، الشدة، الخدمات المتأثرة)
- الطلبات/التذاكر (إنشاؤها، الرد الأول، الحل، انتظار العميل)
- الصيانة (مجدولة مقابل طارئة؛ وهل تُحتسب ضد التوافر)
- الانقطاعات الجزئية (تدهور الأداء) وما إذا كان سيتم احتسابها
وحدّد من يحتاج ماذا: الدعم يريد تحذيرًا في الوقت الحقيقي، المدراء يريدون ملخصات أسبوعية، والعملاء يريدون ملخصات بسيطة (وغالبًا صفحة حالة).
اختر 1–3 مقاييس للإصدار الأول
حافظ على نطاق صغير. اختَر الحد الأدنى الذي يثبت أن النظام يعمل من طرف إلى طرف، مثل:
- نسبة التوافر لكل خدمة شهريًا
- زمن استجابة الحوادث (الرد الأول) ضمن ساعات العمل
- زمن الحل للحوادث شديدة الشأن
قائمة مراجعة المتطلبات ومعايير النجاح
أنشئ صفحة واحدة للاختبار لاحقًا:
- تعريفات المقاييس واضحة (طوابع البداية/النهاية، المنطقة الزمنية، التقريب)
- قواعد الإدراج/الاستثناء (الصيانة، انتظار العميل)
- عتبات الأهداف لكل طبقة (مثال: 99.9%، استجابة ساعة واحدة)
- متطلبات الإخراج (تقارير للعملاء، لوحة داخلية، تصدير)
النجاح يعني: شخصان يحسبان نفس الشهر يدويًا والنظام يُطابق النتيجة بالضبط.
نموذج البيانات لـ SLA والخدمات والحوادث والأحداث
متعقب SLA الصحيح يبدأ بنموذج بيانات يشرح لماذا الرقم هو ما هو عليه. إذا لم تستطع تتبع رقم التوافر الشهري وصولًا للأحداث والقواعد المستخدمة، ستواجه نزاعات مع العملاء وغموضًا داخليًا.
الكيانات الأساسية (اجعلها بسيطة وصريحة)
على الأقل، مثّل:
- Customer (tenant/account): يملك الخدمات، التقويمات، جهات الاتصال، وتفضيلات التقارير.
- Service: الشيء المقاس (API، تطبيق ويب، مكونات إقليمية). ضمن علاقة أب/ابن إن كنت ستلخّص مكونات متعددة.
- Plan: غلاف تجاري (مثل "Gold")، يُستخدم لربط مجموعة سياسات SLA افتراضية.
- SLA policy: القواعد القابلة للقياس: هدف التوافر، هدف زمن الاستجابة، نافذة القياس، وما يُعتبر "مستثنى".
- Incident: تجميع سهل القراءة (عنوان، شدة، الجدول الزمني) يُشير للأحداث الأساسية.
- Event: الحقائق الثابتة (تغيرات الحالة، إشارات المراقبة، الإقرارات) التي تُدفع الحسابات.
علاقة مفيدة: customer → service → SLA policy (قد تمر عبر plan). الحوادث والأحداث تشير للخدمة والعميل.
مخطط زمني بسيط للتتبع الزمني
أخطاء الوقت هي السبب الأول لحسابات SLA الخاطئة. خزّن:
occurred_at كـ UTC (طابع زمني مع دلالات المنطقة)received_at (عندما رصدها نظامك)source (اسم المراقبة، التكامل، يدوي)external_id (لمنع الازدواجية عند المحاولات المتكررة)payload (JSON خام للتصحيح المستقبلي)
خزّن أيضًا customer.timezone (سلسلة IANA مثل America/New_York) للعرض ومنطق ساعات العمل، لكن لا تُعدّل وقت الحدث باستخدامه.
ساعات العمل والعطل
إن كانت SLA زمن الاستجابة تتوقف خارج ساعات العمل، مثلّ التقويمات صراحةً:
working_hours لكل عميل (أو لكل منطقة/خدمة): يوم الأسبوع + وقت البداية/النهايةholiday_calendar مرتبط بالمنطقة أو العميل، بنطاقات تاريخية وتسميات
اجعل قواعد التحديث قابلة للبيانات حتى يمكن لفرق العمليات تعديل عطلة دون نشر نسخة جديدة.
القابلية للتدقيق: الخام مقابل المحسوب
خزن الأحداث الخام في جدول قابل للإلحاق فقط، وخزن النتائج المحسوبة منفصلةً (مثال: sla_period_result). يجب أن يتضمن كل صف نتيجة: حدود الفترة، إصدار المدخلات (نسخة السياسة + نسخة المحرك)، ومراجع إلى معرفات الأحداث المستخدمة. هذا يجعل إعادة الحساب آمنة ويعطيك أثر تدقيقي عندما يسأل العملاء: "أي دقائق انقطاع احتسبتم؟"
استيعاب الأحداث: كيف تدخل البيانات لتطبيقك
أرقام SLA جديرة بالثقة بقدر ثقة الأحداث التي تستوعبها. الهدف بسيط: التقط كل تغيير مهم (بدء انقطاع، اعتراف بالحادث، استعادة الخدمة) مع طوابع زمنية ثابتة وسياق كافٍ لحساب الامتثال لاحقًا.
مصادر الأحداث الشائعة
تسحب معظم الفرق من مزيج من الأنظمة:
- أدوات التذاكر/الحوادث (Jira Service Management، ServiceNow، Zendesk): طوابع الإنشاء/الاعتراف/الحل، تغيّرات الأولوية.
- أدوات المراقبة (Pingdom، Datadog، CloudWatch، Prometheus Alertmanager): إشارات up/down، تنبيه fired/cleared، نتائج الفحص الاصطناعي.
- سجلات البنية والتطبيق: أحداث النشر، ارتفاع الأخطاء، فشل فحوصات الصحة.
- إدخالات يدوية: واجهة صغيرة لـ"بدء/إنهاء انقطاع محقق تجاريًا" أو "بدء نافذة صيانة" عندما لا تعرف الأتمتة الحقيقة.
خيارات الاستيعاب (ومتى تستخدم كلًا منها)
Webhooks عادةً الأفضل للدقة في الوقت الحقيقي وحمل أقل: يدفَع النظام المصدر الأحداث إلى نقطة نهاية لديك.
Polling بديل جيد عندما لا تتوافر webhooks: يتيح تطبيقك جلب التغيّرات دوريًا منذ آخر موشر. احتج لتعامل مع حدود المعدل ومنطق "since" بدقة.
CSV import مفيد لملء البيانات التاريخية والهجرات. اعتبره مسار استيعاب أساسيًا حتى تتمكن من إعادة معالجة فترات تاريخية دون حيل.
تنسيق حدث موصى به (مع قابلية عدم التكرار)
وحّد كل شيء إلى شكل "حدث" داخلي واحد، حتى لو اختلفت الحمولات الصادرة:
event_id (مطلوب): فريد ومستقر عبر المحاولات. فضّل GUID المصدر أو أنشئ هاش حتمي.source (مطلوب): مثل datadog, servicenow, manual.event_type (مطلوب): مثل incident_opened, incident_acknowledged, service_down, service_up.occurred_at (مطلوب): وقت حدوث الحدث (ليس وقت الاستلام)، مع دلالة المنطقة الزمنية.received_at (نظام): وقت استيعابه في نظامك.service_id (مطلوب): الخدمة ذات الصلة بالـSLA.incident_id (اختياري ولكنه موصى به): لربط أحداث متعددة بذات الحادث.attributes (اختياري): الأولوية، المنطقة، شريحة العميل، إلخ.
خزن event_id مع قيد فريد لجعل الاستيعاب قابلًا للعدم التكرار: المحاولات المتكررة لن تُنشئ سجلات مكررة.
قواعد التحقق التي تمنع البيانات السيئة
ارفِض أو عزل الأحداث التي:
- تفتقد طوابع زمنية صالحة، أو
occurred_at في المستقبل البعيد
- لا تتطابق مع
service_id معروف (أو اجعلها تتبع مسار "غير مطابقة")
- تكرر
event_id موجودًا بالفعل
- تصل خارج الترتيب بحيث تكسر قواعدك (احتفظ بها لكن وسّمها "تحتاج مراجعة" بدلًا من استبدالها بصمت)
هذه الدقة في البداية توفر عليك جدالًا حول تقارير الـSLA لاحقًا—لأنك ستكون قادرًا على الإشارة إلى مدخلات نظيفة وقابلة للتتبع.
محرك حسابات SLA: تحويل الأحداث إلى امتثال
محرك الحساب هو المكان الذي تتحول فيه "الأحداث الخام" إلى نتائج SLA يمكن الدفاع عنها. المفتاح هو التعامل معه كالمحاسبة: قواعد حتمية، مدخلات واضحة، وسجل قابل للإعادة.
ابدأ بخط زمني مُوحد
حوّل كل شيء إلى تيار مرتب واحد لكل حادث (أو لكل أثر خدمة):
- طوابع زمنية (UTC) لـ: بدأ الحادث، الاعتراف/الرد الأول، التخفيف، الحل، إعادة الفتح
- تغيرات الحالة: إيقاف/استئناف، انتظار العميل، تفعيل نافذة صيانة
- النطاق: أي خدمة(خدمات) وعميل(عملاء) تضرروا وبأي شدة
من هذا الخط الزمني، احسب المدد بجمع الفترات، لا بطرح طابعين بصورة عشوائية.
زمن الاستجابة الأولي (TTFR) وزمن الحل (TTR)
عرّف TTFR كزمن "قابل للاحتساب" من incident_start إلى first_agent_response (أو acknowledged بحسب صياغة SLA). عرّف TTR كزمن "قابل للاحتساب" من incident_start إلى resolved.
"قابل للاحتساب" يعني إزالة الفترات التي لا تُحتسب:
- خارج ساعات العمل (إذا كانت SLA ضمن ساعات العمل)
- الإيقافات الصريحة (مثال: "انتظار العميل")
- الاستثناءات مثل الصيانة المجدولة أو تأخيرات الطرف الثالث
تفصيل تنفيذي: خزّن دالة التقويم (ساعات العمل، العطل) ودالة القواعد التي تأخذ الخط الزمني وتُرجع الفترات المحتسبة.
الانقطاعات الجزئية وحوادث متعددة الخدمات
قرّر مُسبقًا إن كنت ستحسب:
- SLA لكل خدمة (موصى به): حادث واحد قد يُنتج سجلات تأثير متعددة لكل خدمة، كل منها مع TTFR/TTR خاص بها
- SLA لكل عميل: نفس الانقطاع قد يؤثر على مجموعة فرعية من المستخدمين فقط
للانقطاعات الجزئية، زِن التأثير فقط إذا طلب العقد ذلك؛ وإلا اعتبر "تدهور" فئة انتهاك منفصلة.
القابلية للتتبع: خزّن المدخلات والمخرجات وإمكانية الإعادة
يجب أن يكون كل حساب قابلاً لإعادة الإنتاج. خزّن:
- الأحداث الدقيقة المستخدمة (مع المعرفات والطوابع الزمنية والمصدر)
- الفترات المشتقة (ما اُستثني ولماذا)
- النتائج النهائية (TTFR، TTR، أعلام الانتهاك، وإصدار القاعدة)
عندما تتغير القواعد، يمكنك إعادة تشغيل الحسابات حسب الإصدار بدون إعادة كتابة التاريخ — وهذا مهم للمراجعات ونزاعات العملاء.
منطق التقارير: الفترات، التوافر، وحالات الحافة
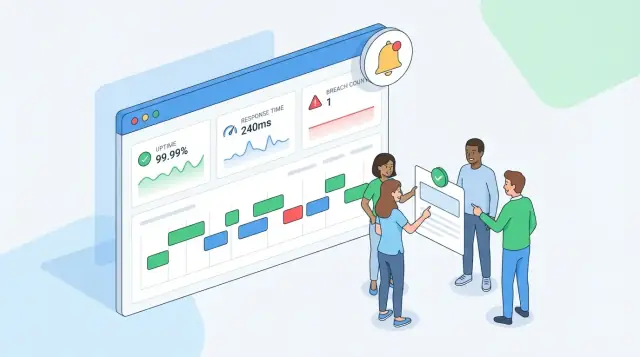
لوحة React مضمّنة
احصل على لوحة React مع باكاند Go وPostgreSQL في بناء واحد.
التقارير هي المكان الذي يكسب فيه تتبع SLA الثقة—أو يثير الأسئلة. يجب أن يجعل تطبيقك واضحًا ما النطاق الزمني المقاس، أي الدقائق اُحتسبت، وكيف تشكلت الأرقام النهائية.
الفترات: تقويمية، فواتير، ونوافذ متحركة
ادعم فترات التقرير الشائعة:
- شهر/ربع تقويمي (مثال: 1–31 مارس)
- دورات الفوترة (مثال: 15–14، متوافقة مع الفواتير)
- نوافذ متحركة (مثال: "آخر 30 يومًا" مُحدّثة يوميًا)
خزن الفترات كبدايات/نهايات واضحة (طوابع زمنية) حتى يمكنك إعادة تشغيل الحسابات لاحقًا وشرح النتائج.
التوافر: إجمالي الدقائق مقابل الدقائق المؤهلة
مصدر ارتباك شائع هو ما إذا كان المقام قسمة على كامل الفترة أو فقط "الوقت المؤهل".
عرّف قيمتين لكل فترة:
- الدقائق المؤهلة: الدقائق التي تُحتسب تجاه SLA (غالبًا تستثني الصيانة المخططة وتأخيرات العميل أو أوقات خارج الدعم)
- دقائق التوقف: دقائق مؤهلة حيث تعتبر الخدمة متوقفة
ثم احسب:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
إذا كانت الدقائق المؤهلة صفرًا (مثال: خدمة تُراقب فقط خلال ساعات العمل والفترة لا تحتوي ساعات)، عرّف القاعدة مقدمًا: إما "N/A" أو اعتبرها 100% — لكن كن متسقًا ووثّق ذلك.
تحويل الأرقام إلى نتيجة نجاح/فشل واضحة
معظم العقود تحتاج إلى نسبة ونتيجة ثنائية:
- النسبة: مثال 99.95% للفترة
- نجاح/فشل: قارنها بهدف الـSLA (مثال: اجتياز إذا ≥ 99.9%)
وخزّن أيضًا "المسافة إلى الانتهاك" (ميزانية التوقف المتبقية) حتى تُحذر اللوحات قبل عبور العتبة.
حالات الحافة التي يجب معالجتها بوضوح
- المناطق الزمنية: اختر منطقة تقارير لكل عميل/عقد (غالبًا منطقة العميل) وحوّل الأحداث بشكل متناسق.
- التوقيت الصيفي: لا تفترض أن اليوم فيه 1440 دقيقة — استخدم طوابع زمنية واعية بالمنطقة حتى تكون طول الفترة صحيحًا عند التحويل الصيفي.
- نهايات مفقودة: أحيانًا لا يوجد طابع "مُحلّ" للحادث. اعتبرها "مفتوحة" وحدّها عند نهاية التقرير، مع وسم للسجلات للتنظيف.
وفي الختام، احتفظ بالمدخلات الخام (الأحداث المضمنة/المستبعدة والتعديلات) حتى يمكن لكل تقرير أن يجيب على "لماذا هذا الرقم؟" دون تهويم.
واجهة المستخدم واللوحات التي توضح حالة SLA فورًا
محرك الحساب قد يكون مثاليًا ومع ذلك يفشل المستخدمون إذا لم تجب الواجهة عن السؤال الأساسي فورًا: "هل نفيّ بالـSLA الآن، ولماذا؟" صمّم التطبيق لتبدأ كل شاشة بحالة واضحة، ثم تتيح الحفر إلى الأرقام والأحداث الخام التي أنتجتها.
طرق العرض الرئيسية للبناء
لوحة نظرة عامة (للعمليات والمدراء). قدّم بلاطات صغيرة: امتثال الفترة الحالية، التوافر، امتثال زمن الاستجابة، و"الوقت المتبقي قبل الانتهاك" حيثما ينطبق. ضع تسميات صريحة.
تفاصيل العميل (لفِرق الحسابات والتقارير الموجهة للعملاء). صفحة العميل تجمع كل الخدمات وطبقات SLA الخاصة به، مع حالة بسيطة ناجح/تحذير/فشل وشرح قصير ("حاصلتان؛ 18 دقيقة توقف محتسبة"). أضف روابط إلى /status وتصدير التقارير.
تفاصيل الخدمة (للبحث العميق). اعرض قواعد SLA الدقيقة، نافذة الحساب، وتفصيل كيفية تشكيل رقم الامتثال. أضف رسمًا زمنيًا للتوافر وقائمة الحوادث المحتسبة.
خط زمني الحادث (للمراجعات). اعرض حدثًا واحدًا مع تسلسل الأحداث (اكتشاف، اعتراف، تخفيف، حل) والطوابع المستخدمة لمقاييس الرد والحل.
عوامل تصفية تطابق الأسئلة الحقيقية
اجعل عوامل التصفية متسقة عبر الشاشات: نطاق التاريخ، العميل، الخدمة، الطبقة، والشدة. استخدم نفس الوحدات في كل الأماكن (دقائق مقابل ثوانٍ؛ نسب بنفس عدد الكسور). عند تغير نطاق التاريخ حدّث كل مقياس في الصفحة.
الحفر دون فقدان الثقة
كل مقياس ملخّص يجب أن يحتوي مسار "لماذا؟":
- من النسبة → قائمة الحوادث المحتسبة في تلك الفترة
- من الحادث → الأحداث الخام والفترات المشتقة المستخدمة
- من التوافر → فترات التوقف مع المصادر (حدث مراقبة مقابل تعديل يدوي)
استخدم تلميحات مقتضبة لشرح مصطلحات مثل "دقائق مستبعدة" أو "ساعات العمل"، وأظهر نص القاعدة الكامل على صفحة الخدمة حتى لا يخمن الناس.
اجعلها بسيطة وواضحة
فضّل اللغة العادية على الاختصارات. لعرض الحالة، اجمع اللون مع تسميات نصية ("خطر: استُخدِم 92% من ميزانية الأخطاء") لتجنب اللبس. إن وفر التطبيق سجلات تدقيق، أضف مربعًا صغيرًا "آخر تغيير" على قواعد SLA والروابط إلى /audit لتمكين التحقق.
التنبيه والإشعارات عند الانتهاكات
انطلق سريعًا
انشر واستضف تطبيق SLA، ثم أضف نطاقًا مخصصًا عند جاهزيته.
التنبيه هو حيث يتوقف تطبيق تتبع SLA عن كونه تقريرًا سلبيًا ويصبح أداة لمساعدة الفرق على تجنب العقوبات. أفضل التنبيهات في الوقت المناسب ومحددة وقابلة للتنفيذ — تخبر من يجب أن يفعل ماذا بعد، لا تُشير فقط إلى أن "الأمر سيء".
عرّف محفزات تنبيه تتوافق مع القرارات الواقعية
ابدأ بثلاثة أنواع من المحفزات:
- الاقتراب من الانتهاك: مثال: "تبقّى 30 دقيقة للالتزام بزمن الاستجابة" أو "التوافر هذا الشهر وصل 99.92% والـSLA 99.9%". هذا النوع الأكثر قيمة لأنه يمكّن من التعافي.
- حدوث الانتهاك: يُطلق عند تأكيد المحرك أن الـSLA لم يُلبى للفترة المعنية.
- انتهاكات متكررة: اكتشف أنماطًا مثل "3 انتهاكات خلال 30 يومًا" أو "نفس الخدمة خالفت مرتين هذا الأسبوع".
اجعل المحفزات قابلة للتخصيص لكل عميل/خدمة/SLA.
اختر القنوات واعمِل على جعل الرسائل قابلة للتنفيذ
أرسل التنبيهات حيث يستجيب الناس فعليًا:
- البريد الإلكتروني للإشعارات الملائمة للتدقيق وأصحاب المصلحة الخارجيين.
- Slack للتنسيق الداخلي السريع.
- SMS (اختياري) للتصعيدات عالية الشدة.
كل تنبيه يجب أن يتضمن روابط عميقة مثل /alerts، /customers/{id}، /services/{id} وصفحة الحادث أو الحدث لتمكين المجيبين من التحقق السريع من الأرقام.
تقليل الضوضاء: عدم التكرار، ساعات الهدوء، والتصعيد
نفّذ عدم تكرار بتجميع التنبيهات بالمفتاح نفسه (عميل + خدمة + SLA + فترة) وكبت التكرارات لنقطة تبريد محددة.
أضف ساعات هدوء بحسب منطقة فريق العمل حتى تنتظر التنبيهات غير الحرجة ساعات العمل، بينما يمكن لـ"الانتهاك الحاصل" تجاوز ساعات الهدوء إن كانت الشدة عالية.
أخيرًا، ادعم قواعد التصعيد (مثال: إشعار المعاون بعد 10 دقائق، تصعيد للمدير بعد 30) لمنع تكدس التنبيهات في صندوق واحد.
التحكم في الوصول، المصادقة، وسجلات التدقيق
بيانات SLA حساسة لأنها تكشف أداء داخلي وامتيازات خاصة بالعملاء. عامل التحكم في الوصول كجزء من "قواعد الحساب": نفس الحادث قد يعطي نتائج امتثال مختلفة بحسب SLA المطبقة لذلك العميل.
الأدوار التي يجب دعمها من اليوم الأول
احتفظ بالأدوار بسيطة ثم توسع تدريجيًا:
- مسؤول (Admin): يهيئ الإعدادات العامة، يدير الخدمات، السياسات، المستخدمين، التكاملات والفوترة.
- وكيل (Agent): ينشئ/يحدّث الحوادث ونوافذ الصيانة، يرفق الأحداث ويضيف ملاحظات ما بعد الحادث.
- مدير (Manager): يقرأ كل شيء في نطاقه، يوافق على تعريفات SLA، ويصدر تقارير.
- مشاهد العميل: يرى خدماته فقط، أهداف الـSLA، تاريخ الحوادث، والتقارير الموجهة للعميل.
افتراض عملي: RBAC + نطاق المستأجر — كل سجل له مالك tenant. المستخدمون الداخليون قد يكونون مقيدين لعدة مستأجرين؛ مشاهدو العملاء لمستأجر واحد فقط.
ما يمكن لكل دور رؤيته/تعديله
كن صريحًا بشأن البيانات الخاصة بالعملاء:
- لا ينبغي لمشاهد العميل أن يرى الحقول الداخلية الخاصة (افتراضات السبب الجذري، الشدة الداخلية، ملاحظات النداء، الوسوم الخاصة).
- يجب إصدار نسخ من سياسات SLA حتى يرى العميل شروط الـSLA المطبقة في وقت الحادث.
خيارات المصادقة التي لا تُسبب قيودًا لاحقًا
ابدأ بـالبريد/كلمة المرور واطلب MFA للأدوار الداخلية. خطط لدعم SSO لاحقًا (SAML/OIDC) عبر فصل الهوية عن التفويض. للتكاملات، أصدر مفاتيح API مربوطة بحساب خدمة بنطاق ضيق وإمكانية تدوير.
سجلات التدقيق التي ستشكرك لاحقًا
أضف إدخالات تدقيق غير قابلة للتعديل لـ:
- تغييرات قواعد SLA (العتبات، الجداول، الاستثناءات، الربط بالخدمات/العملاء)
- تعديلات الحوادث (الطوابع، انتقالات الحالة، تجاوزات التوقف اليدوية)
- تغييرات الصلاحيات ومفاتيح API
خزن من، ما الذي تغيّر (قبل/بعد)، متى، أين (IP/وكيل المستخدم)، ومعرّف الارتباط. اجعل سجلات التدقيق قابلة للبحث والتصدير (مثال: /settings/audit-log).
تصميم API للتكاملات والأتمتة
نادراً ما يكون تطبيق تتبع SLA منعزلًا. ستحتاج API يسمح لأدوات المراقبة، أنظمة التذاكر، وتدفقات العمل الداخلية بإنشاء الحوادث، دفع الأحداث، وسحب التقارير برمجيًا.
ابدأ بواجهة صغيرة ومتوقعة
استخدم مسارًا مُنسخًا بالإصدار (مثال: /api/v1/...) حتى تتمكن من تطور الحمولات دون كسر التكاملات.
نقاط نهاية أساسية تغطي معظم الحالات:
- الأحداث:
POST /api/v1/events لاستيعاب تغيّرات الحالة. GET /api/v1/events للتدقيق والتصحيح.
- الحوادث:
POST /api/v1/incidents, PATCH /api/v1/incidents/{id} (للاعتراف، الحل، التعيين), GET /api/v1/incidents.
- SLA:
GET /api/v1/slas, POST /api/v1/slas, PUT /api/v1/slas/{id} لإدارة العقود والعتبات.
- التقارير:
GET /api/v1/reports/sla?service_id=...&from=...&to=... لملخصات الامتثال.
- التنبيهات:
POST /api/v1/alerts/subscriptions لإدارة الويبهوكس/البريد؛ GET /api/v1/alerts لسجل التنبيهات.
اجعل التصفح والتصفية متسقين
اختر اصطلاحًا واحدًا واستخدمه في كل مكان: مثالًا limit مع صفحات مؤشرية (cursor)، وفلاتر قياسية مثل service_id, sla_id, status, from, to. حافظ على الفرز متوقعًا (مثال: sort=-created_at).
عرّف استجابات الأخطاء التي يعتمد عليها المدمجون
أعد أخطاء منظمة بحقول ثابتة:
{ "error": { "code": "VALIDATION_ERROR", "message": "service_id is required", "fields": { "service_id": "missing" } } }
استخدم حالات HTTP واضحة (400 صحة، 401/403 مصادقة/تفويض، 404 غير موجود، 409 تعارض، 429 حد المعدل). لأجل استيعاب الأحداث، فكّر في قابلية عدم التكرار (Idempotency-Key) حتى لا تُضاعف المحاولات الحوادث.
حدود المعدل والأساسيات الأمنية
طبق حدود معقولة لكل رمز (وحدود أشد لنقاط الاستيعاب)، طهّر المدخلات، وحقّق الطوابع الزمنية/المناطق الزمنية. فضّل رموز API بمدى ضيق (قراءة تقارير مقابل كتابة حوادث)، وسجل دائمًا من استدعى أي نقطة نهاية للتتبع (تفاصيل في قسم سجلات التدقيق على /blog/audit-logs).
استراتيجية الاختبار: أثبت أن الأرقام صحيحة
أطلق MVP بسيط لـSLA
أنشئ النسخة الأولى مع وقت التشغيل، TTFR، وTTR لخدمة واحدة.
أرقام SLA مفيدة فقط إذا وثق بها الناس. اختبارات تطبيق تتبع SLA يجب أن تركز أقل على "هل الصفحة تحمّلت" وأكثر على "هل حسابات الزمن تتصرف بدقة طبقًا للعقد؟" عامل قواعد الحساب كمِيزة منتج مع مجموعة اختبارات خاصة بها.
اختبر القواعد بالوحدات بزمن ثابت
ابدأ باختبار وحدات لمحرك الحساب مع مدخلات حتمية: خط زمني لأحداث (فتح الحادث، الاعتراف، التخفيف، الحل) ومجموعة قواعد SLA مُحددة بوضوح.
استخدم طوابع زمنية ثابتة و"تجميد الوقت" حتى لا تعتمد اختباراتك على الساعة الحقيقية. غطِ حالات الحافة:
- حادث يبدأ قبل فترة التقرير وينتهي داخلها
- حوادث متداخلة (هل تُدمج دقائق التوقف أم تتراكم؟)
- عدة إيقافات (صيانة، انتظار العميل)
- دقائق/ثواني على الحدود (تمامًا عند 00:00، نهاية الشهر، يوم كبيس)
اختبارات شاملة للنهاية إلى النهاية
أضف مجموعة صغيرة من اختبارات E2E التي تشغّل التدفق الكامل: استيعاب الأحداث → حساب الامتثال → توليد التقرير → عرض الواجهة. هذه تختبر التوافق بين ما حسبه المحرك وما عرضه اللوحة. احتفظ بالسيناريوهات قليلة لكنها عالية القيمة، وفرض التأكد من الأرقام النهائية.
أنشئ قواعد جاهزة لإعادة الاستخدام للتقويمات والمناطق الزمنية
ابتكر قوالب اختبار لساعات العمل، العطل، والمناطق الزمنية. تريد حالات قابلة للتكرار مثل "يحدث الحادث الجمعة 17:55 بتوقيت محلي" و"العطلة تؤثر على حساب زمن الاستجابة".
راقب تطبيق SLA نفسه
الاختبار لا يتوقف عند النشر. أضف مراقبة لأخطاء الوظائف، حجم الطوابير، مدة إعادة الحساب، ومعدلات الخطأ. إذا تأخر الاستيعاب أو فشل مهمة ليلية، فقد يكون تقرير SLA خاطئًا حتى لو كان الكود صحيحًا.
النشر والعمليات وخارطة طريق MVP عملية
إطلاق تطبيق تتبع SLA أقل ما يكون عن بنية تحتية فاخرة وأكثر ما يكون عن عمليات متوقعة: حساباتك يجب أن تعمل في الوقت المناسب، بياناتك يجب أن تكون آمنة، والتقارير قابلة لإعادة الإنتاج.
مسار نشر بسيط وموثوق
ابدأ بخدمات مُدارة حتى تركز على الصحة الحسابية:
- قاعدة بيانات مُدارة (PostgreSQL): نسخ احتياطي آلي، استرداد نقطة زمنية، تشفير.
- استضافة حاويات للتطبيق/الـAPI (منصة حاويات مُدارة): استرجاع سريع للنسخ وبيئات متسقة.
- تخزين كائني للصادرات (CSV/PDF) وقطع كبيرة، مع قواعد دورة حياة.
حافظ على بيئات قليلة: dev → staging → prod، كل منها بقاعدة بيانات وسرية خاصة.
مهام خلفية تحتاجها من اليوم الأول
تتبع SLA ليس طلب/استجابة فقط؛ يعتمد على أعمال مجدولة:
- مهام الحساب: إعادة حساب نوافذ SLA عند ورود أحداث جديدة، وإعادة التشغيل عند ورود بيانات متأخرة.
- توليد التقارير: ملخصات يومية/شهرية، تصديرات جاهزة للعملاء.
- نظافة البيانات: أرشفة الأحداث القديمة، ضغط الجداول المشتقة، التحقق من سلامة المراجع.
شغّل المهام عبر عامل + طابور، أو مجدول مُدار يستدعي واجهات داخلية. اجعل المهام قابلية الإعادة وآمنة لإعادة المحاولة وسجّل كل تشغيل للتدقيق.
الاحتفاظ والتصديرات (دون مبالغة)
حدّد الاحتفاظ حسب نوع البيانات: احتفظ بالنتائج المشتقة لفترة أطول من أحداث الخام. للصدارات، قدّم CSV أولًا (سريع وشفاف)، ثم قوالب PDF لاحقًا. كن واضحًا: التصديرات تنسيق "بأفضل جهد"، بينما تظل قاعدة البيانات مصدر الحقيقة.
خارطة طريق مرحلية للحفاظ على نطاق ضيق
- MVP: خدمة واحدة، SLA واحدة، منطقة زمنية واحدة، لوحة أساسية + تقرير شهري.
- مزيد من المقاييس: SLA زمن الاستجابة، نوافذ الصيانة، الاستثناءات، عدة جداول زمنية.
- بوابة العملاء: عروض لكل عميل، التحكم في الوصول، تقارير قابلة للتنزيل.
- صفحة الحالة: صفحات عامة/خاصة مدعومة بالتوافر المحسوب (انظر /blog/status-pages).
تسريع النمذجة مع Koder.ai (اختياري)
إذا أردت التحقق سريعًا من نموذج البيانات، تدفق الاستيعاب، وواجهة التقارير، يمكن لمنصات توليد التطبيقات مثل Koder.ai مساعدتك في الوصول لنموذج عمل أولي بدون دورة هندسة كاملة. لأن Koder.ai يولد تطبيقات كاملة عبر المحادثة (واجهة ويب + باكند)، فهو طريقة عملية لابتكار:
- لوحة React لعرض الامتثال وميزانية الأخطاء وخطوط الأحداث،
- باكند Go + PostgreSQL لتخزين الأحداث والنتائج الدورية،
- نقاط نهاية للتصدير وتقارير العميل.
بمجرد إثبات المتطلبات والحسابات (الجزء الصعب)، يمكنك التقدم، تصدير الشيفرة، والانتقال لبناء وتشغيل تقليدي—مع الحفاظ على ميزات مثل لقطات واسترداد أثناء التكرار السريع.