04 أبريل 2025·8 دقيقة
كيفية بناء تطبيق ويب لتتبع موثوقية الأدوات الداخلية
تعلم كيف تصمم وتبني تطبيق ويب يتتبع موثوقية الأدوات الداخلية باستخدام SLIs/SLOs، سير عمل للحوادث، لوحات، تنبيهات، وتقارير.
تعلم كيف تصمم وتبني تطبيق ويب يتتبع موثوقية الأدوات الداخلية باستخدام SLIs/SLOs، سير عمل للحوادث، لوحات، تنبيهات، وتقارير.
قبل اختيار المقاييس أو بناء اللوحات، قرر ما الذي سيتحمل مسؤوليته تطبيق الموثوقية — وما الذي لن يكون ضمنه. نطاق واضح يمنع من أن يتحول التطبيق إلى «بوابة عمليات» شاملة لا يثق بها أحد.
ابدأ بسرد الأدوات الداخلية التي سيغطيها التطبيق (مثل: نظم التذاكر، الرواتب، تكاملات CRM، خطوط بيانات) والفرق التي تمتلكها أو تعتمد عليها. كن صريحًا بشأن الحدود: «موقع الويب الموجه للعملاء» قد يكون خارج النطاق، بينما «وحدة إدارة داخلية» هي ضمنه.
تستخدم المنظمات الكلمة بطرق مختلفة. اكتب تعريف العمل بلغة بسيطة — عادة مزيج من:
إذا اختلفت الفرق، سيتحول التطبيق إلى مقارنة تفاحات مع برتقالات.
اختر 1–3 نتائج رئيسية، مثل:
هذه النتائج ستوجه لاحقًا ما الذي تقيسه وكيف تعرضه.
سرد من سيستخدم التطبيق وما القرارات التي يتخذونها: مهندسون يحققون في الحوادث، دعم يصعد القضايا، مديرون يراجعون الاتجاهات، وأصحاب مصلحة يحتاجون تحديثات الحالة. هذا سيشكل المصطلحات، الأذونات، ومستوى التفاصيل في كل عرض.
يتوقف تتبع الموثوقية على اتفاق الجميع على معنى "الجيد". ابدأ بفصل ثلاثة مصطلحات متشابهة الصوت.
SLI (مؤشر مستوى الخدمة) هو قياس: "ما نسبة الطلبات الناجحة؟" أو "كم استغرق تحميل الصفحات؟"
SLO (هدف مستوى الخدمة) هو الهدف لذلك القياس: "99.9% نجاح خلال 30 يومًا."
SLA (اتفاقية مستوى الخدمة) هي وعد مع عواقب، غالبًا موجهة للخارج (تعويضات، غرامات). للأدوات الداخلية، ستضع غالبًا SLOs بدون SLAs رسمية — كافية لمواءمة التوقعات دون تحويل الموثوقية إلى قانون تعاقدي.
اجعلها قابلة للمقارنة عبر الأدوات وسهلة الشرح. أساس عملي قد يكون:
تجنب الإضافة حتى تستطيع الإجابة: "أي قرار ستدفعه هذه المقاييس؟"
استخدم نوافذ متدحرجة حتى تتحدث بطاقات الأداء باستمرار:
يجب أن يحول تطبيقك المقاييس إلى فعل. عرّف مستويات الشدة (مثلاً Sev1–Sev3) ومحفزات صريحة مثل:
هذه التعاريف تجعل التنبيه والجداول الزمنية للحوادث وتتبع ميزانية الأخطاء متسقة عبر الفرق.
تطبيق تتبع الموثوقية موثوق بقدر جودة البيانات تحته. قبل بناء خطوط استيعاب، خرّط كل إشارة ستعتبرها "حقيقة" واكتب السؤال الذي تجيب عليه (التوافر، الكمون، الأخطاء، تأثير النشر، استجابة الحادث).
يمكن لمعظم الفرق تغطية الأساسيات باستخدام مزيج من:
كن صريحًا بشأن أي الأنظمة هي الموثوقة. على سبيل المثال، قد يأتي "SLI التوافر" فقط من الفحوص الاصطناعية، لا من سجلات الخادم.
حدد تردد التحديث حسب الاستخدام: قد تُحدّث لوحات المعلومات كل 1–5 دقائق، بينما تُحسب بطاقات الأداء كل ساعة/يوم.
أوجد معرفات متسقة للأدوات/الخدمات، البيئات (prod/stage)، والمالكين. اتفق على قواعد التسمية مبكرًا حتى لا تصبح "Payments-API" و"payments_api" و"payments" كيانات منفصلة.
خطّط ما الذي تحتفظ به وكم من الوقت (مثلاً: الأحداث الخام 30–90 يومًا، التجميعات اليومية 12–24 شهرًا). تجنّب استيعاب حمولات حساسة؛ خزّن فقط البيانات الوصفية اللازمة لتحليل الموثوقية (طوابع زمنية، رموز الحالة، دلائل الكمون، علامات الحوادث).
يجب أن يجعل مخططك شيئين سهلا: الإجابة على أسئلة اليوم‑يومي ("هل هذه الأداة صحية؟") وإعادة بناء ما حدث خلال حادث ("متى بدأت الأعراض، من غيّر ماذا، أي تنبيهات ظهرت؟"). ابدأ بمجموعة صغيرة من الكيانات الأساسية واجعل العلاقات صريحة.
قاعدة عملية قد تكون:
هذا الهيكل يدعم اللوحات ("الأداة → الحالة الحالية → الحوادث الأخيرة") والتفاصيل ("الحادث → الأحداث → الفحوص والمقاييس المرتبطة").
أضف حقول تدقيق حيثما تحتاج للمسائلة والتاريخ:
created_by, created_at, updated_atstatus بالإضافة إلى تتبع تغيير الحالة (في جدول Event أو جدول تاريخي مخصص)أخيرًا، أدرج وسومًا مرنة للتصفية والتقارير (مثلاً: الفريق، الأهمية، النظام، الامتثال). جدول ربط tool_tags (tool_id, key, value) يبقي الوسم متسقًا ويسهّل حسابات الملخصات لاحقًا.
يجب أن يكون متتبع الموثوقية مملًا بأفضل معنى: سهل التشغيل، سهل التغيير، وسهل الدعم. "التكديس الصحيح" غالبًا ما يكون ما تستطيع فريقك صيانته دون بطولات.
اختر إطار ويب شائع يعرفه فريقك — Node/Express أو Django أو Rails كلها خيارات جيدة. أعط أولوية ل:
إذا كنت تدمج مع أنظمة داخلية (SSO، التذاكر، الدردشة)، اختر النظام البيئي الذي تسهُل فيه هذه التكاملات.
إذا أردت تسريع النسخة الأولى، منصة "vibe-coding" مثل Koder.ai يمكن أن تكون نقطة انطلاق عملية: تصف الكيانات (أدوات، فحوص، SLOs، حوادث)، تدفقات العمل (تنبيه → حادث → تحليل بعد الحادث)، ولوحات المعلومات في الدردشة، ثم تولد هيكل تطبيق ويب جاهز بسرعة. لأن Koder.ai غالبًا ما تستهدف React في الواجهة وGo + PostgreSQL في الخلفية، فهي تتناسب جيدًا مع التكديس الافتراضي "الممل والقابل للصيانة"—ويمكنك تصدير الشيفرة المصدرية لاحقًا إذا انتقلت إلى خط أنابيب يدوي بالكامل.
لأغلب تطبيقات الموثوقية الداخلية، PostgreSQL هو الافتراضي المناسب: يدير التقارير العلائقية، استعلامات الزمن، والتدقيق جيدًا.
أضف مكونات إضافية فقط عندما تحل مشكلة حقيقية:
قرر بين:
أيًا كان خيارك، طوّر بيئات dev/staging/prod وأتمت النشر (CI/CD)، حتى لا تغيّر التحديثات أرقام الموثوقية بصمت. إذا استخدمت نهج منصة (بما في ذلك Koder.ai)، ابحث عن ميزات فصل البيئات، الاستضافة، والاسترجاع السريع (snapshots) حتى تتمكن من التجريب بأمان.
وثق التكوين في مكان واحد: متغيرات البيئة، الأسرار، وأعلام الميزات. احتفظ بدليل "كيفية التشغيل محليًا" وورقة تشغيل مختصرة (ماذا تفعل إذا توقف الاستيعاب، تراكم الطابور، أو امتلأت قاعدة البيانات). صفحة قصيرة في /docs غالبًا ما تكون كافية.
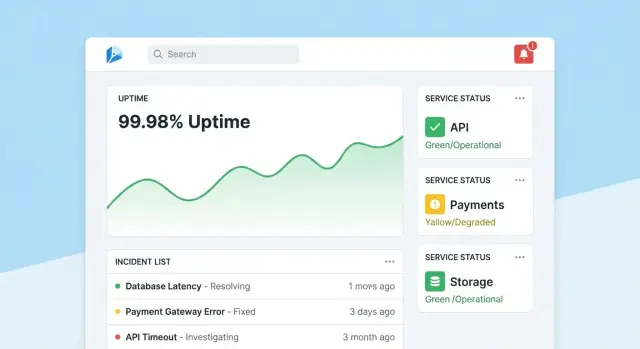
ينجح تطبيق تتبع الموثوقية عندما يستطيع الناس الإجابة عن سؤالين في ثوانٍ: "هل نحن بخير؟" و"ماذا أفعل بعد ذلك؟" صمّم الشاشات حول تلك القرارات، مع تنقّل واضح من النظرة العامة → أداة محددة → حادث محدد.
اجعل الصفحة الرئيسية مركز قيادة مضغوط. ابدأ بملخص الصحة العام (مثلاً: عدد الأدوات التي تفي بـSLOs، الحوادث النشطة، أكبر المخاطر الحالية)، ثم عرض الحوادث والتنبيهات الأخيرة بأوسمة الحالة.
حافظ على العرض الافتراضي هادئًا: أظهر فقط ما يحتاج اهتمامًا. امنح كل بطاقة رابط تفصيلي مباشر للأداة أو الحادث المتأثر.
كل صفحة أداة يجب أن تجيب عن "هل هذه الأداة موثوقة بما فيه الكفاية؟" و"لماذا/لماذا لا؟" أدرج:
صمّم الرسوم لغير الخبراء: ضع وحدات القياس، وَاضِح حدود SLO، وأضف تلميحات صغيرة بدل ضوابط تقنية كثيفة.
صفحة الحادث هي سجل حي. أدرج جدولًا زمنيًا (أحداث ملتقطة تلقائيًا مثل: تنبيه تم إطلاقه، تم الاعتراف، تم التخفيف)، تحديثات بشرية، المستخدمون المتأثرون، والإجراءات المتخذة.
سهّل نشر التحديثات: مربع نص واحد، حالات محددة مسبقًا (Investigating/Identified/Monitoring/Resolved)، وملاحظات داخلية اختيارية. عند إغلاق الحادث، يجب أن يوفّر إجراء "بدء تحليل ما بعد الحادث" معلومات مملوءة مسبقًا من الجدول الزمني.
يحتاج المدراء لواجهات بسيطة لإدارة الأدوات، الفحوص، أهداف SLO، والمالكين. حسّن للدقة: افتراضات معقولة، تحقق، وتحذيرات عند تغيّر يؤثر على التقارير. أضف أثر "آخر تعديل" مرئيًا حتى يثق الناس بالأرقام.
تبقى بيانات الموثوقية مفيدة إذا وثق الناس بها. هذا يعني ربط كل تغيير بهوية، تقييد من يمكنه إجراء تعديلات مؤثرة، والحفاظ على تاريخ واضح يمكنك الرجوع إليه أثناء المراجعات.
لتطبيق داخلي، افتراضيًا استخدم SSO (SAML) أو OAuth/OIDC عبر موفر الهوية (Okta، Azure AD، Google Workspace). هذا يقلل إدارة كلمات المرور ويجعل الإدماج/الإخراج تلقائيًا.
تفاصيل عملية:
ابدأ بأدوار بسيطة وأضف قواعد أدق عند الحاجة:
حّمِ الإجراءات التي تغيّر نتائج الموثوقية أو سرد التقارير:
سجّل كل تعديل على SLOs، الفحوص، وحقول الحوادث مع:
اجعل سجلات التدقيق قابلة للبحث ومرئية من صفحات التفاصيل ذات الصلة (مثلاً: صفحة الحادث تعرض تاريخ التغييرات كاملًا). هذا يبقي المراجعات واقعية ويقلّل النقاشات أثناء التحليلات بعد الحادث.
المراقبة هي "طبقة الحساسات" لتطبيق الموثوقية: تحوّل السلوك الحقيقي إلى بيانات موثوقة. للأدوات الداخلية، الفحوص الاصطناعية غالبًا أسرع طريق لأنك تتحكم فيما يعنيه "صحيح".
ابدأ بمجموعة صغيرة من أنواع الفحوص التي تغطي معظم التطبيقات الداخلية:
اجعل الفحوص حتمية. إذا يمكن أن يفشل التحقق بسبب محتوى متغير، ستخلق ضوضاء وتُضعف الثقة.
لكل تشغيل فحص، التقط:
خزن البيانات إما كأحداث سلسلة زمنية (صف لكل تشغيل فحص) أو كتجميعات زمنية (مثلاً تجميعات دقيقة بعد دقيقة مع العدادات وتوزيعات الكمون). البيانات الخام مفيدة للتصحيح؛ التجميعات مفيدة للوحة الأداء السريعة. تفعل الفرق عادة كليهما: تحتفظ بالأحداث الخام 7–30 يومًا والتجميعات لفترة أطول.
نتيجة فحص مفقودة لا يجب أن تُفسّر تلقائيًا على أنها "متوقف". أضف حالة غير معروفة للحالات مثل:
هذا يمنع تضخيم وقت التوقف ويجعل "فجوات المراقبة" مرئية كمشكلة تشغيلية مستقلة.
استخدم عمال خلفيين (جدولة شبيهة بالكرون، طوابير) لتشغيل الفحوص بفترات ثابتة (مثلاً كل 30–60 ثانية للأدوات الحرجة). أدرج مهلات، محاولات إعادة مع تراجع، وحدود تزامن حتى لا تُحمّل الفاحص الخدمات الداخلية. احفظ كل نتيجة تشغيل — حتى الفاشلة — حتى تعرض لوحة وقت التشغيل الحالة الحالية وتاريخًا موثوقًا.
التنبيهات هي المكان الذي يتحول فيه تتبع الموثوقية إلى فعل. الهدف بسيط: إعلام الأشخاص المناسبين، بالسياق المناسب، في الوقت المناسب — دون إغراق الجميع.
ابدأ بتعريف قواعد التنبيه التي تربط مباشرة إلى SLIs/SLOs. نمطان عمليان:
لكل قاعدة، احفظ الـ"لماذا" جنبًا إلى الـ"ما": أي SLO متأثر، نافذة التقييم، والشدة المقصودة.
أرسل الإشعارات عبر القنوات التي يعيش فيها فرقك (البريد، Slack، Microsoft Teams). يجب أن تتضمن كل رسالة:
تجنّب إلقاء مقاييس خام. قدّم "الخطوة التالية" القصيرة مثل "افحص النشرات الأخيرة" أو "افتح السجلات".
نفّذ:
حتى في أداة داخلية، يحتاج الناس للسيطرة. أضف تصعيدًا يدويًا (زر في صفحة التنبيه/الحادث) وادمج مع أدوات المناوبة إن وجدت (PagerDuty/Opsgenie أو ما شابه)، أو على الأقل قائمة دوران قابلة للتكوين مخزنة في التطبيق.
إدارة الحوادث تحول "رأينا تنبيهًا" إلى استجابة مشتركة وقابلة للتتبع. بنِ ذلك داخل تطبيق الموثوقية حتى ينتقل الناس من الإشارة إلى التنسيق دون التنقل بين أدوات متعددة.
اجعل إنشاء حادث ممكنًا مباشرة من تنبيه، صفحة خدمة، أو مخطط وقت التشغيل. عبِّئ الحقول الأساسية مسبقًا (الخدمة، البيئة، مصدر التنبيه، وقت الظهور الأول) وعيّن معرف حادث فريد.
مجموعة الحقول الافتراضية الجيدة تبقي العملية خفيفة: الشدة، أثر العملاء (الفرق الداخلية المتأثرة)، المالك الحالي، وروابط للتنبيه المسبب.
استخدم دورة بسيطة تطابق كيف تعمل الفرق فعليًا:
كل تغيير حالة يجب أن يسجل من قام به ومتى. أضف تحديثات جدول زمني (ملاحظات قصيرة مع طابع زمني)، ودعم للمرفقات وروابط لدفاتر التشغيل والتذاكر (مثلاً: /runbooks/payments-retries أو /tickets/INC-1234). يصبح هذا الموضوع الموحد "ما حدث وماذا فعلنا".
يجب أن تكون التحليلات بعد الحادث سريعة للبدء ومتسقة للمراجعة. وفّر قوالب تحتوي على:
اربط بنود العمل بالحادث، تتبع الإكمال، وأبرز البنود المتأخرة على لوحات الفريق. إذا دعمت "مراجعات التعلم"، قدّم وضع "بدون لوم" يركز على تغييرات النظام والعملية بدل الأخطاء الفردية.
التقارير هي المكان الذي يتحول فيه تتبع الموثوقية إلى اتخاذ قرار. اللوحات تساعد المشغلين؛ بطاقات الأداء تساعد القادة على فهم ما إذا كانت الأدوات الداخلية تتحسن، أي المجالات تحتاج استثمارًا، وماذا يعني "جيد".
ابنِ عرضًا ثابتًا وقابلًا للتكرار لكل أداة (واختياريًا لكل فريق) يجيب عن أسئلة سريعة:
حيثما أمكن، أضف سياقًا خفيفًا: "فشل SLO بسبب نشرين" أو "معظم وقت التوقف من الاعتماد X"، دون تحويل التقرير لمراجعة حادث كاملة.
القادة نادرًا ما يريدون "كل شيء". أضف فلاتر لـ الفريق، أهمية الأداة (مثلاً Tier 0–3)، ونافذة الزمن. تأكد أن نفس الأداة يمكن أن تظهر في عدة ملخصات (فريق البنية التحتية يمتلكها، والمالية تعتمد عليها).
وفّر ملخصات أسبوعية وشهرية يمكن مشاركتها خارج التطبيق:
حافظ على السرد متسقًا ("ما الذي تغيّر منذ الفترة الماضية؟" "أين نحن فوق الميزانية؟"). إذا احتجت تمهيدًا لأصحاب المصلحة، اربط بدليل قصير مثل /blog/sli-slo-basics.
سرعان ما يصبح متتبع الموثوقية مصدرًا للحقيقة. اعتبره نظام إنتاج: مؤمن افتراضيًا، مقاوم للبيانات السيئة، وسهل الاسترداد عند حدوث خطأ.
قفل كل نقطة نهاية — حتى "الداخلية فقط" منها.
أبقِ بيانات الاعتماد خارج الشيفرة وخارج السجلات.
خزن الأسرار في مدير أسرار ودوّرها. امنح التطبيق أقل امتياز لقاعدة البيانات: أدوار للقراءة/الكتابة منفصلة، قصر الوصول على الجداول اللازمة، واستخدم بيانات اعتماد قصيرة العمر حيثما أمكن. شفّر النقل (TLS) بين المتصفح↔التطبيق و التطبيق↔قاعدة البيانات.
المقاييس موثوقة فقط إذا كانت الأحداث المادية موثوقة. أضف تحققًا خادميًا للطوابع الزمنية (فروق الساعة/المنطقة)، الحقول المطلوبة، ومفاتيح idempotency لإلغاء التكرارات. تتبَّع أخطاء الاستيعاب في طابور رسائل ميتة أو جدول "حجر صحي" حتى لا تُسمم اللوحات الأحداث السيئة.
أتمت ترحيل قواعد البيانات واختبر عمليات التراجع. جدولة النسخ الاحتياطية، اختبر استعادتها دوريًا، ووثق خطة استعادة حد أدنى (من، ماذا، كم من الوقت). أخيرًا، اجعل تطبيق الموثوقية نفسه موثوقًا: أضف فحوص صحة، مراقبة تأخر الطوابير وزمن استجابة DB، وتنبيه عند هبوط الاستيعاب إلى صفر بصمت.
ينجح تطبيق تتبع الموثوقية عندما يثق الناس به ويستخدمونه فعلاً. عامل الإصدار الأول كحلقة تعلم، لا كإطلاق شامل.
اختر 2–3 أدوات داخلية واسعة الاستخدام ولها مالكون واضحون. نفّذ مجموعة صغيرة من الفحوص (مثلاً: توافر الصفحة الرئيسية، نجاح تسجيل الدخول، ونقطة API رئيسية) وانشر لوحة واحدة تجيب: "هل تعمل؟ إذا لا، ماذا تغيّر ومن يملكها؟"
اجعل التجربة مرئية لكن محدودة: فريق واحد أو مجموعة صغيرة من المستخدمين القويين تكفي للتحقق من التدفق.
في الأسبوعين الأولين، اجمع ملاحظات نشطة حول:
حوّل الملاحظات إلى عناصر قابلة للتنفيذ في سجل الأعمال. زر "أبلغ عن مشكلة بهذا المقياس" على كل رسم يكشف أسرع الرؤى.
أضف القيمة طبقة تلو الأخرى: اربط بأداة الدردشة للإشعارات، ثم بأداة الحوادث لإنشاء تذاكر تلقائيًا، ثم CI/CD لعلامات النشر. يجب أن تقلل كل تكامل العمل اليدوي أو تقصّر زمن التشخيص — وإلا فهو تعقيد زائد.
إذا كنت تريد نموذجًا أوليًا سريعًا، ضع في اعتبارك وضع التخطيط في Koder.ai لرسم النطاق الأولي (الكيانات، الأدوار، وتدفقات العمل) قبل توليد النسخة الأولى. إنها طريقة بسيطة للحفاظ على MVP ضيق — ولأنك تستطيع أخذ لقطات واسترجاع، يمكنك التكرار على اللوحات والاستيعاب بأمان مع تحسّن تعريفات الفرق.
قبل التوسع لفرق أكثر، عرّف مقاييس نجاح مثل: مستخدمي اللوحات النشطين أسبوعيًا، تقليل زمن الكشف، تقليل التنبيهات المكررة، أو مراجعات SLO منتظمة. انشر خارطة طريق خفيفة في /blog/reliability-tracking-roadmap ووسع أداة تلو الأخرى مع مالكين وتدريبات واضحة.
ابدأ بتحديد النطاق (ما الأدوات والبيئات المشمولة) وتعريف العمل لما تعنيه الموثوقية (التوافر، الكمون، الأخطاء). ثم اختر 1–3 نتائج تريد تحسينها (مثل: اكتشاف أسرع، تقارير أوضح) وصمم الشاشات الأولى حول القرارات الأساسية التي يحتاج المستخدمون لاتخاذها: «هل نحن بخير؟» و«ماذا أفعل بعد ذلك؟»
SLI هو ما تقيسه (مثل: % الطلبات الناجحة، زمن الاستجابة p95). SLO هو الهدف لتلك القياسات (مثلاً 99.9% خلال 30 يومًا). SLA هو وعد رسمي مع عواقب (غالبًا موجه للعملاء الخارجيين). للأدوات الداخلية، عادةً تُستخدم SLOs للمواءمة بدون عبء الالتزامات الرسمية لشكل SLA.
استخدم مجموعة أساسية صغيرة تُقارن بسهولة عبر الأدوات:
أضف مقاييس أخرى فقط إذا استطعت تسمية القرار الذي ستدفعه تلك المقياس (تنبيه، أولوية، أعمال سعة، إلخ).
النافذات المتدحرجة تبقي بطاقات الأداء محدّثة باستمرار:
اختر النوافذ التي تتوافق مع طريقة مراجعة مؤسستك للأداء حتى تبدو الأرقام مفهومة وتُستخدم.
عرّف مُشغلات شدة واضحة مرتبطة بتأثير المستخدم والمدة، مثل:
اكتب هذه القواعد في التطبيق حتى تبقى التنبيهات، الجداول الزمنية للحوادث، والتقارير متسقة عبر الفرق.
ابدأ بتحديد أي نظام هو “مصدر الحقيقة” لكل سؤال:
كن صريحًا (مثلاً: «SLI التوافر يأتي فقط من الفحوص»)، وإلا ستنشأ خلافات حول أي الأرقام تُحسب.
استخدم pull للأنظمة التي يمكنك الاستعلام عنها مجدولًا (APIs للمراقبة، APIs للتذاكر). استخدم push (webhooks/أحداث) للأحداث عالية الحجم أو القريبة من الزمن الحقيقي (نشر، تنبيهات، تحديثات الحوادث). الانقسام الشائع: لوحات المعلومات تُحدّث كل 1–5 دقائق، أما بطاقات الأداء فتُحسب كل ساعة/يوم.
عادةً ستحتاج إلى:
سجل كل تعديل ذي تأثير عالٍ مع من، متى، ما الذي تغيّر (قبل/بعد)، ومن أين جاء (UI/API/أتمتة). اجمع ذلك مع وصول قائم على الأدوار:
هذه الضوابط تمنع تغييرات صامتة تقوّض الثقة في أرقام الموثوقية.
عامل غياب نتائج الفحص كحالة غير معروفة، لا كمؤشر تلقائي على التوقف. بيانات مفقودة قد تنتج عن:
إظهار «غير معروف» يمنع تضخيم وقت التوقف ويُظهر فجوات المراقبة كمشكلة تشغيلية بحد ذاتها.
اجعل العلاقات صريحة (أداة → فحوص → مقاييس؛ حادث → أحداث) حتى تبقى استعلامات «نظرة عامة → تفصيل» بسيطة.