30 أكتوبر 2025·8 دقيقة
كيفية بناء تطبيق ويب لتتبع نتائج التجارب بحسب المنتج
تعلم كيفية بناء تطبيق ويب لتتبع نتائج التجارب عبر المنتجات: نموذج البيانات، المقاييس، الأذونات، التكاملات، اللوحات، والتقارير الموثوقة.
تعلم كيفية بناء تطبيق ويب لتتبع نتائج التجارب عبر المنتجات: نموذج البيانات، المقاييس، الأذونات، التكاملات، اللوحات، والتقارير الموثوقة.
معظم الفرق لا تفشل في التجارب لأن الأفكار قليلة—بل تفشل لأن النتائج متناثرة. منتج واحد له رسوم بيانية في أداة تحليلات، وآخر في جدول بيانات، وثالث في شريحة عرض تحتوي لقطات شاشة. بعد شهور، لا يستطيع أحد الإجابة على أسئلة بسيطة مثل "هل اختبرنا هذا بالفعل؟" أو "أي نسخة فازت، وبأي تعريف للمقياس؟"
يجب أن يُركّز تطبيق تتبع التجارب على توحيد ما الذي اختُبر، ولماذا، وكيف قِيس، وماذا حدث—عبر منتجات وفرق متعددة. بدونه، تضيع الفرق وقتها في إعادة بناء تقارير، الجدال حول الأرقام، وإعادة تشغيل اختبارات قديمة لأن الدروس غير قابلة للبحث.
هذا ليس أداة للمحللين فقط.
متتبع جيد يخلق قيمة للأعمال عن طريق تمكين:
كن صريحًا: هذا التطبيق مخصص أساسًا لتتبع وتقرير نتائج التجارب—لا لتشغيل التجارب من البداية للنهاية. يمكنه الربط بالأدوات الموجودة (feature flagging، التحليلات، مستودع البيانات) مع امتلاك السجل البنيوي للتجربة وتفسيرها النهائي والمتفق عليه.
متتبع التجارب الحد الأدنى يجب أن يجيب عن سؤالين دون البحث في المستندات أو الجداول: ما الذي نختبره و ماذا تعلمنا. ابدأ بمجموعة صغيرة من الكيانات والحقول التي تعمل عبر المنتجات، ثم توسع فقط عندما تشعر الفرق بألم حقيقي.
اجعل نموذج البيانات بسيطًا بما يكفي لاستخدامه بنفس الطريقة عبر كل فريق:
ادعم الأنماط الأكثر شيوعًا من اليوم الأول:
حتى إن لم تستخدم عمليات النشر إحصاءات رسمية في البداية، فإن تتبعها جنبًا إلى جنب مع التجارب يساعد الفرق على تجنب إعادة تنفيذ "اختبارات" بدون سجل.
عند الإنشاء، افرض فقط ما يحتاجه الناس لتشغيل وتفسير الاختبار لاحقًا:
اجعل النتائج قابلة للمقارنة بفرض بنية:
إذا بنيت هذا فقط، يمكن للفرق أن تجد التجارب بسهولة، تفهم الإعداد، وتسجل النتائج—حتى قبل إضافة تحليلات متقدمة أو أتمتة.
نجاح متتبع التجارب عبر المنتجات يعتمد على نموذج البيانات. إذا تصادمت المعرفات، تذبذبت المقاييس، أو كانت القطاعات غير متسقة، قد تبدو لوحتك "صحيحة" بينما تروي قصة خاطئة.
ابدأ باستراتيجية معرفات واضحة:
checkout_free_shipping_banner) بالإضافة إلى experiment_id ثابتcontrol, treatment_aهذا يتيح لك مقارنة النتائج عبر المنتجات دون التخمين فيما إذا كانت “Web Checkout” و “Checkout Web” نفس الشيء.
اجعل الكيانات الأساسية صغيرة وصريحة:
حتى لو تمت الحسابات في مكان آخر، فإن تخزين المخرجات (النتائج) يمكّن لوحات سريعة وتاريخًا موثوقًا.
المقاييس والتجارب ليست ثابتة. نمذج:
هذا يمنع تغير تجارب الشهر الماضي عندما يحدث شخص ما تحديثًا في منطق KPI.
اخطط لقطاعات متسقة عبر المنتجات: البلد، الجهاز، مستوى الخطة، جديد مقابل عائد.
أخيرًا، أضف مسار تدقيق يلتقط من عدّل ماذا ومتى (تغييرات الحالة، تقسيم المرور، تحديثات تعريف المقياس). هذا ضروري للثقة والمراجعات والحكم.
إذا أخطأ متتبعك في حساب المقاييس (أو كانت غير متسقة عبر المنتجات)، تصبح "النتيجة" مجرد رأي مع رسم بياني. أسرع طريقة لمنع ذلك هي التعامل مع المقاييس كأصول مشتركة للمنتج—وليس مقتطفات استعلام عشوائية.
أنشئ كتالوج مقاييس يكون مصدر الحقيقة للتعريفات، منطق الحساب، والملكية. يجب أن يتضمن كل إدخال:
احتفظ بالكتالوج قريبًا من مكان عمل الناس (مثلاً: رابط من سير إنشاء التجربة) ومؤرشفًا حتى تستطيع شرح النتائج التاريخية.
قرر مسبقًا ما هي "وحدة التحليل" لكل مقياس: لكل مستخدم، لكل جلسة، لكل حساب، أو لكل طلب. معدل التحويل "لكل مستخدم" قد يختلف عن "لكل جلسة" حتى لو كان كلاهما صحيحًا.
لتقليل الالتباس، خزّن اختيار التجميع مع تعريف المقياس، واطلبه عند إعداد التجربة. لا تدع كل فريق يختار الوحدة بشكل اعتباطي.
لكثير من المنتجات نوافذ تحويل (مثلاً: التسجيل اليوم، الشراء خلال 14 يومًا). عرّف قواعد النسب بوضوح:
اجعل هذه القواعد مرئية في لوحة النتائج حتى يعرف القارئ ماذا ينظر إليه.
من أجل لوحات سريعة وقابلية التدقيق، خزّن كلا النوعين:
هذا يمكّن العرض السريع مع القدرة على إعادة الحساب عند تغير التعريفات.
اعتمد معيارًا للتسمية يشفر المعنى (مثال: activation_rate_user_7d, revenue_per_account_30d). افرض معرفات فريدة، ادعم الأسماء المستعارة، ونبه على شبه التكرارات عند إنشاء مقياس للحفاظ على كتالوج نظيف.
قيمة متتبع التجارب تعتمد على مصداقية البيانات التي يستقبلها. الهدف هو الإجابة الموثوقة عن سؤالين لكل منتج: من تعرّض لأي متغير، وماذا فعل بعد ذلك؟ كل شيء آخر—المقاييس، الإحصاءات، اللوحات—يعتمد على هذا الأساس.
معظم الفرق تختار أحد الأنماط التالية:
مهما اخترت، وحد حدّ الحدث الأدنى عبر المنتجات: exposure/assignment، أحداث التحويل الأساسية، وكمية سياق كافية للربط (user ID/device ID، الطابع الزمني، experiment ID، variant).
عرّف خريطة واضحة من الأحداث الخام إلى المقاييس التي يبلغ عنها المتتبع (مثلاً: purchase_completed → Revenue, signup_completed → Activation). احتفظ بهذه الخريطة لكل منتج، لكن اجعل التسمية متسقة عبر المنتجات حتى تقارن لوحة نتائج A/B ما يقارن بمثله.
تحقق من الاكتمال مبكرًا:
ابنِ فحوصًا تعمل عند كل تحميل وتفشل بصوت عالٍ:
اعرض هذه التحذيرات في التطبيق كتنبيهات مرتبطة بالتجربة، لا مخفية في السجلات.
خطوط الأنابيب تتغير. عندما تصلح خطأ في القياس أو منطق إلغاء التكرار، ستحتاج إلى إعادة معالجة البيانات التاريخية للحفاظ على اتساق المقاييس وKPIs.
خطط لـ:
عامل التكاملات كميزات منتج: وثّق SDKs المدعومة، مخططات الأحداث، وخطوات استكشاف الأعطال. إن كان لديك منطقة وثائق، اربطها كرابط نسبي مثل /docs/integrations.
إن لم يثق الناس بالأرقام، فلن يستخدموا المتتبع. الهدف ليس الإبهار بالرياضيات—بل جعل القرارات قابلة للتكرار والدفاع عبر المنتجات.
قرر مسبقًا إن هل سيكون التطبيق معلنًا عن نتائج تكرارية (p-values، فترات ثقة) أم بايزية (احتمال التحسن، فترات موثوقة). كلاهما يعمل، لكن مزجهما عبر المنتجات يسبب ارتباكًا.
قاعدة عملية: اختر النهج الذي تفهمه منظمتك بالفعل، ثم وثق المصطلحات، الإعدادات الافتراضية، والعتبات.
على الأقل، يجب أن تجعل شاشة النتائج هذه العناصر بلا لبس:
اعرض أيضًا نافذة التحليل، وحدات العد (مستخدمون، جلسات، طلبات)، وإصدار تعريف المقياس المستخدم. هذه التفاصيل هي الفرق بين تقرير متسق وجدال.
إذا اختبرت فرق كثيرة متغيرات كثيرة، أو مقاييس كثيرة، أو تفقد النتائج يوميًا، فإن الإيجابيات الكاذبة تصبح محتملة. يجب أن يشفّر تطبيقك سياسة بدلاً من تركها لكل فريق:
أضف علامات آلية تظهر بجانب النتائج، لا مخفية في السجلات:
بجانب الأرقام، أضف شرحًا قصيرًا يمكن للقارئ غير التقني الوثوق به، مثل: "التقدير الأفضل هو +2.1% رفع، لكن الأثر الحقيقي قد يكون بين -0.4% و +4.6%. ليست لدينا أدلة قوية بعد لإعلان فائز."
أدوات التجارب الجيدة تساعد الناس على الإجابة عن سؤالين بسرعة: ما الذي يجب أن أنظر إليه بعد؟ و ماذا نفعل حيال ذلك؟ يجب أن تقلل الواجهة من البحث عن السياق وتجعل "حالة القرار" صريحة.
ابدأ بثلاث صفحات تغطي معظم الاستخدام:
في الصفحة القائمة وصفحة المنتج، اجعل الفلاتر سريعة وثابتة: product, owner, date range, status, primary metric, segment. يجب أن يستطيع المستخدم تضييق البحث إلى "تجارب الدفع، المملوكة من Maya، الجارية هذا الشهر، المقياس الرئيسي = التحويل، القطاع = مستخدمون جدد" في ثوان.
عامل الحالة كمفردات محكومة، لا نص حر:
Draft → Running → Stopped → Shipped / Rolled back
اعرض الحالة في كل مكان (صفوف القائمة، رأس التفاصيل، وروابط المشاركة) وسجّل من غيّرها ولماذا. هذا يمنع "الإطلاق الصامت" والنتائج غير الواضحة.
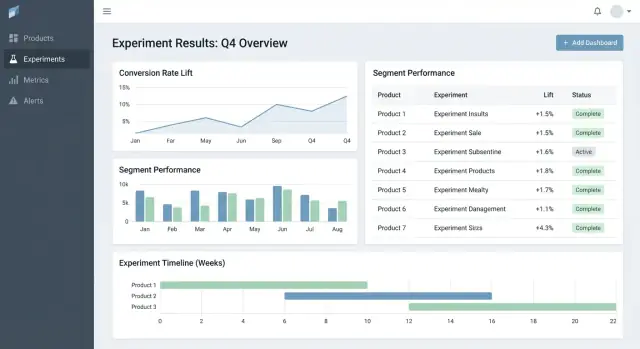
في عرض تفاصيل التجربة، قدم جدول نتائج مضغوط لكل مقياس:
ابق الرسوم المتقدمة خلف قسم "المزيد من التفاصيل" حتى لا يشعر متخذي القرار بالإرهاق.
أضف تصدير CSV للمحللين وروابط قابلة للمشاركة لأصحاب المصلحة، لكن طبّق الوصول: يجب أن تحترم الروابط الأدوار وأذونات المنتج. زر "نسخ الرابط" و"تصدير CSV" يغطيان غالبية حاجات التعاون.
إن امتد متتبعك لعدة منتجات، فإن التحكم في الوصول وقابلية التدقيق ليستا اختياريتين. هما ما يجعل الأداة آمنة للاعتماد عبر الفرق وموثوقة أثناء المراجعات.
ابدأ بمجموعة أدوار بسيطة وثبتها عبر التطبيق:
اجعل قرارات الـ RBAC مركزية (طبقة سياسة واحدة)، حتى يطبقها كل من واجهة المستخدم وAPI بنفس الطريقة.
تحتاج كثير من المؤسسات وصولًا مُحددًا لكل منتج: الفريق A يرى تجارب المنتج A فقط. نمذج هذا صراحة (مثلاً: عضويات user ↔ product)، وتأكد أن كل استعلام يُرشّح حسب المنتج.
لحالات حسّاسة (بيانات شركاء، قطاعات خاضعة للتنظيم)، أضف قيود صفية إضافية على نغمة وضع مثيلًا: وسم التجارب أو شرائح النتائج بمستوى حساسية ويتطلب إذنًا إضافيًا لعرضها.
سجّل شيئين بشكل منفصل:
اعرض تاريخ التغييرات في الواجهة للشفافية، واحتفظ بسجلات أعمق للتحقيقات.
عرّف قواعد احتفاظ لـ:
اجعل سياسة الاحتفاظ قابلة للتكوين حسب المنتج والحساسية. عندما يجب حذف بيانات، احتفظ بسجل رمزي مبسط (ID، وقت الحذف، السبب) للحفاظ على سلامة التقارير دون الإبقاء على المحتوى الحساس.
يصبح المتتبع مفيدًا حقًا عندما يغطي دورة حياة التجربة بالكامل، لا النتيجة فقط. ميزات سير العمل تحول المستندات، التذاكر، والرسوم المتفرقة إلى عملية قابلة للتكرار تحسّن الجودة وتجعل الدروس قابلة لإعادة الاستخدام.
نمذج التجارب كسلسلة حالات (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). يجب أن يكون لكل حالة "معايير خروج" واضحة حتى لا تُبادر التجارب إلى الإنتاج بدون ضروريات مثل فرضية، مقياس رئيسي، وحواجز سلامة.
الموافقات لا تحتاج أن تكون ثقيلة. خطوة مراجع بسيطة (مثلاً: منتج + بيانات) مع مسار تدقيق لمن اعتمد ماذا ومتى يمكن أن تمنع أخطاء يمكن تفادها. بعد الانتهاء، اجعل ملخصًا موجزًا إلزاميًا قبل أن تُعلَن التجربة "Published" لضمان تسجيل النتائج والسياق.
أضف قوالب لـ:
القوالب تقلل الاحتكاك وتسرع المراجعات لأن الجميع يعرف أين ينظر. اجعلها قابلة للتعديل لكل منتج مع الحفاظ على لب مشترك.
نادراً ما تعيش التجارب بمعزل—يحتاج الناس للسياق المحيط. اسمح للمستخدمين بإرفاق روابط للتذاكر/المواصفات والكتابات ذات الصلة (مثال: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). خزّن حقول "تعلم" مُهيكلة مثل:
ادعم إشعارات عند تراجع الحواجز (مثلاً: معدل الخطأ، الإلغاءات) أو عند تغير النتائج ماديًا بعد بيانات متأخرة أو إعادة حساب مقياس. اجعل التنبيهات قابلة للتصرف: عرض المقياس، العتبة، الإطار الزمني، ومالك للاقرار أو التصعيد.
وفر مكتبة يمكن تصفيتها حسب المنتج، منطقة الميزة، الجمهور، المقياس، النتيجة، والوسوم (مثل: “pricing”، “onboarding”، “mobile”). أضف اقتراحات "تجارب مشابهة" استنادًا إلى الوسوم/المقاييس المشتركة حتى تتجنب الفرق إعادة اختبار نفس الأمر وتبني على الدروس السابقة.
لا تحتاج إلى "مكدس مثالي" لبناء تطبيق تتبع التجارب—لكن تحتاج إلى حدود واضحة: أين تعيش البيانات، أين تُجرى الحسابات، وكيف يمكن للفرق الوصول إلى النتائج بشكل متسق.
لعديد من الفرق، إعداد بسيط وقابل للتوسع يبدو كالتالي:
هذا التقسيم يحافظ على سرعات سير العمل المعاملاتي مع ترك المستودع للتعامل مع الحسابات على نطاق واسع.
إذا أردت مُسرعًا لواجهة المستخدم (قائمة التجارب → التفاصيل → الملخص) قبل الالتزام بدورة هندسية كاملة، قد يساعدك منصة "vibe-coding" مثل Koder.ai على توليد أساس React + backend من مواصفات دردشة. مفيدة بشكل خاص لإنشاء الكيانات، النماذج، أساسيات RBAC، وCRUD ملائم للتدقيق، ثم التكرار على عقود البيانات مع فريق التحليلات.
عادة أمامك ثلاث خيارات:
مستودع-أول غالبًا الأبسط إذا كان فريق البيانات يملك SQL موثوق. backend-heavy مفيد للتحديثات منخفضة الكمون أو منطق مخصص لكنه يزيد التعقيد.
لوحات التجارب كثيرًا ما تكرر نفس الاستعلامات. خطط لـ:
إذا تدعم عدة منتجات أو وحدات عمل، قرر مبكرًا:
حل شائع: بنية مشتركة مع نموذج قوي لـ tenant_id وتطبيق وصول صفّي مفروض.
اجعل سطح API صغيرًا وصريحًا. معظم الأنظمة تحتاج نقاط نهاية لـ experiments, metrics, results, segments, و permissions (مع قراءات صديقة للتدقيق). هذا يسهل إضافة منتجات جديدة دون إعادة كتابة الأساس.
المتتبع مفيد فقط إذا وثق الناس به. الثقة تأتي من اختبار منضبط، مراقبة واضحة، وعمليات متوقعة—خاصة عندما تغذي لوحات بيانات متعددة منتجات وخطوط أنابيب.
ابدأ بتسجيل منظم لكل خطوة حرجة: استيعاب الأحداث، التعيين، تلخيص المقاييس، وحساب النتائج. أدرج معرفات مثل المنتج، experiment_id, metric_id, و pipeline run_id حتى يمكن تتبع نتيجة واحدة إلى مدخلاتها.
أضف مقاييس نظامية (زمن استجابة API، زمن وظائف، عمق الطابور) ومقاييس بيانات (الأحداث المعالجة، % الأحداث المتأخرة، % المرفوضة بالتحقق). اكمل هذا بتتبع عبر الخدمات لتتمكن من الإجابة: "لماذا هذه التجربة تفتقد بيانات الأمس؟"
فحوص تحديث البيانات هي أسرع طريقة لمنع فشل صامت. إن كان SLA هو "يوماًيًا قبل 9ص"، رصد أحدث partition لكل منتج ومرجع، وأبلغ عند:
انشئ اختبارات على ثلاثة مستويات:
احتفظ بمجموعة "بيانات ذهبية" صغيرة ذات مخرجات معروفة لاكتشاف التراجع قبل النشر.
عامل الهجرات كجزء من العمليات: أرخّ تعريفات المقاييس ومنطق الحساب، وتجنب إعادة كتابة تجارب تاريخية إلا بطلب صريح. عند الحاجة لتغيير، قدّم مسار backfill متحكمًا ووثّق ما تغيّر في مسار التدقيق.
وفر عرضًا إداريًا لإعادة تشغيل خط لأنابيب لنطاق تاريخ/تجربة محددة، فحص أخطاء التحقق، وتوسيم الحوادث بتحديثات حالة. اربط ملاحظات الحادث مباشرة من التجارب المتأثرة حتى يفهم المستخدمون التأخيرات ولا يتخذوا قرارات على بيانات غير مكتملة.
طرح متتبع تجارب عبر المنتجات أقل ما يكون عن "يوم الإطلاق" وأكثر عن تقليل الغموض تدريجيًا: ما الذي يُتَتبَّع، من يملكه، وهل الأرقام تطابق الواقع.
ابدأ بـ منتج واحد ومجموعة مقاييس صغيرة وواثقة (مثلاً: التحويل، التفعيل، الإيراد). الهدف هو التحقق من سريان العمل الكامل—إنشاء تجربة، التقاط التعرض والنتائج، حساب النتائج، وتسجيل القرار—قبل زيادة التعقيد.
بمجرد استقرار المنتج الأول، وسع منتجًا تلو الآخر مع وتيرة إعداد متوقعة. يجب أن يشعر كل منتج أن الإعداد قابل للتكرار، لا مشروعًا مخصصًا.
إذا كانت مؤسستك تميل إلى "دورات بناء منصة" طويلة، ففكر في نهجين متوازيين: بناء عقود البيانات المتينة (الأحداث، المعرفات، تعريفات المقاييس) بالتوازي مع طبقة تطبيق رقيقة. أحيانًا تستخدم الفرق Koder.ai لإطلاق تلك الطبقة الرقيقة بسرعة—النماذج، اللوحات، الأذونات، والتصدير—ثم تشددها مع نمو الاعتماد (بما في ذلك تصدير الكود الأساسي والتراجع التدريجي عبر لقطات عند تغير المتطلبات).
استخدم قائمة تحقق خفيفة لإدخال المنتجات ومخططات الأحداث:
حيث يساعد الاعتماد، اربط "الخطوات التالية" من نتائج التجربة إلى مناطق المنتج ذات الصلة (مثلاً، تجارب التسعير تربط إلى /pricing). اجعل الروابط معلوماتية ومحايدة—بدون دلالات نتائج.
قِس ما إذا كانت الأداة تصبح المكان الافتراضي للقرارات:
أغلب عمليات الطرح تتعثر على بعض المسببات المتكررة:
ابدأ بتجميع السجل النهائي والمتفق عليه لكل تجربة:
يمكنك الربط إلى أدوات إدارة الـ feature flags وأنظمة التحليلات، لكن يجب أن يمتلك المتتبع السجل المنظم حتى تظل النتائج قابلة للبحث والمقارنة مع مرور الوقت.
لا—حافظ على النطاق مركزاً على تتبع وتقرير النتائج.
نموذج MVP عملي:
بهذه الطريقة تتجنب إعادة بناء منصة تجارب كاملة بينما تصلح مشكلة “نتائج مبعثرة”.
نموذج الحد الأدنى الذي يعمل عبر الفرق يجب أن يتضمن:
استخدم معرفات ثابتة واعتبر أسماء العرض قابلة للتعديل:
product_id: لا يتغير حتى لو تغير اسم المنتجexperiment_id: معرف داخلي غير قابل للتغييرexperiment_key: سلاش/سلاجل قابلة للقراءة (يمكن فرض التفرد داخل المنتج)اجعل معايير النجاح واضحة عند الإعداد:
هذا يقلل الجدل لاحقاً لأن القارئ سيرى ما يعنيه الفوز قبل أن يبدأ الاختبار.
أنشئ كتالوج مقاييس رسمي يكون مصدر الحقيقة للتعريفات وصياغة الحسابات. يجب أن يحتوي كل مدخل على:
عند تغيير المنطق، أنشر إصداراً جديداً من المقياس بدل تعديل التاريخ—وخزّن أي تجربة أي إصدار استُخدم.
الحد الأدنى من الأدوات والاختبارات لجودة البيانات يجب أن يضمن ارتباطات موثوقة بين التعرض والنتائج:
ثم أتمتة اختبارات مثل:
اختر "لهجة" إحصائية واحدة والتزم بها:
أياً كانت الطرائق، اعرض دائماً:
عامل التحكم في الوصول كجزء أساسي من التصميم:
وسجل دائرتين منفصلتين:
طرح تدريجي قابل للتكرار:
تجنب الأخطاء الشائعة: تعريفات متباينة للمقاييس، تتبع تعرض مفقود/منحرف، ملكية غير واضحة، ومحاولة توسيع المقاييس قبل كسب ثقة في سير العمل الأساسي.
product_id ثابت)experiment_id غير قابل للتغيير + experiment_key سهل القراءة)control, treatment_a, إلخ)أضف Segment وTime window مبكراً إذا توقعت تقسيمات ثابتة (مثلاً: مستخدمون جدد مقابل عائدين، 7 أيام مقابل 30 يوم).
variant_key: سلاسل ثابتة مثل control, treatment_aهذا يمنع التصادمات ويجعل التقارير عبر المنتجات موثوقة عندما تنحرف قواعد التسمية.
عرض هذه التحذيرات على صفحة التجربة لكي تكون واضحة وغير مخفية في السجلات.
التناسق أهم من التعقيد لبناء ثقة على مستوى المؤسسة.
هذا يجعل الأداة آمنة لاعتمادها عبر المنتجات والفرق.