22 Sep 2025·8 menit
Apa itu Kafka dan Bagaimana Digunakan dalam Sistem Modern?
Pelajari apa itu Apache Kafka, bagaimana topik dan partisi bekerja, dan di mana Kafka cocok dalam sistem modern untuk peristiwa real-time, log, dan pipeline data.
Pelajari apa itu Apache Kafka, bagaimana topik dan partisi bekerja, dan di mana Kafka cocok dalam sistem modern untuk peristiwa real-time, log, dan pipeline data.
Apache Kafka adalah sebuah platform streaming peristiwa terdistribusi. Singkatnya, ini adalah “pipa” bersama yang tahan lama yang memungkinkan banyak sistem memublikasikan fakta tentang apa yang terjadi dan memungkinkan sistem lain membaca fakta itu—dengan cepat, pada skala besar, dan berurutan.
Tim menggunakan Kafka ketika data perlu bergerak dengan andal antar sistem tanpa keterikatan yang ketat. Alih-alih satu aplikasi memanggil aplikasi lain secara langsung (dan gagal saat aplikasi itu mati atau lambat), producer menulis peristiwa ke Kafka. Consumer membacanya ketika mereka siap. Kafka menyimpan peristiwa untuk jangka waktu yang dapat dikonfigurasi, sehingga sistem bisa pulih dari gangguan dan bahkan memproses ulang riwayat.
Panduan ini ditujukan untuk insinyur yang berpikiran produk, tim data, dan pemimpin teknis yang menginginkan model mental praktis tentang Kafka.
Anda akan mempelajari blok bangunan inti (producer, consumer, topik, broker), bagaimana Kafka skala dengan partisi, bagaimana ia menyimpan dan memutar ulang peristiwa, dan di mana posisinya dalam arsitektur berbasis event. Kami juga akan membahas kasus penggunaan umum, jaminan pengiriman, dasar keamanan, perencanaan operasi, dan kapan Kafka tepat (atau tidak tepat) untuk tugas tertentu.
Kafka paling mudah dipahami sebagai log peristiwa bersama: aplikasi menulis peristiwa ke dalamnya, dan aplikasi lain membaca peristiwa tersebut nanti—seringkali secara real time, kadang jam atau hari kemudian.
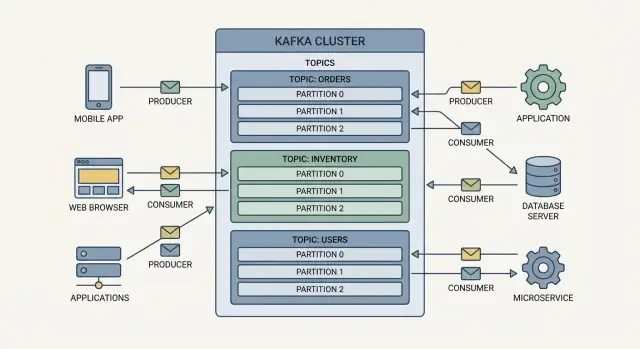
Producer adalah penulis. Seorang producer mungkin memublikasikan peristiwa seperti “order placed,” “payment confirmed,” atau “temperature reading.” Producer tidak mengirim peristiwa langsung ke aplikasi tertentu—mereka mengirim ke Kafka.
Consumer adalah pembaca. Sebuah consumer mungkin menggerakkan dashboard, memicu alur pengiriman, atau memuat data ke analytics. Consumer memutuskan apa yang harus dilakukan dengan peristiwa, dan mereka dapat membaca sesuai kecepatan mereka sendiri.
Peristiwa di Kafka dikelompokkan ke dalam topik, yang pada dasarnya adalah kategori bernama. Contoh:
orders untuk peristiwa terkait pesananpayments untuk peristiwa pembayaraninventory untuk perubahan stokSebuah topik menjadi aliran “sumber kebenaran” untuk jenis peristiwa itu, yang memudahkan banyak tim menggunakan data yang sama tanpa membangun integrasi satu-off.
Sebuah broker adalah server Kafka yang menyimpan peristiwa dan melayaninya ke consumer. Dalam praktiknya, Kafka dijalankan sebagai cluster (beberapa broker bekerja bersama) sehingga dapat menangani lebih banyak lalu lintas dan tetap berjalan bahkan jika satu mesin gagal.
Consumer sering dijalankan dalam consumer group. Kafka membagi pekerjaan membaca di antara grup, sehingga Anda dapat menambahkan lebih banyak instance consumer untuk menskalakan pemrosesan—tanpa setiap instance melakukan pekerjaan yang sama.
Kafka skala dengan membagi pekerjaan menjadi topik (aliran peristiwa terkait) dan kemudian membagi setiap topik menjadi partisi (potongan lebih kecil, independen dari aliran itu).
Topik dengan satu partisi hanya bisa dibaca oleh satu consumer pada satu waktu di dalam sebuah consumer group. Tambahkan lebih banyak partisi, dan Anda dapat menambahkan lebih banyak consumer untuk memproses peristiwa secara paralel. Begitulah cara Kafka mendukung streaming peristiwa ber-volume tinggi dan pipeline data real-time tanpa mengubah setiap sistem menjadi bottleneck.
Partisi juga membantu menyebarkan beban ke broker. Alih-alih satu mesin menangani semua tulis dan baca untuk sebuah topik, beberapa broker dapat menampung partisi berbeda dan berbagi trafik.
Kafka menjamin urutan dalam satu partisi. Jika peristiwa A, B, dan C ditulis ke partisi yang sama dalam urutan itu, consumer akan membacanya A → B → C.
Ordering antar partisi tidak dijamin. Jika Anda membutuhkan ordering ketat untuk sebuah entitas (seperti pelanggan atau pesanan), biasanya Anda memastikan semua peristiwa untuk entitas itu masuk ke partisi yang sama.
Saat producer mengirim peristiwa, mereka dapat menyertakan key (misalnya, order_id). Kafka menggunakan key untuk merutekan peristiwa terkait secara konsisten ke partisi yang sama. Itu memberi Anda ordering yang dapat diprediksi untuk key tersebut sambil tetap memungkinkan topik menyebar ke banyak partisi.
Setiap partisi dapat direplikasi ke broker lain. Jika satu broker gagal, broker lain yang memiliki replika dapat mengambil alih. Replikasi adalah alasan utama Kafka dipercaya untuk sistem pub-sub dan event-driven yang kritis: ini meningkatkan ketersediaan dan mendukung toleransi kesalahan tanpa memaksa tiap aplikasi membangun logika failover sendiri.
Gagasan kunci di Apache Kafka adalah peristiwa tidak hanya diteruskan dan dilupakan. Mereka ditulis ke disk dalam log berurutan, sehingga consumer bisa membacanya sekarang—atau nanti. Ini membuat Kafka berguna bukan hanya untuk memindahkan data, tetapi juga untuk menyimpan riwayat yang tahan lama tentang apa yang terjadi.
Saat producer mengirim peristiwa ke topik, Kafka menambahkannya ke penyimpanan di broker. Consumer kemudian membaca dari log yang tersimpan itu sesuai kecepatan mereka sendiri. Jika sebuah consumer mati selama satu jam, peristiwa tetap ada dan dapat dikejar setelah pemulihan.
Kafka menyimpan peristiwa sesuai kebijakan retensi:
Retensi dikonfigurasi per-topik, sehingga Anda dapat memperlakukan topik “audit trail” berbeda dari topik telemetri ber-volume tinggi.
Beberapa topik lebih mirip changelog daripada arsip historis—misalnya, “pengaturan pelanggan saat ini.” Log compaction menjaga setidaknya peristiwa terbaru untuk setiap key, sementara rekaman lama yang digantikan mungkin dihapus. Anda tetap mendapatkan sumber kebenaran yang tahan lama untuk status terbaru, tanpa pertumbuhan tak terhingga.
Karena peristiwa tetap tersimpan, Anda dapat memutar ulang untuk merekonstruksi state:
Dalam praktiknya, replay dikendalikan oleh dari mana consumer “mulai membaca” (offset-nya), memberi tim net pengaman yang kuat saat sistem berkembang.
Kafka dibangun untuk menjaga data mengalir bahkan ketika bagian sistem gagal. Ia melakukan ini dengan replikasi, aturan jelas tentang siapa yang menjadi “pemimpin” untuk setiap partisi, dan acknowledgment tulis yang dapat dikonfigurasi.
Setiap partisi topik memiliki satu broker leader dan satu atau lebih replika follower di broker lain. Producer dan consumer berkomunikasi dengan leader untuk partisi itu.
Follower terus menyalin data dari leader. Jika leader turun, Kafka dapat mempromosikan follower yang sudah sinkron menjadi leader baru, sehingga partisi tetap tersedia.
Jika broker gagal, partisi yang dipimpinnya menjadi tidak tersedia sejenak. Controller Kafka (koordinasi internal) mendeteksi kegagalan dan memicu pemilihan leader untuk partisi-partisi itu.
Jika setidaknya satu replika follower cukup up-to-date, ia dapat mengambil alih sebagai leader dan klien melanjutkan produce/consume. Jika tidak ada replika yang in-sync, Kafka mungkin menunda penulisan (tergantung pengaturan) untuk menghindari kehilangan data yang sudah diakui.
Dua parameter utama membentuk durabilitas:
Secara konseptual:
Untuk mengurangi duplikat saat retry, tim sering mengombinasikan acks yang lebih aman dengan producer idempoten dan pengelolaan consumer yang solid.
Keamanan yang lebih tinggi biasanya berarti menunggu konfirmasi lebih banyak dan menjaga lebih banyak replika tetap sinkron, yang dapat menambah latensi dan mengurangi throughput puncak.
Pengaturan latensi rendah bisa cocok untuk telemetri atau clickstream di mana kehilangan sesekali dapat diterima, tetapi pembayaran, inventory, dan log audit biasanya membenarkan keamanan ekstra.
Arsitektur berbasis event (EDA) adalah cara membangun sistem di mana kejadian bisnis—order dibuat, pembayaran dikonfirmasi, paket dikirim—diwakili sebagai peristiwa yang dapat direaksikan oleh bagian lain dari sistem.
Kafka sering menjadi pusat EDA sebagai “aliran peristiwa” bersama. Alih-alih Layanan A memanggil Layanan B secara langsung, Layanan A mempublikasikan peristiwa (mis. OrderCreated) ke topik Kafka. Banyak layanan lain dapat mengonsumsi peristiwa itu dan mengambil tindakan—mengirim email, menahan inventory, memulai pemeriksaan fraud—tanpa Layanan A perlu mengetahui keberadaan mereka.
Karena layanan berkomunikasi melalui peristiwa, mereka tidak perlu mengoordinasikan API request/response untuk setiap interaksi. Ini mengurangi dependensi ketat antar tim dan memudahkan penambahan fitur baru: Anda dapat memperkenalkan consumer baru untuk peristiwa yang sudah ada tanpa mengubah producer.
EDA bersifat alami asinkron: producer menulis peristiwa dengan cepat, dan consumer memprosesnya sesuai kecepatan mereka. Saat terjadi lonjakan trafik, Kafka membantu meredam lonjakan sehingga sistem downstream tidak langsung jatuh. Consumer dapat diskalakan untuk mengejar ketinggalan, dan jika satu consumer mati sementara, ia dapat melanjutkan dari posisi terakhir.
Pikirkan Kafka sebagai “feed aktivitas” sistem. Producer memublikasikan fakta; consumer berlangganan fakta yang mereka pedulikan. Pola ini memungkinkan pipeline data real-time dan alur kerja berbasis event sambil menjaga layanan tetap sederhana dan lebih independen.
Kafka biasanya muncul ketika tim perlu memindahkan banyak “fakta yang terjadi” (peristiwa) antar sistem—dengan cepat, andal, dan sehingga banyak consumer dapat menggunakan kembali data itu.
Aplikasi sering membutuhkan riwayat append-only: login pengguna, perubahan izin, pembaruan catatan, atau tindakan admin. Kafka bekerja baik sebagai aliran pusat peristiwa ini, sehingga alat keamanan, pelaporan, dan ekspor kepatuhan dapat membaca sumber yang sama tanpa menambah beban ke database produksi. Karena peristiwa dipertahankan untuk periode tertentu, Anda juga dapat memutarnya ulang untuk membangun kembali tampilan audit setelah bug atau perubahan skema.
Alih-alih layanan saling memanggil langsung, mereka dapat memublikasikan peristiwa seperti “order created” atau “payment received.” Layanan lain berlangganan dan bereaksi sesuai waktunya sendiri. Ini mengurangi coupling yang ketat, membantu sistem tetap berfungsi selama outage parsial, dan memudahkan penambahan kemampuan baru (mis. pemeriksaan fraud) hanya dengan mengonsumsi aliran peristiwa yang ada.
Kafka adalah tulang punggung umum untuk memindahkan data dari sistem operasional ke platform analytics. Tim dapat men-stream perubahan dari database aplikasi dan mengirimkannya ke warehouse atau data lake dengan latensi rendah, sambil menjaga aplikasi produksi terpisah dari kueri analitik yang berat.
Sensor, perangkat, dan telemetri aplikasi sering datang dalam lonjakan. Kafka dapat menyerap lonjakan, men-buffer dengan aman, dan membiarkan pemrosesan downstream mengejar—berguna untuk monitoring, alerting, dan analisis jangka panjang.
Kafka lebih dari broker dan topik. Sebagian besar tim mengandalkan alat pendamping yang membuat Kafka praktis untuk pemindahan data sehari-hari, pemrosesan stream, dan operasi.
Kafka Connect adalah kerangka integrasi Kafka untuk mendapatkan data masuk Kafka (source) dan keluar Kafka (sink). Alih-alih membuat dan memelihara pipeline satu-per-satu, Anda menjalankan Connect dan mengonfigurasi connector.
Contoh umum termasuk menarik perubahan dari database, mengimpor event SaaS, atau mengirim data Kafka ke data warehouse atau object storage. Connect juga menstandarisasi kekhawatiran operasional seperti retry, offset, dan paralelisme.
Jika Connect untuk integrasi, Kafka Streams untuk komputasi. Ini adalah library yang Anda tambahkan ke aplikasi untuk mentransformasikan stream secara real time—memfilter peristiwa, memperkaya, melakukan join antar stream, dan membangun agregat (mis. “orders per minute”).
Karena aplikasi Streams membaca dari topik dan menulis kembali ke topik, mereka cocok secara alami dalam sistem berbasis event dan dapat diskalakan dengan menambah instance.
Saat banyak tim memublikasikan peristiwa, konsistensi menjadi penting. Manajemen skema (sering via schema registry) mendefinisikan field apa yang harus ada dan bagaimana ia berevolusi dari waktu ke waktu. Itu membantu mencegah pemutusan seperti producer yang mengganti nama field yang bergantung pada consumer.
Kafka sensitif secara operasional, jadi pemantauan dasar sangat penting:
Sebagian besar tim juga menggunakan UI manajemen dan otomatisasi untuk deploy, konfigurasi topik, dan kebijakan kontrol akses (lihat /blog/kafka-security-governance).
Kafka sering digambarkan sebagai “log yang tahan lama + consumer,” tetapi yang paling dikhawatirkan tim adalah: apakah saya akan memproses setiap peristiwa satu kali, dan apa yang terjadi saat terjadi kegagalan? Kafka memberi Anda blok bangunan, dan Anda memilih trade-off.
At-most-once berarti Anda mungkin kehilangan peristiwa, tetapi tidak akan memproses duplikat. Ini bisa terjadi jika consumer commit posisinya terlebih dahulu lalu crash sebelum menyelesaikan pekerjaan.
At-least-once berarti Anda tidak akan kehilangan peristiwa, tetapi duplikat mungkin terjadi (mis. consumer memproses peristiwa, crash, lalu memproses ulang setelah restart). Ini adalah default yang paling umum.
Exactly-once bertujuan menghindari kehilangan dan duplikat end-to-end. Di Kafka, ini biasanya melibatkan producer transaksional dan pemrosesan yang kompatibel (sering via Kafka Streams). Ini kuat, tapi lebih terbatas dan memerlukan pengaturan yang hati-hati.
Dalam praktiknya, banyak sistem menerima pola at-least-once dan menambahkan pengamanan:
Offset consumer adalah posisi rekaman terakhir yang diproses di sebuah partisi. Saat Anda commit offset, Anda mengatakan, “Saya selesai sampai sini.” Commit terlalu awal dan Anda berisiko kehilangan; commit terlalu terlambat dan Anda menambah duplikat setelah kegagalan.
Retry harus dibatasi dan terlihat. Pola umum adalah:
Ini membuat satu “pesan beracun” tidak memblokir seluruh grup consumer sambil tetap menjaga data untuk perbaikan nanti.
Kafka sering membawa peristiwa bisnis-kritis (order, pembayaran, aktivitas pengguna). Itu membuat keamanan dan tata kelola bagian dari desain, bukan setelahnya.
Autentikasi menjawab “siapa kamu?” Otorisasi menjawab “apa yang boleh kamu lakukan?” Di Kafka, autentikasi umum dilakukan dengan SASL (mis. SCRAM atau Kerberos), sementara otorisasi ditegakkan dengan ACL (access control list) di level topik, grup consumer, dan cluster.
Polanya yang praktis adalah prinsip least privilege: producer hanya dapat menulis ke topik yang mereka miliki, dan consumer hanya dapat membaca topik yang mereka perlukan. Ini mengurangi paparan data tidak sengaja dan membatasi blast radius jika kredensial bocor.
TLS mengenkripsi data saat berpindah antar aplikasi, broker, dan tooling. Tanpa itu, peristiwa bisa disadap di jaringan internal, bukan hanya internet publik. TLS juga membantu mencegah serangan mitm dengan memvalidasi identitas broker.
Saat banyak tim berbagi cluster, aturan pengaman diperlukan. Konvensi penamaan topik yang jelas (mis. <team>.<domain>.<event>.<version>) membuat kepemilikan terlihat dan membantu tooling menerapkan kebijakan secara konsisten.
Gabungkan penamaan dengan kuota dan template ACL sehingga satu beban kerja yang berisik tidak menguras yang lain, dan layanan baru memulai dengan default yang aman.
Perlakukan Kafka sebagai sistem catatan peristiwa hanya jika Anda memang bermaksud. Jika peristiwa berisi PII, gunakan minimisasi data (kirim ID alih-alih profil lengkap), pertimbangkan enkripsi tingkat field, dan dokumentasikan topik mana yang sensitif.
Pengaturan retensi harus sesuai persyaratan hukum dan bisnis. Jika kebijakan mengatakan “hapus setelah 30 hari,” jangan menyimpan 6 bulan “untuk berjaga-jaga.” Tinjauan dan audit berkala menjaga konfigurasi tetap selaras seiring sistem berkembang.
Menjalankan Apache Kafka bukan sekadar “install lalu lupa.” Ia berperilaku lebih seperti utilitas bersama: banyak tim bergantung padanya, dan kesalahan kecil dapat merambat ke aplikasi downstream.
Kapasitas Kafka sebagian besar soal matematika yang Anda tinjau secara berkala. Tuas terbesar adalah partisi (paralelisme), throughput (MB/s masuk dan keluar), dan pertumbuhan penyimpanan (berapa lama Anda menyimpan data).
Jika trafik berlipat dua, Anda mungkin perlu lebih banyak partisi untuk menyebarkan beban ke broker, lebih banyak disk untuk menahan retensi, dan lebih banyak headroom jaringan untuk replikasi. Kebiasaan praktis adalah meramalkan laju tulis puncak dan mengalikan dengan retensi untuk memperkirakan pertumbuhan disk, lalu menambahkan buffer untuk replikasi dan “kesuksesan tak terduga.”
Harapkan pekerjaan rutin di luar menjaga server tetap hidup:
Biaya dipengaruhi oleh disk, egress jaringan, dan jumlah/ukuran broker. Kafka terkelola bisa mengurangi beban staf dan mempermudah upgrade, sementara self-hosting bisa lebih murah dalam skala besar jika Anda memiliki operator berpengalaman. Trade-offnya adalah waktu pemulihan dan beban on-call.
Tim biasanya memantau:
Dashboard dan alert yang baik mengubah Kafka dari “kotak misteri” menjadi layanan yang dapat dipahami.
Kafka cocok ketika Anda perlu memindahkan banyak peristiwa dengan andal, menyimpannya untuk sementara, dan membiarkan banyak sistem bereaksi terhadap aliran data yang sama sesuai kecepatan mereka. Ini sangat berguna ketika data perlu dapat diputar ulang (untuk backfill, audit, atau membangun layanan baru) dan ketika Anda mengharapkan produsen/consumer bertambah seiring waktu.
Kafka cenderung unggul ketika Anda memiliki:
Kafka bisa berlebihan jika kebutuhan Anda sederhana:
Dalam kasus ini, overhead operasional (penentuan ukuran cluster, upgrade, monitoring, on-call) mungkin lebih besar daripada manfaat.
Kafka juga melengkapi—bukan menggantikan—database (sistem catatan), cache (bacaan cepat), dan alat ETL batch (transformasi besar berkala).
Tanyakan:
Jika Anda menjawab “ya” untuk sebagian besar, Kafka biasanya pilihan yang masuk akal.
Kafka paling cocok ketika Anda membutuhkan “sumber kebenaran” bersama untuk aliran peristiwa real-time: banyak sistem menghasilkan fakta (order dibuat, pembayaran diotorisasi, inventory berubah) dan banyak sistem mengonsumsi fakta itu untuk menjalankan pipeline, analytics, dan fitur reaktif.
Mulailah dengan aliran sempit bernilai tinggi—misalnya memublikasikan peristiwa “OrderPlaced” untuk layanan downstream (email, pemeriksaan fraud, pemenuhan). Hindari menjadikan Kafka antrean serba guna sejak hari pertama.
Tuliskan:
Jaga skema awal sederhana dan konsisten (timestamp, ID, dan nama peristiwa yang jelas). Putuskan apakah Anda akan menegakkan skema sejak awal atau berevolusi secara hati-hati.
Kafka berhasil ketika ada yang bertanggung jawab atas:
Tambahkan pemantauan segera (consumer lag, kesehatan broker, throughput, tingkat error). Jika belum punya tim platform, mulailah dengan layanan terkelola dan batas yang jelas.
Produce peristiwa dari satu sistem, konsumsi di satu tempat, dan buktikan loop end-to-end. Baru kemudian kembangkan ke lebih banyak consumer, partisi, dan integrasi.
Jika Anda ingin bergerak cepat dari “ide” ke layanan event-driven yang bekerja, alat seperti Koder.ai dapat membantu Anda mem-prototype aplikasi pendukung dengan cepat (UI React, backend Go, PostgreSQL) dan menambahkan producer/consumer Kafka secara iteratif via workflow berbasis chat. Ini berguna untuk membangun dashboard internal dan layanan ringan yang mengonsumsi topik, dengan fitur seperti planning mode, ekspor kode sumber, deployment/hosting, dan snapshot dengan rollback.
Jika Anda memetakan ini ke pendekatan berbasis event, lihat /blog/event-driven-architecture. Untuk merencanakan biaya dan lingkungan, cek /pricing.
Kafka adalah platform streaming peristiwa terdistribusi yang menyimpan peristiwa dalam log yang tahan lama dan bersifat append-only.
Producer menulis peristiwa ke topik, dan consumer membacanya secara independen (seringkali secara real time, tetapi juga bisa nanti) karena Kafka mempertahankan data untuk jangka waktu yang dikonfigurasi.
Gunakan Kafka ketika beberapa sistem membutuhkan aliran peristiwa yang sama, Anda menginginkan loose coupling, dan mungkin perlu melakukan replay riwayat.
Ini sangat berguna untuk:
Sebuah topik adalah kategori bernama untuk peristiwa (seperti orders atau payments).
Partisi adalah potongan dari topik yang memungkinkan:
Kafka hanya menjamin urutan di dalam satu partisi.
Kafka menggunakan key record (mis. order_id) untuk merutekan peristiwa terkait secara konsisten ke partisi yang sama.
Aturan praktis: jika Anda butuh ordering per-entity (semua peristiwa untuk order/customer berurutan), pilih key yang merepresentasikan entitas tersebut sehingga peristiwa-peristiwa itu jatuh di satu partisi.
Grup consumer adalah sekumpulan instance consumer yang berbagi pekerjaan untuk sebuah topik.
Di dalam grup:
Jika Anda memerlukan dua aplikasi berbeda untuk menerima setiap peristiwa, mereka harus menggunakan grup consumer yang berbeda.
Kafka menyimpan peristiwa di disk berdasarkan kebijakan topik, sehingga consumer bisa mengejar ketinggalan setelah downtime atau memproses ulang riwayat.
Tipe retensi umum:
Retensi diatur per-topik, jadi topik audit bernilai tinggi bisa disimpan lebih lama daripada telemetri ber-volume tinggi.
Log compaction menjaga setidaknya rekaman terbaru per key, menghapus rekaman lama yang telah digantikan seiring waktu.
Ini berguna untuk aliran “state saat ini” (mis. pengaturan atau profil) di mana Anda peduli pada nilai terbaru per key, bukan setiap perubahan historis—sementara tetap mempertahankan sumber kebenaran yang tahan lama untuk nilai terbaru.
Polanya yang paling umum di Kafka adalah at-least-once: Anda tidak akan kehilangan peristiwa, tetapi duplikat bisa terjadi.
Untuk menangani ini dengan aman:
Offset adalah “penanda” consumer per partisi.
Jika Anda commit offset terlalu awal, Anda bisa kehilangan pekerjaan saat crash; terlalu terlambat, Anda akan memproses ulang dan menghasilkan duplikat.
Polanya sering dipakai: retry terbatas dengan backoff, lalu kirim rekaman yang gagal ke dead-letter topic sehingga satu pesan bermasalah tidak memblokir seluruh grup consumer.
Kafka Connect memindahkan data masuk/keluar Kafka menggunakan connector (source dan sink) alih-alih menulis kode pipeline khusus.
Kafka Streams adalah library untuk mentransformasi dan mengagregasi stream secara real time di dalam aplikasi Anda (filter, join, enrich, aggregate), membaca dari topik dan menulis kembali ke topik.
Connect biasanya untuk integrasi; Streams untuk komputasi.