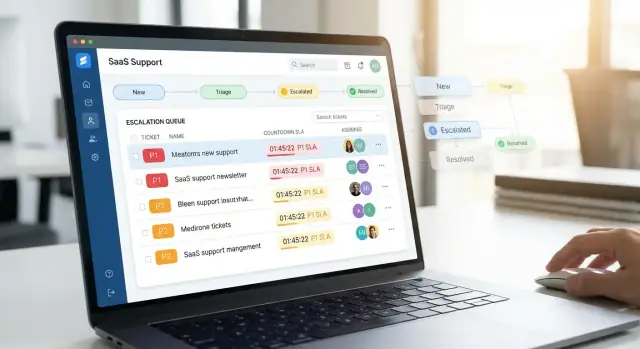
Klarifikasi Alur Eskalasi dan Tujuan
Sebelum Anda membuat layar atau menulis kode, putuskan untuk apa aplikasi ini dan perilaku apa yang harus ditegakkan. Eskalasi bukan sekadar “pelanggan marah”—mereka adalah tiket yang membutuhkan penanganan lebih cepat, visibilitas lebih tinggi, dan koordinasi yang lebih ketat.
Apa yang dihitung sebagai eskalasi?
Definisikan kriteria eskalasi dengan bahasa yang jelas agar agen dan pelanggan tidak perlu menebak. Pemicu umum meliputi:
- Gangguan atau degradasi parah
- Pelanggan VIP atau kontrak “dukungan prioritas”
- Terancam pelanggaran SLA (atau pelanggaran berulang)
- Isu yang berdampak pada keamanan, penagihan, atau aspek hukum
Juga definisikan apa yang bukan eskalasi (misalnya, pertanyaan cara pakai, permintaan fitur, bug minor) dan bagaimana permintaan tersebut sebaiknya diarahkan.
Peran dan tanggung jawab
Daftar peran yang dibutuhkan alur kerja Anda dan apa yang bisa dilakukan tiap peran:
- Agent: menetriase dan menyelesaikan, memperbarui tiket, mengikuti playbook
- Lead: meninjau eskalasi, menugaskan ulang, menyetujui perubahan prioritas
- Manager: bertanggung jawab atas pelaporan, standar komunikasi pelanggan, kebijakan eskalasi
- On-call: menerima alert mendesak dan mengambil kepemilikan setelah jam kerja
- Customer admin: mengirim dan menelusuri tiket, menambahkan pemangku kepentingan internal
Tulis siapa yang memiliki tiket pada setiap langkah (termasuk handoff) dan apa arti “kepemilikan” (kewajiban respons, waktu pembaruan berikutnya, dan otoritas untuk mengeskalasi).
Saluran yang diprioritaskan
Mulai dengan satu set input kecil sehingga Anda bisa rilis lebih cepat dan menjaga triase konsisten. Banyak tim memulai dengan email + web form, lalu menambahkan chat setelah SLA dan routing stabil.
Tujuan dan metrik keberhasilan
Pilih hasil terukur yang harus diperbaiki oleh aplikasi:
- First response time (secara keseluruhan dan untuk eskalasi)
- Resolution time atau waktu mitigasi insiden
- Reopen rate dan jumlah “pinged for update”
- Missed SLA rate dan waktu yang tidak dimiliki
Keputusan ini menjadi requirement produk untuk sisa pembangunan.
Rancang Model Data untuk Tiket, SLA, dan Eskalasi
Aplikasi dukungan prioritas hidup atau mati oleh model datanya. Jika fondasi benar, routing, pelaporan, dan penegakan SLA menjadi lebih sederhana—karena sistem memiliki fakta yang dibutuhkan.
Mulai dengan “dasar” tiket (apa yang harus selalu diketahui agen)
Setidaknya, setiap tiket harus menangkap: peminta (kontak), perusahaan (akun pelanggan), subjek, deskripsi, dan lampiran. Perlakukan deskripsi sebagai pernyataan masalah asli; pembaruan selanjutnya berada di komentar sehingga Anda bisa melihat bagaimana cerita berkembang.
Tambahkan field khusus eskalasi (apa yang membuat ini “prioritas”)
Eskalasi membutuhkan struktur lebih dari dukungan umum. Field umum termasuk severity (seberapa parah), impact (berapa banyak pengguna/berapa besar pendapatan), dan priority (seberapa cepat Anda akan merespons). Tambahkan field affected service (mis. Billing, API, Mobile App) agar triase bisa mengarahkan dengan cepat.
Untuk deadline, simpan waktu jatuh tempo eksplisit (seperti “first response due” dan “resolution/next update due”), bukan hanya “nama SLA.” Sistem bisa menghitung timestamp ini, tetapi agen harus melihat waktu tepatnya.
Model hubungan untuk pekerjaan nyata
Model praktis biasanya mencakup:
- Customers → banyak Contacts
- Customers → banyak Tickets
- Tickets → banyak Comments (internal + publik)
- Tickets → banyak Tasks (item checklist, tindak lanjut)
Ini menjaga kolaborasi tetap rapi: percakapan di komentar, item aksi di tasks, dan kepemilikan di tiket.
Definisikan status (dan jaga konsistensinya)
Gunakan set status kecil dan stabil seperti: New, Triaged, In Progress, Waiting, Resolved, Closed. Hindari status yang “hampir sama”—setiap status ekstra membuat pelaporan dan otomatisasi kurang andal.
Tentukan apa yang harus tak dapat diubah untuk audit
Untuk pelacakan SLA dan akuntabilitas, beberapa data harus append-only: timestamp dibuat/diperbarui, riwayat perubahan status, event start/stop SLA, perubahan eskalasi, dan siapa yang membuat tiap perubahan. Lebih baik gunakan audit log (atau tabel event) sehingga Anda bisa merekonstruksi apa yang terjadi tanpa tebakan.
Tetapkan Level Prioritas dan Aturan SLA
Prioritas dan aturan SLA adalah “kontrak” yang ditegakkan aplikasi Anda: apa yang ditangani terlebih dahulu, seberapa cepat, dan siapa yang bertanggung jawab. Jaga skema sederhana, dokumentasikan dengan jelas, dan buat sulit untuk dioverride tanpa alasan.
Skema prioritas sederhana (P1–P4)
Gunakan empat level agar agen bisa mengklasifikasikan cepat dan manajer bisa melaporkan konsisten:
- P1 — Critical outage / severe impact: Produk down, kehilangan data terjadi, atau dicurigai insiden keamanan. Banyak pengguna atau seluruh akun pelanggan terblokir.
- P2 — Major degradation: Fitur inti sebagian rusak, solusi sementara terbatas, dan dampak bisnis tinggi tapi tidak total.
- P3 — Standard issue: Satu pengguna atau fitur non-inti terdampak. Ada solusi sementara. Banyak tiket akan berada di sini.
- P4 — Low urgency / requests: Pertanyaan cara pakai, bug minor, permintaan fitur, pertanyaan penagihan yang tidak menghalangi penggunaan.
Definisikan “impact” (berapa banyak pengguna/pelanggan) dan “urgency” (seberapa sensitif waktu) di UI untuk mengurangi salah label.
Definisikan SLA berdasarkan plan, tier pelanggan, dan prioritas
Model data Anda harus memungkinkan SLA bervariasi menurut plan/tier pelanggan (mis. Free/Pro/Enterprise) dan prioritas. Biasanya, Anda melacak setidaknya dua timer:
- First response SLA (waktu untuk mengakui dan mulai mengambil kepemilikan)
- Resolution SLA atau next-update SLA (waktu untuk menyelesaikan atau memberikan pembaruan bermakna)
Contoh: Enterprise + P1 mungkin membutuhkan first response dalam 15 menit, sedangkan Pro + P3 bisa 8 jam kerja. Tampilkan tabel aturan terlihat bagi agen dan tautkan dari halaman tiket.
Jam kerja, 24/7, dan kalender libur
SLA sering bergantung pada apakah plan mencakup 24/7 coverage.
- Untuk business-hours SLA, simpan jadwal kerja (timezone, hari kerja, jam mulai/akhir).
- Untuk 24/7 SLA, jam selalu berjalan.
- Tambahkan kalender libur (per wilayah jika perlu) agar timer tidak “terbengkalai” pada hari ketika tak ada yang bekerja.
Tampilkan pada tiket baik “SLA remaining” maupun jadwal yang digunakannya (agar agen mempercayai penghitung waktu).
Pause SLA, “waiting on customer”, dan penanganan breach
Alur nyata membutuhkan jeda. Aturan umum: jeda SLA ketika tiket Waiting on customer (atau Waiting on third party), dan dilanjutkan saat pelanggan merespons.
Jelaskan secara eksplisit:
- Status mana yang menjeda timer SLA
- Apakah jeda berlaku untuk response SLA, resolution SLA, atau keduanya
- Apa yang terjadi saat breach (mis. auto-escalate priority, paging on-call, notifikasi manager, memberi tag “SLA Breached” pada tiket)
Hindari breach yang diam. Penanganan breach harus membuat event terlihat di riwayat tiket.
Siapa yang mendapat peringatan sebelum dan setelah breach
Tetapkan setidaknya dua ambang alert:
- Pre-breach warning (mis. 50% dan 80% SLA terpakai): beri tahu pemilik tiket dan channel tim yang bertugas.
- Breach alert: beri tahu on-call (untuk P1/P2), team lead, dan opsional customer success untuk akun tier tinggi.
Rutekan alert berdasarkan prioritas dan tier agar orang tidak dipage untuk kebisingan P4. Untuk detail lebih lanjut, hubungkan bagian ini ke aturan on-call Anda di /blog/notifications-and-on-call-alerting.
Bangun Logika Triase, Routing, dan Kepemilikan
Triase dan routing adalah tempat aplikasi dukungan prioritas jadi menyelamatkan waktu—atau menciptakan kebingungan. Tujuannya sederhana: setiap permintaan baru harus mendarat di tempat yang tepat dengan cepat, dengan pemilik yang jelas dan langkah selanjutnya yang terlihat.
Buat inbox triase yang bisa diandalkan agen
Mulai dengan inbox triase khusus untuk tiket tidak ditugaskan atau needs-review. Jaga agar cepat dan dapat diprediksi:
- Urutan default berdasarkan sinyal urgensi (priority, SLA due time, customer tier)
- Filter untuk area produk, region/timezone, channel (email/chat/web), dan akun “VIP”
- Tampilan “No owner / No category” yang menyoroti gap kualitas data
Inbox yang baik meminimalkan klik: agen harus bisa klaim, rute ulang, atau eskalasi dari daftar tanpa membuka setiap tiket.
Definisikan aturan routing (dan buat dapat dijelaskan)
Routing harus berbasis aturan, tapi bisa dibaca oleh non-engineer. Input umum:
- Product area (dipilih pengguna, terdeteksi dari form, atau diinfer)
- Keywords dalam subjek/body (mis. “outage”, “invoice”, “SSO”)
- Customer tier (standard vs. priority)
- Region (rutekan ke tim yang sesuai timezone)
Simpan “mengapa” untuk setiap keputusan routing (mis. “Matched keyword: SSO → Auth team”). Itu memudahkan penyelesaian sengketa dan memperbaiki pelatihan.
Override manual dan jalur eskalasi
Bahkan aturan terbaik butuh jalan keluar. Izinkan pengguna berwenang mengoverride routing dan memicu jalur eskalasi seperti:
Agent → Team lead → On-call
Override harus meminta alasan singkat dan membuat entri audit. Jika Anda punya paging on-call, hubungkan tindakan eskalasi ke sana (lihat /blog/notifications-and-on-call-alerting).
Dedupe dan tautkan pekerjaan terkait
Tiket duplikat membuang waktu SLA. Tambahkan alat ringan:
- Sarankan duplikasi potensial berdasarkan pelanggan + subjek serupa + jangka waktu
- Biarkan agen link tiket ke incident induk (“related to INC-123”)
Tiket yang ditautkan harus mewarisi pembaruan status dan pesan publik dari induk.
Aturan kepemilikan: satu nama, satu antrean
Definisikan keadaan kepemilikan yang jelas:
- Single assignee (satu orang yang bertanggung jawab)
- Team queue (tidak ditugaskan dalam tim; gunakan saat handoff sering terjadi)
- Handoff (transfer eksplisit dengan catatan dan checkpoint SLA baru jika perlu)
Tampilkan kepemilikan di mana-mana: tampilan daftar, header tiket, dan log aktivitas. Ketika seseorang bertanya “Siapa yang pegang ini?”, aplikasi harus menjawab segera.
Buat Dasbor Dukungan yang Cepat Digunakan Agen
Aplikasi dukungan prioritas sukses atau gagal dalam 10 detik pertama agen menggunakannya. Dasbor harus menjawab tiga pertanyaan segera: apa yang butuh perhatian sekarang, mengapa, dan apa yang bisa saya lakukan selanjutnya.
Tampilan kunci yang benar-benar dipakai agen
Mulai dengan beberapa tampilan berutilitas tinggi daripada labirin tab:
- Queue (worklist): tampilan default dengan filter untuk priority, SLA status, channel, area produk, dan assignee.
- Ticket detail: dibuka dengan satu klik, dengan konteks dan aksi di atas fold.
- Customer profile: tampilan ringkas tier akun, eskalasi terbaru, insiden aktif, dan kontak kunci.
- SLA board: tampilan berbasis waktu yang menyoroti apa yang akan segera breach, bukan hanya yang sudah terlambat.
Petunjuk visual yang mengurangi beban kognitif
Gunakan sinyal yang jelas dan konsisten sehingga agen tidak perlu “membaca” setiap baris:
- Priority chips (P1–P4) dengan warna + teks yang dapat diakses (jangan hanya warna).
- SLA countdown (mis. “45m to first response”) dan indikator “breach risk”.
- Badge pemblokir (Waiting on customer, Waiting on engineering, Needs approval) agar pekerjaan yang terjebak terlihat.
Jaga tipografi sederhana: satu warna aksen utama, dan hierarki ketat (judul → pelanggan → status/SLA → pembaruan terakhir).
Aksi cepat dan kecepatan triase
Setiap baris tiket harus mendukung aksi cepat tanpa membuka halaman penuh:
- Assign / reassign, escalate, change priority, request info, set blocker, add internal note.
Tambahkan aksi massal (assign, close, apply tag, set blocker) untuk membersihkan backlog dengan cepat.
Keyboard, aksesibilitas, dan “tanpa kejutan”
Dukung shortcut keyboard untuk pengguna power: / untuk mencari, j/k untuk berpindah, e untuk eskalasi, a untuk assign, g lalu q untuk kembali ke queue.
Untuk aksesibilitas, pastikan kontras cukup, focus states terlihat, kontrol diberi label, dan teks status ramah screen reader (mis. “SLA: 12 minutes remaining”). Buat tabel responsif sehingga alur yang sama bekerja di layar lebih kecil tanpa menyembunyikan field kritis.
Notifikasi dan Paging On-Call
Kolaborasi pada Alur Kerja
Ajak pemimpin dan rekan on-call untuk meninjau jalur eskalasi dan izin bersama-sama.
Notifikasi adalah “sistem saraf” aplikasi dukungan prioritas: mereka mengubah perubahan tiket menjadi tindakan tepat waktu. Tujuannya bukan memberi notifikasi lebih banyak—tetapi memberi pada orang yang tepat, di channel yang tepat, dengan konteks cukup untuk merespons.
Mulai dengan set event yang memicu pesan. Jenis bernilai tinggi yang umum meliputi:
- Assignment: tiket ditugaskan atau ditugaskan ulang ke agen atau tim
- Mention: seseorang @mentions agen di catatan internal
- SLA warning: tiket mendekati target first response atau resolution
- SLA breach: target terlewat (dengan alasan jika diketahui)
- Escalation: prioritas naik, eksekutif/pelanggan ditambahkan, atau declared incident
Setiap pesan harus menyertakan ID tiket, nama pelanggan, prioritas, pemilik saat ini, timer SLA, dan deep link ke tiket.
Pilih channel tanpa kehilangan kontrol
Gunakan in-app untuk kerja sehari-hari, dan email untuk pembaruan yang tahan lama dan handoff. Untuk skenario on-call sejati, tambahkan SMS/push sebagai channel opsional yang dikhususkan untuk event mendesak (seperti eskalasi P1 atau breach yang akan terjadi).
Mencegah alert fatigue
Alert fatigue merusak waktu respons. Tambahkan kontrol seperti pengelompokan, jam senyap, dan deduplikasi:
- Gabungkan peringatan SLA yang berulang ke dalam satu thread
- Dedupe fluktuasi “assignment changed” dalam jendela singkat
- Hormati quiet hours dengan override untuk insiden kritis
Template + riwayat pengiriman
Sediakan template untuk pembaruan yang dikirim ke pelanggan dan catatan internal agar nada dan kelengkapan konsisten. Lacak status pengiriman (sent, delivered, failed) dan simpan timeline notifikasi per tiket untuk audit dan tindak lanjut. Tab “Notifications” sederhana di halaman detail tiket mempermudah tinjauan ini.
Halaman Detail Tiket: Kolaborasi dan Komunikasi
Halaman detail tiket adalah tempat pekerjaan eskalasi benar-benar terjadi. Halaman itu harus membantu agen memahami konteks dalam hitungan detik, berkoordinasi dengan rekan, dan berkomunikasi dengan pelanggan tanpa kesalahan.
Pisahkan apa yang dilihat pelanggan vs. yang internal
Buat composer memilih secara eksplisit Customer Reply atau Internal Note, dengan styling berbeda dan preview yang jelas. Catatan internal harus mendukung pemformatan cepat, tautan ke runbook, dan tag privat (mis. “needs engineering”). Balasan pelanggan harus default ke template ramah dan tunjukkan persis apa yang akan dikirim.
Percakapan beruntun + lampiran aman
Dukung thread kronologis yang mencakup email, transkrip chat, dan event sistem. Untuk lampiran, prioritaskan keamanan:
- Pemindaian virus dan allowlist tipe file
- Batas ukuran dan link unduhan yang kadaluarsa
- Peringatan redaksi untuk data sensitif (token, password)
Jika menampilkan file yang diberikan pelanggan, jelaskan siapa yang mengunggah dan kapan.
Makro, quick replies, dan langkah tersimpan
Tambahkan macros yang memasukkan respons pra-disetujui plus checklist troubleshooting (mis. “collect logs,” “restart steps,” “status page wording”). Biarkan tim memelihara perpustakaan macro bersama dengan riwayat versi sehingga eskalasi tetap konsisten dan patuh.
Timeline peristiwa kunci
Di samping pesan, tampilkan timeline event ringkas: perubahan status, pembaruan prioritas, pause/resume SLA, transfer assignee, dan pergeseran level eskalasi. Ini mencegah pertanyaan “apa yang berubah?” dan membantu tinjauan pasca-insiden.
Alat kolaborasi yang tidak menciptakan kebisingan
Aktifkan @mentions, followers, dan tasks yang ditautkan (tiket engineering, dokumen insiden). Mentions harus memberi notifikasi hanya pada orang yang tepat, dan followers harus menerima ringkasan ketika tiket berubah secara material—bukan setiap ketikan.
Keamanan, Privasi, dan Izin
Rencanakan SLA dan Kepemilikan
Gunakan Mode Perencanaan untuk memetakan peran, status, dan aturan SLA sebelum menghasilkan kode.
Keamanan bukan fitur yang ditunda untuk aplikasi eskalasi: eskalasi sering berisi email pelanggan, screenshot, log, dan catatan internal. Bangun pengaman sejak awal agar agen bisa bergerak cepat tanpa membocorkan data atau kehilangan kepercayaan.
Kontrol akses berbasis peran (RBAC) yang cocok untuk kerja dukungan
Mulai dengan set peran kecil yang bisa dijelaskan dalam satu kalimat tiap-tiapnya (mis. Agent, Team Lead, On-Call Engineer, Admin). Lalu definisikan apa yang bisa tiap peran lihat, edit, komentar, tugaskan ulang, dan ekspor.
Pendekatan praktis: “default deny” permissions:
- Visibilitas eskalasi: batasi per tim, antrean, dan akun pelanggan (mis. hanya agen antrean Enterprise yang bisa membuka eskalasi Enterprise).
- Hak edit: izinkan agen mengubah status dan menambah catatan, tapi batasi perubahan SLA, override prioritas, dan pembatalan eskalasi ke lead/admin.
- Field sensitif: perlakukan PII pelanggan (email, telepon), log keamanan, dan lampiran sebagai izin terpisah.
Privasi by design: default least-privilege
Kumpulkan hanya yang dibutuhkan alur kerja. Jika Anda tidak perlu badan pesan lengkap atau alamat IP penuh, jangan simpan. Saat menyimpan data pelanggan, jelaskan field mana yang wajib vs opsional, dan hindari menyalin data dari sistem lain kecuali ada alasan.
Untuk pola akses, asumsikan “agen support melihat minimal data untuk menyelesaikan tiket.” Gunakan scoping akun dan antrean sebelum menambah aturan kompleks.
Lindungi dasar: autentikasi, sesi, dan CSRF
Gunakan autentikasi mapan (SSO/OIDC bila mungkin), minta password kuat bila digunakan, dan dukung multi-factor authentication untuk peran yang meningkat.
Perkuat sesi:
- Cookie Secure, HttpOnly; masa sesi pendek untuk tindakan admin
- Rotasi saat login dan perubahan hak istimewa
- Proteksi CSRF untuk request yang mengubah state
Rahasia, audit log, dan akses sensitif
Simpan rahasia di penyimpanan rahasia terkelola (bukan di source control). Catat akses ke data sensitif (siapa melihat eskalasi, mengunduh lampiran, mengekspor tiket), dan buat audit log sulit diubah serta dapat dicari.
Retensi dan ekspor (tanpa berlebihan)
Tentukan aturan retensi untuk tiket, lampiran, dan audit log (mis. hapus lampiran setelah N hari, simpan audit log lebih lama). Sediakan ekspor untuk pelanggan atau pelaporan internal, tapi hindari mengklaim sertifikasi kepatuhan tertentu kecuali bisa diverifikasi. Alur “data export” sederhana plus workflow admin-only untuk “delete request” adalah awal yang baik.
Pilih Tech Stack dan Arsitektur
Aplikasi eskalasi hanya efektif jika mudah diubah. Aturan eskalasi, SLA, dan integrasi berkembang terus, jadi prioritaskan stack yang tim Anda bisa pelihara dan rekrut untuknya.
Pilih stack yang cocok dengan tim
Pilih alat yang familiar ketimbang yang “sempurna”. Beberapa kombinasi umum dan terbukti:
- React + Node.js (Express/NestJS): baik jika Anda ingin dashboard sangat interaktif dan banyak UI real-time.
- Django (Python): tooling admin kuat, pengembangan CRUD cepat, cocok untuk aplikasi ber-fokus workflow.
- Rails (Ruby): konvensi bagus untuk membangun produk bergaya ticketing dengan cepat.
Jika Anda sudah menjalankan monolith lain, menyamakan ekosistem sering mengurangi waktu onboarding dan kompleksitas operasional.
Jika ingin bergerak lebih cepat tanpa komitmen build engineering besar, Anda juga bisa memprototaip (dan iterasi) alur kerja di platform low-code seperti Koder.ai—terutama untuk bagian standar seperti dashboard agen berbasis React, backend Go/PostgreSQL, dan logika SLA/notifikasi berbasis job.
Penyimpanan data: relasional dulu, pencarian bila perlu
Untuk record inti—tiket, pelanggan, SLA, event eskalasi, penugasan—gunakan database relasional (Postgres umum dipakai). Memberi Anda transaksi, constraint, dan query yang ramah pelaporan.
Untuk pencarian cepat across subject lines, teks percakapan, dan nama pelanggan, pertimbangkan index pencarian nanti (mis. Elasticsearch/OpenSearch). Buat opsional dulu: mulai dengan Postgres full-text search, lalu naik kelas jika perlu.
Background jobs adalah kewajiban
Aplikasi eskalasi bergantung pada pekerjaan berbasis waktu dan integrasi yang tidak boleh dijalankan dalam request web:
- Timer SLA dan pengecekan breach
- Notifikasi (email/SMS/push)
- Paging on-call
- Sinkronisasi pesan dari email/chat/CRM
Gunakan job queue (mis. Celery, Sidekiq, BullMQ) dan buat job idempotent agar retry tidak menciptakan alert duplikat.
Definisikan API sejak dini dan konsisten
Baik pilih REST atau GraphQL, definisikan boundary resource sejak awal: tickets, comments, events, customers, dan users. Gaya API konsisten mempercepat integrasi dan UI. Rencanakan webhook endpoint dari awal (signing secrets, retry, dan rate limits).
Hosting dan lingkungan
Jalankan setidaknya dev/staging/prod. Staging harus meniru setelan prod (provider email, queue, webhook) dengan kredensial test aman. Dokumentasikan langkah deploy dan rollback, dan simpan konfigurasi di environment variables—bukan di kode.
Integrasi: Email, Chat, CRM, dan Webhook
Integrasi membuat aplikasi eskalasi menjadi “tempat kerja” tim Anda, bukan sekadar tempat lain untuk diperiksa. Mulai dengan channel yang dipakai pelanggan Anda, lalu tambahkan hook otomatis agar alat lain bereaksi terhadap event eskalasi.
Email: parsing inbound, pengiriman outbound, threading
Email biasanya integrasi berdampak tinggi. Dukung inbound forwarding (mis. support@) dan parse:
- From/To/Cc, subject, body (prefer plain-text fallback), dan lampiran
- Message-ID dan In-Reply-To untuk threading
- Domain pelanggan dan petunjuk signature untuk penemuan kontak
Untuk outbound, kirim dari tiket (reply/forward) dan pertahankan header threading agar balasan kembali ke tiket yang sama. Simpan timeline percakapan bersih: tunjukkan apa yang pelanggan lihat, bukan catatan internal.
Alat chat (opsional): ubah pesan menjadi tiket
Untuk chat (Slack/Teams/widget intercom-style), buat sederhana: ubah percakapan menjadi tiket dengan transkrip yang jelas dan partisipan. Hindari sinkronisasi setiap pesan secara default—tawarkan tombol “Attach last 20 messages” agar agen mengendalikan kebisingan.
Sinkronisasi CRM/direktori pelanggan: identifikasi tier dan kontak
Sinkron CRM memungkinkan dukungan prioritas otomatis. Tarik company, plan/tier, account owner, dan kontak kunci. Pemetaan akun CRM ke tenant Anda membuat tiket baru bisa mewarisi aturan prioritas segera.
Webhook untuk event kunci
Sediakan webhook untuk event seperti ticket.escalated, ticket.resolved, dan sla.breached. Sertakan payload stabil (ticket ID, timestamps, severity, customer ID) dan tanda request agar penerima dapat memverifikasi.
Dokumentasikan dan permudah setup
Tambahkan flow admin kecil dengan tombol uji (“Send test email”, “Verify webhook”). Simpan dokumennya di satu tempat (mis. /docs/integrations) dan tunjukkan langkah pemecahan masalah umum seperti masalah SPF/DKIM, header threading yang hilang, dan pemetaan field CRM.
Pengujian, Monitoring, dan Keandalan
Bangun MVP Lebih Cepat
Rancang alur eskalasi dan ubahnya menjadi aplikasi yang berfungsi di Koder.ai.
Aplikasi dukungan prioritas menjadi “sumber kebenaran” saat situasi tegang. Jika timer SLA meleset, routing salah, atau izin bocor data, kepercayaan cepat hilang. Anggap keandalan sebagai fitur: uji yang penting, ukur apa yang terjadi, dan rencanakan kegagalan.
Uji aturan yang menggerakkan urgensi
Fokuskan tes otomatis pada logika yang mengubah hasil:
- Perhitungan SLA: kondisi mulai/berhenti, jam kerja, pause, ambang breach, dan timestamp "next due".
- Routing dan kepemilikan: aturan triase, penugasan round-robin/berbasis skill, dan trigger eskalasi.
- Permissions: RBAC untuk antrean, detail tiket, catatan internal, dan pesan yang terlihat pelanggan.
Tambahkan suite end-to-end kecil yang meniru alur agen (create ticket → triage → escalate → resolve) untuk menangkap asumsi yang rusak antara UI dan backend.
Seed data dan skenario realistis
Buat seed data yang berguna lebih dari demo: beberapa pelanggan, multiple tier (standard vs. priority), prioritas bervariasi, dan tiket di berbagai status. Sertakan kasus sulit seperti tiket yang dibuka kembali, “waiting on customer”, dan banyak assignee. Ini membuat latihan triase bermakna dan membantu QA mereproduksi edge case.
Observability: tahu sebelum pelanggan memberi tahu
Instrument aplikasi agar Anda bisa menjawab: “Apa yang gagal, untuk siapa, dan kenapa?”
- Error tracking untuk exception di job SLA/routing.
- Log terstruktur dengan ticket ID, rule ID, dan correlation ID.
- Monitoring performa pada halaman kritis dan worker background.
Load testing dan pemulihan aman
Jalankan load test pada view bertrafik tinggi seperti queues, search, dan dashboards—terutama saat pergantian shift.
Terakhir, siapkan playbook insiden Anda sendiri: feature flags untuk aturan baru, langkah rollback migrasi DB, dan prosedur jelas untuk menonaktifkan automasi sambil menjaga agen tetap produktif.
Rencana Peluncuran, Pelaporan, dan Iterasi
Aplikasi dukungan prioritas hanya “selesai” ketika agen mempercayainya di bawah tekanan. Cara terbaik mencapai itu adalah luncurkan kecil, ukur apa yang benar-benar terjadi, dan iterasi dalam loop singkat.
Mulai dengan MVP yang membuktikan alur kerja
Tahan dorongan untuk merilis semua fitur. Rilis pertama Anda harus mencakup jalur terpendek dari “escalation baru” ke “selesai dengan akuntabilitas”:
- Inbox triase dengan pengurutan jelas (priority, SLA due, customer tier)
- Halaman detail tiket yang mendukung pembaruan cepat dan catatan internal
- Penghitung SLA terlihat (first response dan resolution/next update jika relevan)
- Alert dasar untuk impending breaches dan perubahan status
Jika menggunakan Koder.ai, bentuk MVP ini cocok dengan default umumnya (React UI, layanan Go, PostgreSQL), dan kemampuan snapshot/rollback berguna saat Anda masih menyetel perhitungan SLA, aturan routing, dan batas izin.
Pilot dengan tim kecil dan tinjau mingguan
Roll out ke grup pilot (satu region, satu lini produk, atau satu rotasi on-call) dan lakukan review feedback mingguan. Jaga struktural: apa yang memperlambat agen, data apa yang hilang, notifikasi mana yang bising, dan di mana manajemen eskalasi gagal (handoff, kepemilikan tidak jelas, atau tiket salah rute).
Taktik praktis: simpan changelog ringan di dalam aplikasi agar agen melihat perbaikan dan merasa didengar.
Tambahkan pelaporan yang mendorong aksi, bukan vanity
Setelah penggunaan konsisten, kenalkan laporan yang menjawab pertanyaan operasional:
- Kepatuhan SLA: rate breach menurut prioritas, tier pelanggan, dan channel
- Volume eskalasi: tren dari waktu ke waktu dan lonjakan setelah rilis
- Penyebab utama: tag/alasan yang berkorelasi dengan eskalasi
- Beban agen: tiket terbuka per agen dan waktu ke first-touch
Laporan ini harus mudah diekspor dan mudah dijelaskan ke pemangku kepentingan non-teknis.
Iterasi aturan dan makro menggunakan hasil nyata
Routing dan aturan triase akan salah di awal—dan itu normal. Tuning aturan triase berdasarkan misroutes, waktu penyelesaian, dan feedback on-call. Lakukan hal yang sama untuk macro dan canned replies: hapus yang tidak mengurangi waktu, dan perbaiki yang meningkatkan komunikasi insiden dan kejelasan.
Publikasikan roadmap sederhana dan sumber bantuan
Jaga roadmap pendek dan terlihat dalam produk (“Next 30 days”). Tautkan ke konten bantuan dan FAQ agar pelatihan tidak menjadi pengetahuan suku. Jika Anda memelihara informasi publik, buat mudah ditemukan via link internal seperti /pricing atau /blog sehingga tim bisa self-serve pembaruan dan best practice.