30 Okt 2025·8 menit
Cara Membuat Aplikasi Web untuk Melacak Hasil Eksperimen per Produk
Pelajari cara membangun aplikasi web untuk melacak eksperimen lintas produk: model data, metrik, izin, integrasi, dasbor, dan pelaporan yang andal.
Masalah yang harus diselesaikan aplikasi web ini
Kebanyakan tim tidak gagal dalam eksperimen karena kekurangan ide—mereka gagal karena hasilnya tersebar. Satu produk memiliki grafik di alat analitik, yang lain di spreadsheet, lagi satu di slide deck dengan screenshot. Beberapa bulan kemudian, tak ada yang bisa menjawab pertanyaan sederhana seperti “Apakah kita sudah menguji ini?” atau “Versi mana yang menang, menggunakan definisi metrik apa?”
Masalah inti: hasil terfragmentasi dan kebenaran yang tidak konsisten
Aplikasi pelacakan eksperimen harus memusatkan apa yang diuji, mengapa, bagaimana diukur, dan apa yang terjadi—di seluruh produk dan tim. Tanpa ini, tim membuang waktu membangun ulang laporan, berdebat soal angka, dan menjalankan ulang tes lama karena pembelajaran tidak dapat dicari.
Untuk siapa ini (dan apa yang dibutuhkan masing‑masing kelompok)
Ini bukan hanya alat analis.
- Product manager butuh cara cepat melihat hasil, kepercayaan, dan status keputusan.
- Analis butuh tempat andal untuk mendokumentasikan asumsi, definisi metrik, dan pengecualian.
- Engineer butuh kejelasan tentang feature flag, varian, dan kondisi rollout yang termasuk cakupan.
- Leadership butuh pandangan konsisten tentang dampak di seluruh produk, tanpa deck kustom.
Hasil yang harus dioptimalkan
Tracker yang baik menciptakan nilai bisnis dengan memungkinkan:
- Keputusan lebih cepat (lebih sedikit waktu mengejar tautan dan persetujuan)
- Lebih sedikit kesalahan pelaporan (satu sumber kebenaran untuk “angka final”)
- Pembelajaran bersama (riwayat yang dapat dicari tentang keberhasilan, kegagalan, dan tes netral)
Batasan ruang lingkup yang jelas
Jelasakan: aplikasi ini terutama untuk melacak dan melaporkan hasil eksperimen—bukan untuk menjalankan eksperimen end-to-end. Ia dapat menautkan ke alat yang sudah ada (feature flagging, analitik, data warehouse) sambil memiliki rekaman terstruktur dari eksperimen dan interpretasi final yang disepakati.
Persyaratan: tracker eksperimen minimum yang layak
Tracker eksperimen minimum yang layak harus menjawab dua pertanyaan tanpa harus berburu di dokumen atau spreadsheet: apa yang kita uji dan apa yang kita pelajari. Mulailah dengan sekumpulan entitas dan field kecil yang bekerja lintas produk, lalu kembangkan hanya ketika tim merasakan sakit nyata.
Entitas inti yang perlu didukung
Sederhanakan model data sehingga setiap tim menggunakannya dengan cara yang sama:
- Product: area permukaan (app/site/API) tempat perubahan dikirim.
- Experiment: satu hipotesis dan satu keputusan.
- Variant: kontrol dan satu atau beberapa treatment.
- Metric: pengukuran bernama dengan pemilik dan definisi.
- Segment: pemotongan audiens opsional (pengguna baru, pengguna berbayar, wilayah) untuk pelaporan.
Jenis eksperimen (mulai kecil, tetap fleksibel)
Dukung pola paling umum sejak hari pertama:
- A/B tests (control vs treatment)
- Multivariate tests (beberapa varian)
- Feature flag rollouts (eksposur berbasis persentase)
Meski rollouts awalnya tidak selalu memakai statistik formal, melacaknya bersama eksperimen membantu tim menghindari mengulang “tes” tanpa catatan.
Field minimum yang wajib tiap eksperimen
Saat pembuatan, minta hanya yang diperlukan untuk menjalankan dan menginterpretasikan tes nanti:
- Hipotesis (perubahan apa, untuk siapa, dan mengapa)
- Owner (satu orang yang bertanggung jawab)
- Tanggal mulai/selesai (rencana dan aktual)
- Targeting (aturan kelayakan) dan alokasi (pembagian trafik)
- Tautan ke rollout/flag, tiket, atau spesifikasi (URL relatif seperti /projects/123)
Kriteria keberhasilan dan status keputusan
Buat hasil dapat dibandingkan dengan memaksa struktur:
- Metrik utama (pengukuran keberhasilan utama)
- Guardrails (metrik yang tidak boleh memburuk)
- Status keputusan: proposed → running → analyzed → shipped/rolled back → archived
Jika Anda membangun hanya ini, tim dapat menemukan eksperimen, memahami setup, dan mencatat hasil—bahkan sebelum Anda menambahkan analitik lanjutan atau automasi.
Model data yang bekerja lintas produk
Tracker eksperimen lintas-produk berhasil atau gagal karena model datanya. Jika ID bertabrakan, metrik bergeser, atau segment tidak konsisten, dasbor Anda bisa “tampak benar” sementara menceritakan kisah yang salah.
Pilih identifier yang stabil (dan patuhi)
Mulailah dengan strategi identifier yang jelas:
product_id: stabil saat rename (jangan gunakan display name sebagai kunci)experiment_key: slug yang ramah manusia (mis.checkout_free_shipping_banner) plusexperiment_idyang tak dapat diubahvariant_key: label stabil seperticontrol,treatment_a
Ini memungkinkan Anda membandingkan hasil antar produk tanpa menebak apakah “Web Checkout” dan “Checkout Web” adalah hal yang sama.
Koleksi/tabel inti
Jaga entitas inti kecil dan eksplisit:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (atau anonymous_id), variant_key, assigned_at
- metric_defs: nama metrik, logika numerator/denominator, unit (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Meski komputasi terjadi di tempat lain, menyimpan output (results) memungkinkan dasbor cepat dan riwayat yang andal.
Jendela waktu dan versioning
Metrik dan eksperimen tidak statis. Modelkan:
- time windows (mis. “7 hari pertama setelah assignment”, “minggu kalender”)
- definisi metrik yang versioned: saat perhitungan metrik berubah, buat versi baru alih‑alih mengedit yang lama
Ini mencegah eksperimen bulan lalu berubah saat seseorang memperbarui logika KPI.
Segmen dan jejak audit
Rencanakan segmen konsisten lintas produk: negara, perangkat, tier paket, baru vs kembali.
Terakhir, tambahkan audit trail yang menangkap siapa mengubah apa dan kapan (perubahan status, pembagian trafik, update definisi metrik). Ini penting untuk kepercayaan, review, dan governance.
Definisi metrik dan perhitungan konsisten
Jika tracker eksperimen Anda salah menghitung metrik (atau tidak konsisten antar produk), “hasil” hanyalah opini dengan grafik. Cara tercepat mencegah ini adalah memperlakukan metrik sebagai aset produk bersama—bukan potongan query ad-hoc.
Bangun katalog metrik kanonis
Buat katalog metrik sebagai satu sumber kebenaran untuk definisi, logika perhitungan, dan kepemilikan. Setiap entri metrik harus menyertakan:
- Definisi bahasa-biasa (mendukung keputusan apa)
- Pemilik (orang/tim yang bertanggung jawab atas perubahan)
- Formula tepat dan event/field yang diperlukan
- Aturan inklusi/eksklusi (mis. pengguna internal, bot, order yang dikembalikan)
- Level agregasi valid dan produk yang didukung
Simpan katalog dekat dengan tempat orang bekerja (mis. ditautkan dari alur pembuatan eksperimen) dan versioning sehingga Anda dapat menjelaskan hasil historis.
Standarkan level agregasi
Putuskan sejak awal unit analisis tiap metrik: per user, per session, per account, atau per order. Conversion rate “per user” bisa berbeda dari “per session” meski keduanya benar.
Untuk mengurangi kebingungan, simpan pilihan agregasi dengan definisi metrik, dan wajibkan saat eksperimen disiapkan. Jangan biarkan tiap tim memilih unit secara ad‑hoc.
Tangani konversi tertunda dan atribusi
Banyak produk punya jendela konversi (mis. mendaftar hari ini, membeli dalam 14 hari). Definisikan aturan atribusi konsisten:
- Kapan jam mulai dihitung (waktu exposure, kunjungan pertama, waktu assignment)?
- Apa yang dihitung sebagai konversi jika pengguna diekspos berkali-kali?
- Bagaimana menangani perjalanan lintas‑perangkat atau lintas‑produk?
Buat aturan ini terlihat di dasbor sehingga pembaca tahu apa yang mereka lihat.
Simpan hitungan mentah dan statistik terkomputasi
Untuk dasbor cepat dan auditabilitas, simpan keduanya:
- Hitungan mentah (exposures, converters, penjumlahan revenue, input varians)
- Statistik terkomputasi (lift, interval kepercayaan, p-value)
Ini memungkinkan rendering cepat sambil tetap memberi kemampuan recompute saat definisi berubah.
Konvensi penamaan mencegah proliferasi metrik
Adopsi standar penamaan yang menyandikan makna (mis. activation_rate_user_7d, revenue_per_account_30d). Wajibkan ID unik, terapkan alias, dan tandai near-duplicates saat pembuatan metrik untuk menjaga katalog tetap bersih.
Pengumpulan data: event, pipeline, dan pengecekan kualitas
Tracker eksperimen Anda hanya seandalan data yang masuk. Tujuannya adalah menjawab dua pertanyaan untuk setiap produk: siapa yang diekspos ke varian mana, dan apa yang mereka lakukan setelahnya? Semua hal lain—metrik, statistik, dasbor—bergantung pada pondasi itu.
Pilih pendekatan ingestion
Kebanyakan tim memilih salah satu pola ini:
- Event stream (near real-time): Bagus untuk pembacaan cepat dan debugging lebih cepat. Memerlukan kematangan engineering lebih untuk tetap stabil.
- Daily batch: Lebih sederhana dioperasikan dan lebih murah. Terbaik bila keputusan tidak perlu jam‑jam.
- Hybrid: Stream exposures dan event kritis (agar assignment dapat divalidasi cepat), batch sisanya untuk kelengkapan dan kontrol biaya.
Apa pun yang dipilih, standarkan set event minimum lintas produk: exposure/assignment, event konversi kunci, dan konteks cukup untuk join (user ID/device ID, timestamp, experiment ID, variant).
Peta event produk ke metrik (dan validasi kelengkapan)
Definisikan peta jelas dari event mentah ke metrik yang dilaporkan tracker (mis. purchase_completed → Revenue, signup_completed → Activation). Pertahankan pemetaan ini per produk, tapi pakai penamaan konsisten agar dashboard A/B test membandingkan yang sepadan.
Validasi kelengkapan sejak awal:
- Pastikan setiap exposure punya experiment ID dan variant.
- Pastikan event konversi menyertakan field identitas yang sama untuk join exposure.
- Waspadai drop-off event antara client, server, dan warehouse (mobile SDK sering jadi penyebab).
Pengecekan kualitas data yang harus diotomasi
Buat pengecekan yang berjalan tiap load dan memicu kegagalan keras:
- Missing exposure events: konversi tanpa exposure sebelumnya (sering bug instrumentasi atau mismatch identitas).
- Skewed allocations: varian menerima 70/30 saat diharapkan 50/50 (bisa jadi bug targeting).
- Timestamp sanity: exposure setelah konversi, atau delay besar yang menunjuk masalah jam.
Tampilkan ini di aplikasi sebagai peringatan yang terikat ke eksperimen, bukan disembunyikan di log.
Backfill dan reprocessing
Pipeline berubah. Saat Anda memperbaiki bug instrumentasi atau logika deduplikasi, Anda perlu memproses ulang data historis agar metrik dan KPI konsisten.
Rencanakan untuk:
- Transformasi versioned (supaya Anda tahu logika mana yang menghasilkan hasil)
- Backfill aman (batasi scope menurut tanggal/produk/eksperimen)
- Jejak audit recomputation
Dokumentasikan integrasi
Perlakukan integrasi sebagai fitur produk: dokumentasikan SDK yang didukung, skema event, dan langkah pemecahan masalah. Jika Anda punya area docs, tautkan sebagai path relatif seperti /docs/integrations.
Statistik dan perhitungan hasil yang dapat dipercaya
Atur katalog metrik
Buat definisi metrik versi sehingga hasil tetap dapat dibandingkan seiring waktu.
Jika orang tidak mempercayai angka, mereka tidak akan menggunakan tracker. Tujuannya bukan memukau dengan matematika—tetapi membuat keputusan dapat diulang dan dapat dipertahankan lintas produk.
Pilih satu “dialek” statistik dan patuhi
Putuskan sejak awal apakah aplikasi akan melaporkan hasil frequentist (p-values, confidence intervals) atau Bayesian (probabilitas meningkat, credible intervals). Keduanya bisa bekerja, tetapi mencampurnya antar produk menyebabkan kebingungan (“Kenapa tes ini menunjukkan 97% chance to win, sementara yang lain p=0.08?”).
Aturan praktis: pilih pendekatan yang organisasi Anda sudah pahami, lalu standarkan terminologi, default, dan ambang.
Definisikan dengan tepat apa yang ditampilkan UI
Setidaknya, tampilan hasil harus membuat item ini tidak ambigu:
- Lift (absolut dan/atau relatif) terhadap kontrol
- Interval (confidence interval atau credible interval) ditampilkan sebagai rentang, bukan hanya estimasi titik
- Kekuatan bukti (p-value untuk frequentist, atau probabilitas mengalahkan kontrol untuk Bayesian)
Tampilkan juga jendela analisis, unit yang dihitung (users, sessions, orders), dan versi definisi metrik yang digunakan. Detail ini membedakan antara pelaporan konsisten dan perdebatan.
Multiple comparisons dan kebijakan “peeking”
Jika tim menguji banyak varian, banyak metrik, atau memeriksa hasil tiap hari, false positive menjadi mungkin. Aplikasi Anda harus mengodekan kebijakan alih‑alih membiarkannya ke tiap tim:
- Multiple comparisons: putuskan apakah Anda menyesuaikan (mis. kontrol false discovery rate) atau menandai hasil sebagai “unadjusted exploratory”.
- Repeated peeking: baik (1) melarangnya dengan tanggal akhir tetap dan status “finalized”, atau (2) mendukung metode sekuensial dan menampilkan panduan “safe-to-stop”.
Guardrails yang menangkap mode kegagalan umum
Tambahkan flag otomatis yang muncul di samping hasil, bukan tersembunyi di log:
- Sample Ratio Mismatch (SRM): peringatan saat pembagian trafik menyimpang dari alokasi yang diharapkan.
- Deteksi anomali: tandai penurunan/kenaikan mendadak pada trafik, konversi, atau revenue yang bisa menandakan pemutusan tracking, outage, atau traffic bot.
Penjelasan dengan bahasa sederhana
Di samping angka, tambahkan penjelasan singkat yang dapat dipercaya pembaca non-teknis, mis. “Estimasi terbaik adalah +2.1% lift, tetapi efek sebenarnya bisa berada antara -0.4% dan +4.6%. Kita belum memiliki bukti kuat untuk menyatakan pemenang.”
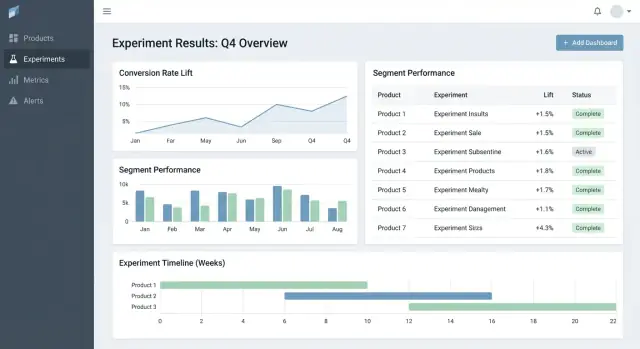
UX dan dasbor untuk pengambilan keputusan cepat
Alat eksperimen yang baik membantu orang menjawab dua pertanyaan cepat: Apa yang harus saya lihat selanjutnya? dan Apa yang harus kita lakukan? UI harus meminimalkan berburu konteks dan membuat “status keputusan” jelas.
Halaman kunci untuk mengakar alur kerja
Mulai dengan tiga halaman yang menutupi sebagian besar penggunaan:
- Experiments list: antrean yang bisa diurutkan untuk seluruh organisasi (atau per produk).
- Experiment detail: satu sumber kebenaran untuk setup, hasil, dan keputusan.
- Product overview: ringkasan tes aktif, keputusan terbaru, dan kesehatan metrik untuk satu produk.
Pada list dan halaman produk, buat filter cepat dan persistennya: product, owner, rentang tanggal, status, primary metric, dan segment. Orang harus bisa menyaring ke “Eksperimen Checkout, dimiliki Maya, berjalan bulan ini, metrik utama = conversion, segment = new users” dalam hitungan detik.
Status keputusan yang dapat dipercaya
Perlakukan status sebagai kosakata terkontrol, bukan teks bebas:
Draft → Running → Stopped → Shipped / Rolled back
Tampilkan status di mana‑mana (baris list, header detail, dan tautan bagikan) dan catat siapa yang mengubahnya dan mengapa. Ini mencegah “peluncuran diam‑diam” dan hasil yang tidak jelas.
Tabel hasil yang membuat keputusan jelas
Di tampilan detail eksperimen, utamakan tabel hasil ringkas per metrik:
- Baseline
- Variant
- Lift
- Ketidakpastian (confidence interval atau credible interval)
- Catatan (mis. caveat instrumentasi, quirks segment)
Simpan chart lanjutan di balik bagian “More details” agar pengambil keputusan tidak kewalahan.
Sharing dan ekspor tanpa kehilangan kontrol
Tambahkan CSV export untuk analis dan shareable links untuk pemangku kepentingan, tetapi terapkan akses: tautan harus menghormati peran dan izin produk. Tombol sederhana “Copy link” plus aksi “Export CSV” memenuhi sebagian besar kebutuhan kolaborasi.
Izin, privasi, dan governance
Masuk ke lingkungan langsung
Sebarkan dan host tracker Anda agar tim bisa mulai menggunakannya saat Anda mengembangkan.
Jika tracker Anda mencakup banyak produk, kontrol akses dan auditabilitas bukan opsional. Mereka adalah alasan alat ini aman diadopsi lintas tim dan dapat dipertanggungjawabkan saat review.
Kontrol akses berbasis peran (RBAC)
Mulai dengan set peran sederhana dan pertahankan konsistensi di seluruh aplikasi:
- Viewer: akses read-only ke eksperimen, hasil, dan dasbor.
- Editor: membuat/mengedit eksperimen, mengunggah dokumen pendukung, set status (draft → running → concluded).
- Admin: mengelola pengguna, izin, definisi metrik, aturan retensi, dan integrasi.
Pusatkan keputusan RBAC (satu lapisan kebijakan), sehingga UI dan API menegakkan aturan yang sama.
Izin berbasis produk dan baris
Banyak organisasi butuh akses berskala produk: Tim A bisa melihat eksperimen Produk A tapi bukan Produk B. Modelkan ini secara eksplisit (mis. user ↔ product memberships), dan pastikan setiap query difilter berdasarkan produk.
Untuk kasus sensitif (mis. data partner, segmen yang diatur), tambahkan pembatasan baris di atas pembatasan produk. Pendekatan praktis adalah memberi tag sensitivitas pada eksperimen (atau potongan hasil) dan memerlukan izin tambahan untuk melihatnya.
Jejak audit: akses + riwayat perubahan
Log dua hal terpisah:
- Change logs: siapa mengedit eksperimen, definisi metrik, atau keputusan—apa yang berubah dan kapan.
- Access logs: siapa melihat atau mengekspor hasil (terutama untuk eksperimen sensitif).
Tampilkan riwayat perubahan di UI untuk transparansi, dan simpan log lebih dalam untuk investigasi.
Aturan retensi dan penghapusan
Tentukan aturan retensi untuk:
- Metadata eksperimen (hipotesis, pemilik, tanggal, catatan keputusan)
- Hasil terkomputasi (effect sizes, confidence intervals, flag signifikansi)
Buat retensi dapat dikonfigurasi menurut produk dan sensitivitas. Saat data harus dihapus, simpan catatan minimal (ID, waktu penghapusan, alasan) untuk mempertahankan integritas pelaporan tanpa menyimpan konten sensitif.
Fitur alur kerja: dari ide ke perpustakaan pembelajaran
Tracker menjadi benar-benar berguna saat mencakup siklus hidup eksperimen penuh, bukan hanya p-value akhir. Fitur alur kerja mengubah docs, tiket, dan grafik yang tersebar menjadi proses yang dapat diulang yang meningkatkan kualitas dan membuat pembelajaran mudah digunakan ulang.
Alur hidup: idea → review → run → post‑mortem
Modelkan eksperimen sebagai rangkaian state (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Setiap state harus memiliki “exit criteria” jelas sehingga eksperimen tidak hidup tanpa elemen esensial seperti hipotesis, metrik utama, dan guardrails.
Persetujuan tidak perlu berat. Langkah reviewer sederhana (mis. product + data) plus jejak audit siapa yang menyetujui apa dan kapan bisa mencegah kesalahan yang dapat dihindari. Setelah selesai, wajibkan post‑mortem singkat sebelum eksperimen ditandai “Published” agar hasil dan konteks tertangkap.
Template yang menstandarisasi pemikiran
Tambahkan template untuk:
- Brief eksperimen (tujuan, hipotesis, audiens target, metrik keberhasilan, guardrails, rencana rollout)
- Catatan analisis (sumber data, eksklusi, pengecekan sanity, interpretasi, risiko)
Template mengurangi gesekan “halaman kosong” dan mempercepat review karena semua orang tahu di mana mencari. Biarkan template bisa diedit per produk sambil mempertahankan inti yang sama.
Pembelajaran: tautkan semuanya, buat dapat dicari
Eksperimen jarang berdiri sendiri—orang butuh konteks sekitarnya. Biarkan pengguna melampirkan tautan ke tiket/spesifikasi dan tulis ulang terkait (mis. /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Simpan field “Learning” terstruktur seperti:
- Apa yang berubah (keputusan)
- Apa yang kita pelajari (insight)
- Apa yang harus dilakukan selanjutnya (tindak lanjut)
Notifikasi untuk guardrails dan perubahan hasil
Dukung notifikasi saat guardrails memburuk (mis. error rate, pembatalan) atau saat hasil berubah secara material setelah data terlambat atau perhitungan metrik ulang. Buat notifikasi bersifat actionable: tampilkan metrik, threshold, timeframe, dan pemilik untuk mengakui atau eskalasi.
Tampilan perpustakaan untuk menggunakan ulang pekerjaan masa lalu
Sediakan perpustakaan yang bisa disaring menurut produk, area fitur, audiens, metrik, hasil, dan tag (mis. “pricing,” “onboarding,” “mobile”). Tambahkan saran “eksperimen serupa” berdasarkan tag/metrik bersama agar tim tidak mengulang tes yang sama dan justru membangun dari pembelajaran sebelumnya.
Arsitektur dan opsi tech stack
Anda tidak perlu stack “sempurna” untuk membangun aplikasi pelacakan eksperimen—tetapi Anda butuh batasan yang jelas: di mana data tinggal, di mana perhitungan dijalankan, dan bagaimana tim mengakses hasil secara konsisten.
Stack baseline praktis
Untuk banyak tim, setup sederhana dan skalabel terlihat seperti:
- Frontend: React (atau Vue) untuk dasbor dan alur kerja
- Backend API: Node.js/Express, Python/FastAPI, atau Java/Spring—pilih yang tim Anda bisa pelihara
- Database: Postgres untuk data aplikasi (eksperimen, definisi metrik, izin)
- Analytics warehouse: BigQuery/Snowflake/Redshift untuk data event dan agregasi besar
Pembagian ini menjaga workflow transaksional tetap cepat sementara warehouse menangani komputasi skala besar.
Jika Anda ingin membuat prototipe UI workflow cepat (experiments list → detail → readout) sebelum commit ke siklus engineering penuh, platform vibe-coding seperti Koder.ai dapat membantu menghasilkan fondasi React + backend dari spesifikasi chat. Berguna untuk mengeluarkan entitas, form, scaffolding RBAC, dan CRUD yang audit‑friendly, lalu iterasi kontrak data dengan tim analitik Anda.
Di mana perhitungan metrik sebaiknya berada?
Umumnya ada tiga opsi:
- Warehouse-first: model SQL menghitung metrik dan tabel hasil eksperimen. Aplikasi hanya membaca.
- Backend jobs: worker menghitung hasil secara terjadwal atau saat eksperimen berubah.
- Hybrid: agregasi kanonis di warehouse, dengan post-processing backend (formatting, guardrails, caching).
Warehouse-first sering paling sederhana jika tim data sudah menguasai SQL tepercaya. Backend-heavy bekerja bila butuh update low-latency atau logika khusus, tapi menambah kompleksitas aplikasi.
Performa: cache dan precompute
Dasbor eksperimen sering mengulang query yang sama (KPI top-line, time series, potongan segment). Rencanakan untuk:
- Precompute rollups (agregat metrik harian per eksperimen/variant/segment)
- Cache pembacaan mahal di lapisan API (mis. Redis) dengan aturan invalidasi jelas
- Gunakan materialized views atau tabel terjadwal di warehouse untuk dasbor umum
Multi-tenant vs single-tenant
Jika Anda mendukung banyak produk atau unit bisnis, putuskan awal:
- Single-tenant (shared schema): lebih mudah dioperasikan, tetapi memerlukan penyaringan izin yang ketat.
- Multi-tenant: schema/proyek terpisah per produk/tim untuk isolasi lebih kuat, tapi lebih overhead.
Kompromi umum adalah infrastruktur bersama dengan model tenant_id yang kuat dan enforcement akses baris.
Definisikan API inti
Jaga surface API kecil dan eksplisit. Kebanyakan sistem butuh endpoint untuk experiments, metrics, results, segments, dan permissions (plus read yang audit-friendly). Ini memudahkan menambah produk tanpa menulis ulang plumbing.
Testing, monitoring, dan operasi yang andal
Tambahkan tampilan mobile
Buat aplikasi pendamping Flutter untuk pembacaan cepat dan pengecekan status.
Tracker eksperimen hanya berguna jika orang mempercayainya. Kepercayaan itu datang dari testing disiplin, monitoring jelas, dan operasi yang dapat diprediksi—terutama saat banyak produk dan pipeline memberi makan dashboard yang sama.
Observability yang sesuai cara orang menggunakan aplikasi
Mulai dengan logging terstruktur untuk setiap langkah penting: ingestion event, assignment, rollup metrik, dan komputasi hasil. Sertakan identifier seperti product, experiment_id, metric_id, dan pipeline run_id agar support bisa menelusuri satu hasil kembali ke inputnya.
Tambahkan metrik sistem (latensi API, runtime job, queue depth) dan metrik data (event diproses, % event terlambat, % drop karena validasi). Lengkapi dengan tracing antar layanan agar bisa menjawab, “Mengapa eksperimen ini kehilangan data kemarin?”
Pengecekan kelayakan data (data freshness) adalah cara tercepat mencegah kegagalan diam. Jika SLA “harian jam 9 pagi”, monitor freshness per produk dan sumber, dan alert saat:
- partisi terbaru hilang
- volume event menyimpang tajam dari baseline
- job rollup selesai tapi menghasilkan nol baris
Tes otomatis: lindungi data dan matematika
Buat tes pada tiga level:
- Skema dan constraints: field wajib, keunikan (mis. satu assignment per user per eksperimen), foreign keys, dan rentang tanggal valid.
- Izin: tes RBAC (viewer/editor/admin), dan scoping produk agar tim hanya melihat yang semestinya.
- Matematika hasil: unit test untuk lift, confidence intervals, flag signifikansi, dan kasus tepi (sample kecil, nol denominator, banyak varian).
Simpan dataset kecil “golden” dengan output terknown agar Anda bisa mendeteksi regresi sebelum merilis.
Deploy, migrasi, dan keamanan historis
Perlakukan migrasi sebagai bagian operasi: versioning definisi metrik dan logika komputasi hasil, dan hindari menulis ulang eksperimen historis kecuali diminta eksplisit. Saat perubahan diperlukan, berikan jalur backfill terkontrol dan dokumentasikan apa yang berubah di jejak audit.
Alat admin untuk insiden dan reprocessing
Sediakan tampilan admin untuk menjalankan ulang pipeline untuk eksperimen/rentang tanggal spesifik, memeriksa error validasi, dan menandai insiden dengan pembaruan status. Tautkan catatan insiden langsung dari eksperimen terdampak agar pengguna memahami keterlambatan dan tidak membuat keputusan berdasarkan data yang tidak lengkap.
Rencana rollout dan jebakan umum yang harus dihindari
Meluncurkan aplikasi pelacakan eksperimen lintas produk lebih sedikit tentang “hari peluncuran” dan lebih banyak tentang mengurangi ambiguitas secara bertahap: apa yang dilacak, siapa yang memilikinya, dan apakah angka cocok dengan kenyataan.
Urutan rollout yang praktis
Mulai dengan satu produk dan set metrik kecil dan tepercaya (mis. conversion, activation, revenue). Tujuannya adalah memvalidasi alur end-to-end—membuat eksperimen, menangkap exposure dan outcome, menghitung hasil, dan merekam keputusan—sebelum Anda menambah kompleksitas.
Setelah produk pertama stabil, perluas produk demi produk dengan ritme onboarding yang dapat diprediksi. Setiap produk baru harus terasa seperti setup yang dapat diulang, bukan proyek kustom.
Jika organisasi Anda cenderung tersangkut di siklus “pembangunan platform” panjang, pertimbangkan pendekatan dua‑jalur: bangun kontrak data yang tahan lama (event, ID, definisi metrik) paralel dengan lapisan aplikasi tipis. Tim kadang menggunakan Koder.ai untuk menyiapkan lapisan tipis itu dengan cepat—form, dasbor, izin, dan ekspor—lalu menguatkannya seiring adopsi (termasuk ekspor kode sumber dan rollback iteratif via snapshot saat kebutuhan berubah).
Checklist rollout untuk setiap produk baru
Gunakan checklist ringan untuk onboarding produk dan skema event secara konsisten:
- Konfirmasi taksonomi event dan konvensi penamaan (dan siapa yang dapat mengubahnya)
- Verifikasi event exposure ada dan dapat dikaitkan unik ke user/session
- Peta metrik ke skema event produk (termasuk edge case seperti refund, pembatalan)
- Jalankan backfill atau periode parallel-run untuk membandingkan dengan analitik yang ada
- Tetapkan kepemilikan untuk setup eksperimen, validasi data, dan catatan keputusan final
Di mana membantu adopsi, tautkan “next steps” dari hasil eksperimen ke area produk terkait (mis. eksperimen terkait pricing dapat menautkan ke /pricing). Jaga tautan informatif dan netral—tanpa implikasi hasil.
Pantau adopsi agar dapat memperbaiki gesekan lebih awal
Ukur apakah alat menjadi tempat default untuk keputusan:
- Weekly active users menurut peran (PM, analis, engineer)
- Eksperimen yang dibuat dan diselesaikan
- Persentase dengan catatan keputusan terisi (bukan hanya hasil yang dilihat)
- Waktu dari akhir eksperimen → keputusan dicatat
Jebakan umum yang harus dihindari
Seringkali rollout tersandung pada beberapa masalah berulang:
- Definisi metrik tidak konsisten antar produk (nama sama, rumus berbeda)
- Tracking exposure hilang atau cacat, menyebabkan hasil bias
- Kepemilikan tidak jelas untuk validasi dan sign-off, memicu eksperimen ‘zombie’
- Perubahan skema diam‑diam yang merusak tren tanpa ada yang menyadari
- Menskalakan ke banyak metrik terlalu cepat, sebelum workflow inti dipercaya
Pertanyaan umum
Masalah apa yang sebenarnya diselesaikan oleh aplikasi pelacakan eksperimen?
Mulailah dengan memusatkan catatan akhir yang disepakati dari setiap eksperimen:
- apa yang diuji (hipotesis, varian)
- di mana dijalankan (produk)
- bagaimana diukur (definisi metrik + versi)
- apa hasilnya (hasil, ketidakpastian, keputusan)
Anda bisa menautkan ke alat feature-flag dan sistem analitik, tetapi tracker harus memiliki riwayat terstruktur agar hasil tetap dapat dicari dan dibandingkan dari waktu ke waktu.
Apakah tracker eksperimen harus menjalankan eksperimen end-to-end?
Tidak—fokuskan ruang lingkup pada pelacakan dan pelaporan hasil.
MVP praktis:
- menyimpan metadata eksperimen (pemilik, tanggal, targeting, pembagian trafik)
- menyimpan definisi metrik (dengan versi)
- menyimpan hasil terkomputasi (lift + ketidakpastian) dan catatan keputusan
- menautkan ke sistem eksternal (flag, tiket, dashboard)
Ini menghindari membangun ulang seluruh platform eksperimen sambil memperbaiki masalah “hasil yang tersebar.”
Entitas inti apa yang harus dimasukkan dalam model data MVP?
Model minimum yang bekerja antar-tim adalah:
Bagaimana desain identifier agar hasil tetap konsisten antar produk?
Gunakan ID yang stabil dan jadikan label tampilan dapat diubah:
product_id: tidak pernah berubah, walau nama produk berubahexperiment_id: ID internal yang tak dapat diubah- : slug yang mudah dibaca (unik per produk jika perlu)
Field apa yang harus diwajibkan saat membuat eksperimen?
Buat “kriteria keberhasilan” eksplisit saat setup:
- wajibkan satu metrik utama (driver keputusan)
- definisikan guardrails (metrik yang tidak boleh memburuk)
- simpan status keputusan terkontrol (mis. Draft → Running → Analyzed → Shipped/Rolled back → Archived)
Struktur ini mengurangi perdebatan kemudian karena pembaca melihat apa arti “menang” sebelum tes dijalankan.
Bagaimana cara mencegah definisi metrik yang tidak konsisten antar tim?
Buat katalog metrik kanonis dengan:
- definisi bahasa-biasa + tujuan keputusan
- formula tepat dan event/field yang dibutuhkan
- aturan inklusi/eksklusi (bot, pengguna internal, refund)
- unit analisis (user/session/order/account)
- kepemilikan dan versioning
Saat logika berubah, publikasikan versi metrik baru daripada mengubah sejarah—lalu simpan versi mana yang digunakan tiap eksperimen.
Instrumentasi dan pengecekan kualitas data minimum apa yang diperlukan?
Minimal instrumentasi dan pengecekan kualitas data:
- event assignment/exposure yang memuat experiment ID dan variant
- event konversi utama dengan field identitas yang cocok (user/device/account)
- timestamp yang dapat dipercaya untuk jendela atribusi
Otomatiskan pengecekan seperti:
Haruskah kita memakai statistik frequentist atau Bayesian dalam tracker?
Pilih satu “dialek” statistik dan konsisten:
- Frequentist: p-value + confidence intervals
- Bayesian: probability of improvement + credible intervals
Apa pun yang dipilih, selalu tampilkan:
- lift vs control
- interval (rentang, bukan hanya titik)
- jendela analisis, unit yang dihitung, dan versi definisi metrik
Fitur izin dan governance apa yang penting untuk tracker lintas-produk?
Perlakukan kontrol akses sebagai fondasi:
- RBAC: Viewer / Editor / Admin
- Akses skop produk: pengguna hanya melihat produk yang mereka miliki
- opsi pembatasan baris untuk eksperimen sensitif
Simpan dua jejak audit terpisah:
Bagaimana sebaiknya kita melakukan rollout tracker dan jebakan apa yang harus diwaspadai?
Urutkan rollout yang bisa diulang:
- mulai dengan satu produk dan satu set metrik yang kecil (mis. conversion, activation, revenue)
- validasi end-to-end: assignment → joins → metrics → results → decision notes
- perluas produk demi produk dengan checklist onboarding yang sama
Hindari jebakan umum: