13 Nov 2025·8 menit
Bagaimana Basis Data NoSQL Muncul untuk Mengatasi Masalah Skalabilitas dan Fleksibilitas
Pelajari mengapa basis data NoSQL muncul: skala web, kebutuhan data yang fleksibel, dan keterbatasan sistem relasional—plus model utama dan komprominya.
Masalah Apa yang Ingin Diselesaikan NoSQL?
NoSQL muncul ketika banyak tim menemukan ketidakcocokan antara kebutuhan aplikasi mereka dan apa yang dioptimalkan oleh basis data relasional tradisional (basis data SQL). SQL tidak “gagal” — tetapi pada skala web, beberapa tim mulai memprioritaskan tujuan yang berbeda.
Dua tekanan utama: skala dan perubahan
Pertama, skala. Aplikasi konsumen populer mulai melihat lonjakan lalu lintas, tulis konstan, dan volume besar data yang dihasilkan pengguna. Untuk beban kerja ini, “tinggal beli server yang lebih besar” menjadi mahal, lambat diimplementasikan, dan akhirnya dibatasi oleh ukuran mesin terbesar yang bisa dioperasikan.
Kedua, perubahan. Fitur produk berkembang cepat, dan data di belakangnya tidak selalu cocok ke dalam himpunan tabel yang tetap. Menambahkan atribut baru ke profil pengguna, menyimpan beberapa tipe event, atau mengimpor JSON semi-terstruktur dari berbagai sumber sering berarti migrasi skema berulang dan koordinasi antar-tim.
Mengapa basis data relasional kesulitan pada kasus tertentu
Basis data relasional sangat baik dalam menegakkan struktur dan memungkinkan kueri kompleks di tabel yang dinormalisasi. Tapi beberapa beban kerja skala besar membuat keunggulan itu sulit dimanfaatkan:
- Banyak tulis konkuren di banyak tabel dapat menciptakan kontensi.
- Kueri berat yang bergantung pada join bisa menjadi mahal seiring pertumbuhan data.
- Penskalalaan horizontal di banyak mesin memungkinkan, tetapi mengoperasikannya sambil menjaga konsistensi ketat di mana-mana bisa rumit.
Hasilnya: beberapa tim mencari sistem yang menukar beberapa jaminan dan kemampuan untuk mendapatkan penskalaan yang lebih sederhana dan iterasi yang lebih cepat.
NoSQL: keluarga pendekatan, bukan satu hal
NoSQL bukan satu basis data tunggal atau desain. Istilah payung ini mencakup sistem yang menekankan kombinasi beberapa hal seperti:
- Penskalaan horizontal (menambah lebih banyak mesin)
- Model data fleksibel
- Pola akses yang dioptimalkan untuk kebutuhan aplikasi tertentu
Mengatur ulang ekspektasi
NoSQL tidak pernah dimaksudkan sebagai pengganti universal untuk SQL. Ini adalah kumpulan kompromi: Anda bisa mendapatkan skalabilitas atau fleksibilitas skema, tetapi mungkin menerima jaminan konsistensi yang lebih lemah, opsi kueri ad-hoc yang terbatas, atau tanggung jawab lebih besar dalam pemodelan data di tingkat aplikasi.
Mengapa Penskalalan Tradisional Mulai Gagal
Selama bertahun-tahun, jawaban standar untuk basis data yang lambat sederhana: beli server yang lebih besar. Tambah CPU, RAM, disk lebih cepat, dan pertahankan skema serta model operasional yang sama. Pendekatan “skala vertikal” ini bekerja—sampai tidak lagi praktis.
Penskalalan vertikal menghadapi batas keras
Mesin kelas atas cepat menjadi mahal, dan kurva harga/performanya akhirnya tidak ramah. Upgrade sering memerlukan persetujuan anggaran besar yang jarang dan jendela pemeliharaan untuk memindahkan data dan cutover. Bahkan jika Anda mampu membeli hardware lebih besar, satu server tetap memiliki batas: satu bus memori, satu subsistem penyimpanan, dan satu node utama yang menyerap beban tulis.
Pertumbuhan mengubah bentuk beban kerja
Seiring produk tumbuh, basis data menghadapi tekanan baca/tulis konstan, bukan puncak sesekali. Lalu lintas menjadi benar-benar 24/7, dan fitur tertentu menciptakan pola akses yang tidak merata. Sebagian kecil baris atau partisi yang sering diakses bisa mendominasi lalu lintas, menghasilkan tabel panas (hot tables) atau key panas (hot keys) yang memperlambat semuanya.
Bottleneck operasional menjadi umum:
- Pembengkakan indeks saat fitur baru membutuhkan indeks sekunder
- Kontensi dari banyak tulis konkuren yang mengenai tabel sama
- Tunggu kunci yang membuat latensi tidak dapat diprediksi di bawah beban
- Lag replikasi dan failover yang lebih lambat seiring dataset tumbuh
Server lebih besar tidak menyelesaikan ketersediaan global
Banyak aplikasi juga perlu tersedia di beberapa wilayah, bukan hanya cepat di satu data center. Satu basis data “utama” di satu lokasi meningkatkan latensi untuk pengguna jauh dan membuat outage lebih katastrofik. Pertanyaannya bergeser dari “Bagaimana kita membeli kotak yang lebih besar?” menjadi “Bagaimana kita menjalankan basis data di banyak mesin dan lokasi?”
Kebutuhan Model Data yang Fleksibel
Basis data relasional unggul ketika bentuk data stabil. Tetapi banyak produk modern tidak tetap statis. Skema tabel memang sengaja ketat: setiap baris mengikuti set kolom, tipe, dan constraint yang sama. Kepastian itu berharga—sampai Anda melakukan iterasi cepat.
Skema kaku dan biaya nyata perubahan
Dalam praktiknya, perubahan skema yang sering bisa mahal. Pembaruan yang tampak kecil mungkin memerlukan migrasi, backfill, update indeks, penjadwalan deployment yang terkoordinasi, dan perencanaan kompatibilitas agar jalur kode lama tidak rusak. Pada tabel besar, menambahkan kolom atau mengubah tipe bisa menjadi operasi yang memakan waktu dengan risiko operasional nyata.
Gesekan itu mendorong tim menunda perubahan, menumpuk solusi sementara, atau menyimpan blob berantakan di field teks—semua itu bukan ideal untuk iterasi cepat.
Data semi-terstruktur cocok dengan evolusi produk
Banyak data aplikasi bersifat semi-terstruktur: objek bersarang, field opsional, dan atribut yang berevolusi dari waktu ke waktu.
Misalnya, “profil pengguna” mungkin dimulai dengan nama dan email, lalu berkembang menjadi preferensi, akun tertaut, alamat pengiriman, pengaturan notifikasi, dan flag eksperimen. Tidak setiap pengguna punya semua field itu, dan field baru muncul secara bertahap. Model gaya dokumen bisa menyimpan bentuk bersarang dan tidak seragam langsung tanpa memaksa setiap record ke template kaku yang sama.
Iterasi lebih cepat, lebih sedikit join canggung
Fleksibilitas juga mengurangi kebutuhan untuk join kompleks pada bentuk data tertentu. Ketika satu layar membutuhkan objek yang tersusun (mis. order dengan item, info pengiriman, dan riwayat status), desain relasional mungkin memerlukan banyak tabel dan join—serta lapisan ORM yang mencoba menyembunyikan kompleksitas itu namun sering menambah gesekan.
Pilihan NoSQL membuat pemodelan data lebih dekat dengan bagaimana aplikasi membaca dan menulisnya, membantu tim mengirim perubahan lebih cepat.
Perubahan Web-Skala yang Mengubah Kebutuhan Basis Data
Aplikasi web tidak hanya menjadi lebih besar—mereka berubah bentuk. Alih-alih melayani sejumlah pengguna internal yang dapat diprediksi pada jam kerja, produk mulai melayani jutaan pengguna global sepanjang waktu, dengan lonjakan tiba-tiba yang dipicu oleh peluncuran, berita, atau sharing sosial.
Ekspektasi selalu-aktif menaikkan standar: downtime menjadi berita besar, bukan sekadar ketidaknyamanan. Pada saat yang sama, tim diminta mengirim fitur lebih cepat—sering sebelum ada yang tahu seperti apa “bentuk akhir” data.
Terdistribusi menjadi jalur pertumbuhan default
Untuk mengikuti, penskalaan satu server tidak lagi cukup. Semakin banyak lalu lintas yang ditangani, semakin Anda menginginkan kapasitas yang bisa ditambahkan secara bertahap—tambahkan node lain, sebarkan beban, isolasi kegagalan.
Ini mendorong arsitektur ke arah fleet mesin daripada satu “kotak utama”, dan mengubah harapan tim terhadap basis data: bukan hanya kebenaran, tetapi performa yang dapat diprediksi di bawah konkurensi tinggi dan perilaku yang anggun saat bagian sistem tidak sehat.
Pola yang diadopsi tim sebelum basis data mengejar
Sebelum “NoSQL” menjadi kategori mainstream, banyak tim sudah memodifikasi sistem untuk realitas web-skala:
- Lapisan caching (sering in-memory) untuk mengurangi baca berulang
- Denormalisasi untuk menghindari join mahal dan mengurangi round-trip
- View yang sudah dihitung dan rollup termaterialisasi untuk feed, timeline, dan dashboard
Teknik ini bekerja, tetapi memindahkan kompleksitas ke dalam kode aplikasi: invalidasi cache, menjaga konsistensi data yang diduplikasi, dan membangun pipeline untuk record “ready-to-serve”.
Bagaimana ini memaksa basis data berevolusi
Seiring pola ini menjadi standar, basis data harus mendukung distribusi data di banyak mesin, mentolerir kegagalan parsial, menangani volume tulis tinggi, dan merepresentasikan data yang berevolusi dengan bersih. Basis data NoSQL muncul sebagian untuk membuat strategi web-skala umum menjadi fitur utama daripada pekerjaan rutin yang terus-menerus.
Kompromi Terdistribusi dan Teorema CAP
Jadikan perubahan lebih aman
Eksperimen dengan skema dan logika, lalu kembalikan dengan cepat saat model gagal.
Saat data tinggal di satu mesin, aturan terasa sederhana: ada satu sumber kebenaran, dan setiap baca atau tulis bisa segera diperiksa. Saat Anda menyebarkan data ke banyak server (sering lintas wilayah), realitas baru muncul: pesan bisa tertunda, node bisa gagal, dan bagian sistem bisa berhenti berkomunikasi sementara.
Kompromi terdistribusi inti (dalam bahasa sederhana)
Basis data terdistribusi harus memutuskan apa yang dilakukan ketika koordinasi tidak aman. Haruskah tetap melayani permintaan sehingga aplikasi tetap “up”, walau hasil mungkin sedikit ketinggalan? Atau menolak beberapa operasi sampai dapat mengonfirmasi replika sepakat, yang bisa terlihat seperti downtime bagi pengguna?
Situasi ini muncul saat kegagalan router, jaringan overload, deployment bergulir, kesalahan konfigurasi firewall, dan keterlambatan replikasi lintas-wilayah.
CAP dalam satu bingkai: C, A, dan P
Teorema CAP adalah singkatan dari tiga properti yang diinginkan bersamaan:
- Consistency (Konsistensi): setiap baca mengembalikan tulis terbaru (atau error). Praktisnya, “semua orang melihat jawaban yang sama sekarang.”
- Availability (Ketersediaan): setiap permintaan mendapat respons (tidak selalu data terbaru).
- Partition Tolerance (Toleransi Partisi): sistem terus beroperasi meski jaringan terpecah menjadi grup terisolasi.
Poin utama bukanlah “pilih dua selamanya.” Melainkan: ketika partisi jaringan terjadi, Anda harus memilih antara konsistensi dan ketersediaan. Dalam sistem web-skala, partisi dianggap tak terelakkan—terutama dalam pengaturan multi-wilayah.
Partisi berkaitan langsung dengan outage nyata
Bayangkan aplikasi berjalan di dua wilayah demi ketahanan. Putus kabel atau masalah routing menghalangi sinkronisasi.
- Jika memprioritaskan ketersediaan, kedua wilayah terus menerima tulis, dan data bisa sementara berbeda.
- Jika memprioritaskan konsistensi, satu wilayah mungkin menolak tulis (atau baca) sampai dapat memastikan kesepakatan.
Berbagai sistem NoSQL (dan konfigurasi dari sistem yang sama) membuat kompromi berbeda tergantung apa yang paling penting: pengalaman pengguna saat gagal, jaminan kebenaran, kesederhanaan operasional, atau perilaku pemulihan.
Penskalaan Horizontal: Sharding dan Replikasi sebagai Ide Inti
Penskalaan horizontal berarti menambah kapasitas dengan menambah mesin (node) alih-alih membeli server yang lebih besar. Bagi banyak tim, ini merupakan pergeseran finansial dan operasional: node komoditas bisa ditambahkan secara bertahap, kegagalan diharapkan, dan pertumbuhan tidak memerlukan migrasi “kotak besar” yang berisiko.
Sharding (partisi): menyebarkan pekerjaan
Agar banyak node berguna, sistem NoSQL mengandalkan sharding (juga disebut partisi). Alih-alih satu basis data menangani setiap permintaan, data dibagi ke partisi dan didistribusikan ke node.
Contoh sederhana adalah partisi berdasarkan key (mis. user_id):
- Node A menyimpan user 1–1.000.000
- Node B menyimpan user 1.000.001–2.000.000
Baca dan tulis tersebar, mengurangi hotspot dan membiarkan throughput tumbuh saat Anda menambah node. Key partisi menjadi keputusan desain: pilih key yang selaras dengan pola kueri, atau Anda bisa secara tidak sengaja memusatkan terlalu banyak lalu lintas ke satu shard.
Replikasi: ketersediaan dan penskalaan baca
Replikasi berarti menyimpan beberapa salinan data yang sama di node berbeda. Ini meningkatkan:
- Ketersediaan: jika satu node gagal, replika lain bisa melayani permintaan.
- Kapasitas baca: pembacaan bisa dilayani dari beberapa replika.
Replikasi juga memungkinkan menyebarkan data antar rak atau wilayah untuk bertahan dari outage terlokalisir.
Biaya tersembunyi: rebalancing dan operasional
Sharding dan replikasi memperkenalkan pekerjaan operasional berkelanjutan. Saat data tumbuh atau node berubah, sistem harus merebalans—memindahkan partisi sambil tetap online. Jika ditangani buruk, rebalancing bisa menyebabkan lonjakan latensi, beban tidak merata, atau kekurangan kapasitas sementara.
Ini adalah kompromi inti: penskalaan lebih murah melalui banyak node, dengan imbalan distribusi yang lebih kompleks, pemantauan, dan penanganan kegagalan.
Model Konsistensi: Dari Ketat ke Eventual
Setelah data terdistribusi, basis data harus mendefinisikan apa arti “benar” saat pembaruan terjadi bersamaan, jaringan melambat, atau node tidak bisa berkomunikasi.
Konsistensi ketat (strong)
Dengan konsistensi kuat, begitu sebuah tulis diakui, setiap pembaca harus langsung melihatnya. Ini cocok dengan pengalaman “sumber kebenaran tunggal” yang sering diasosiasikan dengan basis data relasional.
Tantangannya adalah koordinasi: jaminan ketat antar node memerlukan banyak pesan, menunggu cukup banyak respons, dan menangani kegagalan di tengah penerbangan. Semakin jauh node atau semakin sibuk, semakin besar latensi yang mungkin dikenakan—terkadang pada setiap operasi tulis.
Konsistensi eventual
Konsistensi eventual melonggarkan jaminan itu: setelah sebuah tulis, node berbeda mungkin sementara mengembalikan jawaban yang berbeda, tetapi sistem akan konvergen seiring waktu.
Contoh:
- Penghitung “like” mungkin menunjukkan 101 like di satu replika sementara replika lain masih menunjukkan 100 selama beberapa detik.
- Postingan baru bisa muncul di feed untuk beberapa pengguna lebih cepat daripada yang lain, terutama lintas-wilayah.
Untuk banyak pengalaman pengguna, ketidaksesuaian sementara itu dapat diterima jika sistem tetap cepat dan tersedia.
Konflik dan bagaimana mereka diselesaikan
Jika dua replika menerima pembaruan hampir bersamaan, basis data membutuhkan aturan penggabungan:
- Timestamp (last-write-wins): simpan pembaruan dengan timestamp terbaru. Sederhana, tetapi bisa kehilangan data jika jam berbeda atau “terbaru” bukan yang semantik benar.
- Version vector (secara konseptual): lacak replika mana yang melihat pembaruan mana, deteksi tulis konkuren, lalu gabung atau tampilkan konflik.
Di mana konsistensi kuat tetap penting
Konsistensi kuat biasanya bernilai untuk pemindahan uang, batas inventori, username unik, izin, dan alur kerja di mana “dua kebenaran untuk sementara” bisa menyebabkan kerugian nyata.
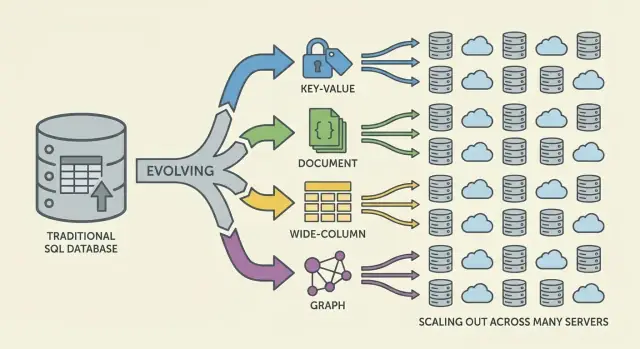
Keluarga Utama Basis Data NoSQL (dan Apa yang Mereka Optimalkan)
Buat bukti konsep yang berfungsi
Ubah catatan pola akses Anda menjadi UI React dan API Go yang berfungsi dalam hitungan menit.
NoSQL adalah kumpulan model yang membuat kompromi berbeda seputar skala, latensi, dan bentuk data. Memahami “keluarga” membantu memprediksi apa yang akan cepat, apa yang menyakitkan, dan mengapa.
Key-value store: cepat karena sederhana
Basis data key-value menyimpan sebuah nilai di balik kunci unik, seperti hashmap terdistribusi raksasa. Karena pola akses biasanya “get by key” / “set by key,” mereka bisa sangat cepat dan skala horizontal.
Cocok ketika Anda sudah tahu key lookup (session, caching, feature flag), tetapi terbatas untuk kueri ad-hoc: memfilter di banyak field sering bukan tujuan sistem ini.
Basis data dokumen: record fleksibel, bentuk seperti JSON
Basis data dokumen menyimpan dokumen mirip JSON (sering dikelompokkan dalam collection). Setiap dokumen dapat memiliki struktur sedikit berbeda, mendukung fleksibilitas skema saat produk berkembang.
Mereka dioptimalkan untuk membaca dan menulis dokumen utuh dan kueri berdasarkan field di dalamnya—tanpa memaksa tabel kaku. Komprominya: memodelkan relasi bisa menjadi rumit, dan join (jika didukung) bisa lebih terbatas dibanding sistem relasional.
Wide-column store: throughput tulis tinggi pada skala besar
Basis data wide-column (terinspirasi Bigtable) mengorganisir data berdasarkan row key, dengan banyak kolom yang dapat bervariasi per baris. Mereka unggul pada tingkat tulis masif dan penyimpanan terdistribusi, cocok untuk time-series, event, dan log.
Mereka cenderung menghargai desain yang hati-hati berdasarkan pola akses: Anda kueri efisien berdasarkan primary key dan aturan pengelompokan, bukan filter arbitrer.
Basis data graf: kueri relasi sebagai prioritas
Basis data graf memperlakukan relasi sebagai data kelas-pertama. Alih-alih melakukan join berulang-ulang, mereka menelusuri edge antara node, membuat kueri “bagaimana barang-barang ini saling terkait?” menjadi alami dan cepat (cincin penipuan, rekomendasi, grafik dependensi).
Panduan cepat: kapan tiap model paling cocok
- Key-value: lookup tercepat berdasarkan ID; caching, session, counter
- Dokumen: data produk yang berevolusi; profil, katalog, konten
- Wide-column: ingest besar-besaran; telemetri, log, time-series
- Graf: kueri relasi dalam-dalam; social graph, routing, analisis penipuan
Perubahan Pemodelan Data: Lebih Sedikit Join, Desain yang Lebih Berniat
Basis data relasional mendorong normalisasi: memecah data ke banyak tabel dan merakitnya dengan join saat query. Banyak sistem NoSQL mendorong Anda mendesain berdasarkan pola akses terpenting—kadang dengan biaya duplikasi—untuk menjaga latensi dapat diprediksi di seluruh node.
Mengapa denormalisasi begitu umum
Dalam basis data terdistribusi, sebuah join bisa mengharuskan menarik data dari banyak partisi atau mesin. Itu menambah hop jaringan, koordinasi, dan latensi tak terduga. Denormalisasi (menyimpan data terkait bersama) mengurangi round-trip dan menjaga baca sering kali tetap “lokal”.
Konsekuensi praktis: Anda mungkin menyimpan nama pelanggan yang sama di record orders meskipun juga ada di customers, karena kueri “tampilkan 20 order terakhir” adalah kueri inti.
Batasan kueri: lebih sedikit join, lebih banyak pemodelan di aplikasi
Banyak basis data NoSQL mendukung join terbatas (atau tidak sama sekali), sehingga aplikasi mengambil tanggung jawab lebih besar:
- Ambil dokumen/baris berdasarkan key dan render langsung
- Baca dua dataset terpisah dan gabung di kode
- Precompute read model (jumlah, ringkasan) untuk menghindari scan mahal
Inilah sebabnya pemodelan NoSQL sering dimulai dengan: “Layar apa yang harus kita muat?” dan “Apa kueri utama yang harus cepat?”
Indeks sekunder—dan biaya tersembunyinya
Indeks sekunder bisa membuka kueri baru (“temukan pengguna berdasarkan email”), tapi tidak gratis. Dalam sistem terdistribusi, setiap tulis bisa memperbarui banyak struktur indeks, menghasilkan:
- Amplifikasi tulis: satu tulis logis menjadi beberapa tulis fisik
- Penyimpanan ekstra: entri indeks bisa mendekati ukuran data
- Kompleksitas operasional: indeks bisa lag atau memerlukan tuning
Contoh pilihan pemodelan yang meningkatkan performa
- Embed daripada reference: simpan item order di dalam dokumen order agar membaca order bisa sekali permintaan
- Bucket data time-series: simpan event per device per hari untuk menghindari partisi tak terbatas
- Materialize read models: pertahankan record "user_profile_summary" untuk menyajikan halaman profil tanpa memindai posting, like, dan follow
Manfaat dan Kompromi yang Diterima Tim
Validasi model baca
Buat prototipe fitur yang menunjukkan bagaimana denormalisasi memengaruhi alur UI.
NoSQL diadopsi bukan karena “lebih baik” dalam segala hal, melainkan karena tim bersedia menukar kenyamanan tertentu dari basis data relasional untuk kecepatan, skala, dan fleksibilitas di bawah tekanan web-skala.
Apa yang didapat tim
Penskalaan horizontal sebagai desain. Banyak sistem NoSQL membuat menambah mesin (penskalaan horizontal) menjadi praktis daripada terus-menerus meng-upgrade satu server. Sharding dan replikasi adalah kapabilitas inti, bukan perhatian belakangan.
Skema fleksibel. Sistem dokumen dan key-value mengizinkan aplikasi berevolusi tanpa harus melewati setiap perubahan field melalui definisi tabel yang ketat, mengurangi gesekan saat persyaratan berubah mingguan.
Polanya ketersediaan tinggi. Replikasi lintas node dan wilayah mempermudah menjaga layanan berjalan selama kegagalan hardware atau pemeliharaan.
Apa yang dibayar tim
Duplikasi data dan denormalisasi. Menghindari join sering berarti menduplikasi data. Itu meningkatkan performa baca tapi menambah penyimpanan dan memperkenalkan kompleksitas "update di mana-mana".
Kejutan konsistensi. Konsistensi eventual bisa diterima—sampai tidak. Pengguna mungkin melihat data ketinggalan atau edge case yang membingungkan kecuali aplikasi dirancang untuk mentolerir atau menyelesaikan konflik.
Analitik yang lebih sulit (kadang). Beberapa penyimpanan NoSQL unggul pada operasi baca/tulis operasional tetapi membuat kueri ad-hoc, pelaporan, atau agregasi kompleks lebih merepotkan dibanding sistem SQL-first.
Mengapa operasi dan tooling penting
Adopsi NoSQL awal sering memindahkan usaha dari fitur basis data ke disiplin engineering: memantau replikasi, mengelola partisi, menjalankan kompaksi, merencanakan backup/restore, dan melakukan load-testing pada skenario kegagalan. Tim dengan kematangan operasional tinggi paling diuntungkan.
Cara mengevaluasi kompromi
Pilih berdasarkan realitas beban kerja: latensi yang diharapkan, puncak throughput, pola kueri dominan, toleransi bacaan ketinggalan, dan kebutuhan pemulihan (RPO/RTO). Pilihan NoSQL yang “tepat” biasanya yang cocok dengan bagaimana aplikasi Anda gagal, skalanya, dan cara data perlu diquery—bukan yang memiliki daftar fitur terpanjang.
Bagaimana Memutuskan Jika NoSQL Tepat Hari Ini
Memilih NoSQL tidak seharusnya dimulai dari merek basis data atau hype—melainkan dari apa yang aplikasi Anda butuhkan, bagaimana ia akan tumbuh, dan apa arti “benar” bagi pengguna.
Mulai dari kebutuhan dan pola akses
Sebelum memilih datastore, tuliskan:
- 5–10 kueri/operasi teratas yang harus didukung (baca, tulis, pencarian, agregasi)
- Trafik yang diharapkan sekarang vs 12–24 bulan
- Toleransi terhadap data ketinggalan (milidetik, detik, tidak pernah)
- Ekspektasi kegagalan (apa yang terjadi jika node atau wilayah turun?)
Jika Anda tidak bisa menjelaskan pola akses dengan jelas, pilihan apa pun akan menjadi tebakan—terutama dengan NoSQL, di mana pemodelan sering dibentuk oleh cara Anda membaca dan menulis.
Checklist sederhana keputusan (SQL vs NoSQL vs hybrid)
Gunakan ini sebagai penyaring cepat:
- Pilih SQL jika Anda membutuhkan konsistensi kuat secara default, kueri ad-hoc kompleks, dan banyak relasi yang diuntungkan oleh join.
- Pilih NoSQL jika Anda membutuhkan penskalaan horizontal yang mudah untuk pola akses tertentu, bisa mendesain data di sekitar pola tersebut, dan dapat menerima konsistensi longgar untuk beberapa alur kerja.
- Pilih hybrid jika bagian aplikasi berbeda kebutuhannya (umum pada produk nyata).
Sinyal praktis: jika "kebenaran inti" Anda (order, pembayaran, inventori) harus selalu benar, pertahankan itu di SQL atau penyimpanan lain yang konsisten kuat. Jika Anda melayani konten volume tinggi, session, caching, feed aktivitas, atau data pengguna yang fleksibel, NoSQL bisa sangat cocok.
Pertimbangkan polyglot persistence dengan sengaja
Banyak tim sukses menggunakan beberapa penyimpanan: misalnya, SQL untuk transaksi, basis data dokumen untuk profil/konten, dan key-value untuk session. Tujuannya bukan menambah kompleksitas demi kompleksitas—melainkan mencocokkan tiap beban kerja dengan alat yang menanganinya secara bersih.
Ini juga tempat workflow developer penting. Jika Anda bereksperimen pada arsitektur (SQL vs NoSQL vs hybrid), kemampuan untuk cepat membuat prototype bekerja—API, model data, dan UI—dapat mengurangi risiko. Platform seperti Koder.ai membantu tim melakukan itu dengan menghasilkan aplikasi full-stack dari chat, biasanya dengan frontend React dan backend Go + PostgreSQL, lalu memungkinkan Anda mengekspor source code. Bahkan jika nanti Anda memperkenalkan store NoSQL untuk beban kerja tertentu, memiliki sistem SQL yang kuat sebagai “system of record” plus prototyping cepat, snapshot, dan rollback dapat membuat eksperimen lebih aman dan lebih cepat.
Validasi dengan pengujian, bukan opini
Apa pun pilihan Anda, buktikan dengan pengujian:
- Jalankan load test dengan kueri dan ukuran data realistis.
- Lakukan failure drill (matikan node, simulasi masalah jaringan, uji restore).
- Buat rencana evolusi skema: bagaimana menambah field, migrasi record, dan menjaga versi lama/baru bekerja selama rollout.
Jika Anda tidak bisa menguji skenario ini, keputusan basis data tetap teoretis—dan produksi akan menjadi tempat pengujian itu dilakukan.
Pertanyaan umum
Apa yang awalnya ingin diselesaikan oleh NoSQL?
NoSQL menangani dua tekanan umum:
- Skala: volume tulis tinggi, lonjakan lalu lintas, dan dataset yang melebihi kemampuan satu “server besar”.
- Perubahan: kebutuhan produk yang cepat berubah membuat migrasi skema relasional sering kali mahal dan berisiko.
Bukan karena SQL “buruk”, melainkan karena beban kerja yang berbeda memerlukan kompromi yang berbeda.
Mengapa penskalaan satu server relasional mulai gagal?
Pendekatan “skala vertikal” tradisional mencapai batas praktis:
- Perangkat keras kelas atas cepat mahal dan pembaruannya mengganggu operasi.
- Satu mesin menjadi bottleneck untuk tulis, penyimpanan, dan failover.
- Pengguna global mengalami latensi tinggi jika basis data utama hanya ada di satu wilayah.
Sistem NoSQL lebih mengandalkan penskalakan horizontal dengan menambah node daripada terus membeli mesin lebih besar.
Mengapa skema kaku menjadi masalah untuk aplikasi modern?
Skema relasional ketat demi konsistensi, tapi menyulitkan saat iterasi cepat. Pada tabel besar, perubahan sederhana bisa memerlukan:
- Migrasi dan backfill
- Pembaruan indeks
- Koordinasi deployment antar tim
- Risiko downtime atau jendela pemeliharaan panjang
Model dokumen seringkali mengurangi gesekan ini dengan mengizinkan field opsional dan bentuk yang berevolusi.
Apakah NoSQL hanya tentang penskalaan horizontal?
Tidak selalu. Banyak basis data SQL bisa diskalakan secara horizontal, tetapi itu sering kompleks secara operasional (strategi sharding, join lintas-shard, transaksi terdistribusi).
Sistem NoSQL sering menjadikan distribusi (partisi + replikasi) sebagai fitur utama, dioptimalkan untuk pola akses yang lebih sederhana dan dapat diprediksi pada skala besar.
Mengapa desain NoSQL sering menggunakan denormalisasi dan lebih sedikit join?
Denormalisasi menyimpan data dalam bentuk yang dibaca aplikasi, sering menggandakan field untuk menghindari join mahal.
Contoh: menyimpan nama pelanggan di dalam record orders agar permintaan “20 order terakhir” menjadi satu baca cepat.
Komprominya adalah kompleksitas update: Anda harus menjaga konsistensi data yang digandakan lewat logika aplikasi atau pipeline.
Apa arti teorema CAP dalam praktik untuk NoSQL?
Dalam sistem terdistribusi, saat terjadi partisi jaringan basis data harus memilih perilaku ketika koordinasi tidak mungkin:
- Lebih memilih ketersediaan: tetap melayani permintaan, mungkin mengembalikan data yang ketinggalan.
- Lebih memilih konsistensi: menolak atau membatasi operasi sampai replika sepakat.
CAP mengingatkan bahwa pada saat partisi Anda tidak bisa menjamin konsistensi sempurna dan ketersediaan penuh bersamaan.
Apa perbedaan antara konsistensi kuat dan konsistensi eventual?
Konsistensi kuat berarti setelah sebuah tulis diakui, semua pembaca langsung melihatnya; ini sering membutuhkan koordinasi antar node.
Konsistensi eventual berarti replika mungkin sementara tidak sinkron, tapi akan konvergen seiring waktu. Ini cocok untuk feed, penghitung, dan pengalaman berorientasi ketersediaan jika aplikasi bisa menerima sedikit keterlambatan.
Bagaimana basis data NoSQL menangani penulisan yang saling bertentangan?
Konflik terjadi ketika replika menerima pembaruan bersamaan. Strategi umum:
- Last-write-wins (berdasarkan timestamp): sederhana, tetapi bisa menghapus pembaruan jika “terbaru” bukan yang benar secara semantik.
- Pendekatan versioning (mis. vektor): mendeteksi konkruensi lalu menggabung atau menyorot konflik.
Pilihan tergantung apakah hilangnya pembaruan antar-periode dapat diterima untuk tipe data tersebut.
Bagaimana saya memilih antara key-value, dokumen, wide-column, dan graf?
Panduan singkat cocoknya:
- Key-value: lookup cepat berdasarkan ID (session, caching, feature flag).
- Dokumen: record fleksibel seperti JSON (profil, katalog, konten).
- Wide-column: throughput tulis masif (event, log, time-series).
- Graf: traversal relasi (rekomendasi, ringkasan penipuan, dependency graph).
Pilih berdasarkan pola akses dominan, bukan sekadar popularitas.
Bagaimana cara mengetahui apakah NoSQL pilihan yang tepat untuk sistem saya hari ini?
Mulai dengan kebutuhan dan uji, bukan opini:
- Daftarkan 5–10 operasi utama dan proyeksi pertumbuhan.
- Tentukan toleransi untuk bacaan ketinggalan dan skenario kegagalan (node/wilayah down).
- Jalankan load test dengan ukuran data realistis.
- Lakukan failure drill (matikan node, simulasi partisi, uji restore).