Apa Arti Konsistensi dan Ketersediaan dalam Praktik
Ketika sebuah basis data dibagi ke beberapa mesin (replika), Anda mendapatkan kecepatan dan ketahanan—tetapi juga memperkenalkan periode di mana mesin‑mesin itu tidak sepenuhnya sejalan atau tidak dapat saling berbicara dengan andal.
Konsistensi (arti sederhana)
Konsistensi berarti: setelah sebuah penulisan berhasil, semua orang membaca nilai yang sama. Jika Anda memperbarui email profil, pembacaan berikutnya—tidak peduli replika mana yang menjawab—mengembalikan email baru.
Dalam praktiknya, sistem yang memprioritaskan konsistensi mungkin menunda atau menolak beberapa permintaan saat kegagalan untuk menghindari jawaban yang bertentangan.
Ketersediaan (arti sederhana)
Ketersediaan berarti: sistem merespons setiap permintaan, bahkan jika beberapa server mati atau terputus. Anda mungkin tidak mendapatkan data terbaru, tapi Anda mendapat jawaban.
Dalam praktiknya, sistem yang memprioritaskan ketersediaan dapat menerima tulis dan melayani baca meskipun replika tidak sepakat, lalu menyeimbangkan perbedaan nanti.
Apa arti pertukaran ini bagi aplikasi nyata
Sebuah pertukaran berarti Anda tidak dapat memaksimalkan kedua tujuan sekaligus untuk setiap skenario kegagalan. Jika replika tidak dapat berkoordinasi, basis data harus:
- Menunggu/gagal beberapa permintaan untuk melindungi satu kebenaran yang disepakati (memihak konsistensi), atau
- Terus merespons pengguna meskipun berisiko data lama atau konflik (memihak ketersediaan)
Contoh sederhana: keranjang belanja vs transfer bank
- Keranjang belanja: Jika jumlah item di keranjang sedikit berbeda untuk sementara di perangkat lain, itu mengganggu tapi biasanya dapat diterima. Banyak tim memilih ketersediaan lebih tinggi dan merekonsiliasi kemudian.
- Transfer bank: Jika Anda memindahkan $500 dan saldo Anda sementara menunjukan dua jawaban berbeda, itu masalah serius. Di sini, konsistensi yang lebih kuat sering bernilai meski terjadi kegagalan "silakan coba lagi".
Tidak ada pilihan terbaik tunggal
Keseimbangan yang tepat bergantung pada kesalahan yang bisa Anda toleransi: pemadaman singkat, atau periode singkat data yang salah/kadaluwarsa. Kebanyakan sistem nyata memilih titik di tengah—dan membuat pertukaran itu eksplisit.
Mengapa Distribusi Mengubah Aturannya
Sebuah basis data disebut “terdistribusi” ketika menyimpan dan melayani data dari banyak mesin (node) yang berkoordinasi melalui jaringan. Bagi aplikasi, ia mungkin masih tampak seperti satu basis data—tetapi di balik layar, permintaan dapat ditangani oleh node yang berbeda di tempat berbeda.
Replikasi: alasan tim menambah node
Kebanyakan basis data terdistribusi mereplikasi data: catatan yang sama disimpan di banyak node. Tim melakukan ini untuk:
- menjaga layanan tetap berjalan jika sebuah mesin mati
- mengurangi latensi dengan melayani pengguna dari node terdekat
- menskalakan pembacaan (dan kadang penulisan) di lebih banyak perangkat keras
Replikasi kuat, tapi langsung menimbulkan pertanyaan: jika dua node masing‑masing memiliki salinan data yang sama, bagaimana Anda menjamin mereka selalu setuju?
Kegagalan parsial adalah normal, bukan luar biasa
Di satu server, “mati” biasanya jelas: mesin menyala atau tidak. Di sistem terdistribusi, kegagalan sering parsial. Satu node mungkin hidup tapi lambat. Link jaringan bisa menjatuhkan paket. Sekumpulan rak bisa kehilangan konektivitas sementara klaster lain tetap berjalan.
Ini penting karena node tidak bisa seketika tahu apakah node lain benar‑benar mati, sementara tak terjangkau, atau hanya tertunda. Sambil menunggu, mereka harus memutuskan apa yang dilakukan terhadap pembacaan dan penulisan masuk.
Jaminan berubah ketika komunikasi tidak dijamin
Dengan satu server, ada satu sumber kebenaran: setiap pembacaan melihat penulisan sukses terbaru.
Dengan banyak node, “terbaru” tergantung pada koordinasi. Jika sebuah penulisan berhasil di node A tapi node B tak dapat dijangkau, apakah basis data harus:
- memblokir penulisan sampai B mengakui (melindungi konsistensi), atau
- menerima penulisan saja (melindungi ketersediaan)?
Ketegangan itu—yang nyata karena jaringan tidak sempurna—itulah mengapa distribusi mengubah aturannya.
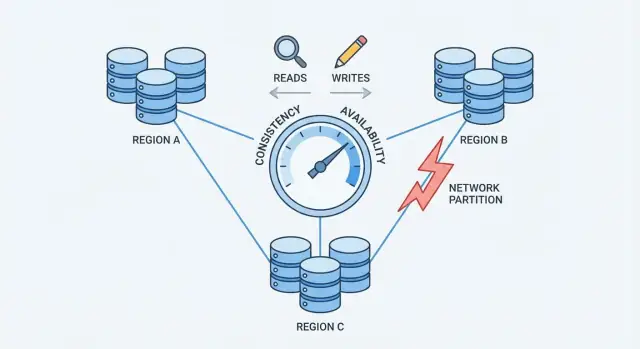
Partisi Jaringan: Masalah Inti
Sebuah partisi jaringan adalah putusnya komunikasi antara node yang seharusnya bekerja sebagai satu basis data. Node mungkin masih berjalan dan sehat, tetapi mereka tidak dapat bertukar pesan dengan andal—karena saklar yang gagal, link yang kelebihan beban, perubahan routing yang buruk, aturan firewall yang salah, atau bahkan tetangga berisik di jaringan cloud.
Mengapa partisi tak terhindarkan pada skala besar
Setelah sistem tersebar ke banyak mesin (sering lintas rak, zona, atau region), Anda tidak lagi mengendalikan setiap hop di antara mereka. Jaringan menjatuhkan paket, memperkenalkan penundaan, dan kadang terbelah menjadi “pulau”. Pada skala kecil kejadian ini jarang; pada skala besar itu rutinitas. Bahkan gangguan singkat cukup penting, karena basis data membutuhkan koordinasi konstan untuk menyetujui apa yang terjadi.
Bagaimana partisi menciptakan data “terbaru” yang saling bertentangan
Selama partisi, kedua sisi terus menerima permintaan. Jika pengguna dapat menulis di kedua sisi, masing‑masing dapat menerima pembaruan yang sisi lain tidak lihat.
Contoh: Node A memperbarui alamat pengguna menjadi “New Street.” Pada saat yang sama, Node B memperbarui menjadi “Old Street Apt 2.” Masing‑masing menganggap tulisannya paling baru—karena tidak ada cara untuk membandingkan catatan secara real time.
Gejala yang terlihat pengguna
Partisi tidak muncul sebagai pesan error rapi; mereka muncul sebagai perilaku membingungkan:
- Timeout: basis data menunggu node lain untuk mengonfirmasi tulis atau baca.
- Bacaan usang: Anda menyegarkan dan masih melihat data lama karena mengenai replika yang ketinggalan.
- Perilaku split‑brain: pengguna berbeda melihat “kebenaran” yang berbeda, tergantung ke sisi mana mereka tersambung.
Ini adalah titik tekanan yang memaksa pilihan: ketika jaringan tidak bisa menjamin komunikasi, basis data terdistribusi harus memilih memprioritaskan konsistensi atau ketersediaan.
CAP Tanpa Jargon
CAP adalah cara ringkas menggambarkan apa yang terjadi saat basis data tersebar ke banyak mesin.
Tiga istilah (dalam bahasa sederhana)
- Konsistensi (C): setelah Anda menulis sebuah nilai, pembacaan berikutnya mengembalikan nilai itu.
- Ketersediaan (A): setiap permintaan mendapat respons non‑error, bahkan jika beberapa server bermasalah.
- Toleransi partisi (P): sistem terus beroperasi walau jaringan terbelah dan server tidak bisa berkomunikasi dengan andal.
Inti yang harus diingat
Saat tidak ada partisi, banyak sistem bisa tampak konsisten dan tersedia.
Saat ada partisi, Anda harus memilih apa yang diprioritaskan:
- Pilih Konsistensi: tolak atau tunda beberapa permintaan sampai server bisa sepakat.
- Pilih Ketersediaan: terima permintaan di masing‑masing sisi dari pemisahan, walau jawaban sementara bisa berbeda.
Garis waktu sederhana yang bisa Anda bayangkan
- 10:00 Klien menulis
balance = 100 ke Server A.
- 10:01 Partisi jaringan: Server A tak bisa menjangkau Server B.
- 10:02 Klien membaca dari Server B.
- Jika Anda memprioritaskan Konsistensi, Server B harus menolak atau menunggu.
- Jika Anda memprioritaskan Ketersediaan, Server B merespons, tetapi mungkin masih mengatakan
balance = 80.
Kesalahpahaman umum
CAP tidak berarti “pilih dua” sebagai aturan permanen. Maksudnya saat terjadi partisi, Anda tidak bisa menjamin kedua Konsistensi dan Ketersediaan pada saat yang sama. Di luar partisi, Anda sering bisa hampir mendapat keduanya—sampai jaringan tidak berperilaku.
Memilih Konsistensi: Apa yang Anda Dapatkan dan Apa yang Hilang
Memilih konsistensi berarti basis data mengutamakan “semua melihat satu kebenaran” daripada “selalu merespons”. Dalam praktiknya, ini biasanya mengarah ke konsistensi kuat, sering disebut perilaku linearizable: setelah sebuah penulisan diakui, pembacaan berikutnya (dari mana pun) mengembalikan nilai itu, seolah‑olah ada satu salinan yang selalu up‑to‑date.
Apa yang terjadi selama partisi
Ketika jaringan terbelah dan replika tidak dapat berkomunikasi, sistem yang kuat konsistensi tidak dapat dengan aman menerima pembaruan independen di kedua sisi. Untuk melindungi kebenaran, biasanya:
- Memblokir permintaan sambil menunggu koordinasi, atau
- Menolak permintaan (mengembalikan error/timeout) jika tidak dapat menjangkau replika/pemimpin yang diperlukan.
Dari perspektif pengguna, ini bisa terlihat seperti pemadaman walaupun beberapa mesin masih berjalan.
Apa yang Anda peroleh
Manfaat utamanya adalah penalaran yang lebih sederhana. Kode aplikasi bisa berperilaku seolah‑olah berbicara ke satu basis data, bukan beberapa replika yang mungkin berbeda. Ini mengurangi momen “aneh” seperti:
- Membaca data yang lebih tua tepat setelah pembaruan sukses
- Melihat dua nilai berbeda untuk catatan yang sama tergantung replika yang Anda temui
- Kehilangan invarian (mis. overselling inventori) karena tulis yang bertentangan
Anda juga mendapatkan model mental yang lebih bersih untuk audit, penagihan, dan hal yang harus benar pada percobaan pertama.
Apa yang Anda korbankan
Konsistensi punya biaya nyata:
- Latensi lebih tinggi: banyak operasi harus menunggu koordinasi (sering lintas mesin atau region).
- Lebih banyak error saat kegagalan: partisi, replika lambat, atau masalah pemimpin dapat berarti timeout atau “coba lagi nanti”.
Jika produk Anda tidak bisa mentolerir permintaan yang gagal selama gangguan parsial, konsistensi kuat mungkin terasa mahal—meskipun itu pilihan yang tepat untuk kebenaran.
Memilih Ketersediaan: Apa yang Anda Dapatkan dan Apa yang Hilang
Prototipe pilihan CAP dengan cepat
Bangun alur kerja terdistribusi kecil di chat dan lihat bagaimana pilihan konsistensi memengaruhi perilaku.
Memilih ketersediaan berarti Anda mengoptimalkan janji sederhana: sistem merespons, bahkan ketika bagian infrastruktur tidak sehat. Dalam praktiknya, “ketersediaan tinggi” bukan berarti “tidak pernah error”—itu berarti sebagian besar permintaan tetap mendapat jawaban saat node gagal, replika kewalahan, atau link jaringan putus.
Apa yang terjadi selama partisi jaringan
Ketika jaringan terbelah, replika tidak dapat berkomunikasi dengan andal. Basis data yang memprioritaskan ketersediaan biasanya terus melayani trafik dari sisi yang dapat dijangkau:
- Baca dijawab secara lokal dari data yang saat ini dimiliki replika.
- Tulis diterima secara lokal dan antre/distribusikan nanti saat konektivitas kembali.
Ini menjaga aplikasi tetap berjalan, tetapi berarti replika berbeda mungkin sementara menerima kebenaran berbeda.
Apa yang Anda peroleh
Anda mendapatkan uptime lebih baik: pengguna masih bisa menelusuri, menambah item ke keranjang, mengirim komentar, atau merekam event walau sebuah region terisolasi.
Anda juga mendapatkan pengalaman pengguna yang lebih mulus saat tekanan. Daripada timeout, aplikasi dapat terus berfungsi (“pembaruan Anda tersimpan”) dan menyinkronkan kemudian. Untuk banyak beban kerja konsumer dan analitik, pertukaran itu sepadan.
Apa yang Anda korbankan
Harganya adalah basis data dapat mengembalikan bacaan usang. Pengguna mungkin memperbarui profil di satu replika, lalu segera membaca dari replika lain dan melihat nilai lama.
Anda juga berisiko konflik tulis. Dua pengguna (atau satu pengguna dari dua lokasi) dapat memperbarui rekaman yang sama di sisi partisi yang berbeda. Saat partisi sembuh, sistem harus merekonsiliasi riwayat yang berbeda. Bergantung aturan, satu tulis bisa “menang”, field bisa digabung, atau konflik mungkin memerlukan logika aplikasi.
Desain berfokus ketersediaan menerima ketidaksepakatan sementara agar produk tetap merespons—lalu menginvestasikan cara mendeteksi dan memperbaiki perbedaan itu nanti.
Kuorum dan Voting: Jalan Tengah Praktis
Kuorum adalah teknik “voting” praktis yang dipakai banyak basis data terreplikasi untuk menyeimbangkan konsistensi dan ketersediaan. Alih‑alih mempercayai satu replika, sistem meminta cukup replika untuk setuju.
Ide (N, R, W)
Anda sering melihat kuorum dengan tiga angka:
- N: berapa banyak replika ada untuk satu potongan data
- W: berapa replika yang harus mengonfirmasi sebuah tulis sebelum dianggap sukses
- R: berapa replika yang dikonsultasikan untuk sebuah baca
Aturan praktis: jika R + W > N, maka setiap pembacaan tumpang tindih dengan penulisan sukses terbaru pada setidaknya satu replika, yang mengurangi kemungkinan membaca data usang.
Contoh intuitif
Jika Anda punya N=3 replika:
- Pendekatan satu replika (R=1, W=1): Cepat dan sangat tersedia, tapi Anda mudah membaca replika yang usang.
- Mayoritas voting (R=2, W=2): Sebuah tulis harus mencapai 2 replika, dan sebuah baca meminta 2 replika. Ini meningkatkan peluang Anda melihat nilai terbaru karena set baca dan tulis tumpang tindih.
Beberapa sistem memilih W=3 (semua replika) untuk konsistensi lebih kuat, tetapi itu bisa menyebabkan lebih banyak kegagalan tulis saat ada replika lambat atau mati.
Apa yang dilakukan kuorum saat partisi
Kuorum tidak menghilangkan masalah partisi—mereka menentukan siapa yang diperbolehkan membuat kemajuan. Jika jaringan terbelah 2–1, sisi yang punya 2 replika masih bisa memenuhi R=2 dan W=2, sementara replika terisolasi tunggal tidak bisa. Itu mengurangi pembaruan yang bertentangan, tetapi berarti beberapa klien akan melihat error atau timeout.
Trade‑off
Kuorum biasanya berarti latensi lebih tinggi (lebih banyak node untuk dihubungi), biaya lebih tinggi (lalu lintas antar‑node), dan perilaku kegagalan yang lebih rumit (timeout terlihat seperti ketidaktersediaan). Keuntungannya adalah jalan tengah yang dapat disetel: Anda dapat memutar R dan W ke arah pembacaan lebih segar atau keberhasilan tulis lebih tinggi tergantung kebutuhan.
Konsistensi Akhir dan Anomali Umum
Konsistensi akhirnya berarti replika diperbolehkan sementara tidak sinkron, asalkan mereka konvergen ke nilai yang sama nanti.
Analogi konkret
Bayangkan rantai kedai kopi memperbarui papan “sold out” kue. Satu toko menandai habis, tapi pembaruan itu sampai ke toko lain beberapa menit kemudian. Selama jendela itu, toko lain mungkin masih menampilkan “tersedia” dan menjual yang terakhir. Sistem tidak “rusak”—pembaruan hanya sedang mengejar.
Anomali umum yang akan Anda lihat
Saat data masih menyebar, klien dapat mengamati perilaku yang terasa mengejutkan:
- Bacaan usang: Anda membaca data lama dari replika yang belum menerima penulisan terbaru.
- Kesenjangan read‑your‑writes: Anda menulis pembaruan, lalu segera membaca dari replika lain (atau setelah failover) dan tidak melihat perubahan Anda.
- Pembaruan urutan‑terbalik: dua pembaruan tiba dalam urutan berbeda di replika yang berbeda, menghasilkan tampilan yang tak konsisten sementara.
Teknik yang membantu replika berkonvergensi
Sistem eventual consistency biasanya menambahkan mekanisme latar belakang untuk mengurangi jendela inkonsistensi:
- Read repair: bila pembacaan mendeteksi replika yang tidak cocok, sistem memperbarui replika usang di latar belakang.
- Hinted handoff: jika sebuah replika down, node lain menyimpan “hint” tulisan untuk diteruskan saat replika kembali.
- Anti‑entropy (sinkronisasi): rekonsiliasi periodik (sering via merkle tree atau checksum) untuk menemukan dan memperbaiki drift.
Kapan konsistensi akhirnya bekerja dengan baik
Cocok ketika ketersediaan lebih penting daripada kerapian waktu: feed aktivitas, penghitung view, rekomendasi, cache profil, log/telemetri, dan data non‑kritis lain yang “benar dalam beberapa saat” dapat diterima.
Resolusi Konflik: Bagaimana Tulis yang Menyimpang Diselesaikan
Ubah contoh jadi demo
Modelkan keranjang, saldo, dan retry untuk melihat kegagalan nyata sejak dini.
Saat basis data menerima tulis di banyak replika, ia bisa berakhir dengan konflik: dua (atau lebih) pembaruan pada item yang sama yang terjadi secara independen pada replika berbeda sebelum sinkronisasi.
Contoh klasik: pengguna mengubah alamat pengiriman di satu perangkat sambil mengubah nomor telepon di perangkat lain. Jika masing‑masing update mendarat pada replika berbeda selama pemutusan sementara, sistem harus menentukan apa yang menjadi rekaman “sebenarnya” saat replika bertukar data lagi.
Last‑write‑wins (LWW): sederhana, tapi berisiko
Banyak sistem memulai dengan last‑write‑wins: pembaruan dengan cap waktu terbaru menimpa yang lain.
Sederhana dan cepat, tetapi bisa menghilangkan data tanpa terlihat. Jika “terbaru” menang, maka perubahan lama yang penting bisa terhapus—bahkan jika kedua pembaruan menyentuh field berbeda.
Ini juga mengasumsikan jam dapat dipercaya. Perbedaan jam antar mesin (clock skew) dapat membuat pembaruan yang “salah” menang.
Menyimpan riwayat: version vectors dan ide terkait
Penanganan konflik yang lebih aman biasanya membutuhkan pelacakan sejarah kausal. Pada tingkat konseptual, version vectors (dan varian lebih sederhana) melampirkan metadata kecil pada setiap rekaman yang merangkum “replika mana yang telah melihat pembaruan mana.” Saat replika bertukar versi, basis data dapat mendeteksi apakah satu versi menyertakan yang lain (tidak ada konflik) atau apakah mereka menyimpang (konflik yang perlu resolusi).
Beberapa sistem memakai timestamp logis (mis. Lamport clocks) atau jam logis hibrida untuk mengurangi ketergantungan pada jam dinding sambil tetap memberi petunjuk pengurutan.
Menggabungkan alih‑alih menimpa
Saat konflik terdeteksi, Anda punya pilihan:
- Merge di tingkat aplikasi: aplikasi Anda memutuskan cara menggabungkan field, meminta pengguna, atau menyimpan kedua versi untuk review.
- CRDTs (Conflict‑Free Replicated Data Types): struktur data yang dirancang untuk bergabung secara otomatis dan deterministik (berguna untuk counter, set, teks kolaboratif, dll.). Mereka sering menghindari perilaku pemenang‑mengambil‑semua sambil tetap sangat tersedia.
Pendekatan terbaik bergantung pada apa arti “benar” untuk data Anda—kadang kehilangan tulis dapat diterima, dan kadang itu bug bisnis‑kritis.
Cara Memilih untuk Kasus Penggunaan Anda
Memilih sikap konsistensi/ketersediaan bukan debat filosofis—itu keputusan produk. Mulailah dengan menanyakan: berapa biaya jika salah untuk sesaat, dan berapa biaya mengatakan "coba lagi nanti"?
Peta risiko bisnis ke kebutuhan konsistensi
Beberapa domain butuh jawaban tunggal berwenang saat menulis karena “hampir benar” tetap salah:
- Uang dan penagihan: beban ganda, overdraft, dan refund biasanya menuntut konsistensi kuat.
- Identitas dan izin: login, reset kata sandi, kontrol akses, dan perubahan peran harus menghindari split‑brain.
- Inventori dan kapasitas: jika overselling tidak dapat diterima (tiket, stok terbatas), condong ke konsisten—atau desain reservasi eksplisit.
Jika dampak ketidaksesuaian sementara rendah atau bisa dibalik, Anda biasanya bisa condong ke ketersediaan.
Putuskan berapa banyak data usang yang bisa Anda toleransi
Banyak pengalaman pengguna baik‑baik saja dengan pembacaan sedikit lama:
- Feed dan timeline: sebuah posting muncul beberapa detik kemudian biasanya dapat diterima.
- Analitik dan dashboard: angka batch atau tertunda umum dan diharapkan.
- Cache dan indeks pencarian: pengguna menerima “belum terbarui” jika cepat dan stabil.
Jadilah eksplisit tentang seberapa usang yang boleh: detik, menit, atau jam. Anggaran waktu itu mengarahkan pilihan replikasi dan kuorum Anda.
Pilih mode kegagalan yang paling dibenci pengguna
Saat replika tidak sepakat, Anda biasanya berakhir dengan salah satu dari tiga hasil UX:
- Spinner / menunggu (utamakan kebenaran, mungkin terasa lambat)
- Error / retry (jujur, tetapi mengganggu)
- Hasil usang (halus, tetapi kadang mengejutkan)
Pilih opsi yang paling sedikit merusak per fitur, bukan secara global.
Daftar cepat
Condong ke C (konsistensi) jika: hasil yang salah menimbulkan risiko finansial/legal, isu keamanan, atau tindakan yang tidak dapat dibalik.
Condong ke A (ketersediaan) jika: pengguna menghargai responsif, data usang dapat ditoleransi, dan konflik bisa diselesaikan dengan aman nanti.
Jika ragu, pisahkan sistem: jaga rekaman kritis dengan konsistensi kuat, dan biarkan tampilan turunan (feed, cache, analitik) mengoptimalkan ketersediaan.
Pola Desain untuk Mengurangi Rasa Sakit dari Pertukaran
Uji mode baca dan tulis
Jalankan aplikasi React dan API Go untuk menguji penulisan ketat dan pembacaan longgar.
Jarang Anda harus memilih satu “pengaturan konsistensi” untuk seluruh sistem. Banyak basis data modern membiarkan Anda memilih konsistensi per operasi—dan aplikasi pintar memanfaatkan itu untuk menjaga pengalaman pengguna lancar tanpa berpura‑pura pertukaran tidak ada.
Gunakan tingkat konsistensi per operasi
Perlakukan konsistensi seperti kenop yang Anda putar berdasarkan apa yang pengguna lakukan:
- Pembaruan kritis (pembayaran, pengurangan inventori, perubahan kata sandi): gunakan konsistensi lebih kuat (mis. tulis quorum/linearizable).
- Bacaan tidak kritis (feed, dashboard, “terakhir terlihat”): izinkan bacaan lebih lemah (lokal/satu replika/eventual) untuk kecepatan dan ketahanan.
Ini menghindari membayar biaya konsistensi terkuat untuk segala hal, sambil tetap melindungi operasi yang benar‑benar membutuhkannya.
Campur kuat dan lemah dalam satu alur
Pol yang umum adalah kuat untuk tulis, lebih lemah untuk baca:
- Tulis dengan level ketat sehingga sistem memiliki catatan otoritatif.
- Baca dengan level longgar, dan jika Anda mendeteksi sesuatu “aneh” (item hilang, counter usang), refresh dengan baca lebih kuat atau tampilkan indikator “sedang memperbarui”.
Dalam beberapa kasus, sebaliknya bekerja: tulis cepat (queued/eventual) ditambah baca kuat saat mengonfirmasi hasil (“Apakah pesanan saya terpasang?”).
Rancang untuk retry: idempotensi
Saat jaringan goyah, klien retry. Buat retry aman dengan idempotency keys sehingga “kirim pesanan” yang dieksekusi dua kali tidak membuat dua pesanan. Simpan dan gunakan kembali hasil pertama saat kunci yang sama muncul lagi.
Alur panjang: saga dan kompensasi
Untuk aksi multi‑langkah di banyak layanan, gunakan saga: setiap langkah punya aksi kompensasi (refund, lepas reservasi, batalkan pengiriman). Ini membuat sistem dapat dipulihkan meski bagian‑bagian sementara tidak sepakat atau gagal.
Pengujian dan Observabilitas untuk Konsistensi vs Ketersediaan
Anda tidak bisa mengelola pertukaran konsistensi/ketersediaan jika Anda tidak bisa melihatnya. Masalah produksi sering terlihat seperti “kegagalan acak” sampai Anda menambahkan pengukuran dan tes yang tepat.
Apa yang diukur (dan mengapa)
Mulailah dengan set kecil metrik yang berkaitan langsung ke dampak pengguna:
- Latensi (p50/p95/p99): pantau lonjakan saat failover, perubahan pemimpin, atau retry kuorum.
- Tingkat error: pisahkan error “keras” (timeout, 5xx) dari error “lunak” (dilayani dari fallback, hasil parsial).
- Tingkat baca usang: persentase baca yang mengembalikan data lebih lama dari target Anda (mis. lebih dari 2 detik).
- Tingkat konflik: seberapa sering tulis bersamaan memerlukan rekonsiliasi (termasuk overwrite LWW).
Jika bisa, tag metrik menurut mode konsistensi (quorum vs lokal) dan region/zone untuk menemukan tempat perilaku menyimpang.
Uji partisi dengan sengaja
Jangan tunggu pemadaman nyata. Di staging, jalankan eksperimen chaos yang mensimulasikan:
- paket yang dijatuhkan dan latensi tinggi antar replika
- satu region menjadi tak terjangkau
- partisi parsial di mana hanya sebagian node bisa saling bicara
Verifikasi bukan hanya “sistem tetap hidup,” tapi jaminan apa yang bertahan: apakah baca tetap segar, apakah tulis terblokir, apakah klien mendapat error yang jelas?
Alerting yang menangkap pertukaran lebih awal
Tambahkan alert untuk:
- lag replikasi melampaui jendela usang yang ditoleransi
- kegagalan kuorum (tidak bisa mencapai cukup replika) dan kenaikan jumlah retry
- peningkatan konflik tulis atau backlog rekonsiliasi
Terakhir, buat janji eksplisit: dokumentasikan apa yang sistem Anda janjikan saat operasi normal dan saat partisi, dan edukasikan tim produk serta support tentang apa yang mungkin dilihat pengguna dan bagaimana merespons.
Prototipe Pilihan CAP Lebih Cepat (Tanpa Membangun Ulang Segala Sesuatu)
Jika Anda mengeksplorasi pertukaran ini dalam produk baru, berguna memvalidasi asumsi lebih awal—terutama mode kegagalan, perilaku retry, dan seperti apa “usang” di UI.
Satu pendekatan praktis adalah mem‑prototype versi kecil alur kerja (path tulis, path baca, retry/idempotensi, dan job rekonsiliasi) sebelum komit ke arsitektur penuh. Dengan layanan prototyping seperti Koder.ai, tim dapat cepat menyiapkan web app dan backend lewat alur kerja berbasis chat, mengiterasi model data dan API, serta menguji pola konsistensi berbeda (mis. tulis ketat + baca santai) tanpa overhead pipeline build tradisional. Saat prototipe cocok dengan perilaku yang diinginkan, Anda bisa mengekspor kode sumber dan mengembangkannya menjadi produksi.