Mengapa Kubernetes Mengubah Operasi Sehari-hari
Kubernetes tidak hanya memperkenalkan alat baru—ia mengubah bagaimana “ops sehari-hari” terlihat ketika Anda menjalankan puluhan (atau ratusan) layanan. Sebelum orkestrasi, tim sering merangkai skrip, runbook manual, dan pengetahuan kultural untuk menjawab pertanyaan berulang yang sama: Di mana layanan ini seharusnya berjalan? Bagaimana kita menggulirkan perubahan dengan aman? Apa yang terjadi saat sebuah node mati pukul 2 pagi?
Apa yang sesungguhnya diselesaikan oleh “orkestrasi"
Pada intinya, orkestrasi adalah lapisan koordinasi antara niat Anda (“jalankan layanan ini seperti ini”) dan realitas yang berantakan—mesin bisa gagal, lalu lintas bergeser, dan deploy terjadi terus-menerus. Alih-alih memperlakukan tiap server sebagai snowflake spesial, orkestrasi memperlakukan komputasi sebagai kumpulan dan workload sebagai unit yang dapat dijadwalkan dan dipindahkan.
Kubernetes memopulerkan model di mana tim menggambarkan apa yang mereka inginkan, dan sistem terus-menerus bekerja untuk membuat realitas sesuai deskripsi itu. Pergeseran ini penting karena membuat operasi kurang tentang kepahlawanan dan lebih tentang proses yang dapat diulang.
Tiga hasil yang langsung dirasakan tim
Kubernetes menstandarkan hasil operasional yang dibutuhkan sebagian besar tim layanan:
- Penyebaran: cara konsisten untuk menyatakan apa yang harus dijalankan, memperbaruinya, dan memverifikasi kesehatannya.
- Penskalaan: jalur praktis dari satu instance ke banyak, tanpa merancang ulang layanan atau menyiapkan mesin secara manual.
- Operasi layanan: cara stabil agar layanan saling menemukan, merutekan lalu lintas, dan terus bekerja saat instance berubah.
Catatan tentang cakupan dan sumber
Artikel ini fokus pada ide dan pola yang terkait dengan Kubernetes (dan pemimpin seperti Brendan Burns), bukan biografi pribadi. Saat kita membahas “bagaimana itu dimulai” atau “mengapa dirancang seperti ini,” klaim-klaim tersebut harus didukung sumber publik—pidato konferensi, dokumen desain, dan dokumentasi upstream—agar ceritanya tetap dapat diverifikasi dan bukan berdasarkan mitos.
Brendan Burns dalam Kisah Asal Kubernetes (Tingkat Tinggi)
Brendan Burns secara luas diakui sebagai salah satu dari tiga pendiri awal Kubernetes, bersama Joe Beda dan Craig McLuckie. Dalam kerja awal Kubernetes di Google, Burns membantu membentuk arah teknis dan cara proyek dijelaskan kepada pengguna—terutama tentang “bagaimana Anda mengoperasikan perangkat lunak” daripada sekadar “bagaimana menjalankan kontainer.” (Sumber: Kubernetes: Up & Running, O’Reilly; daftar AUTHORS/maintainers di repositori proyek Kubernetes)
Kolaborasi open source membentuk desain
Kubernetes tidak sekadar “dirilis” sebagai sistem internal yang selesai; ia dibangun secara publik dengan sekumpulan kontributor, kasus penggunaan, dan batasan yang terus berkembang. Keterbukaan itu mendorong proyek ke arah antarmuka yang bisa bertahan di berbagai lingkungan:
- API yang jelas dan versioned alih-alih detail implementasi tersembunyi
- perilaku portabel di berbagai penyedia cloud dan on-prem
- titik ekstensi sehingga inti bisa tetap relatif kecil namun mendukung banyak kebutuhan
Tekanan kolaboratif ini penting karena memengaruhi apa yang dioptimalkan Kubernetes: primitif bersama dan pola yang dapat diulang yang bisa disepakati banyak tim, walau mereka mungkin berbeda alat.
Apa arti “distandarkan” di sini
Saat orang mengatakan Kubernetes “menstandarkan” penyebaran dan operasi, biasanya yang dimaksud bukan membuat setiap sistem identik. Maksudnya adalah menyediakan kosakata bersama dan serangkaian alur kerja yang dapat diulang antar tim:
- “deployment,” “service,” “ingress,” “job,” “namespace” sebagai istilah bersama
- model konsisten untuk menyatakan apa yang Anda inginkan (dan membiarkan sistem bekerja untuk mencapainya)
- cara yang dapat diprediksi untuk menggulirkan perubahan, menskalakan, dan pulih dari kegagalan
Model bersama ini memudahkan dokumentasi, tooling, dan praktik tim untuk dipindahkan dari satu perusahaan ke perusahaan lain.
Kubernetes proyek vs. ekosistem
Penting membedakan Kubernetes (proyek open-source) dari ekosistem Kubernetes.
Proyek adalah API inti dan komponen control plane yang mengimplementasikan platform. Ekosistem adalah segala sesuatu yang tumbuh di sekitarnya—distribusi, layanan terkelola, add-on, dan proyek CNCF terkait. Banyak “fitur Kubernetes” yang diandalkan orang di dunia nyata (stack observability, engine kebijakan, alat GitOps) hidup di ekosistem itu, bukan di inti proyek itu sendiri.
Gagasan Inti: Keadaan yang Diinginkan Deklaratif
Konfigurasi deklaratif adalah pergeseran sederhana dalam cara Anda menggambarkan sistem: alih-alih menyusun langkah yang harus dilakukan, Anda menyatakan apa yang Anda inginkan sebagai hasil akhir.
Dalam istilah Kubernetes, Anda tidak memberitahu platform “jalankan kontainer, lalu buka port, lalu restart jika crash.” Anda mendeklarasikan “harus ada tiga salinan aplikasi ini berjalan, dapat dijangkau di port ini, menggunakan image container ini.” Kubernetes bertanggung jawab membuat realitas sesuai deklarasi itu.
Keadaan yang diinginkan vs skrip imperatif
Operasi imperatif seperti runbook: urutan perintah yang bekerja terakhir kali, dijalankan lagi saat ada perubahan.
Keadaan yang diinginkan lebih mirip kontrak. Anda mencatat hasil yang dimaksud dalam file konfigurasi, dan sistem terus bekerja menuju hasil itu. Jika ada drift—sebuah instance mati, node menghilang, perubahan manual masuk—platform mendeteksi ketidaksesuaian dan mengoreksinya.
Sebelum/setelah: perintah runbook vs YAML
Sebelumnya (pemikiran runbook imperatif):
- SSH ke server
- Tarik image container baru
- Hentikan proses lama
- Jalankan proses baru
- Perbarui aturan load balancer
- Jika lalu lintas melonjak, ulangi di server lain
Pendekatan ini bisa bekerja, tetapi mudah berakhir dengan server “snowflake” dan daftar centang panjang yang hanya dipercaya beberapa orang.
Sesudah (keadaan deklaratif yang diinginkan):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Anda mengubah file (mis. memperbarui image atau replicas), menerapkannya, dan controller Kubernetes bekerja merekonsiliasi apa yang berjalan dengan apa yang dideklarasikan.
Mengapa ini mengurangi pekerjaan berulang dan drift
Keadaan deklaratif menurunkan pekerjaan berulang operasional dengan mengubah “lakukan 17 langkah ini” menjadi “pertahankan seperti ini.” Ia juga mengurangi drift konfigurasi karena sumber kebenaran eksplisit dan dapat direview—sering berada di version control—sehingga kejutan lebih mudah terlihat, diaudit, dan di-rollback secara konsisten.
Controller dan Rekonsiliasi: Sistem yang Menjaga Semua Benar
Kubernetes terasa “mengelola sendiri” karena dibangun di sekitar pola sederhana: Anda menggambarkan apa yang Anda inginkan, dan sistem terus-menerus bekerja membuat realitas sesuai deskripsi itu. Mesin pola ini adalah controller.
Apa itu controller (dengan kata sederhana)
Controller adalah loop yang mengamati keadaan klaster saat ini dan membandingkannya dengan keadaan yang diinginkan yang Anda deklarasikan dalam YAML (atau lewat panggilan API). Ketika melihat celah, ia bertindak untuk menguranginya.
Ia bukan skrip satu-kali dan bukan menunggu manusia mengklik tombol. Ia berjalan berulang—amati, putuskan, bertindak—sehingga bisa merespons perubahan setiap saat.
Rekonsiliasi: bagaimana Kubernetes “menjaga semuanya tetap benar”
Perilaku banding-dan-koreksi yang berulang ini disebut rekonsiliasi. Ini mekanisme di balik janji umum “self-healing.” Sistem tidak mencegah kegagalan secara ajaib; ia memperhatikan drift dan memperbaikinya.
Drift bisa terjadi karena alasan biasa:
- sebuah proses crash
- sebuah node menghilang
- seseorang menskalakan sesuatu naik atau turun
- sebuah deployment diperbarui
Rekonsiliasi berarti Kubernetes memperlakukan peristiwa-peristiwa tersebut sebagai sinyal untuk memeriksa kembali niat Anda dan mengembalikannya.
Hasil yang sebenarnya diperhatikan orang
Controller diterjemahkan ke hasil operasional yang familier:
- Mengganti pod yang gagal: jika sebuah pod mati, controller melihat Anda masih menginginkannya dan menjadwalkan yang baru.
- Menjaga jumlah replika: jika Anda meminta 5 replika dan hanya 4 yang berjalan, Kubernetes berusaha membuat yang hilang.
- Mempertahankan kemajuan rollout: selama pembaruan, controller menggerakkan sistem menuju versi baru sambil menjaga ketersediaan.
Kuncinya adalah Anda tidak mengejar gejala secara manual. Anda mendeklarasikan target, dan loop kontrol melakukan pekerjaan kontinu untuk “membiarkannya tetap begitu.”
Mengapa ini meluas melampaui satu fitur
Pendekatan ini tidak terbatas pada satu tipe resource. Kubernetes menggunakan pola controller-dan-rekonsiliasi yang sama di banyak objek—Deployment, ReplicaSet, Job, Node, endpoint, dan lainnya. Konsistensi itu adalah alasan besar Kubernetes menjadi platform: setelah Anda memahami pola ini, Anda dapat memprediksi bagaimana sistem akan berperilaku saat menambahkan kapabilitas baru (termasuk custom resource yang mengikuti loop yang sama).
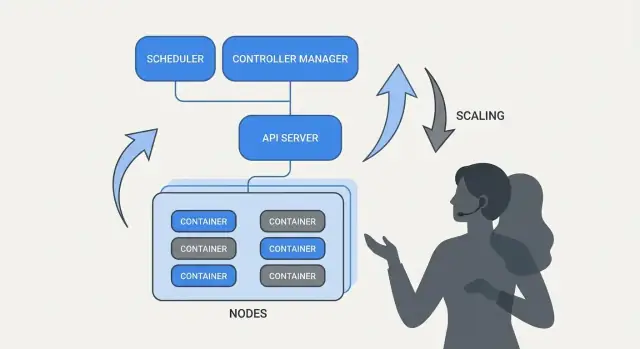
Penjadwalan sebagai Fitur Produk, Bukan Tugas Manual
Pilih paket yang sesuai
Beralih dari prototipe individu ke kerja siap-tim dengan paket yang sesuai untuk Anda.
Jika Kubernetes hanya “menjalankan kontainer,” ia masih meninggalkan bagian tersulit bagi tim: memutuskan di mana setiap workload harus berjalan. Penjadwalan adalah sistem bawaan yang menempatkan Pod ke node yang tepat secara otomatis, berdasarkan kebutuhan resource dan aturan yang Anda definisikan.
Ini penting karena keputusan penempatan langsung memengaruhi uptime dan biaya. API web yang terjebak pada node yang penuh bisa menjadi lambat atau crash. Job batch yang ditempatkan di dekat layanan sensitif latensi bisa menimbulkan masalah noisy-neighbor. Kubernetes mengubah ini menjadi kapabilitas produk yang dapat diulang alih-alih rutinitas spreadsheet-dan-SSH.
Apa yang dioptimalkan scheduler
Secara dasar, scheduler mencari node yang bisa memenuhi permintaan Pod Anda.
- Request CPU/mem: request memesan kapasitas untuk keputusan penempatan. Jika Anda meminta 500m CPU dan 1Gi memori, Kubernetes hanya akan mempertimbangkan node dengan kapasitas tersedia yang cukup.
Kebiasaan tunggal ini—menetapkan request yang realistis—sering mengurangi instabilitas “acak” karena layanan kritis berhenti bersaing dengan semuanya.
Constraint umum yang sering dipakai tim
Selain resource, kebanyakan klaster produksi mengandalkan beberapa aturan praktis:
- Affinity / anti-affinity: “tempatkan bersama” (untuk localitas cache) atau “jaga terpisah” (untuk menghindari satu kegagalan node mematikan semua replika).
- Taints dan tolerations: tandai node tertentu sebagai tujuan khusus (node GPU, node sistem, node kepatuhan) dan izinkan hanya workload yang disetujui mendarat di sana.
Bagaimana ini mengurangi outage
Fitur penjadwalan membantu tim mengkodekan niat operasional:
- Sebarkan replika di beberapa node untuk bertahan dari kegagalan node.
- Isolasi job “spiky” jauh dari layanan yang berhadapan dengan pelanggan.
- Jaga agar node mahal (seperti GPU) tidak digunakan oleh workload yang salah.
Inti praktisnya: perlakukan aturan penjadwalan seperti kebutuhan produk—tulis, tinjau, dan terapkan secara konsisten—sehingga keandalan tidak tergantung pada ingatan seseorang pada jam 2 pagi.
Salah satu ide paling praktis Kubernetes adalah penskalaan tidak seharusnya memerlukan perubahan kode aplikasi atau menemukan pendekatan deployment baru. Jika aplikasi dapat berjalan sebagai satu kontainer, definisi workload yang sama biasanya bisa tumbuh ke ratusan atau ribuan salinan.
Penskalaan punya dua lapis
Kubernetes memisahkan penskalaan menjadi dua keputusan terkait:
- Berapa banyak pod yang dijalankan (lebih banyak salinan aplikasi untuk throughput atau redundansi).\n- Berapa kapasitas klaster yang Anda miliki (cukup node—dan ukuran node yang tepat—untuk menempatkan pod-pod itu).
Pemecahan ini penting: Anda bisa meminta 200 pod, tetapi jika klaster hanya punya ruang untuk 50, “penskalaan” menjadi antrean pekerjaan yang pending.
Autoscaling, secara konseptual (HPA, VPA, Cluster Autoscaler)
Kubernetes biasa menggunakan tiga autoscaler, masing-masing fokus pada tuas berbeda:
- Horizontal Pod Autoscaler (HPA): mengubah jumlah pod berdasarkan sinyal seperti pemakaian CPU, memori, atau metrik aplikasi kustom.
- Vertical Pod Autoscaler (VPA): menyesuaikan request/limit pod sehingga tiap pod mendapat lebih (atau lebih sedikit) CPU/memori.
- Cluster Autoscaler: menambah atau menghapus node sehingga scheduler punya cukup ruang untuk menempatkan pod yang Anda minta.
Digunakan bersama, ini mengubah penskalaan menjadi kebijakan: “jaga latency stabil” atau “jaga CPU sekitar X%,” bukan rutinitas paging manual.
Keberhasilan penskalaan bergantung pada apa
Penskalaan hanya bekerja sebaik inputnya:
- Metrik: CPU mudah tapi tidak selalu bermakna; laju permintaan, kedalaman antrean, dan latency seringkali lebih menggambarkan beban nyata.\n- Request/limit resource: ini memberi tahu scheduler apa yang dibutuhkan pod. Tanpa itu, keputusan penempatan dan autoscaling menjadi perkiraan.\n- Polanya beban: lalu lintas spike, warm-up lambat, dan job berat latar mengubah seberapa cepat penskalaan harus bereaksi.
Kesalahan umum
Dua kesalahan yang sering muncul: penskalaan pada metrik yang salah (CPU tetap rendah sementara permintaan timeout) dan tidak adanya request resource (autoscaler tidak bisa memprediksi kapasitas, pod dipadatkan terlalu rapat, dan performa menjadi tidak konsisten).
Deploy Aman: Rollout, Health Check, dan Rollback
Perubahan besar yang dipopulerkan Kubernetes adalah memperlakukan “deploy” sebagai masalah kontrol berkelanjutan, bukan skrip sekali jalan yang Anda jalankan jam 5 sore Jumat. Rollout dan rollback adalah perilaku kelas satu: Anda mendeklarasikan versi yang Anda inginkan, dan Kubernetes menggerakkan sistem menuju versi itu sambil terus memeriksa apakah perubahan aman.
Rollout sebagai transisi terkontrol
Dengan Deployment, rollout adalah penggantian bertahap Pod lama dengan Pod baru. Alih-alih menghentikan semuanya dan memulai lagi, Kubernetes bisa memperbarui langkah demi langkah—menjaga kapasitas tersedia sementara versi baru membuktikan kemampuannya menangani lalu lintas nyata.
Jika versi baru mulai gagal, rollback bukanlah prosedur darurat. Itu operasi normal: Anda bisa mengembalikan ke ReplicaSet sebelumnya (versi baik terakhir) dan membiarkan controller mengembalikan keadaan lama.
Probe: mencegah rilis “jalan tapi buruk”
Health checklah yang mengubah rollout dari berdasarkan harapan menjadi dapat diukur.
- Readiness probe menentukan apakah sebuah Pod harus menerima lalu lintas. Kontainer bisa berjalan tapi belum siap (memanaskan cache, menunggu dependensi). Readiness mencegah mengirim pengguna ke instance yang belum bisa merespons dengan benar.
- Liveness probe mendeteksi saat sebuah kontainer macet atau tidak sehat dan perlu di-restart. Ini menghindari mode kegagalan lambat di mana proses hidup tapi rusak.
Dipakai dengan baik, probe mengurangi kesuksesan palsu—deploy yang terlihat baik karena Pod mulai, tetapi sebenarnya gagal melayani permintaan.
Strategi deployment: rolling, blue/green, canary
Kubernetes mendukung rolling update secara bawaan, tetapi tim sering menambahkan pola tambahan:
- Blue/green: pertahankan dua lingkungan penuh dan alihkan lalu lintas dari yang lama (blue) ke yang baru (green) setelah green terverifikasi.
- Canary: kirim sebagian kecil lalu lintas ke versi baru, pantau metrik, lalu perluas secara bertahap.
Keamanan yang bisa diukur (dan diotomatisasi)
Deploy aman bergantung pada sinyal: error rate, latency, saturasi, dan dampak pada pengguna. Banyak tim mengaitkan keputusan rollout ke SLO dan error budget—jika canary menghabiskan terlalu banyak budget, promosi berhenti.
Tujuannya adalah pemicu rollback otomatis berbasis indikator nyata (readiness gagal, 5xx meningkat, lonjakan latency), sehingga “rollback” menjadi respons sistem yang dapat diprediksi—bukan momen kepahlawanan larut malam.
Operasi Layanan: Penemuan, Routing, dan Jaringan Stabil
Miliki basis kode
Ambil source code dan terapkan pola Kubernetes Anda di pipeline sendiri.
Platform kontainer terasa “otomatis” hanya jika bagian lain sistem tetap bisa menemukan aplikasi Anda setelah berpindah. Di klaster produksi nyata, pod dibuat, dihapus, dijadwalkan ulang, dan diskalakan sepanjang waktu. Jika setiap perubahan mengharuskan memperbarui alamat IP di konfigurasi, operasi berubah menjadi pekerjaan sibuk konstan—dan outage menjadi rutin.
Mengapa penemuan layanan penting
Penemuan layanan adalah praktik memberi klien cara andal untuk mencapai sekumpulan backend yang berubah. Di Kubernetes, pergeseran kuncinya adalah Anda berhenti menargetkan instance individu (“panggil 10.2.3.4”) dan mulai menargetkan nama layanan (“panggil checkout”). Platform mengurus pod mana yang saat ini melayani nama itu.
Service, selector, dan endpoints (dengan kata sederhana)
Sebuah Service adalah pintu depan stabil untuk sekelompok pod. Ia memiliki nama konsisten dan alamat virtual di dalam klaster, bahkan saat pod di bawahnya berubah.
Selector adalah bagaimana Kubernetes memutuskan pod mana yang “di balik” pintu tersebut. Biasanya cocok dengan label, seperti app=checkout.
Endpoints (atau EndpointSlices) adalah daftar dinamis IP pod yang saat ini cocok dengan selector. Saat pod diskalakan, digulirkan, atau dijadwalkan ulang, daftar ini diperbarui otomatis—klien terus menggunakan nama Service yang sama.
Alamat stabil, load balancing, dan routing lalu lintas
Secara operasional, ini menyediakan:
- Alamat stabil: aplikasi berbicara ke nama DNS Service alih-alih mengejar IP Pod.\n- Load balancing: lalu lintas didistribusikan ke pod sehat di balik Service.\n- Routing yang dapat diprediksi: Anda bisa memisahkan “siapa yang harus menerima lalu lintas” (labels/selectors) dari “di mana pod dijalankan saat ini.”
Untuk lalu lintas north–south (dari luar klaster), Kubernetes biasanya menggunakan Ingress atau pendekatan Gateway yang lebih baru. Keduanya menyediakan titik masuk terkontrol di mana Anda bisa merutekan permintaan berdasarkan hostname atau path, dan sering memusatkan hal seperti terminasi TLS. Ide pentingnya tetap sama: jaga akses eksternal stabil sementara backend berubah di bawahnya.
Self-Healing: Apa Artinya di Produksi
“Self-healing” di Kubernetes bukanlah sihir. Itu adalah seperangkat reaksi otomatis terhadap kegagalan: restart, reschedule, dan replace. Platform mengamati apa yang Anda katakan Anda inginkan (desired state) dan terus mendorong realitas kembali ke arah itu.
Restart: saat sebuah kontainer crash
Jika sebuah proses keluar atau kontainer menjadi tidak sehat, Kubernetes dapat merestartnya di node yang sama. Ini biasanya dipicu oleh:
- Liveness probes: “Apakah kontainer ini masih berfungsi?” Jika tidak, restart.\n- Restart policies: aturan kapan restart harus terjadi.
Pola produksi umum: satu kontainer crash → Kubernetes me-restartnya → Service Anda terus merutekan hanya ke Pod yang sehat.
Reschedule dan replace: saat sebuah node gagal
Jika sebuah node turun seluruhnya (masalah hardware, kernel panic, jaringan hilang), Kubernetes mendeteksi node sebagai tidak tersedia dan mulai memindahkan pekerjaan ke tempat lain. Secara garis besar:
- Node ditandai tidak sehat/tidak siap.\n- Pod yang berjalan di sana dianggap hilang.\n- Controller membuat Pod pengganti di node sehat lain untuk mengembalikan jumlah replika yang diinginkan.
Ini adalah “self-healing” di tingkat klaster: sistem mengganti kapasitas, bukan menunggu manusia SSH masuk.
Observability: bagaimana Anda tahu ia menyembuhkan
Self-healing hanya penting jika Anda bisa memverifikasinya. Tim biasanya memantau:
- Log (log aplikasi dan event platform) untuk melihat apa yang di-restart dan mengapa\n- Metrik seperti hitungan restart, probe gagal, dan readiness node\n- Alert saat healing tidak bekerja (mis. CrashLoopBackOff berulang, kekurangan replika, atau terlalu banyak eviction)
Misconfigurations yang mematahkan self-healing
Bahkan dengan Kubernetes, “healing” bisa gagal jika pengaman salah:
- Probe liveness/readiness yang buruk atau hilang (positif palsu atau Pod tidak pernah siap)
- Tidak ada request/limit resource, menyebabkan penjadwalan tak terduga atau OOM kill
- Replika terlalu sedikit (satu Pod tidak cukup menyediakan kontinuitas)
- Timing probe terlalu agresif yang menyebabkan badai restart
- Workload bergantung pada status lokal node tanpa strategi penyimpanan durabel
Saat self-healing disusun dengan baik, outage menjadi lebih kecil dan lebih singkat—dan yang lebih penting, dapat diukur.
Luncurkan aplikasi web
Hasilkan UI React yang sesuai batas layanan dan ritme rilis Anda.
Kubernetes tidak menang hanya karena bisa menjalankan kontainer. Ia menang karena menawarkan API standar untuk kebutuhan operasional paling umum—deploy, penskalaan, jaringan, dan observasi workload. Ketika tim sepakat pada “bentuk” objek yang sama (seperti Deployment, Service, Job), tooling bisa dibagi antar organisasi, pelatihan menjadi lebih sederhana, dan serah terima antara dev dan ops tidak lagi bergantung pada pengetahuan kultural.
Mengapa API standar mengubah alur kerja tim
API konsisten berarti pipeline deploy Anda tidak perlu mengetahui kekhasan setiap aplikasi. Ia bisa melakukan tindakan yang sama—create, update, roll back, dan check health—menggunakan konsep Kubernetes yang sama.
Ini juga meningkatkan penyelarasan: tim keamanan bisa mengekspresikan pengaman sebagai kebijakan; SRE dapat menstandarkan runbook di sekitar sinyal kesehatan umum; pengembang bisa memikirkan rilis dengan kosakata bersama.
Memperluas Kubernetes: CRD dan Operator
Perubahan ke platform menjadi jelas dengan Custom Resource Definitions (CRD). CRD memungkinkan Anda menambahkan tipe objek baru ke klaster (mis. Database, Cache, atau Queue) dan mengelolanya dengan pola API yang sama seperti resource bawaan.
Sebuah Operator memasangkan objek kustom itu dengan controller yang terus-menerus merekonsiliasi realitas ke keadaan yang diinginkan—menangani tugas yang dulu manual, seperti backup, failover, atau upgrade versi. Manfaat utamanya bukan otomasi ajaib; melainkan mengulang kembali pola control loop yang sama yang Kubernetes terapkan pada semua hal lainnya.
Kecocokan dengan GitOps, CI/CD, dan pemeriksaan kebijakan
Karena Kubernetes bersifat API-driven, ia terintegrasi rapi dengan alur kerja modern:
- GitOps: keadaan yang diinginkan disimpan di Git; perubahan ditinjau seperti kode.\n- CI/CD: pipeline dapat menerapkan manifest, menunggu readiness, dan mempromosikan versi.\n- Policy checks: admission controller dapat memblokir konfigurasi berisiko sebelum mencapai produksi.
Jika Anda ingin panduan praktis lebih lanjut tentang deployment dan operasi yang dibangun di atas ide-ide ini, telusuri /blog.
Apa yang Bisa Diterapkan Tim Hari Ini (Bahkan di Luar Kubernetes)
Ide-ide terbesar Kubernetes—banyak dikaitkan dengan pembingkaian awal Brendan Burns—terjemahkan dengan baik bahkan jika Anda menjalankan VM, serverless, atau setup kontainer yang lebih kecil.
Pola yang meningkatkan operasi sehari-hari
Tuliskan “keadaan yang diinginkan” dan biarkan otomasi menegakkannya. Baik itu Terraform, Ansible, atau pipeline CI, perlakukan konfigurasi sebagai sumber kebenaran. Hasilnya adalah lebih sedikit langkah deploy manual dan jauh lebih sedikit kejutan “it worked on my machine”.
Gunakan rekonsiliasi, bukan skrip sekali jalan. Alih-alih skrip yang dijalankan sekali dan berharap yang terbaik, bangun loop yang terus memverifikasi properti kunci (versi, konfigurasi, jumlah instance, kesehatan). Inilah cara mendapatkan operasi yang dapat diulang dan pemulihan yang dapat diprediksi setelah kegagalan.
Jadikan penjadwalan dan penskalaan fitur produk yang eksplisit. Definisikan kapan dan mengapa Anda menambah kapasitas (CPU, kedalaman antrean, SLO latency). Bahkan tanpa autoscaling Kubernetes, tim bisa menstandarkan aturan skala sehingga pertumbuhan tidak memerlukan penulisan ulang aplikasi atau membangunkan seseorang.
Standarkan rollout. Pembaruan bergulir, health check, dan prosedur rollback cepat mengurangi risiko perubahan. Anda dapat mengimplementasikannya dengan load balancer, feature flag, dan pipeline deployment yang mengandalkan sinyal nyata.
Checklist adopsi aman
- Definisikan keadaan yang diinginkan layanan: versi, konfigurasi, dependensi, dan jumlah instance minimum
- Tambahkan endpoint kesehatan (ekuivalen liveness dan readiness) dan hubungkan ke load balancer atau pipeline deploy Anda
- Otomatiskan langkah rollout: deploy, verifikasi, alihkan lalu lintas, dan rollback jika gagal
- Buat “reconciler” kecil: pengecekan terjadwal yang memperbaiki drift (konfigurasi salah, instance hilang)
- Tambahkan pemicu penskalaan dengan batas jelas (maks instance, cooldown, aturan persetujuan)
Apa yang tidak akan diselesaikan sendiri
Pola-pola ini tidak akan memperbaiki desain aplikasi yang buruk, migrasi data yang tidak aman, atau kontrol biaya. Anda tetap membutuhkan API yang versioned, rencana migrasi, anggaran/limit, dan observabilitas yang mengaitkan deploy dengan dampak terhadap pelanggan.
Langkah berikutnya
Pilih satu layanan yang berhadapan langsung dengan pelanggan dan terapkan checklist secara menyeluruh, lalu perluas.
Jika Anda membangun layanan baru dan ingin sampai ke “sesuatu yang bisa dideploy” lebih cepat, Koder.ai bisa membantu menghasilkan aplikasi web/backend/mobile penuh dari spesifikasi yang digerakkan chat—umumnya React di frontend, Go dengan PostgreSQL di backend, dan Flutter untuk mobile—lalu mengekspor source code sehingga Anda bisa menerapkan pola Kubernetes yang dibahas di sini (konfigurasi deklaratif, rollout yang dapat diulang, dan operasi yang mudah di-rollback). Untuk tim yang mengevaluasi biaya dan tata kelola, Anda juga bisa meninjau /pricing.