Apa Itu Sharding (dan Apa yang Bukan)
Sharding (juga disebut partisi horizontal) berarti mengambil apa yang tampak seperti satu basis data untuk aplikasi Anda dan membagi datanya ke beberapa mesin, yang disebut shard. Setiap shard hanya memegang subset baris, tetapi bersama-sama mereka merepresentasikan keseluruhan dataset.
Satu tabel logis, banyak tempat fisik
Model mental yang membantu adalah perbedaan antara struktur logis dan penempatan fisik.
- Logis: Anda masih punya satu tabel “Users” (kolom dan makna sama).
- Fisik: baris untuk tabel itu disimpan di tempat berbeda—mis. user dengan ID 1–1.000.000 di shard A, dan jutaan berikutnya di shard B.
Dari sudut pandang aplikasi, Anda ingin menjalankan kueri seolah itu satu tabel. Di balik layar, sistem harus memutuskan shard mana yang perlu dihubungi.
Bukan replikasi, bukan “beli mesin lebih besar”
Sharding berbeda dari replikasi. Replikasi membuat salinan data yang sama pada beberapa node, terutama untuk ketersediaan dan penskalaan baca. Sharding membagi data sehingga setiap node menyimpan rekaman yang berbeda.
Juga berbeda dari skala vertikal, di mana Anda mempertahankan satu database tapi memindahkannya ke mesin yang lebih besar (lebih CPU/RAM/disk lebih cepat). Skala vertikal bisa lebih sederhana, tetapi punya batas praktis dan cepat mahal.
Yang tidak otomatis diperbaiki oleh sharding
Sharding menambah kapasitas, tetapi tidak otomatis membuat basis data Anda “mudah” atau membuat semua kueri lebih cepat.
- Join bisa menjadi mahal jika baris terkait berada di shard berbeda.
- Transaksi lintas-shard lebih sulit; pembaruan “all-or-nothing” mungkin memerlukan koordinasi.
- Kompleksitas operasional meningkat: routing, rebalancing, debugging, dan penanganan kegagalan menjadi bagian dari sistem.
Jadi sharding paling baik dipahami sebagai cara untuk menskalakan penyimpanan dan throughput—bukan peningkatan gratis untuk setiap aspek perilaku basis data.
Mengapa Tim Melakukan Sharding: Masalah yang Ingin Dipecahkan
Sharding jarang menjadi pilihan pertama. Tim biasanya sampai ke sana setelah sistem sukses mencapai batas fisik—atau setelah rasa sakit operasional menjadi terlalu sering untuk diabaikan. Motivasinya lebih sedikit “kami ingin sharding” dan lebih banyak “kami perlu terus tumbuh tanpa satu basis data menjadi single point of failure dan biaya.”
Titik nyeri yang mendorong tim ke sharding
Satu node basis data bisa kehabisan ruang dalam beberapa cara:
- Batas penyimpanan: tabel dan indeks tumbuh sampai disk sempit, backup melambat, dan operasi maintenance menjadi berisiko.
- Batas throughput tulis: CPU, WAL/redo, atau kontensi lock membatasi berapa banyak tulis per detik yang bisa disangga.
- Batas throughput baca: bahkan dengan caching dan replika, beberapa beban dapat membanjiri primary (atau replika menjadi mahal untuk diskalakan).
- Noisy neighbors: satu tenant, pelanggan, atau pola beban menguasai sumber daya dan menurunkan kinerja orang lain.
Saat masalah ini muncul secara reguler, masalahnya sering bukan satu kueri buruk—melainkan satu mesin yang memikul terlalu banyak tanggung jawab.
Tujuan: scale out, isolasi, dan kendali biaya
Sharding basis data menyebarkan data dan lalu lintas ke beberapa node sehingga kapasitas bertambah dengan menambah mesin daripada meng-upgrade satu. Jika dilakukan dengan benar, juga bisa mengisolasi beban kerja (sehingga lonjakan satu tenant tidak merusak latensi tenant lain) dan mengendalikan biaya dengan menghindari instance premium yang semakin besar.
Tanda peringatan awal bahwa Anda hampir mencapai batas
Polanya termasuk p95/p99 yang naik pada puncak, lag replikasi yang lebih panjang, backup/restore melebihi jendela yang dapat diterima, dan perubahan skema “kecil” menjadi acara besar.
Mengapa sharding biasanya langkah terakhir
Sebelum berkomitmen, tim biasanya menghabiskan opsi yang lebih sederhana: indexing dan perbaikan kueri, caching, read replica, partitioning dalam satu database, mengarsipkan data lama, dan upgrade hardware. Sharding bisa menyelesaikan masalah skala, tetapi juga menambahkan koordinasi, kompleksitas operasional, dan mode kegagalan baru—jadi ambang untuk menerapkannya sebaiknya tinggi.
Basis data yang di-shard bukan satu hal—ia adalah sekumpulan bagian yang bekerja sama. Alasan sharding terasa “sulit untuk dipahami” adalah karena kebenaran dan kinerja bergantung pada bagaimana bagian-bagian ini berinteraksi, bukan hanya pada mesin basis datanya.
Shard: partisi independen (dengan indeks sendiri)
Sebuah shard adalah subset data, biasanya disimpan di server atau cluster tersendiri. Setiap shard umumnya memiliki:
- penyimpanan (file data)
- indeks (agar kueri cepat di dalam shard itu)
- batas lokal (CPU, memori, disk, koneksi)
Dari sudut aplikasi, setup sharded sering berusaha terlihat seperti satu basis data logis. Tetapi di balik layar, kueri yang akan menjadi “satu lookup indeks” pada single-node mungkin berubah menjadi “temukan shard yang benar, lalu lakukan lookup.”
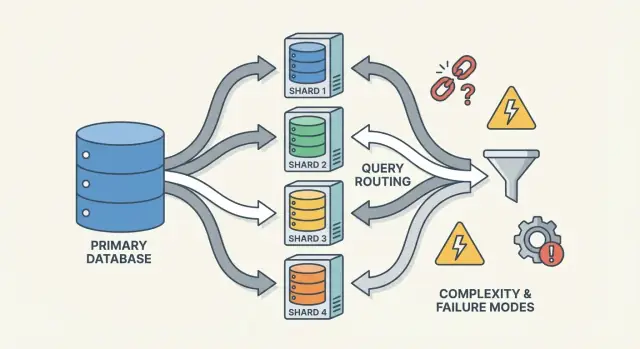
Router/koordinator: bagaimana permintaan mencapai shard yang tepat
Sebuah router (kadang disebut koordinator, query router, atau proxy) adalah pengatur lalu lintas. Ia menjawab pertanyaan praktis: diberikan permintaan ini, shard mana yang harus menanganinya?
Ada dua pola umum:
- Client-side routing: library aplikasi mengetahui peta shard dan terkoneksi langsung ke shard yang tepat.
- Proxy routing: aplikasi terkoneksi ke layanan router, yang meneruskan permintaan.
Router mengurangi kompleksitas di aplikasi, tetapi juga bisa menjadi bottleneck atau titik kegagalan baru jika tidak dirancang dengan hati-hati.
Sharding bergantung pada metadata—sumber kebenaran yang menjelaskan:
- peta shard (shard mana yang memiliki rentang/bucket/ID tertentu)
- kepemilikan (terutama selama migrasi, ketika kepemilikan bisa sementara saling tumpang tindih)
- kesehatan dan keanggotaan (node mana yang up, peran primary/replica, status draining)
Informasi ini sering tinggal di layanan konfigurasi (atau database “control plane” kecil). Jika metadata usang atau inkonsisten, router bisa mengirim lalu lintas ke tempat yang salah—meskipun setiap shard sehat.
Pekerjaan latar belakang: balancing, migrasi, dan backup
Akhirnya, sharding bergantung pada proses latar belakang yang menjaga sistem tetap layak dipakai seiring waktu:
- rebalancing data ketika satu shard tumbuh lebih cepat dari lainnya
- migrasi ketika memindahkan kepemilikan antar shard
- backup/restore yang bekerja di banyak shard (dan memenuhi tujuan pemulihan Anda)
Pekerjaan ini mudah diabaikan sejak awal, tapi sering menjadi sumber kejutan produksi—karena mereka mengubah bentuk sistem saat masih melayani lalu lintas.
Memilih Kunci Shard: Perdagangan Besar Pertama
Kunci shard adalah field (atau kombinasi field) yang digunakan sistem untuk memutuskan shard mana yang menyimpan sebuah baris/dokumen. Pilihan tunggal itu diam-diam menentukan kinerja, biaya, dan bahkan fitur mana yang terasa “mudah” nanti—karena ia mengontrol apakah permintaan bisa dirutekan ke satu shard atau harus menyebar ke banyak shard.
Apa yang membuat kunci shard “bagus”
Kunci yang baik cenderung memiliki:
- Kardinalitas tinggi: banyak nilai berbeda (mis.
user_id daripada country).
- Distribusi merata: nilai menyebarkan tulis dan baca ke seluruh shard daripada menumpuk di satu.
- Pola akses stabil: sesuai dengan cara Anda paling sering meng-query data hari ini dan bagaimana Anda berharap meng-query-nya kuartal berikutnya.
Contoh umum adalah sharding berdasarkan tenant_id pada aplikasi multi-tenant: sebagian besar baca dan tulis untuk satu tenant tetap pada satu shard, dan tenant yang banyak jumlahnya bisa menyebarkan beban.
Apa yang membuat kunci shard “buruk” (dan mengapa menyakitkan)
Beberapa kunci hampir menjamin masalah:
- Kunci monotonic/berbasis waktu (timestamp, ID auto-increment): data baru terkumpul pada shard “terakhir”, menciptakan hotspot tulis.
- Field kardinalitas rendah (status, plan_tier, country): terlalu sedikit nilai membuat beberapa shard melakukan sebagian besar pekerjaan.
- Identifier yang berubah (email, username yang bisa diubah): jika kuncinya berubah, memindahkan data antar shard menjadi mahal dan berisiko.
Bahkan jika field berkardinalitas rendah nyaman untuk filter, seringkali mengubah kueri rutin menjadi scatter-gather karena baris yang cocok tersebar di mana-mana.
Perdagangan nyata: kenyamanan kueri vs kualitas distribusi
Kunci shard terbaik untuk load balancing tidak selalu yang terbaik untuk kueri produk.
- Pilih kunci yang selaras dengan pola akses utama (mis.
user_id), dan beberapa kueri “global” (mis. laporan admin) menjadi lebih lambat atau memerlukan pipeline terpisah.
- Pilih kunci yang selaras untuk reporting (mis.
region), dan Anda berisiko hotspot dan kapasitas yang tidak merata.
Kebanyakan tim merancang di sekitar perdagangan ini: optimalkan kunci shard untuk operasi yang paling sering dan sensitif-latensi—dan tangani sisanya dengan indeks, denormalisasi, replika, atau tabel analytics khusus.
Strategi Sharding yang Umum (Range, Hash, Directory)
Tidak ada satu cara “terbaik” untuk sharding. Strategi yang Anda pilih membentuk betapa mudahnya merutekan kueri, seberapa merata data tersebar, dan pola akses seperti apa yang akan menyulitkan.
Range sharding
Dengan range sharding, setiap shard memiliki irisan kontigu dari ruang kunci—misalnya:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Routing sederhana: lihat kunci, pilih shard.
Masalahnya adalah hotspot. Jika pengguna baru selalu mendapat ID meningkat, shard “terakhir” menjadi bottleneck tulis. Range sharding juga sensitif terhadap pertumbuhan tak merata (satu range populer, yang lain sepi). Keuntungannya: kueri rentang (“semua order dari 1–31 Okt”) bisa efisien karena data dikelompokkan secara fisik.
Hash sharding
Hash sharding menjalankan kunci shard melalui fungsi hash dan menggunakan hasilnya untuk memilih shard. Ini biasanya menyebarkan data lebih merata, membantu menghindari masalah “semua menuju shard terbaru”.
Pertukarannya: kueri rentang menjadi menyulitkan. Kueri seperti “customer dengan ID antara X dan Y” tidak lagi memetakan ke sedikit shard; ia bisa menjangkau banyak.
Detail praktis yang sering diremehkan tim adalah consistent hashing. Alih-alih memetakan langsung ke jumlah shard (yang mengacak semuanya saat Anda menambah shard), banyak sistem memakai hash ring dengan “virtual node” sehingga penambahan kapasitas hanya memindahkan sebagian kunci.
Directory (lookup) sharding
Directory sharding menyimpan pemetaan eksplisit (tabel/layanan lookup) dari key → lokasi shard. Ini paling fleksibel: Anda bisa menempatkan tenant tertentu di shard dedikasi, memindahkan satu pelanggan tanpa memindahkan semuanya, dan mendukung ukuran shard yang tidak merata.
Kelemahannya adalah ketergantungan ekstra. Jika direktori lambat, usang, atau tidak tersedia, routing terganggu—meskipun shard-shard sehat.
Kunci komposit dan sub-sharding
Sistem nyata sering mencampur pendekatan. Kunci shard komposit (mis. tenant_id + user_id) menjaga isolasi tenant sambil menyebarkan beban di dalam tenant. Sub-sharding serupa: pertama rute berdasarkan tenant, lalu hash di dalam grup shard tenant itu untuk menghindari satu tenant besar mendominasi satu shard.
Cara Kueri Bekerja: Routing vs Scatter-Gather
Prototipe Sharding Aman
Buat prototipe layanan yang memahami shard lewat chat, lalu iterasi aman dengan snapshot dan rollback.
Basis data yang di-shard memiliki dua jalur kueri yang sangat berbeda. Memahami jalur mana yang dipakai menjelaskan sebagian besar kejutan kinerja—dan mengapa sharding bisa terasa tidak terduga.
Kueri single-shard: jalur cepat
Hasil ideal adalah merutekan kueri ke tepat satu shard. Jika permintaan menyertakan kunci shard (atau sesuatu yang bisa dipetakan), sistem bisa mengirimkannya langsung ke tempat yang benar.
Itulah sebabnya tim sangat memperhatikan membuat pembacaan umum “menyadari kunci shard”. Satu shard berarti lebih sedikit hop jaringan, eksekusi lebih sederhana, lebih sedikit lock, dan koordinasi jauh lebih sedikit. Latensi sebagian besar adalah database melakukan pekerjaannya, bukan cluster berdebat siapa yang harus mengerjakan.
Baca scatter-gather: fan-out dan tail latency
Saat kueri tidak bisa dirutekan tepat (mis. memfilter pada field non-kunci shard), sistem mungkin mem-broadcast ke banyak atau semua shard. Setiap shard menjalankan kueri secara lokal, lalu router (atau koordinator) menggabungkan hasil—mengurutkan, menghapus duplikat, menerapkan LIMIT, dan menggabungkan agregat parsial.
Fan-out ini memperbesar tail latency: meskipun 9 shard merespon cepat, satu shard lambat bisa menahan seluruh permintaan. Ini juga melipatgandakan beban: satu permintaan pengguna bisa menjadi N permintaan shard.
Join dan agregasi lintas-shard
Join lintas-shard mahal karena data yang sebelumnya “bertemu” di dalam satu database kini harus berpindah antar shard (atau ke koordinator). Bahkan agregasi sederhana (COUNT, SUM, GROUP BY) bisa membutuhkan rencana dua fase: hitung hasil parsial di setiap shard, lalu gabungkan.
Batasan indexing: lokal vs global
Sebagian besar sistem default ke indeks lokal: setiap shard mengindeks hanya datanya sendiri. Mereka murah untuk dipelihara, tapi tidak membantu routing—jadi kueri masih bisa scatter.
Indeks global bisa memungkinkan routing terarah pada field non-kunci shard, tapi mereka menambah overhead penulisan, koordinasi ekstra, dan tantangan skala serta konsistensi.
Tulis dan Transaksi Lintas Shard
Tulis adalah titik di mana sharding berhenti terasa seperti sekadar “penskalahan” dan mulai mengubah rancangan fitur. Tulis yang menyentuh satu shard bisa cepat dan sederhana. Tulis yang melintasi shard bisa lambat, rentan kegagalan, dan mengejutkan susah untuk dibuat benar.
Tulis single-shard: jalur menyenangkan
Jika setiap permintaan bisa dirutekan ke tepat satu shard (biasanya lewat kunci shard), database bisa memakai mekanisme transaksi normalnya. Anda mendapat atomicity dan isolation dalam shard itu, dan sebagian besar masalah operasional tampak seperti masalah single-node yang familiar—cukup diulang N kali.
Tulis multi-shard: di mana kompleksitas melonjak
Saat Anda perlu memperbarui data di dua shard dalam satu “aksi logis” (mis. transfer uang, memindahkan order antar customer, memperbarui agregat yang disimpan di tempat lain), Anda masuk ke wilayah transaksi terdistribusi.
Transaksi terdistribusi sulit karena butuh koordinasi antar mesin yang bisa lambat, terpartisi, atau restart kapan saja. Protokol seperti two-phase commit menambah round trip, bisa memblokir pada timeout, dan membuat kegagalan ambigu: apakah shard B sudah menerapkan perubahan sebelum koordinator mati? Jika klien mencoba ulang, apakah Anda menggandakan penulisan? Jika tidak retry, apakah Anda kehilangan perubahan?
Pola untuk menghindari tulis lintas-shard
Beberapa taktik umum mengurangi frekuensi kebutuhan transaksi multi-shard:
- Lokalisasi data: kumpulkan catatan terkait di shard yang sama (mis. semua untuk satu customer).
- Routing permintaan: pastikan operasi dimiliki oleh satu shard dan anggap lainnya hanya input baca.
- Denormalisasi: duplikasi potongan data kecil sehingga pembaruan tidak perlu ber-fan-out.
Idempotensi dan keamanan retry
Di sistem sharded, retry bukan opsi—mereka tak terelakkan. Buat penulisan idempotent dengan menggunakan ID operasi stabil (mis. idempotency key) dan biarkan database menyimpan penanda “sudah diterapkan”. Dengan begitu, jika timeout terjadi dan klien mencoba lagi, percobaan kedua menjadi no-op alih-alih menggandakan biaya, order duplikat, atau counter yang inkonsisten.
Konsistensi dan Replikasi: Menjaga Data Tetap Benar
Pilih Kunci Shard
Gunakan Mode Perencanaan untuk memetakan kunci shard, jalur kueri, dan langkah migrasi sebelum menulis kode.
Sharding memecah data Anda ke beberapa mesin, tapi tidak menghilangkan kebutuhan akan redundansi. Replikasi adalah yang menjaga shard tersedia saat sebuah node mati—dan juga yang membuat pertanyaan “apa yang benar sekarang?” menjadi lebih sulit.
Replikasi di dalam setiap shard
Sebagian besar sistem mereplikasi di dalam setiap shard: satu primary (leader) menerima tulis, dan satu atau lebih replika menyalin perubahan itu. Jika primary gagal, sistem mempromosikan replika (failover). Replica juga bisa melayani baca untuk mengurangi beban.
Pertukarannya adalah waktu. Replica baca bisa tertinggal beberapa mili- hingga beberapa detik. Kesenjangan itu normal, tapi penting ketika pengguna mengharapkan “saya baru saja memperbarui, jadi harusnya saya melihatnya.”
Model konsistensi secara sederhana
- Strong consistency: setelah tulis berhasil, bacaan akan mencerminkannya (berdasarkan janji sistem). Ini biasanya berarti membaca dari leader atau menunggu konfirmasi replica.
- Eventual consistency: sistem akan berkonvergensi, tetapi bacaan bisa sementara mengembalikan data lama.
Dalam setup sharded, Anda sering berakhir dengan konsistensi kuat di dalam shard dan jaminan lebih lemah di seluruh shard, terutama ketika operasi multi-shard terlibat.
“Sumber kebenaran tunggal” ketika data terpisah
Dengan sharding, “sumber kebenaran tunggal” biasanya berarti: untuk setiap potongan data, ada satu tempat otoritatif untuk menulisnya (biasanya leader shard). Secara global, tidak ada satu mesin yang bisa langsung mengonfirmasi keadaan terbaru semua hal. Anda punya banyak kebenaran lokal yang harus disinkronkan melalui replikasi.
Kendala global: unik, foreign key, counter
Kendala menjadi rumit ketika data yang perlu dicek berada pada shard berbeda:
- Unik (mis. username): menegakkan “tidak ada duplikat di mana pun” bisa memerlukan indeks terpusat, "constraint shard" khusus, atau workflow reservasi di level aplikasi.
- Foreign keys: jika parent dan child berada di shard berbeda, database sulit menegakkan integritas referensial tanpa koordinasi lintas-shard.
- Counter (total global, ID berurutan): pendekatan naif membuat bottleneck. Perbaikan umum termasuk range per-shard, batching, atau menerima hitungan tak terlalu tepat.
Pilihan ini bukan sekadar detail implementasi—mereka mendefinisikan apa arti “benar” untuk produk Anda.
Rebalancing dan Resharding Tanpa Downtime
Rebalancing menjaga basis data sharded tetap layak dipakai saat kenyataan berubah. Data tumbuh tak merata, kunci shard yang awalnya seimbang mengalami skew, Anda menambah node untuk kapasitas, atau Anda perlu pensiun hardware. Semua itu dapat menjadikan satu shard bottleneck—meskipun desain awal terlihat sempurna.
Mengapa ini sulit
Berbeda dengan satu database, sharding memasukkan lokasi data ke logika routing. Saat Anda memindahkan data, Anda tidak hanya menyalin byte—Anda mengubah tempat kueri harus dikirim. Itu berarti rebalancing semata-mata soal metadata dan klien sebanyak soal penyimpanan.
Pola migrasi online (copy → overlap → cutover)
Kebanyakan tim mengejar workflow online yang menghindari jendela “stop the world” besar:
- Copy: Backfill shard target dari shard sumber saat sistem hidup.
- Dual-write (kadang dual-read): Selama transisi, tulis perubahan baru ke lokasi lama dan baru. Baca mungkin memeriksa keduanya (atau gunakan aturan “yang baru menang”) sampai yakin.
- Cutover: Perbarui peta shard sehingga router/klien mengirim lalu lintas ke lokasi baru.
- Cleanup: Hentikan dual-write, hapus salinan lama, dan reclaim/kompak ruang.
Peta shard dan perilaku klien
Perubahan peta shard adalah peristiwa pemecah jika klien melakukan cache keputusan routing. Sistem yang baik memperlakukan metadata routing seperti konfigurasi: versikan, refresh sering, dan jelaskan apa yang terjadi saat klien mengakses kunci yang dipindahkan (redirect, retry, atau proxy).
Risiko operasional yang perlu direncanakan
Rebalancing sering menyebabkan penurunan kinerja sementara (tulis ekstra, churn cache, beban copy latar belakang). Pemindahan parsial umum—beberapa rentang bermigrasi sebelum lainnya—jadi Anda butuh observabilitas jelas dan rencana rollback (mis. mengembalikan peta dan mengalirkan dual-write) sebelum cutover.
Hotspot dan Skew: Ketika “Pembagian Merata” Rusak
Sharding berasumsi kerja akan tersebar. Kejutan adalah cluster bisa tampak “merata” di atas kertas (jumlah baris per shard sama) sementara berperilaku sangat tidak merata di produksi.
Partisi panas (hot keys)
Hotspot terjadi ketika irisan kecil dari ruang kunci mendapat sebagian besar lalu lintas—pikirkan akun selebriti, produk populer, tenant yang menjalankan job berat, atau kunci berbasis waktu di mana “hari ini” menarik semua tulis. Jika kunci-kunci itu dipetakan ke satu shard, shard itu menjadi bottleneck meskipun shard lain menganggur.
Skew: ukuran data vs lalu lintas
“Skew” bukan satu hal:
- Skew data: satu shard memegang lebih banyak byte/baris (tekanan penyimpanan, backup lebih lama, scan lebih lambat).
- Skew lalu lintas: satu shard menangani lebih banyak QPS atau kueri berat (CPU jenuh, antrean, lonjakan latensi).
Mereka tidak selalu cocok. Shard dengan data sedikit bisa menjadi paling panas jika punya kunci yang paling sering diminta.
Cara mendeteksinya cepat
Anda tidak perlu tracing mahal untuk melihat skew. Mulai dengan dashboard per-shard:
- p95 latency per shard (p95 satu shard yang menjauh adalah tanda bahaya)
- QPS (dan write QPS) per shard
- Penyimpanan terpakai / ukuran tabel per shard
Jika latensi satu shard naik seiring QPS-nya sementara yang lain tetap datar, kemungkinan Anda menghadapi hotspot.
Mitigasi
Perbaikan biasanya menukar kesederhanaan untuk keseimbangan:
- Pilih kunci shard yang menyebarkan lalu lintas, bukan hanya rekaman.
- Tambahkan bucketing/salting untuk kunci panas (memecah satu kunci logis ke beberapa bucket fisik).
- Gunakan cache untuk item baca-banyak.
- Terapkan rate limit atau kuota per-tenant untuk melindungi cluster.
- Pecah shard panas (atau pindahkan range panas) ketika satu shard tidak bisa didinginkan.
Mode Kegagalan dan Debugging di Sistem Sharded
Bandingkan Strategi Sharding
Bandingkan cepat pola sharding range, hash, dan directory dalam prototipe terpisah.
Sharding tidak hanya menambah server—ia menambah cara kegagalan dan lebih banyak tempat untuk memeriksa saat sesuatu salah. Banyak insiden bukan "basis data turun" tapi "satu shard turun", atau "sistem tidak sepakat tentang di mana data berada."
Mode kegagalan umum
Beberapa pola sering muncul:
- Satu shard tidak tersedia (crash, disk penuh, GC panjang), menyebabkan outage parsial: beberapa pelanggan bekerja, lainnya gagal.
- Router salah merutekan lalu lintas, sering setelah perubahan konfigurasi atau deploy yang buruk. Baca bisa diam-diam kembali kosong jika dikirim ke shard yang salah.
- Metadata usang atau inkonsisten (mis. peta shard). Selama migrasi atau pecahan, komponen berbeda bisa merutekan kunci yang sama secara berbeda.
- Masalah jaringan parsial: timeout antara router dan sebagian shard bisa tampak seperti error “acak” dan memicu retry yang memperbesar beban.
Bagaimana debugging berubah
Di database single-node, Anda men-tail satu log dan memeriksa satu set metrik. Dalam sistem sharded, Anda butuh observabilitas yang mengikuti permintaan melintasi shard.
Gunakan correlation ID di setiap permintaan dan propagasikan dari lapis API melalui router ke setiap shard. Padukan itu dengan distributed tracing sehingga kueri scatter-gather menunjukkan shard mana yang lambat atau gagal. Metrik harus dipecah per shard (latensi, kedalaman antrean, tingkat error), jika tidak shard panas tersembunyi dalam rata-rata fleet.
Insiden kebenaran data
Kegagalan sharding sering muncul sebagai bug kebenaran data:
- Duplikasi setelah retry atau penulisan non-idempotent.
- Baris hilang ketika migrasi memindahkan data tetapi routing masih menunjuk lokasi lama.
- Split-brain writes jika dua view metadata menerima tulis untuk rentang kunci yang sama.
Backup, restore, dan recovery bencana
"Restore the database" menjadi "restore banyak bagian dalam urutan yang benar." Anda mungkin perlu me-restore metadata dulu, lalu setiap shard, lalu verifikasi boundary shard dan aturan routing cocok dengan titik waktu yang direstore. Rencana DR harus termasuk latihan yang membuktikan Anda bisa merakit kembali cluster konsisten—bukan hanya memulihkan mesin individu.
Kapan Tidak Perlu Sharding: Alternatif Praktis dan Checklist Keputusan
Sharding sering dianggap sebagai “saklar penskalaan”, tetapi juga merupakan peningkatan permanen dalam kompleksitas sistem. Jika Anda bisa memenuhi tujuan kinerja dan reliabilitas tanpa membagi data antar node, Anda biasanya mendapatkan arsitektur yang lebih sederhana, debugging lebih mudah, dan lebih sedikit edge case operasional.
Alternatif praktis yang sering memberi banyak headroom
Sebelum berkomitmen ke sharding, coba opsi yang mempertahankan satu basis data logis:
- Indexing + tuning kueri: Perbaiki jalur lambat dulu—indeks hilang, kueri tak berbatas, join mahal, dan pola N+1.
- Caching: Taruh respon yang stabil dan banyak dibaca di depan cache (cache di level aplikasi, CDN untuk konten publik, atau cache in-memory untuk kunci panas).
- Read replicas: Alihkan trafik baca tanpa mengubah jalur tulis (dengan menerima lag replica saat OK).
- Partitioned tables di satu node: Banyak DB mendukung partitioning tabel yang meningkatkan maintenance dan kinerja kueri tanpa routing lintas-node.
Di mana alat membantu: prototipe layanan sadar-shard tanpa komitmen berlebih
Cara praktis untuk mengurangi risiko sharding adalah mem-prototype plumbing (batas routing, idempotensi, workflow migrasi, dan observabilitas) sebelum Anda mengikat database produksi.
Misalnya, dengan Koder.ai Anda bisa cepat memutar layanan kecil yang realistis dari chat—seringkali UI admin React plus backend Go dengan PostgreSQL—dan bereksperimen dengan API sadar-kunci-shard, idempotency key, dan perilaku cutover di sandbox yang aman. Karena Koder.ai mendukung mode planning, snapshot/rollback, dan export kode sumber, Anda dapat mengiterasi keputusan desain terkait sharding (seperti bentuk routing dan metadata) lalu membawa kode dan runbook hasilnya ke stack utama saat siap.
Kapan sharding cocok (dan kapan tidak)
Sharding lebih cocok ketika dataset atau throughput tulis jelas melebihi batas single node dan pola kueri Anda dapat andal dirutekan oleh kunci shard (sedikit join lintas-shard, minimal kueri scatter-gather).
Ini kurang cocok ketika produk Anda butuh banyak kueri ad-hoc, transaksi multi-entitas sering, kendala unik global, atau ketika tim tidak bisa mendukung beban operasional (rebalancing, resharding, respons insiden).
Checklist keputusan cepat
Tanyalah:
- Workload: Apakah bottleneck CPU, I/O, memori, atau kontensi lock—dan bisa diperbaiki tanpa sharding?
- Pola kueri: Bisakah 90%+ kueri kritis dirutekan oleh kunci shard?
- Kapasitas tim: Siapa yang memelihara peta shard, runbook on-call, dan perilaku transaksi lintas-shard?
- SLO: Bisakah Anda mentoleransi degradasi parsial (satu shard turun) dan tail latency yang lebih panjang?
Rencanakan pertumbuhan, bukan hanya diagram
Bahkan jika Anda menunda sharding, rancang jalur migrasi: pilih identifier yang tidak akan menghalangi kunci shard di masa depan, hindari meng-hardcode asumsi single-node, dan latih bagaimana Anda akan memindahkan data dengan downtime minimal. Waktu terbaik untuk merencanakan resharding adalah sebelum Anda benar-benar membutuhkannya.