15 Mei 2025·8 menit
Cara Membangun Aplikasi Web untuk Memperkaya Data Pelanggan
Pelajari cara membangun aplikasi web yang memperkaya catatan pelanggan: arsitektur, integrasi, pencocokan, validasi, privasi, pemantauan, dan tips peluncuran.
Tentukan Tujuan, Pengguna, dan Ruang Lingkup Enrichment
Sebelum memilih alat atau menggambar diagram arsitektur, pastikan apa yang dimaksud dengan “memperkaya” dalam organisasi Anda. Tim sering mencampur beberapa jenis enrichment dan kemudian kesulitan mengukur kemajuan—atau berdebat tentang kapan pekerjaan dianggap selesai.
Apa yang dihitung sebagai enrichment?
Mulailah dengan memberi nama kategori bidang yang ingin Anda perbaiki dan alasannya:
- Firmografis: ukuran perusahaan, industri, lokasi kantor pusat, tahap pendanaan
- Kontak: jabatan, email/telepon terverifikasi, senioritas, peran
- Perilaku: sinyal penggunaan produk, intent, skor keterlibatan
- Field kustom: territory internal, tingkat akun, skor kecocokan ICP
Tulis bidang mana yang wajib, mana yang diinginkan, dan mana yang seharusnya tidak pernah diperkaya (misalnya atribut sensitif).
Siapa yang akan menggunakan aplikasi—dan untuk apa?
Identifikasi pengguna utama dan tugas teratas mereka:
- Sales ops: mengurangi duplikat, menstandarkan akun, memperbaiki routing
- Marketing ops: memperkaya lead untuk segmentasi dan penargetan yang lebih baik
- Support: menampilkan konteks akun saat menangani tiket
- Analyst: dataset tepercaya untuk pelaporan
Setiap kelompok pengguna biasanya memerlukan alur kerja berbeda (pemrosesan massal vs. peninjauan per-record), jadi tangkap kebutuhan itu sejak awal.
Definisikan outcome, batasan ruang lingkup, dan metrik keberhasilan
Daftarkan outcome dalam istilah yang terukur: tingkat pencocokan lebih tinggi, lebih sedikit duplikat, routing lead/akun lebih cepat, atau kinerja segmentasi yang lebih baik.
Tetapkan batasan yang jelas: sistem mana saja yang termasuk (CRM, penagihan, analitik produk, meja support) dan mana yang tidak—setidaknya untuk rilis pertama.
Terakhir, sepakati metrik keberhasilan dan tingkat kesalahan yang dapat diterima (mis. cakupan enrichment, tingkat verifikasi, tingkat duplikat, dan aturan “gagal yang aman” ketika enrichment tidak pasti). Ini menjadi bintang penunjuk untuk sisa pembangunan.
Modelkan Data Pelanggan Anda dan Identifikasi Kekurangan
Sebelum memperkaya apa pun, pastikan jelas apa arti “pelanggan” dalam sistem Anda—dan apa yang sudah Anda ketahui tentang mereka. Ini mencegah membayar untuk enrichment yang tidak dapat Anda simpan, dan menghindari merge yang membingungkan nanti.
Inventarisasi field dan sumber yang ada
Mulailah dengan katalog sederhana field (mis. nama, email, perusahaan, domain, telepon, alamat, jabatan, industri). Untuk setiap field, catat dari mana asalnya: input pengguna, import CRM, sistem penagihan, alat support, formulir pendaftaran produk, atau penyedia enrichment.
Juga tangkap bagaimana ia dikumpulkan (wajib vs opsional) dan seberapa sering berubah. Misalnya, jabatan dan ukuran perusahaan berubah seiring waktu, sementara ID pelanggan internal seharusnya tidak berubah.
Definisikan model identitas: orang, perusahaan, akun
Sebagian besar alur enrichment melibatkan minimal dua entitas:
- Orang (kontak/lead): individu dengan email, telepon, peran
- Perusahaan (organisasi): bisnis dengan domain, lokasi, firmografis
Putuskan apakah Anda juga membutuhkan Akun (hubungan komersial) yang dapat menghubungkan banyak orang ke satu perusahaan dengan atribut seperti plan, tanggal kontrak, dan status.
Catat hubungan yang Anda dukung (mis. banyak orang → satu perusahaan; satu orang → beberapa perusahaan sepanjang waktu).
Dokumentasikan masalah data yang umum
Daftarkan isu yang sering muncul: nilai yang hilang, format yang tidak konsisten ("US" vs "United States"), duplikat akibat import, record usang, dan sumber yang bertentangan (alamat penagihan vs alamat CRM).
Pilih kunci yang diperlukan dan tetapkan level kepercayaan
Pilih identifier yang akan Anda gunakan untuk pencocokan dan pembaruan—biasanya email, domain, telepon, dan ID pelanggan internal.
Tetapkan setiapnya dengan level kepercayaan: kunci mana yang otoritatif, mana yang “best effort”, dan mana yang sebaiknya tidak pernah ditimpa.
Perjelas kepemilikan dan izin edit
Sepakati siapa yang memiliki field mana (Sales ops, Support, Marketing, Customer success) dan definisikan aturan edit: apa yang bisa diubah manusia, apa yang bisa diubah otomatisasi, dan apa yang memerlukan persetujuan.
Goverance ini menghemat waktu ketika hasil enrichment bertentangan dengan data yang ada.
Pilih Sumber Enrichment dan Kontrak Data
Sebelum menulis kode integrasi, putuskan dari mana data enrichment akan datang dan apa yang boleh Anda lakukan dengannya. Ini mencegah mode kegagalan umum: merilis fitur yang bekerja secara teknis tetapi melanggar ekspektasi biaya, keandalan, atau kepatuhan.
Sumber enrichment tipikal
Anda biasanya akan menggabungkan beberapa input:
- Sistem internal: CRM, penagihan, tiket support, analitik produk, platform email, data warehouse
- API pihak ketiga: firmografis perusahaan, validasi kontak, kode industri, technografis, sinyal risiko
- Daftar yang diunggah: CSV dari tim sales, acara, mitra, atau penyedia data
- Webhook: pembaruan real-time dari alat yang sudah mengamati perubahan (mis. verifikasi email, penyedia identitas)
Cara mengevaluasi sumber
Untuk setiap sumber, beri skor pada cakupan (seberapa sering mengembalikan sesuatu yang berguna), kebaruan (seberapa cepat terupdate), biaya (per panggilan/per record), batas laju, dan ketentuan penggunaan (apa yang boleh disimpan, berapa lama, dan untuk tujuan apa).
Periksa juga apakah penyedia mengembalikan skor keyakinan dan provenance yang jelas (dari mana sebuah field berasal).
Definisikan kontrak data
Perlakukan setiap sumber sebagai kontrak yang menentukan nama dan format field, field wajib vs opsional, frekuensi pembaruan, latensi yang diharapkan, kode error, dan semantik confidence.
Sertakan pemetaan eksplisit (“field penyedia → field kanonis Anda”) plus aturan untuk null dan nilai konflik.
Keputusan fallback dan penyimpanan
Rencanakan apa yang terjadi ketika sumber tidak tersedia atau mengembalikan hasil dengan kepercayaan rendah: retry dengan backoff, masukkan antrean untuk nanti, atau fallback ke sumber sekunder.
Putuskan apa yang Anda simpan (atribut stabil yang dibutuhkan untuk pencarian/pelaporan) versus apa yang dihitung on demand (lookup yang mahal atau sensitif waktu).
Terakhir, dokumentasikan pembatasan penyimpanan atribut sensitif (mis. identifier pribadi, demografi terinferensi) dan tetapkan aturan retensi sesuai.
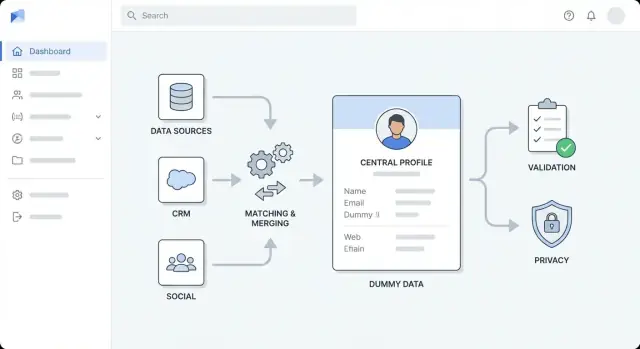
Rancang Arsitektur Tingkat Tinggi
Sebelum memilih alat, putuskan bagaimana bentuk aplikasi. Arsitektur tingkat tinggi yang jelas membuat pekerjaan enrichment lebih dapat diprediksi, mencegah “quick fixes” menjadi sampah permanen, dan membantu tim mengestimasi usaha.
Pilih gaya arsitektur yang cocok dengan tim Anda
Untuk sebagian besar tim, mulai dengan modular monolith: satu aplikasi yang dapat dideploy, dibagi secara internal menjadi modul-modul yang terdefinisi dengan baik (ingestion, matching, enrichment, UI). Lebih mudah dibangun, dites, dan debug.
Pindah ke layanan terpisah ketika ada alasan jelas—mis. throughput enrichment tinggi, perlu skala independen, atau tim berbeda memiliki kepemilikan berbeda. Pembagian umum:
- Layanan API (permintaan sinkron, autentikasi, CRUD record)
- Layanan worker (enrichment asinkron, retry)
- UI (review, approval, aksi massal)
Pisahkan concern ke lapisan
Pertahankan batasan eksplisit agar perubahan tidak menyebar ke mana-mana:
- Lapisan ingestion: import dari CRM/file dan normalisasi input
- Lapisan enrichment: memanggil vendor/sumber internal dan menyimpan hasil
- Lapisan validasi: menerapkan aturan kualitas data dan menandai exception
- Lapisan penyimpanan: profil pelanggan, payload sumber mentah, sejarah audit
- Lapisan presentasi: tampilan UI, antrean review, approval
Rancang untuk enrichment asinkron sejak hari pertama
Enrichment lambat dan rentan gagal (batas laju, timeout, data parsial). Perlakukan enrichment sebagai job:
- API membuat job dan merespons cepat
- Worker memproses job via queue (dengan retry dan backoff)
- UI menampilkan status job dan memungkinkan re-run bila perlu
Rencanakan environment dan konfigurasi
Siapkan dev/staging/prod sejak awal. Simpan kunci vendor, threshold, dan feature flag di konfigurasi (bukan kode), dan buat mudah untuk mengganti penyedia per environment.
Sinkronkan dengan diagram satu halam
Sketsakan diagram sederhana yang menunjukkan: UI → API → database, plus queue → workers → penyedia enrichment. Gunakan itu dalam review sehingga semua setuju pada tanggung jawab sebelum implementasi.
Prototyping jalur cepat (opsional)
Jika tujuan Anda memvalidasi alur kerja dan layar review sebelum menginvestasikan siklus engineering penuh, platform vibe-coding seperti Koder.ai dapat membantu mem-prototype inti aplikasi dengan cepat: UI berbasis React untuk review/approval, lapisan API Go, dan penyimpanan berbasis PostgreSQL.
Ini berguna untuk membuktikan model job (enrichment asinkron dengan retry), sejarah audit, dan pola akses berbasis peran, lalu mengekspor kode sumber saat siap untuk produksionalisasi.
Siapkan Penyimpanan, Queue, dan Layanan Pendukung
Sebelum mulai menghubungkan penyedia enrichment, perbaiki “plumbing”-nya. Keputusan penyimpanan dan pemrosesan background sulit diubah nanti, dan mereka langsung memengaruhi keandalan, biaya, dan auditabilitas.
Database utama: profil + histori
Pilih database utama untuk profil pelanggan yang mendukung data terstruktur dan atribut fleksibel. Postgres adalah pilihan umum karena dapat menyimpan field inti (nama, domain, industri) bersamaan dengan field enrichment semi-terstruktur (JSON).
Sama pentingnya: simpan riwayat perubahan. Alih-alih menimpa nilai tanpa jejak, tangkap siapa/apa yang mengubah field, kapan, dan mengapa (mis. “vendor_refresh”, “manual_approval”). Ini memudahkan approval dan menjaga aman saat rollback.
Queue: enrichment dan retry
Enrichment bersifat asinkron: API membatasi laju, jaringan gagal, dan beberapa vendor merespons lambat. Tambahkan job queue untuk pekerjaan background:
- Permintaan enrichment (single record dan massal)
- Retry dengan backoff
- Refresh terjadwal (mis. setiap 30/90 hari)
- Dead-letter handling untuk job yang terus gagal
Ini menjaga UI tetap responsif dan mencegah gangguan vendor menjatuhkan aplikasi.
Cache: lookup cepat dan pelacakan rate-limit
Cache kecil (mis. Redis) membantu lookup sering (mis. “perusahaan berdasarkan domain”) dan melacak rate limit vendor serta jendela cooldown. Berguna juga untuk idempotency keys agar import berulang tidak memicu enrichment ganda.
Penyimpanan file dan retensi
Rencanakan object storage untuk import/ekspor CSV, laporan error, dan file “diff” yang digunakan dalam alur review.
Tetapkan aturan retensi sejak awal: simpan payload vendor mentah hanya selama diperlukan untuk debugging dan audit, dan hapus log sesuai jadwal yang selaras dengan kebijakan kepatuhan Anda.
Bangun Pipeline Ingestion dan Normalisasi
Prototipe Alur Pengayaan
Buat prototipe aplikasi pengayaan dari rencana obrolan, lalu sempurnakan dengan mode perencanaan.
Aplikasi enrichment hanya sebaik data yang Anda berikan. Ingestion adalah tempat Anda memutuskan bagaimana informasi masuk, dan normalisasi adalah tempat Anda membuat informasi itu konsisten agar dapat dicocokkan, diperkaya, dan dilaporkan.
Putuskan bagaimana data masuk
Kebanyakan tim membutuhkan campuran titik masuk:
- Endpoint API untuk produk Anda atau alat internal mendorong pelanggan baru/terupdate
- Webhook dari CRM atau sistem penagihan untuk perubahan real-time
- Pull terjadwal (sinkron malam) untuk sistem yang tidak mendukung push
- Import CSV untuk backfill dan upload sekali
Apapun yang Anda dukung, buat langkah “raw ingest” ringan: terima data, autentikasi, log metadata, dan enqueue pekerjaan untuk pemrosesan.
Normalisasi dan standardisasi sejak awal
Buat lapisan normalisasi yang mengubah input berantakan menjadi bentuk internal yang konsisten:
- Nama: potong spasi, pisah nama lengkap bila memungkinkan, tangani casing
- Telepon: ubah ke format E.164 dan simpan asumsi negara eksplisit
- Alamat: standarkan field (street, locality, region, postal code) dan simpan teks asli
- Domain/email: lowercase, hapus parameter tracking dari URL, validasi sintaks
Validasi, karantina, dan jaga idempotensi
Tentukan field wajib per tipe record dan tolak atau karantina record yang gagal pemeriksaan (mis. email/domain hilang untuk pencocokan perusahaan). Item yang dikarantina harus dapat dilihat dan diperbaiki di UI.
Tambahkan idempotency keys untuk mencegah pemrosesan ganda saat retry terjadi (biasa dengan webhook dan jaringan yang flakey). Pendekatan sederhana adalah hashing (source_system, external_id, event_type, event_timestamp).
Lacak lineage per field
Simpan provenance untuk setiap record dan, idealnya, setiap field: sumber, waktu ingestion, dan versi transformasi. Ini membuat pertanyaan seperti: “Mengapa nomor telepon ini berubah?” dan “Import mana yang menghasilkan nilai ini?” dapat dijawab.
Implementasikan Pencocokan, Deduplikasi, dan Penggabungan
Memperoleh enrichment yang benar bergantung pada mengidentifikasi siapa itu siapa secara andal. Aplikasi Anda memerlukan aturan pencocokan yang jelas, perilaku merge yang dapat diprediksi, dan jaring pengaman saat sistem tidak yakin.
Definisikan aturan pencocokan (dan ambang kepercayaan)
Mulai dengan identifier deterministik:
- Kunci tepat: email (dinormalisasi ke lowercase), customer ID, tax/VAT ID, atau domain yang terverifikasi
Kemudian tambahkan pencocokan probabilistik untuk kasus di mana kunci tepat tidak ada:
- Pencocokan fuzzy: nama + domain perusahaan, nama + lokasi, kesamaan telepon
Tetapkan skor pencocokan dan ambang batas, misalnya:
- Auto-merge hanya di atas ambang tinggi
- Antri untuk review manual di rentang “mungkin”
- Tolak di bawah ambang rendah
Rencanakan logika deduplikasi dan merge
Ketika dua record mewakili pelanggan yang sama, tentukan bagaimana field dipilih:
- Presedensi field: “email terverifikasi mengalahkan yang tidak terverifikasi,” “timestamp lebih baru menang,” “CRM mengesampingkan enrichment untuk pemilik kontak”
- Skor kepercayaan sumber: urutkan sumber (CRM, penagihan, penyedia enrichment) untuk menyelesaikan konflik
- Penanganan konflik: simpan kedua nilai jika memungkinkan (mis. beberapa nomor telepon) atau simpan nilai yang kalah di histori
Jejak audit dan alur review
Setiap merge harus membuat event audit: siapa/apa yang memicunya, nilai sebelum/sesudah, kapan, skor pencocokan, dan ID record yang terlibat.
Untuk pencocokan yang ambigu, sediakan layar review dengan perbandingan berdampingan dan opsi “merge / tidak merge / minta data lebih banyak.”
Pengaman terhadap merge massal tak sengaja
Minta konfirmasi ekstra untuk merge massal, batasi jumlah merge per job, dan dukung preview “dry run”.
Tambahkan juga jalur undo (atau pembalikan merge) menggunakan histori audit sehingga kesalahan tidak permanen.
Integrasikan API Enrichment dan Tangani Keandalan
Enrichment adalah titik di mana aplikasi Anda bertemu dunia luar—banyak penyedia, respons yang tidak konsisten, dan ketersediaan yang tak terduga. Perlakukan setiap penyedia sebagai konektor yang bisa dipasang sehingga Anda dapat menambah, menukar, atau menonaktifkan sumber tanpa mengubah seluruh pipeline.
Bangun konektor penyedia (auth, retry, pemetaan error)
Buat satu konektor per penyedia enrichment dengan antarmuka konsisten (mis. enrichPerson(), enrichCompany()). Simpan logika spesifik penyedia di dalam konektor:
- Autentikasi (API key, token OAuth, refresh token)
- Retry standar untuk kegagalan sementara
- Pemetaan error (ubah error penyedia menjadi kategori Anda sendiri seperti
invalid_request,not_found,rate_limited,provider_down)
Ini menyederhanakan alur downstream: mereka menangani tipe error Anda, bukan quirks tiap penyedia.
Tangani rate limit dengan throttling dan backoff
Sebagian besar API enrichment memberlakukan kuota. Tambahkan throttling per penyedia (dan kadang per endpoint) agar permintaan tetap di bawah batas.
Saat terkena limit, gunakan exponential backoff dengan jitter dan hormati header Retry-After jika ada.
Rencanakan juga kegagalan “lambat”: timeout dan respons parsial harus ditangani sebagai event yang bisa di-retry, bukan hilang diam-diam.
Simpan confidence dan bukti (sesuai kebijakan)
Hasil enrichment jarang absolut. Simpan skor keyakinan penyedia bila tersedia, plus skor internal Anda berdasarkan kualitas pencocokan dan kelengkapan field.
Jika kontrak dan kebijakan privasi mengizinkan, simpan bukti mentah (URL sumber, identifier, timestamp) untuk mendukung audit dan membangun kepercayaan pengguna.
Strategi multi-penyedia: pilih “yang terbaik tersedia”
Dukung banyak penyedia dengan aturan pemilihan: termurah pertama, skor tertinggi, atau per-field “yang terbaik tersedia”.
Catat penyedia yang menyuplai setiap atribut agar Anda bisa menjelaskan perubahan dan melakukan rollback bila perlu.
Aturan refresh terjadwal
Enrichment menjadi usang. Terapkan kebijakan refresh seperti “re-enrich setiap 90 hari,” “refresh saat field kunci berubah,” atau “refresh hanya jika kepercayaan menurun.”
Jadwalkan bisa dikonfigurasi per pelanggan dan per tipe data untuk mengontrol biaya dan noise.
Tambahkan Aturan Kualitas Data dan Validasi
Pertahankan Kepemilikan Penuh
Saat siap, ekspor kode sumber dan pindahkan ke pipeline Anda yang sudah ada.
Enrichment hanya membantu jika nilai baru dapat dipercaya. Perlakukan validasi sebagai fitur inti: melindungi pengguna dari import berantakan, respons pihak ketiga yang tidak andal, dan korupsi saat merge.
Definisikan aturan validasi per field
Mulailah dengan “katalog aturan” sederhana per field, dipakai bersama oleh UI form, pipeline ingestion, dan API publik.
Aturan umum termasuk pemeriksaan format (email, telepon, kode pos), nilai yang diizinkan (kode negara, daftar industri), rentang (jumlah karyawan, band pendapatan), dan ketergantungan yang wajib (jika country = US, maka state wajib).
Pertahankan aturan versi sehingga Anda bisa mengubahnya dengan aman seiring waktu.
Tambahkan pemeriksaan kualitas yang mencerminkan penggunaan nyata
Selain validasi dasar, jalankan pemeriksaan kualitas data yang menjawab pertanyaan bisnis:
- Kelengkapan: Apakah kita memiliki field minimum untuk menggunakan record?
- Keunikan: Apakah identifier “unik” (domain, tax ID) terduplikasi?
- Konsistensi: Apakah field terkait cocok (country vs. kode telepon)?
- Ketepatan waktu: Seberapa lama nilai itu, dan apakah perlu di-refresh?
Beri skor pada record dan sumber
Ubah pemeriksaan menjadi scorecard: per record (kesehatan keseluruhan) dan per sumber (seberapa sering memberi nilai valid/terkini).
Gunakan skor untuk mengarahkan otomatisasi—mis. hanya menerapkan enrichment otomatis di atas ambang tertentu.
Rute kegagalan secara prediktabel
Saat record gagal validasi, jangan buang.
Kirim ke antrean “data-quality” untuk retry (isu sementara) atau review manual (input buruk). Simpan payload gagal, pelanggaran aturan, dan saran perbaikan.
Buat error mudah dipahami
Kembalikan pesan yang jelas dan dapat ditindaklanjuti untuk import dan klien API: field mana yang gagal, mengapa, dan contoh nilai yang valid.
Ini mengurangi beban support dan mempercepat pembersihan.
Buat UI untuk Review, Approval, dan Pekerjaan Massal
Pipeline enrichment Anda hanya memberi nilai ketika orang bisa meninjau apa yang berubah dan dengan percaya diri mendorong pembaruan ke sistem hulu. UI harus membuat “apa yang terjadi, mengapa, dan apa yang harus saya lakukan selanjutnya?” menjadi jelas.
Layar inti yang perlu dirancang
Profil pelanggan adalah basis. Tampilkan identifier kunci (email, domain, nama perusahaan), nilai field saat ini, dan badge status enrichment (mis. Belum diperkaya, Dalam proses, Perlu review, Disetujui, Ditolak).
Tambahkan timeline histori perubahan yang menjelaskan pembaruan dengan bahasa sederhana: “Ukuran perusahaan diubah dari 11–50 menjadi 51–200.” Buat setiap entri dapat diklik untuk melihat detail.
Sediakan saran merge saat duplikat terdeteksi. Tampilkan dua (atau lebih) record kandidat berdampingan dengan rekomendasi “survivor” dan preview hasil merge.
Pekerjaan massal yang sesuai operasi nyata
Sebagian besar tim bekerja dalam batch. Sertakan aksi massal seperti:
- Memperkaya record terpilih (atau enqueue untuk pemrosesan malam)
- Menyetujui/menolak saran merge
- Mengekspor hasil (CSV) untuk audit atau review offline
Gunakan langkah konfirmasi yang jelas untuk aksi destruktif (merge, overwrite) dengan jendela “undo” bila mungkin.
Pencarian cepat, filter, dan provenance per field
Tambahkan pencarian global dan filter berdasarkan email, domain, perusahaan, status, dan skor kualitas.
Biarkan pengguna menyimpan tampilan seperti “Perlu review” atau “Pembaruan kepercayaan rendah.”
Untuk setiap field yang diperkaya, tampilkan provenance: sumber, timestamp, dan confidence.
Panel sederhana “Mengapa nilai ini?” membangun kepercayaan dan mengurangi bolak-balik.
Alur terarah untuk pengguna non-teknis
Buat keputusan sederhana dan terarah: “Terima nilai yang disarankan,” “Pertahankan yang ada,” atau “Edit manual.” Jika diperlukan kontrol lebih mendalam, sembunyikan di bawah toggle “Advanced” sehingga tidak menjadi default.
Keamanan, Privasi, dan Dasar Kepatuhan
Bangun Aplikasi Inti dengan Cepat
Hasilkan UI review React, API Go, dan basis data PostgreSQL dalam satu tempat.
Aplikasi enrichment menyentuh identifier sensitif (email, nomor telepon, detail perusahaan) dan sering menarik data dari pihak ketiga. Perlakukan keamanan dan privasi sebagai fitur inti, bukan tugas "nanti".
Kontrol akses berbasis peran (RBAC)
Mulai dengan peran yang jelas dan default prinsip least-privilege:
- Admin: kelola user, peran, konektor, kebijakan retensi
- Ops: jalankan job enrichment, selesaikan konflik, setujui merge
- Viewer: akses read-only untuk pelaporan dan support
Pertahankan izin granular (mis. “export data”, “lihat PII”, “setujui merge”), dan pisahkan environment sehingga data produksi tidak tersedia di dev.
Lindungi data sensitif
Gunakan TLS untuk semua lalu lintas dan enkripsi saat istirahat untuk database dan object storage.
Simpan API key di secrets manager (bukan file env di source control), putar secara berkala, dan beri scope per environment.
Jika menampilkan PII di UI, tambahkan default aman seperti masking (mis. tampilkan 2–4 digit terakhir) dan minta izin eksplisit untuk menampilkan nilai penuh.
Persetujuan dan batasan penggunaan data
Jika enrichment bergantung pada consent atau ketentuan kontrak, enkode batasan itu dalam alur kerja:
- Lacak sumber data, tujuan, dan penggunaan yang diizinkan per field
- Dokumentasikan apa yang Anda simpan dan alasannya (halaman kebijakan internal singkat seperti /privacy atau /docs/data-handling membantu)
- Hindari mengumpulkan field yang tidak Anda butuhkan—lebih sedikit data berarti risiko lebih rendah
Auditing, retensi, dan penghapusan
Buat jejak audit untuk akses dan perubahan:
- Log siapa melihat/mengekspor record
- Log siapa mengubah apa dan kapan (nilai sebelum/sesudah, job ID, penyedia enrichment)
Terakhir, dukung permintaan privasi dengan tooling praktis: jadwal retensi, penghapusan record, dan alur “lupakan” yang juga membersihkan salinan di log, cache, dan backup bila memungkinkan (atau tandai untuk kadaluarsa).
Pemantauan, Analitik, dan Kontrol Operasional
Pemantauan bukan hanya untuk uptime—ini cara Anda menjaga enrichment dapat dipercaya saat volume, penyedia, dan aturan berubah.
Perlakukan setiap run enrichment sebagai job terukur dengan sinyal yang jelas untuk di-trend dari waktu ke waktu.
Metrik yang benar-benar membantu
Mulai dengan set metrik operasional kecil yang terkait outcome:
- Throughput job (record/menit) dan waktu-selesai per run
- Tingkat sukses vs tingkat gagal, dibagi menurut tipe kegagalan (validasi, pencocokan, penyedia)
- Latensi penyedia (p50/p95) dan timeout per sumber enrichment
- Tingkat pencocokan (seberapa sering Anda berhasil melampirkan enrichment)
- Duplikat yang dicegah (berapa banyak yang akan ter-merge salah tanpa pengecekan)
Angka-angka ini cepat menjawab: “Apakah kita memperbaiki data, atau cuma memindahkannya?”
Alert dan penjaga keamanan
Tambahkan alert yang memicu pada perubahan, bukan noise:
- Lonjakan kegagalan atau record yang dikarantina
- Antrian backlog atau konsumen lambat (sinyal pipeline macet)
- Gelombang error penyedia (429/5xx), latensi meningkat, atau timeout meningkat
Ikat alert ke tindakan konkret, seperti menjeda penyedia, menurunkan concurrency, atau beralih ke data cache/stale.
Dashboard admin untuk operator
Sediakan tampilan admin untuk run terbaru: status, hitungan, retry, dan daftar record yang dikarantina beserta alasan.
Sertakan kontrol “replay” dan aksi massal aman (retry semua timeout penyedia, jalankan ulang hanya proses matching).
Traceability dengan log
Gunakan structured logs dan correlation ID yang mengikuti satu record dari ujung ke ujung (ingest → match → enrichment → merge).
Ini membuat support pelanggan dan debugging insiden jauh lebih cepat.
Playbook insiden dan rollback
Tulis playbook singkat: apa yang dilakukan saat penyedia menurun, saat tingkat pencocokan runtuh, atau saat duplikat lolos.
Simpan opsi rollback (mis. batalkan merge untuk jangka waktu) dan dokumentasikan di /runbooks.
Pengujian, Rollout, dan Rencana Iterasi
Pengujian dan rollout adalah tempat aplikasi enrichment menjadi aman untuk dipercaya. Tujuannya bukan “lebih banyak tes”—tapi keyakinan bahwa pencocokan, merge, dan validasi berperilaku dapat diprediksi di bawah data dunia nyata yang berantakan.
Uji bagian yang berisiko terlebih dahulu
Prioritaskan tes di sekitar logika yang dapat merusak record secara silent:
- Aturan pencocokan: unit test untuk pencocokan tepat, fuzzy, dan komposit (mis. email + domain perusahaan). Sertakan near-duplicates dan field yang tertukar.
- Hasil merge: uji presedensi field (prioritas sumber), penanganan konflik, dan aturan “jangan timpa”.
- Kasus tepi validasi: email malformed, format telepon internasional, country hilang, identifier duplikat, dan nilai “unknown”.
Gunakan dataset sintetis (nama, domain, alamat yang dihasilkan) untuk memvalidasi akurasi tanpa mengekspos data pelanggan nyata.
Simpan “golden set” versi untuk output match/merge yang diharapkan sehingga regresi terlihat jelas.
Tahapkan rollout untuk mengurangi blast radius
Mulai kecil, lalu perluas:
- Pilot scope: satu tim atau satu segmen (mis. lead SMB saja)
- Aksi terbatas: mulai dengan “saran pembaruan” yang perlu persetujuan sebelum menulis kembali ke CRM
- Ramp up: tingkatkan volume record, lalu aktifkan penulisan otomatis untuk field berisiko rendah
Tentukan metrik keberhasilan sebelum memulai (presisi pencocokan, tingkat approval, pengurangan edit manual, dan waktu-ke-enrich).
Dokumentasikan alur kerja dan checklist integrasi
Buat dokumen singkat untuk pengguna dan integrator (link dari area produk Anda atau /pricing jika Anda membatasi fitur). Sertakan checklist integrasi:
- Metode auth API, batas laju, dan perilaku retry
- Field yang diperlukan untuk permintaan enrichment
- Payload webhook/event (dan versioning)
- Kode error dan aturan “partial enrichment”
- Ekspektasi log audit dan retensi data
Untuk perbaikan berkelanjutan, jadwalkan tinjauan ringan: analisis validasi gagal, override manual yang sering, dan mismatch—lalu perbarui aturan dan tambahkan tes.
Referensi praktis untuk memperketat aturan: /blog/data-quality-checklist.
Build vs. accelerate: catatan praktis
Jika Anda sudah tahu alur kerja target tetapi ingin mempersingkat waktu dari spesifikasi → aplikasi kerja, pertimbangkan menggunakan Koder.ai untuk menghasilkan implementasi awal (UI React, layanan Go, penyimpanan PostgreSQL) dari rencana berbasis chat terstruktur.
Tim sering menggunakan pendekatan ini untuk menyiapkan UI review, pemrosesan job, dan histori audit dengan cepat—lalu iterasi dengan planning mode, snapshot, dan rollback saat kebutuhan berkembang. Ketika Anda membutuhkan kontrol penuh, Anda dapat mengekspor kode sumber dan melanjutkan di pipeline yang ada. Koder.ai menawarkan tier free, pro, business, dan enterprise yang membantu mencocokkan eksperimen vs kebutuhan produksi.