Apa arti “di luar vs di dalam” dengan bahasa sederhana
Saat Anda membangun aplikasi, mudah membayangkan request tiba rapi, satu per satu, dalam urutan yang benar. Jaringan nyata tidak seperti itu. Pengguna menekan "Bayar" dua kali karena layar macet. Koneksi seluler terputus tepat setelah menekan tombol. Sebuah webhook datang terlambat, atau datang dua kali. Kadang-kadang tidak pernah datang sama sekali.
Ide Pat Helland tentang data di luar vs di dalam adalah cara yang rapi untuk memikirkan kekacauan itu.
Seperti apa “di luar”
"Di luar" adalah semua yang sistem Anda tidak kendalikan. Di situlah Anda berkomunikasi dengan orang dan sistem lain, dan di mana pengiriman tidak pasti: request HTTP dari browser dan aplikasi mobile, pesan dari antrean, webhook pihak ketiga (pembayaran, email, pengiriman), dan retry yang dipicu oleh klien, proxy, atau job background.
Di luar, anggap pesan bisa tertunda, terduplikasi, atau datang tidak berurutan. Bahkan jika sesuatu "biasanya andal," rancang untuk hari ketika tidak demikian.
Apa arti “di dalam”
"Di dalam" adalah apa yang sistem Anda bisa buat menjadi dapat diandalkan. Itu adalah state tahan lama yang Anda simpan, aturan yang Anda tegakkan, dan fakta yang bisa Anda buktikan nanti:
- Record database dan riwayatnya
- Aturan bisnis (misalnya: "sebuah order hanya bisa dibayar satu kali")
- Sumber kebenaran untuk status (pending, paid, canceled)
Di dalamlah Anda melindungi invariant. Jika Anda menjanjikan "satu pembayaran per order," janji itu harus ditegakkan di dalam, karena bagian luar tidak bisa dipercaya untuk berperilaku benar.
Perubahan mindsetnya sederhana: jangan mengasumsikan pengiriman sempurna atau waktu sempurna. Perlakukan setiap interaksi dari luar sebagai saran yang tidak andal yang mungkin diulang, dan buat bagian dalam bereaksi dengan aman.
Ini penting bahkan untuk tim kecil dan aplikasi sederhana. Saat pertama kali gangguan jaringan membuat charge duplikat atau order tersangkut, itu berhenti menjadi teori dan menjadi refund, tiket dukungan, dan hilangnya kepercayaan.
Contoh konkret: pengguna menekan "Place order," aplikasi mengirim request, dan koneksi terputus. Pengguna mencoba lagi. Jika bagian dalam Anda tidak punya cara untuk mengenali "ini adalah percobaan yang sama," Anda mungkin membuat dua order, memesan inventori dua kali, atau mengirim dua konfirmasi email.
Pelajaran utama dari Pat Helland
Inti pemikiran Helland sederhana: dunia luar tidak pasti, tetapi bagian dalam sistem Anda harus tetap konsisten. Jaringan menjatuhkan paket, ponsel kehilangan sinyal, jam terpaut, dan pengguna menekan refresh. Aplikasi Anda tidak bisa mengendalikan itu semua. Yang bisa dikendalikan adalah apa yang Anda terima sebagai "benar" setelah data melewati batas yang jelas.
Waktu dan ketidakpastian dalam satu momen sehari-hari
Bayangkan seseorang memesan kopi lewat ponsel sambil berjalan di gedung dengan Wi‑Fi buruk. Mereka mengetuk "Bayar." Spinner berputar. Jaringan terputus. Mereka mengetuk lagi.
Mungkin request pertama sampai ke server Anda, tapi respons tidak pernah kembali. Atau mungkin tidak ada request yang sampai. Dari pandangan pengguna, kedua kemungkinan itu terlihat sama.
Itulah waktu dan ketidakpastian: Anda belum tahu apa yang terjadi, dan mungkin akan tahu nanti. Sistem Anda perlu berperilaku masuk akal saat menunggu.
Retry, duplikasi, dan reordering
Setelah Anda menerima bahwa bagian luar tidak andal, beberapa perilaku "aneh" menjadi normal:
- Retry menghasilkan duplikat (dua request "Bayar").
- Pesan datang tidak berurutan ("batal" tiba sebelum "bayar").
- Sebuah request diproses, tetapi klien tidak pernah melihat responsnya.
Data dari luar adalah klaim, bukan fakta. "Saya sudah bayar" hanyalah pernyataan yang dikirim lewat saluran yang tidak andal. Itu menjadi fakta hanya setelah Anda mencatatnya di dalam sistem dengan cara yang tahan lama dan konsisten.
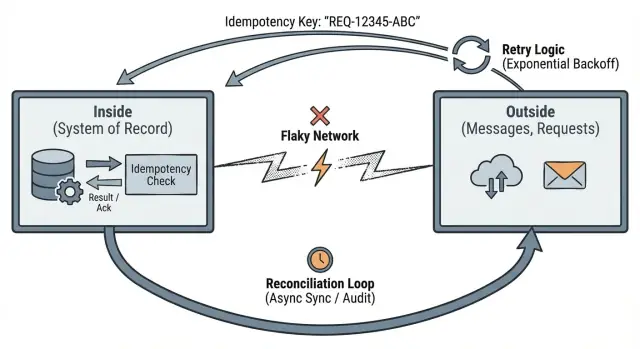
Ini mendorong Anda ke tiga kebiasaan praktis: definisikan batas yang jelas, buat retry aman dengan idempotensi, dan rencanakan rekonsiliasi ketika kenyataan tidak sesuai.
Batas yang jelas: apa yang dimiliki sistem Anda dan apa yang tidak
Ide "di luar vs di dalam" dimulai dengan pertanyaan praktis: di mana kebenaran sistem Anda dimulai dan berakhir?
Di dalam batas, Anda bisa membuat jaminan kuat karena Anda mengendalikan data dan aturan. Di luar batas, Anda melakukan upaya terbaik dan menganggap pesan bisa hilang, terduplikasi, tertunda, atau datang tidak berurutan.
Dalam aplikasi nyata, batas itu sering muncul di tempat seperti:
- Endpoint API yang menulis record ke database Anda
- Consumer antrean yang mengubah event menjadi perubahan tersimpan
- Handler callback yang mencatat apa yang dikatakan penyedia terjadi
- Pengirim yang memberi tahu sistem lain setelah Anda commit state sendiri
Setelah Anda menggambar garis itu, tentukan invariant mana yang tidak bisa dinegosiasikan di dalamnya. Contoh:
- ID order unik di database Anda.
- Saldo tidak pernah negatif.
- Status hanya bergerak maju (created -> paid -> shipped).
- Setiap request eksternal yang Anda terima memiliki jejak audit tersimpan.
Batas juga perlu bahasa yang jelas untuk "di mana kita sekarang." Banyak kegagalan hidup di celah antara "kami mendengar Anda" dan "kami menyelesaikannya." Pola yang membantu adalah memisahkan tiga makna:
- Received: pesan sampai di edge Anda (belum tentu tersimpan)
- Accepted: Anda menyimpannya dan dapat mencoba kembali pekerjaan nanti dengan aman
- Processed: pekerjaan yang dimaksud selesai dan Anda mencatat hasilnya
Saat tim melewatkan ini, mereka mendapatkan bug yang hanya muncul di bawah beban atau selama pemadaman parsial. Satu sistem menggunakan "paid" untuk berarti uang ditangkap; sistem lain mengartikan itu sebagai percobaan pembayaran yang dimulai. Ketidaksesuaian itu menciptakan duplikat, order tersangkut, dan tiket dukungan yang tidak bisa direproduksi.
Idempotensi: membuat retry menjadi aman
Idempotensi berarti: jika request yang sama dikirim dua kali, sistem memperlakukannya seperti satu request dan mengembalikan hasil yang sama.
Retry itu normal. Timeout terjadi. Klien mengulangi diri. Jika bagian luar bisa mengulangi, bagian dalam Anda harus mengubah itu menjadi perubahan state yang stabil.
Contoh sederhana: sebuah aplikasi mobile mengirim "bayar $20" lalu koneksi terputus. Aplikasi mengulang. Tanpa idempotensi, pelanggan mungkin tertagih dua kali. Dengan idempotensi, request kedua mengembalikan hasil charge pertama.
Cara umum mengimplementasikan idempotensi
Kebanyakan tim menggunakan salah satu pola ini (kadang campuran):
- Idempotency key: klien mengirimkan key unik per aksi yang dimaksud (misal,
Idempotency-Key: ...). Server menyimpan key dan respons akhir.
- Tabel de-duplikasi: simpan baris yang di-key oleh (client_id, key) atau (order_id, operation) dan tolak efek samping kedua.
- Natural keys: gunakan identifier bisnis yang sudah unik, sehingga "create payment" hanya bisa ada sekali.
Saat duplikat datang, perilaku terbaik biasanya bukan "409 conflict" atau error generik. Perilaku terbaik adalah mengembalikan hasil yang sama seperti pertama kali, termasuk ID resource dan status yang sama. Itulah yang membuat retry aman untuk klien dan job background.
Di mana menyimpan record (dan berapa lama)
Record idempotensi harus hidup di dalam boundary Anda di penyimpanan tahan lama, bukan di memori. Jika API Anda restart dan lupa, jaminan keamanan hilang.
Simpan record cukup lama untuk menutup retry realistis dan pengiriman tertunda. Jendela waktu tergantung pada risiko bisnis: menit hingga jam untuk create berisiko rendah, hari untuk pembayaran/email/pengiriman di mana duplikasi mahal, dan lebih lama jika partner bisa retry dalam periode panjang.
Cara menghindari jebakan “transaksi terdistribusi”
Transaksi terdistribusi terdengar menenangkan: satu commit besar melintasi layanan, antrean, dan database. Dalam praktiknya sering tidak tersedia, lambat, atau terlalu rapuh untuk diandalkan. Begitu ada hop jaringan, Anda tidak bisa mengasumsikan semuanya commit bersama.
Jebakan umum adalah membangun workflow yang hanya berfungsi jika setiap langkah sukses sekarang juga: simpan order, charge kartu, reservasi inventori, kirim konfirmasi. Jika langkah 3 timeout, apakah itu gagal atau sukses? Jika Anda retry, akankah Anda double-charge atau double-reserve?
Dua pendekatan praktis menghindari ini:
- Outbox/inbox: tulis intent tahan lama di database Anda (baris outbox) dalam transaksi yang sama dengan perubahan state Anda, lalu worker mengirim pesan itu. Di sisi penerima, simpan inbox yang di-key oleh message ID sehingga penanganan aman jika pesan yang sama datang lagi.
- Langkah gaya saga dengan kompensasi: pecah workflow menjadi langkah-langkah kecil yang selesai secara independen. Jika langkah berikutnya gagal, jalankan kompensasi (mis. melepas inventori atau membatalkan order yang belum dibayar) daripada mencoba mengembalikan sejarah.
Pilih satu gaya per workflow dan konsisten. Mencampur "kadang kita pakai outbox" dengan "kadang kita anggap sukses sinkron" menciptakan kasus tepi yang sulit diuji.
Aturan sederhana membantu: jika Anda tidak bisa commit atomik melintasi batas, rancang untuk retry, duplikasi, dan penundaan.
Rekonsiliasi: bagaimana sistem nyata pulih dari ketidaksesuaian
Rekonsiliasi mengakui kebenaran dasar: ketika aplikasi Anda berbicara dengan sistem lain lewat jaringan, kadang-kadang Anda akan berbeda pendapat tentang apa yang terjadi. Request timeout, callback datang terlambat, dan orang mengulang aksi. Rekonsiliasi adalah cara Anda mendeteksi ketidaksesuaian dan memperbaikinya seiring waktu.
Perlakukan sistem luar sebagai sumber kebenaran yang independen. Aplikasi Anda menyimpan catatan internalnya sendiri, tetapi perlu cara untuk membandingkan catatan itu dengan apa yang partner, penyedia, dan pengguna sebenarnya lakukan.
Mekanisme rekonsiliasi umum
Kebanyakan tim menggunakan seperangkat alat sederhana (membosankan itu bagus): worker yang mencoba kembali aksi tertunda dan memeriksa status eksternal, pemindaian terjadwal untuk inkonsistensi, dan aksi perbaikan admin kecil untuk dukungan agar bisa retry, cancel, atau mark as reviewed.
Apa yang dibandingkan dan apa yang dicatat
Rekonsiliasi hanya bekerja jika Anda tahu apa yang dibandingkan: ledger internal vs ledger penyedia (pembayaran), status order vs status pengiriman (fulfillment), status langganan vs status penagihan.
Buat state yang dapat diperbaiki. Alih-alih langsung lompat dari "created" ke "completed," gunakan state penyangga seperti pending, on hold, atau needs review. Itu membuat aman untuk mengatakan "kami belum yakin," dan memberi rekonsiliasi tempat yang jelas untuk mendarat.
Tangkap jejak audit kecil pada perubahan penting:
- Kapan Anda mengirim request dan kapan terakhir kali Anda menerima balasan
- Correlation ID yang mengikat record Anda ke event/referensi eksternal
- Status eksternal terakhir yang diketahui (dan dari mana datangnya)
- Field alasan untuk override manual (siapa, apa, mengapa)
Contoh: jika aplikasi Anda meminta label pengiriman dan jaringan terputus, Anda mungkin berakhir dengan "tidak ada label" secara internal sementara kurir sebenarnya membuatnya. Worker rekonsiliasi dapat mencari berdasarkan correlation ID, menemukan label ada, dan memajukan order (atau menandainya untuk review jika detail tidak cocok).
Langkah demi langkah: merancang workflow yang tahan kegagalan jaringan
Setelah Anda mengasumsikan jaringan akan gagal, tujuannya berubah. Anda bukan berusaha membuat setiap langkah sukses dalam satu kali coba. Anda berusaha membuat setiap langkah aman diulang dan mudah diperbaiki.
Workflow praktis
-
Tulis pernyataan batas satu kalimat. Jelaskan apa yang dimiliki sistem Anda (sumber kebenaran), apa yang Anda mirror, dan apa yang hanya Anda minta dari sistem lain.
-
Daftar mode kegagalan sebelum jalur bahagia. Minimal: timeout (Anda tidak tahu apakah berhasil), request duplikat, sukses parsial (satu langkah terjadi, langkah berikutnya tidak), dan event yang datang tidak berurutan.
-
Pilih strategi idempotensi untuk tiap input. Untuk API sinkron, seringkali idempotency key ditambah hasil tersimpan. Untuk pesan/event, biasanya ID pesan unik dan record "apakah saya sudah memproses ini?".
-
Persist intent, lalu bertindak. Pertama simpan sesuatu yang tahan lama seperti "PaymentAttempt: pending" atau "ShipmentRequest: queued," lalu lakukan panggilan eksternal, lalu simpan hasilnya. Kembalikan reference ID yang stabil sehingga retry menunjuk pada intent yang sama alih-alih membuat yang baru.
-
Bangun rekonsiliasi dan jalur perbaikan, dan buat terlihat. Rekonsiliasi bisa berupa job yang memindai record "pending terlalu lama" dan memeriksa status lagi. Jalur perbaikan bisa berupa aksi admin aman seperti "retry," "cancel," atau "mark resolved," dengan catatan audit. Tambahkan observabilitas dasar: correlation ID, field status yang jelas, dan beberapa hitungan (pending, retries, failures).
Contoh: jika checkout timeout tepat setelah Anda memanggil penyedia pembayaran, jangan menebak. Simpan percobaan, kembalikan attempt ID, dan biarkan pengguna retry dengan idempotency key yang sama. Nanti, rekonsiliasi dapat mengonfirmasi apakah penyedia sudah menagih atau tidak dan memperbarui percobaan tanpa double-charge.
Contoh skenario: alur order dengan retry dan callback tertunda
Seorang pelanggan menekan "Place order." Layanan Anda mengirim request pembayaran ke penyedia, tetapi jaringan tidak stabil. Penyedia punya kebenarannya sendiri, dan database Anda punya kebenaran Anda. Mereka akan menyimpang kecuali Anda merancang untuk itu.
Apa yang terjadi di luar (event yang Anda tidak kendalikan)
Dari sudut pandang Anda, bagian luar adalah aliran pesan yang bisa terlambat, berulang, atau hilang:
- "Submit order" mengenai API Anda.
- Request pembayaran Anda pergi ke penyedia.
- Penyedia mengirim webhook yang mengatakan "authorized."
- Penyedia mengulang webhook dan mengirim callback yang sama lagi.
- Klien Anda timeout dan mengulang "Place order."
Tidak satu pun dari langkah itu menjamin "exactly once." Mereka hanya menjamin "mungkin."
Apa yang Anda simpan di dalam (record yang Anda kendalikan)
Di dalam boundary Anda, simpan fakta tahan lama dan minimal yang diperlukan untuk mengaitkan event luar ke fakta itu.
Saat pelanggan pertama kali melakukan order, buat record order dengan status jelas seperti pending_payment. Juga buat record payment_attempt dengan referensi unik penyedia plus idempotency_key yang terkait dengan aksi pelanggan.
Jika klien timeout dan retry, API Anda tidak seharusnya membuat order kedua. Ia harus mencari idempotency_key dan mengembalikan order_id yang sama dan status saat ini. Pilihan itu mencegah duplikasi ketika jaringan gagal.
Sekarang webhook tiba dua kali. Callback pertama memperbarui payment_attempt ke authorized dan memindahkan order ke paid. Callback kedua mencapai handler yang sama, tetapi Anda mendeteksi bahwa Anda sudah memproses event penyedia itu (dengan menyimpan provider event ID, atau dengan memeriksa status saat ini) dan tidak melakukan apa-apa. Anda masih bisa merespons 200 OK, karena hasilnya sudah benar.
Akhirnya, rekonsiliasi menangani kasus-kasus berantakan. Jika order masih pending_payment setelah jeda, job background memanggil penyedia lagi menggunakan referensi yang disimpan. Jika penyedia mengatakan "authorized" tetapi Anda melewatkan webhook, Anda memperbarui record. Jika penyedia mengatakan "failed" tetapi Anda menandainya paid, Anda menandai untuk review atau memicu aksi kompensasi seperti refund.
Kesalahan umum yang menyebabkan duplikasi dan status tersangkut
Kebanyakan record duplikat dan alur kerja "tersangkut" berasal dari mencampur apa yang terjadi di luar sistem Anda (request datang, pesan diterima) dengan apa yang Anda commit dengan aman di dalam sistem.
Kegagalan klasik: klien mengirim "place order," server Anda mulai bekerja, jaringan terputus, dan klien retry. Jika Anda memperlakukan tiap retry sebagai kebenaran baru, Anda mendapatkan double charge, order duplikat, atau email berulang.
Penyebab umum:
- Terlalu cepat mempercayai request masuk: mengirim email atau mencatat "order dibuat" sebelum commit database menjadi tahan lama.
- Retry yang membuat baris baru: menghasilkan ID order baru pada setiap percobaan alih-alih memetakan retry ke satu hasil.
- Menganggap pengiriman "exactly once": antrean dan callback tidak menjanjikan itu. Duplikasi, penundaan, dan reordering terjadi.
- Tidak ada identifier stabil: jika Anda tidak bisa menjawab "apakah saya pernah melihat niat ini sebelumnya?", Anda tidak bisa mencegah duplikasi.
- Hanya sukses/gagal, tanpa middle state: tanpa state pending/awaiting, timeout menjadi misteri dan pengguna mengklik lagi.
Satu masalah membuat semuanya lebih buruk: tidak ada jejak audit. Jika Anda menimpa field dan hanya menyimpan state terakhir, Anda kehilangan bukti yang diperlukan untuk rekonsiliasi nanti.
Pengecekan kesehatan yang baik: "Jika saya menjalankan handler ini dua kali, apakah hasilnya sama?" Jika jawabannya tidak, duplikasi bukan edge case langka. Mereka dijamin akan terjadi.
Daftar periksa cepat dan langkah praktis berikutnya
Jika Anda ingat satu hal: aplikasi Anda harus tetap benar bahkan ketika pesan datang terlambat, datang dua kali, atau tidak datang sama sekali.
Gunakan daftar periksa ini untuk menemukan titik lemah sebelum mereka menjadi record duplikat, pembaruan hilang, atau alur kerja tersangkut:
- Sumber kebenaran jelas: untuk tiap workflow, Anda bisa menunjuk satu tempat yang adalah "kebenaran" (sering database Anda).
- Setiap write bisa di-retry dengan aman: tiap command/API call punya idempotency key (atau natural unique key).
- ID stabil dan correlation ID ada ujung-ke-ujung: Anda bisa menelusuri satu aksi bisnis melalui log, tabel, dan callback.
- Rekonsiliasi berjalan otomatis: Anda secara berkala membandingkan "apa yang kita yakini" vs "apa yang terjadi" dan memperbaiki atau mengangkat alert yang jelas.
- Rollback tidak merusak state: perubahan state dapat diaudit dan kompatibel antar versi.
Jika Anda tidak bisa menjawab salah satu dengan cepat, itu biasanya berarti batas kabur atau transisi state hilang.
Langkah praktis berikutnya:
-
Rancang batas dan state terlebih dahulu. Definisikan sejumlah kecil status per workflow (mis. Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
-
Tambahkan idempotensi pada tempat yang paling berisiko. Mulailah dengan write berisiko tinggi: create order, capture payment, issue refund. Simpan idempotency key di PostgreSQL dengan constraint unik sehingga duplikat ditolak dengan aman.
-
Perlakukan rekonsiliasi sebagai fitur normal. Jadwalkan job yang mencari record "pending terlalu lama", memeriksa sistem eksternal lagi, dan memperbaiki state lokal.
-
Iterasi dengan aman. Sesuaikan transisi dan aturan retry, lalu uji dengan sengaja mengirim ulang request yang sama dan memproses ulang event yang sama.
Jika Anda membangun cepat di platform berbasis chat seperti Koder.ai (koder.ai), tetaplah menanamkan aturan ini di layanan yang Anda hasilkan sejak awal: kecepatan datang dari otomatisasi, tetapi keandalan datang dari batas yang jelas, handler idempoten, dan rekonsiliasi.