Apa Arti “Distributed SQL” (Tanpa Hype)
“Distributed SQL” adalah database yang terasa seperti database relasional tradisional—tabel, baris, join, transaksi, dan SQL—tetapi dirancang untuk berjalan sebagai klaster di banyak mesin (seringkali lintas wilayah) sambil tetap berperilaku seperti satu basis data logis.
Kombinasi itu penting karena mencoba memberikan tiga hal sekaligus:
- SQL dan pemodelan relasional: skema yang familiar, constraint, dan tooling query.
- Skala-out: tambah node untuk meningkatkan kapasitas, bukan “membeli server lebih besar.”
- Konsistensi kuat: baca dan tulis mengikuti aturan transaksi yang jelas, bahkan saat data tersebar.
Antara RDBMS klasik dan NoSQL
RDBMS klasik (seperti PostgreSQL atau MySQL) biasanya paling mudah dioperasikan ketika semuanya berada di satu node primer. Anda bisa menskalakan pembacaan dengan replika, tetapi menskalakan penulisan dan bertahan dari outage regional biasanya membutuhkan arsitektur tambahan (sharding, failover manual, dan logika aplikasi yang hati-hati).
Banyak sistem NoSQL mengambil jalan sebaliknya: utamakan skala dan ketersediaan, kadang dengan merelaksasi jaminan konsistensi atau menawarkan model query yang lebih sederhana.
Distributed SQL mencari jalan tengah: pertahankan model relasional dan transaksi ACID, tetapi distribusikan data secara otomatis untuk menangani pertumbuhan dan kegagalan.
Masalah yang ingin diselesaikan
Database Distributed SQL dibuat untuk masalah seperti:
- Aplikasi global dengan pengguna di banyak wilayah, di mana latensi dan uptime sama-sama penting.
- Ketersediaan tinggi tanpa prosedur failover manual yang rumit.
- Pertumbuhan seiring waktu, di mana Anda ingin menambah kapasitas secara bertahap dan mempertahankan satu antarmuka database.
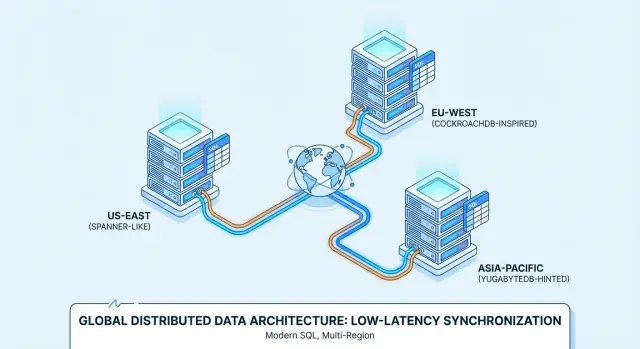
Itulah mengapa produk seperti Google Spanner, CockroachDB, dan YugabyteDB sering dievaluasi untuk penyebaran multi-wilayah dan layanan yang selalu aktif.
Tetapkan ekspektasi (bukan pilihan default)
Distributed SQL tidak otomatis “lebih baik.” Anda menerima lebih banyak bagian yang bergerak dan realitas performa yang berbeda (lompatan jaringan, konsensus, latensi lintas-wilayah) sebagai tukaran untuk ketahanan dan skala.
Jika beban kerja Anda muat pada satu database yang dikelola dengan baik dengan setup replikasi sederhana, RDBMS konvensional bisa lebih sederhana dan lebih murah. Distributed SQL layak ketika alternatifnya adalah sharding kustom, failover kompleks, atau kebutuhan bisnis yang menuntut konsistensi multi-wilayah dan uptime.
Cara Kerja Distributed SQL di Level Implementasi
Distributed SQL berusaha terasa seperti database SQL yang familiar sambil menyimpan data di banyak mesin (dan seringkali di banyak wilayah). Tantangannya adalah mengoordinasikan banyak komputer agar berperilaku sebagai satu sistem yang dapat diandalkan.
Replikasi + konsensus: bagaimana node sepakat
Setiap potongan data biasanya disalin ke beberapa node (replikasi). Jika satu node gagal, salinan lain masih bisa melayani baca dan menerima tulis.
Untuk mencegah replika menyimpang, sistem Distributed SQL menggunakan protokol konsensus—paling umum Raft (CockroachDB, YugabyteDB) atau Paxos (Spanner). Secara garis besar, konsensus berarti:
- Satu replika bertindak sebagai “pemimpin” untuk grup replika.
- Tulis dikirim ke pemimpin.
- Pemimpin hanya mengonfirmasi tulis setelah mayoritas replika mengakuinya.
“Suara mayoritas” itulah yang memberi Anda konsistensi kuat: setelah transaksi commit, klien lain tidak akan melihat versi data yang lebih lama.
Sharding/partisi: tempat data berada
Tidak ada satu mesin yang bisa menampung semuanya, jadi tabel dibagi menjadi potongan-potongan kecil yang disebut shard/partisi (Spanner menyebutnya splits; CockroachDB menyebutnya ranges; YugabyteDB menyebutnya tablets).
Setiap partisi direplikasi (menggunakan konsensus) dan ditempatkan pada node tertentu. Penempatan tidak acak: Anda bisa memengaruhinya lewat kebijakan (mis. simpan data pelanggan EU di wilayah EU, atau tempatkan partisi “hot” di node yang lebih cepat). Penempatan yang baik mengurangi perjalanan lintas jaringan dan membuat performa lebih dapat diprediksi.
Transaksi lintas node (dan mengapa itu menambah latensi)
Dengan database single-node, sebuah transaksi sering bisa commit hanya dengan operasi disk lokal. Di Distributed SQL, transaksi bisa menyentuh beberapa partisi—mungkin di node berbeda.
Commit yang aman biasanya memerlukan koordinasi tambahan:
- Mengunci atau memvalidasi data di partisipan yang terlibat
- Mereplikasi tulis lewat konsensus (pengakuan mayoritas)
- Finalisasi keputusan commit sehingga semua partisipan sepakat
Langkah-langkah itu memperkenalkan round trip jaringan, itulah mengapa transaksi terdistribusi biasanya menambah latensi—terutama ketika data melintasi wilayah.
Perilaku multi-wilayah: baca/tulis yang sadar lokalitas
Saat penyebaran melintasi wilayah, sistem berupaya menjaga operasi agar “dekat” dengan pengguna:
- Baca sadar-lokalitas bisa dilayani dari replika terdekat saat aman.
- Tulis sadar-lokalitas bisa diarahkan ke pemimpin di wilayah yang dipilih, atau menempatkan pemimpin dekat penulis utama.
Inilah inti keseimbangan multi-wilayah: Anda bisa mengoptimalkan respons lokal, tetapi konsistensi kuat lintas jarak jauh tetap akan menimbulkan biaya jaringan.
Kapan Anda Benar-benar Membutuhkannya (Dan Kapan Tidak)
Sebelum memilih distributed SQL, cek kebutuhan dasar Anda. Jika Anda punya satu wilayah primer, beban yang dapat diprediksi, dan tim operasi kecil, RDBMS konvensional (atau Postgres/MySQL terkelola) biasanya cara paling sederhana untuk mengirim fitur dengan cepat. Anda sering bisa memperpanjang setup satu-wilayah jauh dengan replika baca, caching, dan pengoptimalan skema/index.
Pemicu jelas: kapan Distributed SQL layak dipertimbangkan
Distributed SQL pantas dipertimbangkan saat satu (atau lebih) dari ini benar:
- Anda punya pengguna nyata di banyak wilayah dan ingin database dekat dengan mereka tanpa membangun sharding di level aplikasi.
- Persyaratan uptime tinggi (mis. harus tahan kegagalan zona/wilayah) dan satu wilayah primer tidak bisa diterima.
- Volume data atau throughput tulis melebihi skala vertikal, dan Anda ingin skala horizontal sambil mempertahankan semantik SQL.
- Anda butuh konsistensi kuat lintas node/wilayah untuk transaksi inti (pesanan, saldo, reservasi) tanpa menyatukan banyak sistem.
- Kepatuhan memaksa penempatan geografis (residensi data) sambil tetap membutuhkan satu basis data logis.
Anti-pemicu: kapan biasanya bukan pilihan yang tepat
Sistem terdistribusi menambah kompleksitas dan biaya. Berhati-hatilah jika:
- Tim Anda kecil dan tidak punya waktu mempelajari mode kegagalan dan pola operasi baru.
- Traffic rendah atau sporadis dan Anda tidak mungkin melampaui batas satu-wilayah segera.
- Anda punya anggaran latensi yang sangat ketat untuk tulis single-key dan tidak bisa mentolerir overhead koordinasi konsistensi kuat.
- Beban kerja Anda berat di analitik (scan besar, laporan kompleks). Anda mungkin lebih baik memisahkan OLTP dari analytics.
Checklist keputusan cepat
Jika Anda bisa menjawab “ya” untuk dua atau lebih, Distributed SQL kemungkinan layak dievaluasi:
- Apakah Anda butuh multi-wilayah dengan data konsisten?
- Apakah Anda butuh failover otomatis lintas zona/wilayah?
- Apakah skala menjadi krisis berulang?
- Apakah sharding menambah overhead engineering lebih besar daripada database itu sendiri?
- Apakah Anda perlu menegakkan residensi data dengan satu model operasional?
Konsistensi, Ketersediaan, dan Latensi: Tradeoff Inti
Distributed SQL terdengar seperti “mendapatkan semuanya sekaligus,” tetapi sistem nyata memaksa pilihan—terutama saat wilayah tidak bisa saling berkomunikasi dengan andal.
CAP, dijelaskan untuk keputusan produk
Anggap partisi jaringan sebagai “link antar wilayah bermasalah atau turun.” Saat itu terjadi, sebuah database bisa memprioritaskan:
- Konsistensi: semua melihat jawaban yang sama dan terbaru (atau operasi gagal).
- Ketersediaan: aplikasi terus menerima baca/tulis di tiap wilayah (meskipun jawaban sementara bisa berbeda).
Sistem Distributed SQL biasanya dibangun untuk mengutamakan konsistensi pada transaksi. Itu sering diinginkan tim—sampai sebuah partisi membuat operasi tertentu harus menunggu atau gagal.
Konsistensi kuat (dan mengapa uang serta inventaris peduli)
Konsistensi kuat berarti setelah transaksi commit, bacaan berikutnya mengembalikan nilai yang sudah di-commit—tidak ada “berhasil di satu wilayah tapi tidak di wilayah lain.” Ini kritis untuk:
- Pembayaran dan saldo (mencegah double-spend atau total yang keliru)
- Inventaris / reservasi (mencegah overselling barang terakhir)
Jika janji produk Anda adalah “saat kami konfirmasi, itu nyata,” konsistensi kuat adalah fitur, bukan kemewahan.
Read-your-writes dan isolasi di aplikasi nyata
Dua perilaku praktis yang penting:
- Read-your-writes: setelah pengguna memperbarui profilnya (atau membuat pesanan), layar berikutnya harus menunjukkan status baru, bukan replika yang lebih lama.
- Isolasi transaksi: menentukan bagaimana aksi konkuren berinteraksi. Dengan isolasi lebih kuat, Anda menghindari bug halus seperti dua pelanggan berhasil memesan kursi yang sama.
Biaya latensi dari konsensus lintas-wilayah
Konsistensi kuat lintas wilayah biasanya memerlukan konsensus (beberapa replika harus setuju sebelum commit). Jika replika tersebar antar benua, kecepatan cahaya menjadi pembatas produk: setiap tulis lintas-wilayah dapat menambah puluhan hingga ratusan milidetik.
Tradeoff-nya sederhana: lebih banyak keselamatan geografis dan kebenaran sering berarti latensi tulis lebih tinggi, kecuali Anda dengan cermat memilih di mana data tinggal dan di mana transaksi diizinkan commit.
Spanner vs CockroachDB vs YugabyteDB: Gambaran Praktis
Google Spanner adalah database Distributed SQL yang ditawarkan terutama sebagai layanan terkelola di Google Cloud. Ia dirancang untuk penyebaran multi-wilayah ketika Anda menginginkan satu basis data logis dengan data direplikasi di node dan wilayah. Spanner mendukung dua pilihan dialek SQL—GoogleSQL (dialek nativenya) dan dialek kompatibel PostgreSQL—jadi portabilitas bervariasi bergantung pada pilihan dialek dan fitur aplikasi Anda.
CockroachDB adalah database Distributed SQL yang berusaha terasa akrab bagi tim yang terbiasa dengan PostgreSQL. Ia menggunakan protokol wire PostgreSQL dan mendukung sebagian besar gaya SQL ala PostgreSQL, tetapi bukan pengganti Postgres byte-per-byte (beberapa ekstensi dan perilaku edge-case berbeda). Anda bisa menjalankannya sebagai layanan terkelola (CockroachDB Cloud) atau self-host.
YugabyteDB adalah database terdistribusi dengan API SQL kompatibel PostgreSQL (YSQL) dan API tambahan kompatibel Cassandra (YCQL). Seperti CockroachDB, sering dievaluasi oleh tim yang menginginkan ergonomi pengembangan mirip Postgres sambil melakukan scale-out lintas node dan wilayah. Tersedia self-host dan layanan terkelola (YugabyteDB Managed), dengan penyebaran umum dari HA satu-wilayah hingga multi-wilayah.
Managed vs self-hosted: apa yang berubah
Layanan terkelola biasanya mengurangi pekerjaan operasional (upgrade, backup, integrasi monitoring), sementara self-host memberi kontrol lebih atas jaringan, tipe instance, dan di mana data dijalankan secara fisik. Spanner paling umum dikonsumsi sebagai managed di GCP; CockroachDB dan YugabyteDB banyak terlihat di model managed dan self-host, termasuk multi-cloud dan on-prem.
Kompatibilitas SQL dalam praktik
Ketiganya berbicara “SQL,” tetapi kompatibilitas harian tergantung pada pilihan dialek (Spanner), cakupan fitur Postgres (CockroachDB/YugabyteDB), dan apakah aplikasi Anda bergantung pada ekstensi, fungsi, atau semantik transaksi Postgres tertentu.
Waktu pengujian di sini sangat berharga: uji query, migrasi, dan perilaku ORM Anda lebih awal daripada berasumsi kesetaraan drop-in.
Kasus Penggunaan: SaaS Global dengan Pengguna Regional
Uji Beban Kerja Nyata
Buat prototipe alur checkout, booking, atau ledger dan uji pola transaksi secara ujung ke ujung.
Cocok klasik untuk Distributed SQL adalah produk B2B SaaS dengan pelanggan di Amerika Utara, Eropa, dan APAC—mis. alat dukungan, platform HR, dashboard analytics, atau marketplace.
Kebutuhan bisnisnya sederhana: pengguna ingin responsivitas aplikasi "lokal", sementara perusahaan ingin satu basis data logis yang selalu tersedia.
Residensi data dan penempatan per-tenant
Banyak tim SaaS berakhir dengan campuran kebutuhan:
- Pelanggan EU mengharapkan data mereka tetap di EU (GDPR, komitmen kontraktual).
- Beberapa pelanggan meminta penyimpanan di dalam negeri (mis. Jerman, Australia, Singapura).
- Lainnya tidak peduli, tetapi tetap ingin latensi rendah.
Distributed SQL bisa memodelkannya dengan rapi menggunakan lokalitas per-tenant: tempatkan data primer tiap tenant di wilayah tertentu (atau set wilayah) sambil mempertahankan skema dan model query yang konsisten di seluruh sistem. Itu menghindarkan Anda dari “satu database per wilayah” yang berantakan sambil tetap memenuhi kebutuhan residensi.
Meminimalkan latensi: baca regional dan penempatan penulisan
Untuk menjaga aplikasi tetap cepat, umumnya Anda bertujuan:
- Baca regional: layani query berat-baca dari replika dekat pengguna.
- Penempatan tulis: tempatkan leader/tim replika primer di wilayah tempat tenant sering menulis.
Ini penting karena round trip lintas-wilayah mendominasi latensi yang dirasakan pengguna. Bahkan dengan konsistensi kuat, desain lokalitas yang baik memastikan sebagian besar permintaan tidak membayar biaya jaringan antar-benua.
Realitas operasional
Keuntungan teknis hanya berarti jika operasi tetap dapat dikelola. Untuk SaaS global, rencanakan:
- Perubahan skema online yang tidak mengunci tabel lintas wilayah.
- Migrasi tenant (memindahkan tenant dari satu wilayah ke wilayah lain dengan downtime minimal).
- Monitoring dan alerting untuk lag replikasi, hotspot, query lambat, dan insiden wilayah.
Jika dilakukan dengan baik, Distributed SQL memberi Anda pengalaman produk tunggal yang tetap terasa lokal—tanpa membagi tim engineering menjadi “stack EU” dan “stack APAC.”
Kasus Penggunaan: Alur Keuangan dan Ledger
Sistem finansial adalah area di mana “eventually consistent” bisa berubah jadi uang hilang. Jika pelanggan membuat pesanan, pembayaran diotorisasi, dan saldo diperbarui, langkah-langkah itu harus sepakat pada satu kebenaran—sekarang juga.
Konsistensi kuat penting karena mencegah dua wilayah (atau dua layanan) membuat keputusan “masuk akal” yang menghasilkan ledger yang salah.
Mengapa konsistensi kuat tidak bisa ditawar
Dalam alur tipikal—buat pesanan → reservasi dana → capture pembayaran → perbarui saldo/ledger—Anda menginginkan jaminan seperti:
- Pesanan tidak boleh ditandai “dibayar” jika capture pembayaran tidak terjadi.
- Saldo tidak boleh menjadi negatif karena dua transaksi bersaing.
- Refund tidak boleh diterapkan dua kali karena dua worker me-retry job yang sama.
Distributed SQL cocok di sini karena memberi Anda transaksi ACID dan constraint lintas node (dan seringkali lintas wilayah), sehingga invariansi ledger Anda bertahan bahkan saat terjadi kegagalan.
Idempotensi dan pola “tanpa double charge”
Sebagian besar integrasi pembayaran penuh dengan retry: timeout, webhook retry, dan pemrosesan ulang job adalah hal biasa. Database harus membantu membuat retry aman.
Pendekatan praktis adalah memadukan kunci idempotensi di level aplikasi dengan unik yang ditegakkan database:
- Simpan
idempotency_key per pelanggan/percobaan pembayaran.
- Tambahkan constraint unik pada
(account_id, idempotency_key).
- Bungkus “buat record pembayaran + terapkan entri ledger” dalam satu transaksi.
Dengan begitu, percobaan kedua menjadi no-op yang tidak berbahaya alih-alih double charge.
Menangani lonjakan tanpa merusak kebenaran
Event penjualan dan run payroll bisa menciptakan ledakan tulis mendadak (otorisasi, capture, transfer). Dengan Distributed SQL, Anda bisa scale out dengan menambah node untuk meningkatkan throughput tulis sambil mempertahankan model konsistensi yang sama.
Kuncinya adalah merencanakan hot keys (mis. satu akun merchant menerima semua traffic) dan menggunakan pola skema yang menyebarkan beban.
Kepatuhan, audit, dan retensi
Alur keuangan biasanya membutuhkan audit trail yang immutable, keterlacakan (siapa/apa/kapan), dan kebijakan retensi yang dapat diprediksi. Bahkan tanpa menyebut regulasi spesifik, anggaplah Anda perlu: entri ledger append-only, record berstempel waktu, kontrol akses, dan aturan retensi/arsip yang tidak mengorbankan auditabilitas.
Kasus Penggunaan: Inventaris, Booking, dan Reservasi
Latih Failover Lebih Awal
Terapkan lingkungan uji dan jalankan latihan kegagalan terhadap lalu lintas yang realistis.
Inventaris dan reservasi terlihat sederhana sampai Anda punya banyak wilayah yang melayani sumber daya langka yang sama: kursi terakhir konser, produk "limited drop", atau kamar hotel untuk malam tertentu.
Yang sulit bukan membaca ketersediaan—tetapi mencegah dua orang berhasil mengklaim item yang sama hampir bersamaan.
Dari mana konflik muncul
Dalam setup multi-wilayah tanpa konsistensi kuat, tiap wilayah bisa sementara percaya inventaris tersedia berdasarkan data yang sedikit kedaluwarsa. Jika dua pengguna checkout di wilayah berbeda selama jendela itu, kedua transaksi bisa diterima secara lokal dan kemudian bertabrakan saat rekonsiliasi.
Begitulah oversell lintas-wilayah terjadi: bukan karena sistem “salah”, tetapi karena sistem mengizinkan kebenaran yang berbeda-beda untuk sementara.
Distributed SQL sering dipilih di sini karena bisa menegakkan hasil otoritatif tunggal untuk alokasi tulis—jadi “kursi terakhir” benar-benar dialokasikan sekali, bahkan jika permintaan datang dari berbagai benua.
Contoh konkret
- Booking kursi: Dua pengguna klik titik yang sama di peta kursi. Dengan konsistensi kuat, hanya satu transaksi yang commit; yang lain langsung gagal dan UI dapat menyuruh refresh.
- Limited drops: 500 item live dan ribuan mencoba checkout. Anda menginginkan decrement-and-allocate atomik, bukan “usaha terbaik” dengan refund kemudian.
- Reservasi hotel: Unit inventaris bukan hanya kamar, tetapi room-night. Double-booking rentang tanggal itu mahal dan sulit dibalik.
Pola umum yang cocok dengan Distributed SQL
Hold + confirm: Tempatkan hold sementara (record reservasi) dalam transaksi, lalu konfirmasi pembayaran di langkah kedua.
Kedaluwarsa: Hold harus kedaluwarsa otomatis (mis. setelah 10 menit) agar inventaris tidak tertahan jika pengguna meninggalkan checkout.
Transactional outbox: Saat reservasi dikonfirmasi, tulis baris “event untuk dikirim” dalam transaksi yang sama, lalu kirim secara asinkron ke email, fulfillment, analytics, atau message bus—tanpa risiko celah "terbooking tapi konfirmasi tidak terkirim."
Intinya: jika bisnis Anda tidak bisa menoleransi double-allocation lintas wilayah, jaminan transaksi kuat menjadi fitur produk, bukan sekadar kelebihan teknis.
Kasus Penggunaan: Ketersediaan Tinggi dan Pemulihan Bencana
Ketersediaan tinggi (HA) cocok untuk Distributed SQL saat downtime mahal, outage tak terduga tak dapat diterima, dan Anda ingin agar pemeliharaan terasa membosankan.
Tujuannya bukan "tidak pernah gagal"—melainkan memenuhi SLO yang jelas (mis. 99.9% atau 99.99% uptime) bahkan saat node mati, zona gelap, atau Anda menerapkan upgrade.
“Always-on” dalam praktik: SLO, pemeliharaan, kegagalan
Mulailah dengan menerjemahkan “selalu aktif” menjadi ekspektasi terukur: downtime bulanan maksimum, recovery time objective (RTO), dan recovery point objective (RPO).
Sistem Distributed SQL bisa terus melayani baca/tulis melalui banyak kegagalan umum, tetapi hanya jika topologi Anda cocok dengan SLO dan aplikasi Anda menangani error sementara (retry, idempotensi) dengan rapi.
Pemeliharaan terencana juga penting. Rolling upgrade dan penggantian instance lebih mudah saat database bisa memindahkan leadership/replika menjauh dari node yang terdampak tanpa mematikan seluruh klaster.
Redundansi multi-zone vs multi-wilayah
Multi-zone melindungi Anda dari outage satu AZ/zone dan banyak kegagalan hardware, biasanya dengan latensi dan biaya lebih rendah. Seringkali cukup jika kepatuhan dan basis pengguna Anda kebanyakan di satu wilayah.
Multi-wilayah melindungi Anda dari outage regional penuh dan mendukung failover regional. Tradeoffnya adalah latensi tulis lebih tinggi untuk transaksi konsisten kuat yang melintasi wilayah, plus perencanaan kapasitas yang lebih kompleks.
Ekspektasi failover (dan pengujian dengan game days)
Jangan berasumsi failover instan atau tak terlihat. Definisikan apa arti “failover” untuk layanan Anda: lonjakan error singkat? periode read-only? beberapa detik latensi meningkat?
Jalankan "game days" untuk membuktikannya:
- Matikan sebuah node, lalu sebuah zone; verifikasi dashboard SLO dan budget error klien Anda.
- Simulasikan partisi jaringan dan verifikasi perilaku leader/replika.
- Latih evakuasi wilayah dan ukur RTO nyata.
Replikasi bukan backup
Bahkan dengan replikasi sinkron, tetap jaga backup dan latih pemulihan. Backup melindungi dari kesalahan operator (migrasi buruk, delete tidak sengaja), bug aplikasi, dan korupsi yang bisa terkopi.
Validasi point-in-time recovery (jika tersedia), kecepatan restore, dan kemampuan memulihkan ke lingkungan bersih tanpa menyentuh produksi.
Kasus Penggunaan: Residensi Data dan Arsitektur Berbasis Kepatuhan
Kebutuhan residensi data muncul ketika regulasi, kontrak, atau kebijakan internal mengatakan bahwa rekaman tertentu harus disimpan (dan kadang diproses) di dalam negara atau wilayah tertentu.
Ini bisa berlaku untuk data pribadi, informasi kesehatan, data pembayaran, beban kerja pemerintahan, atau dataset “milik pelanggan” di mana kontrak klien menentukan lokasi data.
Distributed SQL sering dipertimbangkan di sini karena bisa mempertahankan satu basis data logis sambil secara fisik menempatkan data di wilayah berbeda—tanpa memaksa Anda menjalankan stack aplikasi terpisah per geografi.
Mengapa aturan residensi mengubah desain database
Jika regulator atau pelanggan mensyaratkan "data tetap di wilayah", tidak cukup hanya punya replika rendah-latensi di dekatnya. Anda mungkin perlu menjamin bahwa:
- Salinan primer (atau semua salinan) data tertentu disimpan hanya di wilayah yang disetujui
- Backup dan snapshot mengikuti aturan yang sama
- Operator dan layanan di luar wilayah tidak bisa mengakses data mentah
Ini mendorong tim ke arsitektur di mana lokasi adalah perhatian utama, bukan tambahan belakangan.
Penempatan per-pelanggan dan kontrol akses (tingkat tinggi)
Polanya umum di SaaS adalah penempatan data per-tenant. Contoh: baris tenant EU dipinkan ke wilayah EU, pelanggan AS ke wilayah AS.
Secara garis besar Anda kombinasi:
- Aturan penempatan data (di mana data tenant boleh berada)
- Kontrol identitas dan akses (layanan/human mana yang bisa membacanya)
- Enkripsi dan manajemen kunci (kadang dengan kunci yang terikat wilayah)
Tujuannya membuat sulit melanggar residensi lewat akses operasional, restore backup, atau replikasi lintas-wilayah.
Persyaratan hukum berbeda—libatkan penasihat
Kewajiban residensi dan kepatuhan sangat bervariasi menurut negara, industri, dan kontrak. Mereka juga berubah dari waktu ke waktu.
Perlakukan topologi database sebagai bagian dari program kepatuhan Anda, dan validasi asumsi dengan penasihat hukum yang berkompeten (dan, jika relevan, auditor Anda).
Bagaimana topologi multi-wilayah memengaruhi reporting dan analytics
Topologi yang ramah residensi bisa mempersulit “pandangan global” bisnis. Jika data pelanggan sengaja disimpan di wilayah terpisah, analytics dan pelaporan mungkin:
- Membutuhkan pipeline pelaporan regional (compute berjalan di tempat data berada)
- Menggunakan ekspor teragregasi (hanya metrik yang diizinkan keluar wilayah)
- Menerima latensi lebih tinggi untuk dashboard lintas-wilayah, karena query global mungkin melintasi wilayah atau bergantung pada dataset terduplikasi/terturun
Dalam praktiknya, banyak tim memisahkan beban operasional (konsisten kuat, peka residensi) dari analytics (warehouse regional atau dataset agregat yang diatur ketat) agar kepatuhan tetap terkelola tanpa memperlambat pelaporan produk sehari-hari.
Rencanakan Topologi
Petakan region, tenant, dan aturan residensi data sebelum menulis migrasi.
Distributed SQL bisa menyelamatkan Anda dari outage menyakitkan dan keterbatasan regional, tetapi jarang menghemat uang secara default. Perencanaan awal membantu menghindari membayar “asuransi” yang sebenarnya tidak Anda butuhkan.
Penggerak biaya utama
Sebagian besar anggaran terbagi ke dalam empat kelompok:
- Node (compute): Anda membayar untuk menjaga banyak replika online—seringkali 3+ per wilayah—plus kapasitas ekstra untuk failover. Desain multi-wilayah biasanya memerlukan headroom lebih banyak daripada Postgres satu-wilayah.
- Storage: Replikasi menggandakan ukuran data. Dataset 2 TB dengan tiga replika menjadi ~6 TB sebelum backup, index, dan overhead.
- Traffic antar-wilayah: Replikasi lintas-wilayah, pembacaan, dan traffic klien bisa menjadi pos biaya material. Biasanya ini kejutan pertama setelah Anda aktif-aktif.
- Waktu operasional: Bahkan layanan terkelola membutuhkan kerja: tuning skema/query, respons insiden, perencanaan kapasitas, pengujian upgrade, dan tata kelola (terutama soal residensi/kepatuhan).
Memperkirakan dampak latensi pada journey pengguna nyata
Sistem Distributed SQL menambah koordinasi—terutama untuk tulis konsisten kuat yang harus dikonfirmasi kuorum.
Cara praktis memperkirakan dampak:
- Pilih 2–3 journey kunci (checkout, booking, “simpan perubahan”).
- Hitung berapa banyak transaksi tulis dan langkah read-after-write yang ada di jalur kritis.
- Untuk tiap langkah, asumsikan round trip multi-wilayah bila koordinasi diperlukan. Jika RTT lintas-wilayah 80–120 ms, dua langkah tulis berurutan bisa menambah 160–240 ms.
Ini tidak berarti “jangan lakukan”, tetapi berarti Anda harus merancang journey untuk mengurangi tulis berurutan (batching, retry idempoten, transaksi kurang chatty).
Kompleksitas vs alternatif yang lebih sederhana
Jika pengguna Anda kebanyakan di satu wilayah, Postgres satu-wilayah dengan replika baca, backup bagus, dan rencana failover teruji bisa lebih murah dan sederhana—dan cepat.
Distributed SQL menjustifikasi biayanya saat Anda benar-benar butuh tulis multi-wilayah, RPO/RTO ketat, atau penempatan ramah residensi.
Framing ROI sederhana
Anggap pengeluaran sebagai pertukaran:
- Risiko yang dihindari: lebih sedikit outage yang berdampak pada pendapatan, lebih kecil eksposur kehilangan data, lebih sedikit akhir pekan insiden global.
- Pendapatan yang terlindungi: konversi lebih tinggi dari latensi lebih rendah untuk pengguna regional, posisi enterprise yang lebih kuat (SLA, kepatuhan).
- Pengeluaran: klaster dasar + overhead replikasi + traffic + waktu engineering.
Jika kerugian yang dihindari (downtime + churn + risiko kepatuhan) lebih besar daripada premi berulang, desain multi-wilayah dibenarkan. Jika tidak, mulai lebih sederhana—dan siapkan jalur berkembang ke depan.
Checklist Adopsi dan Langkah Selanjutnya
Mengadopsi Distributed SQL lebih dari sekadar “angkat dan pindah” database; ini soal membuktikan bahwa beban kerja spesifik Anda berperilaku baik ketika data dan konsensus tersebar di node (dan mungkin wilayah). Rencana ringan membantu menghindari kejutan.
Proof-of-concept (PoC) fokus
Pilih satu beban kerja yang mewakili rasa sakit nyata: mis. checkout/booking, provisioning akun, atau posting ledger.
Tentukan metrik keberhasilan di muka:
- Korektness: tidak ada double-booking, tidak ada update hilang, perilaku transaksi yang dapat diprediksi
- SLO latensi: p50/p95 untuk 3 query teratas (sertakan target lintas-wilayah bila relevan)
- Throughput: QPS sustain saat puncak + margin keamanan (biasanya 2–3×)
- Ketahanan: perilaku saat node gagal dan (jika relevan) saat wilayah hilang
- Upaya operasional: waktu mendeteksi, mendiagnosis, dan memulihkan dari incident yang disimulasikan
Jika ingin maju lebih cepat di tahap PoC, buat permukaan aplikasi kecil yang "realistis" (API + UI) daripada hanya benchmark sintetis. Misalnya, tim kadang memakai Koder.ai untuk memutar aplikasi React + Go + PostgreSQL starter, lalu mengganti lapisan database ke CockroachDB/YugabyteDB (atau sambungkan ke Spanner) untuk menguji pola transaksi, retry, dan perilaku kegagalan end-to-end. Intinya bukan starter stack—tetapi mempersingkat loop dari “ide” ke “beban kerja yang bisa Anda ukur.”
Checklist desain (yang sering menyakiti kemudian)
- Skema: pilih primary key yang mendistribusikan tulis; hindari kunci berurutan yang “hot”
- Index: pertahankan hanya yang diperlukan; pahami amplifikasi tulis dari index sekunder
- Partisi/penempatan: putuskan partition key (dan aturan geo/zone) berdasarkan pola akses
- Hot spot: identifikasi “celebrity rows” (counter global, tabel single-tenant) dan desain ulang lebih awal
- Migrasi: rencanakan perubahan skema online dan backfill; uji jalur rollback
Hal operasional dasar dari hari pertama
Monitoring dan runbook sama pentingnya dengan SQL:
- Dashboard untuk latensi, retry, contention, kesehatan replikasi/konsensus, disk, dan compaction
- Runbook insiden: query lambat, restart node, replika gagal, beban tidak merata
- Load testing yang meniru produksi (campuran baca/tulis, lonjakan, transaksi panjang)
- Backup + latihan restore (termasuk point-in-time recovery jika didukung)
Langkah selanjutnya
Mulai dengan sprint PoC, lalu alokasikan waktu untuk tinjauan kesiapan produksi dan cutover bertahap (dual writes atau shadow reads bila mungkin).
Jika perlu bantuan menganggarkan biaya atau tier, lihat /pricing. Untuk walkthrough praktis dan pola migrasi, jelajahi /blog.
Jika Anda akhirnya mendokumentasikan temuan PoC, tradeoff arsitektur, atau pelajaran migrasi, pertimbangkan membagikannya dengan tim (dan publik jika memungkinkan): platform seperti Koder.ai bahkan menawarkan cara mendapatkan kredit untuk membuat konten edukasi atau merujuk pembuat lain, yang dapat menutup biaya eksperimen saat Anda mengevaluasi opsi.