Apa Arti Pencarian Semantik (Tanpa Basa-basi)
Pencarian semantik adalah cara mencari yang fokus pada apa yang Anda maksudkan, bukan hanya kata-kata persis yang Anda ketik.
Jika Anda pernah mencari sesuatu dan berpikir, “jawabannya jelas ada di sini—kenapa tidak ketemu?”, Anda merasakan batasan pencarian berbasis kata kunci. Pencarian tradisional mencocokkan istilah. Itu bekerja saat pengucapan dalam kueri dan konten saling tumpang tindih.
Kenapa pencarian kata kunci sering meleset
Pencarian kata kunci kesulitan dengan:
- Sinonim dan pengungkapan: “cancel” vs “close” vs “terminate” akun.
- Niat: “how do I stop being billed?” sebenarnya tentang membatalkan langganan.
- Konteks: “apple charger” (merek) vs “apple tree charger” (konyol, tapi Anda paham maksudnya).
Ia juga dapat memberi bobot berlebihan pada kata yang berulang, mengembalikan hasil yang tampak relevan di permukaan sementara mengabaikan halaman yang sebenarnya menjawab pertanyaan dengan kata-kata berbeda.
Contoh sederhana
Bayangkan pusat bantuan dengan artikel berjudul “Pause or cancel your subscription.” Seorang pengguna mencari:
“stop my payments next month”
Sistem kata kunci mungkin tidak memberi peringkat artikel itu tinggi jika tidak berisi kata “stop” atau “payments.” Pencarian semantik dirancang untuk memahami bahwa “stop my payments” sangat terkait dengan “cancel subscription,” dan menempatkan artikel itu di atas—karena maknanya selaras.
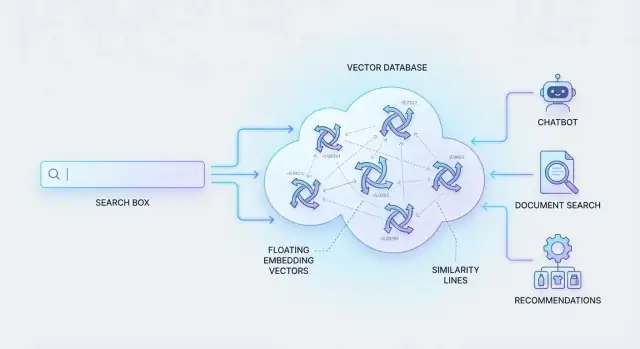
Di mana database vektor masuk
Untuk membuat ini bekerja, sistem merepresentasikan konten dan kueri sebagai “sidik jari makna” (angka yang menangkap kesamaan). Lalu mereka harus mencari melalui juta-an sidik jari ini dengan cepat.
Itu yang dibuat untuk database vektor: menyimpan representasi numerik ini dan mengambil kecocokan paling mirip secara efisien, sehingga pencarian semantik terasa instan bahkan pada skala besar.
Embedding: Mengubah Konten Menjadi Vektor Bermakna
Embedding adalah representasi numerik dari makna. Alih-alih menggambarkan sebuah dokumen dengan kata kunci, Anda mewakilinya sebagai daftar angka (sebuah “vektor”) yang menangkap apa yang dibahas konten itu. Dua potong konten yang bermakna serupa akan berakhir dengan vektor yang berdekatan di ruang numerik itu.
Seperti apa sebenarnya embedding
Anggap embedding sebagai koordinat di peta berdimensi sangat tinggi. Anda biasanya tidak akan membaca angkanya langsung—mereka tidak dibuat untuk manusia. Nilainya ada pada bagaimana mereka berperilaku: jika “cancel my subscription” dan “how do I stop my plan?” menghasilkan vektor yang berdekatan, sistem dapat menganggapnya terkait meskipun mereka berbagi sedikit (atau tak sama sekali) kata.
Teks, gambar, dan audio bisa jadi vektor
Embedding tidak terbatas pada teks.
- Embedding teks mewakili kalimat, paragraf, tiket dukungan, deskripsi produk, dan lainnya.
- Embedding gambar mewakili kesamaan visual dan konsep (mis. “sepatu lari merah”).
- Embedding audio bisa mewakili pembicara, nada, atau makna ucapan bila dipasangkan dengan model suara.
Inilah sebabnya satu database vektor bisa mendukung “pencarian dengan gambar”, “temukan lagu serupa”, atau “rekomendasi produk seperti ini.”
Dihasilkan oleh model—bukan ditulis manual
Vektor tidak berasal dari penandaan manual. Mereka dibuat oleh model machine learning yang dilatih untuk memampatkan makna menjadi angka. Anda mengirim konten ke model embedding (di-host sendiri atau oleh penyedia), dan model mengembalikan vektor. Aplikasi Anda menyimpan vektor itu berdampingan dengan konten asli dan metadata.
Kenapa pilihan embedding memengaruhi kualitas dan biaya
Model embedding yang Anda pilih memengaruhi hasil secara signifikan. Model yang lebih besar atau lebih spesifik sering meningkatkan relevansi tetapi lebih mahal (dan mungkin lebih lambat). Model yang lebih kecil bisa lebih murah dan cepat, tetapi mungkin kehilangan nuansa—terutama untuk bahasa domain-spesifik, multi-bahasa, atau kueri pendek. Banyak tim menguji beberapa model di awal untuk menemukan trade-off terbaik sebelum skala.
Cara Database Vektor Menyimpan Data
Database vektor dibangun di sekitar ide sederhana: menyimpan “makna” (sebuah vektor) bersama informasi yang Anda perlukan untuk mengidentifikasi, memfilter, dan menampilkan hasil.
Model data dasar
Sebagian besar record tampak seperti ini:
- ID: pengenal unik yang Anda kontrol (mis.
doc_18492 atau UUID)
- Vektor (embedding): array angka yang mewakili makna konten
- Metadata: field key–value seperti title, URL, tags, author, language, created_at, atau tenant_id
Misalnya, artikel pusat bantuan dapat menyimpan:
- ID:
kb_123
- Vektor: 768 angka floating-point (untuk model embedding umum)
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
Vektor yang mendorong kesamaan semantik. ID dan metadata yang membuat hasil bisa dipakai.
Metadata melakukan dua pekerjaan:
- Filtering sebelum/atau setelah pencarian vektor: “Hanya tampilkan hasil dari produk X,” “Hanya Bahasa Inggris,” “Hanya dokumen yang dapat diakses pengguna ini,” atau “Hanya item yang lebih baru dari 90 hari.” Ini penting untuk relevansi dan kontrol akses.
- Tampilan dan aksi: Saat menampilkan hasil, pengguna tidak mau melihat vektor—mereka mau judul, cuplik, dan tautan (URL). Metadata menyediakan detail yang dibutuhkan UI Anda.
Tanpa metadata yang baik, Anda mungkin mengambil makna yang benar tetapi tetap menampilkan konteks yang keliru.
Ukuran vektor umum dan implikasi penyimpanan
Ukuran embedding tergantung pada model: 384, 768, 1024, dan 1536 dimensi umum dipakai. Dimensi lebih banyak dapat menangkap nuansa, tetapi juga menambah:
- Penyimpanan (setiap record menyimpan lebih banyak angka)
- Tekanan memori untuk pencarian cepat
- Waktu pembuatan indeks (terutama dengan pengindeksan ANN)
Sebagai intuisi kasar: menggandakan dimensi sering menaikkan biaya dan latensi kecuali Anda mengimbangi dengan pilihan indeks atau kompresi.
Pola update: insert, change, dan delete
Dataset nyata berubah, jadi database vektor biasanya mendukung:
- Insert: menambahkan konten baru dengan embedding dan metadata-nya
- Update: mengubah metadata (mis. tags) atau mengganti vektor jika konten berubah
- Delete: menghapus konten usang atau dicabut
- Re-embed: menghitung ulang vektor ketika Anda mengganti model embedding, mengubah chunking, atau mengedit teks secara signifikan
Merencanakan update sejak awal mencegah masalah “pengetahuan usang” di mana pencarian mengembalikan konten yang tidak lagi sesuai.
Pencarian Kesamaan: Menemukan “Makna Terdekat” dengan Cepat
Setelah teks, gambar, atau produk Anda diubah menjadi embedding (vektor), pencarian menjadi masalah geometri: “Vektor mana yang paling dekat dengan vektor kueri ini?” Ini disebut nearest-neighbor search. Alih-alih mencocokkan kata kunci, sistem membandingkan makna dengan mengukur seberapa dekat dua vektor.
Nearest neighbors dengan bahasa sederhana
Bayangkan setiap potongan konten sebagai titik di ruang multi-dimensi yang sangat besar. Saat pengguna mencari, kuerinya diubah menjadi titik lain. Pencarian kesamaan mengembalikan item yang titiknya paling dekat—tetangga terdekat Anda. Tetangga itu kemungkinan berbagi niat, topik, atau konteks, bahkan jika mereka tidak berbagi kata yang sama.
Metrik kesamaan umum
Database vektor biasanya mendukung beberapa cara standar untuk memberi skor “kedekatan”:
- Cosine similarity: membandingkan sudut antara vektor (bagus saat Anda peduli pada arah/makna lebih dari magnitudo).
- Dot product: terkait dengan cosine, tetapi juga dipengaruhi panjang vektor; sering dipakai dengan embedding yang dinormalisasi.
- Euclidean distance: jarak garis lurus antara titik (berguna pada beberapa model dan domain).
Model embedding yang berbeda dilatih dengan metrik tertentu dalam pikiran, jadi penting menggunakan yang direkomendasikan oleh penyedia model.
Pencarian exact vs approximate (ANN)
Pencarian exact memeriksa setiap vektor untuk menemukan tetangga sejati terdekat. Itu akurat, tetapi menjadi lambat dan mahal saat Anda berskala ke jutaan item.
Sebagian besar sistem menggunakan pencarian approximate nearest neighbor (ANN). ANN memakai struktur indeks pintar untuk mempersempit pencarian ke kandidat paling menjanjikan. Biasanya Anda mendapatkan hasil yang “cukup dekat” dengan hasil terbaik—jauh lebih cepat.
Trade-off latensi vs recall
ANN populer karena memungkinkan Anda men-tune sesuai kebutuhan:
- Latensi lebih rendah (respon lebih cepat) dengan mencari lebih sedikit kandidat.
- Recall lebih tinggi (menemukan lebih banyak kecocokan terbaik) dengan mencari lebih banyak kandidat.
Itu sebabnya pencarian vektor bekerja baik di aplikasi nyata: respons tetap cepat sambil tetap mengembalikan hasil sangat relevan.
Alur Kerja Pencarian Semantik dari Awal hingga Akhir
Pencarian semantik paling mudah dipahami sebagai pipeline sederhana: Anda ubah teks menjadi makna, cari makna serupa, lalu tampilkan kecocokan paling berguna.
1) Embed kueri
Pengguna mengetik pertanyaan (misalnya: “How do I cancel my plan without losing data?”). Sistem menjalankan teks itu melalui model embedding, menghasilkan vektor—array angka yang merepresentasikan makna kueri daripada kata-kata persisnya.
2) Cari di database vektor
Vektor kueri dikirim ke database vektor, yang melakukan pencarian kesamaan untuk menemukan vektor “terdekat” di antara konten yang tersimpan.
Sebagian besar sistem mengembalikan top-K kecocokan: K chunk/dokumen paling mirip.
- Kenapa K bisa dikonfigurasi: K lebih kecil lebih cepat dan sering cukup (mis. K=5).
- K lebih besar meningkatkan recall (lebih kecil kemungkinan melewatkan jawaban yang benar), tetapi mungkin memasukkan lebih banyak hasil “nyaris relevan” (mis. K=50).
3) (Opsional) Rerank untuk presisi
Pencarian kesamaan dioptimalkan untuk kecepatan, jadi top-K awal bisa berisi near-miss. Reranker adalah model kedua yang melihat kueri dan setiap kandidat bersama-sama lalu menyusun ulang menurut relevansi.
Anggaplah: pencarian vektor memberi Anda daftar pendek kuat; reranking memilih urutan terbaik.
4) Kembalikan hasil (atau diteruskan ke downstream)
Akhirnya, Anda mengembalikan kecocokan terbaik ke pengguna (sebagai hasil pencarian), atau meneruskannya ke asisten AI (mis. sistem RAG) sebagai konteks pembumian.
Jika membangun alur ini ke dalam aplikasi, platform seperti Koder.ai dapat membantu Anda prototipe dengan cepat: Anda mendeskripsikan pengalaman pencarian semantik atau RAG dalam antarmuka chat, lalu mengiterasi front-end React dan back end Go/PostgreSQL sambil menjaga pipeline retrieval (embedding → vector search → optional rerank → answer) sebagai bagian inti produk.
Contoh cepat “kata kunci vs semantik”
Jika artikel pusat bantuan Anda mengatakan “terminate subscription” dan pengguna mencari “cancel my plan,” pencarian kata kunci mungkin melewatkannya karena “cancel” dan “terminate” tidak cocok.
Pencarian semantik akan biasanya mengambilnya karena embedding menangkap bahwa kedua frasa itu mengekspresikan niat yang sama. Tambahkan reranking, dan hasil teratas biasanya menjadi bukan hanya “serupa,” tetapi langsung bisa ditindaklanjuti untuk pertanyaan pengguna.
Deploy aplikasi AI Anda
Dari ide lokal ke aplikasi yang dihosting dan bisa Anda bagikan dengan tim.
Pencarian vektor murni hebat pada “makna,” tetapi pengguna tidak selalu mencari berdasarkan makna. Kadang mereka butuh kecocokan eksak: nama lengkap orang, SKU, ID faktur, atau kode error dari log. Pencarian hibrida menyelesaikan ini dengan menggabungkan sinyal semantik (vektor) dan leksikal (pencarian kata kunci tradisional seperti BM25).
Apa yang dilakukan “pencarian hibrida” sebenarnya
Kueri hibrida biasanya menjalankan dua jalur retrieval secara paralel:
- Pencarian vektor: menemukan konten yang secara konseptual mirip, meskipun pengucapan berbeda.
- Pencarian kata kunci/BM25: menemukan konten yang berbagi token yang sama, memberi bobot pada istilah eksak dan kata langka.
Sistem lalu menggabungkan kandidat tersebut menjadi satu daftar berperingkat.
Kapan hibrida jadi pilihan lebih baik
Pencarian hibrida menonjol ketika data Anda menyertakan string “harus cocok”:
- Nama produk dengan modifier spesifik (mis. “Pro Max”, “Gen 2”)
- ID (nomor order, ID tiket, nomor part)
- Kode error (“E0421”, “ORA-00933”) dan flag perintah
- Istilah domain langka di mana sinonim berisiko
Pencarian semantik saja mungkin mengembalikan halaman terkait luas; pencarian kata kunci sendiri mungkin melewatkan jawaban relevan yang diungkapkan berbeda. Hibrida menutup kedua mode kegagalan itu.
Filter metadata membatasi retrieval sebelum peringkat (atau bersamaan dengannya), meningkatkan relevansi dan kecepatan. Filter umum meliputi:
- Bahasa (kembalikan hanya dokumen berbahasa Inggris)
- Rentang tanggal (kebijakan terbaru, catatan rilis terbaru)
- Kategori atau sumber (docs vs tickets; “billing” vs “security”)
- Tag kontrol akses (hanya apa yang boleh dilihat pengguna ini)
Bagaimana pemeringkatan bekerja (tingkat tinggi)
Sebagian besar sistem memakai campuran praktis: jalankan kedua pencarian, normalisasi skor supaya dapat dibandingkan, lalu terapkan bobot (mis. “lebih condong ke kata kunci untuk ID”). Beberapa produk juga mererank daftar gabungan dengan model ringan atau aturan, sementara filter memastikan Anda memberi peringkat pada subset yang tepat sejak awal.
RAG: Menggunakan Database Vektor untuk Membumikan Respon LLM
Retrieval-Augmented Generation (RAG) adalah pola praktis untuk mendapatkan jawaban LLM yang lebih dapat dipercaya: ambil informasi relevan terlebih dulu, lalu hasilkan respons yang terkait dengan konteks yang diambil.
Ide RAG dalam satu kalimat
Alih-alih meminta model “mengingat” dokumen perusahaan Anda, Anda simpan dokumen itu (sebagai embedding) di database vektor, ambil potongan paling relevan saat pertanyaan datang, dan masukkan mereka ke LLM sebagai konteks pendukung.
Kenapa database vektor membantu mengurangi hallucination
LLM hebat menulis, tetapi akan percaya diri mengisi celah saat fakta yang diperlukan tidak ada. Database vektor memudahkan mengambil passage makna-terdekat dari basis pengetahuan Anda dan menyediakannya ke prompt.
Pembumian itu menggeser model dari “menciptakan jawaban” menjadi “meringkas dan menjelaskan sumber-sumber ini.” Ini juga membuat jawaban lebih mudah diaudit karena Anda dapat melacak chunk mana yang diambil dan menunjukkan sitasi jika perlu.
Dasar-dasar chunking (agar retrieval bekerja)
Kualitas RAG sering bergantung lebih pada chunking daripada pada model.
- Ukuran chunk: Tuju chunk yang memuat gagasan lengkap (sering bagian pendek). Terlalu kecil kehilangan makna; terlalu besar menarik noise.
- Overlap: Tambahkan overlap kecil agar detail penting di batas tidak terpisah dari konteks.
- Pertahankan konteks: Simpan judul, heading, dan identifier (nama dokumen, bagian, tanggal) sebagai metadata agar hasil mudah dipahami dan difilter.
Diagram pipeline RAG sederhana (deskripsi)
Bayangkan alur ini:
Pertanyaan pengguna → Embed pertanyaan → Vector DB ambil top-k chunk (+ filter metadata opsional) → Bangun prompt dengan chunk yang diambil → LLM menghasilkan jawaban → Kembalikan jawaban (dan sumber).
Database vektor berada di tengah sebagai “memori cepat” yang memberi bukti paling relevan untuk setiap permintaan.
Kasus Penggunaan AI Umum yang Didukung Database Vektor
Bangun pencarian semantik dengan cepat
Prototipe alur pencarian semantik di chat, lalu sempurnakan React UI dan backend Go.
Database vektor tidak hanya membuat pencarian “lebih pintar”—mereka memungkinkan pengalaman produk di mana pengguna bisa menjelaskan apa yang mereka inginkan dalam bahasa alami dan tetap mendapatkan hasil relevan. Berikut beberapa kasus praktis yang sering muncul.
Dukungan pelanggan: temukan jawaban melampaui kata kunci
Tim dukungan sering punya basis pengetahuan, tiket lama, transkrip chat, dan catatan rilis—tetapi pencarian kata kunci kesulitan dengan sinonim, parafrase, dan deskripsi masalah yang samar.
Dengan pencarian semantik, agen (atau chatbot) dapat mengambil tiket lama yang berarti sama meski pengucapannya berbeda. Itu mempercepat penyelesaian, mengurangi duplikasi kerja, dan membantu agen baru cepat paham. Memadukan pencarian vektor dengan filter metadata (garis produk, bahasa, tipe isu, rentang tanggal) menjaga hasil tetap fokus.
Penemuan produk: cari katalog sesuai cara orang bicara
Pembeli jarang tahu nama produk yang tepat. Mereka mencari niat seperti “ransel kecil yang muat laptop dan terlihat profesional.” Embedding menangkap preferensi—gaya, fungsi, batasan—sehingga hasil terasa lebih seperti asisten penjualan manusia.
Pendekatan ini cocok untuk katalog ritel, listing travel, properti, papan pekerjaan, dan marketplace. Anda juga bisa menggabungkan relevansi semantik dengan constraint terstruktur seperti harga, ukuran, ketersediaan, atau lokasi.
Rekomendasi: “item serupa” dan penemuan konten
Fitur klasik database vektor adalah “temukan item seperti ini.” Jika pengguna melihat item, membaca artikel, atau menonton video, Anda dapat mengambil konten lain dengan makna atau atribut serupa—bahkan saat kategori tidak cocok sempurna.
Ini berguna untuk:
- Modul “More like this”
- Artikel terkait dan saran basis pengetahuan
- Deteksi duplikat atau near-duplicate (untuk moderasi konten atau pembersihan)
Pencarian internal dengan izin: kebijakan, dokumen, catatan rapat
Di dalam perusahaan, informasi tersebar di dokumen, wiki, PDF, dan catatan rapat. Pencarian semantik membantu karyawan menanyakan dengan alami (“Apa kebijakan reimbursement kami untuk konferensi?”) dan menemukan sumber dokumen yang tepat.
Bagian yang tidak bisa ditawar adalah kontrol akses. Hasil harus menghormati izin—sering dengan memfilter berdasarkan tim, pemilik dokumen, tingkat kerahasiaan, atau daftar ACL—sehingga pengguna hanya mengambil apa yang mereka boleh lihat.
Jika ingin memperluas, lapisan retrieval yang sama ini juga yang mendorong sistem Q&A yang dibumikan (dibahas di bagian RAG).
Data Pipelines: Ingest, Chunking, dan Update
Sistem pencarian semantik hanya sebaik pipeline yang memasoknya. Jika dokumen masuk tidak konsisten, di-chunk buruk, atau tidak pernah di-reembed setelah diedit, hasil akan menyimpang dari yang diharapkan pengguna.
Alur ingest sederhana (yang bekerja)
Sebagian besar tim mengikuti urutan yang dapat diulang:
- Kumpulkan data (dokumen, PDF, tiket, log chat, halaman wiki, data produk).
- Bersihkan (hapus boilerplate, perbaiki encoding, normalisasi whitespace, ekstrak teks utama).
- Chunk (pecah ke potongan berukuran yang ingin diambil pengguna).
- Embed (hasilkan vektor dengan model embedding pilihan).
- Upsert (tulis vektor + metadata ke database vektor, mengganti bila perlu).
Langkah “chunk” adalah tempat banyak pipeline menang atau kalah. Chunk yang terlalu besar mengencerkan makna; terlalu kecil kehilangan konteks. Pendekatan praktis adalah chunk berdasarkan struktur alami (heading, paragraf, pasangan Q&A) dan menyimpan overlap kecil untuk kontinuitas.
Menjaga embedding tetap up-to-date
Konten berubah terus—kebijakan diperbarui, harga berubah, artikel ditulis ulang. Perlakukan embedding sebagai data turunan yang harus dihasilkan ulang.
Taktik umum:
- Simpan source document ID, chunk ID, dan content hash. Jika hash berubah, re-embed chunk itu.
- Gunakan soft deletes (tandai chunk lama tidak aktif) untuk menghindari hasil hantu.
- Rebuild selektif alih-alih re-embedding semuanya.
Batch vs streaming updates
- Batch cocok untuk backfill besar, sinkron malam hari, dan konten yang dapat diprediksi (dokumentasi, basis pengetahuan).
- Streaming cocok untuk sumber yang cepat berubah (tiket dukungan, konten buatan pengguna, inventaris). Ini mengurangi kedaluwarsa tapi membutuhkan pemantauan dan kontrol biaya yang lebih kuat.
Multi-bahasa dan multi-model
Jika Anda melayani banyak bahasa, Anda bisa menggunakan model embedding multibahasa (lebih sederhana) atau model per-bahasa (kadang kualitas lebih tinggi). Jika Anda bereksperimen dengan model, versikan embedding Anda (mis. embedding_model=v3) sehingga bisa menjalankan A/B test dan rollback tanpa merusak pencarian.
Pencarian semantik bisa terasa “bagus” di demo dan tetap gagal di produksi. Bedanya adalah pengukuran: Anda butuh metrik relevansi yang jelas dan target kecepatan, dievaluasi pada kueri yang mirip perilaku pengguna nyata.
Metrik relevansi yang mencerminkan kepuasan pengguna
Mulailah dengan seperangkat metrik kecil dan konsisten:
- Precision / Recall: Precision memberi tahu berapa banyak hasil yang dikembalikan benar-benar relevan; recall memberi tahu berapa banyak item relevan yang berhasil Anda ambil. Gunakan ini bila Anda punya definisi “relevan” yang jelas.
- MRR (Mean Reciprocal Rank): Bagus saat pengguna mengharapkan satu jawaban “terbaik”. MRR menghargai menempatkan dokumen yang tepat di dekat atas.
- nDCG: Berguna saat beberapa hasil bisa relevan pada tingkat berbeda (sangat relevan vs cukup relevan).
- Latency (p50/p95): Lacak rata-rata dan latensi ekor. p50 cepat tapi p95 lambat tetap terasa lambat bagi pengguna.
Bangun test set yang dapat dipercaya
Buat set evaluasi dari:
- Kueri nyata dari log pencarian atau tiket dukungan (anonymized).
- Dokumen yang diharapkan (label emas) yang disepakati oleh ahli domain.
- Kasus tepi: kueri pendek (“refund”), pertanyaan panjang, istilah ambigu, nama produk langka, dan kueri “no-result” di mana perilaku benar adalah mengatakan “tidak ditemukan”.
Versikan test set agar Anda bisa membandingkan hasil antar rilis.
A/B testing dan loop umpan balik
Metrik offline tidak menangkap semuanya. Jalankan A/B test dan kumpulkan sinyal ringan:
- Jempol naik/turun pada hasil
- Click-through dan dwell time
- Event “refine search”
Gunakan umpan balik ini untuk memperbarui penilaian relevansi dan menemukan pola kegagalan.
Memantau drift seiring waktu
Performa dapat berubah ketika:
- Anda mengganti model embedding atau mengubah cara chunking.
- Korpus Anda bergeser (produk baru, perubahan kebijakan, istilah musiman).
Jalankan kembali suite pengujian setelah perubahan apa pun, pantau tren metrik mingguan, dan atur alert untuk penurunan mendadak pada MRR/nDCG atau lonjakan p95 latency.
Keamanan, Privasi, dan Pertimbangan Kontrol Akses
Bagikan di domain Anda
Tempatkan pencarian semantik atau chatbot Anda di domain kustom agar pemangku kepentingan bisa mencobanya.
Pencarian vektor mengubah cara data diambil, tetapi tidak boleh mengubah siapa yang diizinkan melihatnya. Jika sistem semantik atau RAG Anda bisa “menemukan” chunk yang tepat, ia juga bisa tidak sengaja mengembalikan chunk yang pengguna tidak berwenang melihat—kecuali Anda merancang izin dan privasi ke dalam langkah retrieval.
Kontrol akses: terapkan saat retrieval
Aturan paling aman sederhana: seorang pengguna hanya boleh mengambil konten yang mereka diizinkan baca. Jangan bergantung pada aplikasi untuk “menyembunyikan” hasil setelah database vektor mengembalikannya—karena pada saat itu konten sudah keluar dari boundary penyimpanan Anda.
Pendekatan praktis meliputi:
- ACL per dokumen (atau per chunk): simpan field izin bersamaan dengan setiap vektor sehingga setiap kueri dapat menegakkannya.
- Isolasi tenant: untuk aplikasi multi-tenant, pisahkan data per tenant (partisi logis, namespace, atau indeks terpisah) untuk menghindari kebocoran antar-tenant.
Banyak database vektor mendukung filter berbasis metadata (mis. tenant_id, department, project_id, visibility) yang berjalan bersamaan dengan pencarian kesamaan. Digunakan dengan benar, ini adalah cara bersih untuk menerapkan izin saat retrieval.
Detail penting: pastikan filter wajib dan dijalankan di sisi server, bukan logika client opsional. Juga hati-hati dengan “role explosion” (terlalu banyak kombinasi). Jika model izin Anda kompleks, pertimbangkan precompute “effective access groups” atau gunakan layanan otorisasi terpisah untuk membuat token filter saat kueri.
PII dan data sensitif: putuskan apa yang tidak pernah di-embed
Embedding dapat mengkode makna dari teks asli. Itu tidak otomatis mengungkap PII mentah, tetapi masih meningkatkan risiko (mis. fakta sensitif jadi lebih mudah diambil).
Pedoman yang efektif:
- Hindari embedding field yang sangat sensitif (SSN, detail pembayaran, identifikasi medis) bila mungkin.
- Redaksi sebelum embedding jika teks harus bisa dicari (gantilah nilai tepat dengan placeholder).
- Simpan asli secara terpisah dan ambil hanya setelah pemeriksaan izin.
Kebutuhan operasional: backup, retensi, dan audit
Perlakukan indeks vektor Anda sebagai data produksi:
- Backup dan recovery: indeks bisa mahal untuk dibangun ulang; rencanakan snapshot atau jalur rebuild dari data sumber.
- Kebijakan retensi: hapus vektor saat dokumen sumber kedaluwarsa atau permintaan pengguna untuk penghapusan.
- Auditabilitas: log siapa yang mencari apa (setidaknya konteks kueri dan ID dokumen yang dikembalikan) untuk mendukung investigasi dan kepatuhan.
Jika diterapkan dengan baik, praktik-praktik ini membuat pencarian semantik terasa ajaib bagi pengguna—tanpa menjadi kejutan keamanan nanti.
Perangkap, Biaya, dan Daftar Periksa Pemilihan Praktis
Database vektor bisa terasa “plug-and-play,” tetapi kebanyakan kekecewaan muncul dari pilihan di sekitarnya: bagaimana Anda chunk data, model embedding mana yang Anda pilih, dan seberapa andal Anda menjaga semuanya tetap up-to-date.
Mode kegagalan umum (dan cara mendeteksinya)
Chunking yang buruk adalah penyebab nomor 1 hasil tidak relevan. Chunk yang terlalu besar mengencerkan makna; terlalu kecil kehilangan konteks. Jika pengguna sering berkata “ditemukan dokumen yang benar tapi bagian yang salah,” strategi chunking Anda kemungkinan perlu diperbaiki.
Model embedding yang salah muncul sebagai ketidakcocokan semantik konsisten—hasilnya fasih tapi meleset dari topik. Ini terjadi saat model tidak cocok dengan domain Anda (legal, medis, tiket dukungan) atau tipe konten Anda (tabel, kode, teks multi-bahasa).
Data usang menciptakan masalah kepercayaan dengan cepat: pengguna mencari kebijakan terbaru tetapi mendapat versi kuartal lalu. Jika data sumber berubah, embedding dan metadata Anda juga harus diupdate (dan penghapusan harus benar-benar menghapus).
Penanganan cold-start dan hasil kosong
Di awal, Anda mungkin punya konten terlalu sedikit, terlalu sedikit kueri, atau tidak cukup umpan balik untuk menyetel retrieval. Rencanakan untuk:
- Fallback: pencarian kata kunci atau jawaban kurasi saat hasil semantik lemah.
- UX hasil kosong: tampilkan kategori terkait, tanyakan pertanyaan klarifikasi, atau perlebar filter.
- Kueri pemanasan: uji dengan seperangkat pertanyaan representatif sebelum peluncuran.
Penggerak biaya untuk dianggarkan
Biaya biasanya datang dari empat sumber:
- Compute embedding (backfill satu kali + update berkelanjutan)
- Penyimpanan (vektor, metadata, dan indeks)
- Volume kueri (reads, egress jaringan, dan concurrency)
- Reranking (opsional tapi kuat; dapat menambah biaya model per-kueri)
Jika membandingkan vendor, minta estimasi bulanan sederhana menggunakan jumlah dokumen yang Anda perkirakan, ukuran chunk rata-rata, dan QPS puncak. Banyak kejutan muncul setelah indexing dan selama lonjakan trafik.
Daftar periksa praktis untuk memilih database vektor
Gunakan daftar singkat ini untuk memilih database vektor yang sesuai kebutuhan:
- Kualitas pencarian: Apakah mendukung pencarian hibrida (kata kunci + vektor) dan filter metadata? Dapatkah Anda menambahkan reranking?
- Performa: Opsi pengindeksan ANN, latensi yang dapat diprediksi pada trafik puncak Anda, dan skala yang mudah.
- Operasi data: Upserts, deletes, re-indexing, versioning, dan backfills tanpa downtime.
- Observability: Log kueri, metrik recall/latensi, dan alat untuk debug “kenapa hasil ini.”
- Keamanan: Enkripsi, isolasi tenant, kontrol peran, dan pola filter-berdasarkan-izin.
- Integrasi: SDK, bahasa yang didukung, dan konektor untuk penyimpanan Anda (S3, database, dokumen).
- Total cost: Harga transparan untuk penyimpanan, penulisan, pembacaan, dan compute terkelola.
Memilih dengan baik lebih soal keandalan: bisakah Anda menjaga data tetap segar, mengontrol akses, dan mempertahankan kualitas saat konten dan trafik berkembang?