05 Mei 2025·8 menit
Datadog dan Pergeseran ke Platform: Telemetri, Integrasi, Alur Kerja
Lihat bagaimana Datadog menjadi platform ketika telemetri, integrasi, dan alur kerja jadi produk—serta ide praktis yang bisa Anda terapkan pada stack Anda.
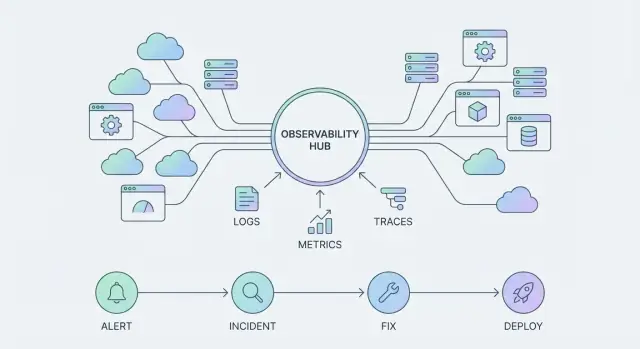
Mengapa Observabilitas Berubah Menjadi Platform
Sebuah alat observabilitas membantu Anda menjawab pertanyaan spesifik tentang sistem—biasanya dengan menampilkan grafik, log, atau hasil query. Itu sesuatu yang Anda “gunakan” saat ada masalah.
Sebuah platform observabilitas lebih luas: menstandarkan bagaimana telemetri dikumpulkan, bagaimana tim mengeksplorasinya, dan bagaimana insiden ditangani secara end-to-end. Ia menjadi sesuatu yang organisasi Anda “jalankan” setiap hari, di banyak layanan dan tim.
Dari grafik ke hasil
Kebanyakan tim mulai dengan dashboard: grafik CPU, grafik error-rate, mungkin beberapa pencarian log. Itu berguna, tapi tujuan sebenarnya bukan membuat grafik lebih indah—melainkan deteksi lebih cepat dan resolusi lebih cepat.
Pergeseran ke platform terjadi ketika Anda berhenti bertanya, “Bisakah kita mem-graph ini?” dan mulai bertanya:
- Bisakah on-call engineer menemukan akar masalah dalam hitungan menit, bukan jam?
- Bisakah kita mengarahkan alert yang tepat ke tim yang tepat secara otomatis?
- Bisakah kita mengubah pola insiden berulang menjadi playbook yang dapat diulang?
Itu adalah pertanyaan berfokus hasil, dan mereka membutuhkan lebih dari visualisasi. Mereka butuh standar data bersama, integrasi konsisten, dan alur kerja yang menghubungkan telemetri ke aksi.
Tiga pilar yang sebenarnya Anda beli
Seiring platform seperti Datadog berkembang, “permukaan produk” bukan hanya dashboard. Ada tiga pilar yang saling terkait:
- Telemetri: logs, metrics, dan traces yang dikumpulkan secara konsisten dan diberi label dengan cukup baik untuk dipercaya.
- Integrasi: koneksi pra-bangun yang memudahkan adopsi dan memperluas cakupan tanpa lem custom.
- Alur kerja: respons insiden, routing alert, kepemilikan, dan tindak lanjut—sehingga pembelajaran bersifat kumulatif.
Nilai platform semakin bertambah
Sebuah dashboard tunggal bisa membantu satu tim. Sebuah platform menjadi lebih kuat setiap layanan yang onboarded, setiap integrasi yang ditambahkan, dan setiap alur kerja yang distandarkan. Seiring waktu, ini berkomponensasi menjadi lebih sedikit blind spot, lebih sedikit duplikasi tooling, dan insiden yang lebih pendek—karena setiap perbaikan menjadi dapat digunakan ulang, bukan sekadar kasus satu kali.
Telemetri Menjadi Permukaan Produk
Ketika observabilitas berubah dari “alat yang kita query” menjadi “platform yang kita bangun di atasnya,” telemetri berhenti menjadi limbah mentah dan mulai berperan sebagai permukaan produk. Apa yang Anda pilih untuk diterbitkan—dan seberapa konsisten Anda menerbitkannya—menentukan apa yang tim Anda bisa lihat, otomatisasi, dan percayai.
Jenis telemetri inti (dan untuk apa mereka)
Kebanyakan tim menstandarkan sekelompok sinyal kecil:
- Metrics: tren numerik dari waktu ke waktu (latency, error rate, saturation).
- Logs: catatan rinci yang bisa dibaca manusia untuk investigasi dan audit.
- Traces: jalur permintaan lintas layanan untuk menemukan di mana waktu dan kegagalan terjadi.
- Events: catatan diskrit “sesuatu berubah” (deploy, feature flag, insiden).
- Profiles: perilaku CPU/memori untuk menempatkan jalur kode yang mahal.
Secara terpisah, setiap sinyal berguna. Bersama-sama, mereka menjadi antarmuka tunggal ke sistem Anda—apa yang Anda lihat di dashboard, alert, timeline insiden, dan postmortem.
Konsistensi mengalahkan volume
Mode kegagalan umum adalah mengumpulkan “segala sesuatu” tapi menamainya tidak konsisten. Jika satu layanan menggunakan userId, layanan lain menggunakan uid, dan yang ketiga tidak mencatat apapun, Anda tidak bisa dengan andal menyaring data, menggabungkan sinyal, atau membangun monitor yang dapat digunakan ulang.
Tim mendapatkan lebih banyak nilai dengan menyepakati beberapa konvensi—nama service, tag environment, request ID, dan set atribut standar—daripada menggandakan volume ingestion.
Apa arti high-cardinality sebenarnya (dan mengapa penting)
Field high-cardinality adalah atribut dengan banyak kemungkinan nilai (seperti user_id, order_id, atau session_id). Mereka kuat untuk debugging isu “hanya terjadi pada satu pelanggan”, tapi bisa juga menaikkan biaya dan memperlambat query jika dipakai di mana-mana.
Pendekatan platform itu disengaja: simpan high-cardinality di tempat yang memberikan nilai investigasi jelas, dan hindari di tempat yang dimaksudkan untuk agregat global.
Konteks terpadu mengurangi pekerjaan korelasi
Imbalannya adalah kecepatan. Ketika metrics, logs, traces, events, dan profiles berbagi konteks yang sama (service, version, region, request ID), insinyur menghabiskan lebih sedikit waktu merajut bukti dan lebih banyak waktu memperbaiki masalah sebenarnya. Alih-alih lompat antar alat dan menebak, Anda mengikuti satu benang dari gejala ke akar penyebab.
Dari Pengumpulan Data ke Strategi Telemetri
Kebanyakan tim memulai observabilitas dengan “memasukkan data.” Itu perlu, tapi bukan strategi. Strategi telemetri yang baik menjaga onboarding cepat dan membuat data Anda cukup konsisten untuk memasok dashboard bersama, alert yang dapat dipercaya, dan SLO yang bermakna.
Jalur-ingest umum (dan kelebihan masing-masing)
Datadog biasanya mendapatkan telemetri melalui beberapa jalur praktis:
- Agent pada host/VM: cara tercepat untuk mengumpulkan metrics infrastruktur, logs, dan APM dengan perubahan kode minimal.
- Collector dan gateway (mis. OpenTelemetry Collector): berguna saat Anda ingin kontrol sentral, routing multi-destinasi, redaksi, atau pemrosesan standar.
- API dan SDK langsung: membantu untuk event kustom, metrics bisnis, atau saat agent tidak memungkinkan.
- Integrasi serverless: nyaman untuk runtime terkelola di mana Anda tidak mengontrol host, tapi Anda perlu sengaja memilih apa yang diterbitkan.
Kecepatan vs standardisasi: tentukan apa yang Anda optimalkan
Di awal, kecepatan menang: tim memasang agent, mengaktifkan beberapa integrasi, dan langsung melihat manfaat. Risikonya setiap tim menemukan tag, nama service, dan format log sendiri—membuat tampilan lintas-service berantakan dan alert sulit dipercaya.
Aturan sederhana: izinkan onboarding “quick start”, tapi wajibkan “standardize dalam 30 hari.” Itu memberi momentum tanpa mengunci kekacauan.
Konvensi penamaan dan tagging ringan
Anda tidak perlu taksonomi besar. Mulailah dengan set kecil yang harus dibawa setiap sinyal (logs, metrics, traces):
service: singkat, stabil, huruf kecil (mis.checkout-api)env:prod,staging,devteam: identifier tim pemilik (mis.payments)version: versi deploy atau git SHA
Jika mau satu lagi yang cepat memberi manfaat, tambahkan tier (frontend, backend, data) untuk menyederhanakan penyaringan.
Sampling, retensi, dan default yang sadar biaya
Masalah biaya biasanya muncul dari default yang terlalu murah hati:
- Traces: mulai dengan head-based sampling untuk endpoint volume tinggi; simpan 100% untuk alur kritis.
- Logs: default ke “error + event bisnis penting”, lalu tambahkan info/debug secara selektif dengan retensi terbatasi waktu.
- Retensi: simpan data resolusi tinggi lebih singkat (hari), roll-up atau simpan agregat kunci lebih lama (minggu/bulan).
Tujuannya bukan mengumpulkan lebih sedikit—melainkan mengumpulkan data yang tepat secara konsisten, sehingga Anda dapat men-scale penggunaan tanpa kejutan.
Integrasi sebagai Kanal Distribusi Sebenarnya
Kebanyakan orang menganggap alat observabilitas sebagai “sesuatu yang Anda pasang.” Dalam praktik, mereka menyebar melalui organisasi sebagaimana konektor bagus menyebar: satu integrasi pada satu waktu.
Apa arti “integrasi” sebenarnya
Integrasi bukan hanya pipa data. Biasanya punya tiga bagian:
- Sumber data: menarik metrics, logs, traces, events, dan topologi dari sistem yang sudah Anda jalankan (layanan cloud, Kubernetes, database, CI/CD, SaaS).
- Enrichment: menambahkan konteks agar telemetri langsung dapat digunakan—nama service, environment, tag kepemilikan, versi deploy, dan metadata cloud.
- Aksi: melakukan sesuatu dengan apa yang Anda pelajari—membuat ticket, mem-paging on-call, memberi anotasi pada deploy, menskalakan resource, atau memicu runbook.
Bagian terakhir inilah yang membuat integrasi menjadi distribusi. Jika alat hanya membaca, itu destinasi dashboard. Jika juga menulis, itu menjadi bagian dari kerja harian.
Mengapa integrasi mempercepat adopsi
Integrasi bagus mengurangi waktu setup karena mereka dikirim dengan default yang masuk akal: dashboard pra-bangun, monitor rekomendasi, aturan parsing, dan tag umum. Alih-alih setiap tim menciptakan “dashboard CPU” atau “alert Postgres” sendiri, Anda mendapat titik awal standar yang mengikuti praktik terbaik.
Tim masih menyesuaikan—tetapi mereka menyesuaikan dari baseline bersama. Standardisasi ini penting saat Anda mengkonsolidasikan tools: integrasi menciptakan pola berulang yang bisa dicopy oleh layanan baru, menjaga pertumbuhan tetap terkelola.
Prioritaskan integrasi dua-arah
Saat menilai opsi, tanyakan: bisakah ia mengambil sinyal dan melakukan aksi? Contoh termasuk membuka insiden di sistem tiket Anda, memperbarui channel insiden, atau melampirkan link trace kembali ke PR atau tampilan deploy. Setup bidirectional inilah tempat alur kerja mulai terasa “native.”
Metode shortlist sederhana
Mulailah kecil dan dapat diprediksi:
- Infrastruktur kritis dulu (cloud provider, Kubernetes, load balancer, database inti).
- Lalu pipeline deploy (CI/CD, feature flags, tracking rilis) agar telemetri sejajar dengan perubahan.
- Tambahkan SaaS per-tim (queue, cache, auth, payments) setelah tagging dan konvensi kepemilikan stabil.
Aturan praktis: prioritaskan integrasi yang langsung meningkatkan respons insiden, bukan yang hanya menambah lebih banyak grafik.
Tampilan Standar: Service, Dashboard, dan Monitor
Tampilan standar adalah tempat sebuah platform observabilitas menjadi dapat dipakai sehari-hari. Ketika tim berbagi model mental yang sama—apa itu “service”, apa itu “sehat”, dan kemana harus klik pertama—debugging menjadi lebih cepat dan serah terima lebih rapi.
Mulai dengan golden signals (dan buat terlihat)
Pilih beberapa “golden signals” dan peta tiap satu ke dashboard reuseable yang konkret. Untuk kebanyakan service, itu adalah:
- Latency (p95/p99 untuk endpoint kunci)
- Traffic (request per detik, job yang diproses)
- Errors (rate dan tipe error teratas)
- Saturation (CPU, memory, kedalaman antrean, koneksi DB)
Kuncinya konsistensi: satu layout dashboard yang bekerja antar service mengalahkan sepuluh dashboard bespoke yang cerdas.
Katalog service menciptakan kepemilikan bersama
Katalog service (meskipun ringan) mengubah “seseorang harus melihat ini” menjadi “tim ini yang memilikinya.” Ketika service ditag dengan owner, environment, dan dependensi, platform bisa menjawab pertanyaan dasar dengan cepat: Monitor mana yang berlaku untuk service ini? Dashboard mana yang harus saya buka? Siapa yang dipaging?
Kejelasan itu mengurangi ping-pong Slack saat insiden dan membantu insinyur baru mandiri.
Blok bangunan yang bisa diskalakan
Perlakukan ini sebagai artefak standar, bukan tambahan opsional:
- Dashboard untuk golden signals dan dependensi kunci
- Monitor yang terkait SLO atau gejala berdampak pengguna
- Notebook untuk investigasi dan timeline post-insiden
- Runbook (ditautkan dari monitor) untuk 5–10 menit pertama respons
Anti-pola yang harus dihindari
Vanity dashboard (grafik cantik tanpa keputusan di baliknya), alert one-off (dibuat buru-buru, tak pernah dituning), dan query yang tidak terdokumentasi (hanya satu orang yang paham filter ajaib) semua menciptakan noise platform. Jika sebuah query penting, simpan, beri nama, dan lampirkan ke tampilan service yang bisa ditemukan orang lain.
Alur Kerja: Di Mana Observabilitas Memberi Nilai Bisnis
Miliki Kode Sumber
Hasilkan alat internal dengan cepat, lalu ekspor kode sumber untuk repo Anda dan tinjau.
Observabilitas hanya menjadi “nyata” bagi bisnis ketika memperpendek jarak antara masalah dan perbaikan percaya diri. Itu terjadi lewat alur kerja—jalur berulang yang membawa Anda dari sinyal ke aksi, dan dari aksi ke pembelajaran.
Perjalanan insiden: alert → triage → komunikasi → mitigasi → belajar
Alur kerja yang skalabel lebih dari sekadar mem-paging seseorang.
Sebuah alert seharusnya membuka loop triage terfokus: konfirmasi dampak, identifikasi service terdampak, dan tarik konteks paling relevan (deploy terbaru, kesehatan dependensi, lonjakan error, sinyal saturasi). Dari situ, komunikasi mengubah kejadian teknis menjadi respons terkoordinasi—siapa yang memegang insiden, apa yang dilihat pengguna, dan kapan pembaruan berikutnya.
Mitigasi adalah tempat Anda ingin memiliki “aksi aman” di ujung jari: feature flags, pengalihan trafik, rollback, rate limits, atau workaround yang diketahui. Akhirnya, pembelajaran menutup loop dengan review ringan yang menangkap apa yang berubah, apa yang bekerja, dan apa yang harus diotomatisasi berikutnya.
Tooling insiden + ChatOps = kolaborasi, bukan pahlawan tunggal
Platform seperti Datadog menambah nilai ketika mereka mendukung kerja bersama: channel insiden, pembaruan status, handoff, dan timeline konsisten. Integrasi ChatOps bisa mengubah alert menjadi percakapan terstruktur—membuat insiden, menetapkan peran, dan memposting grafik serta query kunci langsung di thread sehingga semua melihat bukti yang sama.
Isi runbook yang baik
Runbook yang berguna singkat, tegas, dan aman. Harus memuat: tujuan (pulihkan layanan), owner/rotasi on-call, pemeriksaan langkah demi langkah, link ke dashboard/monitor yang tepat, dan “aksi aman” yang mengurangi risiko (dengan langkah rollback). Jika tidak aman dijalankan jam 3 pagi, itu belum selesai.
Tautkan insiden ke deploy dan perubahan
Akar masalah lebih cepat ditemukan ketika insiden dikorelasikan otomatis dengan deploy, perubahan konfigurasi, dan flip feature flag. Jadikan “apa yang berubah?” sebagai tampilan kelas satu sehingga triage dimulai dengan bukti, bukan dugaan.
SLO dan Error Budget sebagai Sistem Operasi Tim
Apa itu SLO (dan mengapa mengalahkan “dashboard hijau”)
Sebuah SLO (Service Level Objective) adalah janji sederhana tentang pengalaman pengguna dalam jendela waktu—mis. “99.9% request berhasil selama 30 hari” atau “p95 page load di bawah 2 detik.”
Itu mengalahkan “dashboard hijau” karena dashboard sering menampilkan kesehatan sistem (CPU, memory, antrean) alih-alih dampak ke pelanggan. Sebuah layanan bisa terlihat hijau tapi masih mengecewakan pengguna (mis. dependency timeout, atau error terkonsentrasi di satu region). SLO memaksa tim mengukur apa yang benar-benar dirasakan pengguna.
Error budget: cara bersama berbicara soal risiko
Error budget adalah jumlah ketidakandalan yang diizinkan oleh SLO Anda. Jika Anda menjanjikan 99.9% sukses selama 30 hari, Anda “diizinkan” sekitar 43 menit error dalam jendela itu.
Ini menciptakan sistem operasi praktis untuk keputusan:
- Budget sehat: kirim fitur, jalankan eksperimen, ambil risiko wajar.
- Budget terbakar: perlambat rilis, fokus perbaikan reliabilitas, kurangi perubahan.
- Budget habis: hentikan deploy berisiko dan atasi sumber kegagalan teratas.
Alih-alih berdebat di rapat rilis, Anda memperdebatkan angka yang bisa dilihat semua orang.
Alert pada burn rate, bukan setiap spike
Alert SLO bekerja terbaik saat Anda alert pada burn rate (seberapa cepat Anda mengonsumsi error budget), bukan pada hitungan error mentah. Itu mengurangi noise:
- Lonjakan singkat yang pulih sendiri mungkin tidak mem-paging siapapun.
- Isu berkelanjutan yang akan menghabiskan budget segera memicu alert yang jelas dan dapat ditindaklanjuti.
Banyak tim memakai dua jendela: fast burn (paging cepat) dan slow burn (ticket/notifikasi).
Set starter SLO ringan untuk service web biasa
Mulailah kecil—dua sampai empat SLO yang akan benar-benar Anda gunakan:
- Availability: % request sukses (mis. HTTP 2xx/3xx) selama 30 hari.
- Latency: p95 request di bawah threshold (pisah read vs write jika perlu).
- Checkout / endpoint kritis: success rate untuk jalur bisnis yang paling penting.
- Freshness (jika relevan): job background selesai dalam X menit.
Setelah ini stabil, Anda bisa memperluas—jika tidak, Anda hanya membangun tembok dashboard tambahan. Untuk lebih lanjut, lihat /blog/slo-monitoring-basics.
Alerting yang Skalabel Tanpa Membakar Orang
Luncurkan Observability Hub
Bangun observability hub ringan yang menghubungkan layanan dengan pemilik, dasbor, dan runbook.
Alerting sering membuat program observabilitas tersendat: data ada, dashboard bagus, tapi pengalaman on-call menjadi berisik dan tidak dipercaya. Jika orang belajar mengabaikan alert, platform kehilangan kemampuan melindungi bisnis.
Mengapa alert fatigue terjadi (dan mengapa sinyal terduplikasi)
Penyebab paling umum konsisten:
- Terlalu banyak alert “FYI” yang tidak perlu tindakan.
- Ambang yang disalin antar service tanpa konteks (aturan CPU yang sama untuk beban berbeda).
- Banyak tools atau tim memberi alert pada gejala yang sama—mis. monitor error-rate APM dan monitor berbasis log keduanya paging untuk insiden yang sama.
- Metrics berisik (percentile latency yang spike, efek autoscaling) yang memicu fluktuasi bukan masalah nyata.
Dalam istilah Datadog, duplikasi sinyal sering muncul ketika monitor dibuat dari “permukaan” berbeda (metrics, logs, traces) tanpa memutuskan mana yang jadi halaman kanonis.
Routing: kepemilikan, severity, dan jam tenang
Skala alerting dimulai dengan aturan routing yang masuk akal:
- Kepemilikan: setiap monitor harus punya owner (service/tim) dan jalur eskalasi.
- Severity: gunakan paging untuk isu mendesak-dampak pengguna; gunakan ticket/chat untuk yang lebih rendah.
- Maintenance windows: deploy terencana, migrasi, dan load test tidak menghasilkan page.
Aturan sederhana yang menjaga alert tetap dapat ditindaklanjuti
Default berguna: alert pada gejala yang dirasakan pengguna, bukan setiap perubahan metric. Page pada hal yang dirasakan pengguna (error rate, checkout gagal, latency berkepanjangan, SLO burn), bukan pada “input” (CPU, jumlah pod) kecuali mereka dapat memprediksi dampak secara andal.
Ritme review yang benar-benar bekerja
Jadikan hygiene alert bagian operasi: pruning dan tuning monitor bulanan. Hapus monitor yang tak pernah menyala, sesuaikan ambang yang terlalu sering menyala, dan gabungkan duplikat sehingga setiap insiden punya satu halaman utama plus konteks pendukung.
Jika dikelola dengan baik, alerting menjadi alur kerja yang dipercaya orang—bukan generator kebisingan latar belakang.
Governance: Bagaimana Platform Tetap Dapat Digunakan Saat Tumbuh
Menyebut observabilitas sebagai “platform” bukan hanya soal mengumpulkan logs, metrics, traces, dan banyak integrasi di satu tempat. Itu juga mengimplikasikan governance: konsistensi dan guardrail yang menjaga sistem tetap dapat dipakai ketika jumlah tim, service, dashboard, dan alert meningkat.
Tanpa governance, Datadog (atau platform apa pun) bisa terdorong menjadi scrapbook berisik—ratusan dashboard sedikit berbeda, tag tidak konsisten, kepemilikan tidak jelas, dan alert yang tidak dipercaya.
Governance adalah masalah orang-dan-proses
Governance yang baik memperjelas siapa yang memutuskan apa, dan siapa yang bertanggung jawab saat platform jadi berantakan:
- Tim platform: mendefinisikan standar (tagging, naming, pola dashboard), menyediakan komponen bersama, dan memelihara integrasi.
- Pemilik service: memiliki kualitas telemetri untuk service mereka dan menjaga monitor tetap bermakna.
- Keamanan & kepatuhan: menetapkan aturan penanganan data (PII, retensi, batas akses) dan meninjau integrasi berisiko tinggi.
- Leadership: menyelaraskan governance dengan prioritas bisnis (target reliabilitas, ekspektasi respons insiden) dan mendanai pekerjaan.
Kontrol praktis yang mencegah ‘sprawl’ observabilitas
Beberapa kontrol ringan lebih efektif daripada dokumen kebijakan panjang:
- Template by default: dashboard starter dan paket monitor per tipe service (API, worker queue, database) agar tim memulai secara konsisten.
- Kebijakan tagging: set kecil wajib (mis.
service,env,team,tier) plus aturan jelas untuk tag opsional. Terapkan di CI bila mungkin. - Akses dan kepemilikan: gunakan RBAC untuk data sensitif dan wajibkan owner untuk dashboard/monitor.
- Alur persetujuan untuk perubahan berdampak tinggi: monitor yang mem-paging orang, pipeline log yang memengaruhi biaya, dan integrasi yang menarik data sensitif harus melalui review.
Reuse mengalahkan penemuan ulang
Cara tercepat meningkatkan kualitas adalah berbagi apa yang bekerja:
- Library bersama: paket internal atau snippet yang menstandarkan field logging, atribut trace, dan metric umum.
- Dashboard & monitor yang dapat digunakan ulang: katalog pusat “golden” yang bisa di-clone dan disesuaikan tim.
- Standar versioned: perlakukan aset kunci seperti kode—dokumentasikan perubahan, deprecate pola lama, dan umumkan pembaruan di satu tempat.
Jika ingin ini bertahan, buat jalur yang di-govern menjadi jalur yang mudah—lebih sedikit klik, setup lebih cepat, dan kepemilikan lebih jelas.
Biaya, Nilai, dan Flywheel Platform
Begitu observabilitas berperilaku seperti platform, ia mulai mengikuti ekonomi platform: semakin banyak tim yang mengadopsi, semakin banyak telemetri yang dihasilkan, dan semakin berguna platform itu.
Itu menciptakan flywheel:
- Lebih banyak layanan onboarded → visibilitas lintas-layanan dan korelasi lebih baik
- Visibilitas lebih baik → diagnosis lebih cepat, lebih sedikit insiden berulang, lebih banyak kepercayaan pada tool
- Kepercayaan lebih banyak → lebih banyak tim menginstrumentasi dan berintegrasi → lebih banyak data lagi
Tantangannya adalah loop yang sama juga menaikkan biaya. Lebih banyak host, container, logs, traces, synthetics, dan custom metrics bisa tumbuh lebih cepat daripada anggaran Anda jika tidak dikelola dengan sengaja.
Tuas biaya praktis (tanpa membunuh sinyal)
Anda tidak perlu “mematikan semuanya.” Mulailah dengan membentuk data:
- Sampling: simpan traces fidelity tinggi untuk endpoint kritis, sampling lebih agresif di tempat lain.
- Tier retensi: retensi singkat untuk raw logs volume tinggi; retensi lebih lama untuk stream audit/keamanan yang dikurasi.
- Filtering & parsing logs: buang noise jelas sejak awal (health checks, permintaan asset statis) dan standarkan parsing sehingga bisa diroute berdasar atribut.
- Agregasi metric: pilih percentiles, rates, dan rollup daripada cardinality tak terbatas (mis. per-user IDs).
KPI yang menghubungkan biaya ke hasil
Pantau sekumpulan kecil metrik yang menunjukkan apakah platform memberikan imbal balik:
- MTTD (mean time to detect)
- MTTR (mean time to resolve)
- Jumlah insiden dan insiden berulang (akar penyebab sama)
- Frekuensi deploy (dan change failure rate jika Anda melacaknya)
Menjalankan review “nilai vs biaya” kuartalan (tanpa menyalahkan)
Buat itu review produk, bukan audit. Ajak platform owners, beberapa tim layanan, dan finance. Tinjau:
- Penggerak biaya teratas menurut tipe data (logs/metrics/traces) dan per tim
- Keberhasilan terbesar: insiden yang dipersingkat, outage dihindari, toil berkurang
- 2–3 aksi yang disepakati (mis. sesuaikan aturan sampling, tambah tier retensi, perbaiki integrasi berisik)
Tujuannya kepemilikan bersama: biaya menjadi input untuk keputusan instrumentasi yang lebih baik, bukan alasan menghentikan observasi.
Apa Artinya untuk Stack Alat Observabilitas Anda
Utamakan SLO
Prototipe dashboard SLO yang menyoroti burn rate dan menjaga peringatan tetap terkait dampak pengguna.
Jika observabilitas berubah menjadi platform, “tool stack” Anda berhenti menjadi koleksi solusi titik dan mulai bertindak seperti infrastruktur bersama. Pergeseran itu membuat sprawl alat lebih dari sekadar gangguan: ia menciptakan duplikasi instrumentasi, definisi yang tidak konsisten (apa yang dihitung sebagai error?), dan beban on-call lebih tinggi karena sinyal tidak selaras di logs, metrics, traces, dan insiden.
Konsolidasi tidak berarti “satu vendor untuk semuanya” secara default. Itu berarti lebih sedikit sistem pencatat untuk telemetri dan respons, kepemilikan lebih jelas, dan jumlah tempat yang harus dilihat orang saat outage lebih kecil.
Apa yang bisa diselesaikan konsolidasi
Sprawl alat biasanya menyembunyikan biaya di tiga tempat: waktu untuk berpindah UI, integrasi rapuh yang harus Anda pelihara, dan governance terfragmentasi (penamaan, tag, retensi, akses).
Pendekatan platform yang lebih terpadu bisa mengurangi switching context, menstandarkan tampilan service, dan membuat alur kerja insiden dapat diulang.
Checklist keputusan (cepat tapi praktis)
Saat menilai stack Anda (termasuk Datadog atau alternatif), uji dengan pertanyaan:
- Integrasi wajib: cloud provider, Kubernetes, CI/CD, manajemen insiden, paging, dan datastore kunci—plus sistem bisnis yang “tidak bisa kita kirim tanpa itu.”
- Alur kerja: dapatkah Anda bergerak dari alert → owner → runbook → timeline → postmortem tanpa copy/paste manual?
- Governance: standar tagging, kontrol akses, retensi, dan guardrail untuk sprawl dashboard/monitor?
- Model harga: apa yang menggerakkan biaya (host, container, logs ingested, traces terindeks)? Bisakah Anda memproyeksikan pertumbuhan tanpa kejutan?
Jalankan pilot dengan metrik sukses jelas
Pilih satu atau dua service dengan traffic nyata. Definisikan metrik sukses tunggal seperti “waktu mengidentifikasi akar penyebab turun dari 30 menit ke 10” atau “kurangi alert berisik sebanyak 40%.” Instrument hanya yang diperlukan, dan tinjau hasil setelah dua minggu.
Simpan dokumentasi internal terpusat sehingga pembelajaran bersifat kumulatif—tautkan runbook pilot, aturan tagging, dan dashboard dari satu tempat (mis. /blog/observability-basics sebagai titik awal internal).
Rencana Adopsi Praktis yang Bisa Anda Salin
Anda tidak “meng-roll out Datadog” sekali. Anda mulai kecil, menetapkan standar dini, lalu skala apa yang berhasil.
Rollout 30/60/90 hari
Hari 0–30: Onboard (buktikan nilai cepat)
Pilih 1–2 layanan kritis dan satu perjalanan pelanggan. Instrument logs, metrics, dan traces secara konsisten, dan hubungkan integrasi yang sudah Anda andalkan (cloud, Kubernetes, CI/CD, on-call).
Hari 31–60: Standarkan (buat dapat diulang)
Ubah pembelajaran menjadi default: penamaan service, tagging, template dashboard, penamaan monitor, dan kepemilikan. Buat tampilan “golden signals” (latency, traffic, errors, saturation) dan set SLO minimal untuk endpoint terpenting.
Hari 61–90: Skala (perluas tanpa kekacauan)
Onboard tim tambahan menggunakan template yang sama. Perkenalkan governance (aturan tag, metadata wajib, proses review untuk monitor baru) dan mulai lacak biaya vs penggunaan agar platform tetap sehat.
Di mana Koder.ai cocok (praktis)
Setelah Anda memperlakukan observabilitas sebagai platform, biasanya akan muncul kebutuhan untuk aplikasi “lem” kecil di sekitarnya: UI katalog service, hub runbook, halaman timeline insiden, atau portal internal yang menghubungkan owner → dashboard → SLO → playbook.
Itu jenis tooling internal ringan yang bisa Anda bangun cepat di Koder.ai—platform vibe-coding yang memungkinkan Anda menghasilkan web app via chat (umumnya React frontend, Go + PostgreSQL backend), dengan ekspor kode sumber dan dukungan deploy/hosting. Dalam praktik, tim menggunakannya untuk mem-prototype dan mengirim permukaan operasional yang mempermudah governance dan alur kerja tanpa mengalihkan tim produk utama dari roadmap.
Kemenangan cepat yang dikirim minggu pertama
- Top 10 monitor untuk availability, error rate, latency, saturation, dan dependency kunci
- Marker deploy (dari CI/CD) di dashboard dan traces untuk korelasi perubahan instan
- Template insiden: apa yang terjadi, dampak, timeline, owner, link ke dashboard/query, langkah berikutnya
Pelatihan yang benar-benar nempel
Jalankan dua sesi 45 menit: (1) “Cara kita query di sini” dengan pola query bersama (per service, env, region, version), dan (2) “Playbook troubleshooting” dengan alur sederhana: konfirmasi dampak → periksa marker deploy → persempit ke service → inspeksi traces → konfirmasi kesehatan dependency → putuskan rollback/mitigasi.
Checklist copy/paste
- Aturan penamaan service + tagging terdokumentasi
- Template dashboard + monitor dipublikasikan
- Top 10 monitor diaktifkan dan dimiliki
- 1–3 SLO didefinisikan untuk jalur kritis
- Template insiden dan alur disepakati
- Dua sesi pelatihan dilakukan + rekaman dibagikan
- Review governance bulanan (tag, monitor, biaya) dijadwalkan
Pertanyaan umum
Apa perbedaan antara alat observabilitas dan platform observabilitas?
Alat observabilitas adalah sesuatu yang Anda konsultasikan saat ada masalah (dashboard, pencarian log, sebuah query). Platform observabilitas adalah sesuatu yang Anda jalankan terus-menerus: menstandarkan telemetri, integrasi, akses, kepemilikan, alerting, dan alur insiden di seluruh tim sehingga hasilnya meningkat (deteksi dan resolusi lebih cepat).
Mengapa tim 'melampaui sekedar dashboard'?
Karena keuntungan terbesar datang dari hasil, bukan tampilan visual:
- menemukan akar masalah dengan cepat
- mengarahkan alert yang tepat ke pemilik yang tepat
- mengubah insiden berulang menjadi playbook yang dapat diulang
Grafik membantu, tetapi Anda butuh standar bersama dan alur kerja untuk konsisten menurunkan MTTD/MTTR.
Tag telemetri apa yang harus kita standarkan dulu?
Mulailah dengan baseline yang wajib dibawa setiap sinyal:
serviceenv(prod,staging, )
Apa arti high-cardinality, dan kapan kita harus menggunakannya?
Field high-cardinality (seperti user_id, order_id, session_id) berguna saat debugging kasus "hanya satu pelanggan yang bermasalah", tetapi mereka bisa menaikkan biaya dan memperlambat query jika dipakai di mana-mana.
Gunakan secara sengaja:
- simpan di logs/traces saat Anda menyelidiki permintaan individual
- hindari di metrics global yang dimaksudkan untuk agregat dan dashboard
Jenis telemetri mana yang paling penting dalam pendekatan platform ala Datadog?
Sebagian besar tim menstandarkan:
- metrics untuk tren (latency, error rate, saturation)
- logs untuk investigasi rinci dan audit
- traces untuk melihat jalur permintaan antar layanan
- events untuk “sesuatu berubah” (deploy, feature flag)
Apa jalur-ingest umum, dan bagaimana memilih di antara mereka?
Default praktis:
- agent di host/VM untuk pengumpulan infrastruktur + APM/log dengan cepat
- OpenTelemetry Collector (atau gateway) saat Anda butuh kontrol sentral, redaksi, atau routing ke banyak tujuan
- SDK/APIs untuk event bisnis/metrics kustom
- integrasi serverless untuk runtime terkelola, dengan kontrol sampling/volume yang disengaja
Pilih jalur yang sesuai kebutuhan kontrol Anda, lalu terapkan aturan penamaan/tagging yang sama di semuanya.
Bagaimana kita menyeimbangkan onboarding cepat dengan standardisasi jangka panjang?
Lakukan keduanya:
- izinkan quick start agar tim cepat merasakan manfaat
- minta penyelarasan dalam 30 hari (penamaan service, tag, format log, dashboard/monitor inti)
Ini mencegah setiap tim menciptakan skema sendiri-sendiri sambil menjaga momentum adopsi.
Mengapa integrasi bertindak seperti saluran distribusi untuk observabilitas?
Karena integrasi lebih dari sekadar pipa data—mereka meliputi:
- enrichment (tag kepemilikan, metadata cloud, versi)
- default (dashboard, monitor, aturan parsing)
- aksi (ticket, paging, pembuatan insiden, anotasi)
Prioritaskan integrasi bidirensional yang menerima sinyal dan juga memicu/mencatat aksi, sehingga observabilitas menjadi bagian dari kerja sehari-hari—bukan sekedar UI tujuan.
Apa yang harus disertakan dalam “standard views” agar insinyur bisa debug cepat?
Berpegang pada konsistensi dan reuse:
- satu layout “golden signals” per tipe service (latency, traffic, errors, saturation)
- katalog service dengan kepemilikan yang jelas
- monitor terkait dampak pengguna atau SLO, dengan runbook yang ditautkan
Hindari dashboard vanity dan alert sekali pakai. Jika sebuah query penting, simpan, beri nama, dan lampirkan ke tampilan service yang bisa ditemukan orang lain.
Bagaimana SLO dan alert burn-rate mengurangi noise dibanding alert tradisional?
Alert berdasarkan burn rate (seberapa cepat Anda mengonsumsi error budget), bukan setiap lonjakan sementara. Pola umum:
- fast burn: paging cepat untuk isu berat dan tahan lama
- slow burn: notifikasi atau ticket untuk degradasi yang lebih pelan
Buat starter set kecil (2–4 SLO per service) dan perluas hanya setelah tim benar-benar menggunakannya. Untuk dasar, lihat /blog/slo-monitoring-basics.
Mengapa alert fatigue terjadi (dan mengapa sinyal jadi terduplikasi)?
Alasan umum:
- terlalu banyak alert “FYI” yang tak perlu tindakan
- ambang yang disalin antar service tanpa konteks
- banyak alat/ tim yang memberi alert untuk gejala yang sama
- metric berisik yang memicu fluktuasi bukan masalah nyata
Di Datadog sering muncul duplikasi sinyal ketika monitor dibuat dari permukaan berbeda (metrics, logs, traces) tanpa menentukan yang kanonis untuk paging.
Bagaimana routing harus diatur: kepemilikan, severity, jam tenang?
Skalakan alerting dengan aturan routing yang masuk akal bagi manusia:
- Kepemilikan: setiap monitor harus punya owner (service/tim) dan jalur eskalasi
- Severity: paging untuk isu mendesak yang berdampak pada pengguna; gunakan ticket/chat untuk yang rendah
- Maintenance windows: deploy terjadwal, migrasi, dan load test tidak seharusnya memicu page
Default berguna: .
Kontrol praktis apa yang mencegah 'observability sprawl'?
Sederhanakan dengan kontrol ringan:
- template sebagai default: dashboard dan monitor starter per tipe service
- kebijakan tagging: set kecil yang wajib (mis.
service,env,team, ) dan aturan jelas untuk tag opsional
Tuas biaya praktis apa yang bisa dipakai tanpa menghilangkan sinyal?
Anda tidak perlu “mematikan semuanya”. Mulailah dengan membentuk data:
- Sampling: traces berkualitas tinggi untuk endpoint kritis, sampling lebih agresif di tempat lain
- Tier retensi: retensi singkat untuk raw logs volume tinggi; retensi lebih lama untuk stream audit/keamanan yang dikurasi
- Filtering & parsing logs: drop noise jelas lebih awal (health checks, asset statis) dan standarkan parsing untuk routing berdasar atribut
Apa arti ini untuk stack alat observabilitas kita?
Konsolidasi bukan harus satu vendor untuk semua, tapi berarti lebih sedikit sistem pencatat untuk telemetri dan respons, kepemilikan yang lebih jelas, dan lebih sedikit tempat yang harus dilihat orang saat outage.
Checklist praktis saat mengevaluasi stack:
- integrasi yang wajib: cloud provider, Kubernetes, CI/CD, incident management, paging, datastore kunci
- alur kerja: apakah Anda bisa melompat dari alert → owner → runbook → timeline → postmortem tanpa copy/paste manual?
- governance: standar tagging, kontrol akses, retensi, dan guardrail
- model harga: apa yang menggerakkan biaya? Bisa diprediksi?
Jalankan pilot pada 1–2 service dengan metrik sukses jelas (mis. waktu menemukan root cause turun dari 30 jadi 10 menit) selama dua minggu, dokumentasikan belajar di satu tempat seperti /blog/observability-basics.
Bagaimana rencana adopsi praktis yang bisa ditiru?
Mulai kecil, tetapkan standar dini, lalu skala apa yang berhasil.
30/60/90 hari:
- 0–30 hari: onboard 1–2 service kritis, instrument logs/metrics/traces, hubungkan integrasi (cloud, k8s, CI/CD, on-call)
- 31–60 hari: buat default dari pembelajaran—naming service, tagging, template dashboard, penamaan monitor, ownership; siapkan golden signals dan SLO minimal
- 61–90 hari: onboard tim tambahan pakai template yang sama; perkenalkan governance (tag rules, metadata wajib, proses review) dan pantau cost vs usage
Koder.ai cocok untuk membangun glue apps ringan: katalog service, hub runbook, halaman timeline insiden, atau portal internal yang menghubungkan owner → dashboard → SLO → playbook—cepat diprototipe dan deploy tanpa mengalihdayakan tim produk besar.
Apa kemenangan cepat yang bisa dikirim dalam minggu pertama?
Beberapa kemenangan cepat minggu pertama:
- Top 10 monitor untuk availability, error rate, latency, saturation, dan dependency kunci
- Marker deploy (dari CI/CD) di dashboard dan traces untuk korelasi perubahan instan
- Template insiden: apa yang terjadi, dampak, timeline, owner, link ke dashboard/query, langkah berikutnya
Pelatihan: dua sesi 45 menit — (1) ‘Cara query di sini’ dengan pola query bersama, dan (2) ‘Playbook troubleshooting’ dengan alur singkat: konfirmasi dampak → periksa marker deploy → persempit ke service → inspeksi traces → cek dependency → putuskan rollback/mitigasi.
Checklist copy/paste: