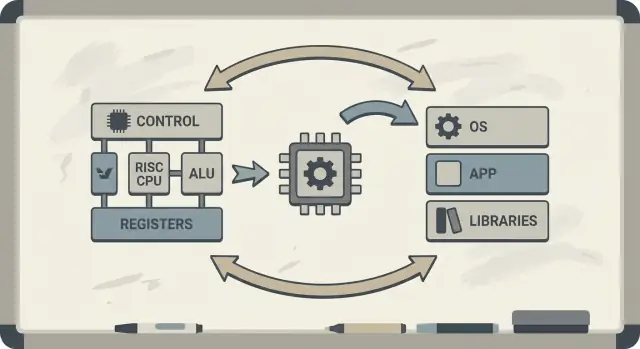
Mengapa Patterson dan RISC masih penting
David Patterson sering diperkenalkan sebagai “pelopor RISC,” tetapi pengaruhnya yang bertahan lebih luas daripada desain CPU tunggal. Ia membantu memopulerkan cara berpikir praktis tentang komputer: perlakukan kinerja sebagai sesuatu yang bisa diukur, disederhanakan, dan ditingkatkan dari ujung ke ujung—dari instruksi yang dikenali chip hingga alat perangkat lunak yang menghasilkan instruksi itu.
“Pemikiran RISC” dengan kata sederhana
RISC (Reduced Instruction Set Computing) adalah gagasan bahwa prosesor bisa berjalan lebih cepat dan lebih dapat diprediksi ketika fokus pada kumpulan instruksi yang lebih kecil dan sederhana. Alih-alih membangun satu menu besar operasi rumit di hardware, Anda membuat operasi umum menjadi cepat, teratur, dan mudah di-pipeline. Hasilnya bukanlah “kapabilitas lebih sedikit”—melainkan blok bangunan sederhana yang dieksekusi secara efisien sering menang pada beban kerja nyata.
Kodesain: chip dan kode saling memperbaiki
Patterson juga mengusung kodesain perangkat keras–perangkat lunak: loop umpan balik di mana arsitek chip, penulis kompiler, dan perancang sistem beriterasi bersama.
Jika sebuah prosesor dirancang untuk mengeksekusi pola sederhana dengan baik, kompiler dapat secara andal menghasilkan pola-pola itu. Jika kompiler menunjukkan bahwa program nyata menghabiskan waktu pada operasi tertentu (misalnya akses memori), hardware dapat disesuaikan untuk menangani kasus-kasus itu lebih baik. Inilah mengapa diskusi tentang arsitektur set instruksi (ISA) secara alami tersambung ke optimisasi kompiler, caching, dan pipelining.
Apa yang akan Anda dapat dari artikel ini
Anda akan memahami mengapa ide-ide RISC terkait dengan kinerja per watt (bukan hanya kecepatan mentah), bagaimana “prediktabilitas” membuat CPU modern dan chip mobile lebih efisien, dan bagaimana prinsip-prinsip ini muncul di perangkat saat ini—dari laptop hingga server cloud.
Jika Anda ingin peta konsep utama sebelum masuk lebih jauh, lompat ke /blog/key-takeaways-and-next-steps.
Masalah yang ditanggapi RISC
Mikroprosesor awal dibangun di bawah kendala ketat: chip punya ruang sirkuit terbatas, memori mahal, dan penyimpanan lambat. Perancang berusaha mengirim komputer yang terjangkau dan “cukup cepat,” sering dengan cache kecil (atau tanpa cache), kecepatan clock sederhana, dan memori utama yang sangat terbatas dibandingkan kebutuhan perangkat lunak.
Taruhan lama: instruksi kompleks = program lebih cepat
Sebuah gagasan populer saat itu adalah bahwa jika CPU menawarkan instruksi tingkat tinggi yang lebih kuat—yang bisa melakukan beberapa langkah sekaligus—program akan berjalan lebih cepat dan lebih mudah ditulis. Jika satu instruksi bisa “melakukan pekerjaan beberapa instruksi,” begitu pemikirannya, Anda akan membutuhkan lebih sedikit instruksi secara keseluruhan, menghemat waktu dan memori.
Itulah intuisi di balik banyak desain CISC (complex instruction set computing): beri pemrogram dan kompiler kotak alat besar dengan operasi canggih.
Ketidakcocokan: apa yang CPU tawarkan vs yang sebenarnya digunakan
Masalahnya, program nyata (dan kompiler yang menerjemahkannya) tidak konsisten memanfaatkan kompleksitas itu. Banyak instruksi paling rumit jarang dipakai, sementara seperangkat kecil operasi sederhana—load data, store data, add, compare, branch—muncul berulang kali.
Sementara itu, mendukung menu besar instruksi kompleks membuat CPU lebih sulit dibangun dan lebih lambat untuk dioptimalkan. Kompleksitas mengonsumsi area chip dan upaya desain yang bisa dipakai untuk membuat operasi umum berjalan secara prediktabel dan cepat.
RISC muncul sebagai respons terhadap celah itu: fokuskan CPU pada apa yang perangkat lunak benar-benar lakukan paling sering, dan buat jalur-jalur tersebut cepat—lalu biarkan kompiler melakukan lebih banyak pekerjaan “orkestrasi” secara sistematis.
RISC vs CISC: gagasan dengan kata sederhana
Cara sederhana memikirkan CISC vs RISC adalah membandingkan peralatan.
CISC (Complex Instruction Set Computing) seperti bengkel penuh alat khusus yang rumit—masing-masing bisa melakukan banyak hal dalam satu gerakan. Satu “instruksi” mungkin memuat data dari memori, melakukan perhitungan, dan menyimpan hasil, semuanya dibundel.
RISC (Reduced Instruction Set Computing) seperti membawa set alat yang lebih kecil dan andal yang sering Anda gunakan—palu, obeng, pita ukur—dan membangun semuanya dari langkah berulang. Setiap instruksi cenderung melakukan satu tugas kecil dan jelas.
Mengapa “lebih sederhana” bisa lebih cepat
Ketika instruksi lebih sederhana dan lebih seragam, CPU bisa mengeksekusinya dengan jalur perakitan yang lebih bersih (sebuah pipeline). Jalur ini lebih mudah dirancang, lebih mudah dijalankan pada kecepatan clock lebih tinggi, dan lebih mudah dijaga agar tetap sibuk.
Dengan instruksi gaya CISC yang “melakukan-banyak,” CPU sering harus mendekode dan memecah instruksi kompleks menjadi langkah internal yang lebih kecil. Itu bisa menambah kompleksitas dan membuat lebih sulit menjaga aliran pipeline.
Prediktabilitas penting
RISC menargetkan waktu instruksi yang dapat diprediksi—banyak instruksi memakan waktu yang kurang lebih sama. Prediktabilitas membantu CPU menjadwalkan pekerjaan secara efisien dan membantu kompiler menghasilkan kode yang menjaga pipeline tetap terisi alih-alih tersendat.
Trade-off (dan mengapa sering menguntungkan)
RISC biasanya membutuhkan lebih banyak instruksi untuk menyelesaikan tugas yang sama. Itu bisa berarti:
- Ukuran program sedikit lebih besar (lebih banyak byte kode)
- Lebih banyak pengambilan instruksi dari memori
Namun itu tetap menguntungkan jika setiap instruksi cepat, pipeline tetap mulus, dan desain keseluruhannya lebih sederhana.
Dalam praktiknya, kompiler yang teroptimasi dengan baik dan caching yang baik bisa mengimbangi kerugian “lebih banyak instruksi”—dan CPU bisa menghabiskan lebih banyak waktu melakukan kerja berguna dan lebih sedikit waktu untuk mengurai instruksi rumit.
Berkeley RISC dan pola pikir “ukur, lalu desain”
Berkeley RISC bukan sekadar set instruksi baru. Itu adalah sikap riset: jangan mulai dari apa yang tampak elegan di atas kertas—mulai dari apa yang program sebenarnya lakukan, lalu bentuk CPU di sekitar kenyataan itu.
Inti kecil dan cepat + kompiler pintar
Secara konseptual, tim Berkeley menginginkan inti CPU yang cukup sederhana agar bisa berjalan sangat cepat dan dapat diprediksi. Alih-alih memenuhi hardware dengan banyak “trik” instruksi rumit, mereka mengandalkan kompiler melakukan lebih banyak pekerjaan: memilih instruksi sederhana, menjadwalkan dengan baik, dan menjaga data di register sebanyak mungkin.
Pembagian kerja ini penting. Inti yang lebih kecil dan bersih lebih mudah di-pipeline secara efektif, lebih mudah dipahami, dan seringkali lebih cepat per transistor. Kompiler, yang melihat seluruh program, bisa merencanakan sebelumnya dengan cara yang sulit dilakukan hardware secara dinamis.
Ukur beban kerja nyata, bukan asumsi
David Patterson menekankan pengukuran karena desain komputer penuh mitos menggoda—fitur yang terdengar berguna tetapi jarang muncul di kode nyata. Berkeley RISC mendorong penggunaan benchmark dan jejak beban kerja untuk menemukan jalur panas: loop, pemanggilan fungsi, dan akses memori yang mendominasi runtime.
Ini berkaitan langsung dengan prinsip “buat kasus umum cepat.” Jika sebagian besar instruksi adalah operasi sederhana dan load/store, maka mengoptimalkan kasus yang sering itu akan memberi keuntungan lebih besar dibanding mempercepat instruksi kompleks yang jarang terjadi.
RISC sebagai cara berpikir
Pelajaran yang bertahan adalah bahwa RISC adalah baik arsitektur maupun pola pikir: sederhanakan yang sering terjadi, validasi dengan data, dan perlakukan hardware dan perangkat lunak sebagai satu sistem yang dapat disetel bersama.
Apa arti kodesain perangkat keras–perangkat lunak
Kodesain perangkat keras–perangkat lunak adalah gagasan bahwa Anda tidak merancang CPU secara terpisah. Anda merancang chip dan kompiler (dan kadang-kadang sistem operasi) saling memikirkan, sehingga program nyata berjalan cepat dan efisien—bukan hanya urutan instruksi sintetis “kasus terbaik”.
Loop umpan balik sederhana
Kodesain bekerja seperti loop rekayasa:
-
Pilihan ISA: arsitektur set instruksi (ISA) menentukan apa yang CPU bisa ekspresikan dengan mudah (misalnya, model “load/store”, banyak register, mode pengalamatan sederhana).
-
Strategi kompiler: kompiler menyesuaikan—menjaga variabel panas di register, menyusun ulang instruksi untuk menghindari stall, dan memilih konvensi pemanggilan yang mengurangi overhead.
-
Hasil beban kerja: Anda mengukur program nyata (kompiler, basis data, grafis, kode OS) dan melihat di mana waktu dan energi dihabiskan.
-
Desain selanjutnya: Anda mengubah ISA dan mikroarsitektur (kedalaman pipeline, jumlah register, ukuran cache) berdasarkan pengukuran itu.
Berikut loop kecil (C) yang menyoroti hubungan:
for (int i = 0; i < n; i++)
sum += a[i];
Pada ISA bergaya RISC, kompiler biasanya menjaga sum dan i di register, menggunakan instruksi load sederhana untuk a[i], dan melakukan penjadwalan instruksi sehingga CPU tetap sibuk sementara load sedang berjalan.
Mengabaikan kompiler membuang-buang silikon dan daya
Jika sebuah chip menambahkan instruksi kompleks atau hardware khusus yang jarang dipakai kompiler, area itu tetap mengonsumsi daya dan usaha desain. Sementara itu, hal-hal “membosankan” yang kompiler pakai—cukup register, pipeline yang dapat diprediksi, konvensi pemanggilan yang efisien—mungkin kurang didanai.
Pemikiran RISC ala Patterson menekankan menghabiskan silikon di tempat yang benar-benar memberi manfaat pada perangkat lunak nyata.
Pipeline, prediktabilitas, dan bantuan kompiler
Bawa pemikiran RISC ke mobile
Buat aplikasi mobile Flutter lewat chat dan iterasi pada kecepatan, daya, dan UX.
Ide kunci RISC adalah membuat “jalur perakitan” CPU lebih mudah dijaga tetap sibuk. Jalur perakitan ini adalah pipeline: alih-alih menyelesaikan satu instruksi sepenuhnya sebelum memulai yang berikutnya, prosesor memecah kerja menjadi tahap (fetch, decode, execute, write-back) dan menumpangkannya. Saat semuanya mengalir, Anda menyelesaikan hampir satu instruksi per siklus—seperti mobil bergerak melalui pabrik multi-stasiun.
Mengapa instruksi sederhana menjaga aliran
Pipeline bekerja terbaik ketika setiap item di jalur serupa. Instruksi RISC dirancang relatif uniform dan dapat diprediksi (sering panjang tetap, dengan pengalamatan sederhana). Itu mengurangi “kasus khusus” di mana satu instruksi membutuhkan waktu ekstra atau sumber daya tak biasa.
Ketika pipeline harus berhenti: hazard dan stall
Program nyata tidak selalu mulus. Kadang instruksi bergantung pada hasil instruksi sebelumnya (Anda tidak bisa memakai nilai sebelum dihitung). Kadang CPU menunggu data dari memori, atau belum tahu jalur branch. Situasi ini menyebabkan stall—jemputan singkat di mana bagian pipeline menganggur. Intuisi sederhananya: stall terjadi ketika tahap berikutnya tidak bisa melakukan kerja berguna karena sesuatu yang dibutuhkan belum tiba.
Kompiler sebagai pengatur lalu lintas
Di sinilah kodesain jelas terlihat. Jika hardware dapat diprediksi, kompiler bisa membantu dengan menyusun ulang urutan instruksi (tanpa mengubah makna program) untuk mengisi “celah.” Misalnya, saat menunggu nilai dihasilkan, kompiler bisa menjadwalkan instruksi independen yang tidak bergantung pada nilai itu.
Pembagian tanggung jawab menjanjikan: CPU tetap lebih sederhana dan cepat pada kasus umum, sementara kompiler melakukan lebih banyak perencanaan. Bersama-sama, mereka mengurangi stall dan meningkatkan throughput—sering kali meningkatkan kinerja nyata tanpa perlu set instruksi yang lebih kompleks.
Cache dan memory wall: tempat kodesain memberi manfaat
CPU bisa mengeksekusi operasi sederhana dalam beberapa siklus, tetapi mengambil data dari memori utama (DRAM) bisa memakan ratusan siklus. Kesenjangan itu ada karena DRAM secara fisik lebih jauh, dioptimalkan untuk kapasitas dan biaya, dan dibatasi oleh latensi (berapa lama satu permintaan) dan bandwidth (berapa banyak byte per detik yang bisa dipindahkan).
Saat CPU semakin cepat, memori tidak berkembang secepat itu—ketimpangan yang tumbuh ini sering disebut memory wall.
Cache dan locality
Cache adalah memori kecil dan cepat yang ditempatkan dekat CPU untuk menghindari hukuman DRAM pada setiap akses. Cache bekerja karena program nyata memiliki locality:
- Temporal locality: jika Anda menggunakan nilai atau instruksi baru-baru ini, kemungkinan besar Anda akan menggunakannya lagi segera.
- Spatial locality: jika Anda mengakses satu alamat, kemungkinan besar Anda akan mengakses alamat di sekitarnya berikutnya.
Chip modern menumpuk cache (L1, L2, L3), berusaha menjaga “working set” kode dan data dekat dengan core.
Di mana ISA dan kompiler memengaruhi perilaku cache
Di sinilah kodesain perangkat keras–perangkat lunak membayar kembali investasinya. ISA dan kompiler bersama-sama membentuk seberapa besar tekanan cache yang dibuat program.
- Ukuran kode penting. Binary yang lebih besar dan urutan instruksi berat dapat meluap ke instruction cache, menyebabkan stall. Pilihan ISA yang meningkatkan kepadatan kode (mis. instruksi terkompresi opsional) dapat menaikkan cache hit rate instruksi.
- Pola akses penting. Desain RISC gaya load/store membuat akses memori eksplisit. Kompiler kemudian bisa menjadwalkan load lebih awal, menyimpan nilai panas di register lebih lama, dan mengurangi lalu lintas memori yang tidak perlu.
- Layout dan blocking. Optimisasi kompiler seperti loop tiling (blocking), penyusunan ulang struktur data, dan petunjuk prefetch bertujuan mengubah “kunjungan DRAM acak” menjadi hit cache yang dapat diprediksi.
Memory wall dalam kinerja nyata
Dalam istilah sehari-hari, memory wall menjelaskan mengapa CPU dengan clock tinggi masih bisa terasa lambat: membuka aplikasi besar, menjalankan kueri basis data, menggulir feed, atau memproses dataset besar seringkali terhambat oleh cache miss dan bandwidth memori—bukan kecepatan aritmetika mentah.
Efisiensi: kinerja per watt, bukan hanya kecepatan mentah
Ubah build jadi kredit
Dapatkan kredit dengan membagikan hasil build Anda atau merujuk orang lain ke Koder.ai.
Lama-kelamaan, diskusi CPU seperti balapan: chip mana yang menyelesaikan tugas paling cepat “menang.” Namun komputer nyata hidup dalam batas fisik—kapasitas baterai, panas, kebisingan kipas, dan tagihan listrik.
Itulah mengapa kinerja per watt menjadi metrik inti: berapa banyak kerja berguna yang Anda dapatkan untuk energi yang dikeluarkan.
Apa arti sebenarnya “kinerja per watt”
Anggap sebagai efisiensi, bukan kekuatan puncak. Dua prosesor mungkin terasa serupa dalam penggunaan sehari-hari, tetapi salah satunya bisa melakukannya sambil menarik daya lebih sedikit, tetap lebih dingin, dan berjalan lebih lama pada baterai yang sama.
Di laptop dan ponsel, ini langsung memengaruhi umur baterai dan kenyamanan. Di pusat data, ini memengaruhi biaya daya dan pendinginan ribuan mesin, plus seberapa rapat Anda bisa menempatkan server tanpa kepanasan.
Mengapa inti yang lebih sederhana sering membuang lebih sedikit energi
Pemikiran RISC mendorong desain CPU menuju melakukan lebih sedikit hal di hardware, dengan eksekusi yang lebih dapat diprediksi. Inti yang lebih sederhana dapat mengurangi daya melalui beberapa sebab:
- Logika kontrol yang lebih sedikit rumit berarti lebih sedikit bagian internal yang berubah setiap siklus.
- Eksekusi yang lebih dapat diprediksi memudahkan menjaga pipeline tetap sibuk tanpa kerja pemulihan mahal.
- Desain yang ramah kompiler memungkinkan perangkat lunak menjadwalkan pekerjaan secara efisien, menghindari hardware melakukan tebakan ekstra.
Poinnya bukan bahwa “sederhana selalu lebih baik.” Melainkan kompleksitas punya biaya energi, dan set instruksi serta mikroarsitektur yang dipilih dengan baik bisa menukar sedikit kecanggihan demi banyak efisiensi.
Perpaduan tujuan antara mobile dan server
Ponsel peduli baterai dan panas; server peduli pasokan daya dan pendinginan. Lingkungan berbeda, pelajaran sama: chip tercepat bukan selalu komputer terbaik. Pemenang sering kali desain yang memberikan throughput stabil sambil mengontrol penggunaan energi.
Apa yang RISC lakukan dengan benar—dan apa yang lebih rumit
RISC sering disingkat sebagai “instruksi lebih sederhana menang,” tetapi pelajaran yang lebih tahan lama lebih halus: set instruksi penting, tetapi banyak keuntungan dunia nyata datang dari bagaimana chip diimplementasikan, bukan hanya tampilan ISA di atas kertas.
Debat “set instruksi penting”
Argumen RISC awal mengisyaratkan bahwa set instruksi yang lebih bersih dan kecil otomatis membuat komputer lebih cepat. Dalam praktiknya, peningkatan terbesar sering datang dari pilihan implementasi yang RISC permudah: decoding yang lebih sederhana, pipelining lebih dalam, clock lebih tinggi, dan kompiler yang bisa menjadwalkan kerja lebih prediktabel.
Itulah mengapa dua CPU dengan ISA berbeda bisa berakhir memiliki kinerja yang mengejutkan mirip jika mikroarsitektur, ukuran cache, prediksi cabang, dan proses fabrikasinya berbeda. ISA menetapkan aturan; mikroarsitektur memainkan permainannya.
Pengukuran mengalahkan daftar fitur
Perubahan besar di era Patterson adalah mendesain dari data, bukan dari asumsi. Alih-alih menambah instruksi karena tampak berguna, tim mengukur apa yang program sebenarnya lakukan, lalu mengoptimalkan kasus umum.
Sikap ini sering mengalahkan desain berbasis fitur, di mana kompleksitas tumbuh lebih cepat daripada manfaatnya. Ini juga membuat trade-off lebih jelas: instruksi yang menghemat beberapa baris kode mungkin menambah siklus, daya, atau area chip—dan biaya itu muncul di mana-mana.
Bukan cerita pemenang-ambil-semua
Pemikiran RISC tidak hanya membentuk “chip RISC.” Seiring waktu, banyak CPU CISC mengadopsi teknik internal mirip RISC (mis. memecah instruksi kompleks menjadi operasi internal yang lebih sederhana) sambil mempertahankan kompatibilitas ISA.
Jadi hasilnya bukan “RISC mengalahkan CISC.” Itu evolusi menuju desain yang menghargai pengukuran, prediktabilitas, dan koordinasi perangkat keras–perangkat lunak yang rapat—tanpa memandang logo pada ISA.
Dari MIPS ke RISC-V: benang yang berlanjut
RISC tidak berhenti di lab. Salah satu garis paling jelas dari riset awal ke praktik modern berjalan dari MIPS ke RISC-V—dua ISA yang menjadikan kesederhanaan dan kejelasan sebagai fitur, bukan kendala.
MIPS: ISA bersih yang mudah dibangun (dan dipelajari)
MIPS sering diingat sebagai ISA pengajaran, dan bukan tanpa alasan: aturannya mudah dijelaskan, format instruksi konsisten, dan model load/store menjaga kompiler tetap leluasa.
Kebersihan itu bukan hanya akademis. Prosesor MIPS dipasarkan pada produk nyata selama bertahun-tahun (dari workstation hingga embedded), sebagian karena ISA yang lugas memudahkan pembuatan pipeline cepat, kompiler yang dapat diprediksi, dan toolchain efisien. Ketika perilaku hardware reguler, perangkat lunak bisa merencanakan sekitarnya.
RISC-V: terbuka, praktis, dan ramah kodesain
RISC-V menghidupkan kembali minat pada pemikiran RISC dengan langkah penting yang tidak dilakukan MIPS: ia adalah ISA terbuka. Itu mengubah insentif. Universitas, startup, dan perusahaan besar bisa bereksperimen, mengirimkan silikon, dan berbagi tooling tanpa harus berunding akses ke set instruksi.
Untuk kodesain, keterbukaan itu penting karena sisi “perangkat lunak” (kompiler, OS, runtime) bisa berkembang di publik bersamaan dengan sisi “perangkat keras,” dengan lebih sedikit hambatan artifisial.
Ekstensi modular: tambahkan bila perlu
Alasan lain RISC-V cocok untuk kodesain adalah pendekatan modularnya. Anda mulai dari ISA basis kecil, lalu menambahkan ekstensi untuk kebutuhan tertentu—seperti matematika vektor, kendala embedded, atau fitur keamanan.
Ini mendorong trade-off yang lebih sehat: alih-alih memasukkan setiap fitur ke dalam desain monolitik, tim dapat menyelaraskan fitur hardware dengan perangkat lunak yang sebenarnya dijalankan.
Jika Anda ingin primer lebih dalam, lihat /blog/what-is-risc-v.
Bagaimana kodesain muncul di komputasi modern
Desain bersama tim Anda
Bekerja bersama pada aplikasi yang sama dan jaga keputusan tetap jelas dengan rencana bersama.
Kodesain bukan catatan sejarah dari era RISC—itulah cara komputasi modern terus menjadi lebih cepat dan efisien. Ide kunci masih ala Patterson: Anda tidak “menang” dengan perangkat keras saja atau perangkat lunak saja. Anda menang ketika keduanya saling melengkapi kekuatan dan batasannya.
Pemikiran RISC di perangkat yang Anda gunakan sehari-hari
Smartphone dan banyak perangkat embedded sangat mengandalkan prinsip RISC (seringkali berbasis ARM): instruksi sederhana, eksekusi yang dapat diprediksi, dan penekanan kuat pada penggunaan energi.
Prediktabilitas ini membantu kompiler menghasilkan kode efisien dan membantu perancang membangun inti yang hemat energi saat Anda menggulir, namun bisa meledak kinerjanya untuk pipeline kamera atau game.
Laptop dan server kian mengejar tujuan yang sama—khususnya kinerja per watt. Bahkan ketika ISA tidak tradisional “RISC,” banyak pilihan desain internal menargetkan efisiensi ala RISC: pipelining dalam, eksekusi lebar, dan manajemen daya agresif yang disesuaikan dengan perilaku perangkat lunak nyata.
Accelerator adalah kodesain yang nyata
GPU, akselerator AI (TPU/ NPU), dan engine media adalah bentuk nyata kodesain: alih-alih memaksa semua kerja lewat CPU serba-guna, platform menyediakan hardware yang cocok untuk pola komputasi umum.
Yang membuat ini kodesain (bukan sekadar “hardware ekstra”) adalah tumpukan perangkat lunak di sekitarnya:
- GPU mendapatkan kecepatannya dari model pemrograman seperti CUDA dan API seperti Vulkan/Metal.
- Akselerator AI bergantung pada kompiler dan optimizer graf yang mengubah model jadi operasi yang disukai chip.
- Encoder/decoder video berfaedah karena OS, browser, dan aplikasi ditulis untuk memanfaatkannya.
Jika perangkat lunak tidak menargetkan akselerator, kecepatan teoretisnya tetap hanya teori.
Tumpukan perangkat lunak bagian dari kinerja
Dua platform dengan spesifikasi serupa bisa terasa sangat berbeda karena “produk nyata” mencakup kompiler, perpustakaan, dan framework. Perpustakaan matematika yang dioptimasi (BLAS), JIT yang baik, atau kompiler yang lebih pintar bisa memberi keuntungan besar tanpa mengubah chip.
Inilah mengapa desain CPU modern sering dipacu oleh benchmark: tim hardware melihat apa yang kompiler dan beban kerja lakukan, lalu menyesuaikan fitur (cache, branch prediction, instruksi vektor, prefetching) untuk membuat kasus umum lebih cepat.
Daftar cepat: apa yang diperhatikan
Saat mengevaluasi platform (ponsel, laptop, server, atau papan embedded), cari sinyal kodesain:
- Kecocokan beban kerja: Apakah aplikasi Anda CPU-bound, GPU-bound, memory-bound, atau cocok untuk akselerator?
- Ketersediaan akselerator: Apakah ada NPU/GPU/engine media—dan apakah alat Anda benar-benar menggunakannya?
- Kemadiran kompiler/toolchain: Apakah ada build yang teroptimasi, alat profiling yang baik, dan dukungan aktif?
- Ekosistem perpustakaan: Apakah perpustakaan inti (matematika, visi, kripto) di-tune untuk hardware itu?
- Perilaku daya: Apakah Anda mendapatkan kinerja berkelanjutan dalam batas termal/ daya?
Kemajuan komputasi modern kurang soal satu “CPU lebih cepat” dan lebih soal seluruh sistem perangkat keras-plus-perangkat lunak yang telah dibentuk—diukur, lalu didesain—di sekitar beban kerja nyata.
Poin penting dan langkah praktis berikutnya
Pemikiran RISC dan pesan lebih luas Patterson dapat diringkas menjadi beberapa pelajaran tahan lama: sederhanakan apa yang harus cepat, ukur apa yang benar-benar terjadi, dan perlakukan perangkat keras serta perangkat lunak sebagai satu sistem—karena pengguna merasakan keseluruhan, bukan komponennya.
Pelajaran yang layak diingat
Pertama, kesederhanaan adalah strategi, bukan estetika. ISA yang bersih dan eksekusi yang dapat diprediksi memudahkan kompiler menghasilkan kode bagus dan CPU menjalankannya secara efisien.
Kedua, pengukuran mengalahkan intuisi. Benchmark dengan beban kerja representatif, kumpulkan data profiling, dan biarkan bottleneck nyata memandu keputusan desain—baik Anda menyetel optimisasi kompiler, memilih SKU CPU, atau merancang ulang hot path kritis.
Ketiga, kodesain adalah tempat keuntungan bertumpuk. Kode yang ramah pipeline, struktur data yang sadar cache, dan tujuan kinerja-per-watt realistis sering memberikan kecepatan praktis lebih besar daripada mengejar throughput teoretis puncak.
Langkah praktis untuk tim produk
Jika Anda memilih platform (sistem berbasis x86, ARM, atau RISC-V), evaluasi seperti pengguna Anda:
- Benchmark skenario end-to-end (waktu startup, throughput steady-state, tail latency), bukan hanya microbenchmark.
- Lacak metrik efisiensi (watt, termal, dampak baterai) bersamaan dengan kinerja.
- Iterasi: profil → ubah satu hal → ukur lagi. Langkah kecil yang tervalidasi akan terakumulasi.
Jika bagian pekerjaan Anda adalah mengubah pengukuran itu menjadi perangkat lunak yang dirilis, memendekkan loop build–measure dapat membantu. Misalnya, tim menggunakan Koder.ai untuk membuat prototipe dan mengembangkan aplikasi nyata melalui alur kerja berbasis chat (web, backend, dan mobile), lalu menjalankan kembali benchmark end-to-end yang sama setelah setiap perubahan. Fitur seperti mode perencanaan, snapshot, dan rollback mendukung disiplin “ukur, lalu desain” yang didorong Patterson—diterapkan pada pengembangan produk modern.
Untuk primer lebih mendalam soal efisiensi, lihat /blog/performance-per-watt-basics. Jika Anda membandingkan lingkungan dan butuh cara sederhana memperkirakan trade-off biaya/kinerja, /pricing mungkin membantu.
Pesan yang bertahan: ide-idenya—kesederhanaan, pengukuran, dan kodesain—terus memberi hasil, bahkan saat implementasi berkembang dari pipeline era MIPS ke core heterogen modern dan ISA baru seperti RISC-V.