27 Sep 2025·8 menit
Blue/Green & Canary Deployments: Strategi Rilis yang Jelas
Pelajari kapan menggunakan Blue/Green vs Canary, bagaimana pergeseran lalu lintas bekerja, apa yang dipantau, serta langkah rollout dan rollback praktis untuk rilis yang lebih aman.
Apa Arti Blue/Green dan Canary Deployments
Mengirim kode baru berisiko karena alasan sederhana: Anda tidak benar-benar tahu bagaimana kode itu berperilaku sampai pengguna nyata menggunakannya. Blue/Green dan Canary adalah dua cara umum untuk mengurangi risiko itu sambil menjaga downtime mendekati nol.
Blue/Green dalam kata-kata sederhana
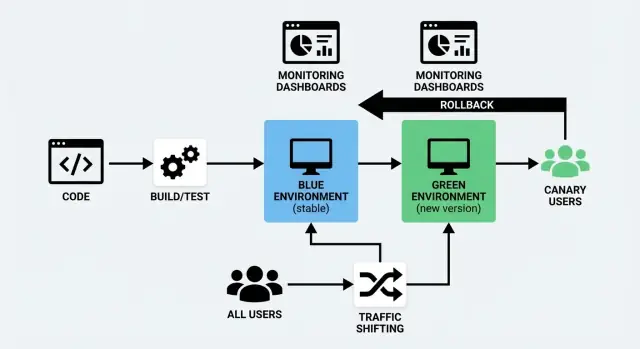
Sebuah blue/green deployment menggunakan dua lingkungan terpisah namun serupa:
- Blue: versi yang saat ini melayani pengguna (konfigurasi “live”).
- Green: setup kedua yang siap dipakai tempat Anda menerapkan versi baru.
Anda menyiapkan lingkungan Green di latar belakang — deploy build baru, jalankan pengecekan, hangatkan — lalu Anda mengalihkan lalu lintas dari Blue ke Green saat sudah yakin. Jika ada masalah, Anda bisa berbalik dengan cepat.
Inti idenya bukanlah “dua warna”, melainkan cutover yang bersih dan bisa dibalik.
Canary dalam kata-kata sederhana
Sebuah canary release adalah rollout bertahap. Alih-alih memindahkan semua orang sekaligus, Anda mengirim versi baru ke sebagian kecil pengguna terlebih dahulu (misalnya 1–5%). Jika semuanya terlihat sehat, Anda memperluas rollout langkah demi langkah sampai 100% lalu lintas menggunakan versi baru.
Inti idenya adalah belajar dari lalu lintas nyata sebelum sepenuhnya berkomitmen.
Tujuan bersama: rilis lebih aman dengan downtime lebih sedikit
Kedua pendekatan ini adalah strategi deployment yang bertujuan untuk:
- mengurangi dampak ke pengguna saat terjadi kegagalan
- mendukung deploy tanpa downtime (atau sedekat mungkin dengan itu)
- membuat rollback lebih tenang dan lebih dapat diprediksi
Mereka melakukannya dengan cara berbeda: Blue/Green fokus pada pengalihan cepat antar lingkungan, sementara Canary fokus pada eksposur terkontrol lewat pergeseran lalu lintas.
Tidak ada pilihan tunggal “terbaik”
Tidak ada pendekatan yang otomatis lebih unggul. Pilihan yang tepat bergantung pada cara produk Anda digunakan, seberapa percaya diri Anda pada pengujian, seberapa cepat Anda butuh umpan balik, dan jenis kegagalan yang ingin Anda hindari.
Banyak tim juga mencampur keduanya — menggunakan Blue/Green untuk kesederhanaan infrastruktur dan teknik Canary untuk eksposur pengguna yang bertahap.
Di bagian berikutnya, kami akan membandingkan langsung dan menunjukkan kapan masing-masing biasanya bekerja paling baik.
Blue/Green vs Canary: Perbandingan Singkat
Blue/Green dan Canary sama-sama cara merilis perubahan tanpa mengganggu pengguna — tetapi mereka berbeda dalam bagaimana lalu lintas berpindah ke versi baru.
Bagaimana lalu lintas berpindah
Blue/Green menjalankan dua lingkungan penuh: “Blue” (saat ini) dan “Green” (baru). Anda memvalidasi Green, lalu mengalihkan semua lalu lintas sekaligus — seperti membalik satu sakelar yang terkontrol.
Canary merilis versi baru ke sebagian kecil pengguna terlebih dahulu (misalnya 1–5%), lalu menggeser lalu lintas secara bertahap sambil memantau performa di dunia nyata.
Kelebihan dan kekurangan yang benar-benar penting
| Faktor | Blue/Green | Canary |
|---|---|---|
| Kecepatan | Cutover sangat cepat setelah validasi | Lebih lambat karena rollout bertahap |
| Risiko | Sedang: rilis yang buruk memengaruhi semua pengguna setelah switch | Lebih rendah: masalah sering muncul sebelum rollout penuh |
| Kompleksitas | Sedang (dua lingkungan, pengalihan bersih) | Lebih tinggi (pembagian lalu lintas, analisis, langkah bertahap) |
| Biaya | Lebih tinggi (efektif menggandakan kapasitas saat rollout) | Sering lebih rendah (bisa memanfaatkan kapasitas yang ada) |
| Cocok untuk | Perubahan besar dan terkoordinasi | Perbaikan kecil yang sering |
Pedoman keputusan sederhana
Pilih Blue/Green ketika Anda menginginkan momen cutover yang bersih dan dapat diprediksi — terutama untuk perubahan besar, migrasi, atau rilis yang memerlukan pemisahan tegas antara “lama vs baru”.
Pilih Canary ketika Anda sering mengirim, ingin belajar dari penggunaan nyata dengan aman, dan lebih suka mengurangi blast radius dengan membiarkan metrik memandu setiap langkah.
Jika ragu, mulai dengan Blue/Green untuk kesederhanaan operasional, lalu tambahkan Canary untuk layanan berisiko tinggi setelah kebiasaan monitoring dan rollback matang.
Kapan Blue/Green Tepat
Blue/Green adalah pilihan kuat ketika Anda ingin rilis terasa seperti “membalik sakelar.” Anda menjalankan dua lingkungan yang mirip produksi: Blue (saat ini) dan Green (baru). Ketika Green terverifikasi, Anda mengarahkan pengguna ke sana.
Anda butuh downtime hampir nol
Jika produk Anda tidak bisa menoleransi jendela pemeliharaan yang terlihat — alur checkout, sistem pemesanan, dashboard yang memerlukan login — Blue/Green membantu karena versi baru sudah dimulai, dihangatkan, dan diperiksa sebelum pengguna nyata diarahkan. Sebagian besar “waktu deploy” terjadi di samping, bukan di depan pelanggan.
Anda ingin rollback sesederhana mungkin
Rollback sering kali hanya mengarahkan lalu lintas kembali ke Blue. Ini berharga ketika:
- rilis harus bisa dibalik dalam hitungan menit
- Anda ingin menghindari hotfix darurat dalam tekanan
- Anda butuh respons kegagalan yang jelas dan dapat diulang
Manfaat utamanya adalah rollback tidak memerlukan rebuild atau redeploy — cukup pengalihan lalu lintas.
Perubahan basis data bisa dibuat kompatibel ke belakang
Blue/Green paling mudah ketika migrasi database kompatibel ke belakang, karena untuk periode singkat Blue dan Green mungkin sama-sama ada (dan mungkin keduanya membaca/menulis, tergantung routing dan setup job). Kecocokan yang baik meliputi:
- perubahan skema additive (kolom baru nullable, tabel baru)
- memperluas format data sedemikian rupa agar kode lama dapat mengabaikannya
Yang berisiko termasuk menghapus kolom, mengganti nama field, atau mengubah makna di tempat — itu dapat mematahkan janji “bisa berbalik” kecuali Anda merencanakan migrasi bertahap.
Anda mampu menyediakan lingkungan duplikat dan kontrol routing
Blue/Green memerlukan kapasitas ekstra (dua tumpukan) dan cara mengarahkan lalu lintas (load balancer, ingress, atau routing platform). Jika Anda sudah memiliki automasi untuk membuat lingkungan dan tuas routing yang bersih, Blue/Green menjadi default yang praktis untuk rilis berkepercayaan tinggi.
Kapan Canary Lebih Masuk Akal
Canary adalah strategi di mana Anda meluncurkan perubahan ke sebagian pengguna nyata terlebih dahulu, belajar dari apa yang terjadi, lalu memperluas. Ini tepat ketika Anda ingin mengurangi risiko tanpa menghentikan sistem untuk rilis besar.
Anda punya banyak lalu lintas — dan sinyal yang jelas
Canary bekerja terbaik untuk aplikasi dengan trafik tinggi karena bahkan 1–5% lalu lintas sudah bisa menghasilkan data bermakna dengan cepat. Jika Anda sudah melacak metrik yang jelas (error rate, latency, konversi, penyelesaian checkout, timeout API), Anda bisa memvalidasi rilis berdasarkan penggunaan nyata daripada hanya mengandalkan lingkungan pengujian.
Anda khawatir tentang performa dan edge case
Beberapa masalah hanya muncul di bawah beban nyata: query DB lambat, cache miss, latensi regional, perangkat yang jarang, atau alur pengguna yang langka. Dengan canary, Anda bisa memastikan perubahan tidak meningkatkan error atau menurunkan performa sebelum mencapai semua pengguna.
Anda butuh rollout bertahap, bukan satu cutover
Jika produk Anda sering dikirim, memiliki banyak tim yang berkontribusi, atau mencakup perubahan yang bisa diperkenalkan bertahap (penyesuaian UI, eksperimen harga, logika rekomendasi), canary cocok secara alami. Anda bisa memperluas dari 1% → 10% → 50% → 100% berdasarkan pengamatan.
Feature flags adalah bagian dari alat Anda
Canary sangat cocok dipasangkan dengan feature flags: Anda bisa deploy kode dengan aman, lalu mengaktifkan fungsi untuk subset pengguna, region, atau akun. Rollback seringkali cukup dengan mematikan flag daripada redeploy.
Jika Anda membangun menuju pengiriman progresif, canary sering menjadi titik awal paling fleksibel.
Lihat juga: /blog/feature-flags-and-progressive-delivery
Dasar-dasar Pergeseran Lalu Lintas (Tanpa Jargon)
Pergeseran lalu lintas berarti mengendalikan siapa yang mendapat versi baru aplikasi Anda dan kapan. Alih-alih memindahkan semua orang sekaligus, Anda memindahkan permintaan secara bertahap (atau selektif) dari versi lama ke versi baru. Ini adalah inti praktis dari baik blue/green deployment maupun canary release — dan juga yang membuat deploy tanpa downtime menjadi realistis.
“Setir” : tempat lalu lintas diarahkan
Anda bisa menggeser lalu lintas di beberapa titik umum dalam stack. Pilihan yang tepat bergantung pada apa yang Anda jalankan dan seberapa rinci kontrol yang Anda butuhkan.
- Load balancer: membagi permintaan masuk antara dua lingkungan atau dua set server.
- Ingress controller (Kubernetes): mengarahkan lalu lintas ke Service berbeda berdasarkan aturan.
- Service mesh: mengontrol lalu lintas antar layanan dengan aturan yang presisi dan visibilitas lebih baik.
- CDN / routing edge: berguna ketika Anda ingin keputusan routing dekat dengan pengguna, sering untuk trafik web.
Anda tidak perlu setiap lapisan. Pilih satu “sumber kebenaran” untuk keputusan routing supaya manajemen rilis Anda tidak jadi tebak-tebakan.
Cara umum membagi lalu lintas
Kebanyakan tim menggunakan salah satu (atau campuran) pendekatan ini untuk pergeseran lalu lintas:
- Berdasarkan persentase: 1% → 5% → 25% → 50% → 100%. Ini pola canary klasik.
- Berdasarkan header: mengarahkan permintaan yang memiliki header tertentu (mis. dari alat QA atau tester internal) ke versi baru.
- Kohort pengguna: memindahkan grup tertentu lebih dulu — karyawan, pengguna beta, wilayah, atau tier pelanggan.
Persentase paling mudah dijelaskan, tetapi kohort seringkali lebih aman karena Anda bisa mengontrol siapa yang melihat perubahan (dan menghindari mengejutkan pelanggan terbesar Anda pada jam pertama).
Session dan cache: dua "gotcha"
Dua hal yang sering merusak rencana deployment yang seharusnya solid:
Sticky sessions (afinitas sesi). Jika sistem Anda mengikat pengguna ke satu server/versi, pembagian 10% lalu lintas mungkin tidak berperilaku seperti 10%. Ini juga dapat menyebabkan bug membingungkan saat pengguna berpindah antar versi di tengah sesi. Jika memungkinkan, gunakan penyimpanan sesi bersama atau pastikan routing menjaga konsistensi pengguna pada satu versi.
Cache warming. Versi baru sering mengalami cache dingin (CDN, cache aplikasi, cache query DB). Itu bisa tampak seperti regresi performa meskipun kodenya baik. Rencanakan waktu untuk menghangatkan cache sebelum meningkatkan lalu lintas, terutama untuk halaman dengan trafik tinggi dan endpoint mahal.
Jadikan perubahan lalu lintas sebagai operasi terkontrol
Perlakukan perubahan routing seperti perubahan produksi, bukan klik sembarang. Dokumentasikan:
- siapa yang boleh mengubah pembagian lalu lintas
- bagaimana disetujui (on-call? release manager? tiket perubahan?)
- di mana dilakukan (konfigurasi load balancer, aturan ingress, kebijakan mesh)
- apa yang dimaksud dengan “stop” (pemicu untuk menghentikan rollout dan mengikuti rencana rollback)
Sedikit tata kelola ini mencegah orang yang berniat baik dari “hanya mendorongnya ke 50%” sementara Anda masih memeriksa kesehatan canary.
Apa yang Dipantau Selama Rollout
Kendalikan Jalur Rilis Anda
Pertahankan kontrol dengan mengekspor kode sumber kapan pun diperlukan.
Rollout bukan hanya “apakah deploy berhasil?” Ini adalah “apakah pengguna nyata mengalami pengalaman yang lebih buruk?” Cara termudah tetap tenang selama Blue/Green atau Canary adalah memantau sekumpulan sinyal kecil yang memberi tahu Anda: apakah sistem sehat, dan apakah perubahan merugikan pelanggan?
Empat sinyal inti: error, latency, saturation, dampak pengguna
Tingkat error: Pantau HTTP 5xx, kegagalan permintaan, timeout, dan error dependensi (database, pembayaran, API pihak ketiga). Canary yang menambah “error kecil” tetap bisa menciptakan beban dukungan besar.
Latency: Amati p50 dan p95 (dan p99 jika tersedia). Perubahan yang menjaga rata-rata tetap stabil masih bisa menciptakan perlambatan ekor panjang yang dirasakan pengguna.
Saturation: Lihat seberapa “penuh” sistem Anda—CPU, memori, IO disk, koneksi DB, kedalaman antrean, pool thread. Masalah saturasi sering muncul sebelum gangguan penuh.
Sinyal dampak pengguna: Ukur apa yang benar-benar dialami pengguna—gagal checkout, keberhasilan sign-in, hasil pencarian, tingkat crash aplikasi, waktu muat halaman kunci. Ini sering lebih bermakna daripada statistik infrastruktur saja.
Bangun “dasbor rilis” yang bisa dibaca semua orang
Buat dasbor kecil yang muat di satu layar dan dibagikan di saluran rilis Anda. Pertahankan konsistensi di setiap rollout agar orang tidak buang waktu mencari grafik.
Sertakan:
- tingkat error (total + endpoint kunci)
- latency (p50/p95 untuk jalur kritis)
- saturation (3 kendala teratas untuk stack Anda, mis. CPU app, koneksi DB, kedalaman antrean)
- KPI dampak pengguna (1–3 alur bisnis paling penting)
Jika menjalankan canary, segmentasikan metrik berdasarkan versi/grup instance sehingga Anda bisa membandingkan canary vs baseline secara langsung. Untuk blue/green, bandingkan lingkungan baru vs lama selama jendela cutover.
Tetapkan ambang jelas untuk jeda/rollback
Putuskan aturan sebelum mulai menggeser lalu lintas. Contoh ambang:
- tingkat error naik X% dari baseline selama Y menit
- p95 latency melewati batas tetap (atau naik X% dari baseline)
- KPI dampak pengguna turun di bawah batas minimum yang dapat diterima
Angka tepatnya tergantung layanan Anda, tapi yang penting adalah kesepakatan. Jika semua orang tahu rencana rollback dan pemicunya, Anda menghindari debat saat pelanggan terdampak.
Alert yang fokus pada jendela rollout
Tambahkan (atau perketat sementara) alert khusus selama jendela rollout:
- lonjakan 5xx/timeout yang tidak terduga
- regresi latency tiba-tiba pada rute kunci
- peningkatan cepat pada sinyal saturasi (pool koneksi, antrean)
Buat alert dapat ditindaklanjuti: "apa yang berubah, di mana, dan apa langkah selanjutnya." Jika alert berisik, orang akan melewatkan sinyal penting ketika pergeseran lalu lintas berjalan.
Pemeriksaan Pra-Rilis yang Menangkap Masalah Lebih Awal
Sebagian besar kegagalan rollout bukan disebabkan bug besar. Mereka disebabkan ketidaksesuaian kecil: nilai konfigurasi hilang, migrasi DB bermasalah, sertifikat kedaluwarsa, atau integrasi yang berperilaku berbeda di lingkungan baru. Pemeriksaan pra-rilis adalah kesempatan Anda menangkap masalah-masalah itu saat blast radius masih kecil.
Mulai dengan health checks dan smoke tests
Sebelum Anda menggeser lalu lintas (baik cutover blue/green atau canary kecil), pastikan versi baru dasar-dasarnya hidup dan bisa melayani permintaan.
- Pastikan endpoint health aplikasi melaporkan OK (bukan sekadar "proses berjalan")
- Validasi dependensi: database, cache, antrean, object storage, penyedia email/SMS
- Konfirmasi secrets dan variabel lingkungan hadir dan scope-nya benar
Jalankan tes end-to-end singkat terhadap lingkungan baru
Unit test bagus, tetapi tidak membuktikan sistem terdeploy bekerja. Jalankan suite end-to-end otomatis singkat terhadap lingkungan baru yang selesai dalam hitungan menit, bukan jam.
Fokus pada alur yang melintasi boundary layanan (web → API → DB → pihak ketiga), dan sertakan setidaknya satu permintaan “nyata” per integrasi kunci.
Verifikasi perjalanan pengguna kritis (yang menghasilkan uang)
Tes otomatis kadang melewatkan hal yang jelas. Lakukan verifikasi targeted, ramah manusia untuk alur inti:
- login dan reset kata sandi
- alur checkout atau pembayaran (termasuk jalur kegagalan)
- aksi inti “buat / ubah / hapus” yang dilakukan pengguna setiap hari
Jika mendukung banyak peran (admin vs customer), sampel setidaknya satu perjalanan per peran.
Pertahankan checklist kesiapan pra-rilis
Checklist mengubah pengetahuan tribal menjadi strategi deployment yang dapat diulang. Jaga agar singkat dan dapat ditindaklanjuti:
- migrasi database diterapkan dan dapat dibalik (atau jelas aman)
- observability siap: logs, dasbor, alert untuk metrik kunci
- rencana rollback ditinjau (siapa, bagaimana, dan apa arti "stop")
Saat pemeriksaan ini rutin, pergeseran lalu lintas menjadi langkah yang terkontrol — bukan lompatan iman.
Blue/Green Rollout: Buku Panduan Praktis
Lakukan Latihan Rilis
Buat satu alur kerja, luncurkan, dan latih rollback supaya hari rilis terasa tenang.
Rollout blue/green paling mudah dijalankan bila Anda memperlakukannya seperti checklist: siapkan, deploy, validasi, switch, observasi, lalu bersihkan.
1) Deploy ke Green (tanpa menyentuh pengguna)
Kirim versi baru ke lingkungan Green sementara Blue terus melayani lalu lintas nyata. Samakan konfigurasi dan secrets supaya Green benar-benar mirror.
2) Verifikasi Green sebelum pengalihan lalu lintas
Lakukan pengecekan cepat dengan sinyal tinggi terlebih dahulu: aplikasi mulai bersih, halaman kunci terbuka, pembayaran/login berfungsi, dan log normal. Jika ada smoke test otomatis, jalankan sekarang. Ini juga saatnya memastikan dasbor dan alert untuk Green aktif.
3) Rencanakan migrasi database dengan cara yang aman (expand/contract)
Blue/green jadi rumit saat database berubah. Gunakan pendekatan expand/contract:
- Expand: tambahkan kolom/tabel baru yang kompatibel ke belakang.
- Deploy Green sehingga bisa bekerja dengan skema lama dan baru.
- Contract: hapus field lama hanya setelah Blue tidak lagi dipakai dan Anda yakin kode baru stabil.
Ini menghindari situasi "Green bekerja, Blue rusak" saat pengalihan.
4) Hangatkan cache dan tangani background job
Sebelum mengalihkan lalu lintas, hangatkan cache kritis (halaman utama, query umum) agar pengguna tidak membayar biaya "cold start."
Untuk background job/cron worker, putuskan siapa yang menjalankan:
- jalankan job hanya di satu lingkungan selama cutover untuk menghindari pemrosesan ganda
5) Alihkan lalu lintas, lalu amati
Balik routing dari Blue ke Green (load balancer/DNS/ingress). Pantau error rate, latency, dan metrik bisnis selama jendela singkat.
6) Verifikasi pasca-switch dan pembersihan
Lakukan spot check ala pengguna nyata, lalu biarkan Blue tersedia sebentar sebagai fallback. Setelah stabil, nonaktifkan job di Blue, arsipkan log, dan deprovisi Blue untuk mengurangi biaya dan kebingungan.
Canary Rollout: Buku Panduan Praktis
Canary rollout soal belajar dengan aman. Alih-alih mengirim semua pengguna sekaligus, Anda mengekspos sebagian kecil lalu lintas nyata, mengamati secara dekat, dan baru kemudian memperluas. Tujuannya bukan "bergerak lambat"—melainkan "membuktikan aman" dengan bukti di setiap langkah.
Rencana ramp sederhana (1–5% → 25% → 50% → 100%)
- Persiapkan canary
Deploy versi baru berdampingan dengan versi stabil saat ini. Pastikan Anda bisa merutekan persentase lalu lintas tertentu ke masing-masing, dan bahwa kedua versi terlihat di monitoring (dasbor terpisah atau tag membantu).
- Tahap 1: 1–5%
Mulai sangat kecil. Di tahap ini masalah jelas muncul: endpoint rusak, konfigurasi hilang, kejutan migrasi DB, atau lonjakan latency tak terduga.
Catat untuk tahap ini:
- apa yang berubah di rilis ini (termasuk perubahan konfigurasi kecil)
- apa yang Anda harapkan terjadi
- apa yang diamati (error, latency, dampak pengguna)
- Tahap 2: 25%
Jika tahap pertama bersih, tingkatkan ke sekitar seperempat lalu lintas. Anda akan melihat variasi dunia nyata lebih banyak: perilaku pengguna berbeda, perangkat langka, kasus tepi, dan konkruensi yang lebih tinggi.
- Tahap 3: 50%
Setengah lalu lintas adalah tempat masalah kapasitas dan performa menjadi lebih jelas. Jika Anda akan mencapai batas skala, seringkali tanda awalnya muncul di sini.
- Tahap 4: 100% (promosi)
Saat metrik stabil dan dampak pengguna dapat diterima, pindahkan semua lalu lintas ke versi baru dan nyatakan dipromosikan.
Memilih interval ramp (berapa lama menunggu tiap tahap)
Waktu ramp tergantung pada risiko dan volume lalu lintas:
- Perubahan berisiko tinggi atau trafik rendah: tunggu lebih lama tiap tahap untuk mendapatkan sinyal yang cukup (mis. 30–60 menit, kadang lebih). Layanan dengan trafik rendah mungkin butuh jam untuk melihat pola bermakna.
- Perubahan risiko rendah dengan trafik tinggi: tahap lebih singkat bisa bekerja (mis. 5–15 menit), karena Anda cepat mengumpulkan data.
Pertimbangkan juga siklus bisnis. Jika produk Anda punya lonjakan (mis. jam makan siang, akhir pekan, jadwal penagihan), jalankan canary cukup lama untuk mencakup kondisi yang biasanya menyebabkan masalah.
Otomatiskan promosi dan rollback
Rollout manual menciptakan keraguan dan inkonsistensi. Jika memungkinkan, otomatiskan:
- promosi ketika metrik kunci tetap dalam ambang untuk jangka waktu yang ditentukan
- rollback ketika ambang dilanggar (mis. error rate atau latency melewati batas)
Otomatisasi tidak menghilangkan penilaian manusia — ia menghilangkan delay.
Perlakukan tiap tahap seperti eksperimen
Untuk setiap langkah ramp, tulis:
- ringkasan perubahan (apa yang persis berbeda)
- kriteria keberhasilan (metrik mana yang harus tetap stabil)
- hasil yang diamati (apa yang Anda lihat, termasuk “tidak ada yang aneh”)
- keputusan (promosikan, tahan, atau rollback) dan alasannya
Catatan ini mengubah riwayat rollout Anda menjadi playbook untuk rilis berikutnya — dan membuat insiden mendatang lebih mudah didiagnosis.
Rencana Rollback dan Penanganan Kegagalan
Rollback paling mudah ketika Anda memutuskan sebelumnya apa itu “buruk” dan siapa yang boleh menekan tombol. Rencana rollback bukan pesimisme — melainkan cara menjaga masalah kecil tidak menjadi gangguan berkepanjangan.
Definisikan pemicu rollback yang jelas
Pilih daftar singkat sinyal dan tetapkan ambang eksplisit agar tidak ada perdebatan saat insiden. Pemicu umum meliputi:
- tingkat error: lonjakan 5xx, checkout gagal, kegagalan login, atau timeout API
- latency: p95/p99 di atas batas yang disepakati selama jangka waktu tertentu (mis. 5–10 menit)
- KPI bisnis: penurunan konversi mendadak, kegagalan pembayaran, penurunan pendaftaran, atau peningkatan pembatalan
Buat pemicu yang terukur ("p95 > 800ms selama 10 menit") dan kaitkan ke pemilik (on-call, release manager) yang berwenang bertindak segera.
Buat rollback cepat (dan membosankan)
Kecepatan lebih penting daripada keanggunan. Rollback Anda harus berupa salah satu:
- balikkan pergeseran lalu lintas (umum untuk blue/green dan canary): kembalikan lalu lintas ke versi stabil sebelumnya
- redeploy versi sebelumnya: jika infrastruktur berubah, dorong build stabil terakhir dan jalankan health check
Hindari “perbaiki manual lalu lanjutkan rollout” sebagai langkah pertama. Stabilisasi dulu, investigasi kemudian.
Rencanakan partial rollout
Dengan canary, beberapa pengguna mungkin membuat data di bawah versi baru. Putuskan sebelumnya:
- Apakah pengguna “canary” langsung diarahkan balik, atau dibiarkan di canary sementara Anda menilai?
- Jika format data berubah, apakah database kompatibel ke belakang? Jika tidak, rollback mungkin memerlukan mitigasi terpisah.
Tinjauan pasca-kejadian yang memperbaiki rilis berikutnya
Setelah stabil, tulis catatan singkat pasca-kejadian: apa yang memicu rollback, sinyal apa yang hilang, dan apa yang akan diubah di checklist. Perlakukan ini sebagai siklus perbaikan produk untuk proses rilis Anda, bukan latihan menyalahkan.
Feature Flags dan Pengiriman Progresif
Bawa Ide Uji Coba ke Mobile
Buat aplikasi mobile Flutter dan lakukan iterasi dengan aman saat meluncurkan perubahan.
Feature flags memungkinkan Anda memisahkan “deploy” (mengirim kode ke produksi) dari “release” (mengaktifkannya untuk orang). Itu penting karena Anda bisa memakai pipeline deployment yang sama — blue/green atau canary — sambil mengontrol eksposur dengan sakelar sederhana.
Deploy tanpa tekanan, rilis dengan maksud
Dengan flag, Anda bisa merge dan deploy dengan aman meskipun fitur belum siap untuk semua orang. Kode ada tetapi dorman. Ketika yakin, Anda mengaktifkan flag secara bertahap — seringkali lebih cepat daripada mendorong build baru — dan jika terjadi masalah, Anda bisa menonaktifkannya sama cepatnya.
Enable terarah (bukan semua-atau-tidak sama sekali)
Pengiriman progresif soal meningkatkan akses dalam langkah yang disengaja. Flag bisa diaktifkan untuk:
- grup pengguna tertentu (staf internal, pengguna beta, tier berbayar)
- wilayah (mulai dari satu negara atau data center)
- persentase pengguna (1% → 10% → 50% → 100%)
Ini sangat membantu ketika canary menunjukkan versi baru sehat, tetapi Anda masih ingin mengelola risiko fitur secara terpisah.
Guardrail agar tidak menumpuk “flag debt”
Feature flags kuat, tapi hanya jika diatur. Beberapa guardrail menjaga agar rapi dan aman:
- kepemilikan: setiap flag punya tim atau orang yang bertanggung jawab
- kedaluwarsa: tentukan tanggal penghapusan (atau tanggal review) supaya flag lama tidak menumpuk
- dokumentasi: tulis apa yang dilakukan flag, siapa yang terpengaruh, dan bagaimana rollback
Aturan praktis: jika seseorang tidak bisa menjawab "apa yang terjadi saat kita mematikannya?" maka flag itu belum siap.
Untuk panduan lebih mendalam tentang penggunaan flag sebagai bagian dari strategi rilis, lihat /blog/feature-flags-release-strategy.
Cara Memilih Strategi dan Memulai
Memilih antara blue/green dan canary bukan soal "mana yang lebih baik." Ini soal jenis risiko yang ingin Anda kendalikan, dan apa yang realistis dijalankan oleh tim dan tooling Anda saat ini.
Cara cepat memutuskan
Jika prioritas utama Anda adalah cutover yang bersih dan tombol “kembali ke versi lama” yang mudah, blue/green biasanya paling sederhana.
Jika prioritas utama Anda adalah mengurangi blast radius dan belajar dari lalu lintas nyata sebelum memperluas, canary adalah pilihan yang lebih aman — terutama ketika perubahan sering atau sulit diuji sepenuhnya sebelumnya.
Aturan praktis: pilih pendekatan yang bisa tim Anda jalankan konsisten pada jam 2 pagi ketika ada masalah.
Mulai kecil: pilot satu hal
Pilih satu layanan (atau satu alur pengguna) dan jalankan pilot beberapa rilis. Pilih sesuatu yang cukup penting untuk berarti, tetapi tidak terlalu kritis sehingga semua orang membeku. Tujuannya membangun kebiasaan tentang pergeseran lalu lintas, monitoring, dan rollback.
Tulis runbook sederhana (dan tetapkan kepemilikan)
Singkat saja—satu halaman cukup:
- apa arti “baik” (metrik kunci dan ambang)
- siapa yang bertanggung jawab selama rollout
- bagaimana cara pause, rollback, dan berkomunikasi
Pastikan kepemilikan jelas. Strategi tanpa pemilik jadi sekadar saran.
Gunakan apa yang sudah Anda miliki terlebih dahulu
Sebelum menambahkan platform baru, lihat alat yang sudah Anda andalkan: pengaturan load balancer, skrip deployment, monitoring yang ada, dan proses insiden. Tambah tooling baru hanya ketika itu menghilangkan hambatan nyata yang Anda rasakan saat pilot.
Jika Anda membangun dan mengirim layanan baru cepat, platform yang menggabungkan pembuatan aplikasi dengan kontrol deployment bisa mengurangi beban operasional. Misalnya, Koder.ai adalah platform vibe-coding yang memungkinkan tim membuat aplikasi web, backend, dan mobile dari antarmuka chat—dan kemudian men-deploy serta meng-host dengan fitur keselamatan praktis seperti snapshots dan rollback, plus dukungan untuk domain kustom dan ekspor kode sumber. Kapabilitas tersebut sesuai dengan tujuan inti artikel ini: membuat rilis dapat diulang, dapat diamati, dan dapat dibalik.
Langkah berikutnya yang disarankan
Jika ingin melihat opsi implementasi dan alur kerja yang didukung, tinjau /pricing dan /docs/deployments. Lalu jadwalkan pilot rilis pertama Anda, catat apa yang berhasil, dan iterasi runbook setelah setiap rollout.