Joe Armstrong dan Erlang: Biarkan Gagal untuk Platform yang Andal
Jelajahi bagaimana Joe Armstrong membentuk konkurensi Erlang, supervisi, dan pola “let it crash”—ide-ide yang masih dipakai untuk membangun layanan real-time andal.
Apa yang Dibahas Postingan Ini (dan Mengapa Masih Penting)
Joe Armstrong bukan hanya salah satu pencipta Erlang—ia juga penjelas paling jelas dan persuasifnya. Lewat ceramah, makalah, dan pendekatan pragmatis, ia memopulerkan ide sederhana: jika Anda ingin perangkat lunak yang tetap berjalan, rancang untuk kegagalan daripada pura‑pura bisa menghindarinya.
Tulisan ini adalah tur berpemandu tentang pola pikir Erlang dan mengapa itu masih relevan saat Anda membangun platform real-time yang andal—seperti sistem chat, routing panggilan, notifikasi langsung, koordinasi multiplayer, dan infrastruktur yang harus merespons cepat dan konsisten meski sebagian komponennya bermasalah.
“Real-time” dalam istilah sederhana
Real-time tidak selalu berarti “mikrodetik” atau “batas waktu keras.” Dalam banyak produk itu berarti:
- respons cepat yang terasa oleh pengguna (tanpa jeda misterius)
- perilaku yang dapat diprediksi saat beban meningkat (mungkin melambat, tapi tidak berputar-putar)
- layanan terus berjalan selama kegagalan parsial (komponen buruk tidak menjatuhkan semuanya)
Erlang dibangun untuk sistem telekomunikasi di mana ekspektasi ini tak bisa dinegosiasikan—dan tekanan itu membentuk gagasan‑gagasan paling berpengaruhnya.
Tiga pilar yang akan kita fokuskan
Daripada masuk ke sintaks, kita akan fokus pada konsep yang membuat Erlang terkenal dan terus muncul ulang dalam desain sistem modern:
- Konkurensi sebagai default: bangun perangkat lunak dari banyak pekerja kecil yang terisolasi daripada beberapa pekerja besar.
- Toleransi kesalahan sebagai tujuan desain: anggap bug, timeout, dan crash akan terjadi—dan rencanakan langkah selanjutnya.
- “Let it crash”: jangan berusaha terlalu keras mempertahankan setiap baris kode; biarkan gagal cepat dan pulihkan dengan rapi menggunakan struktur (bukan tindakan heroik).
Sepanjang jalan, kita akan mengaitkan ide‑ide ini dengan model aktor dan message passing, menjelaskan pohon supervisi dan OTP secara mudah dipahami, dan menunjukkan mengapa BEAM VM membuat pendekatan ini praktis.
Bahkan jika Anda tidak menggunakan Erlang (dan takkan pernah), intinya tetap: framing Armstrong memberi Anda checklist kuat untuk membangun sistem yang tetap responsif dan tersedia saat kenyataan menjadi berantakan.
Motivasi Joe Armstrong: Membangun Sistem yang Tetap Jalan
Switch telekom dan platform routing panggilan tidak bisa “mati untuk pemeliharaan” sebagaimana banyak situs web. Mereka diharapkan terus menangani panggilan, event penagihan, dan trafik signaling sepanjang waktu—sering dengan persyaratan ketersediaan dan waktu respons yang ketat.
Erlang lahir di dalam Ericsson akhir 1980‑an sebagai upaya memenuhi realitas itu dengan perangkat lunak, bukan hanya hardware khusus. Joe Armstrong dan rekan‑rekannya bukan mengejar keanggunan demi keanggunan; mereka mencoba membangun sistem yang dapat dipercaya operator di bawah beban konstan, kegagalan parsial, dan kondisi dunia nyata yang berantakan.
Apa arti “andal” dalam praktik
Perubahan pola pikir kunci adalah bahwa reliabilitas bukanlah sama dengan “tidak pernah gagal.” Dalam sistem besar yang berjalan lama, sesuatu akan gagal: sebuah proses akan menerima input tak terduga, sebuah node akan reboot, link jaringan akan flapping, atau dependensi akan macet.
Jadi tujuannya menjadi:
- terus melayani pengguna meski sebagian komponen bermasalah
- mendeteksi kegagalan dengan cepat
- pulih otomatis dengan intervensi manusia minimal
- mengisolasi bug supaya satu kesalahan tidak menjatuhkan semuanya
Inilah mindset yang kemudian membuat ide seperti pohon supervisi dan “let it crash” terasa masuk akal: Anda merancang kegagalan sebagai kejadian normal, bukan bencana istimewa.
Kurangi mitos, tambahkan pemecahan masalah
Mudah saja menceritakan kisah sebagai terobosan satu visioner. Sudut pandang yang lebih berguna lebih sederhana: keterbatasan telekom memaksa trade‑off berbeda. Erlang memprioritaskan konkurensi, isolasi, dan pemulihan karena itu alat praktis yang diperlukan untuk menjaga layanan tetap berjalan sementara dunia terus berubah di sekitarnya.
Pendekatan berfokus‑masalah ini juga alasan kenapa pelajaran Erlang masih terjemah dengan baik hari ini—di mana uptime dan pemulihan cepat lebih penting daripada pencegahan sempurna.
Konkurensi sebagai Default: Banyak Pekerja Kecil
Ide inti Erlang adalah bahwa “melakukan banyak hal sekaligus” bukan fitur khusus yang ditambahkan kemudian—itu cara normal Anda menyusun sistem.
Proses ringan, dijelaskan sederhana
Di Erlang, pekerjaan dibagi menjadi banyak “proses” kecil. Pikirkan mereka sebagai pekerja kecil, masing‑masing bertanggung jawab pada satu tugas: menangani panggilan telepon, melacak sesi chat, memantau perangkat, mencoba ulang pembayaran, atau mengawasi antrean.
Mereka ringan, artinya Anda bisa memiliki jumlah besar tanpa perlu hardware besar. Alih‑alih satu pekerja berat mencoba menangani semuanya, Anda punya kerumunan pekerja fokus yang bisa mulai cepat, berhenti cepat, dan diganti cepat.
Mengapa “satu program besar” gagal dengan cara berbeda
Banyak sistem dirancang seperti satu program besar dengan banyak bagian yang saling terkait erat. Saat sistem seperti itu terkena bug serius, masalah memori, atau operasi blocking, kegagalan bisa merambat—seperti memutus satu pemutus dan memadamkan seluruh gedung.
Erlang mendorong kebalikan: isolasi tanggung jawab. Jika satu pekerja kecil bermasalah, Anda bisa menghentikan dan mengganti pekerja itu tanpa menjatuhkan pekerjaan lain yang tak terkait.
Message passing seperti “mengirim catatan”
Bagaimana para pekerja ini berkoordinasi? Mereka tidak mengubah state internal satu sama lain. Mereka mengirim pesan—lebih mirip mengirim catatan daripada berbagi papan tulis yang berantakan.
Satu pekerja bisa berkata, “Ada permintaan baru,” “Pengguna ini terputus,” atau “Coba lagi dalam 5 detik.” Penerima membaca catatan itu dan memutuskan apa yang harus dilakukan.
Manfaat utamanya adalah penahanan: karena pekerja terisolasi dan berkomunikasi lewat pesan, kegagalan kecil cenderung tak menyebar ke seluruh sistem.
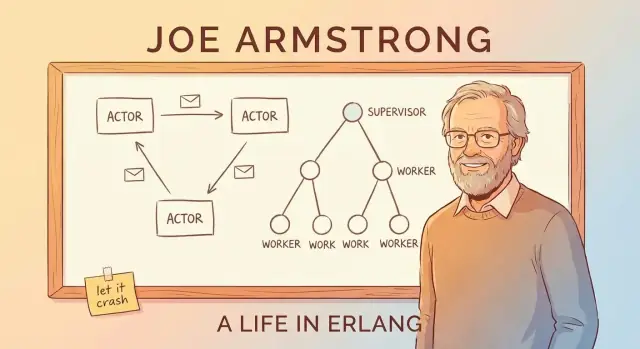
Message Passing dan Model Aktor (Tanpa Jargon)
Cara sederhana memahami "model aktor" Erlang adalah membayangkan sistem yang tersusun dari banyak pekerja kecil, independen.
Aktor: pekerja kecil yang hanya berbicara lewat pesan
Sebuah aktor adalah unit tertutup dengan state privat dan sebuah mailbox. Ia melakukan tiga hal dasar:
- menerima pesan (satu per satu) dari mailbox
- memperbarui state internalnya
- mengirim pesan ke aktor lain
Cukup itu. Tidak ada variabel bersama tersembunyi, tidak ada “mengutak‑atik memori pekerja lain.” Jika satu aktor butuh sesuatu dari lainnya, ia meminta dengan mengirim pesan.
Menghindari shared state menghilangkan banyak kelas bug
Saat multiple thread berbagi data yang sama, Anda bisa mendapat race condition: dua kejadian mengubah nilai yang sama hampir bersamaan, dan hasil bergantung pada timing. Itulah bug yang bersifat intermiten dan sulit direproduksi.
Dengan message passing, setiap aktor memiliki data sendiri. Aktor lain tidak bisa memutasi langsung. Ini tidak menghilangkan semua bug, tetapi secara dramatis mengurangi masalah yang disebabkan oleh akses simultan ke data yang sama.
Back-pressure, dijelaskan seperti antrean di kedai kopi
Pesan tidak datang “gratis.” Jika sebuah aktor menerima pesan lebih cepat daripada yang bisa diproses, mail‑box‑nya (antrian) akan tumbuh. Itu back‑pressure: sistem memberi tahu, secara tidak langsung, “bagian ini kewalahan.”
Dalam praktiknya, Anda memantau ukuran mailbox dan menetapkan batas: menurunkan beban, membatch, sampling, atau menyebarkan pekerjaan ke lebih banyak aktor alih‑alih membiarkan antrean membesar selamanya.
Contoh konkret: notifikasi chat
Bayangkan sebuah aplikasi chat. Setiap pengguna bisa punya aktor yang bertugas mengirim notifikasi. Ketika pengguna offline, pesan terus datang—jadi mailbox tumbuh. Sistem yang baik mungkin membatasi antrean, menjatuhkan notifikasi non‑kritis, atau beralih ke mode digest, daripada membiarkan satu pengguna lambat menurunkan layanan seluruh sistem.
“Let It Crash” Dijelaskan: Gagal Cepat, Pulih Lebih Cepat
“Let it crash” bukan slogan untuk engineering ceroboh. Ini strategi reliabilitas: ketika sebuah komponen memasuki keadaan buruk atau tak terduga, ia harus berhenti cepat dan jelas daripada berjalan pincang.
Apa arti sebenarnya
Daripada menulis kode yang mencoba menangani semua edge case di dalam satu proses, Erlang mendorong menjaga setiap pekerja kecil dan fokus. Jika pekerja itu terkena sesuatu yang benar‑benar tidak bisa ditangani (state korup, asumsi dilanggar, input tak terduga), ia keluar. Bagian lain sistem bertanggung jawab menghidupkannya kembali.
Ini menggeser pertanyaan utama dari “Bagaimana kita mencegah kegagalan?” ke “Bagaimana kita pulihkan dengan rapi saat kegagalan terjadi?”
Trade‑off: lebih sedikit pemeriksaan defensif, logika lebih jelas
Pemrograman defensif di mana‑mana bisa mengubah alur sederhana menjadi labirin kondisional, retry, dan state parsial. “Let it crash” menukar beberapa kompleksitas in‑process itu untuk:
- jalur kode yang lebih sederhana dan mudah dibaca
- deteksi asumsi rusak lebih cepat
- pemulihan yang konsisten (karena dipusatkan)
Gagasan besarnya: pemulihan harus dapat diprediksi dan dapat diulang, bukan improvisasi di setiap fungsi.
Kapan cocok—dan kapan tidak
Cocok ketika kegagalan bisa dipulihkan dan terisolasi: masalah jaringan sementara, permintaan buruk, pekerja macet, timeout pihak ketiga.
Tidak cocok bila crash dapat menyebabkan kerusakan tak terbalikkan, seperti:
- kehilangan data tanpa sumber kebenaran yang tahan lama
- operasi keselamatan‑kritis di mana “coba lagi” tidak bisa diterima
Restart cepat dan state yang diketahui baik
Crashing hanya membantu jika kembali dengan cepat dan aman. Itu berarti me‑restart pekerja ke state yang diketahui baik—sering kali dengan memuat ulang konfigurasi, membangun kembali cache in‑memory dari penyimpanan tahan lama, dan meneruskan kerja tanpa berpura‑pura state rusak tak pernah ada.
Supervision Trees: Merancang untuk Kegagalan dengan Sadar
Ide “let it crash” hanya bekerja karena crash tidak dibiarkan begitu saja. Pola kunci adalah pohon supervisi: hirarki di mana supervisor bertindak seperti manajer dan worker melakukan pekerjaan nyata (menangani panggilan, mengawasi sesi, mengonsumsi antrean, dll.). Ketika worker bermasalah, manajer melihat dan me‑restart‑nya.
Manajer yang me‑restart worker
Supervisor tidak mencoba “memperbaiki” worker yang rusak di tempat. Sebaliknya, ia menerapkan aturan sederhana dan konsisten: jika worker mati, jalankan yang baru. Itu membuat jalur pemulihan dapat diprediksi dan mengurangi kebutuhan error handling ad‑hoc yang tersebar di kode.
Sama pentingnya, supervisor bisa memutuskan kapan tidak me‑restart—jika sesuatu terus‑menerus crash, itu indikasi masalah lebih dalam, dan restart berulang bisa memperburuk keadaan.
Strategi restart (tingkat tinggi)
Supervisi bukan satu ukuran cocok untuk semua. Strategi umum meliputi:
- One‑for‑one: hanya worker yang gagal yang di‑restart. Cocok untuk tugas independen.
- Group restarts: jika satu worker gagal, sekumpulan terkait di‑restart bersama. Cocok untuk komponen yang harus sinkron.
Ketergantungan: bagian yang perlu dipikirkan
Desain supervisi yang baik dimulai dari peta ketergantungan: komponen mana bergantung ke mana, dan apa arti “fresh start” untuk mereka.
Jika handler sesi bergantung pada proses cache, me‑restart hanya handler mungkin meninggalkannya terhubung ke state buruk. Mengelompokkan mereka di bawah supervisor yang tepat (atau me‑restart bersama) mengubah mode kegagalan yang berantakan menjadi perilaku pemulihan yang konsisten dan dapat diulang.
OTP: Komponen Ulang Pakai untuk Layanan Andal
Jika Erlang adalah bahasa, OTP (Open Telecom Platform) adalah kotak bagian yang mengubah “let it crash” menjadi sesuatu yang bisa dijalankan di produksi selama bertahun‑tahun.
OTP sebagai kotak alat pola teruji
OTP bukan sekadar library—itu kumpulan konvensi dan komponen siap‑pakai (disebut behaviours) yang menyelesaikan bagian membosankan tapi penting dari membangun layanan:
gen_serveruntuk worker berumur panjang yang menyimpan state dan menangani permintaan satu per satusupervisoruntuk otomatis me‑restart worker yang gagal menurut aturan jelasapplicationuntuk mendefinisikan bagaimana satu layanan dimulai, dihentikan, dan masuk ke rilis
Mereka bukan “sihir.” Mereka template dengan callback terdefinisi, sehingga kode Anda menyatu ke bentuk yang dikenal alih‑alih menciptakan bentuk baru tiap proyek.
Kenapa pola standar mengalahkan framework custom
Tim sering membuat worker background ad‑hoc, hook monitoring rumahan, dan logika restart satu kali. Itu berhasil—sampai tidak. OTP mengurangi risiko itu dengan mendorong semua orang ke kosakata dan lifecycle yang sama. Ketika engineer baru bergabung, mereka tak perlu mempelajari framework custom terlebih dahulu; mereka mengandalkan pola yang umum dipahami di ekosistem Erlang.
Bagaimana OTP membimbing arsitektur sehari‑hari
OTP mendorong Anda berpikir dalam peran proses dan tanggung jawab: apa itu worker, apa itu koordinator, apa yang harus me‑restart apa, dan apa yang tak boleh di‑restart otomatis.
Ia juga mendorong kebersihan operasional: penamaan jelas, urutan startup eksplisit, shutdown yang dapat diprediksi, dan sinyal monitoring bawaan. Hasilnya adalah perangkat lunak yang didesain untuk berjalan terus—layanan yang bisa pulih dari kesalahan, berevolusi seiring waktu, dan tetap melakukan pekerjaan tanpa pengasuhan manusia terus‑menerus.
BEAM VM: Runtime yang Membuat Model Praktis
Ide besar Erlang—proses kecil, message passing, dan “let it crash”—akan jauh lebih sulit digunakan di produksi tanpa BEAM (virtual machine). BEAM adalah runtime yang membuat pola‑pola ini terasa alami, bukan rapuh.
Penjadwalan: keadilan daripada “satu thread besar”
BEAM dirancang untuk menjalankan banyak proses ringan. Alih‑alih mengandalkan beberapa thread OS dan berharap aplikasi berperilaku, BEAM mengatur penjadwalan proses Erlang sendiri.
Manfaat praktisnya adalah responsivitas saat beban: pekerjaan diiris menjadi potongan kecil dan diputar secara adil, sehingga tak ada pekerja sibuk yang mendominasi sistem terlalu lama. Itu cocok sekali dengan layanan yang tersusun dari banyak tugas independen—masing‑masing melakukan sedikit kerja, kemudian memberi kesempatan.
Isolasi dan pembersihan memori per‑proses
Setiap proses Erlang memiliki heap sendiri dan garbage collection sendiri. Ini detail kunci: membersihkan memori di satu proses tidak memerlukan jeda seluruh program.
Selain itu, proses terisolasi. Jika satu crash, ia tidak merusak memori proses lain, dan VM tetap hidup. Isolasi ini adalah fondasi yang membuat pohon supervisi realistis: kegagalan dikandung, lalu ditangani dengan me‑restart bagian yang gagal alih‑alih merobohkan semuanya.
Distribusi: banyak node, satu sistem
BEAM juga mendukung distribusi dengan cara yang sederhana: Anda bisa menjalankan banyak node Erlang (instance VM terpisah) dan membiarkan mereka berkomunikasi lewat pesan. Jika Anda memahami “proses saling bicara lewat pesan,” distribusi adalah perpanjangan dari ide yang sama—beberapa proses kebetulan hidup di node lain.
BEAM bukan janji kecepatan mentah. Ia membuat konkurensi, isolasi kegagalan, dan pemulihan menjadi default, sehingga cerita reliabilitasnya praktis bukan teoretis.
Upgrade Tanpa Menghentikan Sistem (Hot Code, dengan Hati‑Hati)
Salah satu trik Erlang yang sering dibicarakan adalah hot code swapping: memperbarui bagian sistem yang sedang berjalan dengan downtime minimal (dengan dukungan runtime dan tooling). Janji praktisnya bukan “tak perlu restart lagi,” melainkan “kirim perbaikan tanpa mengubah bug kecil menjadi outage panjang.”
Apa arti “hot code” sebenarnya
Di Erlang/OTP, runtime dapat memuat dua versi modul secara bersamaan. Proses yang sudah ada bisa menyelesaikan kerja menggunakan versi lama sementara panggilan baru bisa memakai versi baru. Itu memberi ruang untuk menambal bug, meluncurkan fitur, atau menyesuaikan perilaku tanpa mengusir semua orang dari sistem.
Jika dilakukan dengan baik, ini mendukung tujuan reliabilitas langsung: lebih sedikit restart penuh, jendela maintenance lebih pendek, dan pemulihan lebih cepat saat sesuatu kebobolan ke produksi.
Batasan yang perlu diperhatikan
Tidak semua perubahan aman disisipkan hidup‑hidup. Contoh perubahan yang butuh kehati‑hatian ekstra (atau restart):
- perubahan bentuk state (proses mengharapkan format data lama, kode baru mengharapkan yang lain)
- perubahan protokol atau format pesan yang harus cocok antar layanan
- migrasi skema yang memakan waktu atau butuh koordinasi
Erlang menyediakan mekanisme untuk transisi terkontrol, tapi Anda tetap harus merancang jalur upgrade.
Mindset: upgrade dan rollback adalah normal
Hot upgrade bekerja terbaik bila upgrade dan rollback diperlakukan sebagai operasi rutin, bukan darurat langka. Itu berarti merencanakan versioning, kompatibilitas, dan jalur “undo” sejak awal. Praktiknya, tim memadukan teknik live‑upgrade dengan rollout bertahap, health check, dan pemulihan berbasis supervisi.
Bahkan jika Anda tidak memakai Erlang, pelajaran yang bisa dibawa pulang: desain sistem sehingga mengubahnya dengan aman adalah kebutuhan utama, bukan pemikiran belakangan.
Di Mana Ide‑Ide Erlang Bersinar di Platform Real‑Time
Platform real‑time kurang soal timing sempurna dan lebih soal tetap responsif saat segala hal terus‑menerus rusak: jaringan goyah, dependensi melambat, dan lonjakan trafik. Desain Erlang—yang dipopulerkan Joe Armstrong—cocok karena menganggap kegagalan dan memperlakukan konkurensi sebagai normal, bukan luar biasa.
Kasus penggunaan real‑time umum
Anda melihat pemikiran bergaya Erlang bersinar di mana ada banyak aktivitas independen terjadi bersamaan:
- Messaging dan chat: jutaan percakapan kecil, masing‑masing dengan state dan retry sendiri.
- Komunikasi real‑time: signaling voice/video, update presence, dan koordinasi sesi.
- Koordinasi IoT: armada perangkat yang check‑in, hilang, dan muncul kembali tak terduga.
- Alur kerja pembayaran: proses multi‑langkah di mana beberapa langkah lambat, tidak tersedia, atau butuh aksi kompensasi.
Apa arti “soft real‑time” biasanya
Kebanyakan produk tidak butuh jaminan keras seperti “setiap aksi selesai dalam 10 ms.” Mereka butuh soft real‑time: latensi rendah yang konsisten untuk permintaan tipikal, pemulihan cepat saat bagian gagal, dan ketersediaan tinggi supaya pengguna jarang merasakan insiden.
Kegagalan itu normal: rancang untuk itu
Sistem nyata menemui masalah seperti:
- Koneksi terputus (jaringan mobile, handoff Wi‑Fi)
- Timeout saat layanan downstream melambat
- Outage parsial di satu wilayah atau dependensi menurun
Model Erlang mendorong mengisolasi tiap aktivitas (sesi pengguna, perangkat, percobaan pembayaran) sehingga kegagalan tak menyebar. Alih‑alih membangun satu komponen raksasa yang “mencoba menangani semua,” tim dapat berpikir dalam unit kecil: setiap worker melakukan satu tugas, bicara lewat pesan, dan jika rusak, di‑restart bersih.
Perpindahan paradigma—dari “mencegah setiap kegagalan” ke “mengandung dan memulihkan kegagalan dengan cepat”—sering membuat platform real‑time terasa stabil di bawah tekanan.
Kesalahpahaman Umum dan Batas Nyata
Reputasi Erlang terkadang terdengar seperti janji: sistem yang tidak pernah turun karena terus me‑restart. Kenyataannya lebih praktis—dan lebih berguna. “Let it crash” adalah alat untuk membangun layanan dapat diandalkan, bukan lisensi mengabaikan masalah berat.
Restart bukan plester luka
Kesalahan umum adalah menganggap supervisi sebagai cara menyembunyikan bug dalam. Jika proses crash segera setelah mulai, supervisor bisa terus me‑restart sampai Anda berujung pada crash loop—membakar CPU, mengisi log, dan mungkin menyebabkan outage yang lebih besar daripada bug awal.
Sistem baik menambahkan backoff, batas intensitas restart, dan perilaku “berhenti dan eskalasi” yang jelas. Restart harus mengembalikan operasi sehat, bukan menyamarkan invariant yang rusak.
State adalah bagian tersulit
Me‑restart proses sering mudah; memulihkan state yang benar sering tidak. Jika state hanya di memori, Anda harus memutuskan apa arti “benar” setelah crash:
- Haruskah Anda membangun ulang dari penyimpanan tahan lama?
- Bisakah Anda replay event dengan aman (idempotensi)?
- Apa yang terjadi pada pekerjaan yang sedang berlangsung atau update setengah jadi?
Toleransi kesalahan tidak menggantikan desain data yang matang. Ia memaksa Anda menjadi eksplisit tentang itu.
Anda tetap butuh observability
Crash hanya berguna jika Anda dapat melihatnya lebih awal dan memahaminya. Itu berarti investasi pada logging, metrik, dan tracing—bukan sekadar “ia restart, jadi baik.” Anda ingin melihat kenaikan tingkat restart, antrean yang membesar, dan dependensi yang melambat sebelum pengguna merasakannya.
Batas operasional nyata ada
Bahkan dengan kekuatan BEAM, sistem bisa gagal dalam cara yang biasa:
- Pertumbuhan memori akibat memory leak, cache, atau heap besar
- Backlog mailbox ketika producer lebih cepat dari consumer (lonjakan latensi dan timeout)
- Kegagalan dependensi (database, API pihak ketiga, DNS) yang restart kode Anda takkan memperbaiki
Model Erlang membantu menahan dan memulihkan kegagalan—tapi ia tidak menghapusnya.
Cara Menerapkan Pelajaran Hari Ini (Bahkan Jika Tidak Menggunakan Erlang)
Hadiah terbesar Erlang bukan sintaks—melainkan seperangkat kebiasaan untuk membangun layanan yang tetap jalan ketika bagian pasti gagal. Anda bisa menerapkan kebiasaan itu di hampir semua stack.
Terjemahkan ide menjadi tindakan konkret
Mulailah dengan membuat batas kegagalan eksplisit. Pecah sistem menjadi komponen yang dapat gagal secara independen, dan pastikan tiap komponen punya kontrak jelas (input, output, dan apa yang dianggap “buruk”).
Lalu otomatisasi pemulihan alih‑alih mencoba mencegah tiap kesalahan:
- Isolasi komponen: jalankan pekerjaan berisiko di proses/container/thread terpisah supaya satu crash tak meracuni semuanya.
- Tetapkan batas: timeouts, retry dengan backoff, circuit breakers, dan bulkheads untuk menghentikan kegagalan beruntun.
- Jadikan pemulihan rutinitas: health checks, auto‑restart, dan default aman supaya sistem kembali ke state yang diketahui baik cepat.
Salah satu cara praktis membuat kebiasaan ini menjadi nyata adalah memasukkannya ke tooling dan lifecycle, bukan sekadar kode. Misalnya, ketika tim menggunakan Koder.ai untuk vibe‑code web, backend, atau mobile via chat, workflow mendorong perencanaan eksplisit (Planning Mode), deployment yang dapat diulang, dan iterasi aman dengan snapshot dan rollback—konsep yang selaras dengan mindset operasional yang dipopulerkan Erlang: anggap perubahan dan kegagalan akan terjadi, dan jadikan pemulihan membosankan.
Titik awal di luar Erlang
Anda dapat meniru pola “supervisi” dengan alat yang mungkin sudah digunakan:
- Supervisor: systemd, Kubernetes Deployments, atau process manager (restart‑on‑failure, readiness probes).
- Isolasi proses: layanan worker terpisah untuk tugas CPU‑heavy atau tidak terpercaya.
- Message passing: antrean/stream (RabbitMQ, SQS, Kafka) untuk mengurai producer dan consumer dan meratakan lonjakan.
Checklist keputusan cepat
Sebelum mengadopsi pola, tentukan apa yang benar‑benar Anda butuhkan:
- Mode kegagalan yang diharapkan: overload, outage parsial, dependensi lambat, input buruk, memory leak.
- Kebutuhan latensi: apakah Anda butuh respons real‑time, atau pemrosesan eventual sudah cukup?
- Tujuan pemulihan: restart cepat, degradasi teratur, atau intervensi manual?
- Keterampilan tim dan tooling: siapa yang memegang on‑call, observability, dan respons insiden?
Jika Anda ingin langkah praktis selanjutnya, lihat panduan lain di /blog, atau jelajahi detail implementasi di /docs (dan rencana di /pricing bila Anda mengevaluasi tooling).
Pertanyaan umum
Mengapa pola pikir Joe Armstrong tentang Erlang masih relevan hari ini?
Erlang memopulerkan pola pemikiran reliabilitas yang praktis: anggap bagian-bagian akan gagal dan rancangkan apa yang terjadi selanjutnya.
Daripada mencoba mencegah setiap kegagalan, pendekatan ini menekankan isolasi kegagalan, deteksi cepat, dan pemulihan otomatis, yang cocok untuk platform real-time seperti chat, routing panggilan, notifikasi, dan layanan koordinator.
Apa arti “real-time” menurut istilah sederhana dalam postingan ini?
Dalam konteks ini, “real-time” biasanya berarti soft real-time:
- respons terasa cepat dan konsisten
- perilaku tetap dapat diprediksi saat beban meningkat
- sistem terus bekerja melalui kegagalan parsial
Ini bukan tentang batas waktu mikrodetik, melainkan menghindari jeda, spiral, dan kegagalan beruntun.
Apa arti “concurrency by default” dalam desain bergaya Erlang?
Concurrency-by-default berarti menyusun sistem sebagai banyak pekerja kecil dan terisolasi daripada beberapa komponen besar dan saling terkait erat.
Setiap pekerja menangani tanggung jawab sempit (sesi, perangkat, panggilan, loop retry), yang mempermudah penskalaan dan isolasi kegagalan.
Apa itu “lightweight processes” di Erlang, dan mengapa itu penting?
Lightweight processes adalah pekerja independen kecil yang dapat Anda buat dalam jumlah besar.
Secara praktis, berguna karena:
- Anda dapat memodelkan satu proses per “entitas” (pengguna/sesi/perangkat)
- kegagalan tetap lokal pada satu pekerja
- me-restart pekerjaan jauh lebih murah dibandingkan mem-boot ulang monolit
Mengapa Erlang memilih message passing daripada shared state?
Message passing adalah koordinasi dengan mengirim pesan daripada berbagi keadaan yang dapat diubah.
Ini membantu mengurangi kelas bug konkurensi (seperti race condition) karena setiap pekerja memiliki data internalnya sendiri; pihak lain hanya bisa meminta perubahan melalui pesan.
Apa itu back-pressure dalam sistem aktor/pesan, dan bagaimana menanganinya?
Back-pressure terjadi ketika pekerja menerima pesan lebih cepat daripada yang bisa diproses, sehingga mailbox-nya membesar.
Cara praktis menanganinya termasuk:
- memantau ukuran mailbox/queue
- menerapkan batas (drop, sampling, atau cap)
- menyebarkan beban ke lebih banyak pekerja
- menurunkan kualitas layanan secara terencana (mis. beralih ke digest untuk notifikasi non-kritis)
Apa arti "let it crash" sebenarnya (dan apa yang bukan artinya)?
“Let it crash” berarti: jika seorang pekerja berada dalam keadaan tidak valid atau tak terduga, ia harus gagal cepat daripada berjalan pincang.
Pemulihan ditangani secara struktural (melalui supervisi), sehingga alur kode lebih sederhana dan pemulihan lebih dapat diprediksi — dengan catatan restart aman dan cepat.
Apa itu supervision trees, dan mengapa mereka penting untuk toleransi kesalahan?
Pohon supervisi adalah hirarki di mana supervisor memantau worker dan me-restart mereka sesuai aturan.
Daripada menyebarkan logika pemulihan ad‑hoc, Anda memusatkannya:
- tentukan apa yang di-restart ketika sesuatu gagal
- cegah crash loop dengan limit/backoff
- restart grup bersamaan jika komponen harus sinkron
Apa itu OTP, dan bagaimana itu membantu membangun layanan yang andal?
OTP adalah sekumpulan pola standar (behaviours) dan konvensi yang membuat sistem Erlang dapat dioperasikan dalam jangka panjang.
Blok bangunan umum termasuk:
gen_serveruntuk worker berumur panjang yang menyimpan state dan menangani request satu per satusupervisoruntuk kebijakan restart otomatisapplicationuntuk mendefinisikan cara service dimulai, dihentikan, dan dimasukkan ke dalam release
Keuntungannya: lifecycle yang dibagi dan dipahami bersama alih-alih framework custom tiap proyek.
Bagaimana saya bisa menerapkan pelajaran Erlang jika tidak menggunakan Erlang?
Anda bisa menerapkan prinsip yang sama di stack lain dengan menjadikan kegagalan dan pemulihan sebagai prioritas:
- isolasi pekerjaan berisiko (proses/servis/container terpisah)
- timeout, retry dengan backoff, circuit breaker, dan bulkhead
- otomatisasi pemulihan (health checks + restart-on-failure)
- gunakan antrean/stream untuk mengurai ketergantungan
Untuk lebih lanjut, postingan ini merujuk ke panduan di /blog dan detail implementasi di /docs.