05 Mei 2025·8 menit
Buat Aplikasi Web untuk Mengelola Timeline Eskalasi Pelanggan
Rencana langkah-demi-langkah membangun aplikasi web yang melacak eskalasi pelanggan, tenggat waktu, SLA, kepemilikan, dan notifikasi—plus pelaporan dan integrasi.
Klarifikasi Masalah Eskalasi dan Kriteria Keberhasilan
Sebelum merancang layar atau memilih stack teknologi, tentukan secara spesifik apa arti “escalation” di organisasi Anda. Apakah itu kasus dukungan yang menua, insiden yang mengancam uptime, keluhan dari akun kunci, atau permintaan yang melewati ambang keparahan tertentu? Jika tim berbeda menggunakan kata itu secara berbeda, aplikasi Anda akan mengenkode kebingungan.
Definisikan eskalasi dengan istilah sederhana
Tulis definisi satu kalimat yang bisa disepakati seluruh tim, lalu tambahkan beberapa contoh. Misalnya: “Eskalasi adalah setiap masalah pelanggan yang membutuhkan tingkat dukungan yang lebih tinggi atau keterlibatan manajemen, dan memiliki komitmen berbatas waktu.”
Juga definisikan apa yang tidak termasuk (mis. tiket rutin, tugas internal) agar v1 tidak membengkak.
Pilih hasil yang dapat Anda ukur
Kriteria keberhasilan harus mencerminkan apa yang ingin Anda tingkatkan—bukan hanya apa yang ingin Anda bangun. Hasil inti yang umum termasuk:
- Lebih sedikit tenggat yang terlewat (pelanggaran SLA)
- Kepemilikan yang jelas pada setiap langkah (siapa yang pegang saat ini)
- Lebih sedikit waktu dihabiskan mengejar pembaruan status
- Pelaporan yang tidak memerlukan spreadsheet manual
Pilih 2–4 metrik yang bisa Anda lacak sejak hari pertama (mis. tingkat pelanggaran, waktu di setiap tahap eskalasi, jumlah penugasan ulang).
Identifikasi pengguna dan pekerjaan yang harus diselesaikan
Daftar pengguna utama (agen, lead tim, manajer) dan pemangku kepentingan sekunder (manajer akun, engineering on-call). Untuk masing-masing, catat apa yang perlu mereka lakukan dengan cepat: mengambil kepemilikan, memperpanjang tenggat dengan alasan, melihat apa selanjutnya, atau merangkum status untuk pelanggan.
Kunci scope v1 dengan contoh nyeri nyata
Tangkap mode kegagalan saat ini dengan cerita konkret: penyerahan yang terlewat antar tier, waktu jatuh tempo yang tidak jelas setelah penugasan ulang, debat “siapa yang menyetujui perpanjangan?”.
Gunakan cerita ini untuk memisahkan kebutuhan mendesak (timeline + kepemilikan + auditabilitas) dari penambahan nanti (dasbor lanjutan, automasi kompleks).
Peta Alur Kerja Eskalasi dan Aturan Timeline
Dengan tujuan yang jelas, tuliskan bagaimana sebuah eskalasi bergerak melalui tim Anda. Alur kerja bersama mencegah “kasus khusus” berubah menjadi penanganan yang tidak konsisten dan SLA yang terlewat.
Definisikan tahap siklus hidup
Mulai dengan set tahap sederhana dan transisi yang diizinkan:
- New → kasus dibuat, belum ada pemilik
- Assigned → pemilik menerima tanggung jawab (orang atau antrian)
- Escalated → dipindah ke tier lebih tinggi, grup spesialis, atau perhatian manajemen
- Resolved → perbaikan/solusi sementara disediakan dan dikonfirmasi (intern atau ke pelanggan)
- Closed → penyelesaian administratif (catatan akhir, tag, penagihan, dll.)
Dokumentasikan apa arti tiap tahap (kriteria masuk) dan apa yang harus benar untuk keluar dari tahap itu (kriteria keluar). Di sinilah Anda menghindari ambiguitas seperti “Resolved tapi masih menunggu pelanggan”.
Spesifikkan pemicu eskalasi
Eskalasi harus dibuat oleh aturan yang bisa Anda jelaskan dalam satu kalimat. Pemicu umum termasuk:
- Perubahan severity (mis. Sev3 → Sev2)
- Risiko SLA (mendekati tenggat respons pertama atau resolusi)
- Flag pelanggan VIP (tingkat akun, klausul kontrak, sponsor eksekutif)
Putuskan apakah pemicu membuat eskalasi secara otomatis, menyarankan kepada agen, atau memerlukan persetujuan.
Daftar timestamp yang diperlukan
Timeline Anda hanya sebaik event yang tercatat. Minimal, tangkap:
- Created time
- First response time
- Each escalation step time (dengan “from/to” tier)
- Resolved time (dan opsional waktu konfirmasi pelanggan)
Aturan kepemilikan dan dependensi
Tulis aturan untuk perubahan kepemilikan: siapa yang bisa menugaskan ulang, kapan diperlukan persetujuan (mis. handoff lintas-tim atau vendor), dan apa yang terjadi jika pemilik pergi di luar shift.
Terakhir, petakan dependensi yang mempengaruhi waktu: jadwal on-call, level tier (T1/T2/T3), dan vendor eksternal (termasuk jendela respons mereka). Ini akan mengarahkan perhitungan timeline dan matriks eskalasi Anda nanti.
Rancang Model Data untuk Timeline, SLA, dan Jejak Audit
Aplikasi eskalasi yang dapat diandalkan sebagian besar adalah masalah data. Jika timeline, SLA, dan riwayat tidak dimodelkan dengan jelas, UI dan notifikasi akan selalu terasa “salah”. Mulailah dengan memberi nama entitas inti dan relasinya.
Entitas kunci (dan apa yang disimpan)
Minimal, rencanakan untuk:
- Customer: detail akun, tier prioritas, kebijakan SLA default, zona waktu.
- Case: subjek, severity, status saat ini, tim pemilik, assignee saat ini, tautan ke customer.
- Escalation: level eskalasi, alasan, waktu trigger, siapa yang menyetujui/memulai, case terkait.
- Milestone: checkpoint bernama (mis. “First response”, “Mitigation plan”, “Exec update”) dengan aturan due.
- Comment: entri diskusi dengan penulis, visibilitas (internal/eksternal), timestamp.
- Attachment: file plus metadata (uploader, ukuran, hash, scope akses).
Model timeline: tanggal jatuh tempo, hitungan mundur, jeda
Perlakukan setiap milestone sebagai timer dengan:
start_at(ketika jam dimulai)due_at(deadline yang dihitung)paused_at/pause_reason(opsional)completed_at(kapan terpenuhi)
Simpan mengapa sebuah tanggal jatuh tempo ada (aturan), bukan hanya timestamp hasilnya. Itu memudahkan penyelesaian sengketa di kemudian hari.
Kalender SLA dan zona waktu
SLA jarang berarti “selalu”. Modelkan sebuah kalender per kebijakan SLA: jam kerja vs 24/7, hari libur, dan jadwal spesifik regional.
Hitung deadline dalam waktu server yang konsisten (UTC), tetapi selalu simpan zona waktu kasus (atau zona waktu pelanggan) sehingga UI dapat menampilkan deadline dengan benar dan pengguna bisa memahaminya.
Riwayat status dan jejak audit
Putuskan lebih awal antara:
- Immutable event log (append-only events seperti
CASE_CREATED,STATUS_CHANGED,MILESTONE_PAUSED), atau - Mutable updates dengan tabel history terpisah.
Untuk kepatuhan dan akuntabilitas, utamakan event log (meskipun Anda juga menyimpan kolom “current state” untuk performa). Setiap perubahan harus mencatat siapa, apa yang berubah, kapan, dan sumber (UI, API, automasi), plus correlation ID untuk menelusuri aksi terkait.
Rencanakan Izin, Peran, dan Akses Data
Izin adalah tempat di mana alat eskalasi mendapat kepercayaan—atau diabaikan dengan spreadsheet samping. Definisikan siapa bisa melakukan apa lebih awal, lalu terapkan secara konsisten di UI, API, dan eksport.
Mulai dengan empat peran praktis
Sederhanakan v1 dengan peran yang cocok dengan cara kerja tim dukungan:
- Agen: membuat dan memperbarui kasus, menambahkan pembaruan yang bisa dilihat pelanggan, menetapkan tindakan berikutnya, dan melihat hanya antrian/akun yang ditugaskan.
- Lead: semua yang agen bisa lakukan, plus menugaskan ulang kasus, menimpa langkah timeline (dengan alasan), dan menyetujui eskalasi.
- Admin: mengelola konfigurasi (aturan SLA, matriks eskalasi, field), pengguna, tim, dan kebijakan izin.
- Viewer: akses baca-saja untuk pemangku kepentingan (mis. produk, ops). Batasi ekspor secara default.
Buat pengecekan peran eksplisit di produk: nonaktifkan kontrol daripada membiarkan pengguna mengklik dan mendapatkan error.
Batasi akses berdasarkan tim, wilayah, dan akun pelanggan
Eskalasi sering melintasi banyak grup (Tier 1, Tier 2, CSM, incident response). Rencanakan dukungan multi-tim dengan mengatur visibilitas menggunakan satu atau lebih dimensi berikut:
- Berbasis tim (siapa yang memiliki antrian)
- Berbasis wilayah (aturan EMEA/APAC, follow-the-sun handoffs)
- Berbasis akun (hanya akun yang ditugaskan, atau akun dalam portofolio)
Default yang baik: pengguna bisa mengakses kasus di mana mereka adalah assignee, watcher, atau anggota tim pemilik—plus akun yang secara eksplisit dibagikan ke peran mereka.
Lindungi field sensitif dengan aturan tingkat-field
Tidak semua data boleh terlihat semua orang. Field sensitif umum termasuk PII pelanggan, detail kontrak, dan catatan internal. Terapkan izin tingkat-field seperti:
- Sembunyikan catatan internal dari viewer dan opsional dari agen yang customer-facing
- Mask PII kecuali pengguna memiliki izin “Sensitive Data”
- Pisahkan input “customer update” vs “internal update” untuk mencegah pembagian tidak sengaja
Autentikasi sekarang, SSO nanti
Untuk v1, email/password dengan dukungan MFA biasanya cukup. Rancang model pengguna agar Anda bisa menambahkan SSO nanti (SAML/OIDC) tanpa menulis ulang izin (mis. simpan peran/tim secara internal, map grup SSO saat login).
Catat event keamanan yang relevan
Anggap perubahan izin sebagai aksi yang harus diaudit. Rekam event seperti pembaruan peran, penugasan ulang tim, unduhan ekspor, dan edit konfigurasi—siapa, kapan, dan apa yang berubah. Ini melindungi Anda selama insiden dan memudahkan review akses.
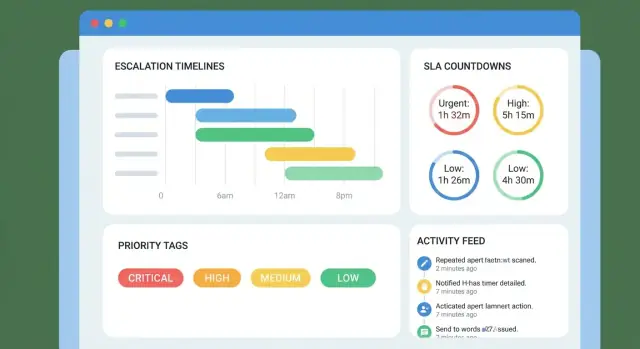
Buat UX Inti: Antrian, Tampilan Kasus, dan Tampilan Timeline
Aplikasi eskalasi Anda berhasil atau gagal di layar sehari-hari: apa yang dilihat lead dukungan pertama kali, seberapa cepat mereka memahami sebuah kasus, dan apakah tenggat berikutnya mudah terlewat.
Layar kunci untuk dirancang dulu
Mulai dengan set halaman kecil yang mencakup 90% pekerjaan:
- Escalation queue (daftar kasus): “workbench” untuk triase dan manajemen harian.
- Detail kasus: satu tempat untuk memahami konteks, pemilik, dan dampak pelanggan.
- Tampilan timeline: milestone, timer SLA, dan apa yang terjadi selanjutnya.
- Laporan: kesehatan SLA dasar dan kasus yang menua (meskipun v1 sederhana).
Jaga navigasi prediktabel: sidebar kiri atau tab atas dengan “Queue”, “My Cases”, “Reports”. Jadikan antrian halaman default.
UX antrian: buat prioritas jelas
Di daftar kasus, tampilkan hanya field yang membantu seseorang memutuskan apa yang harus dilakukan selanjutnya. Baris default yang baik mencakup: customer, prioritas, pemilik saat ini, status, next due date, dan indikator peringatan (mis. “Due in 2h” atau “Overdue by 1d”).
Tambahkan filter cepat dan pencarian praktis:
- Cari berdasarkan nama pelanggan, ID kasus, atau kata kunci
- Filter untuk prioritas, pemilik, status, dan jendela tanggal jatuh tempo (hari ini/minggu ini/terlambat)
Rancang untuk pemindaian: lebar kolom konsisten, chips status jelas, dan satu warna sorot yang digunakan hanya untuk urgensi.
Detail kasus: kurangi pindah konteks
Tampilan kasus harus menjawab, sekilas:
- Apa masalah dan dampak pelanggan?
- Siapa yang memegang langkah berikutnya?
- Apa tenggat berikutnya dan apa yang terjadi jika terlewat?
Tempatkan tindakan cepat dekat bagian atas (jangan disembunyikan di menu): Reassign, Escalate, Add milestone, Add note, Set next deadline. Setiap tindakan harus mengonfirmasi apa yang berubah dan memperbarui timeline segera.
Tampilan timeline: ubah waktu menjadi cerita
Timeline Anda harus terbaca seperti urutan komitmen yang jelas. Sertakan:
- Milestone (dibuat, diakui, melibatkan spesialis, pembaruan ke pelanggan, dll.)
- Timer SLA dengan sisa waktu/status terlambat
- Pemilik langkah berikutnya dan tenggat berikutnya ditampilkan menonjol
Gunakan progressive disclosure: tampilkan event terbaru terlebih dahulu, dengan opsi untuk memperluas riwayat lama. Jika Anda memiliki jejak audit, tautkan dari timeline (mis. “View change log”).
Dasar aksesibilitas yang mencegah kesalahan
Gunakan kontras warna yang dapat dibaca, padukan warna dengan teks (“Overdue”), pastikan semua aksi dapat dijangkau dengan keyboard, dan tulis label yang sesuai bahasa pengguna (“Set next customer update deadline”, bukan “Update SLA”). Ini mengurangi kesalahan klik saat tekanan tinggi.
Bangun Alert, Pengingat, dan Matriks Eskalasi
Lakukan perubahan aman dengan rollback
Gunakan snapshot dan rollback saat aturan garis waktu berubah dan Anda perlu revert yang aman.
Alert adalah “detak jantung” timeline eskalasi: mereka menjaga kasus bergerak tanpa memaksa orang menatap dashboard sepanjang hari. Tujuannya sederhana—memberi tahu orang yang tepat, pada momen yang tepat, dengan kebisingan serendah mungkin.
Definisikan tipe notifikasi (fokus v1)
Mulailah dengan set kecil event yang langsung terkait tindakan:
- Approaching due date (mis. “2 hours left on SLA”) agar seseorang bisa intervensi lebih awal
- Overdue (SLA breached) untuk memicu perilaku eskalasi segera
- Reassignment (kepemilikan berubah) agar pemilik baru dapat mengonfirmasi konteks
- Mentions (mis. @nama dalam catatan internal) untuk mempercepat kolaborasi
Pilih saluran: 1–2 untuk v1
Untuk v1, pilih saluran yang dapat Anda kirimkan dengan andal dan ukur:
- In-app notifications (banner + notification center) biasanya aman sebagai baseline
- Email bekerja baik untuk tim asinkron dan menciptakan jejak dokumen alami
SMS atau alat chat bisa datang nanti setelah aturan dan volume stabil.
Bangun matriks eskalasi dengan ambang yang jelas
Representasikan eskalasi sebagai ambang waktu yang terkait dengan timeline kasus:
- T–2h: beri tahu pemilik kasus (dan opsional lead antrian)
- T–0h: beri tahu pemilik + manajer/on-call
- T+1h: beri tahu manajemen lebih tinggi atau peran eskalasi khusus
Buat matriks dapat dikonfigurasi per prioritas/antrian sehingga “P1 incidents” tidak mengikuti pola yang sama dengan “billing questions.”
Cegah kelelahan notifikasi (batch, dedupe, quiet hours)
Implementasikan deduplication (“jangan kirim notifikasi yang sama dua kali”), batching (ringkasan notifikasi serupa), dan quiet hours yang menunda pengingat non-kritis namun tetap mencatatnya.
Tambahkan acknowledge dan snooze dengan auditabilitas
Setiap alert harus mendukung:
- Acknowledge (siapa/kapan) untuk membuat akuntabilitas
- Snooze (durasi + alasan) dengan batas yang ketat (mis. hanya sebelum breach, max 1–2 kali)
Simpan aksi-aksi ini di jejak audit sehingga pelaporan dapat membedakan “tidak ada yang melihatnya” dari “seseorang melihat dan menunda.”
Integrasikan dengan Alat yang Ada dan Definisikan API
Kebanyakan aplikasi timeline eskalasi gagal ketika mereka meminta orang mengetik ulang data yang sudah ada di tempat lain. Untuk v1, integrasikan hanya yang Anda butuhkan agar timeline akurat dan notifikasi tepat waktu.
Inbound: buat dan perbarui kasus
Putuskan channel mana yang dapat membuat atau memperbarui kasus eskalasi:
- Email: parse mailbox khusus (atau aturan forward) menjadi event “new case”.
- Form web: form intake sederhana untuk Sales/CS log eskalasi.
- Alat ticketing yang ada: ingest pembaruan tiket (status, prioritas, assignee, customer) sehingga timeline eskalasi mencerminkan kenyataan.
Jaga payload inbound kecil: case ID, customer ID, status saat ini, prioritas, timestamp, dan ringkasan singkat.
Outbound: webhooks untuk event kunci
Aplikasi Anda harus memberi tahu sistem lain ketika sesuatu penting terjadi:
- Perubahan status (mis. “Escalated → In Progress → Resolved”)
- Risiko SLA (mis. “breach predicted in 2 hours”)
- Perubahan kepemilikan (handoff ke tim lain)
Gunakan webhooks dengan request yang ditandatangani dan event ID untuk deduplikasi.
Sinkronisasi dua arah: pilih sumber kebenaran
Jika Anda melakukan sinkronisasi dua arah, deklarasikan sumber kebenaran per field (mis. alat ticketing mengontrol status; aplikasi Anda mengontrol timer SLA). Tentukan aturan konflik (“last write wins” jarang benar) dan tambahkan retry logic dengan backoff plus dead-letter queue untuk kegagalan.
Impor akun dan kontak (mapping sederhana)
Untuk v1, impor customer dan kontak menggunakan ID eksternal stabil dan skema minimal: nama akun, tier, kontak kunci, dan preferensi eskalasi. Hindari mirror CRM yang dalam.
Checklist integrasi + kontrak API minimal
Dokumentasikan checklist singkat (metode auth, field wajib, rate limit, retry, environment test). Terbitkan kontrak API minimal (bahkan spes singkat satu halaman) dan versi sehingga integrasi tidak rusak tak terduga.
Implementasikan Backend: Timer, Job, dan Dasar Performa
Berkolaborasi dalam pembangunan
Bagikan proyek Anda dan iterasi bersama lead, agen, dan admin di satu tempat.
Backend Anda perlu melakukan dua hal dengan baik: menjaga waktu eskalasi akurat, dan tetap cepat saat volume kasus tumbuh.
Pilih stack yang tim Anda bisa kirim
Pilih arsitektur paling sederhana yang tim Anda bisa rawat. Aplikasi MVC klasik dengan REST API sering cukup untuk v1 workflow dukungan. Jika Anda sudah memakai GraphQL dengan sukses, itu juga bisa bekerja—tetapi hindari menambahkannya “hanya karena”. Padankan dengan database terkelola (mis. Postgres) agar Anda menghabiskan waktu pada logika eskalasi, bukan operasi DB.
Jika Anda ingin memvalidasi alur kerja end-to-end sebelum komit ke berminggu-minggu engineering, platform vibe-coding seperti Koder.ai dapat membantu Anda mem-prototype loop inti (queue → case detail → timeline → notifications) dari antarmuka chat, lalu iterasi di mode planning dan ekspor kode sumber saat siap. Stack default-nya (React di web, Go + PostgreSQL di backend) cocok secara praktis untuk aplikasi audit-heavy semacam ini.
Background jobs: di sinilah timeline benar-benar terjadi
Eskalasi tergantung pada pekerjaan terjadwal, jadi Anda akan membutuhkan pemrosesan latar belakang untuk:
- Timer yang mengevaluasi due times SLA dan langkah eskalasi berikutnya
- Pengingat (mis. “30 minutes before breach”)
- Eskalasi terjadwal (menugaskan ulang, notifikasi, atau mengubah prioritas)
Implementasikan job yang idempotent (aman dijalankan dua kali) dan retryable. Simpan timestamp “last evaluated at” per case/timeline untuk mencegah aksi ganda.
Tangani waktu dengan benar (atau semuanya rusak)
Simpan semua timestamp di UTC. Konversi ke zona waktu pengguna hanya di batas UI/API. Tambahkan tes untuk kasus tepi: perubahan daylight saving, hari kabisat, dan “paused” clocks (mis. SLA dipause saat menunggu pelanggan).
Dasar performa yang akan Anda syukuri dipasang lebih awal
Gunakan pagination untuk antrian dan tampilan jejak audit. Tambahkan indeks yang cocok dengan filter dan sort Anda—umumnya (due_at), (status), (owner_id), dan komposit seperti (status, due_at).
Attachment: putuskan kebijakan sejak awal
Rencanakan penyimpanan file terpisah dari DB Anda: terapkan batas ukuran/tipe, pindai upload (atau gunakan integrasi provider), dan atur aturan retensi (mis. hapus setelah 12 bulan kecuali legal hold). Simpan metadata di tabel manajemen kasus; file ditempatkan di object storage.
Tambahkan Pelaporan untuk Kesehatan SLA dan Tren Eskalasi
Pelaporan adalah tempat aplikasi eskalasi Anda berhenti menjadi inbox bersama dan menjadi alat manajemen. Untuk v1, targetkan satu halaman pelaporan yang menjawab dua pertanyaan: “Apakah kita memenuhi SLA?” dan “Di mana eskalasi tersendat?” Jaga sederhana, cepat, dan berlandaskan definisi yang disepakati.
Definisikan metrik sebelum membangun chart
Sebuah laporan hanya dapat dipercaya sejauh definisi dasarnya. Tulis ini dalam bahasa sederhana dan petakan ke model data:
- Resolved: kasus ditutup dan tidak lagi dihitung dalam backlog. Putuskan apakah “pending customer confirmation” dihitung resolved atau masih terbuka.
- Breached: deadline SLA lewat saat kasus tidak dipause.
- Paused: waktu berhenti karena alasan yang disetujui (mis. menunggu info pelanggan, ketergantungan pihak ketiga). Definisikan siapa yang bisa pause dan apakah memerlukan catatan.
Juga putuskan clock SLA mana yang dilaporkan: respons pertama, pembaruan berikutnya, atau resolusi (atau ketiganya).
Bangun dua tampilan: dasbor dan tampilan operasional
Dasbor Anda bisa ringan tetapi memberi tindakan:
- Eskalasi berdasarkan status
- Overdue count dan SLA at-risk (akan jatuh tempo)
- Tren backlog dari waktu ke waktu (mis. 7/30 hari terakhir)
Tambahkan tampilan operasional untuk beban kerja harian:
- Antrian per-tim (apa yang perlu diperhatikan sekarang)
- Beban per-pemilik
- Time-to-resolution per-tim/prioritas (median sering lebih jujur daripada rata-rata)
Ekspor dengan aman (dan buktiinya)
Ekspor CSV biasanya cukup untuk v1. Kaitkan ekspor ke izin (akses per-tim, pengecekan peran) dan buat entri audit log untuk setiap ekspor (siapa, kapan, filter yang digunakan, jumlah baris). Ini mencegah “spreadsheet misterius” dan mendukung kepatuhan.
Iterasi dengan umpan balik pemangku kepentingan
Rilis halaman pelaporan pertama dengan cepat, lalu tinjau dengan lead dukungan mingguan selama sebulan. Kumpulkan umpan balik tentang filter yang hilang, definisi yang membingungkan, dan “Saya tidak bisa menjawab X”—itu input terbaik untuk v2.
Uji Aplikasi dengan Skenario Nyata dan Pilot Rollout
Menguji aplikasi timeline eskalasi bukan hanya tentang “apakah ini bekerja?” Tapi tentang “apakah ini berperilaku seperti yang tim dukungan harapkan saat tekanan tinggi?” Fokus pada skenario realistis yang menekan aturan timeline, notifikasi, dan penyerahan kasus.
Unit test: perhitungan timeline yang dapat dipercaya
Taruh sebagian besar usaha tes Anda pada perhitungan timeline, karena kesalahan kecil di sini menghasilkan sengketa SLA besar.
Cakup kasus seperti penghitungan jam kerja, hari libur, dan zona waktu. Tambahkan tes untuk pause (menunggu pelanggan, engineering pending), perubahan prioritas di tengah kasus, dan eskalasi yang menggeser target response/resolve. Juga uji kondisi tepi: kasus dibuat satu menit sebelum tutup jam kerja, atau pause dimulai tepat pada batas SLA.
Integration test: notifikasi dan background job
Notifikasi sering gagal di celah antar sistem. Tulis integration test yang memverifikasi:
- Background job berjalan sesuai jadwal (termasuk retry)
- Alert muncul sekali (tanpa duplikasi) dan berhenti saat kondisi berubah
- Matriks eskalasi mengarahkan ke orang yang tepat saat kepemilikan berubah
Jika Anda menggunakan email, chat, atau webhooks, asser payload dan timing—bukan hanya bahwa “sesuatu dikirim”.
Seed data: buat UX membuktikan dirinya
Buat data sampel realistis yang mengungkap masalah UX sejak awal: pelanggan VIP, kasus jangka panjang, penugasan ulang berulang, insiden yang dibuka kembali, dan periode “panas” dengan spike antrian. Ini membantu memvalidasi bahwa antrian, tampilan kasus, dan timeline terbaca tanpa penjelasan.
Pilot rollout: satu tim, jendela singkat
Jalankan pilot dengan satu tim selama 1–2 minggu. Kumpulkan isu harian: field yang hilang, label membingungkan, kebisingan notifikasi, dan pengecualian pada aturan timeline Anda.
Lacak apa yang pengguna lakukan di luar aplikasi (spreadsheet, saluran samping) untuk menemukan celah.
Definisikan kriteria penerimaan v1
Tulis apa arti “selesai” sebelum peluncuran luas: metrik SLA kunci sesuai hasil yang diharapkan, notifikasi kritis andal, jejak audit lengkap, dan tim pilot dapat menjalankan eskalasi end-to-end tanpa solusi sementara.
Deploy, Monitor, dan Pelihara Sistem
Validasi v1 dengan cepat
Gunakan paket gratis untuk memvalidasi alur eskalasi Anda sebelum menulis spesifikasi.
Mengirim versi pertama bukan garis finish. Aplikasi timeline eskalasi menjadi “nyata” ketika bertahan dari kegagalan sehari-hari: job terlewat, query lambat, notifikasi salah konfigurasi, dan perubahan aturan SLA yang tak terhindarkan. Anggap deployment dan operasi sebagai bagian dari produk.
Checklist deployment praktis
Jaga proses rilis tetap membosankan dan dapat diulang. Minimal, dokumentasikan dan otomatiskan:
- Environment variables: URL database, pengaturan queue/worker, kunci provider email/SMS, secret webhook, kunci enkripsi, dan feature flags.
- Database migrations: jalankan migrasi sebagai langkah penting, dan gagalkan deploy jika tidak apply bersih.
- Backups: tentukan frekuensi dan retensi, dan uji restore ke staging.
- Rollbacks: jelaskan apakah Anda bisa rollback kode saja, atau migrasi memerlukan perbaikan maju (umum saat schema berubah).
Jika ada staging, seed dengan data realistis (disanitasi) agar perilaku timeline dan notifikasi dapat diverifikasi sebelum produksi.
Monitoring yang sesuai mode kegagalan Anda
Pemeriksaan uptime tradisional tidak akan menangkap masalah terburuk. Tambahkan monitoring di tempat eskalasi bisa rusak diam-diam:
- Error tracking untuk web app dan API (exceptions, failed requests).
- Kesehatan job/worker: kedalaman queue, retry job, dead-letter queue, dan alert “job belum berjalan dalam X menit”.
- Dasar performa: query lambat, timeout, dan latensi endpoint untuk case view, queue view, dan rendering timeline.
- Pengiriman notifikasi: email bounce, kegagalan SMS, tingkat 4xx/5xx webhook, dan throttling provider.
Buat playbook on-call kecil: “Jika pengingat eskalasi tidak terkirim, cek A → B → C.” Ini mengurangi downtime saat insiden tekanan tinggi.
Retensi dan penghapusan data
Data eskalasi sering berisi nama pelanggan, email, dan catatan sensitif. Definisikan kebijakan sejak awal:
- Berapa lama menyimpan kasus tertutup, komentar, dan lampiran.
- Apa yang dianonimkan vs dihapus.
- Bagaimana menangani legal hold atau permintaan penghapusan pelanggan.
Buat retensi dapat dikonfigurasi agar Anda tidak perlu perubahan kode untuk pembaruan kebijakan.
Alat admin dasar
Bahkan di v1, admin butuh cara untuk menjaga sistem sehat:
- Manajemen pengguna (peran, deactivate/reactivate, mapping SSO jika relevan)
- Layar konfigurasi untuk kalender SLA, aturan matriks eskalasi, dan rute notifikasi
- Halaman status sistem: last job run, kedalaman queue, status provider notifikasi
Dokumen bantuan dan onboarding
Tulis dokumentasi tugas-singkat: “Buat eskalasi”, “Pause timeline”, “Override SLA”, “Audit siapa yang mengubah apa.”
Tambahkan alur onboarding ringan di aplikasi yang menunjuk pengguna ke antrian, tampilan kasus, dan aksi timeline, plus tautan ke halaman /help untuk referensi.
Rencanakan Peningkatan v2 Tanpa Membuat v1 Terlalu Rumit
Versi 1 harus membuktikan loop inti: sebuah kasus memiliki timeline yang jelas, jam SLA berperilaku dapat diprediksi, dan orang yang tepat mendapat notifikasi. Versi 2 bisa menambahkan fitur tanpa mengubah v1 menjadi sistem “segala hal”. Triknya adalah menjaga backlog peningkatan pendek dan eksplisit yang Anda tarik hanya setelah melihat pola penggunaan nyata.
Tentukan apa yang layak v2
Item v2 yang baik adalah yang (a) mengurangi pekerjaan manual dalam skala, atau (b) mencegah kesalahan mahal. Jika sebagian besar menambahkan opsi konfigurasi, tunda sampai ada bukti beberapa tim benar-benar membutuhkannya.
Peningkatan umum yang menguntungkan
Kalender SLA per pelanggan seringkali menjadi ekspansi bermakna pertama: jam kerja berbeda, hari libur, atau waktu respons kontraktual.
Selanjutnya, tambahkan playbook dan template: langkah eskalasi pre-built, pemangku rekomendasi, dan draf pesan yang membuat respons konsisten.
Routing yang lebih pintar (hanya saat volume butuh)
Saat penugasan menjadi bottleneck, pertimbangkan routing berbasis keterampilan dan jadwal on-call. Pertahankan iterasi pertama sederhana: beberapa keterampilan, pemilik fallback default, dan kontrol override yang jelas.
Automasi dengan guardrail
Auto-escalation bisa memicu saat sinyal muncul (perubahan severity, kata kunci, sentiment, kontak berulang). Mulailah dengan “saran eskalasi” (prompt) sebelum “eskalasi otomatis”, dan catat setiap alasan trigger untuk membangun kepercayaan dan auditabilitas.
Kontrol kualitas yang mencegah kekacauan
Tambahkan field wajib sebelum eskalasi (impact, severity, customer tier) dan langkah persetujuan untuk eskalasi ber-severity tinggi. Ini mengurangi kebisingan dan membantu pelaporan tetap akurat.
Jika ingin mengeksplor pola automasi sebelum membangunnya, lihat /blog/workflow-automation-basics. Jika Anda menyelaraskan scope ke packaging, periksa peta fitur ke tier di /pricing.
Pertanyaan umum
Apa yang harus dimaksud dengan “escalation” dalam aplikasi timeline eskalasi?
Mulailah dengan definisi satu kalimat yang disepakati semua orang (plus beberapa contoh). Sertakan juga non-contoh eksplisit (tiket rutin, tugas internal) agar v1 tidak berubah menjadi sistem tiket umum.
Kemudian tulis 2–4 metrik keberhasilan yang dapat Anda ukur segera, seperti tingkat pelanggaran SLA, waktu di setiap tahap, atau jumlah penugasan ulang.
Kriteria keberhasilan dan metrik apa yang harus saya lacak sejak hari pertama?
Pilih hasil yang merefleksikan perbaikan operasional, bukan sekadar fitur yang dibangun. Metrik praktis untuk v1 meliputi:
- Tingkat pelanggaran SLA
- Waktu yang dihabiskan di setiap tahap siklus hidup
- Waktu ke respons pertama / pembaruan berikutnya / resolusi
- Jumlah penugasan ulang (pergantian tangan)
Pilih sekumpulan kecil yang bisa Anda hitung dari timestamp hari pertama.
Tahap siklus hidup apa yang harus saya gunakan untuk eskalasi?
Gunakan set kecil tahap bersama dengan kriteria masuk/keluar yang jelas, misalnya:
- New → Assigned → Escalated → Resolved → Closed
Tuliskan apa yang harus benar untuk masuk dan keluar tiap tahap. Ini mencegah ambiguitas seperti “Resolved tapi masih menunggu pelanggan.”
Timestamp apa yang diperlukan untuk membangun timeline eskalasi yang dapat diandalkan?
Tangkap event minimum yang diperlukan untuk merekonstruksi timeline dan mempertahankan keputusan SLA:
- Waktu dibuat
- Waktu respons pertama
- Waktu setiap langkah eskalasi (termasuk dari/ke tier)
- Waktu terselesaikan (opsional: waktu konfirmasi pelanggan)
Jika Anda tidak bisa menjelaskan bagaimana sebuah timestamp digunakan, jangan kumpulkan di v1.
Bagaimana saya harus memodelkan SLA dan timer milestone di database?
Modelkan setiap milestone sebagai timer dengan:
start_atdue_at(dihitung)paused_atdanpause_reason(opsional)completed_at
Juga simpan aturan yang menghasilkan (kebijakan + kalender + alasan). Itu membuat audit dan sengketa jauh lebih mudah dibanding hanya menyimpan deadline akhir.
Bagaimana menangani zona waktu, jam kerja, dan hari libur dengan benar?
Simpan semua timestamp dalam UTC, tetapi simpan juga zona waktu kasus/pelanggan untuk tampilan dan penalaran pengguna. Modelkan kalender SLA secara eksplisit (24/7 vs jam kerja, hari libur, jadwal regional).
Uji kasus tepi seperti perubahan daylight saving, tiket dibuat dekat penutupan jam kerja, dan “pause dimulai tepat di batas.”
Peran dan izin apa yang penting untuk aplikasi manajemen eskalasi?
Jaga peran v1 sederhana dan selaras dengan alur kerja nyata:
- Agen: membuat/memperbarui kasus yang ditugaskan kepadanya
- Lead: menugaskan ulang, menyetujui eskalasi, menimpa timeline dengan alasan
- Admin: mengelola aturan SLA, field, tim, izin
- Viewer: baca-saja, ekspor dibatasi
Tambahkan aturan scope (tim/wilayah/akun) dan kontrol tingkat-field untuk data sensitif seperti catatan internal dan PII.
Layar inti apa yang harus disertakan v1 agar eskalasi mudah dikelola?
Rancang layar “sehari-hari” terlebih dulu:
- Antrian (daftar kasus) dengan tanggal jatuh tempo berikutnya dan indikator urgensi yang jelas
- Detail kasus yang menampilkan konteks, pemilik saat ini, batas waktu berikutnya, dan tindakan cepat
- Tampilan timeline yang terbaca seperti rangkaian komitmen
- Laporan dasar (kesehatan SLA + aging)
Optimalkan untuk pemindaian dan kurangi context switching—tindakan cepat tidak boleh tersembunyi dalam menu.
Bagaimana merancang alert tanpa menimbulkan alert fatigue?
Mulailah dengan sekumpulan notifikasi sinyal-tinggi:
- Mendekati tanggal jatuh tempo
- Terlambat (breach)
- Penugasan ulang
- Mention
Pilih 1–2 saluran untuk v1 (biasanya in-app + email), lalu tambahkan matriks eskalasi dengan ambang waktu jelas (T–2h, T–0h, T+1h). Cegah fatigue dengan dedupe, batching, dan quiet hours, serta buat acknowledge/snooze dapat diaudit.
Integrasi dan pilihan desain API apa yang paling penting untuk v1?
Integrasikan hanya yang menjaga timeline akurat:
- Inbound: pembuatan/ pembaruan dari email, form, atau alat ticketing Anda
- Outbound: webhooks untuk status, risiko SLA, dan perubahan kepemilikan
Jika melakukan sinkronisasi dua arah, tentukan sumber kebenaran per field dan aturan konflik (hindari “last write wins”). Publikasikan kontrak API minimal yang versi agar integrasi tidak rusak. Untuk pola automasi, lihat /blog/workflow-automation-basics; untuk pertimbangan packaging, lihat /pricing.