13 Agu 2025·5 menit
Konsep sistem terdistribusi: ide Kleppmann untuk skalasi SaaS
Konsep sistem terdistribusi dijelaskan lewat pilihan nyata tim saat mengubah prototipe menjadi SaaS andal: aliran data, konsistensi, dan kontrol beban.
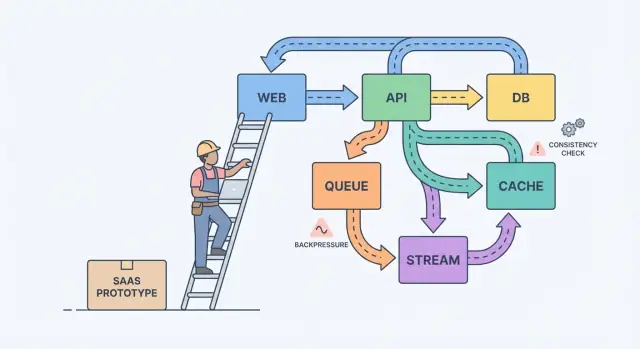
Konsep sistem terdistribusi dijelaskan lewat pilihan nyata tim saat mengubah prototipe menjadi SaaS andal: aliran data, konsistensi, dan kontrol beban.
Sebuah prototipe membuktikan ide. Sebuah SaaS harus bertahan dari penggunaan nyata: traffic puncak, data berantakan, retry, dan pelanggan yang memperhatikan setiap gangguan. Di sinilah semuanya menjadi membingungkan, karena pertanyaannya bergeser dari “apakah ini bekerja?” menjadi “apakah ini terus bekerja?”
Dengan pengguna nyata, “kemarin berhasil” gagal karena alasan yang membosankan. Job latar berjalan lebih lambat dari biasanya. Satu pelanggan mengunggah file 10x lebih besar dari data uji Anda. Penyedia pembayaran macet selama 30 detik. Tidak ada yang eksotis di sini, tetapi efek riaknya menjadi kencang saat bagian-bagian sistem saling bergantung.
Sebagian besar kompleksitas muncul di empat tempat: data (fakta yang sama ada di beberapa tempat dan menyimpang), latensi (panggilan 50 ms kadang jadi 5 detik), kegagalan (timeout, pembaruan parsial, retry), dan tim (orang berbeda mengirim layanan berbeda dengan jadwal berbeda).
Model mental sederhana membantu: komponen, pesan, dan state.
Komponen melakukan kerja (Web app, API, worker, database). Pesan memindahkan kerja antar komponen (request, event, job). State adalah apa yang Anda ingat (pesanan, pengaturan pengguna, status tagihan). Rasa sakit saat skalasi biasanya karena ketidakcocokan: Anda mengirim pesan lebih cepat dari kemampuan komponen, atau memperbarui state di dua tempat tanpa sumber kebenaran yang jelas.
Contoh klasik adalah penagihan. Prototipe mungkin membuat invoice, mengirim email, dan memperbarui plan pengguna dalam satu request. Saat beban naik, email melambat, request timeout, klien retry, dan sekarang Anda punya dua invoice dan satu perubahan plan. Pekerjaan keandalan sebagian besar soal mencegah kegagalan sehari-hari itu menjadi bug yang terlihat pelanggan.
Kebanyakan sistem menjadi lebih sulit karena tumbuh tanpa kesepakatan tentang apa yang harus benar, apa yang cukup cepat, dan apa yang terjadi saat sesuatu gagal.
Mulailah dengan menggambar batas di sekitar apa yang Anda janjikan ke pengguna. Di dalam batas itu, sebutkan tindakan yang harus benar setiap kali (pergerakan uang, kontrol akses, kepemilikan akun). Lalu sebutkan area di mana “akan benar pada akhirnya” cukup (hitungan analytics, indeks pencarian, rekomendasi). Pemisahan ini mengubah teori kabur menjadi prioritas.
Selanjutnya, tuliskan sumber kebenaran Anda. Itu tempat fakta dicatat sekali, tahan lama, dengan aturan jelas. Segala sesuatu selain itu adalah data turunan yang dibangun untuk kecepatan atau kenyamanan. Jika view turunan rusak, Anda harus bisa membangunnya kembali dari sumber kebenaran.
Ketika tim buntu, pertanyaan-pertanyaan ini biasanya memperlihatkan apa yang penting:
Jika seorang pengguna memperbarui plan tagihan, dashboard bisa terlambat. Tapi Anda tidak bisa mentolerir ketidakcocokan antara status pembayaran dan akses nyata.
Jika pengguna mengklik tombol dan harus melihat hasil seketika (simpan profil, muat dashboard, cek izin), API request-response biasa biasanya cukup. Jaga tetap langsung.
Begitu pekerjaan bisa terjadi nanti, pindahkan ke async. Pikirkan mengirim email, menagih kartu, membuat laporan, meresize upload, atau menyinkronkan data ke pencarian. Pengguna tidak harus menunggu ini, dan API Anda tidak perlu terikat saat pekerjaan berjalan.
Antrean adalah daftar tugas: setiap tugas harus ditangani sekali oleh satu worker. Stream (atau log) adalah catatan: event disimpan berurutan sehingga banyak pembaca bisa memutar ulang, mengejar, atau membangun fitur baru nanti tanpa mengubah produser.
Cara praktis memilih:
Contoh: SaaS Anda punya tombol “Create invoice”. API memvalidasi input dan menyimpan invoice di Postgres. Lalu antrean menangani “send invoice email” dan “charge card.” Jika nanti Anda menambah analytics, notifikasi, dan cek fraud, stream InvoiceCreated memungkinkan tiap fitur subscribe tanpa mengubah service inti menjadi labirin.
Seiring produk tumbuh, event berhenti menjadi “bagus untuk dimiliki” dan menjadi jaring pengaman. Desain event yang baik bergantung pada dua pertanyaan: fakta apa yang Anda catat, dan bagaimana bagian produk lain bereaksi tanpa menebak?
Mulailah dengan set kecil event bisnis. Pilih momen yang penting bagi pengguna dan uang: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Nama bertahan lebih lama daripada kode. Gunakan bentuk waktu lampau untuk fakta yang telah selesai, buat spesifik, dan hindari kata yang berbau UI. PaymentSucceeded tetap bermakna bahkan jika nanti Anda menambahkan kupon, retry, atau banyak penyedia pembayaran.
Perlakukan event sebagai kontrak. Hindari catch-all seperti “UserUpdated” dengan sekumpulan field yang berubah tiap sprint. Lebih baik fakta terkecil yang bisa Anda dukung selama bertahun-tahun.
Untuk berkembang aman, utamakan perubahan aditif (field opsional baru). Jika perlu perubahan pecah-compat, publikasikan nama event baru (atau versi eksplisit) dan jalankan keduanya sampai konsumen lama hilang.
Apa yang harus Anda simpan? Jika Anda hanya menyimpan baris terbaru di database, Anda kehilangan cerita bagaimana sampai ke sana.
Event mentah bagus untuk audit, replay, dan debugging. Snapshot bagus untuk pembacaan cepat dan pemulihan cepat. Banyak produk SaaS menggunakan keduanya: simpan event mentah untuk alur kerja kunci (billing, permission) dan pertahankan snapshot untuk tampilan yang berhadapan dengan pengguna.
Konsistensi muncul dalam momen seperti: “Saya ubah plan, kenapa masih tertulis Free?” atau “Saya kirim undangan, kenapa rekan saya belum bisa masuk?”
Konsistensi kuat berarti setelah Anda menerima pesan sukses, setiap layar harus langsung mencerminkan state baru. Konsistensi eventual berarti perubahan menyebar seiring waktu, dan untuk jangka pendek bagian aplikasi bisa berbeda pendapat. Tidak ada yang “lebih baik.” Anda memilih berdasarkan kerusakan yang bisa ditimbulkan oleh ketidakcocokan.
Konsistensi kuat biasanya cocok untuk uang, akses, dan keselamatan: menagih kartu, mengubah kata sandi, mencabut API key, menegakkan batas kursi. Konsistensi eventual sering cocok untuk feed aktivitas, pencarian, analytics, “last seen,” dan notifikasi.
Jika Anda menerima keterlambatan, desainlah untuk itu daripada menyembunyikannya. Jaga UI jujur: tunjukkan status “Updating…” setelah penulisan sampai konfirmasi datang, tawarkan refresh manual untuk daftar, dan gunakan optimistic UI hanya ketika Anda bisa rollback dengan bersih.
Retry adalah tempat konsistensi menjadi licik. Jaringan drop, klien double-click, dan worker restart. Untuk operasi penting, buat request idempotent sehingga mengulang tindakan yang sama tidak menghasilkan dua invoice, dua undangan, atau dua refund. Pendekatan umum adalah idempotency key per aksi ditambah aturan server-side untuk mengembalikan hasil asli untuk pengulangan.
Backpressure diperlukan saat request atau event tiba lebih cepat dari kemampuan sistem Anda. Tanpanya, kerja menumpuk di memori, antrean tumbuh, dan ketergantungan paling lambat (sering database) yang memutuskan kapan semuanya gagal.
Secara sederhana: producer terus berbicara sementara consumer tenggelam. Jika Anda terus menerima lebih banyak kerja, Anda tidak hanya menjadi lebih lambat. Anda memicu reaksi berantai timeout dan retry yang menggandakan beban.
Tanda peringatan biasanya terlihat sebelum outage: backlog terus tumbuh, latensi melonjak setelah spike atau deploy, retry meningkat dengan timeout, endpoint tak terkait gagal saat satu dependency melambat, dan koneksi database penuh pada batas.
Saat mencapai titik itu, pilih aturan jelas untuk apa yang terjadi saat penuh. Tujuannya bukan memproses semuanya dengan biaya apa pun. Tujuannya tetap hidup dan pulih cepat. Tim biasanya mulai dengan satu atau dua kontrol: rate limit (per user atau API key), antrean terbatas dengan kebijakan drop/tunda yang terdefinisi, circuit breaker untuk dependency yang gagal, dan prioritas sehingga request interaktif menang atas job latar.
Lindungi database terlebih dahulu. Jaga pool koneksi kecil dan dapat diprediksi, set timeout query, dan tetapkan batas keras pada endpoint mahal seperti laporan ad-hoc.
Keandalan jarang butuh rewrite besar. Biasanya datang dari beberapa keputusan yang membuat kegagalan terlihat, terkontain, dan dapat dipulihkan.
Mulailah dari alur yang membuat atau merusak kepercayaan, lalu tambahkan rel pengaman sebelum menambah fitur:
Map critical paths. Tuliskan langkah tepat untuk signup, login, reset password, dan alur pembayaran apa pun. Untuk setiap langkah, daftar dependensinya (database, penyedia email, worker latar). Ini memaksa kejelasan tentang apa yang harus langsung versus apa yang bisa diperbaiki “nanti.”
Tambah observability dasar. Beri setiap request ID yang muncul di log. Lacak set kecil metrik yang cocok dengan rasa sakit pengguna: error rate, latency, kedalaman antrean, dan query lambat. Tambah tracing hanya di tempat request melintasi layanan.
Isolasi pekerjaan yang lambat atau fluktuatif. Apa pun yang bicara dengan layanan eksternal atau rutin memakan waktu lebih dari satu detik sebaiknya pindah ke job dan worker.
Desain untuk retry dan kegagalan parsial. Asumsikan timeout terjadi. Buat operasi idempotent, gunakan backoff, tetapkan batas waktu, dan jaga aksi berhadapan pengguna tetap singkat.
Latih pemulihan. Backup hanya berguna jika Anda bisa memulihkannya. Gunakan rilis kecil dan jaga jalur rollback cepat.
Jika tooling Anda mendukung snapshot dan rollback (Koder.ai does), bangun itu ke kebiasaan deployment normal daripada menganggapnya trik darurat.
Bayangkan SaaS kecil yang membantu tim mengon onboarding klien baru. Alurnya sederhana: pengguna signup, memilih plan, membayar, dan menerima email sambutan plus beberapa langkah “memulai.”
Di prototipe, semua terjadi dalam satu request: buat akun, charge kartu, tandai “paid” pada pengguna, kirim email. Itu bekerja sampai traffic tumbuh, retry terjadi, dan layanan eksternal melambat.
Untuk membuatnya dapat diandalkan, tim mengubah tindakan kunci menjadi event dan menyimpan riwayat append-only. Mereka memperkenalkan beberapa event: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Itu memberi mereka jejak audit, mempermudah analytics, dan membiarkan pekerjaan lambat terjadi di latar tanpa memblokir signup.
Beberapa pilihan kecil melakukan sebagian besar pekerjaan:
PaymentSucceeded dengan idempotency key jelas sehingga retry tidak menggandakan pemberian.Jika pembayaran berhasil tapi akses belum diberikan, pengguna merasa ditipu. Perbaikannya bukan “konsistensi sempurna di mana-mana.” Perbaikannya adalah memutuskan apa yang harus konsisten sekarang juga, lalu mencerminkan keputusan itu di UI dengan status seperti “Activating your plan” sampai EntitlementGranted tiba.
Di hari buruk, backpressure membuat perbedaan. Jika API email macet saat kampanye marketing, desain lama akan timeout checkout dan pengguna retry, menciptakan duplikat charge dan duplikat email. Dalam desain yang lebih baik, checkout berhasil, permintaan email antre, dan job replay mengosongkan backlog saat penyedia pulih.
Sebagian besar outage bukan disebabkan satu bug heroik. Mereka datang dari keputusan kecil yang masuk akal di prototipe lalu menjadi kebiasaan.
Salah satu perangkap umum adalah membagi menjadi microservices terlalu dini. Anda berakhir dengan layanan yang lebih sering saling memanggil, kepemilikan tidak jelas, dan perubahan memerlukan lima deploy bukan satu.
Perangkap lain adalah menggunakan “eventual consistency” sebagai alasan gratis. Pengguna tidak peduli istilah itu. Mereka peduli bahwa mereka klik Simpan dan nanti halaman menunjukkan data lama, atau status invoice bolak-balik. Jika Anda menerima keterlambatan, Anda tetap butuh umpan balik pengguna, timeout, dan definisi “cukup baik” di tiap layar.
Pelaku lain yang sering mengulang: menerbitkan event tanpa rencana reprocessing, retry tak terbatas yang menggandakan beban saat insiden, dan membiarkan setiap layanan bicara langsung ke skema database yang sama sehingga satu perubahan merusak banyak tim.
“Production ready” adalah kumpulan keputusan yang bisa Anda tunjuk pada jam 2 pagi. Kejelasan mengalahkan kepintaran.
Mulailah dengan menamai sumber kebenaran Anda. Untuk tiap tipe data kunci (customers, subscriptions, invoices, permissions), putuskan di mana record final berada. Jika aplikasi Anda membaca “kebenaran” dari dua tempat, Anda akhirnya akan menunjukkan jawaban berbeda ke pengguna berbeda.
Lalu lihat retry. Asumsikan setiap aksi penting akan dijalankan dua kali suatu saat. Jika request yang sama menghantam sistem dua kali, bisakah Anda menghindari double charging, double sending, atau double creating?
Checklist kecil yang menangkap kebanyakan kegagalan menyakitkan:
Skalasi terasa lebih mudah ketika Anda memperlakukan desain sistem sebagai daftar pilihan singkat, bukan tumpukan teori.
Tuliskan 3 sampai 5 keputusan yang Anda perkirakan akan dihadapi bulan depan, dengan bahasa sederhana: “Apakah kita pindahkan pengiriman email ke job latar?” “Apakah kita terima analytics yang sedikit usang?” “Aksi mana yang harus langsung konsisten?” Gunakan daftar itu untuk menyelaraskan produk dan engineering.
Lalu pilih satu workflow yang saat ini sinkron dan ubah hanya itu menjadi async. Resi, notifikasi, laporan, dan proses file adalah langkah pertama yang umum. Ukur dua hal sebelum dan sesudah: latensi berhadap-hadapan pengguna (apakah halaman terasa lebih cepat?) dan perilaku kegagalan (apakah retry membuat duplikat atau kebingungan?).
Jika Anda ingin memprototaip perubahan ini dengan cepat, Koder.ai (koder.ai) dapat berguna untuk iterasi pada SaaS React + Go + PostgreSQL sambil menjaga rollback dan snapshot tetap mudah. Patokannya sederhana: kirim satu perbaikan, pelajari dari traffic nyata, lalu putuskan yang berikutnya.
A prototype answers “can we build it?” A SaaS must answer “will it keep working when users, data, and failures show up?”
The biggest shift is designing for:
Pick a boundary around what you promise users, then label actions by impact.
Start with must be correct every time:
Then mark can be eventually correct:
Choose one place where each “fact” is recorded once and treated as final (often Postgres for a small SaaS). That is your source of truth.
Everything else is derived for speed or convenience (caches, read models, search indexes). A good test: if the derived data is wrong, can you rebuild it from the source of truth without guessing?
Use request-response when the user needs an immediate result and the work is small.
Move work to async when it can happen later or can be slow:
Async keeps your API fast and reduces timeouts that trigger client retries.
A queue is a to-do list: each job should be handled once by one worker (with retries).
A stream/log is a record of events in order: multiple consumers can replay it to build features or recover.
Practical default:
Make important actions idempotent: repeating the same request should return the same outcome, not create a second invoice or charge.
Common pattern:
Also use unique constraints where possible (for example, one invoice per order).
Publish a small set of stable business facts, named in past tense, like PaymentSucceeded or SubscriptionStarted.
Keep events:
This keeps consumers from guessing what happened.
Common signs your system needs backpressure:
Good first controls:
Start with basics that match user pain:
Add tracing only where requests cross services; don’t instrument everything before you know what you’re looking for.
“Production ready” means you can answer hard questions quickly:
If your platform supports snapshots and rollback (like Koder.ai), use them as a normal release habit, not only during incidents.
Write it down as a short decision so everyone builds to the same rules.