Mengapa cache membantu—dan mengapa itu mempersulit sistem
Cache menyimpan salinan data dekat dengan tempat data diperlukan sehingga permintaan dapat dilayani lebih cepat, dengan lebih sedikit perjalanan ke sistem inti. Hasilnya biasanya kombinasi dari kecepatan (latensi lebih rendah), biaya (lebih sedikit pembacaan database mahal atau panggilan upstream), dan stabilitas (origin lebih tahan terhadap lonjakan trafik).
Sisi positif: lebih sedikit kerja untuk origin
Ketika cache bisa menjawab permintaan, “origin” Anda (server aplikasi, database, API pihak ketiga) melakukan lebih sedikit. Pengurangannya bisa dramatis: lebih sedikit kueri, lebih sedikit siklus CPU, lebih sedikit hop jaringan, dan lebih sedikit peluang timeout.
Caching juga meratakan lonjakan—membantu sistem yang disizakan untuk beban rata-rata menangani puncak tanpa langsung menskalakan (atau jatuh).
Pertukaran tersembunyi: lebih banyak kerja untuk engineer
Caching tidak menghilangkan pekerjaan; ia memindahkannya ke desain dan operasi. Anda mewarisi pertanyaan baru:
- Apa yang harus dicache?
- Berapa lama?
- Apa yang terjadi saat data berubah?
- Bagaimana mencegah hasil yang usang atau salah?
- Bagaimana men-debug masalah saat cache “menyembunyikan” perilaku origin?
Setiap lapisan cache menambah konfigurasi, monitoring, dan edge case. Cache yang mempercepat 99% permintaan masih bisa menyebabkan insiden menyakitkan pada 1%: expirasi tersinkronisasi, pengalaman pengguna yang tidak konsisten, atau ledakan lalu lintas ke origin.
Lapisan caching vs satu cache
Sebuah satu cache adalah satu penyimpanan (misalnya cache in-memory di samping aplikasi). Sebuah lapisan caching adalah checkpoint terpisah dalam jalur permintaan—CDN, cache browser, cache aplikasi, cache database—masing-masing dengan aturan dan mode kegagalan sendiri.
Posting ini fokus pada kompleksitas praktis yang diperkenalkan oleh banyak lapisan: kebenaran data, invalidasi, dan operasi (bukan algoritme cache low-level atau tuning vendor-spesifik).
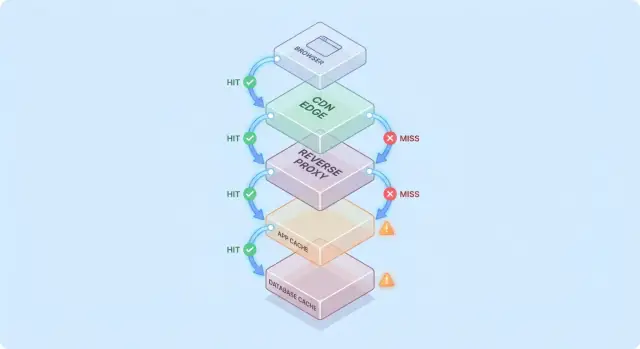
Model sederhana: aliran permintaan melalui beberapa lapisan
Caching lebih mudah dipahami jika Anda membayangkan permintaan bergerak melalui tumpukan checkpoint “mungkin saya sudah punya ini”.
Jalur permintaan tipikal
Jalur umum terlihat seperti ini:
- Client → Edge (CDN) → App → Database
Di setiap hop, sistem bisa mengembalikan respons yang dicache (hit) atau meneruskan permintaan ke lapisan berikutnya (miss). Semakin awal hit terjadi (mis. di edge), semakin banyak beban yang Anda hindari lebih dalam di tumpukan.
Hits itu enak; misses adalah ujian sebenarnya
Hits membuat dashboard terlihat hebat. Misses adalah tempat kompleksitas muncul: mereka memicu kerja nyata (logika aplikasi, kueri database) dan menambah overhead (lookup cache, serialisasi, penulisan cache).
Model mental yang berguna: setiap miss membayar dua kali untuk cache—Anda tetap melakukan pekerjaan asli, plus pekerjaan caching di sekitarnya.
Bagaimana lapisan memindahkan bottleneck
Menambahkan lapisan cache jarang menghilangkan bottleneck; sering kali memindahkannya:
- CDN bisa mengalihkan tekanan dari app, tetapi meningkatkan sensitivitas pada konfigurasi cache dan kecepatan purge.
- Cache aplikasi dapat mengurangi beban database, tetapi menjadikan CPU/memori tingkat app sebagai faktor pembatas baru.
- Caching database (buffer pool, plan cache) dapat menyembunyikan kueri lambat sampai working set tidak lagi muat.
Contoh sederhana “cached dua kali”
Bayangkan halaman produk Anda dicache di CDN selama 5 menit, dan aplikasi juga melalukan cache detail produk di Redis selama 30 menit.
Jika harga berubah, CDN mungkin menyegarkan dengan cepat sementara Redis terus menyajikan harga lama. Sekarang “kebenaran” bergantung pada lapisan mana yang menjawab permintaan—ini gambaran awal kenapa lapisan cache memotong beban tapi meningkatkan kompleksitas sistem.
Lapisan cache umum dan apa yang mereka kuasai
Caching bukan satu fitur—itu tumpukan tempat data bisa disimpan dan digunakan ulang. Setiap lapisan bisa mengurangi beban, tetapi masing-masing punya aturan berbeda untuk kesegaran, invalidasi, dan visibilitas.
Cache browser dan OS (yang Anda kendalikan vs yang tidak)
Browser menyimpan gambar, skrip, CSS, dan kadang respons API berdasarkan header HTTP seperti Cache-Control dan ETag. Ini bisa menghilangkan unduhan berulang sepenuhnya—bagus untuk performa dan mengurangi trafik CDN/origin.
Tantangannya: setelah respons dicache di sisi klien, Anda tidak sepenuhnya mengontrol waktu revalidasinya. Beberapa pengguna bisa menyimpan aset lama lebih lama (atau membersihkan cache secara tak terduga), jadi URL bernomor/berversi (mis. app.3f2c.js) adalah penjaga umum.
Caching CDN/edge untuk konten statis dan semi-statis
CDN menyimpan konten dekat pengguna. Ia unggul untuk file statis, halaman publik, dan respons yang “kebanyakan stabil” seperti gambar produk, dokumentasi, atau endpoint API yang diberi rate limit.
CDN juga bisa mencache HTML semi-statis jika Anda berhati-hati dengan variasi (cookie, header, geo, device). Aturan variasi yang salah sering menjadi sumber penyajian konten yang salah untuk pengguna yang salah.
Reverse proxy caching (tingkat gateway)
Reverse proxy (seperti NGINX atau Varnish) berdiri di depan aplikasi dan bisa mencache seluruh respons. Ini berguna jika Anda menginginkan kontrol terpusat, eviction yang dapat diprediksi, dan perlindungan cepat untuk server origin selama lonjakan trafik.
Biasanya tidak se-global CDN, tetapi lebih mudah disesuaikan untuk route dan header aplikasi Anda.
Caching di tingkat aplikasi (in-memory, Redis, Memcached)
Cache ini menargetkan objek, hasil komputasi, dan panggilan mahal (mis. “profil user by id” atau “aturan harga per region”). Ia fleksibel dan bisa diberi tahu tentang logika bisnis.
Tetapi ini juga memperkenalkan lebih banyak titik keputusan: desain kunci, pilihan TTL, logika invalidasi, dan kebutuhan operasional seperti sizing dan failover.
Caching database dan caching hasil kueri
Sebagian besar database melakukan cache halaman, indeks, dan plan secara otomatis; beberapa mendukung result caching. Ini dapat mempercepat kueri berulang tanpa mengubah kode aplikasi.
Ini sebaiknya dipandang sebagai bonus, bukan jaminan: cache database biasanya paling tidak dapat diprediksi di bawah pola kueri beragam, dan mereka tidak menghilangkan biaya tulis, lock, atau contention seperti cache hulu bisa.
Di mana caching memberikan pengurangan beban terbesar
Caching paling bermanfaat ketika ia mengubah operasi backend yang berulang dan mahal menjadi lookup yang murah. Kuncinya adalah mencocokkan cache dengan workload yang permintaannya cukup mirip—dan cukup stabil—sehingga reuse tinggi.
Workload baca-berat dan komputasi mahal
Jika sistem Anda melayani jauh lebih banyak baca daripada tulis, caching bisa menghilangkan bagian besar kerja database dan aplikasi. Halaman produk, profil publik, artikel help center, dan hasil pencarian/penyaringan sering diminta berulang dengan parameter yang sama.
Caching juga berguna untuk pekerjaan “mahal” yang tidak sepenuhnya terikat database: membuat PDF, meresize gambar, merender template, atau menghitung agregat. Bahkan cache singkat (detik–menit) bisa mereduksi komputasi berulang selama periode sibuk.
Trafik yang spiky dan perlindungan lonjakan
Caching sangat efektif ketika trafik tidak merata. Jika email pemasaran, liputan berita, atau posting sosial mengirim ledakan pengguna ke beberapa URL sama, CDN atau cache edge bisa menyerap mayoritas surge.
Ini mengurangi beban selain “respon yang lebih cepat”: dapat mencegah autoscaling thrash, menghindari kehabisan koneksi database, dan memberi waktu bagi rate limit dan backpressure bekerja.
Backend dengan latensi tinggi dan pengguna lintas-region
Jika backend Anda jauh dari pengguna—secara geografis (lintas-region) atau secara logis (dependency yang lambat)—caching bisa mengurangi beban dan persepsi keterlambatan. Menyajikan konten dari cache CDN dekat pengguna menghindari perjalanan panjang bolak-balik ke origin.
Caching internal juga membantu ketika bottleneck adalah store berlatensi tinggi (database remote, API pihak ketiga, atau layanan bersama). Mengurangi jumlah panggilan menurunkan tekanan concurrency dan memperbaiki tail latency.
Saat caching tidak masuk akal
Caching memberikan manfaat lebih sedikit ketika respons sangat dipersonalisasi (data per-user, detail akun sensitif) atau ketika data berubah terus-menerus (dashboard real-time, inventori yang cepat berubah). Dalam kasus itu, hit rate rendah, biaya invalidasi naik, dan pekerjaan origin yang tersimpan mungkin kecil.
Aturan praktis: caching paling berharga ketika banyak pengguna meminta hal yang sama dalam jendela waktu di mana “hal yang sama” tetap valid. Jika overlap itu tidak ada, lapisan cache tambahan bisa menambah kompleksitas tanpa mengurangi beban.
Invalidation cache: sumber utama kompleksitas
Caching mudah saat data tidak pernah berubah. Begitu data berubah, Anda mewarisi bagian tersulit: memutuskan kapan data cache tidak lagi dapat dipercaya, dan bagaimana setiap lapisan cache mengetahui perubahan tersebut.
Expiry TTL: sederhana, tetapi jarang “benar”
Time-to-live (TTL) menarik karena satu angka dan tanpa koordinasi. Masalahnya: TTL yang “benar” tergantung bagaimana data digunakan.
Jika Anda menetapkan TTL 5 menit untuk harga produk, beberapa pengguna akan melihat harga lama setelah perubahan—potensial masalah hukum atau dukungan. Jika TTL 5 detik, Anda mungkin tidak banyak mengurangi beban. Lebih buruk lagi, bidang berbeda dalam respons yang sama berubah dengan laju berbeda (inventory vs deskripsi), jadi satu TTL memaksa kompromi.
Invalidasi berbasis event: akurat, tapi butuh koordinasi
Invalidasi berbasis event mengatakan: saat sumber kebenaran berubah, publikasikan event dan purge/update semua kunci cache yang terpengaruh. Ini bisa sangat akurat, tetapi menciptakan pekerjaan baru:
- Setiap jalur tulis harus memancarkan event dengan andal.
- Setiap lapisan cache harus berlangganan, retry, deduplikasi, dan menangani delivery yang tidak berurutan.
- Anda memerlukan pemetaan jelas dari “apa yang berubah” ke “kunci mana yang harus di-invalidasi.”
Pemetaan inilah yang membuat “dua hal sulit: penamaan dan invalidasi” menjadi sangat praktis. Jika Anda meng-cache /users/123 dan juga cache daftar “top contributors”, perubahan nama pengguna memengaruhi lebih dari satu kunci. Jika Anda tidak melacak hubungan itu, Anda akan menyajikan realitas campur aduk.
Pola: cache-aside vs write-through vs write-back
Cache-aside (app baca/tulis DB, mengisi cache) umum, tetapi invalidasi ada di tangan Anda.
Write-through (tulis cache dan DB bersamaan) mengurangi risiko staleness, tetapi menambah latensi dan kompleksitas penanganan kegagalan.
Write-back (tulis cache dulu, flush kemudian) meningkatkan kecepatan, tetapi membuat kebenaran dan recovery jauh lebih sulit.
Stale-while-revalidate: “cukup baik” sengaja
Stale-while-revalidate menyajikan data sedikit usang sambil merefresh di latar belakang. Ini meratakan lonjakan dan melindungi origin, tetapi juga keputusan produk: Anda secara eksplisit memilih “cepat dan sebagian besar terkini” dibanding “selalu paling baru.”
Trade-off konsistensi dan kebenaran yang terlihat pengguna
Latih desain kunci cache
Modelkan kunci cache versi dan alur invalidasi dalam aplikasi nyata, bukan hanya diagram.
Caching mengubah apa arti “benar”. Tanpa cache, pengguna biasanya melihat data terbaru yang dikomit (dengan batasan perilaku database normal). Dengan cache, pengguna mungkin melihat data yang sedikit tertinggal—atau inkonsisten antar layar—tanpa indikasi jelas.
Konsistensi kuat vs eventual (dan apa yang benar-benar diperhatikan pengguna)
Konsistensi kuat mengejar “baca-setelah-tulis”: jika pengguna mengubah alamat pengiriman, muatan halaman berikutnya harus menampilkan alamat baru di mana-mana. Ini terasa intuitif, tetapi bisa mahal jika setiap tulis harus segera purge atau merefresh banyak cache.
Eventual consistency mengizinkan staleness singkat: pembaruan akan muncul segera, tapi tidak instan. Pengguna mentoleransi ini untuk konten berdampak rendah (seperti hitungan view), tetapi tidak untuk uang, izin, atau hal yang mengubah apa yang bisa mereka lakukan.
Race condition antara tulis dan refresh cache
Pitfall umum: tulis terjadi bersamaan dengan repopulasi cache:
- Pengguna memperbarui profil.
- Cache di-invalidasi.
- Permintaan lain merepopulasi cache dari replica yang belum menerima pembaruan.
Sekarang cache memuat data lama selama TTL-nya penuh, meskipun database sebenarnya sudah benar.
Inkonsistensi multi-lapisan: edge bilang A, app bilang B
Dengan beberapa lapisan caching, bagian sistem bisa berbeda:
- CDN mengembalikan halaman HTML lama (“Alamat: Jalan Lama”).
- Cache aplikasi mengembalikan JSON yang lebih baru (“Alamat: Jalan Baru”).
- UI menjadi campuran keduanya.
Pengguna menganggap ini “sistem rusak”, bukan “sistem bersifat eventual consistent.”
Versioning mengurangi ambiguitas:
- ETags memungkinkan client/CDN merevalidasi efisien dan menghindari penyajian konten usang saat representasi berubah.
- Kunci cache berversi (mis.
user:123:v7) memungkinkan Anda bergerak maju dengan aman: sebuah penulisan menaikkan versi, dan pembacaan bergeser ke kunci baru tanpa memerlukan penghapusan yang terkoordinasi.
Menetapkan staleness yang dapat diterima per fitur
Keputusan kunci bukan “apakah data usang buruk?” tetapi di mana itu buruk.
Tetapkan anggaran staleness eksplisit per fitur (detik/menit/jam) dan selaraskan dengan ekspektasi pengguna. Hasil pencarian bisa terlambat semenit; saldo akun dan kontrol akses sebaiknya tidak.
Ini menjadikan “kebenaran cache” sebagai persyaratan produk yang bisa diuji dan dimonitor.
Mode kegagalan: stampede, hot keys, dan outage cache
Caching sering gagal dengan cara yang tampak seperti “semua baik-baik lalu semuanya rusak sekaligus.” Kegagalan ini tidak berarti caching buruk—mereka berarti cache mengonsentrasikan pola lalu lintas, sehingga perubahan kecil bisa memicu efek besar.
Cold starts dan distribusi beban setelah deploy
Setelah deploy, autoscale, atau flush cache, Anda mungkin memiliki cache yang sebagian besar kosong. Ledakan trafik berikutnya memaksa banyak permintaan langsung ke database atau API upstream.
Ini sangat menyakitkan ketika trafik meningkat cepat, karena cache belum sempat warm untuk item populer. Jika deploy berbarengan dengan peak usage, Anda bisa secara tidak sengaja membuat load test sendiri.
Stampede cache (thundering herd)
Stampede terjadi ketika banyak pengguna meminta item yang sama tepat saat ia expired (atau belum dicache). Alih-alih satu permintaan yang merekomputasi nilai, ratusan atau ribuan melakukannya—membanjiri origin.
Mitigasi umum meliputi:
- Request coalescing: biarkan permintaan pertama merekomputasi sementara yang lain menunggu hasil
- Locks / single-flight: tegakkan “hanya satu builder” per kunci cache
- Jittered TTLs: randomisasi expirations supaya kunci tidak semuanya kadaluwarsa bersamaan
Jika kebutuhan kebenaran mengizinkan, stale-while-revalidate juga bisa meratakan puncak.
Hot keys dan distribusi yang tidak merata
Beberapa kunci menjadi sangat populer (payload homepage, produk trending, konfigurasi global). Hot keys menciptakan beban tidak merata: satu node cache atau satu jalur backend dihantam sementara yang lain menganggur.
Mitigasi termasuk memecah kunci "global" besar menjadi potongan lebih kecil, menambah sharding/partitioning, atau mencache di lapisan berbeda (mis. memindahkan konten publik yang benar-benar global lebih dekat ke pengguna lewat CDN).
Saat cache down: pilih fallback Anda
Outage cache bisa lebih buruk daripada tidak ada cache, karena aplikasi mungkin tergantung padanya. Putuskan lebih dulu:
- Fail open (bypass cache, panggil origin): ketersediaan lebih baik, risiko beban lebih tinggi
- Fail closed (kembalikan error): melindungi origin, pengalaman pengguna buruk
- Degrade gracefully (sajikan stale/default): seringkali kompromi terbaik
Apa pun pilihan Anda, rate limit dan circuit breaker membantu mencegah kegagalan cache menjadi outage origin.
Overhead operasional: lebih banyak bagian bergerak untuk dikelola
Jalankan uji ROI caching
Buat uji coba kecil di sekitar endpoint utama Anda dan bandingkan latensi serta beban origin.
Caching bisa mengurangi beban pada origin, tetapi menambah jumlah layanan yang Anda operasikan sehari-hari. Bahkan cache yang “dikelola” tetap membutuhkan perencanaan, tuning, dan respons insiden.
Komponen tambahan untuk dijalankan
Lapisan cache baru seringkali berarti cluster baru (atau setidaknya tier baru) dengan batas kapasitasnya sendiri. Tim harus menentukan sizing memori, policy eviction, dan apa yang terjadi saat tekanan tinggi. Jika cache kekurangan ukuran, ia akan churn: hit rate turun, latensi naik, dan origin tetap terbebani.
Drift konfigurasi antar lapisan
Caching jarang tinggal di satu tempat. Anda mungkin punya cache CDN, cache aplikasi, dan caching database—semua menafsirkan aturan secara berbeda.
Perbedaan kecil menumpuk:
- CDN menghormati header, cache app menggunakan TTL hard-coded.
- Satu lapisan bypass pada cookie sementara lain tidak.
- Purge rule ada di satu tempat tapi tidak di tempat lain.
Seiring waktu, “kenapa permintaan ini dicache?” menjadi proyek arkeologi.
Tugas operasional yang sebelumnya tidak ada
Cache membuat pekerjaan berulang: warming kunci penting setelah deploy, purge atau revalidate saat data berubah, resharding saat node ditambah/dihapus, dan latihan apa yang terjadi setelah flush penuh.
Kompleksitas on-call saat insiden
Saat pengguna melaporkan data usang atau kelambatan mendadak, responder sekarang punya beberapa tersangka: CDN, cluster cache, client cache library di app, dan origin. Debug sering berarti memeriksa hit rate, lonjakan eviction, dan timeout di berbagai lapisan—lalu memutuskan apakah bypass, purge, atau scale.
Observabilitas: membuktikan cache benar-benar membantu
Caching hanya merupakan kemenangan jika mengurangi kerja backend dan meningkatkan kecepatan yang dirasakan pengguna. Karena permintaan bisa dilayani oleh banyak lapisan (edge/CDN, cache aplikasi, cache database), Anda butuh observabilitas yang menjawab:
- Lapisan mana yang menyajikan permintaan ini?
- Apa yang berubah ketika permintaan tidak dicache?
Metrik yang benar-benar menjelaskan hasil
Rasio hit tinggi terdengar bagus, tetapi bisa menyembunyikan masalah (seperti baca cache yang lambat atau churn konstan). Lacak set kecil metrik per lapisan:
- Hit ratio dan miss ratio, dipisah per endpoint atau namespace cache
- Latensi per lapisan (waktu baca cache vs waktu origin), idealnya p50/p95/p99
- Tingkat eviction dan umur item (berapa lama entri bertahan sebelum dihapus)
- Indikator beban origin (DB QPS, CPU, saturasi pool koneksi) dikorelasikan dengan hits cache
Jika hit ratio naik tetapi total latensi tidak membaik, cache mungkin lambat, terlalu serial, atau mengembalikan payload berukuran besar.
Tracing lintas lapisan
Distributed tracing harus menunjukkan apakah permintaan dilayani di edge, oleh cache app, atau oleh database. Tambahkan tag konsisten seperti cache.layer=cdn|app|db dan cache.result=hit|miss|stale agar Anda bisa memfilter trace dan membandingkan timing jalur hit vs miss.
Logs dan alert tanpa membocorkan data
Log kunci cache dengan hati-hati: hindari identifier pengguna mentah, email, token, atau URL penuh dengan query string. Lebih baik normalisasi atau hash kunci dan log hanya prefix pendek.
Alert untuk lonjakan miss-rate abnormal, lonjakan latensi pada miss, dan sinyal stampede (banyak miss konkuren untuk pola kunci yang sama). Pisahkan dashboard menjadi view edge, app, dan database, plus satu panel end-to-end yang mengikat semuanya.
Risiko keamanan dan privasi pada respons yang dicache
Caching hebat dalam mengulang jawaban dengan cepat—tetapi juga bisa mengulang jawaban salah ke orang yang salah. Insiden terkait cache seringkali diam: semuanya terlihat cepat dan sehat sementara data bocor.
Bagaimana data sensitif berakhir di cache
Kegagalan umum adalah mencache konten yang dipersonalisasi atau rahasia (detail akun, faktur, tiket support, halaman admin). Ini bisa terjadi di mana saja—CDN, reverse proxy, atau cache aplikasi—terutama dengan aturan “cache semua” yang luas.
Kebocoran halus lain: mencache respons yang menyertakan state session (mis. header Set-Cookie) dan menyajikan respons itu kepada pengguna lain.
Kesalahan otorisasi: permintaan benar, penampil salah
Bug klasik adalah mencache HTML/JSON untuk User A lalu menyajikannya ke User B karena kunci cache tidak memasukkan konteks user. Dalam sistem multi-tenant, identitas tenant harus menjadi bagian dari kunci juga.
Aturan praktis: jika respons bergantung pada autentikasi, peran, geografi, pricing tier, feature flag, atau tenant, kunci cache (atau logika bypass) harus mencerminkan ketergantungan itu.
Perilaku caching HTTP sangat dipengaruhi oleh header:
Cache-Control: cegah penyimpanan tidak disengaja dengan private / no-store saat diperlukanVary: pastikan cache memisahkan respons berdasarkan header permintaan relevan (mis. Authorization, Accept-Language)Set-Cookie: sering jadi tanda bahwa respons tidak boleh dicache publik
Kapan menghindari caching sepenuhnya
Jika kepatuhan atau risiko tinggi—PII, data kesehatan/keuangan, dokumen hukum—gunakan Cache-Control: no-store dan optimalkan sisi server. Untuk halaman campuran, cache hanya fragmen non-sensitif atau aset statis, dan keluarkan data terpersonalisasi dari cache bersama.
Biaya dan ROI: memutuskan apakah lapisan tambahan sepadan
Buat ulang jalur permintaan
Jalankan stack React + Go + Postgres dari chat untuk mereproduksi masalah cache Anda.
Lapisan cache bisa mengurangi beban origin, tetapi jarang “kinerja gratis”. Perlakukan setiap cache baru sebagai investasi: Anda membeli latensi lebih rendah dan pekerjaan backend lebih sedikit dengan menukar uang, waktu engineering, dan permukaan kebenaran yang lebih besar.
Apa yang Anda bayar vs apa yang disimpan
Biaya infrastruktur tambahan vs pengurangan biaya origin. CDN mungkin mengurangi egress dan pembacaan database, tetapi Anda membayar untuk request CDN, penyimpanan cache, dan kadang panggilan invalidasi. Cache aplikasi (Redis/Memcached) menambah biaya cluster, upgrade, dan beban on-call. Penghematan bisa tampak sebagai lebih sedikit replica DB, instance lebih kecil, atau penundaan skala.
Kemenangan latensi vs biaya kesegaran. Setiap cache mengenalkan pertanyaan “seberapa usang yang diterima?”. Kesegaran ketat butuh plumbing invalidasi lebih rumit (dan lebih banyak miss). Ketidak-segaraan yang ditoleransi menghemat komputasi tetapi bisa merusak kepercayaan pengguna—terutama untuk harga, ketersediaan, atau izin.
Waktu engineering: kecepatan fitur vs pekerjaan reliabilitas. Lapisan baru biasanya berarti jalur kode ekstra, lebih banyak pengujian, dan kelas insiden baru untuk dicegah (stampedes, hot keys, partial invalidation). Siapkan biaya pemeliharaan berkelanjutan, bukan hanya implementasi awal.
Jalankan eksperimen kecil untuk mengukur ROI
Sebelum roll out luas, lakukan uji terbatas:
- Pilih satu endpoint atau halaman dengan load jelas (mis. top 5% trafik).
- Definisikan metrik sukses: p95 latency, DB QPS, error rate, cache hit ratio.
- Ramp secara bertahap; lacak perubahan biaya bersamaan dengan performa.
- Batasi waktu eksperimen dan siapkan tombol rollback.
Daftar cek keputusan sederhana
Tambahkan lapisan caching hanya jika:
- Bottleneck terbukti (bukan tebakan) lewat metrik
- Ada target yang jelas (mis. kurangi pembacaan DB 40%)
- Aturan staleness dan invalidasi diterima secara eksplisit
- Anda bisa memonitornya (hit rate, eviction, latensi, error)
- Perkiraan penghematan lebih besar daripada biaya operasional dan engineering selama horizon realistis
Panduan praktis untuk mengurangi kompleksitas saat caching
Caching paling memberikan hasil saat Anda memperlakukannya seperti fitur produk: perlu pemilik, aturan jelas, dan cara aman untuk mematikannya.
Mulai kecil, tetapkan kepemilikan
Tambahkan satu lapisan cache pada satu waktu (mis. CDN atau cache aplikasi dulu), dan tunjuk tim/orang yang bertanggung jawab.
Tentukan siapa yang memiliki:
- perubahan konfigurasi (TTL, bypass rules)
- kapasitas dan perilaku eviction
- respons insiden (apa yang dilakukan saat salah)
Buat kunci cache membosankan dan dapat diprediksi
Sebagian besar bug cache sebenarnya adalah “bug kunci.” Gunakan konvensi terdokumentasi yang mencakup input yang mengubah respons: ruang lingkup tenant/user, locale, kelas device, dan feature flag relevan.
Tambahkan versioning kunci eksplisit (mis. product:v3:...) sehingga Anda bisa meng-invalidasi aman dengan menaikkan versi daripada mencoba menghapus jutaan entri.
Pilih staleness terbatas daripada kesegaran sempurna
Mencoba menjaga semuanya selalu segar mendorong kompleksitas ke setiap jalur tulis.
Sebaliknya, tentukan apa yang “cukup usang” per endpoint (detik, menit, atau “sampai refresh berikutnya”), lalu terapkan dengan:
- TTL yang sesuai dengan ekspektasi bisnis
- refresh di latar belakang (sajikan sedikit usang sambil memperbarui)
- invalidasi berbasis event hanya untuk data yang benar-benar sensitif
Bangun default aman untuk kegagalan
Asumsikan cache akan lambat, salah, atau down.
Gunakan timeout dan circuit breaker sehingga panggilan cache tidak menjatuhkan jalur permintaan. Buat degradasi eksplisit: jika cache gagal, fallback ke origin dengan rate limit, atau sajikan respons minimal.
Roll out dengan kontrol dan runbook
Kiriman caching harus di belakang canary atau rollout persentase, dan sediakan tombol bypass (per route atau header) untuk troubleshooting cepat.
Dokumentasikan runbook: cara purge, cara menaikkan versi kunci, cara menonaktifkan caching sementara, dan di mana memeriksa metrik. Tautkan dari halaman runbook internal agar on-call bisa bertindak cepat.
Prototipe perubahan caching tanpa memperlambat delivery
Pekerjaan caching sering terhenti karena perubahan menyentuh banyak lapisan (header, logika app, model data, dan rencana rollback). Salah satu cara mengurangi biaya iterasi adalah memprototaip jalur permintaan penuh di lingkungan terkontrol.
Dengan Koder.ai, tim bisa cepat menyiapkan stack aplikasi realistis (React di web, backend Go dengan PostgreSQL, dan bahkan klien mobile Flutter) dari workflow berbasis chat, lalu menguji keputusan caching (TTL, desain kunci, stale-while-revalidate) end-to-end. Fitur seperti planning mode membantu mendokumentasikan perilaku caching yang dimaksud sebelum implementasi, dan snapshot/rollback membuat eksperimen konfigurasi cache atau logika invalidasi lebih aman. Ketika siap, Anda bisa export source code atau deploy/host dengan domain kustom—berguna untuk uji performa yang butuh mencerminkan lalu lintas produksi.
Jika Anda menggunakan platform semacam itu, anggap ia sebagai pelengkap observabilitas produksi: tujuannya adalah iterasi desain caching lebih cepat sambil menjaga persyaratan kebenaran dan prosedur rollback tetap eksplisit.