03 Nov 2025·8 menit
Leslie Lamport dan Sistem Terdistribusi: Waktu, Urutan, Kebenaran
Pelajari ide kunci Lamport tentang sistem terdistribusi—jam logis, pengurutan, konsensus, dan kebenaran—dan mengapa konsep ini masih membimbing infrastruktur modern.
Mengapa Lamport Masih Penting untuk Sistem Terdistribusi Modern
Leslie Lamport adalah salah satu peneliti langka yang kerja “teoretis”-nya muncul setiap kali Anda mengirim sistem nyata. Jika Anda pernah menjalankan klaster database, antrean pesan, engine workflow, atau apa pun yang mengeksekusi ulang permintaan dan bertahan dari kegagalan, Anda hidup di dalam masalah yang Lamport bantu beri nama dan selesaikan.
Yang membuat idenya bertahan adalah bahwa mereka tidak terikat pada teknologi tertentu. Mereka menggambarkan kebenaran tidak nyaman yang muncul kapan pun beberapa mesin mencoba berperilaku seperti satu sistem: jam tidak cocok, jaringan menunda dan menjatuhkan pesan, dan kegagalan adalah hal normal—bukan pengecualian.
Tiga tema yang akan kita gunakan sepanjang tulisan ini
Waktu: Dalam sistem terdistribusi, “jam berapa sekarang?” bukan pertanyaan sederhana. Jam fisik bergeser, dan urutan kejadian yang Anda amati bisa berbeda antar mesin.
Pengurutan: Setelah Anda tidak bisa mempercayai satu jam tunggal, Anda butuh cara lain untuk membicarakan kejadian mana yang terjadi lebih dulu—dan kapan Anda harus memaksa semua orang mengikuti urutan yang sama.
Kebenaran: “Biasanya berhasil” bukanlah sebuah desain. Lamport mendorong bidang ini ke definisi yang tegas (safety vs. liveness) dan spesifikasi yang bisa Anda renungkan, bukan hanya diuji.
Apa yang diharapkan (tanpa matematika berat)
Kita akan fokus pada konsep dan intuisi: masalahnya, alat minimal untuk berpikir jelas, dan bagaimana alat-alat itu membentuk desain praktis.
Ini peta jalannya:
- Mengapa tidak adanya jam bersama berarti tidak ada satu cerita global tentang kejadian
- Bagaimana kausalitas (“happened-before”) memunculkan jam logis dan stempel waktu Lamport
- Kapan urutan parsial tidak cukup dan Anda butuh satu garis waktu
- Bagaimana konsensus dan Paxos berkaitan dengan kesepakatan atas urutan
- Mengapa replikasi mesin status bekerja ketika pengurutan dibagi bersama
- Cara membicarakan kebenaran dalam spesifikasi—dan bagaimana alat pemodelan seperti TLA+ membantu
Masalah Inti: Tidak Ada Jam Bersama, Tidak Ada Realitas Tunggal
Sebuah sistem disebut “terdistribusi” ketika terdiri dari beberapa mesin yang berkoordinasi lewat jaringan untuk melakukan satu tugas. Itu terdengar sederhana sampai Anda menerima dua fakta: mesin bisa gagal secara independen (kegagalan parsial), dan jaringan dapat menunda, menjatuhkan, menggandakan, atau menyusun ulang pesan.
Dalam sebuah program tunggal di satu komputer, Anda biasanya bisa menunjuk “apa yang terjadi lebih dulu.” Dalam sistem terdistribusi, mesin berbeda bisa mengamati urutan kejadian yang berbeda—dan keduanya bisa benar dari sudut pandang lokalnya.
Mengapa Anda tidak bisa percaya pada jam global
Menggoda untuk menyelesaikan koordinasi dengan memberi stempel waktu pada semua hal. Tetapi tidak ada satu jam pun yang bisa Anda andalkan di seluruh mesin:
- Jam perangkat keras setiap server bergeser dengan laju masing-masing.
- Sinkronisasi jam (seperti NTP) adalah usaha terbaik, bukan jaminan.
- Virtualisasi, beban CPU, atau jeda bisa membuat waktu melompat atau berhenti sebentar.
Jadi “kejadian A terjadi pada 10:01:05.123” di satu host tidak dapat dibandingkan secara andal dengan “10:01:05.120” di host lain.
Bagaimana penundaan mengacaukan realitas
Penundaan jaringan dapat membalikkan apa yang Anda kira lihat. Sebuah tulis bisa dikirim lebih dulu tapi tiba terlambat. Pengulangan (retry) bisa tiba setelah aslinya. Dua pusat data bisa memproses “permintaan yang sama” dalam urutan yang berlawanan.
Ini membuat debugging unik membingungkan: log dari mesin berbeda bisa bertentangan, dan “diurutkan menurut stempel waktu” dapat membuat cerita yang sebenarnya tidak pernah terjadi.
Konsekuensi nyata
Ketika Anda berasumsi satu garis waktu yang tidak ada, Anda mendapat kegagalan konkret:
- Proses ganda (sebuah pembayaran terganjar dua kali setelah retry)
- Inkonsistensi (dua pengguna sama-sama “berhasil” mengklaim barang terakhir)
- Kehilangan data yang tampak (update yang datang belakangan menimpa yang lebih baru)
Intuisi kunci Lamport dimulai di sini: jika Anda tidak bisa berbagi waktu, Anda harus merumuskan urutan secara berbeda.
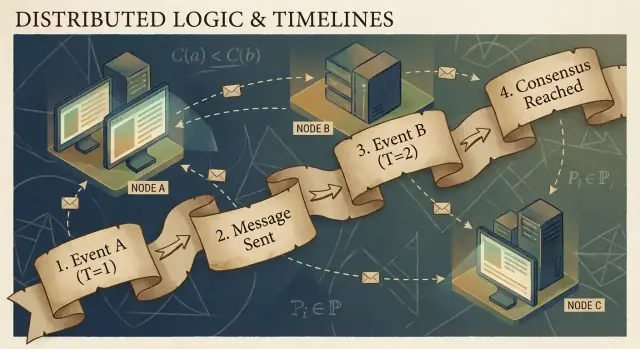
Kausalitas dan Relasi Happened-Before
Program terdistribusi dibuat dari kejadian: sesuatu yang terjadi di node tertentu (proses, server, atau thread). Contohnya termasuk “menerima permintaan,” “menulis baris,” atau “mengirim pesan.” Sebuah pesan adalah penghubung antar node: satu kejadian adalah kirim, kejadian lain adalah terima.
Intuisi utama Lamport adalah bahwa dalam sistem tanpa jam bersama yang dapat diandalkan, hal paling dapat diandalkan yang bisa Anda lacak adalah kausalitas—kejadian mana yang bisa memengaruhi kejadian lain.
Relasi happened-before (→)
Lamport mendefinisikan aturan sederhana yang disebut happened-before, ditulis A → B (kejadian A terjadi sebelum kejadian B):
- Urutan dalam proses yang sama: Jika A dan B terjadi di mesin/proses yang sama, dan A diamati terjadi lebih dulu di proses itu, maka A → B.
- Urutan pesan: Jika A adalah “kirim pesan m” dan B adalah “terima pesan m,” maka A → B.
- Transitif: Jika A → B dan B → C, maka A → C.
Relasi ini memberi Anda sebuah urutan parsial: ia memberitahu beberapa pasangan kejadian berurutan, tetapi tidak semua.
Kisah konkret: pengguna → permintaan → DB → cache
Seorang pengguna menekan “Beli.” Klik itu memicu permintaan ke server API (kejadian A). Server menulis baris order ke database (kejadian B). Setelah penulisan selesai, server memublikasikan pesan “order dibuat” (kejadian C), dan layanan cache menerimanya dan memperbarui entri cache (kejadian D).
Di sini A → B → C → D. Meski jam tidak cocok, struktur pesan dan program menciptakan tautan kausal nyata.
Apa arti “konkuren” sebenarnya
Dua kejadian adalah konkuren ketika tidak ada yang menyebabkan yang lain: bukan (A → B) dan bukan (B → A). Konkuren tidak berarti “pada waktu yang sama”—itu berarti “tidak ada jalur kausal yang menghubungkan keduanya.” Itulah mengapa dua layanan bisa sama-sama mengklaim mereka bertindak “lebih dulu,” dan keduanya bisa benar kecuali Anda menambahkan aturan pengurutan.
Jam Logis: Stempel Waktu Lamport dalam Bahasa Sederhana
Jika Anda pernah mencoba merekonstruksi “apa yang terjadi lebih dulu” di beberapa mesin, Anda pernah menemui masalah dasar: komputer tidak berbagi jam yang disinkronkan sempurna. Jalan pintas Lamport adalah berhenti mengejar waktu sempurna dan mulai melacak urutan.
Idenya: penghitung yang melampir pada tiap kejadian
Stempel waktu Lamport hanyalah angka yang Anda lampirkan ke setiap kejadian bermakna di suatu proses (instance layanan, node, thread—apa pun yang Anda pilih). Anggap itu sebagai “penghitung kejadian” yang memberi Anda cara konsisten untuk mengatakan, “kejadian ini terjadi sebelum yang itu,” meski waktu jam dinding tidak dapat dipercaya.
Dua aturan (dan memang sesederhana itu)
-
Inkrement lokal: sebelum Anda mencatat sebuah kejadian (misalnya, “menulis ke DB”, “mengirim permintaan”, “menambahkan entri log”), naikkan penghitung lokal Anda.
-
Saat menerima, ambil max + 1: ketika Anda menerima pesan yang menyertakan stempel waktu pengirim, set penghitung Anda ke:
max(local_counter, received_counter) + 1
Lalu berikan stempel pada kejadian terima dengan nilai itu.
Aturan ini memastikan stempel waktu menghormati kausalitas: jika kejadian A bisa memengaruhi kejadian B (karena informasi mengalir lewat pesan), maka stempel A akan lebih kecil daripada stempel B.
Apa yang bisa—dan tidak bisa—diberitahukan stempel Lamport
Mereka bisa memberitahu tentang pengurutan kausal:
- Jika
TS(A) < TS(B), A mungkin terjadi sebelum B. - Jika A menyebabkan B (langsung atau tidak langsung), maka pasti
TS(A) < TS(B).
Mereka tidak bisa memberitahu tentang waktu nyata:
- Stempel waktu yang lebih kecil tidak berarti “lebih awal dalam hitungan detik.”
- Dua kejadian bisa konkuren (tidak saling memengaruhi) dan tetap memiliki stempel berbeda karena pola pesan.
Jadi stempel Lamport bagus untuk pengurutan, bukan untuk mengukur latensi atau menjawab “jam berapa kejadian itu?”
Contoh praktis: mengurutkan entri log antar layanan
Bayangkan Layanan A memanggil Layanan B, dan keduanya menulis log audit. Anda ingin tampilan log terpadu yang mempertahankan sebab-akibat.
- Layanan A menaikkan penghitungan, mencatat “mulai pembayaran”, mengirim permintaan ke B dengan stempel 42.
- Layanan B menerima permintaan dengan 42, mengatur penghitungan ke
max(local, 42) + 1, misal 43, dan mencatat “validasi kartu”. - B merespons dengan 44; A menerima, memperbarui ke 45, dan mencatat “pembayaran selesai”.
Sekarang, saat Anda mengagregasi log dari kedua layanan, mengurutkan menurut (lamport_timestamp, service_id) memberi Anda garis waktu stabil dan dapat dijelaskan yang cocok dengan rantai pengaruh nyata—meski jam dinding bergeser atau jaringan menunda pesan.
Dari Urutan Parsial ke Urutan Total: Kapan Anda Membutuhkan Satu Garis Waktu
Kausalitas memberi Anda urutan parsial: beberapa kejadian jelas “sebelumnya” daripada yang lain (karena pesan atau ketergantungan menghubungkannya), tetapi banyak kejadian hanya konkuren. Itu bukan bug—itu bentuk alami realitas terdistribusi.
Urutan parsial: cukup untuk banyak pertanyaan
Jika Anda sedang debugging “apa yang bisa memengaruhi ini?”, atau menegakkan aturan seperti “balasan harus mengikuti permintaan,” urutan parsial adalah tepat. Anda hanya perlu menghormati tepi happened-before; yang lain bisa dianggap independen.
Urutan total: diperlukan ketika sistem harus memilih satu cerita
Beberapa sistem tidak bisa hidup dengan “keduanya urutannya oke.” Mereka butuh satu urutan operasi, terutama untuk:
- Tulis pada objek bersama (“set saldo,” “perbarui profil,” “tambahkan ke log”)
- Perintah yang harus diterapkan identik di mana-mana (replikasi mesin status)
- Resolusi konflik di mana “tulis terakhir menang” harus berarti hal yang sama untuk setiap node
Tanpa urutan total, dua replika bisa sama-sama “benar” secara lokal namun menyimpang secara global: satu menerapkan A lalu B, yang lain menerapkan B lalu A, dan Anda mendapat hasil berbeda.
Bagaimana mendapatkan satu garis waktu?
Anda memperkenalkan mekanisme yang menciptakan urutan:
- Sebuah sequencer/leader yang menetapkan posisi monoton meningkat ke setiap perintah.
- Atau konsensus (mis., pendekatan gaya Paxos) sehingga klaster sepakat pada entri log berikutnya meski ada penundaan dan kegagalan.
Trade-off yang tak bisa dihindari
Urutan total kuat, tapi berbiaya:
- Latensi: Anda mungkin menunggu koordinasi sebelum commit.
- Throughput: sebuah log berurutan bisa menjadi bottleneck.
- Ketersediaan saat kegagalan: jika Anda tidak mencapai cukup node untuk bersepakat, kemajuan bisa terhenti demi melindungi kebenaran.
Pilihan desainnya sederhana untuk dijelaskan: ketika kebenaran membutuhkan satu narasi bersama, Anda membayar biaya koordinasi untuk mendapatkannya.
Konsensus: Sepakat di Tengah Penundaan dan Kegagalan
Pertahankan kepemilikan penuh
Kirim kode sumber yang dihasilkan ke repositori Anda saat desain dirasa tepat.
Konsensus adalah masalah membuat beberapa mesin setuju pada satu keputusan—satu nilai untuk di-commit, satu pemimpin untuk diikuti, satu konfigurasi untuk diaktifkan—meski setiap mesin hanya melihat kejadian lokalnya dan pesan yang kebetulan tiba.
Terdengar sederhana sampai Anda ingat apa yang boleh dilakukan sistem terdistribusi: pesan bisa ditunda, digandakan, disusun ulang, atau hilang; mesin bisa crash dan restart; dan Anda jarang mendapat sinyal bersih bahwa “node ini pasti mati.” Konsensus tentang membuat kesepakatan yang aman dalam kondisi itu.
Mengapa sepakat itu rumit
Jika dua node sementara tidak bisa bicara (partisi jaringan), masing-masing pihak mungkin mencoba “maju” sendiri. Jika kedua belah pihak memutuskan nilai berbeda, Anda bisa berakhir dengan perilaku split-brain: dua pemimpin, dua konfigurasi berbeda, atau dua riwayat yang bersaing.
Bahkan tanpa partisi, penundaan saja sudah menimbulkan masalah. Saat sebuah node mendengar proposal, node lain mungkin sudah bergerak. Tanpa jam bersama, Anda tidak bisa andalkan “proposal A terjadi sebelum proposal B” hanya karena A punya stempel waktu lebih awal—waktu fisik tidak berwenang di sini.
Di mana Anda bertemu konsensus di sistem nyata
Anda mungkin tidak menyebutnya “konsensus” sehari-hari, tapi ia muncul di tugas infrastruktur umum:
- Pemilihan pemimpin (siapa yang memimpin sekarang?)
- Log terreplikasi (apa entri berikutnya dalam sejarah bersama?)
- Perubahan konfigurasi (set node mana yang boleh memilih/commit?)
Dalam setiap kasus, sistem butuh satu hasil yang bisa disepakati semua, atau setidaknya aturan yang mencegah hasil konflik dianggap valid bersamaan.
Paxos sebagai jawaban Lamport
Paxos Lamport adalah solusi dasar untuk masalah “kesepakatan aman” ini. Inti idenya bukan timeout ajaib atau pemimpin sempurna—melainkan seperangkat aturan yang memastikan hanya satu nilai yang bisa dipilih, meski pesan terlambat dan node gagal.
Paxos memisahkan safety (“jangan pernah pilih dua nilai berbeda”) dari progress (“pada akhirnya pilih sesuatu”), menjadikannya cetak biru praktis: Anda bisa mengatur performa dunia nyata sambil menjaga jaminan inti tetap utuh.
Paxos, Tanpa Pusing: Intuisi Kunci tentang Safety
Paxos punya reputasi sulit dibaca, tapi banyak dari itu karena “Paxos” bukan satu algoritme ringkas. Ia adalah keluarga pola terkait untuk membuat kelompok setuju, meski pesan terlambat, digandakan, atau mesin sementara gagal.
Para pemain: proposer, acceptor, dan kuorum
Model mental yang membantu memisahkan siapa yang mengusulkan dari siapa yang memvalidasi.
- Proposer mencoba membuat sebuah nilai dipilih (misalnya: “entri log berikutnya adalah X”).
- Acceptor memberikan suara pada proposal.
- Sebuah kuorum adalah “cukup banyak acceptor” untuk membuat kemajuan—biasanya mayoritas.
Ide strukturalnya: dua mayoritas selalu tumpang tindih. Di tumpang tindih itulah safety berada.
Tujuan safety: jangan pernah memutuskan dua nilai yang berbeda
Safety Paxos mudah dijelaskan: setelah sistem memutuskan suatu nilai, ia tidak boleh memutuskan nilai berbeda—tidak ada keputusan split-brain.
Intuisi kuncinya adalah proposal membawa nomor (anggap: ID pemungutan suara). Acceptor berjanji mengabaikan proposal bernomor lebih tua setelah melihat yang lebih baru. Ketika proposer mencoba dengan nomor baru, ia pertama-tama menanyakan kuorum apa yang sudah mereka terima.
Karena kuorum saling tumpang tindih, proposer baru pasti akan mendengar dari setidaknya satu acceptor yang “mengingat” nilai terakhir yang diterima. Aturannya: jika ada yang diterima di dalam kuorum, Anda harus mengusulkan nilai itu (atau yang paling baru di antara mereka). Batasan itulah yang mencegah dua nilai berbeda dipilih.
Liveness, pada tingkat tinggi
Liveness berarti sistem akhirnya memutuskan sesuatu dalam kondisi wajar (misalnya, pemimpin stabil muncul, dan jaringan akhirnya mengantarkan pesan). Paxos tidak menjanjikan kecepatan dalam kekacauan; ia menjanjikan kebenaran, dan kemajuan setelah keadaan tenang.
Replikasi Mesin Status: Kebenaran Melalui Pengurutan Bersama
Visualisasikan happened-before
Buat tampilan garis waktu yang mengurutkan event berdasarkan timestamp Lamport untuk debugging yang lebih mudah.
Replikasi mesin status (state machine replication) adalah pola kerja banyak sistem ketersediaan tinggi: alih-alih satu server membuat keputusan, Anda menjalankan beberapa replika yang semuanya memproses urutan perintah yang sama.
Ide log terreplikasi
Yang menjadi pusat adalah log terreplikasi: daftar berurutan perintah seperti “put key=K value=V” atau “transfer $10 dari A ke B.” Klien tidak mengirim perintah ke setiap replika dan berharap yang terbaik. Mereka menyerahkan perintah ke grup, dan sistem setuju pada satu urutan perintah itu, lalu setiap replika menerapkannya secara lokal.
Mengapa pengurutan memberi Anda kebenaran
Jika setiap replika mulai dari status awal yang sama dan mengeksekusi perintah yang sama dalam urutan yang sama, mereka akan berakhir pada status yang sama. Itu intuisi safety inti: Anda tidak mencoba menyinkronkan beberapa mesin dengan waktu; Anda membuatnya identik melalui determinisme dan pengurutan bersama.
Inilah mengapa konsensus (seperti protokol gaya Paxos/Raft) sering dipasangkan dengan SMR: konsensus memutuskan entri log berikutnya, dan SMR mengubah keputusan itu menjadi status konsisten di seluruh replika.
Di mana Anda melihatnya di sistem nyata
- Layanan koordinasi (mis., untuk konfigurasi dan pemilihan pemimpin)
- Database dengan write-ahead log yang direplikasi
- Sistem pesan yang memerlukan pengurutan partisi yang ketat
Kekhawatiran praktis yang tidak boleh diabaikan insinyur
Log tumbuh selamanya kecuali Anda mengelolanya:
- Snapshot: secara periodik ambil cuplikan status saat ini sehingga node baru bisa mengejar tanpa memutar ulang seluruh riwayat.
- Kompaksi log: aman membuang entri log lama setelah tercermin di snapshot dan tidak lagi dibutuhkan.
- Perubahan keanggotaan: menambah/menghapus replika harus diurutkan juga, kalau tidak node yang berbeda dapat tidak sepakat tentang siapa yang “ada di grup,” menyebabkan split-brain.
SMR bukan sihir; ia cara disiplin untuk mengubah “persetujuan atas urutan” menjadi “persetujuan atas status.”
Kebenaran: Safety, Liveness, dan Menulis Spesifikasi yang Jelas
Sistem terdistribusi gagal dengan cara yang aneh: pesan tiba terlambat, node restart, jam tidak cocok, dan jaringan terbelah. “Kebenaran” bukan nuansa—itu janji yang bisa Anda nyatakan dengan tepat dan kemudian periksa terhadap setiap situasi, termasuk kegagalan.
Safety vs. liveness (dengan contoh konkret)
Safety berarti “tidak ada hal buruk yang pernah terjadi.” Contoh: dalam store key-value terreplikasi, dua nilai berbeda tidak boleh di-commit untuk indeks log yang sama. Contoh lain: layanan kunci tidak boleh memberikan kunci yang sama kepada dua klien sekaligus.
Liveness berarti “sesuatu yang baik akhirnya terjadi.” Contoh: jika mayoritas replika up dan jaringan akhirnya mengantarkan pesan, permintaan tulis akhirnya selesai. Permintaan kunci akhirnya mendapat ya atau tidak (bukan menunggu selamanya).
Safety mencegah kontradiksi; liveness menghindari kebuntuan permanen.
Invarian: non-negotiable Anda
Sebuah invarian adalah kondisi yang harus selalu terpenuhi, di setiap status yang dapat dicapai. Misalnya:
- “Setiap indeks log memiliki paling banyak satu nilai yang di-commit.”
- “Nomor term pemimpin tidak pernah menurun.”
Jika sebuah invarian bisa dilanggar selama crash, timeout, retry, atau partisi, berarti invarian itu sebenarnya tidak ditegakkan.
Apa arti “bukti” di sini
Sebuah bukti adalah argumen yang mencakup semua kemungkinan eksekusi, bukan hanya jalur normal. Anda menimbang setiap kasus: kehilangan pesan, duplikasi, penyusunan ulang; crash dan restart node; pemimpin yang bersaing; klien yang mengulang.
Spesifikasi mencegah perilaku mengejutkan
Spesifikasi yang jelas mendefinisikan status, aksi yang diperbolehkan, dan properti yang dibutuhkan. Itu mencegah ekspektasi ambigu seperti “sistem harus konsisten” berubah menjadi kontradiksi. Spesifikasi memaksa Anda menyatakan apa yang terjadi selama partisi, apa arti “commit”, dan apa yang bisa diandalkan klien—sebelum produksi mengajari Anda dengan cara keras.
Dari Teori ke Praktik: Pemodelan dengan TLA+
Salah satu pelajaran paling praktis Lamport adalah bahwa Anda bisa (dan sering sebaiknya) merancang protokol terdistribusi pada level yang lebih tinggi daripada kode. Sebelum Anda khawatir tentang thread, RPC, dan loop retry, Anda bisa menuliskan aturan sistem: aksi apa yang diperbolehkan, status apa yang bisa berubah, dan apa yang tidak boleh terjadi.
Untuk apa TLA+ digunakan
TLA+ adalah bahasa spesifikasi dan toolkit model-checking untuk menggambarkan sistem konkuren dan terdistribusi. Anda menulis model sederhana bergaya matematika dari sistem—status dan transisi—plus properti yang Anda pedulikan (mis., “paling banyak satu pemimpin” atau “entri yang di-commit tidak pernah hilang”).
Kemudian model checker mengeksplorasi kemungkinan interleaving, penundaan pesan, dan kegagalan untuk menemukan counterexample: urutan langkah konkret yang melanggar properti Anda. Alih-alih berdebat tentang kasus tepi di rapat, Anda mendapatkan argumen yang dapat dieksekusi.
Bug yang bisa ditangkap model
Pertimbangkan langkah “commit” dalam log terreplikasi. Dalam kode, mudah tidak sengaja membiarkan dua node menandai dua entri berbeda sebagai committed pada indeks yang sama dalam kondisi timing langka.
Model TLA+ bisa mengungkap jejak seperti:
- Node A commit entri X pada indeks 10 setelah mendengar dari kuorum.
- Node B (dengan data usang) juga membentuk kuorum dan commit entri Y pada indeks 10.
Itu adalah commit ganda—pelanggaran safety yang mungkin hanya muncul sebulan sekali di produksi, tapi muncul cepat di bawah pencarian lengkap. Model serupa sering menangkap update yang hilang, double-apply, atau “ack tapi tidak durable”.
Kapan layak dimodelkan
TLA+ paling bernilai untuk logika koordinasi kritis: pemilihan pemimpin, perubahan keanggotaan, aliran seperti consensus, dan protokol apa pun di mana pengurutan dan penanganan kegagalan berinteraksi. Jika sebuah bug bisa merusak data atau mengharuskan pemulihan manual, model kecil biasanya lebih murah daripada debugging nanti.
Jika Anda membangun tooling internal di sekitar ide-ide ini, alur kerja praktisnya adalah menulis spesifikasi ringan (bahkan informal), lalu mengimplementasikan sistem dan menghasilkan tes dari invarian spesifikasi. Platform seperti Koder.ai dapat membantu mempercepat loop build-test: jelaskan perilaku pengurutan/konsensus yang dimaksud dalam bahasa biasa, iterasikan scaffolding layanan (frontend React, backend Go dengan PostgreSQL, atau klien Flutter), dan jaga “apa yang tidak boleh terjadi” tetap terlihat saat Anda produksi.
Takeaway Praktis untuk Membangun dan Mengoperasikan Sistem Andal
Eksperimen dengan konsensus
Rancang layanan pemilihan leader dan uji kasus kegagalan dengan cepat menggunakan snapshot dan rollback.
Hadiah besar Lamport untuk praktisi adalah pola pikir: perlakukan waktu dan pengurutan sebagai data yang Anda modelkan, bukan asumsi yang Anda warisi dari jam dinding. Pola pikir itu menjadi kebiasaan yang bisa Anda terapkan pada hari kerja.
Ubah teori menjadi praktik rekayasa sehari-hari
Jika pesan bisa ditunda, digandakan, atau tiba di luar urutan, rancang setiap interaksi agar aman dalam kondisi itu.
- Idempotensi sebagai default: buat “lakukan lagi” tidak berbahaya. Gunakan idempotency key untuk pembayaran, provisioning, atau tulis apa pun yang mungkin di-retry.
- Retry dengan deduplikasi: retry perlu, tapi tanpa dedup Anda akan menciptakan double-write. Lacak ID permintaan dan simpan penanda “sudah diproses”.
- Pengantaran minimal-sekali + efek tepat-sekali: terimalah bahwa jaringan mungkin mengirim dua kali; pastikan perubahan status Anda tidak ganda.
Hati-hati dengan timeout dan jam
Timeout bukan kebenaran; mereka adalah kebijakan. Timeout hanya memberitahu Anda “saya tidak mendengar kembali tepat waktu,” bukan “sisi lain tidak bertindak.” Dua implikasi konkret:
- Jangan memperlakukan timeout sebagai kegagalan yang definitif. Rancang jalur kompensasi dan rekonsiliasi.
- Hindari menggunakan waktu lokal untuk mengurutkan kejadian antar node. Gunakan nomor urut, penghitung monoton, atau metadata kausal eksplisit (mis., “update ini menggantikan versi X”).
Observabilitas yang menghormati kausalitas
Alat debugging yang baik mengenkripsi pengurutan, bukan hanya stempel waktu.
- Trace ID di mana-mana: propagasikan ID korelasi/trace melalui setiap hop dan baris log.
- Petunjuk kausal di log: catat ID pesan, ID permintaan induk, dan “apa yang saya kira versi terbaru” saat membuat keputusan.
- Replay deterministik: rekam input (perintah) sehingga Anda bisa memutar ulang perilaku dan memastikan apakah bug bergantung timing atau logika.
Pertanyaan desain yang harus diajukan sebelum shipping
Sebelum menambahkan fitur terdistribusi, paksa kejelasan dengan beberapa pertanyaan:
- Apa yang terjadi jika permintaan yang sama diproses dua kali?
- Pengurutan apa yang kita butuhkan (jika ada), dan di mana ia ditegakkan?
- Kegagalan mana yang “aman” (tidak merusak status) vs. “nyaring” (terlihat pengguna) vs. “diam” (korupsi tersembunyi)?
- Apa jalur pemulihan setelah outage parsial atau partisi jaringan?
- Apa yang akan kita log untuk merekonstruksi cerita happened-before di produksi?
Pertanyaan-pertanyaan ini tidak perlu gelar PhD—hanya disiplin untuk memperlakukan pengurutan dan kebenaran sebagai persyaratan produk kelas satu.
Kesimpulan dan Langkah Berikut yang Disarankan
Hadiah abadi Lamport adalah cara berpikir yang jernih ketika sistem tidak berbagi jam dan tidak setuju tentang “apa yang terjadi” secara default. Alih-alih mengejar waktu sempurna, Anda melacak kausalitas (apa yang bisa memengaruhi apa), merepresentasikannya dengan waktu logis (stempel waktu Lamport), dan—ketika produk membutuhkan sejarah tunggal—membangun kesepakatan (konsensus) sehingga setiap replika menerapkan urutan keputusan yang sama.
Benang itu mengarah pada pola pikir rekayasa praktis:
Spesifikasikan dulu, lalu bangun
Tuliskan aturan yang Anda butuhkan: apa yang tidak boleh terjadi (safety) dan apa yang harus terjadi pada akhirnya (liveness). Lalu implementasikan sesuai spesifikasi, dan uji sistem di bawah penundaan, partisi, retry, duplikasi pesan, dan restart node. Banyak “outage misterius” sebenarnya adalah pernyataan yang hilang seperti “sebuah permintaan mungkin diproses dua kali” atau “pemimpin bisa berubah kapan saja.”
Pelajari lebih jauh, dengan langkah terfokus
Jika Anda ingin mendalami tanpa tenggelam dalam formalisme:
- Baca Lamport “Time, Clocks, and the Ordering of Events in a Distributed System” untuk menginternalisasi happened-before.
- Baca “Paxos Made Simple” untuk intuisi safety: setelah sebuah nilai dipilih, kemajuan selanjutnya tidak bisa mengontradiksinya.
- Tonton intro TLA+, lalu model protokol kecil (layanan kunci atau register dua-replika) dan cek.
Coba satu latihan praktis
Pilih komponen yang Anda pegang dan tulis “kontrak kegagalan” satu halaman: apa asumsi Anda tentang jaringan dan penyimpanan, operasi apa yang idempotent, dan jaminan pengurutan apa yang Anda berikan.
Jika Anda ingin membuat latihan ini lebih konkret, bangun layanan “demo pengurutan” kecil: API permintaan yang menambahkan perintah ke log, worker latar yang menerapkannya, plus tampilan admin yang menunjukkan metadata kausal dan retry. Melakukan ini di Koder.ai bisa menjadi cara cepat untuk iterasi—terutama jika Anda ingin scaffolding cepat, deployment/hosting, snapshot/rollback untuk eksperimen, dan ekspor kode sumber saat selesai.
Jika dilakukan dengan baik, ide-ide ini mengurangi outage karena lebih sedikit perilaku yang bersifat implisit. Mereka juga menyederhanakan penalaran: Anda berhenti berdebat tentang waktu dan mulai membuktikan apa arti pengurutan, kesepakatan, dan kebenaran bagi sistem Anda.