18 Agu 2025·8 menit
LLVM karya Chris Lattner: Mesin Tenang di Balik Toolchain Modern
Pelajari bagaimana LLVM karya Chris Lattner menjadi platform kompiler modular yang menopang bahasa dan alat—menghadirkan optimisasi, diagnostik lebih baik, dan build yang cepat.
Apa itu LLVM, dengan Bahasa Sederhana
LLVM paling mudah dipahami sebagai “ruang mesin” yang dibagi oleh banyak kompiler dan alat pengembang.
Saat Anda menulis kode dalam bahasa seperti C, Swift, atau Rust, sesuatu harus menerjemahkan kode itu menjadi instruksi yang dapat dijalankan CPU Anda. Kompiler tradisional sering membangun seluruh jalur itu sendiri. LLVM mengambil pendekatan berbeda: ia menyediakan inti yang berkualitas tinggi dan dapat digunakan ulang yang menangani bagian-bagian paling sulit dan mahal—optimisasi, analisis, dan pembuatan kode mesin untuk banyak jenis prosesor.
Fondasi bersama untuk banyak bahasa
LLVM biasanya bukan kompiler tunggal yang “Anda gunakan langsung” sebagian besar waktu. Ia adalah infrastruktur kompiler: blok-blok bangunan yang bisa dirangkai oleh tim bahasa menjadi sebuah toolchain. Satu tim dapat fokus pada sintaks, semantik, dan fitur bagi pengembang, lalu menyerahkan pekerjaan berat ke LLVM.
Fondasi bersama ini menjadi alasan besar mengapa bahasa modern bisa mengirim toolchain yang cepat dan aman tanpa mengulangi pekerjaan kompiler selama puluhan tahun.
Mengapa ini penting meskipun Anda bukan orang kompiler
LLVM muncul dalam pengalaman pengembang sehari-hari:
- Kecepatan: ia dapat mengubah kode tingkat tinggi menjadi kode mesin yang efisien di berbagai platform.
- Kesalahan dan debugging yang lebih baik: ekosistem di sekitar LLVM memungkinkan diagnostik yang lebih kaya dan alat yang lebih baik.
- Lebih dari “sekadar kompilasi”: analisis statis, sanitizer, coverage, dan bantuan pengembang lain sering dibangun di atas representasi dan pustaka yang sama.
Apa yang akan (dan tidak akan) dibahas artikel ini
Ini adalah tur berpemandu tentang gagasan yang dimulai oleh Chris Lattner: bagaimana LLVM disusun, mengapa lapisan tengah penting, dan bagaimana ia memungkinkan optimisasi serta dukungan multiplatform. Ini bukan buku teks—kita akan fokus pada intuisinya dan dampak dunia nyata, bukan teori formal.
Visi Awal Chris Lattner
Chris Lattner adalah ilmuwan komputer dan insinyur yang, sebagai mahasiswa pascasarjana di awal 2000-an, memulai LLVM karena frustrasi praktis: teknologi kompiler sangat kuat, tetapi sulit digunakan ulang. Jika Anda ingin bahasa pemrograman baru, optimisasi yang lebih baik, atau dukungan untuk CPU baru, Anda sering harus mengutak-atik kompiler “all-in-one” yang sangat tergabung, di mana setiap perubahan memiliki efek samping.
Masalah yang ingin ia selesaikan
Saat itu, banyak kompiler dibangun seperti mesin tunggal besar: bagian yang memahami bahasa, bagian yang mengoptimalkan, dan bagian yang menghasilkan kode mesin saling terkait erat. Itu membuat mereka efektif untuk tujuan awalnya, tapi mahal untuk diadaptasi.
Tujuan Lattner bukanlah “kompiler untuk satu bahasa.” Ia menginginkan fondasi bersama yang bisa memberi tenaga pada banyak bahasa dan banyak alat—tanpa semua orang harus menulis ulang bagian kompleks yang sama berulang kali. Taruhannya adalah jika Anda dapat menstandarkan bagian tengah pipeline, Anda bisa berinovasi lebih cepat di pinggiran.
Mengapa “infrastruktur modular” terasa baru
Perubahan kunci adalah memperlakukan kompilasi sebagai serangkaian blok bangunan terpisah dengan batasan yang jelas. Dalam dunia modular:
- tim bahasa bisa fokus pada parsing dan fitur yang terlihat oleh pengembang,
- tim optimisasi bisa meningkatkan performa sekali dan membagikannya secara luas,
- dukungan hardware bisa ditambahkan tanpa mendesain ulang seluruh bagian hulu.
Pemisahan ini terdengar jelas sekarang, tetapi saat itu berlawanan dengan bagaimana banyak kompiler produksi berkembang.
Open source, dibangun untuk dipakai orang lain
LLVM dirilis sebagai open source sejak awal, yang penting karena infrastruktur bersama hanya bekerja jika banyak pihak bisa mempercayainya, memeriksanya, dan memperluasnya. Seiring waktu, universitas, perusahaan, dan kontributor independen membentuk proyek dengan menambahkan target, memperbaiki kasus tepi, meningkatkan performa, dan membangun alat baru di sekitarnya.
Aspek komunitas itu bukan sekadar kebaikan—itu bagian dari desain: buat inti yang berguna luas, dan akan bernilai untuk dipelihara bersama.
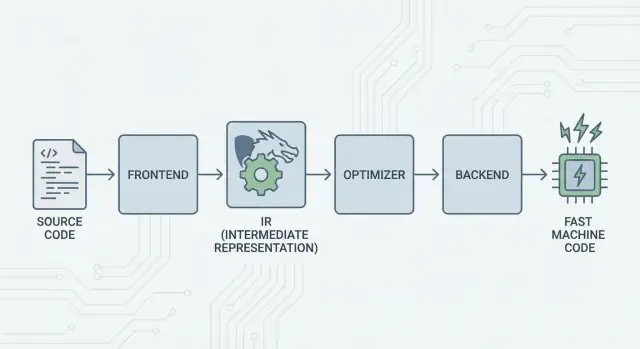
Gagasan Besar: Frontend, Inti Bersama, dan Backend
Ide inti LLVM sederhana: pisahkan kompiler menjadi tiga bagian utama sehingga banyak bahasa bisa berbagi pekerjaan paling sulit.
1) Frontend: “Apa yang dimaksud programmer?”
Sebuah frontend memahami bahasa pemrograman tertentu. Ia membaca kode sumber Anda, memeriksa aturan (sintaks dan tipe), dan mengubahnya menjadi representasi terstruktur.
Poin kunci: frontend tidak perlu tahu setiap detail CPU. Tugasnya adalah menerjemahkan konsep bahasa—fungsi, loop, variabel—ke sesuatu yang lebih universal.
2) Lapisan tengah bersama: satu inti bersama menggantikan kerja N×M
Secara tradisional, membangun kompiler berarti melakukan pekerjaan yang sama berulang-ulang:
- Dengan N bahasa dan M target chip, Anda berakhir dengan N×M kombinasi untuk didukung.
LLVM menguranginya menjadi:
- N frontend yang menerjemahkan ke bentuk bersama
- M backend yang menerjemahkan dari bentuk bersama itu ke kode mesin
“Bentuk bersama” itulah pusat LLVM: pipeline umum tempat optimisasi dan analisis berada. Ini penyederhana besar. Perbaikan di bagian tengah (seperti optimisasi yang lebih baik atau info debugging yang lebih baik) bisa menguntungkan banyak bahasa sekaligus, alih-alih harus diimplementasikan ulang di setiap kompiler.
3) Backend: “Bagaimana kita membuat ini berjalan cepat di CPU itu?”
Sebuah backend mengambil representasi bersama dan menghasilkan keluaran spesifik mesin: instruksi untuk x86, ARM, dan seterusnya. Di sinilah detail seperti register, konvensi pemanggilan, dan pemilihan instruksi menjadi penting.
Gambaran intuitif pipeline
Bayangkan kompilasi sebagai rute perjalanan:
- Kode sumber berada di negara spesifik-bahasa (frontend).
- Ia menyeberang perbatasan ke “bahasa tengah” yang standar (inti representasi dan pass LLVM).
- Lalu naik kereta lokal ke kota tujuan tertentu (backend untuk mesin target Anda).
Hasilnya adalah toolchain modular: bahasa bisa fokus pada mengekspresikan ide dengan jelas, sementara inti bersama LLVM fokus membuat ide-ide tersebut berjalan efisien di banyak platform.
LLVM IR: Lapisan Tengah yang Memungkinkan Penggunaan Ulang
LLVM IR (Intermediate Representation) adalah “bahasa umum” yang terletak di antara bahasa pemrograman dan kode mesin yang dijalankan CPU Anda.
Frontend kompiler (seperti Clang untuk C/C++) menerjemahkan kode sumber Anda ke bentuk bersama ini. Kemudian optimizers dan code generators LLVM bekerja pada IR, bukan pada bahasa asal. Akhirnya, backend mengubah IR menjadi instruksi untuk target tertentu (x86, ARM, dan sebagainya).
Bahasa umum antara alat dan CPU
Anggap LLVM IR sebagai jembatan yang dirancang cermat:
- Di atasnya: banyak bahasa sumber bisa terhubung (C, C++, Rust, Swift, Julia, dll.).
- Di bawahnya: banyak CPU bisa dituju.
- Di tengah: alat analisis dan optimisasi yang sama bisa digunakan ulang.
Inilah mengapa orang sering menggambarkan LLVM sebagai “infrastruktur kompiler” daripada “sebuah kompiler.” IR adalah kontrak bersama yang membuat infrastruktur itu dapat digunakan ulang.
Mengapa IR memungkinkan penggunaan ulang (dan menghemat pekerjaan)
Setelah kode berada di LLVM IR, sebagian besar pass optimisasi tidak perlu tahu apakah kode tersebut berasal dari template C++, iterator Rust, atau generic Swift. Mereka kebanyakan peduli pada gagasan universal seperti:
- “Nilai ini konstan.”
- “Perhitungan ini diulang; bisakah kita menggunakan kembali hasilnya?”
- “Load memori ini bisa dipindahkan atau dihapus dengan aman.”
Jadi tim bahasa tidak perlu membangun (dan memelihara) tumpukan optimizer lengkap mereka sendiri. Mereka bisa fokus pada frontend—parsing, pemeriksaan tipe, aturan spesifik bahasa—lalu menyerahkan pekerjaan berat ke LLVM.
Seperti apa secara konseptual
LLVM IR cukup rendah tingkat untuk dipetakan dengan bersih ke kode mesin, tetapi masih cukup terstruktur untuk dianalisis. Secara konseptual, ia dibangun dari instruksi sederhana (add, compare, load/store), aliran kontrol eksplisit (branch), dan nilai yang bertipe kuat—lebih mirip bahasa assembly yang rapi yang dirancang untuk kompiler daripada sesuatu yang biasanya ditulis manusia.
Bagaimana Optimisasi Bekerja (Tanpa Matematika)
Saat orang mendengar “optimisasi kompiler,” mereka sering membayangkan trik misterius. Di LLVM, sebagian besar optimisasi lebih dipahami sebagai penulisan ulang mekanis yang aman dari program—transformasi yang mempertahankan perilaku kode, tetapi bertujuan membuatnya berjalan lebih cepat (atau lebih kecil).
Pikirkan seperti mengedit, bukan menemukan hal baru
LLVM mengambil kode Anda (dalam LLVM IR) dan berulang kali menerapkan perbaikan kecil, mirip dengan memoles draf:
- Hapus pekerjaan duplikat: Jika sebuah nilai dihitung dua kali dan tidak ada yang berubah di antara keduanya, LLVM dapat menghitungnya sekali dan menggunakan kembali hasil itu.
- Sederhanakan logika yang jelas: Ekspresi konstan dapat dilipat lebih awal (mis. mengubah
3 * 4menjadi12), sehingga CPU melakukan lebih sedikit kerja saat runtime. - Rampingkan loop: Pass terkait loop bisa mengurangi pemeriksaan yang diulang, memindahkan pekerjaan tak berubah ke luar loop, atau mengenali pola yang bisa dieksekusi lebih efisien.
Perubahan ini sengaja konservatif. Sebuah pass hanya melakukan penulisan ulang ketika dapat membuktikan bahwa penulisan ulang itu tidak akan mengubah makna program.
Contoh yang mudah dimengerti
Jika program Anda secara konseptual melakukan hal-hal ini:
- Membaca nilai konfigurasi yang sama setiap iterasi loop
- Melakukan perhitungan yang sama pada input yang sama di beberapa tempat
- Memeriksa kondisi yang selalu benar/salah dalam konteks tertentu
…LLVM berusaha mengubah itu menjadi “lakukan pengaturan sekali,” “gunakan kembali hasil,” dan “hapus cabang yang mati.” Ini lebih seperti pekerjaan rumah tangga daripada sulap.
Trade-off nyata: waktu kompilasi vs. waktu jalankan
Optimisasi tidak gratis: analisis lebih banyak dan lebih banyak pass biasanya berarti kompilasi lebih lambat, meskipun program akhir berjalan lebih cepat. Itulah mengapa toolchain menawarkan level seperti “optimalkan sedikit” vs. “optimalkan agresif.”
Profil dapat membantu di sini. Dengan profile-guided optimization (PGO), Anda menjalankan program, mengumpulkan data penggunaan nyata, lalu mengkompilasi ulang sehingga LLVM memfokuskan upaya pada jalur yang benar-benar penting—membuat trade-off lebih dapat diprediksi.
Backend: Mencapai Banyak CPU Tanpa Menulis Ulang Segalanya
Capai Versi Pertama
Prototipe aplikasi web, backend, atau mobile dengan cepat untuk mendapat umpan balik.
Kompiler memiliki dua tugas yang sangat berbeda. Pertama, ia perlu memahami kode sumber Anda. Kedua, ia perlu menghasilkan kode mesin yang dapat dieksekusi oleh CPU tertentu. Backend LLVM fokus pada tugas kedua itu.
Apa yang sebenarnya dilakukan backend
Anggap LLVM IR sebagai “resep universal” untuk apa yang harus dilakukan program. Backend mengubah resep itu menjadi instruksi tepat untuk keluarga prosesor tertentu—x86-64 untuk sebagian besar desktop dan server, ARM64 untuk banyak ponsel dan laptop baru, atau target khusus seperti WebAssembly.
Secara konkretnya, backend bertanggung jawab untuk:
- Pemilihan instruksi: memetakan operasi IR ke instruksi CPU nyata
- Alokasi register: memilih nilai mana yang tinggal di register CPU yang cepat vs. memori
- Penjadwalan: mengurutkan instruksi agar CPU dapat menjalankannya efisien
- Output assembly/object: menghasilkan kode yang dipahami linker dan OS
Mengapa infrastruktur bersama mempermudah dukungan hardware baru
Tanpa inti bersama, setiap bahasa harus mengimplementasikan semua ini untuk setiap CPU yang ingin didukung—jumlah pekerjaan yang sangat besar dan beban pemeliharaan yang konstan.
LLVM membalik itu: frontend (seperti Clang) menghasilkan LLVM IR sekali, dan backend menangani “mil terakhir” per target. Menambahkan dukungan untuk CPU baru umumnya berarti menulis satu backend (atau memperluas yang ada), bukan menulis ulang setiap kompiler yang ada.
Portabilitas untuk tim yang mengirim ke banyak platform
Untuk proyek yang harus berjalan di Windows/macOS/Linux, di x86 dan ARM, atau bahkan di browser, model backend LLVM adalah keuntungan praktis. Anda dapat mempertahankan satu basis kode dan sebagian besar satu pipeline build, lalu menarget ulang dengan memilih backend berbeda (atau cross-compiling).
Portabilitas itulah alasan LLVM muncul di mana-mana: bukan hanya soal kecepatan—tetapi juga menghindari pekerjaan kompiler spesifik-platform yang berulang yang memperlambat tim.
Clang: Tempat Banyak Pengembang Pertama Kali Merasakan LLVM
Clang adalah frontend untuk C, C++, dan Objective-C yang menancap ke LLVM. Jika LLVM adalah mesin bersama yang dapat mengoptimalkan dan menghasilkan kode mesin, Clang adalah bagian yang membaca file sumber Anda, memahami aturan bahasa, dan mengubah apa yang Anda tulis menjadi bentuk yang dapat diproses LLVM.
Mengapa Clang diperhatikan
Banyak pengembang tidak menemukan LLVM melalui makalah kompiler—mereka mengalaminya pertama kali ketika mengganti kompiler dan umpan balik tiba-tiba menjadi lebih baik.
Diagnostik Clang dikenal lebih mudah dibaca dan lebih spesifik. Alih-alih kesalahan samar, ia sering menunjuk token tepat yang memicu masalah, menampilkan baris relevan, dan menjelaskan apa yang diharapkannya. Itu penting dalam kerja sehari-hari karena siklus “kompilasi, perbaiki, ulang” menjadi kurang menjengkelkan.
Clang juga mengekspos antarmuka yang bersih dan terdokumentasi dengan baik (terutama melalui libclang dan ekosistem tooling Clang yang lebih luas). Itu mempermudah editor, IDE, dan alat pengembang lain mengintegrasikan pemahaman bahasa yang mendalam tanpa menulis ulang parser C/C++.
Bagaimana ini muncul dalam alur kerja sehari-hari
Begitu alat dapat secara andal mem-parse dan menganalisis kode Anda, Anda mulai mendapatkan fitur yang terasa kurang seperti mengedit teks dan lebih seperti bekerja dengan program terstruktur:
- Navigasi kode yang akurat (“jump to definition,” “find references”) bahkan pada proyek C++ besar dengan banyak macro
- Dukungan refactoring yang memahami simbol dan ruang lingkup, bukan sekadar cari-dan-ganti
- Petunjuk inline dan perbaikan cepat yang digerakkan oleh sintaks dan informasi tipe nyata
Inilah mengapa Clang sering menjadi titik sentuh pertama untuk LLVM: dari sinilah peningkatan pengalaman pengembang praktis berasal. Bahkan jika Anda tidak pernah memikirkan LLVM IR atau backend, Anda tetap mendapat manfaat saat autocomplete editor Anda lebih cerdas, pemeriksaan statis lebih tepat, dan kesalahan build lebih mudah ditindaklanjuti.
Mengapa Banyak Bahasa Modern Membangun di Atas LLVM
LLVM menarik bagi tim bahasa karena alasan sederhana: ia memungkinkan mereka fokus pada bahasa alih-alih menghabiskan bertahun-tahun membangun kompiler pengoptimal penuh.
Waktu ke pasar yang lebih cepat
Membangun bahasa baru sudah melibatkan parsing, pemeriksaan tipe, diagnostik, tooling paket, dokumentasi, dan dukungan komunitas. Jika Anda juga harus membuat optimizer produksi, penghasil kode, dan dukungan platform dari awal, pengiriman tertunda—kadang-kadang bertahun-tahun.
LLVM menyediakan inti kompilasi siap pakai: alokasi register, pemilihan instruksi, pass optimisasi matang, dan target untuk CPU umum. Tim bisa mencolokkan frontend yang menurunkan bahasa mereka ke LLVM IR, lalu mengandalkan pipeline yang ada untuk menghasilkan kode native untuk macOS, Linux, dan Windows.
Performa tinggi (tanpa aksi heroik)
Optimizer dan backend LLVM adalah hasil rekayasa jangka panjang dan pengujian dunia nyata yang konstan. Itu diterjemahkan menjadi baseline performa yang kuat untuk bahasa yang mengadopsinya—seringkali cukup baik di awal, dan mampu meningkat seiring LLVM membaik.
Itu bagian dari alasan beberapa bahasa terkenal membangun di sekitarnya:
- Swift menggunakan LLVM untuk menghasilkan binary native yang sangat teroptimasi di platform Apple.
- Rust mengandalkan LLVM untuk pembuatan kode dan banyak target arsitektur.
- Julia menggunakan LLVM untuk memungkinkan kode numerik cepat, termasuk kompilasi runtime untuk beban kerja khusus.
Tidak setiap bahasa membutuhkan LLVM
Memilih LLVM adalah trade-off, bukan keharusan. Beberapa bahasa memprioritaskan binary yang sangat kecil, kompilasi yang sangat cepat, atau kontrol ketat atas seluruh toolchain. Lainnya sudah memiliki kompiler mapan (seperti ekosistem berbasis GCC) atau lebih memilih backend yang lebih sederhana.
LLVM populer karena merupakan default yang kuat—bukan karena satu-satunya jalan yang valid.
JIT dan Kompilasi Runtime: Siklus Umpan Balik Cepat
Skala Sesuai Kecepatan Anda
Pilih Free, Pro, Business, atau Enterprise sesuai sejauh mana Anda ingin mengembangkannya.
“Kompilasi just-in-time” (JIT) paling mudah dipahami sebagai mengompilasi saat Anda menjalankan. Alih-alih menerjemahkan seluruh kode lebih dulu menjadi executable final, mesin JIT menunggu sampai potongan kode benar-benar diperlukan, lalu mengompilasi bagian itu secara langsung—seringkali menggunakan informasi runtime nyata (seperti tipe dan ukuran data tepat) untuk membuat pilihan yang lebih baik.
Mengapa JIT terasa sangat cepat
Karena Anda tidak perlu mengompilasi semuanya di muka, sistem JIT dapat memberikan umpan balik cepat untuk kerja interaktif. Anda menulis atau menghasilkan sedikit kode, menjalankannya segera, dan sistem mengompilasi hanya yang diperlukan saat itu. Jika kode yang sama dijalankan berulang kali, JIT dapat menyimpan hasil terkompilasi atau mengompilasi ulang bagian yang “panas” lebih agresif.
Di mana kompilasi runtime membantu secara praktis
JIT unggul ketika beban kerja dinamis atau interaktif:
- REPL dan notebook: Evaluasi snippet langsung sambil tetap mendapatkan eksekusi dengan kecepatan native untuk loop berat.
- Plugin dan ekstensi: Aplikasi dapat memuat kode pengguna saat runtime dan mengompilasinya sesuai CPU host.
- Beban kerja dinamis: Saat input sangat bervariasi, profiling runtime dapat memandu jalur mana yang layak dioptimalkan.
- Komputasi ilmiah: Kernel yang dihasilkan (untuk ukuran matriks tertentu, bentuk model, atau fitur hardware) dapat dikompilasi sesuai permintaan.
Peran LLVM (tanpa histeria)
LLVM tidak menaklukkan semua program menjadi lebih cepat secara ajaib, dan ia bukan JIT lengkap dengan sendirinya. Apa yang ia sediakan adalah kotak alat: IR yang terdefinisi baik, banyak pass optimisasi, dan pembuatan kode untuk banyak CPU. Proyek dapat membangun mesin JIT di atas blok-blok itu, memilih trade-off tepat antara waktu startup, performa puncak, dan kompleksitas.
Performa, Prediktabilitas, dan Trade-off Dunia Nyata
Toolchain berbasis LLVM dapat menghasilkan kode yang sangat cepat—tetapi “cepat” bukan properti tunggal yang stabil. Itu bergantung pada versi kompiler, CPU target, pengaturan optimisasi, dan bahkan apa yang Anda minta kompiler untuk mengasumsikan tentang program.
Mengapa “sumber sama, hasil berbeda” bisa terjadi
Dua kompiler bisa membaca sumber C/C++ (atau Rust, Swift, dll.) yang sama dan tetap menghasilkan kode mesin yang berbeda nyata. Sebagian karena setiap kompiler memiliki set pass optimisasi, heuristik, dan pengaturan defaultnya sendiri. Bahkan dalam LLVM, Clang 15 dan Clang 18 mungkin membuat keputusan inlining yang berbeda, men-vektorisasi loop berbeda, atau menjadwalkan instruksi secara berbeda.
Ini juga bisa disebabkan oleh perilaku undefined dan perilaku yang tidak ditentukan dalam bahasa. Jika program Anda secara tidak sengaja bergantung pada sesuatu yang standar tidak jamin (mis. overflow bertanda pada C), kompiler yang berbeda—atau flag yang berbeda—mungkin “mengoptimalkan” dengan cara yang mengubah hasil.
Determinisme, build debug, dan build release
Orang sering mengharapkan kompilasi bersifat deterministik: input sama, output sama. Pada praktiknya, Anda akan mendekati itu, tetapi tidak selalu menghasilkan binary identik di lingkungan berbeda. Jalur build, cap waktu, urutan link, data yang dipandu profil, dan pilihan LTO semuanya dapat memengaruhi artefak akhir.
Perbedaan yang lebih praktis adalah debug vs. release. Build debug biasanya menonaktifkan banyak optimisasi untuk mempertahankan debugging langkah-demi-langkah dan stack trace yang terbaca. Build release mengaktifkan transformasi agresif yang dapat mengubah urutan kode, meng-inline fungsi, dan menghapus variabel—bagus untuk performa, tetapi kadang membuat debugging lebih sulit.
Saran praktis: ukur, jangan menebak
Anggap performa sebagai masalah pengukuran:
- Benchmark di hardware representatif dengan dataset realistis.
- Hangatkan cache dan jalankan beberapa iterasi.
- Bandingkan build dengan flag eksplisit (mis. mengganti
-O2vs-O3, mengaktifkan/menonaktifkan LTO, atau memilih target dengan-march).
Perubahan flag kecil dapat menggeser performa ke arah mana pun. Alur kerja paling aman: pilih hipotesis, ukur, dan simpan benchmark yang mendekati penggunaan nyata pengguna Anda.
Tooling di Luar Kompilasi: Analisis, Debugging, dan Keamanan
Iterasi Aman
Simpan titik pemeriksaan sebelum perubahan besar agar Anda bisa kembali dengan percaya diri.
LLVM sering digambarkan sebagai toolkit kompiler, tetapi banyak pengembang merasakan dampaknya melalui alat yang berada di sekitar kompilasi: analyzer, debugger, dan pemeriksaan keamanan yang dapat diaktifkan selama build dan pengujian.
Analisis dan instrumentasi sebagai “add-on”
Karena LLVM mengekspos representasi menengah (IR) dan pipeline pass yang terdefinisi, wajar membangun langkah ekstra yang memeriksa atau menulis ulang kode untuk tujuan selain kecepatan. Sebuah pass bisa menyisipkan penghitung untuk profiling, menandai operasi memori yang mencurigakan, atau mengumpulkan data coverage.
Poin kuncinya adalah fitur-fitur ini dapat diintegrasikan tanpa setiap tim bahasa harus menulis ulang plumbing yang sama.
Sanitizer: menangkap bug mendekati sumber
Clang dan LLVM memopulerkan keluarga runtime “sanitizer” yang menginstrumentasi program untuk mendeteksi kelas bug umum selama pengujian—seperti akses memori di luar batas, use-after-free, race data, dan pola perilaku undefined. Mereka bukan perisai ajaib, dan biasanya memperlambat program, jadi dipakai terutama di CI dan pengujian pra-rilis. Tetapi ketika mereka memicu, sering menunjuk lokasi sumber yang tepat dan penjelasan yang dapat dibaca, yang sangat membantu saat mengejar crash intermiten.
Diagnostik lebih baik = onboarding lebih cepat
Kualitas tooling juga tentang komunikasi. Peringatan yang jelas, pesan kesalahan yang bisa ditindaklanjuti, dan info debug konsisten mengurangi “faktor misteri” bagi pendatang baru. Ketika toolchain menjelaskan apa yang terjadi dan bagaimana memperbaikinya, pengembang menghabiskan lebih sedikit waktu menghafal keanehan kompiler dan lebih banyak waktu mempelajari basis kode.
LLVM tidak menjamin diagnostik atau keamanan sempurna sendirian, tetapi ia menyediakan fondasi bersama yang membuat alat-alat yang berfokus pada pengembang menjadi praktis untuk dibangun, dipelihara, dan dibagikan di banyak proyek.
Kapan Menggunakan LLVM (dan Kapan Tidak)
LLVM paling baik dipahami sebagai “bangun-kopi compiler dan kit tooling.” Fleksibilitas itu adalah alasan mengapa ia memberi tenaga banyak toolchain modern—tetapi juga alasan mengapa ia bukan jawaban tepat untuk setiap proyek.
Saat LLVM cocok
LLVM bersinar ketika Anda ingin menggunakan kembali rekayasa kompiler serius tanpa menulis ulangnya.
Jika Anda membangun bahasa pemrograman baru, LLVM dapat memberi pipeline optimisasi yang terbukti, pembuatan kode matang untuk banyak CPU, dan jalur ke dukungan debugging yang baik.
Jika Anda mengirim aplikasi lintas platform, ekosistem backend LLVM mengurangi pekerjaan yang diperlukan untuk menargetkan arsitektur berbeda. Anda fokus pada bahasa atau logika produk, bukan menulis generator kode terpisah.
Jika tujuan Anda adalah tooling pengembang—linter, analisis statis, navigasi kode, refactoring—LLVM (dan ekosistemnya) adalah fondasi kuat karena kompiler sudah “memahami” struktur dan tipe kode.
Saat mungkin berlebihan
LLVM bisa terasa berat jika Anda bekerja pada sistem embedded kecil di mana ukuran build, memori, dan waktu kompilasi sangat terbatas.
Ia juga mungkin kurang cocok untuk pipeline yang sangat khusus di mana Anda tidak menginginkan optimisasi umum, atau saat “bahasa” Anda lebih mirip DSL tetap dengan pemetaan langsung ke kode mesin yang sederhana.
Checklist sederhana
Tanyakan tiga pertanyaan ini:
- Apakah kita perlu menargetkan banyak platform/CPU sekarang atau segera?
- Apakah kita mendapat manfaat dari optimisasi dan debug info yang sudah ada, alih-alih membangunnya sendiri?
- Apakah kita menginginkan jalur ekosistem (tooling, integrasi, hiring) lebih daripada kompiler minimal?
Jika jawaban “ya” untuk sebagian besar, LLVM biasanya taruhan yang praktis. Jika Anda terutama menginginkan kompiler yang paling kecil dan sederhana untuk satu masalah sempit, pendekatan yang lebih ringan bisa menang.
Catatan praktis untuk tim produk: manfaat LLVM tanpa jadi ahli kompiler
Sebagian besar tim tidak ingin “mengadopsi LLVM” sebagai proyek. Mereka menginginkan hasil: build lintas platform, binary cepat, diagnostik yang baik, dan tooling andal.
Itulah salah satu alasan platform seperti Koder.ai menarik dalam konteks ini. Jika alur kerja Anda semakin didorong oleh otomatisasi tingkat tinggi (perencanaan, menghasilkan kerangka kerja, iterasi cepat), Anda tetap mendapat manfaat dari LLVM secara tidak langsung melalui toolchain yang mendasari—apakah Anda membangun aplikasi React, backend Go dengan PostgreSQL, atau klien mobile Flutter. Pendekatan “vibe-coding” berbasis chat Koder.ai berfokus pada mengirim produk lebih cepat, sementara infrastruktur kompiler modern (LLVM/Clang dan kawan-kawan, jika relevan) terus melakukan pekerjaan tak glamor optimisasi, diagnostik, dan portabilitas di latar belakang.