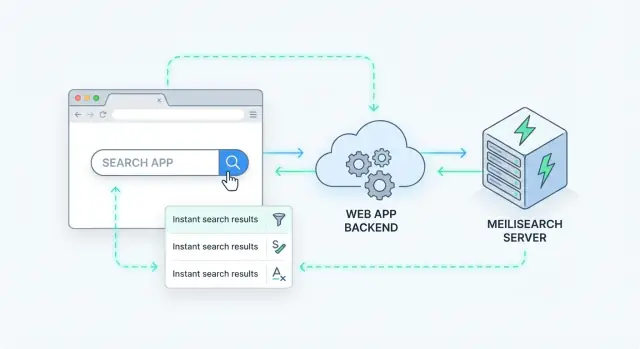
Apa yang harus dihadirkan oleh pencarian server-side instan
Pencarian server-side berarti kueri diproses di server Anda (atau layanan pencarian khusus), bukan di browser. Aplikasi Anda mengirim permintaan pencarian, server menjalankannya terhadap sebuah index, dan mengembalikan hasil yang sudah diberi peringkat.
Ini penting ketika dataset Anda terlalu besar untuk dikirim ke klien, ketika Anda membutuhkan relevansi yang konsisten antar platform, atau ketika kontrol akses tidak bisa ditawar (misalnya alat internal di mana pengguna hanya boleh melihat apa yang mereka diizinkan). Ini juga pilihan default ketika Anda menginginkan analitik, pencatatan, dan performa yang dapat diprediksi.
Apa yang pengguna harapkan (dan langsung mereka sadari)
Orang tidak memikirkan mesin pencari—mereka menilai pengalaman. Alur pencarian “instan” yang baik biasanya berarti:
- Umpan balik cepat: hasil diperbarui dengan cepat saat pengguna mengetik, tanpa jeda canggung.
- Salah ketik tidak merusak: ejaan salah, huruf tertukar, dan kata parsial tetap menemukan item yang tepat.
- Kontrol yang berguna: filtering (kategori, status, rentang harga), pengurutan (terbaru, termurah), dan facet (hitung per filter) terasa alami.
- Urutan relevan: hasil “terbaik” muncul pertama, bukan hanya yang terbaru atau yang penuh kata kunci.
Jika salah satu ini hilang, pengguna akan mengganti kueri, menggulir lebih banyak, atau meninggalkan pencarian sepenuhnya.
Apa yang akan dibantu panduan ini
Artikel ini adalah walkthrough praktis untuk membangun pengalaman tersebut dengan Meilisearch. Kita akan membahas cara menyiapkannya dengan aman, bagaimana menyusun dan menyinkronkan data yang diindeks, cara menyetel relevansi dan aturan perankingan, cara menambahkan filter/pengurutan/facet, serta cara memikirkan keamanan dan penskalaan agar pencarian tetap cepat seiring pertumbuhan aplikasi Anda.
Saat pencarian server-side paling unggul
Meilisearch cocok untuk:
- Dokumentasi dan basis pengetahuan (cari halaman dengan cepat, toleran terhadap salah ketik)
- Katalog produk dan marketplace (filter dan pengurutan sangat penting)
- Alat internal (pencarian yang memperhatikan izin)
- Situs konten (mencari di artikel, panduan, FAQ)
Tujuannya: hasil yang terasa langsung, akurat, dan dapat dipercaya—tanpa menjadikan pencarian proyek teknik besar.
Gambaran Meilisearch dengan bahasa sederhana
Meilisearch adalah mesin pencari yang Anda jalankan berdampingan dengan aplikasi Anda. Anda mengirim dokumen (seperti produk, artikel, pengguna, atau tiket dukungan), dan ia membangun index yang dioptimalkan untuk pencarian cepat. Backend (atau frontend) Anda lalu melakukan query ke Meilisearch melalui API HTTP sederhana dan mendapatkan hasil berperingkat dalam milidetik.
Yang Anda dapatkan langsung
Meilisearch fokus pada fitur yang diharapkan dari pencarian modern:
- Toleransi salah ketik sehingga “iphnoe” masih bisa menemukan “iPhone”.
- Kontrol relevansi (aturan perankingan) sehingga Anda dapat menentukan apa yang berarti “cocok terbaik” bagi bisnis Anda.
- Filter, pengurutan, dan facet sehingga pengguna bisa mempersempit hasil berdasarkan atribut seperti kategori, rentang harga, ketersediaan, atau tag.
Dirancang agar terasa responsif dan memaafkan, bahkan saat kueri pendek, sedikit salah, atau ambigu.
Apa yang bukan Meilisearch
Meilisearch bukan pengganti untuk database utama Anda. Database Anda tetap sumber kebenaran untuk penulisan, transaksi, dan constraint. Meilisearch menyimpan salinan bidang yang Anda pilih untuk dijadikan searchable, filterable, atau displayable.
Model mental yang baik: database untuk menyimpan dan memperbarui data, Meilisearch untuk menemukannya dengan cepat.
Meilisearch bisa sangat cepat, tetapi hasilnya bergantung pada beberapa faktor praktis:
- Ukuran dan bentuk data (jumlah dokumen, jumlah field, dan seberapa banyak teks yang Anda indeks)
- Perangkat keras (CPU, RAM, disk)
- Konfigurasi (field mana yang searchable/filterable/sortable, dan seberapa sering Anda melakukan reindex)
Untuk dataset kecil-ke-menengah, seringkali cukup dijalankan di satu mesin. Saat index tumbuh, Anda perlu lebih hati-hati tentang apa yang diindeks dan bagaimana Anda memperbaruinya—topik yang akan kita bahas di bagian selanjutnya.
Merencanakan index dan model data Anda
Sebelum memasang apa pun, putuskan apa yang sebenarnya akan Anda cari. Meilisearch terasa “instan” hanya jika index dan dokumen Anda cocok dengan cara orang menelusuri aplikasi Anda.
Peta entitas ke index
Mulailah dengan daftar entitas yang dapat dicari—biasanya products, articles, users, help docs, locations, dll. Dalam banyak aplikasi, pendekatan paling bersih adalah satu index per tipe entitas (mis. products, articles). Itu menjaga aturan perankingan dan filter tetap dapat diprediksi.
Jika UX Anda mencari di banyak tipe dalam satu kotak (“cari semuanya”), Anda masih bisa menjaga index terpisah dan menggabungkan hasil di backend, atau membuat index “global” khusus nanti. Jangan memaksa semuanya ke satu index kecuali field dan filter benar-benar selaras.
Pilih primary key dan bentuk dokumen
Setiap dokumen membutuhkan pengenal stabil (primary key). Pilih sesuatu yang:
- tidak pernah berubah (atau sangat jarang berubah)
- unik di seluruh index
- sudah ada di database Anda (mis.
id, sku, slug)
Untuk bentuk dokumen, lebih suka field datar bila memungkinkan. Struktur datar lebih mudah untuk filter dan sort. Field bersarang (nested) baik jika mewakili bundel yang ketat dan tidak berubah (mis. objek author), tetapi hindari nesting yang dalam yang meniru seluruh skema relasional Anda—dokumen pencarian sebaiknya dioptimalkan untuk baca, bukan berbentuk database.
Klasifikasikan field: searchable, filterable, displayed
Cara praktis mendesain dokumen adalah menandai setiap field dengan satu peran:
- Searchable: teks yang diketik orang (title, name, description)
- Filterable: atribut yang dipakai sebagai constraint (category, price range, status, tags)
- Displayed: apa yang Anda kembalikan ke UI (title, thumbnail URL, cuplikan singkat)
Ini mencegah kesalahan umum: mengindeks field “hanya untuk berjaga-jaga” dan kemudian bertanya-tanya mengapa hasilnya berisik atau filter lambat.
Rencanakan untuk konten multibahasa
“Bahasa” bisa berarti hal berbeda dalam data Anda:
- bahasa dokumen (setiap artikel punya
lang: "en")
- lokal pengguna (bahasa UI)
- field campuran bahasa (nama produk dalam banyak bahasa)
Putuskan lebih awal apakah Anda akan menggunakan index terpisah per bahasa (sederhana dan dapat diprediksi) atau satu index dengan field bahasa (lebih sedikit index, logika lebih kompleks). Jawaban yang tepat bergantung pada apakah pengguna mencari dalam satu bahasa pada satu waktu dan bagaimana Anda menyimpan terjemahan.
Menginstal dan menjalankan Meilisearch dengan aman
Menjalankan Meilisearch sederhana, tetapi "aman secara default" membutuhkan beberapa pilihan yang disengaja: dimana Anda menerapkannya, bagaimana Anda menyimpan data, dan bagaimana menangani master key.
Opsi deployment (pilih yang bisa Anda operasikan)
- Docker (paling umum): cepat memulai, mudah di-upgrade, konsisten antar lingkungan. Pasangkan dengan volume persisten.
- VM atau bare metal: baik jika Anda sudah memiliki pipeline deployment Linux standar (systemd, rotasi log, backup).
- Managed hosting: jika tim Anda tidak ingin memelihara server, cari penyedia Meilisearch terkelola atau platform yang menyediakannya sebagai add-on. Anda akan menukar fleksibilitas dengan operasi yang lebih sederhana.
Dasar lingkungan: penyimpanan, memori, backup, monitoring
Penyimpanan: Meilisearch menulis index ke disk. Letakkan direktori data di penyimpanan yang andal dan persisten (bukan penyimpanan kontainer yang ephemeral). Rencanakan kapasitas untuk pertumbuhan: index dapat membesar dengan cepat pada field teks besar dan banyak atribut.
Memori: alokasikan RAM yang cukup agar pencarian tetap responsif di bawah beban. Jika Anda melihat swapping, performa akan menurun.
Backup: backup direktori data Meilisearch (atau gunakan snapshot di lapisan penyimpanan). Uji pemulihan setidaknya sekali; backup yang tidak bisa dipulihkan hanyalah file biasa.
Monitoring: pantau CPU, RAM, penggunaan disk, dan I/O disk. Juga pantau kesehatan proses dan log error. Minimal, beri alert jika layanan berhenti atau ruang disk menipis.
Tetapkan dan simpan master key dengan aman
Selalu jalankan Meilisearch dengan master key pada apa pun selain pengembangan lokal. Simpan di secret manager atau penyimpanan variabel lingkungan terenkripsi (jangan di Git, jangan di .env biasa yang dikomit ke repo).
Contoh (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Juga pertimbangkan aturan jaringan: bind ke interface privat atau batasi akses masuk sehingga hanya backend Anda yang dapat menjangkau Meilisearch.
Checklist saat pertama mulai
curl -s http://localhost:7700/version
Mengindeks dokumen dan menjaga sinkronisasi
Tambah filter dan facet dengan cepat
Buat pencarian katalog produk dengan facet, filter, dan pengurutan hanya dari satu chat.
Pengindeksan Meilisearch bersifat asinkron: Anda mengirim dokumen, Meilisearch mengantri sebuah task, dan hanya setelah task itu berhasil dokumen akan menjadi dapat dicari. Perlakukan pengindeksan seperti sistem job, bukan satu permintaan tunggal.
Alur pengindeksan sederhana (tambah → tunggu → verifikasi)
- Tambah dokumen (pastikan tiap dokumen punya id unik stabil, biasanya
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
- Tunggu task. Respon API menyertakan
taskUid. Poll sampai statusnya succeeded (atau failed).
curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Verifikasi jumlah dan pencarian dasar. Konfirmasi index memiliki jumlah dokumen yang diharapkan dan kueri sederhana mengembalikan hasil.
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Jika jumlah tidak cocok, jangan menebak—periksa detail error task terlebih dahulu.
Batching yang tidak mengejutkan Anda nanti
Batching soal menjaga task tetap dapat diprediksi dan dapat dipulihkan.
- Mulailah dengan 1.000–10.000 dokumen per batch, atau batasi berdasarkan ukuran payload (untuk banyak aplikasi, 5–15 MB per permintaan adalah rentang yang nyaman).
- Lebih baik banyak batch kecil daripada satu upload besar; lebih mudah di-retry dan menemukan data bermasalah.
- Jika Anda sering berubah, indeks secara terus-menerus dalam batch (mis. setiap menit) daripada membangun ulang semuanya.
Update vs reindex penuh
addDocuments berperilaku seperti upsert: dokumen dengan primary key yang sama akan diperbarui, yang baru akan disisipkan. Gunakan ini untuk pembaruan normal.
Lakukan reindex penuh ketika:
- Anda mengubah bentuk dokumen secara signifikan,
- Perlu mengkomputasi ulang field turunan,
- Sinkronisasi Anda melenceng dan Anda ingin reset bersih.
Untuk penghapusan, panggil deleteDocument(s) secara eksplisit; jika tidak, record lama bisa tetap tersisa.
Idempoten: retry aman saat job gagal
Pengindeksan harus bisa di-retry. Kuncinya adalah id dokumen yang stabil.
- Jika upload batch timeout, Anda bisa mengirim ulang batch yang sama: upsert + id stabil berarti Anda tidak akan membuat duplikat.
- Simpan
taskUid yang dikembalikan bersama id batch/job Anda, dan retry berdasarkan status task.
- Jika Anda menjalankan queue, buat worker “at-least-once” aman: duplikat seharusnya tidak berbahaya.
Data seed untuk pengujian pra-produksi cepat
Sebelum data produksi, indeks dataset kecil (200–500 item) yang cocok dengan field nyata Anda. Contoh: set products dengan id, name, description, category, brand, price, inStock, createdAt. Ini cukup untuk memvalidasi alur task, jumlah, dan perilaku update/delete—tanpa menunggu impor besar.
Relevansi dan aturan perankingan yang bisa Anda kendalikan
“Relevansi” pencarian hanyalah: apa yang muncul pertama, dan kenapa. Meilisearch membuatnya dapat disesuaikan tanpa memaksa Anda membangun sistem scoring sendiri.
Mulai dengan atribut yang tepat
Dua pengaturan membentuk apa yang bisa dilakukan Meilisearch dengan konten Anda:
searchableAttributes: field yang dicari saat pengguna mengetik kueri (mis. title, summary, tags). Urutan penting: field yang lebih awal dianggap lebih penting.displayedAttributes: field yang dikembalikan di respons. Ini penting untuk privasi dan ukuran payload—jika field tidak ditampilkan, field itu tidak akan dikirim kembali.
Baseline praktis adalah membuat beberapa field sinyal-tinggi menjadi searchable (title, teks kunci), dan batasi displayed fields ke apa yang UI butuhkan.
Bagaimana aturan perankingan memengaruhi urutan hasil
Meilisearch mengurutkan dokumen yang cocok menggunakan ranking rules—sebuah pipeline "tie-breaker." Secara konseptual, ia memprioritaskan:
- hasil yang cocok dengan kueri dengan baik (termasuk toleransi salah ketik), kemudian
- hasil dengan kecocokan yang lebih kuat (kata lebih dekat, kecocokan di atribut yang lebih penting), lalu
- hasil yang sesuai logika bisnis Anda (pengurutan custom seperti recency atau popularitas).
Anda tidak perlu menghafal internals untuk menyetelnya secara efektif; Anda terutama memilih field mana yang penting dan kapan menerapkan pengurutan custom.
Tujuan tuning umum (dengan contoh)
Tujuan: “Kecocokan judul harus menang.” Letakkan title di awal:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Tujuan: “Konten yang lebih baru muncul dulu.” Tambahkan aturan sort dan minta sort di waktu query (atau set ranking custom):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Lalu request:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Tujuan: “Promosikan item populer.” Jadikan popularity sortable dan urutkan berdasarkan itu saat tepat.
Evaluasi perubahan dengan tes before/after sederhana
Pilih 5–10 kueri nyata pengguna. Simpan hasil teratas sebelum perubahan, lalu bandingkan sesudah.
Contoh:
- Sebelum: kueri
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Sesudah (title-first + exactness): kueri
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Jika daftar “sesudah” lebih cocok dengan niat pengguna, pertahankan pengaturan. Jika merusak kasus tepi, ubah satu hal pada satu waktu (urutan atribut, lalu aturan pengurutan) sehingga Anda tahu apa yang menyebabkan perbaikan.
Filter, pengurutan, dan facet untuk pencarian dunia nyata
Kotak pencarian yang baik bukan sekadar "ketik kata, dapat kecocokan." Orang juga ingin mempersempit hasil ("hanya item yang tersedia") dan mengurutkannya ("termurah dulu"). Di Meilisearch, Anda melakukan ini dengan filters, sorting, dan facets.
Filter dan facet (ide yang sama, UI berbeda)
Filter adalah aturan yang Anda terapkan pada hasil. Facet adalah apa yang Anda tunjukkan di UI untuk membantu pengguna membentuk aturan itu (sering sebagai checkbox atau hitungan).
Contoh non-teknis:
- Category: "Shoes", "Jackets", "Accessories"
- Price: "Under $50", "$50–$100"
- Status: "In stock", "Backorder", "Archived"
Jadi pengguna mungkin mencari “running” lalu memfilter ke category = Shoes dan status = in_stock. Facet dapat menunjukkan hitungan seperti “Shoes (128)” dan “Jackets (42)” sehingga pengguna tahu apa yang tersedia.
Konfigurasi field filterable dan sortable (atau tidak akan bekerja)
Meilisearch membutuhkan Anda secara eksplisit mengizinkan field yang dipakai untuk filtering dan pengurutan.
- Tandai field sebagai filterable ketika Anda akan menggunakannya dalam filter:
category, status, brand, price, created_at (jika Anda memfilter berdasarkan waktu), tenant_id (jika Anda mengisolasi pelanggan).
- Tandai field sebagai sortable ketika Anda akan mengurutkan hasil berdasarkan field itu:
price, rating, created_at, popularity.
Jaga daftar ini ketat. Membuat semuanya filterable/sortable dapat meningkatkan ukuran index dan memperlambat pembaruan.
Bahkan jika Anda punya 50.000 kecocokan, pengguna hanya melihat halaman pertama. Gunakan halaman kecil (sering 20–50 hasil), set limit yang masuk akal, dan paginasi dengan offset (atau fitur paginasi baru jika Anda suka). Juga batasi kedalaman halaman maksimum di aplikasi Anda untuk mencegah permintaan mahal seperti “halaman 400”.
Sinonim dan stop words (opsional, gunakan hati-hati)
- Sinonim membantu ketika kata berbeda berarti sama (mis. "hoodie" ↔ "sweatshirt"). Tambahkan perlahan dan tinjau analitik pencarian—terlalu banyak sinonim bisa menciptakan kecocokan yang mengejutkan.
- Stop words menghapus kata umum ("the", "and"). Mereka dapat mengurangi noise, tetapi juga bisa merusak pencarian tepat seperti nama produk ("The Who", "A Team"). Hanya kustomisasi stop words jika Anda memiliki masalah yang jelas untuk diperbaiki.
Mengintegrasikan Meilisearch ke backend aplikasi Anda
Bawa pencarian ke seluler
Hasilkan client Flutter yang memanggil endpoint pencarian backend Anda secara konsisten.
Cara bersih menambahkan pencarian server-side adalah memperlakukan Meilisearch sebagai layanan data khusus di balik API Anda. Aplikasi menerima permintaan pencarian, memanggil Meilisearch, lalu mengembalikan respons yang dikurasi ke klien.
Pola backend sederhana
Sebagian besar tim berakhir dengan alur seperti ini:
- Klien memanggil endpoint Anda (mis.
GET /api/search?q=wireless+headphones&limit=20).
- Backend Anda memvalidasi input, menerapkan aturan bisnis, dan memutuskan index mana yang akan ditanyakan.
- Backend memanggil Search API Meilisearch dengan kueri pengguna plus filter/sort.
- Backend melakukan post-process pada hasil (sembunyikan field privat, gabungkan dengan data DB, terapkan permissions).
- Backend mengembalikan bentuk respons stabil ke klien.
Pola ini menjaga Meilisearch bisa diganti dan mencegah kode frontend bergantung pada internals index.
Jika Anda membangun aplikasi baru (atau membangun ulang alat internal) dan ingin pola ini cepat diimplementasikan, platform vibe-coding seperti Koder.ai bisa membantu men-scaffold alur penuh—UI React, backend Go, dan PostgreSQL—lalu mengintegrasikan Meilisearch di balik endpoint tunggal /api/search sehingga klien tetap sederhana dan permissions tetap di sisi server.
Query di frontend vs backend (dan kenapa backend lebih aman)
Meilisearch mendukung query dari klien, tetapi query lewat backend biasanya lebih aman karena:
- Rahasia tetap privat: Anda tidak berisiko mengekspos API key yang berhak istimewa.
- Otorisasi konsisten: backend bisa memastikan “apa yang boleh dilihat pengguna” sebelum mengembalikan hit.
- Anda mengontrol kompleksitas query: batasi filter, opsi sort, dan paginasi untuk melindungi performa.
Query frontend masih bisa bekerja untuk data publik dengan kunci terbatas, tetapi jika Anda punya aturan visibilitas per pengguna, rute pencarian lewat server Anda.
Caching kueri populer tanpa merusak relevansi
Traffic pencarian sering berulang (“iphone case”, “return policy”). Tambahkan caching di lapisan API Anda:
- Cache respons penuh untuk periode singkat (mis. 10–60 detik) untuk traffic anonim.
- Normalisasi key cache (trim spasi, lowercase, sertakan filter/sort).
- Invalidasi hati-hati: untuk index yang cepat berubah, jaga TTL pendek daripada mencoba purge agresif.
Rate limiting dan kontrol penyalahgunaan
Perlakukan pencarian sebagai endpoint publik:
- Terapkan rate limit per-IP atau per-user.
- Batasi
limit maksimum dan panjang kueri maksimum.
- Pertimbangkan soft-block terhadap bot jelas sambil tetap mengizinkan pengguna nyata.
Dasar-dasar keamanan: key, kontrol akses, dan multi-tenancy
Meilisearch sering ditempatkan “di balik” aplikasi Anda karena bisa mengembalikan data bisnis sensitif dengan cepat. Perlakukan seperti database: kunci akses, dan expose hanya apa yang seharusnya dilihat tiap pemanggil.
API key: master vs scoped (prinsip least privilege)
Meilisearch punya master key yang bisa melakukan semuanya: buat/hapus index, update settings, dan baca/tulis dokumen. Simpan master key di server saja.
Untuk aplikasi, buat API key dengan aksi terbatas dan index terbatas. Pola umum:
- Job backend: key yang bisa menulis dokumen dan mengubah settings, tetapi hanya pada index tertentu.
- App server: key read-only untuk pencarian.
- Klien (jika perlu): key pencarian sangat terbatas dengan filter ketat.
Least privilege berarti key yang bocor tidak bisa menghapus data atau membaca index lain.
Multi-tenancy: index terpisah atau filter berdasarkan tenantId
Jika Anda melayani banyak pelanggan (tenant), ada dua opsi utama:
1) Satu index per tenant.
Sederhana untuk dipahami dan mengurangi risiko akses silang tenant. Kekurangannya: lebih banyak index untuk dikelola, dan update settings harus diterapkan konsisten.
2) Index bersama + filter tenant.
Simpan field tenantId pada setiap dokumen dan wajibkan filter seperti tenantId = "t_123" untuk semua pencarian. Ini bisa skala dengan baik, tetapi pastikan setiap permintaan selalu menerapkan filter (idealnya via key scoped sehingga pemanggil tidak bisa menghapusnya).
Mencegah kebocoran data: kontrol apa yang bisa dikembalikan
Bahkan jika pencarian benar, hasil bisa membocorkan field yang tidak Anda maksudkan muncul (email, catatan internal, harga pokok). Konfigurasikan apa yang bisa dikembalikan:
- Batasi displayed/retrievable attributes ke allowlist yang aman.
- Simpan field sensitif hanya jika benar-benar perlu—dan hindari mengembalikannya di hasil.
Lakukan tes “worst-case”: cari istilah umum dan pastikan tidak ada field privat muncul.
Keamanan operasional dasar
- Batasi akses jaringan: bind ke localhost atau jaringan privat, dan izinkan inbound hanya dari server aplikasi Anda.
- Tempatkan Meilisearch di balik reverse proxy jika perlu TLS dan rate limiting.
- Simpan key di secrets manager (jangan di source control atau bundle frontend) dan putar secara berkala.
Jika Anda ragu apakah sebuah key boleh di-klien, anggap "tidak" dan jaga pencarian di sisi server.
Luncurkan pencarian instan dalam beberapa hari
Siapkan indeks, filter, dan pengurutan Meilisearch lewat API berorientasi backend.
Meilisearch cepat ketika Anda menjaga dua beban kerja dalam pikiran: pengindeksan (penulisan) dan query pencarian (pembacaan). Kebanyakan "lambat misterius" biasanya salah satu dari keduanya bersaing untuk CPU, RAM, atau disk.
Beban pengindeksan bisa melonjak saat Anda mengimpor batch besar, menjalankan pembaruan sering, atau menambah banyak field searchable. Pengindeksan adalah tugas latar, tetapi tetap menggunakan CPU dan bandwidth disk. Jika antrean task menumpuk, pencarian bisa terasa lebih lambat meski volume query tidak berubah.
Beban query tumbuh dengan traffic, tetapi juga dengan fitur: lebih banyak filter, lebih banyak facet, set hasil lebih besar, dan toleransi salah ketik bisa meningkatkan kerja per permintaan.
I/O disk sering jadi penyebab sunyi. Disk lambat (atau tetangga bising pada volume bersama) bisa mengubah “instan” menjadi “nanti”. NVMe/SSD adalah baseline tipikal untuk produksi.
Langkah penskalaan praktis
Mulailah dengan sizing sederhana: beri Meilisearch cukup RAM untuk menjaga index tetap hot dan cukup CPU untuk menangani peak QPS. Kemudian pisahkan kekhawatiran:
- Jika pengindeksan mengganggu pembacaan, jadwalkan impor besar saat lalu lintas rendah dan pilih batch besar daripada banyak pembaruan kecil.
- Tambahkan replika untuk high availability dan kapasitas baca (aplikasi Anda dapat load-balance permintaan pencarian ke replika).
- Sharding: Meilisearch tidak melakukan sharding otomatis. Jika melebihi kapasitas node tunggal, Anda dapat mempartisi data di tingkat aplikasi (mis. per tenant, region, atau rentang waktu) ke beberapa index atau cluster.
Apa yang perlu dimonitor (supaya Anda tidak menebak)
Pantau beberapa sinyal kecil:
- Latensi pencarian (p50/p95) dan throughput
- Panjang antrean task / waktu proses task (antrean yang naik berarti pengindeksan tidak mengejar)
- CPU, RAM, penggunaan disk dan I/O wait
- Tingkat error (timeout, 4xx/5xx, task gagal)
Backup dan rencana upgrade
Backup harus rutin, bukan heroik. Gunakan fitur snapshot Meilisearch sesuai jadwal, simpan snapshot di luar box, dan uji pemulihan berkala. Untuk upgrade, baca release notes, stage upgrade di environment non-prod, dan rencanakan waktu reindex jika versi mempengaruhi perilaku pengindeksan.
Jika Anda sudah menggunakan snapshot lingkungan dan rollback di platform aplikasi Anda (mis. lewat workflow snapshots/rollback Koder.ai), selaraskan rollout pencarian dengan disiplin yang sama: snapshot sebelum perubahan, verifikasi health checks, dan jaga jalur cepat kembali ke kondisi baik sebelumnya.
Debugging dan checklist rollout praktis
Bahkan dengan integrasi bersih, masalah pencarian cenderung jatuh pada beberapa kategori berulang. Kabar baik: Meilisearch memberi visibilitas cukup (tasks, logs, settings deterministik) untuk men-debug cepat—jika Anda mendekatinya secara sistematis.
Masalah umum (dan arti biasanya)
- "Filter saya tidak bekerja": field tidak ditambahkan ke
filterableAttributes, atau dokumen menyimpannya dalam bentuk yang tak terduga (string vs array vs nested object).
- "Hasil berperingkat aneh": ranking rules, sinonim, stop words, atau kurangnya
sortableAttributes/rankingRules membuat item “salah” muncul di atas.
- "Pencarian menunjukkan data lama": task pengindeksan masih diproses, Anda menulis ke index berbeda dari yang dibaca, atau pipeline sinkronisasi menjatuhkan update/delete.
Alur debugging yang tetap masuk akal
Mulai dengan memeriksa apakah Meilisearch berhasil menerapkan perubahan terakhir Anda.
- Inspeksi status task: setiap perubahan settings dan update dokumen membuat task asinkron. Jika task gagal, perbaiki itu terlebih dahulu (payload buruk, tipe field salah, dokumen berukuran terlalu besar).
- Gunakan log dengan satu pertanyaan di kepala: "Apakah server menerima permintaan saya?" lalu "Apakah permintaan itu selesai diproses?" Hindari memindai semuanya sekaligus.
- Buat kueri minimal yang dapat direproduksi:
- Pilih satu index.
- Gunakan kueri yang mengembalikan set kecil dan stabil.
- Tambahkan constraint satu per satu:
filter, lalu sort, lalu facets.
Jika Anda tidak bisa menjelaskan sebuah hasil, sementara waktu kembalikan konfigurasi: hapus sinonim, kurangi tweak ranking, dan uji dengan dataset kecil. Masalah relevansi kompleks lebih mudah ditemukan pada 50 dokumen daripada pada 5 juta.
Strategi rollout: kurangi blast radius
- Uji index terlebih dahulu: bangun
your_index_v2 paralel, terapkan settings, dan replay sampel query produksi.
- Canary rollout: arahkan persentase kecil traffic pencarian ke index baru atau settings baru, bandingkan click-through dan tingkat "no results".
- Fallback behavior: tentukan apa yang pengguna lihat jika pencarian lambat atau tidak tersedia—hasil cache, kueri sederhana, atau pesan ramah "coba lagi". Jangan biarkan kegagalan pencarian merusak seluruh halaman.
Checklist langkah selanjutnya
- Verifikasi
filterableAttributes dan sortableAttributes cocok dengan kebutuhan UI Anda.
- Konfirmasi task pengindeksan selesai sukses setelah setiap deployment.
- Tambahkan monitor "kesehatan pencarian" kecil (latensi + task gagal).
- Latih rollback: alihkan traffic kembali ke index sebelumnya.
Related guides: /blog (search reliability, indexing patterns, and production rollout tips).