Definisikan Dampak Insiden dan Keputusan yang Harus Didorongnya
Sebelum Anda membangun perhitungan atau dashboard, tentukan apa arti “dampak” dalam organisasi Anda. Jika Anda melewatkan langkah ini, Anda akan mendapatkan skor yang tampak ilmiah tapi tidak membantu siapa pun untuk bertindak.
Apa yang dihitung sebagai “dampak” (dan apa yang tidak)
Dampak adalah konsekuensi terukur dari sebuah insiden terhadap sesuatu yang penting bagi bisnis. Dimensi umum meliputi:
- Pengguna: jumlah pengguna yang tidak bisa login, lonjakan error-rate pada alur penting, penurunan latensi untuk sebuah wilayah.
- Pendapatan: gagal checkout, pemblokiran perpanjangan langganan, penurunan tayangan iklan.
- Risiko SLA/SLO: menit downtime terhadap target uptime, laju pembakaran error budget.
- Tim internal: volume tiket support, beban on-call, deploy yang terblokir.
Pilih 2–4 dimensi utama dan definisikan secara eksplisit. Misalnya: “Impact = pelanggan berbayar yang terdampak + menit SLA berisiko,” bukan “Impact = apa pun yang terlihat buruk di grafik.”
Siapa yang menggunakan aplikasi, dan apa yang mereka butuhkan dalam 10 menit pertama
Peran yang berbeda mengambil keputusan yang berbeda:
- Incident commanders butuh ringkasan cepat dan dapat dipertanggungjawabkan: apa yang rusak, siapa yang terdampak, dan bagaimana tren-nya.
- Support butuh cakupan yang siap-pakai untuk pelanggan: akun, wilayah, atau plan mana yang terdampak.
- Engineering butuh hipotesis blast-radius untuk memandu debugging dan mitigasi.
- Eksekutif butuh pernyataan bisnis yang singkat: tingkat keparahan, dampak pelanggan, dan kepercayaan ETA.
Rancang keluaran “dampak” sehingga setiap audiens bisa menjawab pertanyaan utama mereka tanpa menerjemahkan metrik.
Real-time vs. near-real-time: tetapkan ekspektasi sejak awal
Putuskan latensi yang dapat diterima. “Real-time” mahal dan seringkali tidak perlu; near-real-time (mis. 1–5 menit) sering cukup untuk pengambilan keputusan.
Tuliskan ini sebagai persyaratan produk karena memengaruhi ingest, caching, dan UI.
Keputusan yang harus didukung aplikasi selama insiden
MVP Anda harus langsung mendukung tindakan seperti:
- Menetapkan tingkat keparahan dan level eskalasi
- Memicu komunikasi ke pelanggan (status page, makro support)
- Memprioritaskan pekerjaan mitigasi (layanan/tim mana dulu)
- Memutuskan rollback, feature flags, atau pergeseran trafik
- Mengidentifikasi pelanggan yang perlu dihubungi proaktif
Jika sebuah metrik tidak mengubah keputusan, besar kemungkinan itu bukan “impact”—itu hanya telemetri.
Sebelum Anda merancang layar atau memilih database, tulis apa yang harus dijawab oleh “analisis dampak” selama insiden nyata. Tujuannya bukan presisi sempurna di hari pertama—melainkan hasil yang konsisten, dapat dijelaskan, dan dipercaya responder.
Mulailah dengan data yang harus Anda ingest atau referensikan untuk menghitung dampak:
- Insiden: ID, waktu mulai/selesai, status, tim pemilik, ringkasan, tautan ke saluran/tiket insiden.
- Layanan: daftar layanan kanonis (nama, pemilik, tier/kritikalitas, tautan runbook).
- Dependensi: layanan mana yang bergantung pada layanan lain (meskipun versi pertama kasar).
- Sinyal telemetri: alert, laju pembakaran SLO, error rate/latency, event deploy—apa pun yang menunjukkan degradasi.
- Akun pelanggan: ID akun, plan/SLA, wilayah, kontak kunci, plus bagaimana akun memetakan ke layanan (langsung atau lewat workload).
Opsional saat peluncuran (rencanakan, jangan diwajibkan)
Sebagian besar tim tidak punya pemetaan dependensi atau pelanggan yang sempurna di hari pertama. Tentukan hal apa yang akan Anda izinkan untuk dimasukkan secara manual sehingga aplikasi tetap berguna:
- Seleksi manual layanan/pelanggan yang terdampak saat data hilang
- Estimasi waktu mulai atau cakupan saat telemetri tertunda
- Override dengan alasan (mis. “false positive alert,” “dampak hanya internal”)
Rancang ini sebagai field eksplisit (bukan catatan ad-hoc) sehingga bisa di-query nanti.
Keluaran kunci (apa yang harus dihasilkan aplikasi)
Rilis pertama Anda harus dapat secara andal menghasilkan:
- Layanan yang terdampak dan “mengapa” yang jelas (sinyal + dependensi)
- Daftar pelanggan dengan jumlah menurut plan/wilayah dan tampilan “top accounts”
- Skor keparahan/impact yang bisa dijelaskan dalam bahasa biasa
- Timeline kapan dampak kemungkinan mulai, mencapai puncak, dan pulih
- Opsional tapi bernilai: estimasi biaya (kredit SLA, beban support, risiko pendapatan) dengan rentang kepercayaan
Kendala non-fungsional (apa yang membuatnya dapat dipercaya)
Analisis dampak adalah alat pengambilan keputusan, jadi kendala penting:
- Latensi: dashboard harus bisa dimuat dalam hitungan detik selama insiden
- Ketersediaan: anggap seperti tooling internal kritikal; definisikan target ketersediaan
- Auditability: log siapa yang mengubah override, kapan, dan nilai sebelumnya
- Kontrol akses: batasi data pelanggan sensitif; pisahkan akses baca vs tulis
Tuliskan persyaratan ini sebagai pernyataan yang dapat diuji. Jika Anda tidak bisa memverifikasinya, Anda tidak bisa mengandalkannya saat outage.
Model Data: Insiden, Layanan, Dependensi, dan Pelanggan
Model data Anda adalah kontrak antara ingest, perhitungan, dan UI. Jika Anda melakukannya dengan benar, Anda bisa mengganti sumber tooling, menyempurnakan scoring, dan tetap menjawab pertanyaan yang sama: “Apa yang rusak?”, “Siapa yang terdampak?”, dan “Berapa lama?”
Entitas inti (jaga kecil dan bisa di-link)
Minimal, modelkan ini sebagai record kelas-satu:
- Incident: wadah narasi (judul, severity, status, pemilik), plus pointer ke bukti.
- Service: unit yang Anda petakan dependensinya (API, database, queue, penyedia pihak ketiga).
- Dependency: edge berarah service A → service B dengan metadata (tipe, kritikalitas).
- Signal: observasi ber-stempel waktu (alert, pembakaran SLO, lonjakan error, kegagalan synthetic check).
- Customer: akun atau organisasi yang mengonsumsi layanan.
- Subscription/SLA: apa yang menjadi hak pelanggan (plan, target SLA/SLO, aturan pelaporan).
Jaga ID stabil dan konsisten antar sumber. Jika Anda sudah punya katalog layanan, perlakukan itu sebagai sumber kebenaran dan petakan identifier tool eksternal ke dalamnya.
Pemodelan waktu (dampak adalah masalah jendela waktu)
Simpan beberapa timestamp pada insiden untuk mendukung pelaporan dan analisis:
- start_time / end_time: jendela dampak aktual (bisa disempurnakan nanti)
- detection_time: ketika Anda pertama kali mengetahuinya
- mitigation_time: ketika perbaikan mulai mengurangi dampak
Simpan juga time windows yang dihitung untuk scoring dampak (mis. bucket 5-menit). Ini memudahkan replay dan perbandingan.
Relasi yang menggerakkan “siapa yang terdampak?”
Modelkan dua grafik kunci:
- Service-to-service dependencies (blast radius)
- Customer-to-service usage (cakupan terdampak)
Polanya sederhana: customer_service_usage(customer_id, service_id, weight, last_seen_at) sehingga Anda bisa mengurutkan dampak berdasarkan “seberapa bergantung pelanggan pada layanan itu.”
Versi dan riwayat (dependensi berubah)
Dependensi berkembang, dan perhitungan dampak harus mencerminkan apa yang benar pada saat itu. Tambahkan tanggal efektif pada edge:
dependency(valid_from, valid_to)
Lakukan hal yang sama untuk langganan pelanggan dan snapshot penggunaan. Dengan versi historis, Anda bisa menjalankan ulang insiden masa lalu selama post-incident review dan menghasilkan pelaporan SLA yang konsisten.
Analisis dampak hanya sebaik input yang memberi makaninya. Tujuannya sederhana: tarik sinyal dari tool yang sudah Anda gunakan, lalu ubah menjadi aliran event konsisten yang bisa dipahami aplikasi.
Apa yang harus diingest (dan mengapa)
Mulailah dengan daftar singkat sumber yang andal menggambarkan “sesuatu berubah” selama insiden:
- Monitoring alerts (PagerDuty, Opsgenie, CloudWatch alarms): indikator cepat gejala dan keparahan
- Logs dan traces (ELK, Datadog, backend OpenTelemetry): bukti cakupan (endpoint mana, pelanggan mana)
- Update status page (Statuspage, Cachet): narasi resmi dan timestamp yang ditujukan ke pelanggan
- Ticketing/incident tools (Jira, ServiceNow): kepemilikan, timestamp, dan data pasca-insiden
Jangan mencoba meng-ingest semuanya sekaligus. Pilih sumber yang mencakup deteksi, eskalasi, dan konfirmasi.
Metode ingest yang bisa dipilih
Berbagai tool mendukung pola integrasi yang berbeda:
- Webhooks untuk pembaruan near-real-time (baik untuk alert dan status page)
- Polling untuk API tanpa webhook (gunakan backoff dan rate limit)
- Batch imports untuk backfill historis (berguna untuk validasi awal)
- Entri manual untuk koreksi “last mile” (analis bisa memperbaiki tag layanan yang hilang)
Pendekatan praktis: webhooks untuk sinyal kritikal, plus batch imports untuk mengisi celah.
Normalisasikan ke skema umum
Normalisasikan setiap item masuk menjadi satu bentuk “event”, meskipun sumber menyebutnya alert, incident, atau annotation. Minimal standarisasi:
- Timestamp(s): occurred_at, detected_at, resolved_at (jika tersedia)
- Service identifiers: petakan tag/nama sumber ke service ID kanonis Anda
- Severity/priority: konversi level spesifik tool ke skala Anda
- Source dan payload raw: simpan JSON asli untuk audit dan debugging
Kebersihan data: duplikasi, urutan, field yang hilang
Harapkan data yang berantakan. Gunakan idempotency key (source + external_id) untuk deduplikasi, toleransi untuk event out-of-order dengan mengurutkan berdasarkan occurred_at (bukan waktu kedatangan), dan terapkan default aman saat field hilang (seraya menandainya untuk review).
Antrian kecil “unmatched service” di UI mencegah kesalahan diam-diam dan menjaga hasil impact dapat dipercaya.
Rancang untuk 10 menit pertama
Mulai dengan kebutuhan hampir waktu nyata dan bangun layar minimal yang dibutuhkan penanggap Anda.
Jika peta dependensi Anda salah, blast radius akan salah—meskipun sinyal dan scoring Anda sempurna. Tujuannya adalah membangun grafik dependensi yang dapat dipercaya selama insiden dan juga setelahnya.
Mulai dengan katalog layanan (“sumber kebenaran” Anda)
Sebelum memetakan edge, definisikan node. Buat entri katalog layanan untuk setiap sistem yang mungkin Anda rujuk dalam insiden: API, pekerja background, penyimpanan data, vendor pihak ketiga, dan komponen bersama kritikal lainnya.
Setiap layanan setidaknya harus menyertakan: pemilik/tim, tier/kritikalitas (mis. customer-facing vs internal), target SLA/SLO, dan tautan ke runbook serta docs on-call (mis. /runbooks/payments-timeouts).
Tangkap dependensi: statis vs learned
Gunakan dua sumber yang saling melengkapi:
- Statis (dideklarasikan): apa yang tim katakan mereka bergantung pada (dari IaC, config, manifest layanan, ADR). Stabil dan mudah diaudit.
- Learned (teramati): apa yang sistem Anda benar-benar panggil (dari trace, telemetri service mesh, log gateway API, log audit egress database). Ini menangkap “unknown unknowns”, seperti panggilan downstream yang terlupakan.
Perlakukan ini sebagai tipe edge terpisah agar orang bisa memahami tingkat kepercayaan: “dideklarasikan oleh tim” vs “teramati dalam 7 hari terakhir.”
Arah dan kritikalitas penting
Dependensi harus berarah: Checkout → Payments tidak sama dengan Payments → Checkout. Arah mengarahkan alur reasoning (“jika Payments mengalami degradasi, upstream mana yang mungkin gagal?”).
Juga modelkan dependensi keras vs lunak:
- Hard: kegagalan memblokir fungsionalitas inti (layanan auth untuk login).
- Soft: degradasi mengurangi kualitas tapi ada fallback (rekomendasi, enrichment opsional).
Distingsi ini mencegah melebih-lebihkan dampak dan membantu responder memprioritaskan.
Snapshot grafik untuk replay dan analisis pasca-insiden
Arsitektur Anda berubah setiap minggu. Jika Anda tidak menyimpan snapshot, Anda tidak bisa menganalisis insiden dua bulan lalu dengan akurat.
Persist versi grafik dependensi sepanjang waktu (harian, per deploy, atau saat berubah). Saat menghitung blast radius, selesaikan timestamp insiden ke snapshot grafik terdekat, sehingga “siapa yang terdampak” mencerminkan realitas pada momen itu—bukan arsitektur hari ini.
Perhitungan Dampak: Dari Sinyal ke Skor dan Cakupan yang Terdampak
Setelah Anda meng-ingest sinyal (alert, pembakaran SLO, synthetic check, tiket pelanggan), aplikasi perlu cara konsisten mengubah input berantakan menjadi pernyataan jelas: apa yang rusak, seberapa parah, dan siapa yang terdampak?
Pilih pendekatan scoring (mulai sederhana)
Anda bisa mencapai MVP yang bisa dipakai dengan salah satu pola ini:
- Rule-based scoring: “Jika error rate checkout \u003e 5% selama 10 menit, impact = High.” Mudah dijelaskan dan di-debug.
- Formula berbobot: Gabungkan metrik yang dinormalisasi ke skor tunggal (mis. 0–100). Berguna saat banyak sinyal dan Anda ingin kurva halus.
- Mapping berbasis tier: Pemetaan sistem ke tier bisnis (Tier 0–3) dan batasi atau dorong keparahan berdasarkan tier. Ini menjaga hasil selaras dengan prioritas bisnis.
Apapun pendekatan yang dipilih, simpan nilai antaranya (ambang tercapai, bobot, tier) sehingga orang bisa memahami mengapa skor terjadi.
Definisikan dimensi dampak
Hindari menggabungkan semuanya menjadi satu angka terlalu awal. Lacak beberapa dimensi terpisah, lalu turunkan ke severity keseluruhan:
- Availability: downtime, request gagal, endpoint tak terjangkau
- Latency: degradasi p95/p99 terhadap baseline atau SLO
- Errors: lonjakan error rate, job gagal, timeout
- Kebenaran data: record hilang/keliru, pemrosesan tertunda
- Risiko keamanan: pola akses mencurigakan, indikasi ekspos data
Ini membantu responder berkomunikasi secara tepat (mis. “tersedia tapi lambat” vs “hasil salah”).
Hitung cakupan yang terdampak (pelanggan/pengguna)
Dampak bukan hanya kesehatan layanan—tetapi siapa yang merasakannya.
Gunakan pemetaan penggunaan (tenant → service, plan pelanggan → fitur, trafik pengguna → endpoint) dan hitung pelanggan terdampak dalam jendela waktu yang selaras dengan insiden (waktu mulai, mitigation time, dan periode backfill jika ada).
Jelaskan asumsi: log sampel, estimasi trafik, atau telemetri parsial.
Penyesuaian manual—dengan akuntabilitas
Operator akan perlu melakukan override: false-positive alert, rollout parsial, subset tenant yang diketahui.
Izinkan edit manual terhadap severity, dimensi, dan daftar pelanggan, tetapi wajibkan:
- Siapa yang mengubah apa
- Kapan
- Mengapa (alasan singkat + tautan tiket/runbook opsional)
Jejak audit ini melindungi kepercayaan pada dashboard dan mempercepat post-incident review.
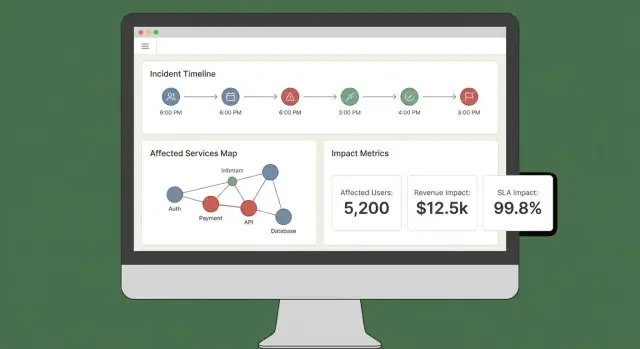
UX dan Dashboard: Buat Dampak Mudah Dipahami dalam Beberapa Menit
Dashboard impact yang baik menjawab tiga pertanyaan cepat: Apa yang terdampak? Siapa yang terdampak? Seberapa yakin kita? Jika pengguna harus membuka lima tab untuk menyusunnya, mereka tidak akan mempercayai keluaran—atau bertindak.
Tampilan inti untuk MVP
Mulailah dengan sedikit tampilan “selalu-ada” yang sesuai workflow insiden nyata:
- Incident overview: status, waktu mulai, skor impact saat ini, layanan/pelanggan terdampak teratas, dan bukti terbaru.
- Affected services: daftar terurut yang menunjukkan severity, wilayah, dan jalur dependensi (agar engineer bisa melihat di mana harus campur tangan).
- Affected customers: jumlah dan akun bernama menurut tier/plan, plus perkiraan dampak pengguna jika dilacak.
- Timeline: aliran kronologis tunggal yang menggabungkan deteksi, deploy, alert, mitigasi, dan perubahan impact.
- Actions: langkah yang disarankan, pemilik, dan tautan ke playbook atau tiket.
Buat “mengapa” terlihat
Skor tanpa penjelasan terasa sewenang-wenang. Setiap skor harus dapat ditelusuri kembali ke input dan aturan:
- Tunjukkan sinyal mana yang berkontribusi (error, latency, health checks, volume support) dan nilainya saat ini.
- Tampilkan aturan dan ambang yang dipakai (mis. “latency p95 \u003e 2s selama 10 min = degraded”).
- Tambahkan indikator kepercayaan ringan (mis. “Kepercayaan Tinggi: dikonfirmasi oleh 3 sumber”).
Panel atau drawer “Jelaskan impact” yang sederhana bisa melakukan ini tanpa memenuhi tampilan utama.
Filter dan drilldown yang sesuai pertanyaan nyata
Permudah pemotongan dampak berdasarkan layanan, wilayah, tier pelanggan, dan rentang waktu. Biarkan pengguna meng-klik titik chart atau baris apa pun untuk menggali bukti mentah (monitor, log, atau event yang memicu perubahan).
Berbagi dan ekspor
Saat insiden aktif, orang butuh pembaruan yang dapat dipindah-pindahkan. Sertakan:
- Tautan yang bisa dibagikan ke tampilan insiden (mematuhi permission)
- Ekspor CSV untuk daftar layanan/pelanggan
- Ekspor PDF untuk pembaruan status dan ringkasan pasca-insiden
Jika Anda sudah punya status page, tautkan ke sana melalui route relatif seperti /status agar tim komunikasi bisa cross-reference dengan cepat.
Keamanan, Izin, dan Audit Logging
Luncurkan halaman ringkasan
Buat tampilan ringkasan insiden yang menunjukkan apa yang rusak, siapa yang terdampak, dan mengapa.
Analisis dampak hanya berguna jika orang mempercayainya—yang berarti mengontrol siapa yang bisa melihat apa dan menyimpan catatan perubahan yang jelas.
Peran dan izin (mulai sederhana)
Definisikan set kecil peran yang cocok dengan jalannya insiden nyata:
- Viewer: akses read-only ke ringkasan insiden dan impact tingkat tinggi.
- Responder: bisa menambah catatan, mengonfirmasi layanan terdampak, dan memperbarui field operasional.
- Incident commander: bisa menyetujui override impact, menetapkan status yang ke pelanggan, dan menutup insiden.
- Admin: mengelola integrasi, penugasan peran, dan retensi data.
Jaga izin sesuai aksi, bukan jabatan. Mis. “bisa mengekspor laporan dampak pelanggan” adalah izin yang bisa diberikan kepada commander dan beberapa admin.
Lindungi data pelanggan sensitif
Analisis dampak sering menyentuh identifier pelanggan, tier kontrak, dan kadang detail kontak. Terapkan least privilege secara default:
- Masking field sensitif (mis. tampilkan 4 karakter terakhir ID akun) kecuali pengguna punya akses eksplisit.
- Pisahkan “siapa yang terdampak” dari “apa yang rusak.” Banyak pengguna hanya butuh impact tingkat layanan, bukan daftar pelanggan.
- Amankan ekspor: watermark PDF/CSV, sertakan pengguna peminta, dan batasi ekspor ke peran yang disetujui. Prefer link download signed yang berlaku singkat.
Audit logging yang menjawab “siapa mengubah apa?”
Log tindakan kunci dengan konteks yang cukup untuk review:
- Edit manual pada input impact (layanan/pelanggan yang terdampak)
- Override skor impact (nilai lama, nilai baru, alasan)
- Acknowledgment dan transisi status
- Pembuatan laporan dan ekspor
Simpan audit log append-only, dengan timestamp dan identitas aktor. Buat dapat dicari per insiden agar berguna selama post-incident review.
Rencanakan kebutuhan kepatuhan (tanpa berlebihan)
Dokumentasikan apa yang bisa Anda dukung sekarang—periode retensi, kontrol akses, enkripsi, dan cakupan audit—dan apa yang ada di roadmap.
Halaman “Security & Audit” singkat di aplikasi Anda (mis. /security) membantu men-setting ekspektasi dan mengurangi pertanyaan ad-hoc selama insiden kritikal.
Workflow dan Notifikasi Saat Insiden Aktif
Analisis dampak hanya penting selama insiden jika itu mengarahkan aksi berikutnya. Aplikasi Anda harus berperilaku seperti “co-pilot” untuk channel insiden: mengubah sinyal masuk menjadi pembaruan yang jelas, dan mendorong orang ketika dampak berubah secara berarti.
Hubungkan ke chat dan channel insiden
Mulai dengan integrasi ke tempat responder sudah bekerja (seringkali Slack, Microsoft Teams, atau tool insiden khusus). Tujuannya bukan menggantikan channel—melainkan memposting pembaruan yang kontekstual dan menjaga catatan bersama.
Polanya praktis: perlakukan channel insiden sebagai input dan output:
- Input: responder men-tag aplikasi (mis. “/impact summarize”, “/impact add affected customer Acme”) untuk mengoreksi atau memperkaya cakupan.
- Output: aplikasi memposting pembaruan singkat dan konsisten (skor impact saat ini, layanan/pelanggan terdampak, tren vs pembaruan terakhir).
Jika Anda membuat prototipe cepat, pertimbangkan membangun workflow end-to-end terlebih dahulu (incident view → summarize → notify) sebelum mematangkan scoring. Platform seperti Koder.ai bisa berguna di sini: Anda bisa iterasi pada dashboard React dan backend Go/PostgreSQL melalui workflow chat-driven, lalu mengekspor kode sumber setelah tim insiden setuju UX cocok dengan realitas.
Notifikasi berbasis ambang (bukan spam)
Hindari spam alert dengan memicu notifikasi hanya ketika impact melewati ambang eksplisit. Pemicu umum meliputi:
- Cakupan: jumlah pelanggan terdampak melonjak (mis. 10 → 100)
- Tier: layanan Tier 1 menjadi terdampak
- Pendapatan / Risiko SLA: potensi pelanggaran SLA atau keterlibatan kontrak bernilai tinggi
- Perluasan blast radius: layanan dependensi baru bergabung ke set terdampak
Saat ambang dilampaui, kirim pesan yang menjelaskan mengapa (apa yang berubah), siapa yang harus bertindak, dan apa langkah selanjutnya.
Tautkan ke runbook dan workflow
Setiap notifikasi harus menyertakan tautan “langkah selanjutnya” agar responder bisa bergerak cepat:
- Runbooks: /blog/incident-runbook-template
- Kebijakan eskalasi: /pricing
- Halaman kepemilikan layanan: /services/payments
Jaga tautan ini stabil dan relatif agar bekerja di semua environment.
Pembaruan pemangku kepentingan: internal dan untuk pelanggan
Buat dua format ringkasan dari data yang sama:
- Internal update: detail teknis, dugaan penyebab, progres mitigasi, kepercayaan ETA.
- Customer-facing update: bahasa sederhana, dampak pengguna saat ini, solusi sementara, waktu pembaruan berikutnya.
Dukung ringkasan terjadwal (mis. setiap 15–30 menit) dan aksi “generate update” on-demand, dengan langkah persetujuan sebelum dikirim ke publik.
Validasi: Testing, Replay, dan Pemeriksaan Akurasi
Jalankan untuk tim
Terapkan aplikasi dampak internal Anda dengan cepat agar penanggap bisa menggunakannya saat insiden nyata.
Analisis dampak hanya berguna jika orang mempercayainya selama insiden dan setelahnya. Validasi harus membuktikan dua hal: (1) sistem menghasilkan hasil yang stabil dan dapat dijelaskan, dan (2) hasil itu cocok dengan apa yang organisasi setujui terjadi kemudian.
Strategi testing: aturan dan pipeline
Mulai dengan tes otomatis yang mencakup dua area paling rentan: logika scoring dan ingest data.
- Unit test untuk aturan scoring: Perlakukan setiap aturan sebagai kontrak. Diberi sinyal spesifik (error rate, latency, synthetic checks, volume tiket), tes Anda harus menegaskan skor impact dan cakupan terdampak yang diharapkan. Sertakan tes batas (tepat di bawah/di atas ambang) agar jitter metrik tidak membalik hasil secara tak terduga.
- Integration test untuk ingest: Validasi jalur penuh dari webhook/event input ke record yang dinormalisasi dan impact yang dihitung. Gunakan payload rekaman dari observability dan tool insiden Anda untuk menangkap schema drift lebih awal.
Jaga fixture tes agar terbaca: ketika seseorang mengubah aturan, mereka harus bisa memahami mengapa skor berubah.
Replay insiden masa lalu untuk memvalidasi keluaran
Mode replay adalah jalur cepat menuju kepercayaan. Jalankan insiden historis melalui aplikasi dan bandingkan apa yang sistem akan tampilkan “pada saat itu” versus apa yang disimpulkan responder kemudian.
Tips praktis:
- Rekonstruksi timeline menggunakan timestamp event (bukan waktu ingest) untuk mencerminkan realitas.
- Bekukan grafik dependensi sesuai tanggal insiden jika katalog layanan Anda sudah berubah.
- Simpan hasil replay agar bisa dibandingkan setelah tweak aturan.
Tangani edge case yang melumpuhkan scoring naif
Insiden nyata jarang seperti outage bersih. Suite validasi Anda harus memasukkan skenario seperti:
- Outage parsial (beberapa endpoint atau segmen pelanggan gagal)
- Degradasi performa (lambat tapi tidak gagal) yang tetap bisa berdampak besar pada bisnis
- Kegagalan multi-region di mana layanan yang sama punya kesehatan berbeda per region
Untuk setiap skenario, pastikan bukan hanya skor, tetapi juga penjelasan: sinyal mana dan dependensi/pelanggan mana yang mendorong hasil.
Mengukur akurasi terhadap temuan pasca-insiden
Definisikan akurasi dalam istilah operasional, lalu lacak. Bandingkan impact yang dihitung dengan hasil post-incident review: layanan yang terdampak, durasi, jumlah pelanggan, pelanggaran SLA, dan severity. Log ketidaksesuaian sebagai isu validasi dengan kategori (data hilang, dependensi salah, ambang buruk, sinyal terlambat).
Seiring waktu, tujuannya bukan kesempurnaan—melainkan lebih sedikit kejutan dan lebih cepat kesepakatan selama insiden.
Deployment, Scaling, dan Iterasi Setelah MVP
Merilis MVP untuk analisis dampak insiden lebih soal keandalan dan loop umpan balik. Pilihan deployment pertama Anda harus mengoptimalkan kecepatan perubahan, bukan skala teoretis masa depan.
Pilih gaya deployment yang bisa Anda kembangkan
Mulailah dengan modular monolith kecuali Anda sudah punya tim platform kuat dan batas layanan yang jelas. Satu unit yang bisa dideploy menyederhanakan migrasi, debugging, dan pengujian end-to-end.
Pecah menjadi layanan hanya saat Anda merasakan sakit nyata:
- pipeline ingest perlu skala mandiri
- banyak tim perlu deploy secara independen
- domain kegagalan sulit dipahami dalam satu aplikasi
Tengah-tengah pragmatis: satu aplikasi + background workers (queue) + ingestion edge terpisah bila perlu. Jika ingin bergerak cepat tanpa membangun platform besar khusus sejak awal, Koder.ai dapat mempercepat MVP: alur “vibe-coding” berbasis chat cocok untuk membangun React UI, API Go, dan model data PostgreSQL, dengan snapshot/rollback saat Anda iterasi aturan scoring dan workflow.
Pilih storage berdasarkan pola akses
Gunakan penyimpanan relasional (Postgres/MySQL) untuk entitas inti: insiden, layanan, pelanggan, kepemilikan, dan snapshot perhitungan impact. Mudah di-query, diaudit, dan dikembangkan.
Untuk sinyal volume tinggi (metrik, event turunan log), tambahkan time-series store (atau penyimpanan kolom) ketika retensi sinyal mentah dan rollup jadi mahal di SQL.
Pertimbangkan graph database hanya jika query dependensi menjadi bottleneck atau model dependensi sangat dinamis. Banyak tim bisa cukup dengan tabel adjacency plus caching.
Tambahkan observability untuk aplikasi itu sendiri
Aplikasi analisis dampak menjadi bagian dari rantai tool insiden Anda, jadi instrumentasikan seperti software produksi:
- error rate dan endpoint yang lambat (terutama “recalculate impact”)
- kedalaman/lag queue worker dan tingkat retry
- throughput ingest dan jumlah kegagalan per sumber
- kesegaran data (waktu sejak pull/push terakhir berhasil)
- durasi perhitungan dan cache hit rate
Ekspos tampilan “health + freshness” di UI agar responder dapat mempercayai (atau mempertanyakan) angkanya.
Rencanakan iterasi dan refactor dengan sengaja
Definisikan scope MVP secara ketat: sekumpulan kecil tool untuk ingest, skor impact yang jelas, dan dashboard yang menjawab “siapa yang terdampak dan seberapa banyak.” Lalu iterasi:
- Fitur berikutnya: ketepatan dependensi yang lebih baik, pembobotan spesifik pelanggan, ekspor pelaporan SLA, replay untuk insiden masa lalu
- Pemicu refactor: Anda menambah special-case setiap minggu, recalculation terlalu lambat, atau model data tidak bisa mengekspresikan realitas tanpa hack
Perlakukan model sebagai produk: beri versi, migrasikan dengan aman, dan dokumentasikan perubahan untuk post-incident review.