Definisikan Tujuan dan Sinyal Adopsi
Sebelum Anda membuat skor kesehatan adopsi pelanggan, tentukan apa yang Anda ingin skor lakukan untuk bisnis. Skor yang dibuat untuk memicu peringatan risiko churn akan berbeda dari yang dimaksudkan untuk membimbing onboarding, edukasi pelanggan, atau perbaikan produk.
Definisikan apa arti “adopsi” untuk produk Anda
Adopsi bukan sekadar “baru-baru ini masuk.” Tuliskan beberapa perilaku yang benar-benar menunjukkan pelanggan mencapai nilai:
- Aktivasi: momen pertama pengguna mencapai hasil bermakna (mis. “mengundang rekan,” “menghubungkan sumber data,” “mempublikasikan laporan”).
- Aksi inti: perilaku berulang bernilai tinggi yang berkorelasi dengan akun sukses (mis. ekspor mingguan, pelaksanaan otomasi, dashboard dilihat oleh banyak pengguna).
- Retensi: penggunaan berlanjut dengan frekuensi yang tepat untuk produk Anda (harian, mingguan, bulanan), idealnya oleh lebih dari satu pengguna dalam akun.
Ini menjadi sinyal adopsi awal Anda untuk analitik penggunaan fitur dan analisis kohort di kemudian hari.
Daftar keputusan yang harus didukung aplikasi Anda
Jelaskan apa yang terjadi saat skor berubah:
- Siapa yang diberi tahu saat akun turun di bawah ambang?
- Playbook apa yang harus diluncurkan (outreach, pelatihan, pemeriksaan support)?
- Insight mana yang harus menginformasikan pemantauan adopsi produk (titik friction, fitur yang kurang digunakan, time-to-value)?
Jika Anda tidak bisa menamai sebuah keputusan, jangan lacak metriknya dulu.
Identifikasi pengguna, peran, dan jendela waktu
Perjelas siapa yang akan menggunakan dashboard customer success:
- Manajer CS butuh prioritisasi dan konteks akun.
- Tim Produk butuh pola, kohort, dan pergerakan level fitur.
- Support butuh aktivitas terbaru terkait tiket dan insiden.
- Leadership butuh roll-up dan tren yang mudah dimengerti.
Pilih jendela standar—7/30/90 hari terakhir—dan pertimbangkan tahapan lifecycle (trial, onboarding, steady-state, renewal). Ini mencegah membandingkan akun baru dengan akun matang.
Tetapkan kriteria keberhasilan
Definisikan “selesai” untuk model skor kesehatan Anda:
- Akurasi: apakah model memprediksi risiko dan sinyal ekspansi lebih baik dari pendekatan saat ini?
- Keterjelasan: dapatkah CSM menjelaskan mengapa skor tinggi/rendah dalam satu menit?
- Kemudahan penggunaan: apakah ini menghemat waktu dan mendorong tindakan yang konsisten?
Tujuan ini membentuk semuanya ke hilir: pelacakan event, logika scoring, dan workflow yang Anda bangun di sekitar skor.
Pilih Metrik untuk Skor Kesehatan Anda
Memilih metrik adalah titik di mana skor Anda menjadi sinyal berguna atau angka berisik. Bidik sekumpulan indikator kecil yang mencerminkan adopsi nyata—bukan sekadar aktivitas.
Mulai dari sinyal adopsi produk
Pilih metrik yang menunjukkan apakah pengguna berulang kali mendapatkan nilai:
- Logins / active users: mis. weekly active users (WAU) dan tren selama 4–8 minggu terakhir.
- Active days: berapa hari berbeda akun aktif dalam minggu/bulan (mencegah false positive “satu sesi besar”).
- Kedalaman fitur: penggunaan “value features” Anda (aksi yang berkorelasi dengan sukses), bukan setiap klik tombol.
- Integrasi yang terhubung: terutama jika integrasi meningkatkan switching costs atau membuka alur kerja penting.
- Pemakaian seat: persentase seat yang dibeli yang diundang, diaktifkan, dan benar-benar aktif.
Sederhanakan daftarnya. Jika Anda tidak bisa menjelaskan mengapa metrik penting dalam satu kalimat, besar kemungkinan bukan input inti.
Tambahkan konteks bisnis (agar skor adil)
Adopsi harus ditafsirkan dalam konteks. Tim 3-seat akan berperilaku berbeda dibanding rollout 500-seat.
Sinyal konteks umum:
- Tier paket dan entitlements fitur
- Ukuran kontrak / band ARR
- Tahap lifecycle: trial vs baru bayar vs di dekat renew
Ini tidak harus “menambah poin,” tapi membantu menetapkan ekspektasi dan ambang yang realistis per segmen.
Putuskan indikator leading vs lagging
Skor yang berguna memadukan:
- Leading indicators (memprediksi kesuksesan): kenaikan active days, penyelesaian onboarding, integrasi pertama terhubung.
- Lagging indicators (mengonfirmasi hasil): renewal, ekspansi, retensi jangka panjang.
Hindari memberi bobot berlebihan pada lagging; mereka hanya menceritakan apa yang sudah terjadi.
Jika Anda memilikinya, NPS/CSAT, volume tiket support, dan catatan CSM bisa menambah nuansa. Gunakan ini sebagai modifier atau flag—bukan sebagai dasar—karena data kualitatif bisa jarang dan subjektif.
Buat data dictionary sederhana
Sebelum membuat chart, sepakati nama dan definisi. Data dictionary ringan harus mencakup:
- Nama metrik (mis.
active_days_28d)
- Definisi jelas (apa yang dihitung, apa yang tidak)
- Jendela waktu dan frekuensi refresh
- Sistem sumber (product events, CRM, support)
Ini mencegah kebingungan "metrik sama, makna berbeda" nanti saat Anda mengimplementasikan dashboard dan alert.
Rancang Model Skor yang Dapat Dijelaskan
Skor adopsi hanya bekerja jika tim Anda mempercayainya. Bidik model yang bisa Anda jelaskan dalam satu menit ke CSM dan lima menit ke pelanggan.
Mulai sederhana: poin berbobot (sebelum ML)
Mulai dengan skor berbasis aturan yang transparan. Pilih beberapa sinyal adopsi (mis. active users, penggunaan fitur kunci, integrasi aktif) dan tetapkan bobot yang mencerminkan momen “aha” produk Anda.
Contoh pembobotan:
- Weekly active users per seat: 0–40 poin
- Frekuensi penggunaan fitur kunci: 0–35 poin
- Luas fitur yang digunakan: 0–15 poin
- Waktu sejak aktivitas bermakna terakhir: 0–10 poin
Buat bobot mudah dipertahankan. Anda bisa meninjau nanti—jangan menunggu model sempurna.
Normalisasi untuk mengurangi bias
Hitungan mentah menghukum akun kecil dan membuat akun besar tampak rata. Normalisasi metrik bila perlu:
- Per seat (penggunaan / licensed seats)
- Berdasarkan umur akun (akun baru vs matang)
- Berdasarkan tier paket (ketersediaan fitur)
Ini membantu skor kesehatan adopsi pelanggan mencerminkan perilaku, bukan sekadar ukuran.
Definisikan green/yellow/red dengan alasan jelas
Tetapkan ambang (mis. Green ≥ 75, Yellow 50–74, Red < 50) dan dokumentasikan mengapa tiap cutoff ada. Kaitkan ambang ke hasil yang diharapkan (risiko renewal, penyelesaian onboarding, kesiapan ekspansi), dan simpan catatan di dokumen internal atau /blog/health-score-playbook.
Buat skor dapat dijelaskan: kontributor dan tren
Setiap skor harus menunjukkan:
- 3 kontributor teratas (apa yang membantu/merugikan)
- Perubahan dari waktu ke waktu (7/30 hari terakhir)
- Ringkasan bahasa-umum (“Penggunaan Fitur X turun 35% week-over-week”)
Rencanakan iterasi: versioning model
Anggap scoring sebagai produk. Versi-kan (v1, v2) dan lacak dampaknya: Apakah peringatan risiko churn menjadi lebih akurat? Apakah CSM bertindak lebih cepat? Simpan versi skor dengan setiap perhitungan agar Anda bisa membandingkan hasil seiring waktu.
Instrumentasikan Event Produk dan Sumber Data
Skor kesehatan hanya seandal data aktivitas di belakangnya. Sebelum Anda membuat logika scoring, pastikan sinyal yang tepat ditangkap konsisten di semua sistem.
Pilih sumber event Anda
Sebagian besar program adopsi menarik data dari campuran:
- Frontend events (page views, klik, interaksi fitur)
- Backend actions (panggilan API, job selesai, record dibuat)
- Billing (paket, renewals, status pembayaran, jumlah seat)
- Support dan tools sukses (tiket, CSAT, milestone onboarding)
Aturan praktis: lacak aksi kritis server-side (lebih sulit dipalsukan, tidak terpengaruh ad blocker) dan gunakan frontend events untuk engagement UI dan discovery.
Definisikan skema event yang jelas
Pertahankan kontrak konsisten agar event mudah di-join, di-query, dan dijelaskan ke stakeholder. Baseline umum:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, dll.)
Gunakan vocabulary terkontrol untuk event_name (mis. project_created, report_exported) dan dokumentasikan di tracking plan sederhana.
Tentukan SDK vs server-side (atau keduanya)
- SDK tracking cepat untuk dikirim dan bagus untuk event UI.
- Server-side tracking lebih baik untuk aksi system-of-record.
Banyak tim melakukan keduanya, tapi pastikan Anda tidak menghitung dua kali aksi dunia nyata yang sama.
Tangani identity dengan benar
Skor biasanya di-rollup ke level akun, jadi Anda butuh pemetaan user→account yang andal. Rencanakan untuk:
- Pengguna yang tergabung di banyak akun
- Merge akun (akuisisi, konsolidasi workspace)
- ID anonim untuk perilaku pra-login (dengan penggabungan aman setelah signup)
Masukkan pemeriksaan kualitas data
Setidaknya, pantau event yang hilang, lonjakan duplikat, dan konsistensi zona waktu (simpan UTC; konversi untuk tampilan). Flag anomali awal sehingga peringatan risiko churn tidak menyala karena tracking rusak.
Modelkan Data dan Penyimpanan
Aplikasi skor kesehatan adopsi pelanggan hidup/mati berdasarkan bagaimana Anda memodelkan “siapa melakukan apa, dan kapan.” Tujuannya membuat pertanyaan umum cepat dijawab: Bagaimana akun ini perform bulan ini? Fitur mana yang sedang naik/turun? Pemodelan data yang baik membuat scoring, dashboard, dan alert sederhana.
Entitas inti untuk dimodelkan
Mulai dengan sekumpulan tabel “source of truth” kecil:
- Accounts: account_id, plan, segment, lifecycle stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions (atau contracts): account_id, start/end, seats, MRR, renewal date
- Features: feature_id, name, category (activation, collaboration, admin, dll.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (or computed_at), overall_score, component scores, explanation fields
Jaga konsistensi entitas ini dengan menggunakan ID stabil (account_id, user_id) di mana-mana.
Pisahkan penyimpanan: relational + analytics
Gunakan relational database (mis. Postgres) untuk accounts/users/subscriptions/scores—hal yang sering Anda update dan join. Simpan event ber-volume tinggi di warehouse/analytics (mis. BigQuery/Snowflake/ClickHouse). Ini membuat dashboard dan analisis kohort responsif tanpa membebani DB transaksi.
Simpan agregat untuk kecepatan
Daripada menghitung ulang dari raw event, pertahankan:
- Ringkasan akun harian (satu baris per akun per hari): active users, hitungan event kunci, last activity, adoption milestones
- Counter fitur: per akun/hari/fitur hitungan penggunaan, unique users, waktu yang dihabiskan (jika tersedia)
Tabel ini menopang chart tren, insight “apa yang berubah”, dan komponen skor.
Untuk tabel event besar, rencanakan retensi (mis. 13 bulan raw, lebih lama untuk agregat) dan partisi berdasarkan tanggal. Cluster/index berdasarkan account_id dan timestamp/date untuk mempercepat query "akun sepanjang waktu".
Di tabel relational, index filter dan join umum: account_id, (account_id, date) pada ringkasan, dan foreign key untuk menjaga kebersihan data.
Rencanakan Arsitektur Aplikasi Web
Rilis skor kesehatan v1
Ubah ide skor kesehatan Anda menjadi dashboard yang berfungsi lewat chat tanpa perlu menyiapkan kerangka.
Arsitektur Anda harus memudahkan pengiriman v1 yang dapat dipercaya, lalu berkembang tanpa rewrite. Mulai dengan memutuskan berapa banyak bagian yang benar-benar Anda butuhkan.
Monolith vs services (jaga v1 sederhana)
Bagi kebanyakan tim, modular monolith adalah jalan tercepat: satu codebase dengan batasan jelas (ingestion, scoring, API, UI), satu unit deployable, dan lebih sedikit kejutan operasional.
Pindah ke services hanya bila ada alasan jelas—kebutuhan scaling terpisah, isolasi data ketat, atau tim berbeda memegang komponen. Lainnya, layanan terpisah prematur menambah titik kegagalan dan memperlambat iterasi.
Definisikan komponen inti
Setidaknya, rencanakan tanggung jawab ini (meski awalnya berada dalam satu aplikasi):
- Ingestion: menerima product events (SDK, Segment, webhook, batch imports).
- Aggregation: mengubah raw events menjadi fakta penggunaan harian/mingguan per akun/user.
- Scoring: menghitung skor kesehatan adopsi pelanggan dan penjelasan pendukung.
- API: melayani skor, tren, dan insight “mengapa” ke UI dan integrasi.
- UI: dashboard customer success dengan tampilan akun, kohort, dan drill-down.
Jika ingin prototipe cepat, pendekatan vibe-coding dapat membantu Anda mendapatkan dashboard kerja tanpa investasi scaffolding berat. Misalnya, Koder.ai dapat menghasilkan UI React dan backend Go + PostgreSQL dari deskripsi chat sederhana—berguna untuk menyiapkan v1 yang bisa diuji tim CS lebih awal.
Scheduled jobs vs streaming
Batch scoring (mis. per jam/hari) biasanya cukup untuk pemantauan adopsi dan jauh lebih mudah dioperasikan. Streaming masuk akal jika Anda butuh alert hampir real-time (mis. penurunan penggunaan mendadak) atau volume event sangat besar.
Hybrid praktis: ingest event terus-menerus, aggregate/scoring menurut jadwal, dan gunakan streaming untuk sejumlah sinyal mendesak.
Lingkungan, secrets, dan kebutuhan non-fungsional
Siapkan dev/stage/prod lebih awal, dengan akun sampel di stage untuk memvalidasi dashboard. Gunakan managed secrets store dan rotasi kredensial.
Dokumentasikan kebutuhan di muka: volume event yang diharapkan, freshness skor (SLA), target latensi API, availability, retensi data, dan batasan privasi (penanganan PII dan kontrol akses). Ini mencegah keputusan arsitektur dibuat telat—di bawah tekanan.
Bangun Data Pipeline dan Job Scoring
Skor kesehatan hanya seandal pipeline yang menghasilkannya. Perlakukan scoring seperti sistem produksi: dapat direproduksi, terobservasi, dan mudah dijelaskan saat seseorang bertanya, “Kenapa akun ini turun hari ini?”
Pipeline sederhana: raw → validated → aggregates
Mulai dengan alur staged yang menyempitkan data menjadi sesuatu yang aman untuk di-score:
- Raw events: append-only ingestion dari app, mobile, integrasi, dan export billing/CRM.
- Validated events: event yang lolos schema check (kolom wajib, tipe benar), identity check (user → account mapping), dan deduplikasi.
- Daily aggregates: rollup per akun (dan opsional workspace/team) seperti active users, hitungan event kunci, milestone time-to-value, dan delta tren.
Struktur ini membuat job scoring cepat dan stabil, karena bekerja pada tabel bersih dan ringkas daripada miliaran baris raw.
Jadwal recalculation dan backfill
Tentukan seberapa “segar” skor perlu:
- Hourly scoring cocok untuk motion high-touch di mana CSM bertindak cepat.
- Daily scoring sering cukup untuk SMB/self-serve dan mengurangi biaya.
Buat scheduler yang mendukung backfills (mis. reprocessing 30/90 hari terakhir) ketika Anda memperbaiki tracking, mengubah bobot, atau menambah sinyal. Backfill harus menjadi fitur kelas-satu, bukan skrip darurat.
Idempotency: hindari double-counting
Job akan di-retry. Import akan dijalankan ulang. Webhook bisa dikirim dua kali. Rancang untuk itu.
Gunakan idempotency key untuk event (event_id atau hash stabil dari timestamp + user_id + event_name + properties) dan tegakkan uniqueness di layer validated. Untuk agregat, upsert by (account_id, date) sehingga recomputation menggantikan hasil sebelumnya alih-alih menambah.
Monitoring dan cek anomali
Tambahkan monitoring operasional untuk:
- Sukses/gagal job dan jumlah retry
- Data lag (seberapa jauh di belakang “sekarang” agregat terbaru Anda)
- Anomali volume (penurunan/ lonjakan event, active users, aksi kunci)
Ambang ringan (mis. “event turun 40% vs rata-rata 7-hari”) mencegah kerusakan silent yang menyesatkan dashboard customer success.
Audit trail untuk setiap skor
Simpan catatan audit per akun per run scoring: metrik input, fitur turunan (mis. perubahan week-over-week), versi model, dan skor final. Saat CSM mengklik “Kenapa?”, Anda bisa menunjukkan persis apa yang berubah dan kapan—tanpa merekayasa balik dari log.
Buat API Aman untuk Kesehatan dan Insight
Kurangi biaya pembangunan
Dapatkan kredit dengan membagikan proses pembangunan Anda atau merekomendasikan rekan ke Koder.ai.
Aplikasi web Anda hidup/mati oleh API-nya. Itu kontrak antara job scoring, UI, dan alat downstream (platform CS, BI, export data). Bidik API yang cepat, prediktabel, dan aman secara default.
Endpoint inti untuk mendukung alur nyata
Rancang endpoint berdasarkan cara Customer Success mengeksplorasi adopsi:
- Account health:
GET /api/accounts/{id}/health mengembalikan skor terbaru, status band (mis. Green/Yellow/Red), dan timestamp perhitungan terakhir.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= untuk skor dari waktu ke waktu dan delta metrik kunci.
- Drivers (“why”):
GET /api/accounts/{id}/health/drivers untuk menunjukkan faktor positif/negatif teratas (mis. “weekly active seats turun 35%”).
- Cohorts:
GET /api/cohorts/health?definition= untuk analisis kohort dan benchmark peer.
- Exports:
POST /api/exports/health untuk menghasilkan CSV/Parquet dengan skema konsisten.
Buat endpoint list mudah diiris:
- Filters:
plan, segment, csm_owner, lifecycle_stage, dan date_range adalah esensial.
- Pagination: gunakan cursor-based pagination (
cursor, limit) untuk stabilitas saat data berubah.
- Caching: cache query berat (cohort rollups, series tren) dan kembalikan
ETag/If-None-Match untuk mengurangi beban ulang. Buat kunci cache peka terhadap filter dan permission.
Keamanan dengan role-based access control
Lindungi data di level akun. Terapkan RBAC (mis. Admin, CSM, Read-only) dan tegakkan di server untuk setiap endpoint. Seorang CSM hanya boleh melihat akun yang menjadi tanggungannya; peran finance mungkin melihat agregat tingkat paket tapi bukan detail user-level.
Selalu kembalikan keterjelasan
Selain angka skor kesehatan adopsi pelanggan, kembalikan field “mengapa”: kontributor teratas, metrik yang terpengaruh, dan baseline perbandingan (periode sebelumnya, median kohort). Ini mengubah pemantauan adopsi produk menjadi tindakan, bukan sekadar laporan, dan membuat dashboard customer success dapat dipercaya.
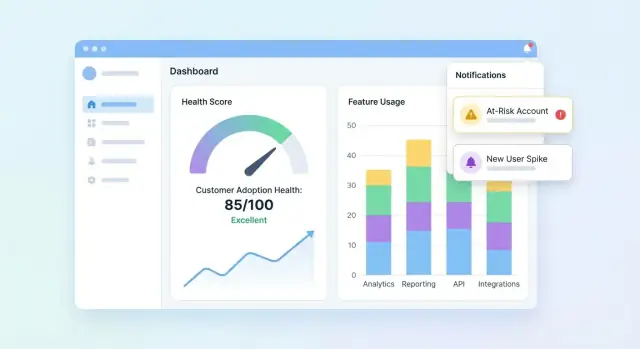
Rancang Dashboard dan Tampilan Akun
UI Anda harus menjawab tiga pertanyaan dengan cepat: Siapa sehat? Siapa yang menurun? Kenapa? Mulai dengan dashboard yang merangkum portofolio, lalu biarkan pengguna drill-in ke akun untuk memahami cerita di balik skor.
Esensial dashboard portofolio
Sertakan kumpulan tiles dan chart ringkas yang bisa dipindai tim customer success dalam beberapa detik:
- Distribusi skor (histogram atau bucket seperti Healthy / Watch / At-risk)
- Daftar at-risk dengan beberapa field yang diperlukan untuk bertindak (akun, owner, skor, last activity, top driver)
- Tren skor dari waktu ke waktu (line chart) dengan opsi filter berdasarkan segmen
Buat daftar at-risk bisa diklik agar pengguna membuka akun dan langsung melihat apa yang berubah.
Tampilan akun: jelaskan skornya
Halaman akun harus dibaca seperti timeline adopsi:
- Timeline event kunci (langkah onboarding selesai, integrasi terhubung, perubahan admin, first-use fitur besar)
- Metrik utama (active users, aksi fitur kunci, waktu sejak aktivitas bermakna)
- Rincian adopsi fitur yang menunjukkan fitur mana yang diadopsi, diabaikan, atau menurun
Tambahkan panel “Kenapa skor ini?”: klik skor menampilkan sinyal kontributor (positif dan negatif) dengan penjelasan bahasa biasa.
Tampilan kohort dan segmen
Sediakan filter kohort yang sesuai dengan cara tim mengelola akun: kohort onboarding, tier paket, dan industri. Padukan setiap kohort dengan garis tren dan tabel kecil top movers agar tim bisa membandingkan hasil dan menemukan pola.
Visual yang dapat diakses dan dapat dipercaya
Gunakan label dan satuan yang jelas, hindari ikon ambigu, dan tawarkan indikator status yang ramah warna (mis. label teks + bentuk). Perlakukan chart sebagai alat keputusan: beri anotasi pada lonjakan, tunjukkan jangka tanggal, dan buat perilaku drill-down konsisten di seluruh halaman.
Tambahkan Alert, Tugas, dan Workflow
Skor kesehatan berguna hanya jika mendorong tindakan. Alert dan workflow mengubah “data menarik” menjadi outreach tepat waktu, perbaikan onboarding, atau nudges produk—tanpa memaksa tim menatap dashboard terus-menerus.
Mulai dengan sekumpulan trigger sinyal tinggi:
- Penurunan skor (mis. turun 15 poin week-over-week)
- Status Red (melintasi ambang kritis)
- Penurunan penggunaan mendadak (penggunaan fitur kunci di bawah baseline)
- Gagal langkah onboarding (item checklist terhenti, integrasi belum selesai)
Jadikan setiap rule eksplisit dan dapat dijelaskan. Alih-alih “Kondisi kesehatan buruk,” alertkan “Tidak ada aktivitas di Fitur X selama 7 hari + onboarding belum lengkap.”
Pilih saluran dan biarkan dapat dikonfigurasi
Tim berbeda bekerja berbeda, jadi bangun dukungan saluran dan preferensi:
- Email untuk pemilik akun dan manajer
- Slack untuk visibilitas tim dan respon cepat
- Tugas in-app di dashboard customer success agar pekerjaan tidak hilang
Biarkan tiap tim mengonfigurasi: siapa diberi tahu, rule mana yang diaktifkan, dan ambang mana yang berarti “mendesak.”
Kurangi noise dengan guardrail
Alert fatigue membunuh pemantauan adopsi. Tambahkan kontrol seperti:
- Cooldown windows (jangan re-alert untuk akun yang sama selama N jam/hari)
- Ambang data minimum (lewati alert jika akun punya terlalu sedikit data terbaru)
- Batching/digests untuk sinyal non-mendesak (ringkasan harian/mingguan)
Tambahkan konteks dan langkah selanjutnya
Setiap alert harus menjawab: apa yang berubah, kenapa penting, dan apa yang harus dilakukan. Sertakan kontributor skor terbaru, timeline singkat (mis. 14 hari terakhir), dan tugas yang disarankan seperti “Jadwalkan panggilan onboarding” atau “Kirim panduan integrasi.” Link ke tampilan akun (mis. /accounts/{id}).
Perlakukan alert seperti item kerja dengan status: acknowledged, contacted, recovered, churned. Pelaporan hasil membantu Anda menyempurnakan rule, memperbaiki playbook, dan membuktikan skor kesehatan mendorong dampak retensi terukur.
Pastikan Kualitas Data, Privasi, dan Tata Kelola
Buat prototipe alur kerja CS
Siapkan tampilan portofolio, detail akun, dan driver 'mengapa' dalam hitungan hari, bukan minggu.
Jika skor kesehatan dibangun di atas data yang tidak andal, tim akan berhenti mempercayainya—dan berhenti bertindak. Perlakukan kualitas, privasi, dan governance sebagai fitur produk, bukan hal yang disampingkan.
Masukkan cek data otomatis
Mulai dengan validasi ringan di setiap titik serah (ingest → warehouse → scoring output). Beberapa tes high-signal menangkap sebagian besar masalah dini:
- Schema checks: kolom yang diharapkan ada, tipe tidak berubah, enum valid.
- Range checks: nilai tidak mungkin (sesi negatif, timestamp di masa depan) gagal cepat.
- Null checks: field wajib (account_id, event_name, occurred_at) tidak boleh kosong.
Saat tes gagal, blokir job scoring (atau tandai hasil sebagai “stale”) agar pipeline rusak tidak diam-diam menghasilkan peringatan risiko churn menyesatkan.
Tangani edge case umum secara eksplisit
Scoring rusak pada skenario “aneh tapi normal.” Definisikan aturan untuk:
- Akun baru dengan sedikit data: tampilkan “data tidak cukup” atau gunakan baseline ramp-up daripada skor rendah.
- Penggunaan musiman: bandingkan ke periode sebelumnya akun atau benchmark kohort daripada ambang universal.
- Outage dan celah tracking: flag window yang terpengaruh dan hindari menghukum pelanggan karena downtime Anda.
Tambahkan kontrol permission dan privasi
Batasi PII secara default: simpan hanya yang diperlukan untuk pemantauan adopsi produk. Terapkan RBAC di web app, log siapa melihat/mengekspor data, dan redaksi export jika field tidak diperlukan (mis. sembunyikan email di CSV).
Buat runbook dan kebiasaan governance
Tulis runbook singkat untuk respons insiden: cara menjeda scoring, backfill data, dan menjalankan ulang job historis. Tinjau metrik customer success dan bobot skor secara berkala—bulanan atau kuartalan—untuk mencegah drift seiring evolusi produk Anda. Untuk penyesuaian proses, tautkan checklist internal Anda dari /blog/health-score-governance.
Validasi, Iterasi, dan Skala Skor Kesehatan
Validasi adalah tempat skor berhenti menjadi “grafik bagus” dan mulai dipercaya untuk mendorong tindakan. Anggap versi pertama sebagai hipotesis, bukan jawaban final.
Jalankan pilot dan kalibrasi terhadap penilaian manusia
Mulai dengan pilot akun (mis. 20–50 lintas segmen). Untuk tiap akun, bandingkan skor dan alasan risiko dengan penilaian CSM.
Cari pola:
- Skor yang konsisten lebih tinggi/rendah dari penilaian CSM (kalibrasi)
- “False alarms” (risiko tinggi tapi akun baik-baik saja) vs “misses” (skor sehat tapi akun churn)
- Alasan yang tidak sesuai kenyataan (gap keterjelasan)
Ukur apakah ini benar-benar berguna
Akurasi membantu, tapi kegunaan yang menghasilkan nilai. Lacak hasil operasional seperti:
- Waktu untuk mendeteksi risiko (seberapa dini Anda menandai masalah)
- Tingkat keberhasilan outreach (persentase akun berisiko yang membaik setelah intervensi)
- Proksi pengurangan churn (perubahan likelihood renewal, sinyal ekspansi, perubahan beban support)
Uji perubahan dengan aman menggunakan versioning
Saat Anda mengubah threshold, bobot, atau menambah sinyal, perlakukan itu sebagai versi model baru. A/B test versi pada kohort atau segmen yang sebanding, dan simpan versi historis agar Anda bisa menjelaskan kenapa skor berubah dari waktu ke waktu.
Kumpulkan umpan balik dalam UI
Tambahkan kontrol ringan seperti “Skor terasa salah” plus alasan (mis. “penyelesaian onboarding terbaru belum tercermin”, “penggunaan musiman”, “pemetaan akun salah”). Rutekan umpan balik ini ke backlog, dan tag ke akun serta versi skor untuk debugging lebih cepat.
Skala dengan roadmap
Setelah pilot stabil, rencanakan pekerjaan scale-up: integrasi lebih dalam (CRM, billing, support), segmentasi (berdasarkan paket, industri, lifecycle), automasi (tugas dan playbook), dan self-serve setup agar tim bisa men-customize tampilan tanpa engineering.
Saat Anda menskalakan, jaga loop build/iterate tetap rapat. Tim sering menggunakan Koder.ai untuk memutar halaman dashboard baru, menyempurnakan shape API, atau menambah fitur workflow (tugas, export, release yang bisa rollback) langsung dari chat—berguna ketika Anda versioning model skor dan perlu mengirim perubahan UI + backend bersama tanpa memperlambat siklus umpan balik CS.